









邊緣檢測方面傳統的算法中最為經典的就是Canny算法,但是標準的Canny是不具有亞像素精度的,而且得到的結果是一堆離散的邊緣點,提取亞像素的方式有很多種,這個在網絡上還有一些資料,而如何將離散點鏈接成一根一根的線條,我一直沒有什麼思路,最近偶然又有朋友給我推薦了一片文章:A Sub-Pixel Edge Detector an Implementation of the Canny /Devernay Algorithm及其配套的代碼,終於完了我這個夢,相關論文及代碼可以從http://www.ipol.im/pub/art/2017/216/下載和查看。
後面仔細看了看這個配套的代碼,應該説其實在四五年前我就下載過,只是當時感覺好複雜,就沒有信心一直看下去,沒想到原來那個就是答案,所以有的時候堅持還真的很重要。
這篇文章提出了自己的一個亞像素邊緣檢測思路,同時也提供了把這些邊緣點鏈接為線條的方法,其邊緣檢測的算法呢我認為一般般,應該説還是沒有Canny好吧。這裏稍微做點介紹。
一、Canny /Devernay邊緣檢測
1、計算圖像的梯度值(X方向梯度、Y方向梯度以及梯度幅值),這個可以用一階中心差分,或者二階中心差分。
這個過程偽代碼如下所示(這裏使用的是一階差分):

一般情況下在進行差分前需要進行下小尺度的高斯模糊,以便減少噪音的干擾。
注意,在計算X及Y方向梯度時,需要注意統一一下計算的方向,及要遵循從左到右以及從上到下這樣一致性。
2、根據梯度值的特性來初步確定邊緣的候選點,並計算其亞像素位置。
