









一、本月導覽與核心看點
2025 年 9 月,SCALE 評測基準持續聚焦 AI 在 SQL 領域的應用前沿。本月,榜單新增了 Moonshot AI(月之暗面) 發佈的最新模型 —— Kimi-K2-Instruct-0905,還在平台功能上進行了升級,旨在為開發者、研究者和企業決策者提供更精細、更具洞察力的技術參考。
本期核心看點:
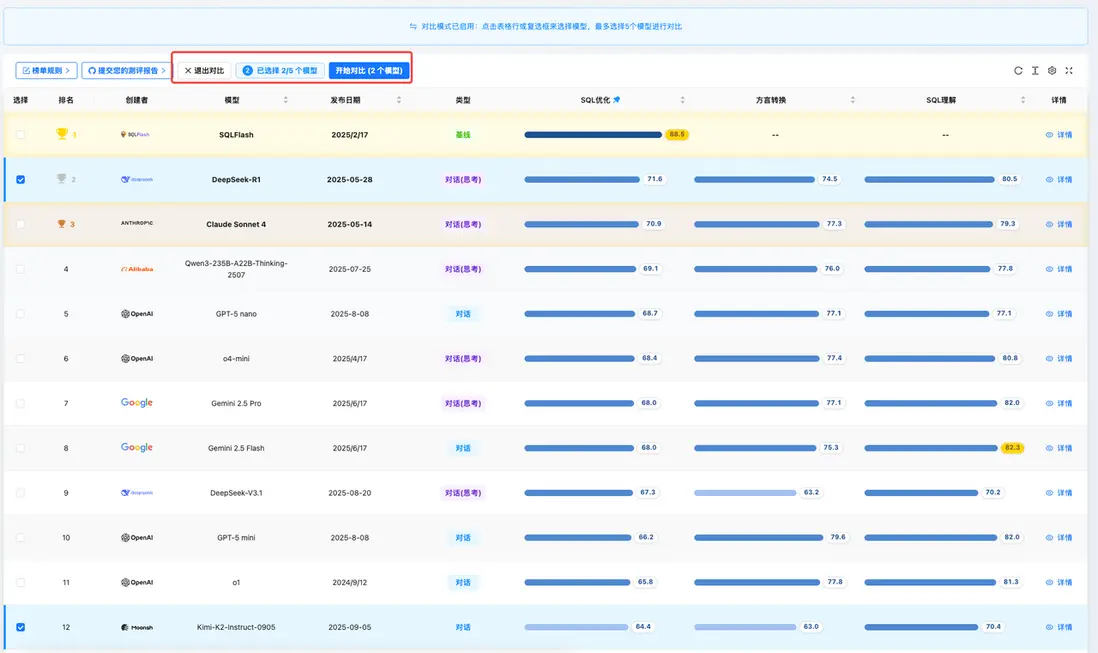
- 新增模型評測:新增的 Kimi K2 模型在「SQL 理解」維度獲得 70.4 分,「SQL 優化」維度獲得 64.4 分,「方言轉換」維度獲得 63.0分。評測結果顯示,該模型在國產數據庫適配和基礎語法處理方面表現突出,但在處理超長複雜查詢和深度優化方面與領先模型存在差距。
- 平台功能升級:新增 模型細分指標排名 與 模型對比 功能。用户現可查看各模型在 「邏輯等價」、「執行準確性」 等細分能力上的排名,並支持對多個模型進行多維度的可視化對比分析,進一步提升了評測數據的透明度與實用性。
二、評測基準説明
為保證評測結果的長期可比性和權威性,本月我們的核心評測基準與算法保持不變。我們繼續沿用 SCALE 自創立之初便確立的三維評測體系,確保所有模型與工具在統一、標準的測試環境下進行評估,以提供公正、可復現的評測結果。
- SQL 理解:考察模型是否能精準解析複雜的查詢邏輯與用户意圖。
