

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課的第一週內容,1.8的內容以及一些相關基礎的補充。
本週為第五課的第一週內容,與 CV 相對應的,這一課所有內容的中心只有一個:自然語言處理(Natural Language Processing,NLP)。
應用在深度學習裏,它是專門用來進行文本與序列信息建模的模型和技術,本質上是在全連接網絡與統計語言模型基礎上的一次“結構化特化”,也是人工智能中最貼近人類思維表達方式的重要研究方向之一。
這一整節課同樣涉及大量需要反覆消化的內容,橫跨機器學習、概率統計、線性代數以及語言學直覺。
語言不像圖像那樣“直觀可見”,更多是抽象符號與上下文關係的組合,因此理解門檻反而更高。
因此,我同樣會儘量補足必要的背景知識,儘可能用比喻和實例降低理解難度。
本篇的內容關於RNN 中的梯度現象,是對 RNN 中存在的問題的闡述,也是對之後的門控機制的引入內容。
1. RNN 中的梯度現象
在很久之前,我們就介紹過深度學習訓練中的梯度現象,這種情況主要出現在深層神經網絡中,在反向傳播中隨着層層的梯度計算導致梯度過大或過小,從而出現梯度爆炸或者梯度消失,導致網絡無法訓練。
而在 RNN 中,即使是我們演示過的單層 RNN ,也可能產生梯度現象,而且這一問題會顯得更加隱蔽,卻也更加嚴重,其原因就在於 RNN 的時間反向傳播特性。
1.1 RNN 的深度
首先,我們知道:RNN 的“深度”並不體現在空間結構上,而是體現在時間維度上。
因此,雖然我們畫出來的 RNN 看起來只有一層,但在訓練時,RNN 會在時間維度上被“展開”為一個共享參數的深層網絡,就像這樣:
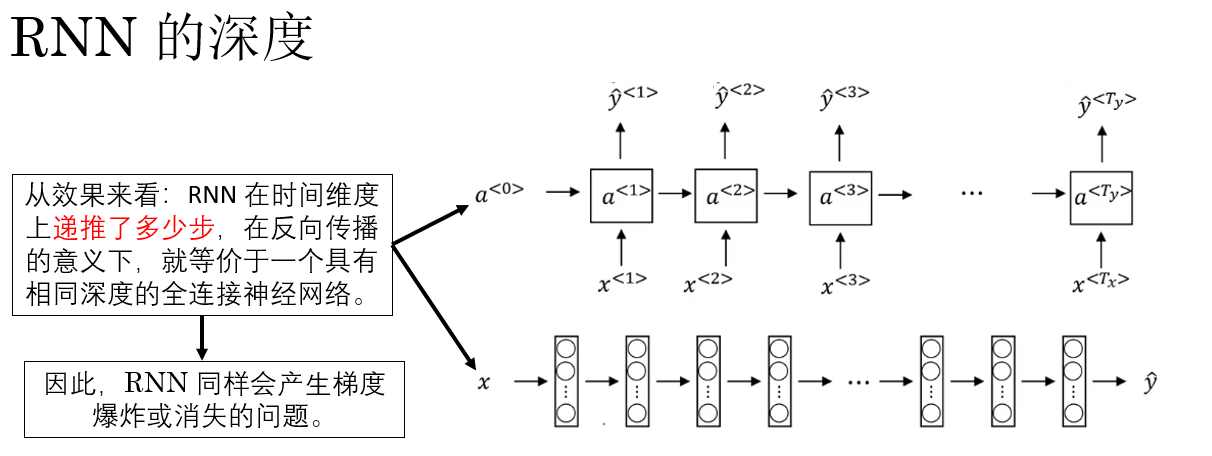