具體來説,當我們完成了第一步的梯度計算後,對於每一個點,當其梯度幅值比左右兩側的點都大時,我們認為其是水平邊緣點,當其梯度幅值比上下不部位都大時,我們認為其是垂直邊緣點,當然也可能出現一個點,其梯度幅值比上下左右都大,這個時候我們還是認為其是水平邊緣點。如果不滿足這兩個條件中的任何一個,則不是邊緣點。
通過上面的原則選擇了邊緣點後,因為這個位置肯定是水平或者垂直方向的最大值,所以呢我們通過領域三個點的二次方插值,可以得到一個局部的最大值,如下面這個曲線所示:
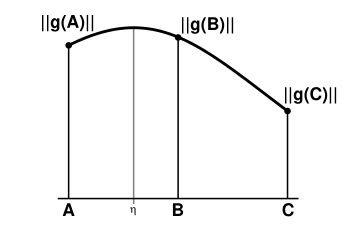
η的座標即是獲取的新的亞像素的邊緣點座標,而且從理論分析可知其和B點的偏差不會大於0.5位置。
η的座標可用下面的公式計算:
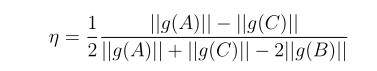
相關的偽代碼如下圖所示:

注意這裏有一個問題,即所獲取的亞像素精度只有一個方向的,也就是説如果X方向是亞像素的,那麼Y方向就是非亞像素,如果Y方向是亞像素的,那麼X方向就是非亞像素。這個是不完美的。
如果不考慮後續的鏈接成線條的過程,那麼下一步就可以直接使用類似於Canny中的雙閥值滯後邊界跟蹤算法了。 但是論文裏是先介紹了鏈接成線的過程。因此我們後面再同步説下這個事情。
二、離散點鏈接成線條
1、邊緣點鏈接
要把離散點鏈接為線條,首先要把所有點按照一定的規則鏈接起來,這個鏈接的規則比較重要。