- SQL 優化:考察模型提升查詢效率與性能的意識和能力。
- 方言轉換:考察模型在主流數據庫之間進行語法遷移的準確性。
我們認為,穩定的評測體系是追蹤模型能力演進、洞察技術發展趨勢的基石。
三、焦點分析
專題:國產新鋭 Kimi K2 首次評測
作為本月新增的焦點模型,Kimi K2 在其首次評測中,各維度得分分別為:
- SQL 理解:70.4
- SQL 優化:64.4
- 方言轉換:63.0
這些分數背後揭示了其作為一個通用大模型在 SQL 領域的具體能力分佈。
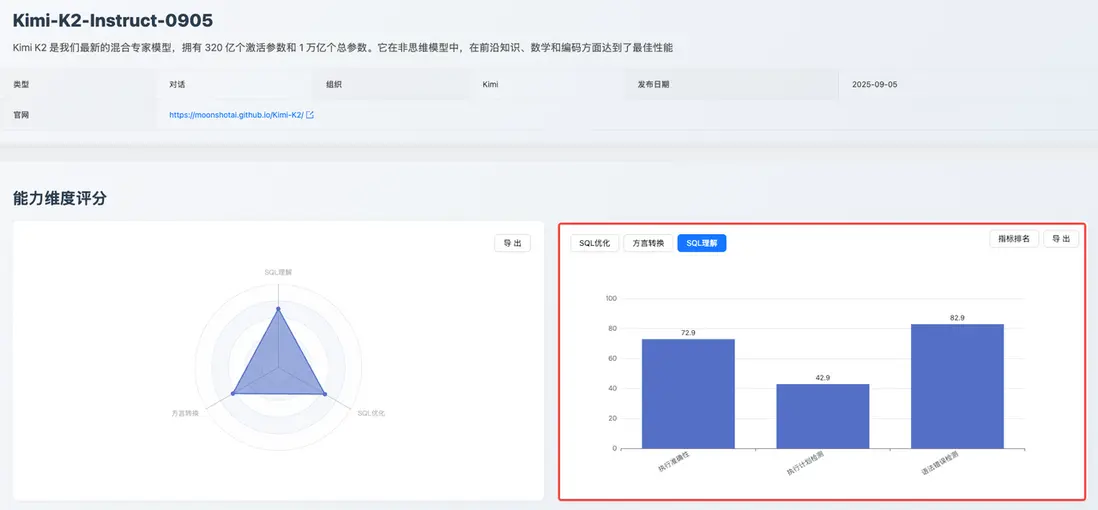
SQL 理解能力:70.4
這是一個穩健的分數,表明 Kimi K2 具備可靠的 Text-to-SQL 基礎能力。
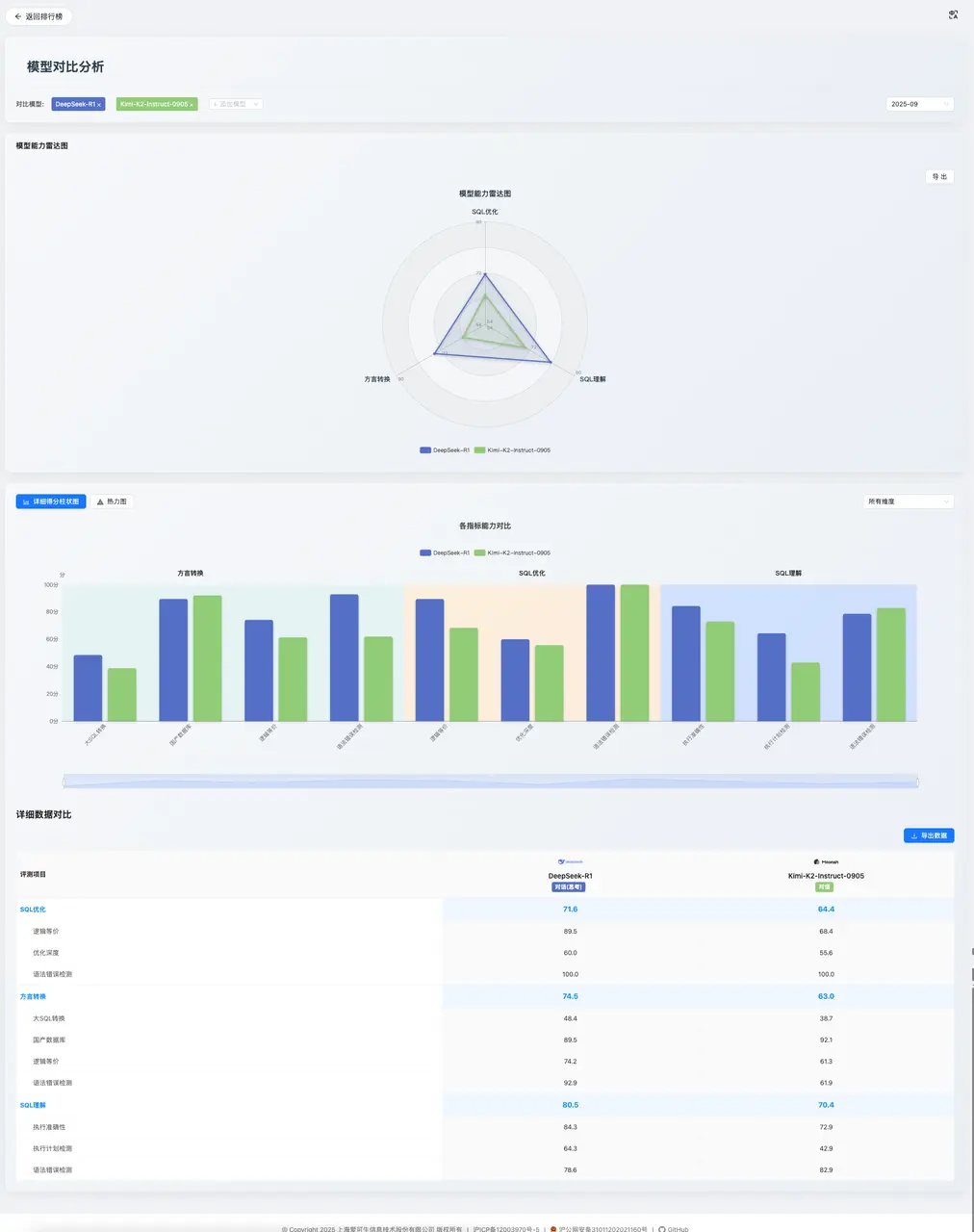
該分數主要得益於其在「執行準確性」(72.9)和「語法錯誤檢測」(82.9)上的良好表現。然而,其在「執行計劃檢測」子項上得分僅為 42.9,這反映出模型能夠準確生成符合用户意圖的 SQL 代碼,但是在評測中發現,Kimi K2 將 SQL 語句類型誤認為執行計劃訪問類型,在訪問類型上填寫為 INSERT、UPDATE 等 SQL 語句類型,表現出過度依賴表面語法特徵而非深層語義理解的問題,Kimi K2 在 SQL 執行計劃理解能力上還有待加強。
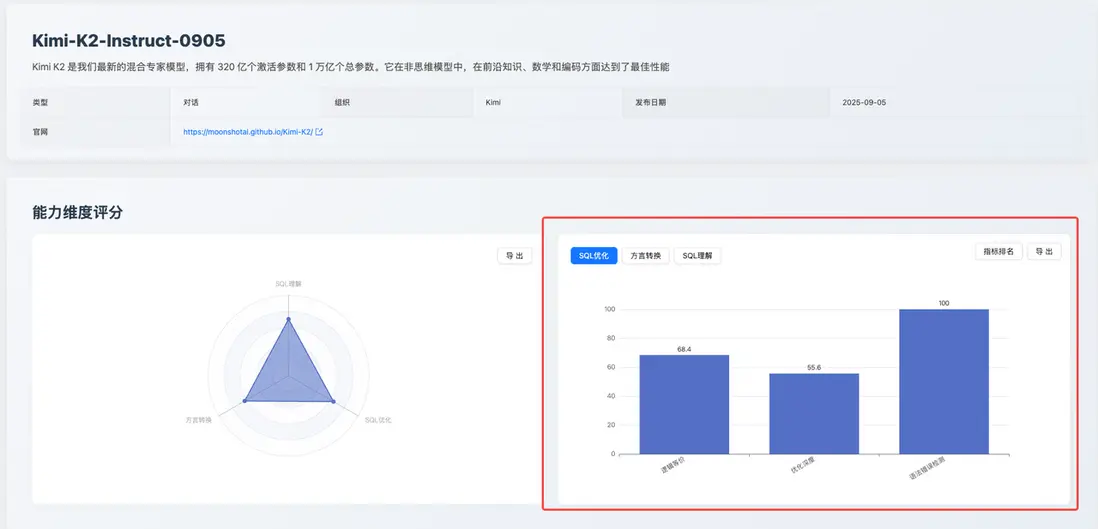