也就是説,如果序列長度為 \(T\),那麼在反向傳播時,梯度就需要沿着時間軸,從第 \(T\) 個時刻一路反傳回第 \(1\) 個時刻。
需要説明的是,這裏時間展開的長度 \(T\) 指的是 RNN 在時間維度上的遞推步數,在我們介紹的基礎 RNN 場景下,通常等同於輸入序列的長度 \(T_x\),而非生成序列的長度 \(T_y\)。
最終,從效果上看,這相當於: 同一組權重矩陣被反覆相乘了 \(T\) 次。
因此,在 RNN 中,我們同樣有必要了解訓練中出現梯度現象的處理方法。
1.2 梯度爆炸的處理:梯度裁剪(Gradient Clipping)
在 RNN 的梯度問題中,梯度爆炸通常是最先、也是最容易被觀察到的現象。
其表現非常直觀:損失函數在訓練過程中劇烈震盪,甚至直接變為 NaN,參數更新完全失控,模型無法繼續訓練。
與梯度消失不同,梯度爆炸並不是“學不到”,而是 “學得太猛”。
因此,相比梯度消失,梯度爆炸問題更容易被控制和緩解。這很好理解:東西多了我們可以扔,但少了我們不能憑空創造出來。
而其中一種最常見、也最直接的方法,就是梯度裁剪(Gradient Clipping)。
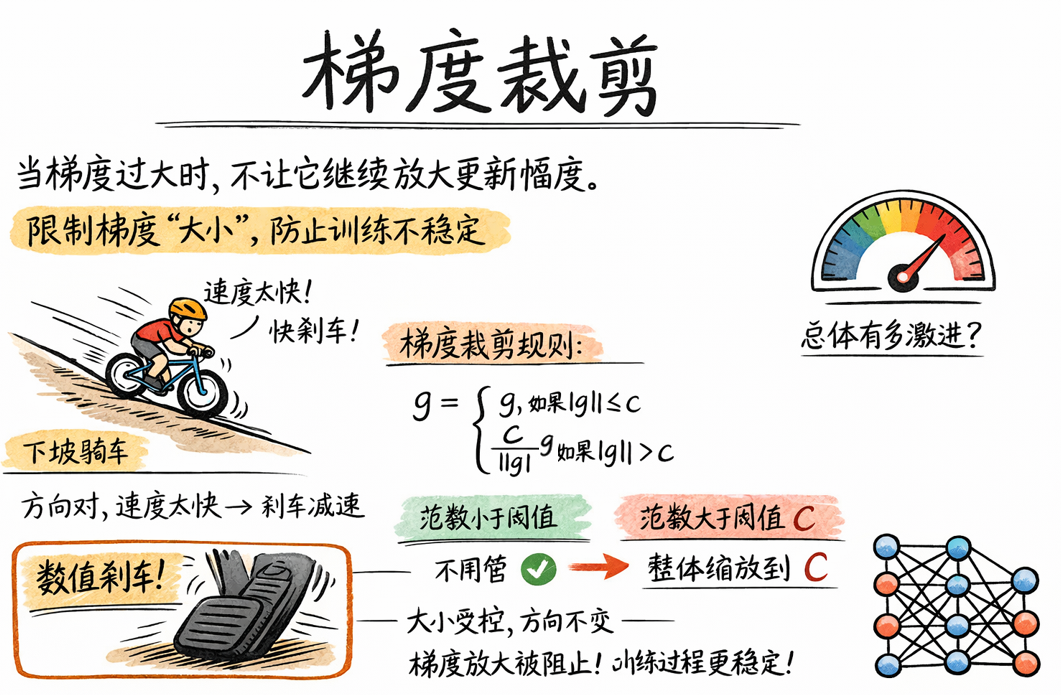
梯度裁剪的思想非常簡單,可以概括為一句話:
當梯度過大時,不讓它繼續放大更新幅度。
也就是説,我們並不試圖改變梯度的“方向”,而只是限制梯度的“大小”,從而避免一次參數更新步長過大,破壞訓練穩定性。
再打個比方:在下坡騎車時,我們的方向是對的,但速度太快容易摔,所以我們通過“剎車”來控制風險。
梯度裁剪,本質上就是反向傳播階段的“數值剎車”。
在實際使用中,最常見的是基於梯度範數(norm)的裁剪方式。
設所有參數的梯度拼接成一個向量 \(g\),其 \(L_2\) 範數為:
我們用 \(L_2\) 範數衡量梯度的整體大小,它反映的是這一次反向傳播中,參數更新“總體有多激進”。
下一步,給定一個閾值 \(c\),梯度裁剪的規則是:
也就是説:
- 如果梯度範數在可接受範圍內:不做任何處理。
- 如果梯度範數超過閾值:整體縮放,使其範數恰好等於 \(c\)。
這樣操作下來,你會發現:梯度裁剪並不會改變梯度各分量之間的相對比例,只是統一縮放其大小到合適程度。
這樣,在反向傳播中,梯度裁剪就會阻斷“指數級放大”的最壞情況, 保證參數更新始終處在一個穩定區間,從而讓訓練過程“至少可以繼續進行下去”。
要強調的是:在實際訓練中時,梯度裁剪幾乎是默認配置,而不是可選技巧。
但是,梯度裁剪也有其侷限性:梯度裁剪只能緩解梯度爆炸,無法解決梯度消失。
原因很簡單:
- 梯度爆炸是“數值過大”的問題 → 可以強行壓縮
- 梯度消失是“信號本身接近於 0” → 裁剪無能為力
因此,對於梯度消失這一更常見也更難緩解的梯度現象,我們需要別的解決方案,這也是我們下面要討論的主要內容。
2. RNN 中的梯度消失:長距離依賴問題
我們知道,RNN 擅長處理序列數據,並能夠逐步積累歷史信息。然而,在長序列訓練中,梯度消失會讓早期時間步的影響被逐漸“抹掉”,這就導致了著名的 長距離依賴問題:模型難以捕捉序列中相隔較遠的信息。
我們用之前的反向傳播例子來演示一下這個問題:
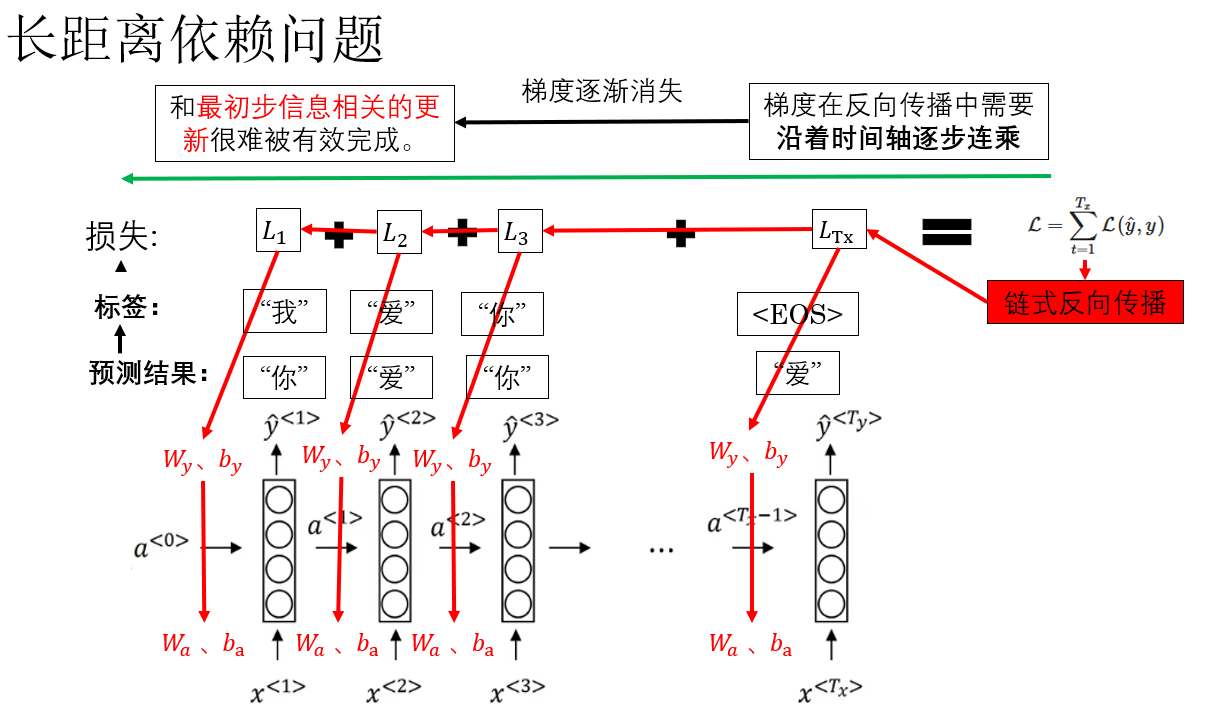
注意我們標紅的字體:當序列過長時,與結尾距離很遠的最初幾步信息很難實現有效更新。因此梯度已經在層層連乘中所剩無幾了。
這樣帶來的後果是什麼?來看看:
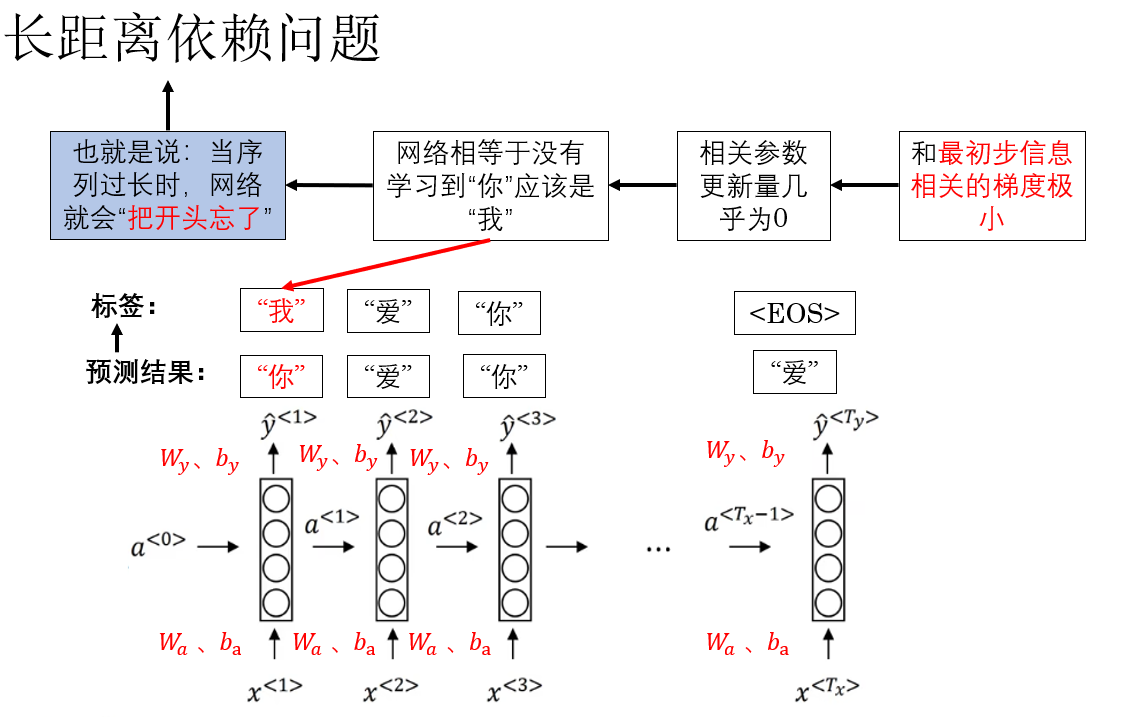
