









作者:盧文豪,百麗時尚數據庫負責人
百麗時尚集團(以下簡稱百麗)是中國領先的大型時尚鞋服集團,旗下擁有20+ 個鞋服品牌,如#BELLE(百麗)、#TATA(他她)、#TEENMIX(天美意)等,覆蓋了從高端到大眾時尚、功能、運動、潮流等品類,線下門店共計8000+,覆蓋300+城市。作為中國時尚鞋履市場佔有率連續十餘年位居第一的企業,百麗擁有發達的線下銷售網絡,從原料到設計到生產,再到終端零售,已形成產供銷一體的完整供應鏈。
在這條供應鏈背後,由集團的科技中心統籌業務系統的建設與運維,包括零售、庫存、財務等核心板塊。為了解除底層技術瓶頸對業務發展的影響,科技中心不斷迭代技術方案。其中作為核心之一的財務系統剛剛經歷了一場“換心臟”手術,將數據庫方案從分庫分表MyCat 架構遷移到 OceanBase,實現了提性能和降成本的 “雙豐收”。
先説成果:性能提升30倍,降本高達原架構的18倍
關鍵功能效率提升30倍。
以財務系統的成本核算功能為例,整體運行時間相對較長。原本在 MyCat 運行時需耗時 10 小時,遷移至 OceanBase 後僅需 20 分鐘,性能提升 30 倍。由監控數據(見圖1)可以看出,原系統在每日 02:00–12:00 期間磁盤持續高負載;而在 OceanBase 環境下,相同任務 20 分鐘內即可完成,負載迅速回落,提效幅度顯著,已得到研發團隊的高度認可。
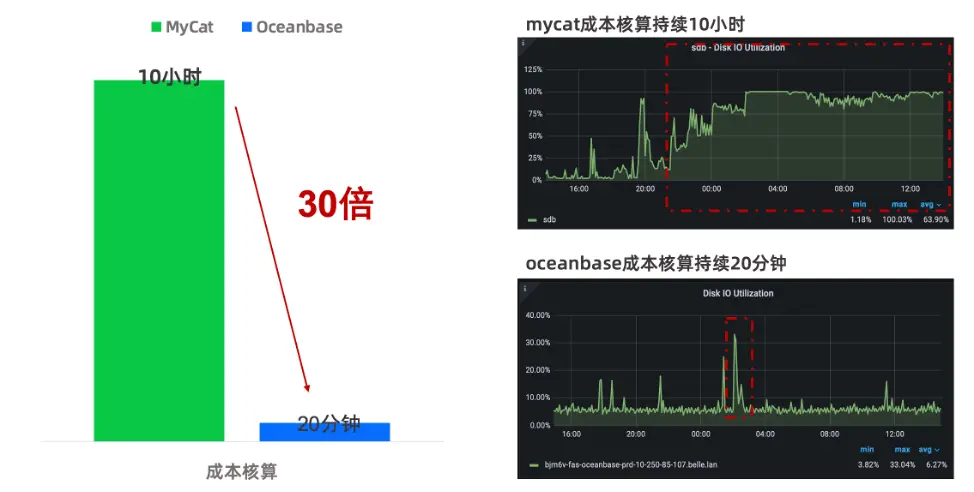
圖1 數據庫遷移前後性能監控數據
存儲成本降96.7%,硬件成本降59.4%。
原來的 MyCat 數據共佔用 20.3 TB,遷移至 OceanBase 後僅佔用 1.3 TB,整體壓縮率高達96.7%。壓縮收益主要來自兩方面:一方面是 OceanBase 自身的高壓縮率,另一方面是原來的 MyCat 架構下存在大量數據冗餘,經過 OceanBase 的存算一體化架構整合,冗餘數據得到釋放。
