









本次主要來聊聊關於 ORM 的內容,歡迎評論交流,歡迎批評指正
分別從如下 4 個方面來展開
- ORM 他是個啥?
<!---->
- 為什麼要用 ORM?
<!---->
- ORM 給我們帶來了哪些問題?
<!---->
- 如何去考慮是否要使用 ORM?
ORM 他是個啥?
一提到 ORM 很多同學知道他是跟數據庫相關的一個內容,但是並不清楚他到底是這個啥,自己需不需要,到底怎麼玩?
實際上 ORM 就那麼一回事,從這三個字母就可以看到
O:Object
R:Relational
M:Mapping
對象關係映射,即關係型數據庫和我們的實體業務對象來進行一個映射,對與我們使用 ORM 對象來説,就直接去使用其對應的各種方法即達到自動持久化的目的,無需關注具體的 sql 細節
因為 ORM 已經為你隱藏了關於 sql 的部分,讓不熟悉 sql 的 xdm 也可以很好的上手
只要你知道如何使用函數,使用對象裏面的方法到底你的數據操作目的即可
為什麼要用 ORM?
為什麼要使用 ORM 呢?難道出了一個新的東西,我們就一定要用嗎?自然是要知道他的好,我們才會去使用
結論先放在前面,使用 ORM
- 可以減少我們重複的寫垃圾代碼,可以提高我們的工作效率,降低開發成本
<!---->
- 訪問數據的時候,可以使用抽象的方式,用起來非常簡潔
<!---->
- 以及 orm 帶來的各種奇淫巧技
舉一個 gorm 的例子
在 GO 中我們訪問 mysql 關係型數據庫,數據庫中提前先創建好了數據庫,數據表,以及 3 條記錄

GO 中有給我們提供對應的庫
import "database/sql"
import _ "github.com/go-sql-driver/mysql"我們可以使用 sql.Open() 連接 mysql 數據庫
func Connect() (*sql.DB, error) {
db, err := sql.Open("mysql", "root:123456@/test_gorm")
if err != nil {
return nil, err
}
return db, nil
}獲取到 db 句柄之後,我們可以通過這樣的方式,輸入 sql 語句來查詢數據
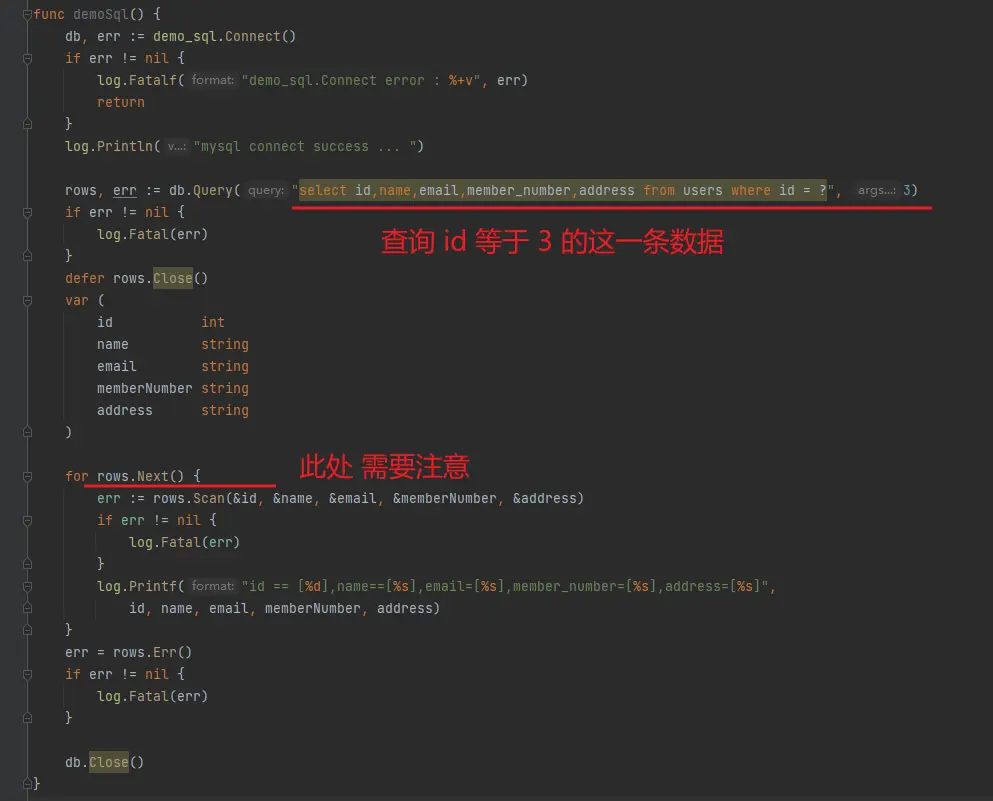
可以發現,本次的查詢語句是 select id,name,email,member_number,address from users where id = ? ,我們再一條數據一條數據的讀取出來(此處需要注意使用讀取 rows.Next() 的時候,需要讀取完畢之後,關閉句柄,否則會資源泄漏)

那麼如果我們換成別的查詢語句,或者其他增刪改的語句呢?