這就是 RNN 中的梯度消失現象,它直接導致 RNN 難以捕捉序列中相隔較遠的依賴關係,顯然,這對模型性能的影響是巨大的。
那麼如何緩解 RNN 中的梯度消失現象?
你可能想到了我們之前介紹過的殘差網絡,即通過在 RNN 中引入殘差連接,為梯度提供了一條直接傳遞的通路,可以在一定程度上緩解梯度消失問題,使深層或長序列的訓練更加穩定。這的確是一種可行的改進方案。但殘差路徑雖然提供了梯度直通通道,但無法進行信息選擇性控制,對於非常長序列仍然存在梯度衰減。
因此,在 RNN 中,我們有一種更好的技術:門控機制,這是在實際實驗和部署中我們更常使用的方法,它不僅能保持梯度穩定傳遞,還能智能控制信息流。
其原理較為複雜,我們經過本篇的引用,在下一篇來詳細展開它。
3. 總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 梯度現象(Gradient Phenomena) | 在深層網絡或 RNN 的反向傳播中,梯度可能過大或過小,導致訓練不穩定,即梯度爆炸或梯度消失 | 就像水流管道,如果水壓過大管道爆裂,水壓過小又無法輸送水 |
| RNN 的“深度” | RNN 在時間維度上展開為共享參數的深層網絡,梯度需要沿時間軸反向傳播,連續乘以權重矩陣 \(T\) 次 | 好比一個接力賽,每一棒都必須傳遞能量,接力棒越多,總能量損耗越大 |
| 梯度裁剪(Gradient Clipping) | 當梯度範數超過閾值 \(c\) 時,對梯度整體縮放,使其範數等於 \(c\);不改變梯度方向,只調整大小 | 就像給過快下坡的車裝剎車,保持安全速度 |
| RNN 的長距離依賴問題 | 梯度在層層連乘或長序列反向傳播中逐漸趨近 0,早期時間步的影響被“抹掉”,導致長距離依賴難以學習 | 像傳話遊戲,信息經過太多人,最開始的話慢慢被模糊甚至忘掉 |