在沒有任何附件條件下,一堆離散點要連接起來,一般來説就是要和最鄰近的點相連,這個可以用歐式距離來評判。但是這種原始方案對於邊緣檢測後的特徵來説過於簡單了,因為邊緣本身還有一定的特性,通常情況下我們不但要考慮兩個點的距離,還要考慮兩個點的梯度方向等因素,因此,我們制定了以下原則:
(1)、首先兩個點要必須都是有效的邊緣點。
(2)、第二兩個點的梯度方向必須一致,所謂的一致其實是指兩個點的梯度方向必須在位於連接兩個點的直線的同一側。
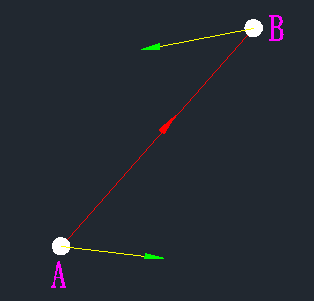
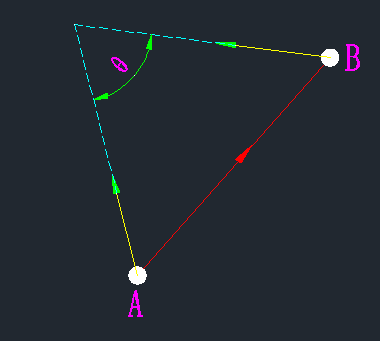
如上左圖所示,A和B是兩個邊緣點,由於A和B兩個的梯度方向分別位於直線AB的左側和右側,即他們不同邊,所以這兩個點不能相鏈接,得分為0,因為他們不同邊説明圖像在這兩個位置的變化趨勢不同,他們就屬於不同性質的點,所以不連接起來。
而右圖,A和B梯度指向同一邊,因此我們認為他們性質相同,可以鏈接。
這是在論文配套的代碼裏的説法,而論文裏則是説A和B處梯度的方向夾角要小於90度,這個似乎也不怎麼影響。
對於由兩點A(x1,y1)和B(x2,y2)定義的直線,要判斷點C(x,y)的位置,則步驟如下:
計算叉積: S = (x2 - x1)*(y - y1) - (y2 - y1)(x - x1)
然後根據符號判斷位置:
若S > 0,則點在直線的左側(相對於從A到B的方向)
若S < 0,則點在直線的右側.
若S = 0,則點在直線上。