SQL 優化能力:64.4
該分數體現了模型在 SQL 優化 方面的能力特點:側重於保證語法的正確性,但在深度優化上表現不足。
具體來看,其「語法錯誤檢測」獲得 100 分滿分,保證了優化後代碼的可用性;「邏輯等價」(68.4),表現尚可。但其核心短板在於「優化深度」(55.6),該項得分僅排名第 14,説明其優化策略傾向於保守和普適,在投影下推和 LIKE 前綴優化測評時表現不佳,Kimi K2 未能使用到這些查詢優化技術,缺乏對複雜查詢進行深度重構以提升性能的能力。
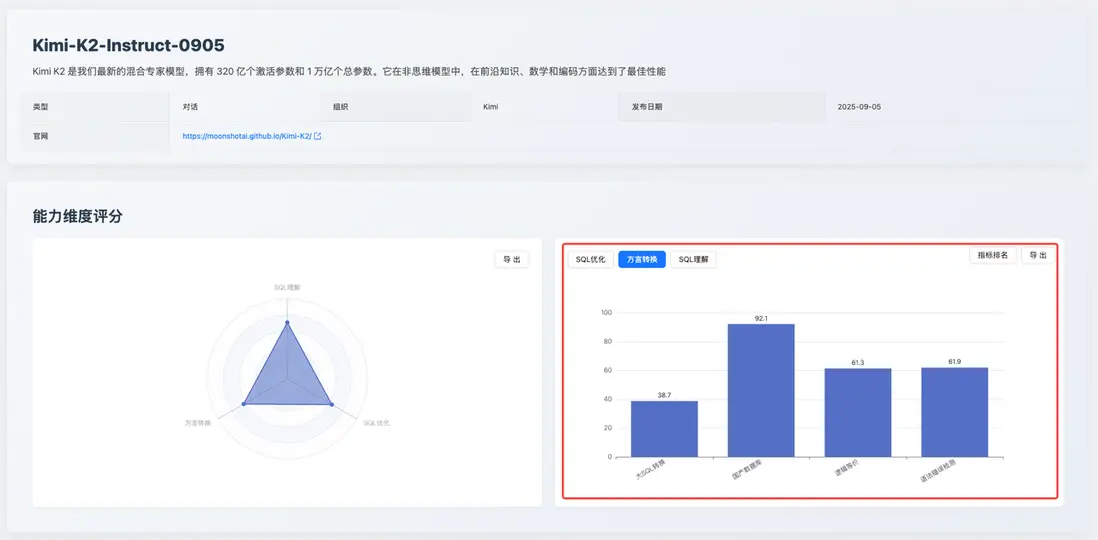
方言轉換能力:63.0
此維度的得分呈現出典型的能力分化。模型的優勢在於對國內數據庫生態的適配性,其「國產數據庫」轉換子項得分高達 92.1。然而,其在處理「大 SQL 轉換」時表現非常掙扎,得分僅為 38.7,這是該模型最主要的短板之一。
這表明,Kimi K2 在處理標準化的、具有明確國產化需求的遷移任務時表現出色,在 SQL Server 到 GaussDB 的大 SQL 轉換時出現了邏輯不等價問題,如在原始 SQL 中 WHERE ProductID = @ProductID Kimi K2 將其錯誤的改寫為 WHERE ProductID = ProductID,原始 SQL 使用參數變量而改寫後使用自身比較恆為真,這將導致更新整個 Products 表,而不是隻更新當前遊標指向的那一行,表現出 Kimi K2 難以應對包含超長、複雜邏輯的異構數據庫遷移場景。
