









前言
彩筆運維勇闖機器學習,今天我們來討論一下lasso迴歸,本期又是一起數學推理過程展示
座標下降法
目標找到一組參數,使目標函數值最小。比如\(f(x,y)=3x^2+5xy+10y^2\),要找到\(x,y\)使得\(f(x,y)\)取值最小
每次固定\(x_j\)之外的所有變量,對\(x_j\)進行最小化,然後不斷的迭代\(x_j\)
推導過程
我們就以上述提到的函數來推導一下,加深對這個過程的理解$$f(x,y)=3x2+5xy+10y2$$
1)首先先尋找一個點,\((1,1)\),計算此時的函數值
2)分別對x,y求偏導
對x求偏導,並且令其導數為0:
同理對y求偏導
3)開始迭代,第一輪
調整x,固定y
調整y,固定x
此時函數值為:
第一輪結束:
- 函數最小值\(f(x,y)=2.3438\)
- \(|Δx|=|-\frac{5}{6}-1| \approx 1.8333\)
- \(|Δy|=|\frac{5}{24}-1| \approx 0.7917\)
4)第二輪
重複第一輪的操作
調整x,固定y
此時函數值為:
調整y,固定x
此時函數值為:
第二輪結束:
- 函數最小值\(f(x,y)=0.1221\)
- \(|Δx|=|-\frac{25}{6}-(-\frac{5}{6})| \approx 0.6597\)
- \(|Δy|=|\frac{25}{576}-\frac{5}{24}| \approx 0.1649\)
5)不斷的迭代,直至收斂
隨着迭代次數的不斷增加,\(|Δx|\)、\(Δy\)、\(f(x,y)\)都在不斷減小
當\(|Δx|\)、\(Δy\)均小於\(10^{-4}\),可以認為函數收斂
凸函數
通過上述的過程模擬,可以找到函數最小值時x,y分別是多少
對於函數\(f(x,y)=3x^2+5xy+10y^2\),可以直接計算偏導數為0,從而求出最小值
解方程組:
該函數最小值是\(f(x,y)=0\),且\(x=0,y=0\)
直接用偏導數可以計算出函數最小值,有前提條件,那就是該函數是凸函數。凸函數的定義:在函數上任意兩點連接的線段總是在函數圖上方或者重合
局部最優解與全局最優解
如果函數不是凸函數,而是類似於這種,在某一個定義域內是凸函數
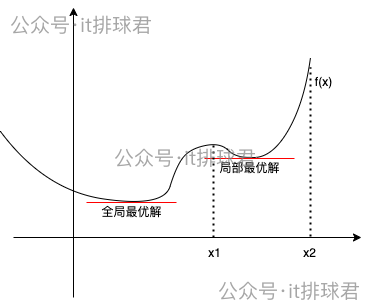
使用座標下降法的時候,選擇的初始值如果在\((x1,x2)\)之間,那找到的最小值就是局部最小,而非全局最小。之前介紹的梯度下降法也有同樣的問題
那要怎麼解決這個問題呢?不好意思,我也不會,還沒學習到,所以暫時略過,後面再説 -_- !
lasso迴歸
介紹完座標下降法之後,最後來到了本文的主題,lasso迴歸,為什麼lasso迴歸能夠降低無用參數的影響?lasso迴歸就是添加了一個參數的絕對值之和作為懲罰項,用線性迴歸為例,線性迴歸的損失函數常用MSE
lasso的數學表達:
我們通過一個例子,來説明lasso迴歸的工作流程。有一個數學模型:2個特徵分別為\(x_1\)、\(x_2\),分別使用不帶lasso懲罰項與帶lasso懲罰項來進行推導
| 樣本 | \(β_1\) | \(β_2\) | y |
|---|---|---|---|
| 1 | 1 | 1 | 2 |
| 2 | 2 | 1 | 2 |
| 3 | 3 | 2 | 4.5 |
最小二乘法
不帶lasso懲罰項,就直接用最小二乘法求解,在之前的小結中曾經推倒過多元迴歸中最小二乘法的計算公式:
首先特徵矩陣\(X\):
$ X=
\begin{pmatrix}
1 & 1 \
2 & 1 \
3 & 2
\end{pmatrix}
$, \(X\)的轉置
$ X^T=
\begin{pmatrix}
1 & 2 & 3 \
1 & 1 & 2 \
\end{pmatrix}
$
矩陣乘法,\(X^T·X= \begin{pmatrix} 1 & 2 & 3 \\ 1 & 1 & 2 \end{pmatrix} \begin{pmatrix} 1 & 1 \\ 2 & 1 \\ 3 & 2 \end{pmatrix} = \begin{pmatrix} 14 & 9 \\ 9 & 6 \end{pmatrix} \)
矩陣求逆常用初等變換法以及伴隨矩陣法,對於上述演示數據,笨辦法我直接用伴隨矩陣求出來,但是都ai時代了,我決定使用chatgpt法(機智如我-_-) :\((X^TX)^{-1} = \begin{pmatrix} 2 & -3 \\ -3 & \frac{14}{3} \end{pmatrix} \)
根據矩陣結合律,我先算一下後面:\(X^T·y_i = \begin{pmatrix} 1 & 2 & 3 \\ 1 & 1 & 2 \end{pmatrix} \begin{pmatrix} 2 \\ 3 \\ 4.5 \end{pmatrix} = \begin{pmatrix} 21.5 \\ 14 \end{pmatrix} \)