所以如果要求兩個點必須在直線的同一側,那麼要麼都在左側,要麼都在右側,所以即要求兩個點的S要麼同時為正,要麼同時為負即兩者相乘為正則可。
另外,我們可以規定如果點在直線的左邊,表示像素點的梯度方向為前鏈式傳播(forward chaining),即邊緣延伸方向與圖像掃描方向一致;如果在右邊,則表示向後鏈式傳播(backward chaining),即邊緣延伸方向與掃描方向相反,這個規定不是強制性的,也可以反過來。
為什麼要有這個規定呢,因為一根線條,如果從一端到另外一端,相鄰的各點之間梯度方向都是要位於他們之間連線的同一側的,這樣線條才能很明確的作為兩個不同性質區域之間的分界線,而不是某兩個點符合這個要求。對於每一個點,我們不確定其在線條中是處於前鏈式中還是後鏈式中。對於每個點,我們都要計算其最佳的前鏈式點以及後鏈式點。注意,當B是A的前鏈式點時,對應的A就是B的反鏈式點。
每個點周邊可能存在多個符合條件的可鏈接點,而某一個點最多隻能有一個前鏈點和一個後鏈點,因此,必須設計出合適的得分評價體系。當兩個點確定可鏈接後,如果判斷屬於前鏈式點,則用距離的倒數表示前鏈式的得分值,即距離越大,得分越低,而屬於反向鏈式,我們則用距離的倒數取反來計量得分,此時,則得分數值越小,越屬於最佳反向鏈接點。為什麼要設計這樣的方式呢,很明顯是為了區分前鏈和後鏈。
在具體的實踐中,我們一般取計算點周邊一定領域的像素來尋找前鏈和後鏈,通常3*3就可以了,但是考慮到噪音的影響,把範圍擴大到5*5領域更為合理。