四、平台升級:更深入、更直觀的對比分析
為了幫助用户將評測數據轉化為實際的選型決策,SCALE 平台本月正式上線了兩項核心功能。其核心價值在於,推動用户從 “看總分排名” 的宏觀瀏覽,轉向“為特定場景找最優解”的深度分析。
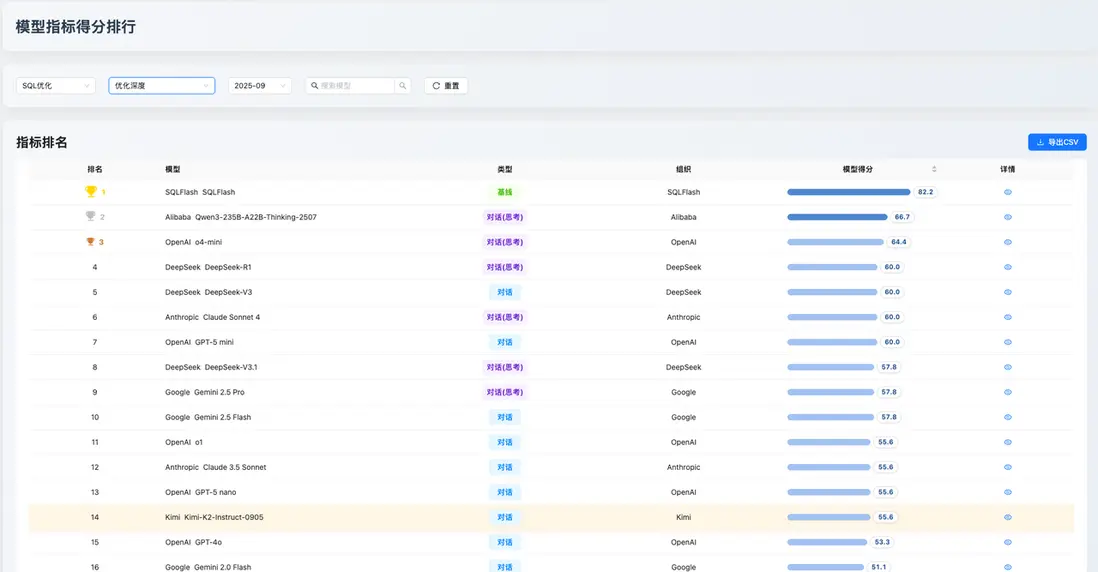
模型細分指標排名
超越總分,洞察模型的“偏科”特性。
此功能支持用户下鑽到 12 個細分指標,查看模型在特定子任務上的排名,以評估模型是否滿足特定場景需求。
應用舉例:以 Kimi K2 為例,其「SQL 優化」總分排名第 12,僅看總分可能會在初步篩選中被忽略。但通過細分指標排名,我們發現其 「語法錯誤檢測」排名第 9,「邏輯等價」排名第 10。這揭示了該模型在保證代碼基礎可用性方面是可靠的,只是在深度優化上存在短板。對於那些優先保障代碼正確性而非極致性能的團隊,Kimi K2 將是一個更優的選項。
模型對比分析
告別盲選,直觀定位場景最優解。
該功能支持用户選擇多個模型,進行多維度可視化對比,直觀地進行選型權衡。
應用舉例:假設一個團隊需要在“支持國產數據庫”和“處理複雜查詢遷移”兩個能力中做出選擇。通過模型對比功能,將 Kimi K2 與 DeepSeek-R1 並列比較,數據將清晰呈現:Kimi K2 在「國產數據庫」轉換上優勢明顯,但在「大 SQL 轉換」上遠遜於 DeepSeek-R1。