最終計算出係數 \(\beta =(X^TX)^{-1}X^Ty_i = \begin{pmatrix} 2 & -3 \\ -3 & \frac{14}{3} \end{pmatrix} \begin{pmatrix} 21.5 \\ 14 \end{pmatrix} = \begin{pmatrix} 1 \\ \frac{2.5}{3} \end{pmatrix} \approx \begin{pmatrix} 1 \\ 0.8333 \end{pmatrix} \)
最終,通過最小二乘法,擬合函數為
帶lasso懲罰項
為了計算方便,先將公式簡化,把n去掉,因為同時縮放n倍,對於結果比對沒有影響
lasso有一個超參數\(\lambda\),我們先設置一下\(\lambda = 2\),用座標下降法:
1)首先尋找一個點\(\beta=(0,0)\),計算出函數值
2)先分別求偏導
這裏的懲罰項並沒有進行導數計算,原因一會再説,先記為\(f_{absolute}'=(\lambda\sum_{j=1}^{p}|\beta|)'\)
所以最終對\(\beta_1\)求偏導:
同理對\(\beta_2\)求偏導:
由於絕對值在0處不可導,所以絕對值的導數需要分段來研究
3)第一次迭代,\(\beta=(0,0)\),更新\(\beta_1\),固定\(\beta_2=0\)
令偏導數為0
由於\(\beta_1<=0\)與計算結果矛盾,所以\(\beta_1=1.464\)
4)第一次迭代,固定\(\beta_1=1.464\),更新\(\beta_2\)
令偏導數為0
這個。。。。怎麼全是矛盾的??計算出來的\(\beta_2\)都不對,那\(\beta_2\)到底取值是什麼,這裏要用次梯度來解決這個問題,一會再詳細討論,這裏只需要知道,\(\beta_2\)取值在[-0.0293, 0.304]之間,而最優解就是0
5)計算函數值
6)第一輪小結
- 函數最小值\(\mathcal{L}(x,y)=3.518\),從33.25下降而來
- \(|Δ\beta_1|=|0-1.464| \approx 1.464\)
- \(|Δ\beta_2|=|0-0| = 0\)
第一次迭代就已經把\(\beta_2\)給家人們打下來了,\(\beta_2\)對於尋找函數最小值,已經沒有意義了,換句話來説,該特徵對於提升模型性能意義不大
但是依然需要繼續尋找最合適的\(\beta_1\),直至收斂,所以還需要繼續迭代下去,下面就不演示了
繼續迭代。。。。最終經過lasso迴歸的擬合函數應該是這樣的:
可以看到,lasso迴歸有可能把一些特徵的係數壓縮成0了,從而去掉該特徵對於目標函數的影響,從而降低該特徵的影響,提高了模型了泛化能力
次梯度
在剛才的推導中,遇到了這個問題,\( \begin{aligned} \beta_2 = \left\{ \begin{array}{ll} \frac{-0.352}{12} \approx -0.0293 \qquad ,\beta_2>0 \\ \frac{1.648}{12} \approx 0.1373 \qquad ,\beta_2=0 \\ \frac{3.648}{12} = 0.304 \qquad ,\beta_2<0 \end{array} \right. \end{aligned} \),\(\beta_2\)與所有的結果都是矛盾的,之所以會出現這種情況,是由於對絕對值求導數導致的。我們都知道,絕對值在0的時候是不可導的
當\(\beta=0\)的時候,需要使用次梯度的概念,什麼是次梯度,我這裏也不班門弄斧的搬概念了,大家有興趣自己去google一下
這裏只需要記住次梯度是一個集合,它的範圍就是,若\( \begin{aligned} \beta_2 = \left\{ \begin{array}{ll} \ a \qquad ,\beta_2>0 \\ \ b \qquad ,\beta_2<0 \end{array} \right. \end{aligned} \),那\(\beta=0\)的次梯度是\([a,b]\)之間
更直接一點,如果我們在次梯度集合中,找到為0的選項,那就意味着找到了函數的最小值點
這也説明了,lasso迴歸不能直接用導數為0的方法來找最優解,需要用到座標下降法的原因
小結
筆者寫這篇文章的時候真是頭皮發麻,“凸函數”、“最優解”等名詞讓我回想起學生時代被高數、微積分支配的恐懼,如今再次面對,竟然能夠坦然處之,甚至覺得莫名親切,進而會心一笑。被動接受與主動求索,還真是不一樣
聯繫我
- 聯繫我,做深入的交流
![]()

至此,本文結束
在下才疏學淺,有撒湯漏水的,請各位不吝賜教...