當我們在搜索範圍內找到一個符合初步提條件的前鏈點B時,需要判斷A點是不是在之前的搜索過程中已經有了一個前鏈點或者B點也已經有了一個後鏈點,如果有其中之一的情況發生,我們都需要確認新搜索到的距離是否比之前的更短,如果更短,則原先的鏈接被切斷,而新的鏈接被加入。同樣,如果是B是後鏈點,也存在類似的情況。
這種處理方式也存在一定的瑕疵,即搜索順序對結果有一定的影響,即結果並不是唯一的,而目前似乎也沒有什麼特別理想的解決方案,現有的處理流程對大部分結果也是可以接受的。 具體可以看下論文的有關描述。
該部分的相關偽代碼如下所示:

貼一部分我整理後的代碼:

2、根據鏈接的信息提取每根完整的線條
當獲得了每個點的前後鏈接信息後,我們就可以從中提取出每個獨立的線條信息了。這裏的大概流程如下:
按先行後列的方式依次掃描圖像中的每一個點,當遇到一個邊緣點時做如下處理:
沿着這個邊緣的後鏈式方向尋找,找到最後一個後鏈式點,這個過程在原始的代碼中非常的巧妙,用了一句表面上看上去不含任何循環體的for語句:
for (I = Index; (J = Prev[I]) >= 0 && J != Index; I = J);
Index表示當前點的位置,從這個位置開始,如果Prev[I]大於等於0,則説明I這個位置有後鏈點,並且這個點不是當前點(因為可能有閉合曲線),則把I賦值為Prev[I]進入到下一個點,直到沒有後鏈點了。
當找到第一個後鏈點,則獲得了曲線的起點,然後在按照前鏈點的座標依次向曲線的重點尋轉,直到找到最後一個前鏈點。
每找到一根曲線,相應的數據中就增加一些信息,這樣就能獲取到邊緣中的所有曲線了。