另外,原來的 MyCat 環境部署共使用 37 台服務器,遷移到 OceanBase 後僅用 10 台服務器即可支撐全部業務,使該業務服務器費用從207萬縮減為84萬,硬件成本下降59.4%。
之所以能夠取得這樣的效果,一方面是由於原架構的冗餘與性能瓶頸對業務系統產生了限制,而新的數據庫方案不僅解開了瓶頸,還帶來了更大的增益。另一方面,歸結於正確的遷移和技術優化,下文展開敍述我們的遷移經驗。
經驗彙總:MyCat 切換 OceanBase 三步走
切換背景
百麗的業務系統原本統一採用#MyCat中間件 實現分庫分表,以每個大區(如華南、華北)規劃分片粒度,確保了絕大多數門店級庫存操作收斂到單分片執行,從而顯著減少分佈式事務。
圖2是業務原來基於MyCat的sharding架構,採用一主兩從的配置,主機房位於北京,兩個從節點位於烏蘭察布機房作為異地容災機房。業務數據根據地區劃分不同的大區分片,每個地區數據訪問經由MyCat下發到各大區分片執行,為了避免分佈式事務,業務層面儘量保證每次獲取的數據都只定位到其中某個大區。
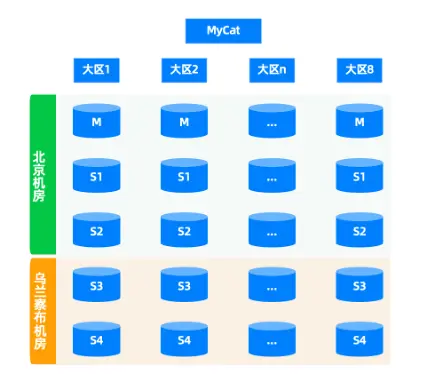
圖2 基於MyCat的sharding架構
在業務的演進過程中,業務數據和業務需求隨之增多,分庫分表 MyCat 架構逐漸暴露出三類主要問題。
第一類問題是數據遷移困難。 當業務需要合併或調整大區時,必須進行跨庫數據搬遷。整個過程腳本複雜、回滾窗口小,風險高、週期長。
第二類問題是MyCat 功能缺陷影響業務。 MyCat 僅提供基礎路由能力,對複雜 SQL(多表關聯、子查詢、聚合統計)和分佈式事務支持有限,因財務等模塊的查詢較為複雜,被迫將分片表改為全局表,且需要應用適配,導致數據冗餘並增加維護成本。
第三類問題是擴展性差。 橫向擴容需要重新劃分大區並再次觸發全量數據遷移,當出現性能瓶頸時,只能依賴垂直升配硬件,無法通過水平擴展快速解決。
