









前言
彩筆運維勇闖機器學習:KNN算法,它也是分類中的一種
開始探索
scikit-learn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
np.random.seed(0)
x0 = np.random.randn(60, 2) * 0.6 + np.array([1, 2])
x1 = np.random.randn(30, 2) * 0.6 + np.array([3, 4])
x2 = np.random.randn(10, 2) * 0.6 + np.array([1, 5])
X = np.vstack((x0, x1, x2))
y = np.array([0]*60 + [1]*30 + [2]*10)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
k = 5
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_std, y_train)
y_pred = knn.predict(X_test_std)
def plot_knn_decision(X, y, model):
h = 0.02
x_min, x_max = X[:, 0].min()-1, X[:, 0].max()+1
y_min, y_max = X[:, 1].min()-1, X[:, 1].max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8,6))
plt.contourf(xx, yy, Z, cmap=plt.cm.Pastel2)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Set1)
plt.grid(True)
plt.show()
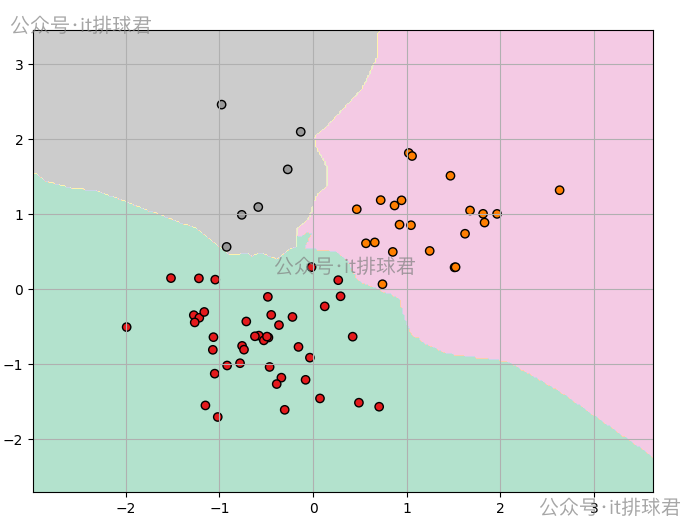
plot_knn_decision(X_train_std, y_train, knn)
這是一個三分類的數據,分類0有60個,分類1有30個,分類2有10個
腳本!啓動:
深入理解KNN
KNN算法屬於惰性學習,沒有所謂的數據訓練的過程。它把訓練數據暫時保存,當有新的數據需要進行分類時,再使用訓練數據進行對應的計算,而這個計算算法常見的是歐氏距離
\[d(A, B) = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2} \]
下面用一個例子來加深一下算法的過程
舉例説明
假設有以下訓練數據
| x1 | x2 | 類別 | |
|---|---|---|---|
| A | 1 | 2 | 0 |
| B | 2 | 3 | 0 |
| C | 3 | 3 | 1 |
| D | 6 | 5 | 1 |
| E | 7 | 2 | 1 |
1)由於是惰性學習,訓練數據就先放着備用
2)假設有一個測試數據,T(3,4),需要對他進行分類
對每一個點分別計算:
- A點,(1,2),\(D_A=\sqrt{(3-1)^2+(4-2)^2} \approx 2.83\)
- B點,(2,3),\(D_A=\sqrt{(3-2)^2+(4-3)^2} \approx 1.41\)
- C點,(3,3),\(D_A=\sqrt{(3-3)^2+(4-3)^2} = 1\)
- D點,(6,5),\(D_A=\sqrt{(3-6)^2+(4-5)^2} \approx 3.16\)
- E點,(7,8),\(D_A=\sqrt{(3-7)^2+(4-8)^2} \approx 5.66\)
3)設置超參數K=3,選擇3個距離最小作為鄰居
| 鄰居 | 距離 | 類別 |
|---|---|---|
| C | 1 | 1 |
| B | 1.41 | 0 |
| A | 2.83 | 0 |
4)投票,少數服從多數,T(3,4)的類別是0
小結
KNN算法的優點是簡單直接,非常容易理解。缺點也很明顯,由於是惰性計算,面對高維的、數據量非常大的數據,往往需要大量的計算才能進行分類,並且對於每一個測試數據都需要“遍歷所有訓練數據”來計算距離,這在大規模 數據集上會變得非常慢。
異常檢測
在之前討論分類問題的時候,遇到了所謂的“類別不平衡”問題,就是多數類佔據樣本的大量,而少數類只佔用非常少的樣本,導致分類算法對於少數類不能正確分類,需要做額外的處理
在實際工作中,“類別不平衡”問題有着非常重要的實踐,比如有100w的日誌,怎麼精準識別出10條異常日誌,除了10條日常,其餘999990條日誌都屬於正常日誌。對於這種問題又叫做“異常檢測”,對於“異常檢測”問題,有一些算法是比較擅長處理的,比如KNN算法
舉例説明
在下列數據中,找出異常點
| x1 | x2 | |
|---|---|---|
| A | 1 | 2 |
| B | 2 | 3 |
| C | 3 | 3 |
| D | 6 | 5 |
| E | 7 | 2 |
1)算法沒變,還是使用歐式距離公式
| A(1,2) | B(2,3) | C(3,3) | D(6,5) | E(7,8) | |