這一可視化結果使得決策路徑變得清晰:如果核心任務是適配國產數據庫,Kimi K2 是更優選擇;反之,則應選擇後者。該功能將複雜的選型評估,轉變為直觀的數據比較,極大提升了決策的效率和準確性。
五、專家點評

尹海文,數據庫專家,CCF 數據庫專委會執行委員、Oracle ACE(Oracle 和 MySQL 方向)、PostgreSQL ACE。公眾號 “四海內皆兄弟” 主理人,圈內擁有 “首席” 稱號。
SCALE 最新發布的 9 月評測榜單,在“評測基準與算法更新説明”這段中可以看到三個關鍵字:SQL 理解、SQL 優化和方言專訪。在我看來,清晰地指向了一個關鍵趨勢:在 AI 與數據庫技術深度融合的當下,我們正從追求“全能冠軍”轉向識別“場景專家”。這份榜單及其功能升級,為行業提供了前所未有的精細化選型視角。
首先,本月新晉的焦點模型 Moonshot 的 Kimi K2 的評測總體結果顯示:SQL 理解(70.4)、SQL 優化(64.4)、方言轉換(63.0)。不過在細分小項上比較亮眼,比如在國產數據庫適配(方言轉換子項 92.1 分)和基礎語法正確性(優化項語法錯誤檢測100分)上表現突出,這精準地切中了當前國產化替代浪潮中對“可用、可靠”的核心訴求。然而,其在“大 SQL 轉換”(38.7分)和“優化深度”(55.6分)上的明顯短板,也同樣坦誠地揭示了其邊界。