三、雙閥值滯後邊界跟蹤
前面提到論文裏的邊緣後續還要進行雙閥值滯後邊界跟蹤算法,特別是滯後邊界跟蹤,在傳統的Canny裏是通過8領域區域生長之類的算法完成的,而如果前期已經進行了邊緣點鏈接,則這個過程就變得非常自然了。
這個過程如下所述:
我們定義一個圖像大小的標記變量,先都設置為0,然後按先行後列的方式依次掃描圖像中的每一個點,當遇到一個邊緣點時做如下處理:
如果這個邊緣點的梯度大於高閾值且對應的標記為0,則把標記修改為1,同時,從這個點的位置開始,首先沿着前鏈點方向依次搜索,如果搜素到的前鏈點處的梯度幅值小於底閾值,則停止循環,同時把此時的搜索位置的前鏈點和後鏈點復位。如果梯度幅值大於低閾值,則標記把對應位置的標記設置為1,這樣下次遇到這個點就不用處理了。然後在按照後鏈點的方向依次搜索,和前鏈點做同樣的處理。
這樣做在一個流程裏把雙閥值及滯後邊界跟蹤算法同時完成,這是因為通過前面的鏈接點編碼,已經保證了相互鏈接之間的點的領域相連性,而無需使用區域生長之類的算法了,相當於是水到渠成的事情了。
注意,在處理完成最後,還要有個額外的全圖搜索處理過程,即把那些是邊緣點且標記依舊為0的點的鏈接信息復位,這是因為前面的處理對於那些梯度幅值小於低閾值的部分可能沒有完全處理到的。
這部分的偽代碼如下圖所示:

四、相關討論
論文的配套的代碼其實是比較慢的,因為把點鏈接起來是個較為耗時的過程,這裏提出一個方案:
我們可以提前進行閾值的處理,特別是在進行鏈接點之前我們就進行低閾值的判斷,這樣就可以篩選掉不少點,有利於後續速度提高。