|---|---|---|---|---|---|
| A(1,2) | - | 1.41 | 2.83 | 5.83 | 8.49 |
| B(2,3) | 1.41 | - | 1 | 4.24 | 6.71 |
| C(3,3) | 2.83 | 1 | - | 3.61 | 5.83 |
| D(6,5) | 5.83 | 4.24 | 3.61 | - | 3.16 |
| E(7,8) | 8.49 | 6.71 | 5.83 | 3.16 | - |
2)設置超參數K=2,找到最近的2個鄰居計算平均距離
- A最近的鄰居:(1.41 2.83),\(D_A=2.12\)
- B最近的鄰居:(1 1.41),\(D_B=1.21\)
- C最近的鄰居:(1 2.83),\(D_C=1.91\)
- D最近的鄰居:(3.16 3.61),\(D_D=3.39\)
- E最近的鄰居:(3.16 5.83),\(D_E=4.5\)
3)找出異常點
- 如果要找出最異常的,那就是E點
- 如果要找出2個的異常點,那就是D與E
scikit-learn
import numpy as np
from sklearn.neighbors import NearestNeighbors
np.random.seed(42)
X_normal = np.random.randn(100, 2)
X_outliers = np.array([[5, 5], [-5, -5], [6, -6]])
X = np.vstack((X_normal, X_outliers))
k = 3
nbrs = NearestNeighbors(n_neighbors=k)
nbrs.fit(X)
distances, _ = nbrs.kneighbors(X)
k_dist = distances[:, -1]
n_outliers = 3
threshold = np.partition(k_dist, -n_outliers)[-n_outliers]
outlier_mask = k_dist >= threshold
outliers = X[outlier_mask]
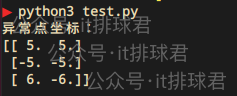
print("異常點座標:")
print(outliers)
腳本!啓動:
畫圖分析
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
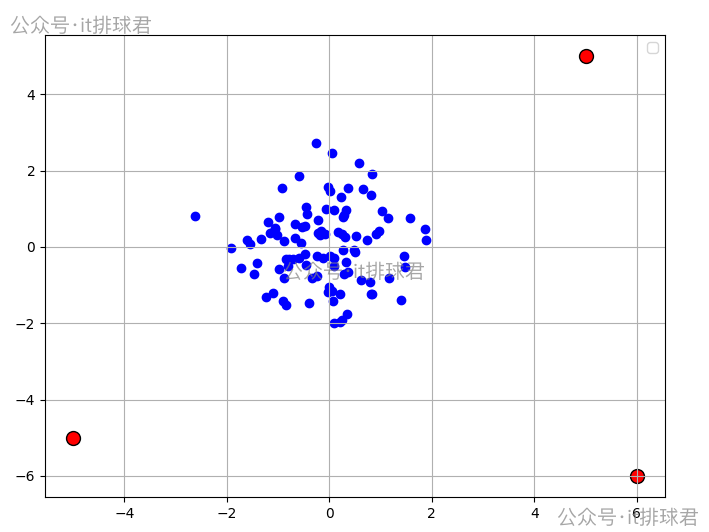
plt.scatter(X[:, 0], X[:, 1], c='blue')
plt.scatter(outliers[:, 0], outliers[:, 1], c='red', edgecolors='black', s=100)
plt.legend()
plt.grid(True)
plt.show()
KNN增強版本LOF
局部離羣因子(LOF)算法,專門用於異常檢測
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import LocalOutlierFactor
X = np.array([
[1, 2],
[2, 3],
[3, 3],
[6, 5],
[7, 9],
[20, 20],
])
k = 2
lof = LocalOutlierFactor(n_neighbors=k, contamination=0.3)
y_pred = lof.fit_predict(X)
anomaly_scores = lof.negative_outlier_factor_
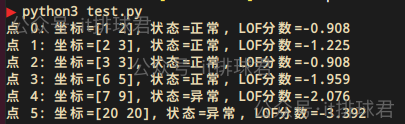
for i, (point, label, score) in enumerate(zip(X, y_pred, anomaly_scores)):
status = "異常" if label == -1 else "正常"
print(f"點 {i}: 座標={point}, 狀態={status}, LOF分數={score:.3f}")
n_neighbors=2,就是超參數k,用來選擇鄰居數contamination=0.3,表示有30%的數據為異常
腳本!啓動:
兩種算法的對比
| KNN | LOF | |
|---|---|---|
| 功能 | 查找最近鄰居 | 檢測局部異常 |
| 輸出 | 每個點最近的 k 個鄰居及其距離 | 每個點的異常標籤(1 或 -1)和 LOF 分數 |
| 適用任務 | 查找最近的用户/商品/樣本 | 檢測數據中的異常點 |
| 是否計算異常 | 否 | 是(negative_outlier_factor_) |
| 參數 | n_neighbors 只是最近鄰個數 | n_neighbors, contamination 控制鄰居數和異常比例 |
小結
- 聯繫我,做深入的交流
![]()

至此,本文結束
在下才疏學淺,有撒湯漏水的,請各位不吝賜教...