為替代 MyCat 並解決其固有痛點,科技中心將選型範圍鎖定於原生分佈式數據庫,並明確兩項核心訴求:一是高可用,零數據丟失;二是在線彈性擴展,無需停服或搬遷數據。
經過市場調研和多輪評估,百麗科技中心最終選定 OceanBase。下文將以財務核心系統從 MyCat 升級至 OceanBase 的項目為例,系統梳理數據庫替換過程中的關鍵實踐。無論採用哪一種替換方案,均需圍繞三個核心步驟展開。
- 數據流轉:梳理全鏈路數據流,明確數據從哪裏來、到哪裏去。
- 數據校驗:確保數據正確性,驗證準確性和一致性。
- 兼容與調優:識別兼容、性能問題,並治理。
第一步:數據流轉
MyCat 架構下
上游數據同步鏈路如圖三所示。
- 主數據 MySQL:通過 MyCat 以全局表方式向各大區 DB 下發集團各業務通用數據。
- 財務應用:其他業務系統也會將數據同步到 MyCat,因為不同業務對應的分區是相同的,所以不同業務間的數據同步是通過DB一一對應的方式進行。
- 同步工具:紅色鏈路代表數據同步鏈路,統一採用阿里開源工具 Otter。
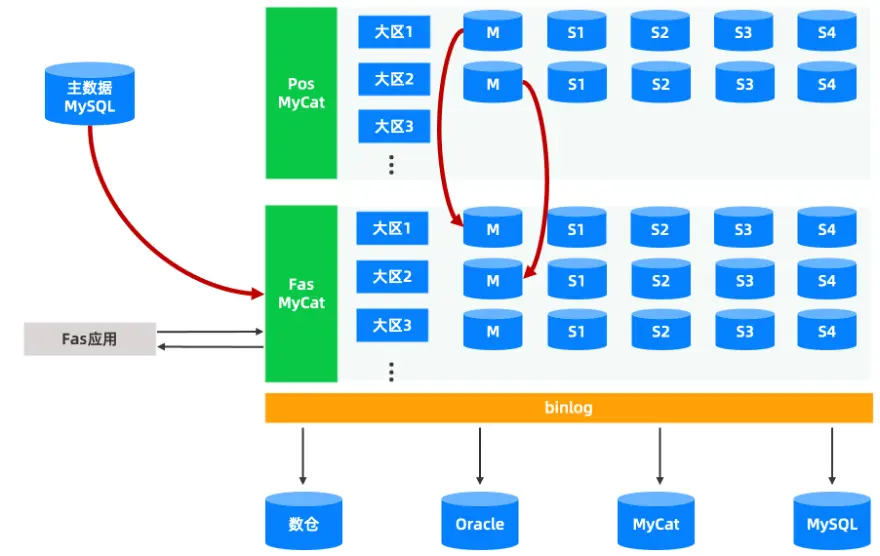
圖3 MyCat架構下,上游數據同步鏈路
下游數據同步鏈路如圖4 所示。
- 數倉:通過 Binlog 抽取實現入倉。
- Oracle:財務系統的業務數據需同步到#Oracle 進行報表分析。
- 同步工具:紅色鏈路代表數據同步鏈路,統一採用阿里開源工具 Otter。
圖4 MyCat架構下,下游數據同步鏈路
OceanBase 架構下
如果使用 OceanBase 替換 MyCat,上線後能否打通現有數據鏈路正常流轉呢?
上游(見圖5)以 OceanBase 作為目標端的鏈路實現比較簡單,只需修改目標端配置即可實現數據同步,可以維持舊方式進行同步。
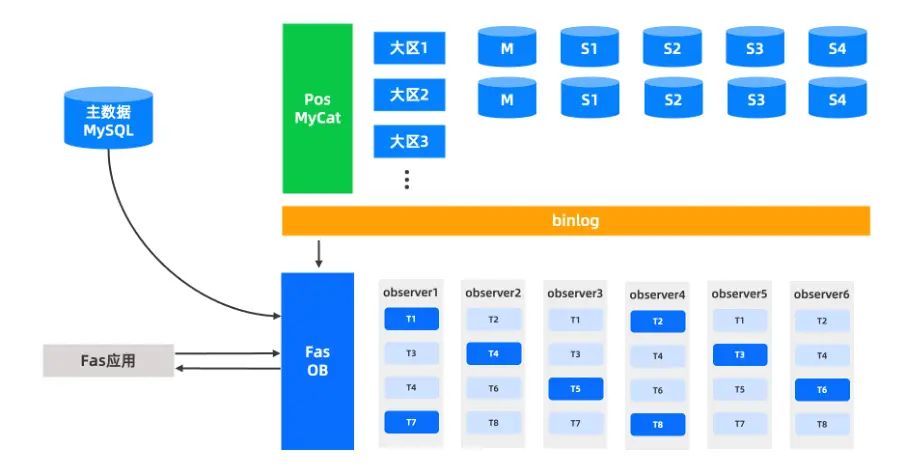
圖5 OceanBase架構下,上游數據同步鏈路