回顧一下以前各種瘋狂寫重複代碼 sql 代碼的情況,流程是一樣的,代碼結構也是類似的,寫着差不多的代碼,過着差不多的人生嗎?
甚至這一塊的代碼很多或許都是複製粘貼,然後改改 sql,改改響應結果
這也太無聊和重複了,咱們還真的是個碼農了?別人搬磚,我們搬代碼?
這不,這個時候,我們就可以使用 ORM 來幫助我們提高生產效率, 減少我們的低價值重複勞動,可以留更多的時間來進行思考和優化
這樣,我們使用 gorm 的話,連接數據我們就可以這樣來寫
func Connect(user, pwd, ip, port string) (*gorm.DB, error) {
db, err := gorm.Open("mysql", fmt.Sprintf("%s:%s@tcp(%s:%s)/test_gorm?charset=utf8&parseTime=True&loc=Local", user, pwd, ip, port))
if err != nil {
return nil, err
}
return db, nil
}上述的查詢就會變成這樣的
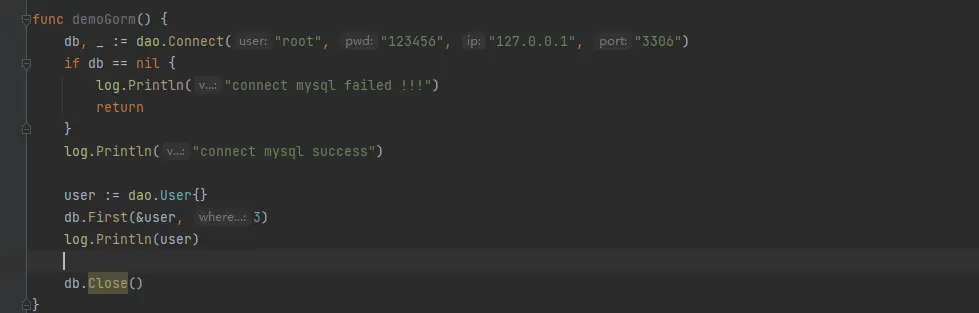
有沒有發現,對應的地方,使用 orm 的方式,對於咱們來説,其實就是需要查詢一條數據,完全都不需要去關心 sql ,只需要按照對象去應用方法就可以查詢我們想要的數據

看到這裏,有沒有初步覺得 ORM 還是很香的,至少咱們寫數據持久化的時候,就不需要寫那麼多重複代碼了,使用 ORM 方便高效
gorm 簡述和提醒
看了上述例子是否會有這些疑問,
- Import 包的時候為什麼導入了又不用?
<!---->
- 為什麼連接數據庫的時候需要帶上
mysql字符串?