但是實測呢,這樣得到的結果和原始流程的結果不太一致,我想這個應該是和前面講的鏈接的不唯一性有一定的關係。但是影響不是很大。
為了對曲線的結果可視化,我們用不同顏色顯示不同的線條,這裏貼出兩個結果圖供參考:
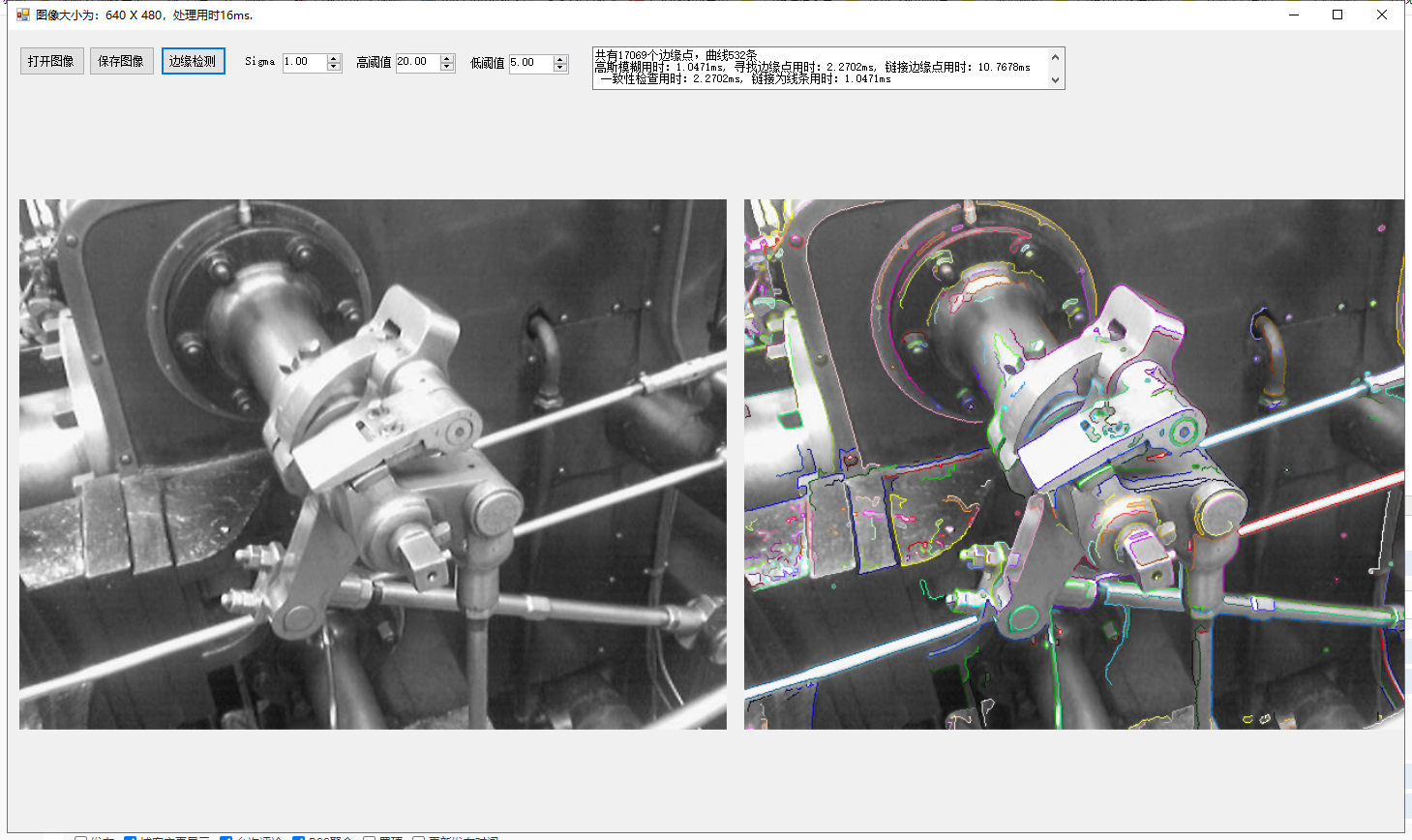
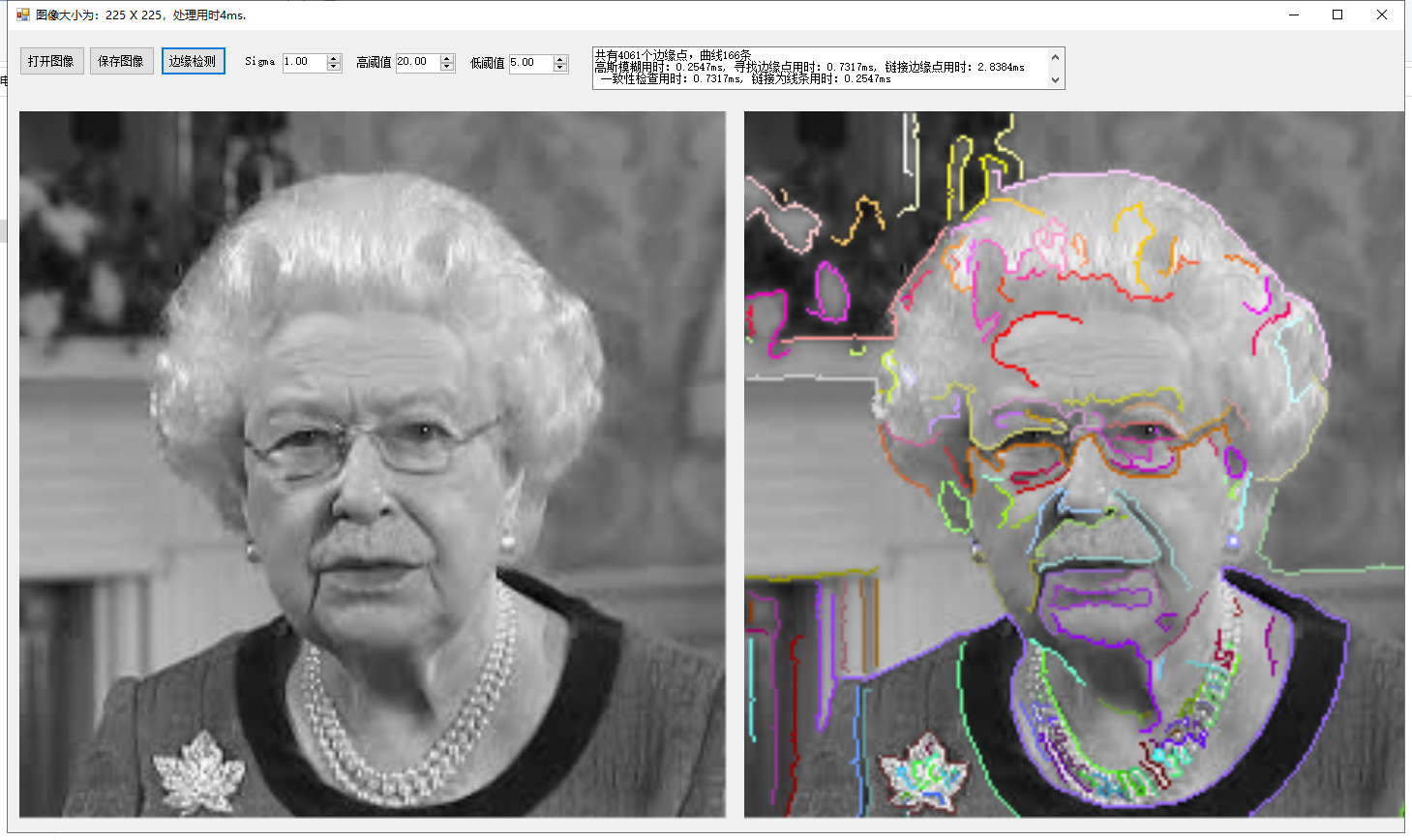
我們把第二個圖的局部結果放大查看:
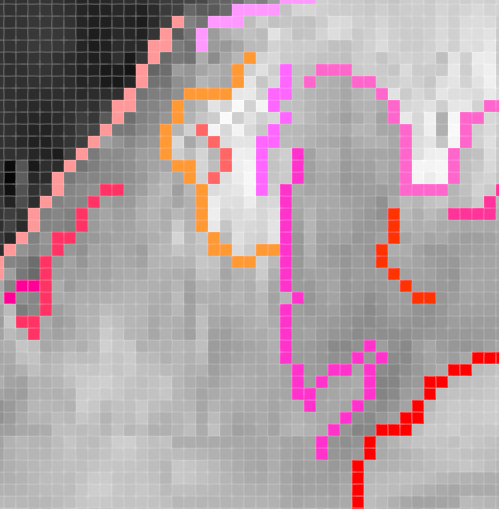
這裏有幾個相交的線條,算法完美的把他們分開為不同的線條。
這裏想到了一些簡單的應用,比如把一些小的毛刺給去除掉,即線段長度小於某個數值則刪除這個邊緣等等。
五、基於Canny的亞像素邊緣檢測和線條提取
當我們通過標準的Canny邊緣檢測獲取了整數的邊緣座標後,也是可以進一步擴展為亞像素座標的,在steger的an Unbiased Detector of Curvilinear Structures一文中,通過Facet Model method模型引入了相關漢森矩陣的特徵值等信息,結合3*3領域相關的梯度幅值數據,有效的獲取了X和Y方向的亞像素座標數據,注意這裏不是單獨X或Y方向亞像素了。這樣在結合前面的線條提取等技術,就可以完成Canny算法的後續擴展,而且Canny本身速度是非常快的,且已經進行了雙閥值滯後邊界跟蹤,因此,提取出的邊界點相對來説是比較少的了,後續的曲線鏈接和提取的計算量下降的比較厲害,因此,擴展的耗時也是可控的。