其次,本次榜單還有一個亮點在於其平台功能的戰略升級。未來幫助用户進行技術選型。其中深化場景是特別提到的。通用大模型不能解決具體的企業自身遇到的問題。如果要精準的滿意的效果,那麼就要貼合企業做垂直領域的工作。這背後反映的正是數據庫應用的複雜現實——企業場景千差萬別。SCALE 此舉,將評測從學術性的能力競賽,提升到了工程化的選型工具層面,極大地提升了其實用價值。
綜上所述,作為行業從業者,我認為未來的重點不在於爭論哪個模型“最強”,而在於如何利用 SCALE 這樣精細化的“能力地圖”,快速定位到最適合當前技術棧與業務場景的 AI 助手。我期待 SCALE 繼續深化企業級真實場景的構建,並呼籲更多廠商參與評測,共同推動 AI 在數據庫領域從“可用”到“好用”的實質性飛躍。
六、總結與展望
隨着 Kimi K2 等新模型的加入,SCALE 評測榜單已累計收錄超過 19 款業界主流 AI 模型及專業工具。本月的功能升級是提升平台價值的重要舉措,更透明、更易用的數據將有助於社區進行審慎的技術選型。
一個開放、透明的評測生態需要社區的共同建設。我們誠摯地邀請國內外更多的模型開發者、數據庫工具提供商提交您的產品參與 SCALE 評測。通過在同一基準下與全球頂尖模型競技,不僅可以精準定位產品優勢與不足,更能提升品牌在開發者社區中的影響力。
即刻訪問 https://sql-llm-leaderboard.com/ranking/2025-09
查看完整榜單並聯系我們提交您的產品。
SCALE:為專業 SQL 任務,選專業 AI 模型。