import _ "github.com/go-sql-driver/mysql"首先,一個庫如果不用的話,那當然是沒有必要導入的,導入了正式因為需要使用
可以看到 mysql 包中的 init 函數,實際上就是做一個註冊,用一個有效的名字,對一個這一個數據庫引擎
func init() {
sql.Register("mysql", &MySQLDriver{})
}Register 實現如下
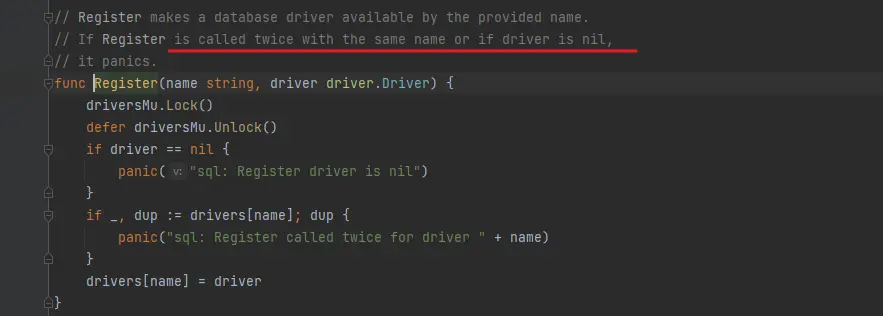
可以看到在sql包裏面有一個全局map,裏把存放了mysql這個名字的driver

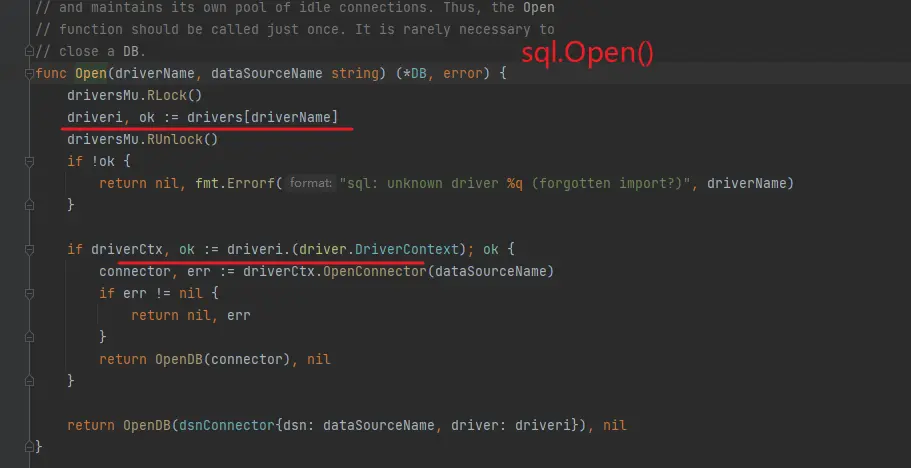
再來查看 gorm.Open() 的實現就一目瞭然了
gorm.Open 中調用了 sql.Open , sql.Open 中去從全局的 map driver中獲取 mysql 字符串對應的引擎
gorm.Open
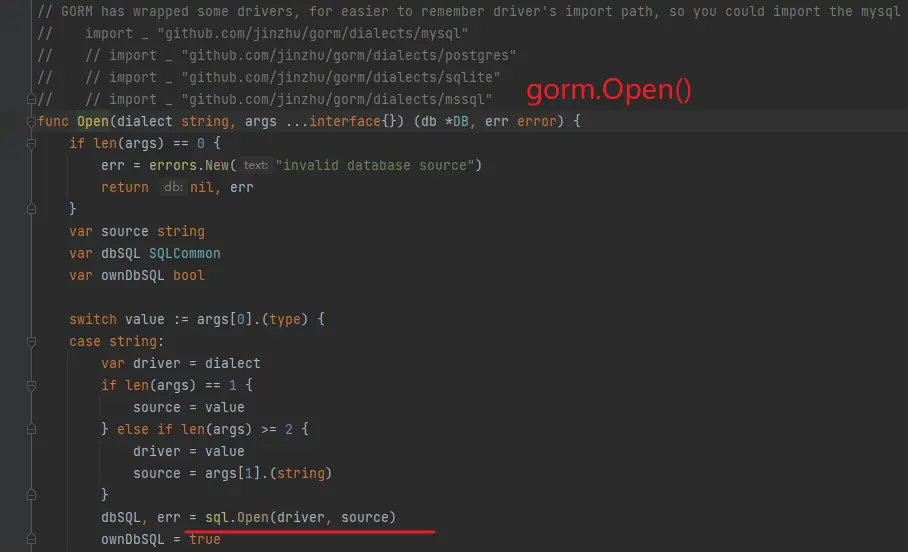
sql.Open
這一塊就到這裏,如果需要系統的學習和了解 gorm,可以從這裏進入:
- https://www.topgoer.cn/docs/gorm/gorm-1c54sbcda16o6
<!---->
- https://gorm.io/
- gorm.Open 為什麼要帶上
charset=utf8&parseTime=True&loc=Local
其中 charset 是表示字符編碼
parseTime 為 True ,表示處理數據的時候,會去解析時間
loc=Local 表示入庫的時候,使用的是本地時區
以及 gorm 有沒有其他的坑?