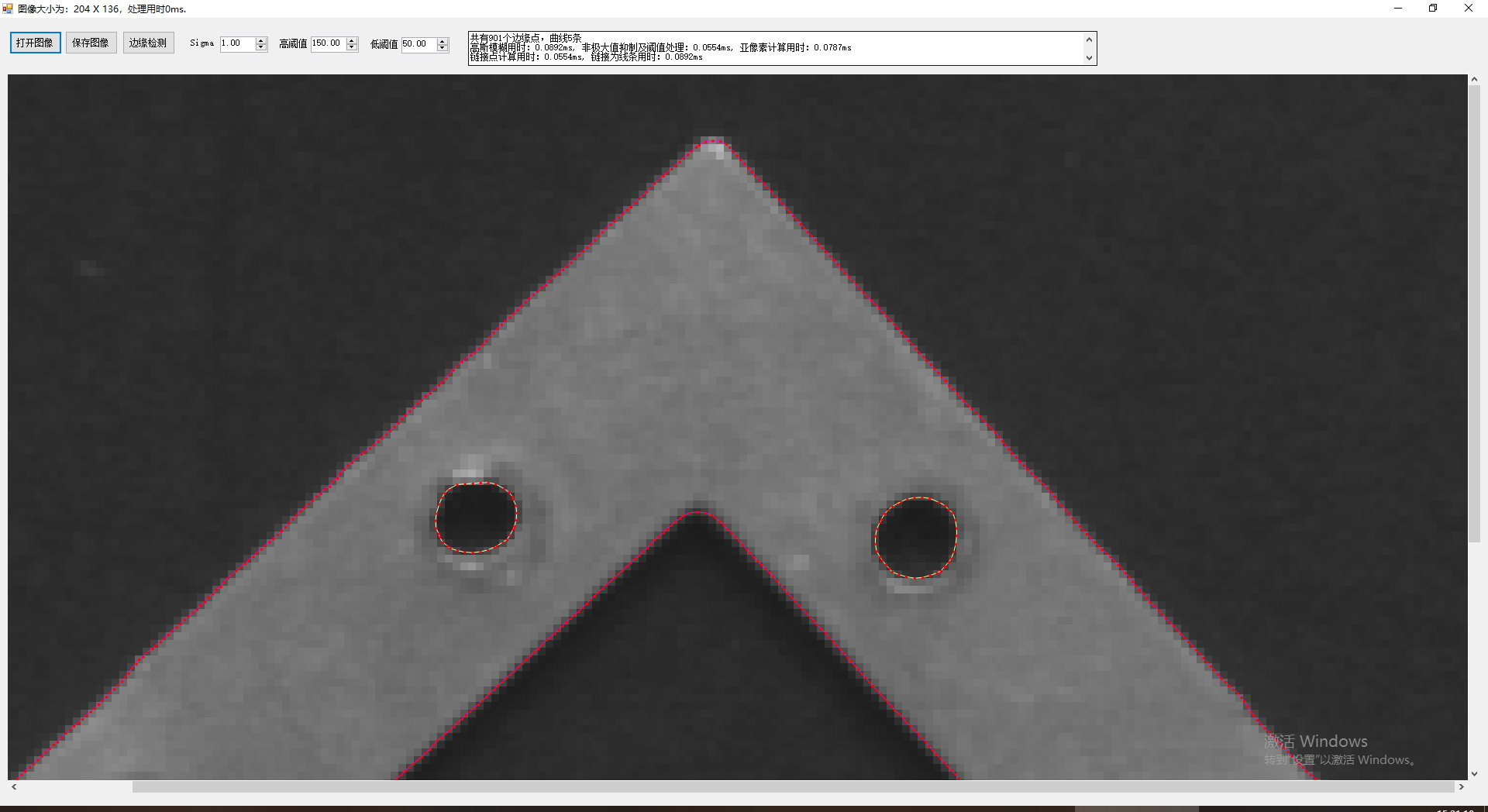
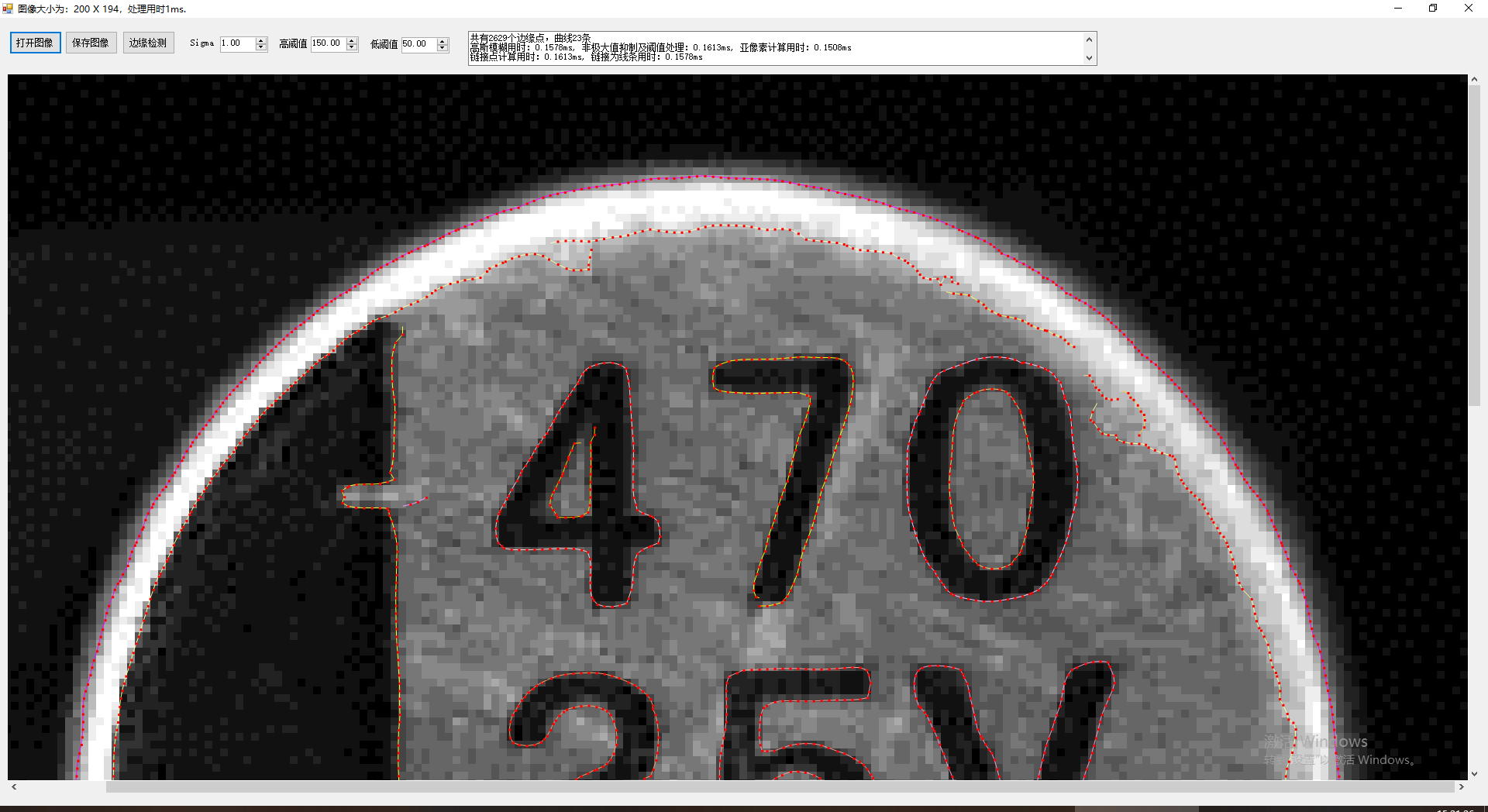
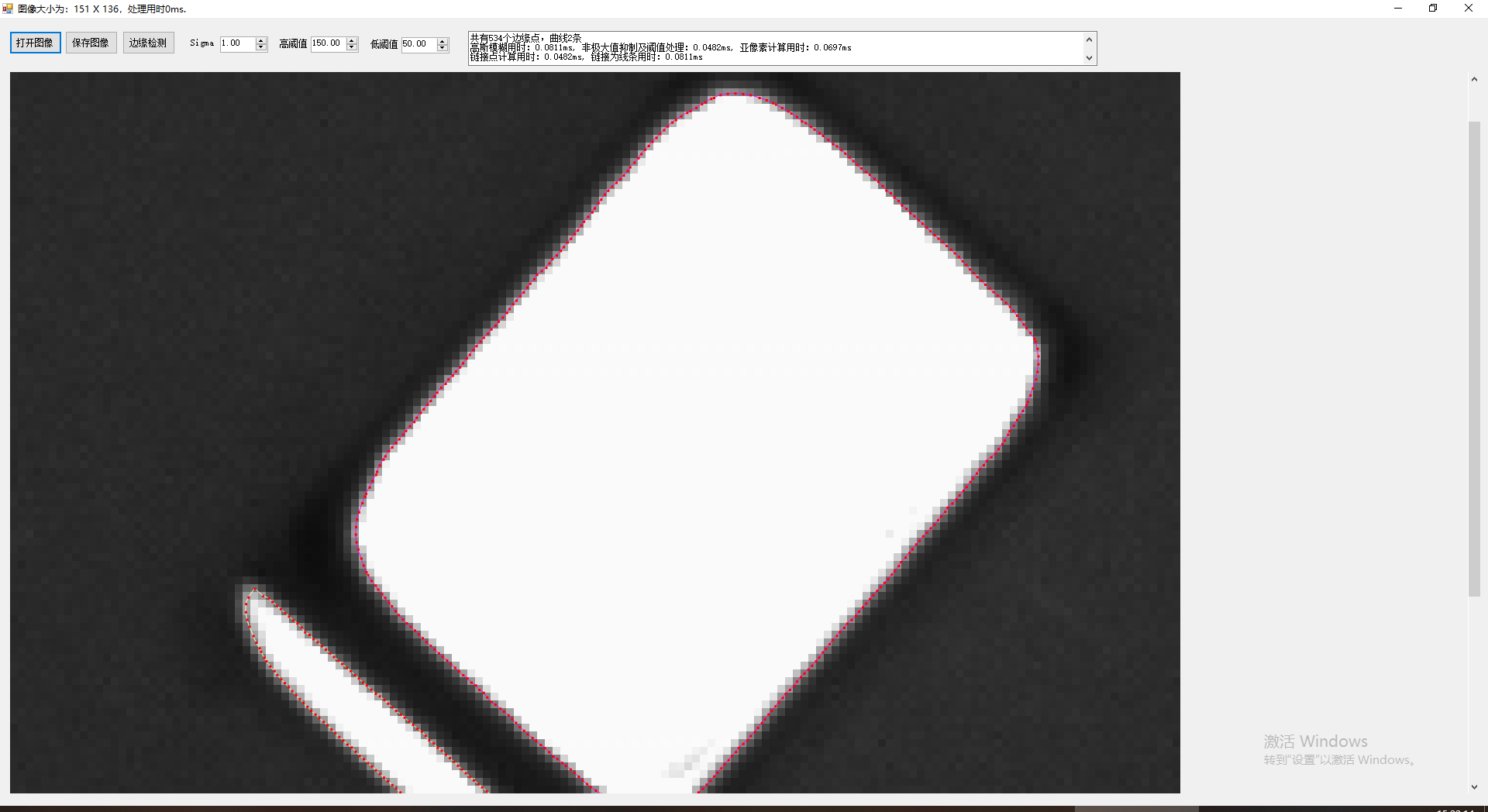
從以上幾圖,可以明顯的看到無論在精度還是展示效果上,擴展的Canny都有着不錯的結果,而目前幾乎所有的成熟的商業軟件中,顯示邊界時都是提取程曲線顯示,而不是簡單的顯示為點,這不僅僅看上去更為高端,實際也能獲取更多的手段對檢測的結果進行進一步的提取和挖掘。
實際上,在編寫這方面的程序時還有很多的細節,比如很多亞像素提取的代碼都把邊界偏移限制在0.5,即如果識別到的亞像素大於0.5,則不做亞像素處理,實際上,這個值可能要放大到0.6甚至0.8,這樣才能保證處理後的邊界連接起來才足夠平滑。這一點在steger的有關論文裏也有提及。
我這裏提供兩個DEMO供大家測試,一個是直接顯示Canny亞像素及曲線提取的結果,一個是放大顯示結果,注意:由於我沒有做動態的放大圖像流程,因此這個DEMO的輸入圖像不要大於500*500。
https://files.cnblogs.com/files/Imageshop/Canny.rar?t=1760599971&download=true
https://files.cnblogs.com/files/Imageshop/CannyZoom10.rar?t=1760599962&download=true