實際上在應用 gorm 的時候,還是會有很多坑等着咱們,此處先給大家避避坑
與其説是坑,實際上還是自己去應用一個技術的時候對其不夠了解,認知沒有對齊導致的
- 創建數據表的坑
使用 gorm 創建數據表的時候,會先要定義一個基本的數據模型,表示數據表中有哪些字段,其中 gorm 默認給我們提供了一些默認 model,根據實際情況使用即可
type Model struct {
ID uint `gorm:"primary_key"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt *time.Time `sql:"index"`
}例如我們子定義的表結構是這樣的:
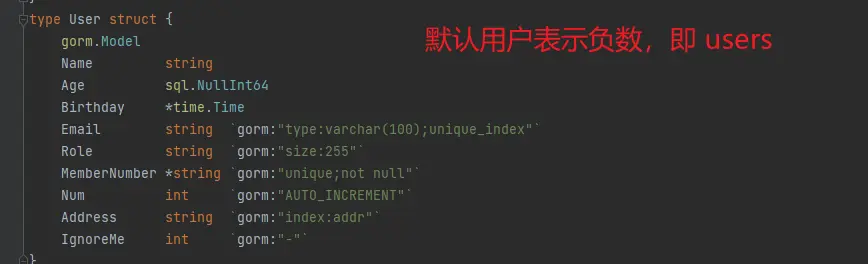
創建出來的表格名為 users ,我們可以使用如下語句禁用表名複數,或者自定義一個表名都是可以的
db.SingularTable(true)- 解析時間的坑
上述使用 gorm.Open() 連接數據庫的時候,咱們指定了 parseTime=True ,那麼後續處理時間類型的數據就不會有問題,如果不指定的話,gorm 處理時間類型的數據會處理出錯
- 想當然的坑
ORM 固然用起來方便,不動 sql 的人用起來也很爽,但是一些基本的操作還是要注意的,否則會對性能影響非常大
例如,查詢一批數據的時候獲取會想當然的這樣來寫
// 偽代碼,示意一波
userList:=[]int{1, 3, 5}
user := dao.User{}
for _,v := range userList {
db.First(&user, v)
}或許在寫其他邏輯的時候這樣寫好像沒啥問題,但是你要明白現在是操作數據庫,怎麼可以循環操作數據庫呢?如果 demo 中的 userList 足夠的大,那麼結果可想而知
在 gorm 完全可以使用 where 的方式來達到我們的查詢目的,還是需要我們理解了之後,靈活使用,不要生搬硬套,例如
users := make([]dao.User, 0)
db.Where("id in (?)", []int{1, 2, 3}).Find(&users)ORM 給我們帶來了哪些問題?
Xdm 閉着眼睛想一下,原來是直接就使用 sql 去操作數據庫的,現在咱們通過了一層 gorm 對象,自然是會對我們的性能帶來影響的,而且 ORM 是多層系統的
- ORM 裏面需要去管理多個關聯和映射,需要消耗資源
<!---->
- 需要咱們學習新知識,增加學習成本
<!---->
- 會產生依賴,長期不用 sql,慢慢的可能你就不會完整的 sql 了
<!---->
- 稍不注意可能就會寫出低性能的代碼
<!---->
- ... 等等,歡迎補充
如何去考慮是否要使用 ORM?
那麼我們知道了 ORM 的優劣,那麼我們是否要去選擇並使用它呢?
根據我們實際項目的需要來定,如果項目比較大,對性能要求較高,那麼還是不要使用了
如果項目不大,並且有很多簡單的,重複的,低效的數據操作,那麼還是可以使用的,使用起來確實非常方便,方便到讓你忘記 sql
總的來説,要還是不要,是個問題,如果是你,你會怎麼選?
歡迎點贊,關注,收藏
朋友們,你的支持和鼓勵,是我堅持分享,提高質量的動力

技術是開放的,我們的心態,更應是開放的。擁抱變化,向陽而生,努力向前行。
我是阿兵雲原生,歡迎點贊關注收藏,下次見~
文中提到的技術點,感興趣的可以查看這些文章:
- GO web 開發 實戰三,數據庫預處理
<!---->
- GO web 開發 實戰二,數據庫相關
<!---->
- GO 語言 Web 開發實戰一