相對上游,下游的替換比較複雜。之前 MyCat 架構下是基於 Binlog 實現的數據同步,如果替換為 OceanBase,無法直接提供 Binlog 日誌以供下游消費。 那麼如何同步數據到下游呢?有兩種解決方案(見圖3)。
第一種方案: 在Fas OceanBase部署OceanBase Binlog Service來生成 Binlog,對整個數據鏈路來説,基本可以通過 Otter 跑通整個鏈路,兼容性是最好的,改動最小。但也存在一些問題,比如MyCat 中有八個MySQL分片,相當於8個線程去採集8個數據庫實例的數據。由於 OceanBase Binlog Service 是以租户為維度,無論是生產Binlog還是消費Binlog,都只能有1個線程去處理。在業務高峯期間, 可能存在性能瓶頸。
第二種方案: OMS 將數據變更下發到 Kafka,通過這種方案,數倉能夠以較低的延遲快速抽取數據,從而滿足實時報表及其他高時效性業務需求,解決了方案一的性能問題。同時由於數據倉庫和部分數據同步到 Oracle 需求,對實時性要求極高,也必須採用 OMS 到 Kafka 的鏈路實現。為此,需要開發數據同步工具,完成下游從 Kafka 到 Oracle 的數據流轉需求。
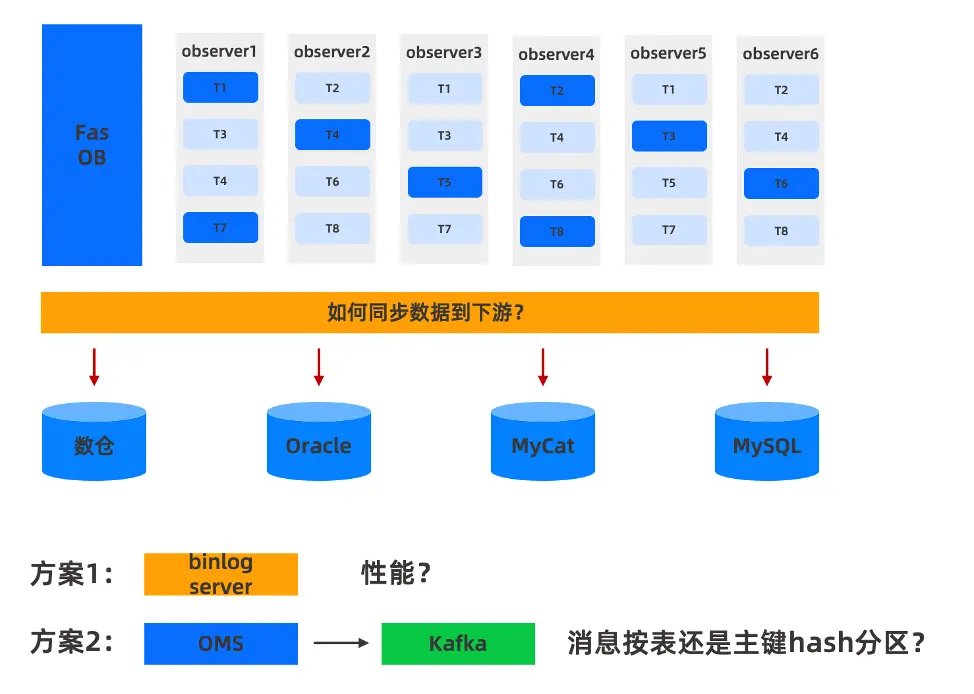
圖6 MyCat替換為OceanBase同步數據至下游的兩種方式
關於 OMS 的使用經驗,我們總結了幾點實踐中遇到的問題與注意事項。
其一,OMS 插入存在衝突會在日誌打印,不影響複製。
OMS 在插入數據時,若檢測到數據衝突,會在日誌中記錄相關信息,不會中斷複製流程。這意味着,例如在分庫場景下,即使存在組件衝突,OceanBase 通過 OMS 的鏈路仍將持續運行,不會因此中斷。對此,我們需在後續工作中加強數據校驗機制,及時發現並處理潛在的數據一致性問題。
其二,OMS V4.2.5.2 之前的版本需要關注字段超過 4K 的複製情況。
在 OMS 4.2.5.2 之前的版本中,對於超過 4K 的LOB字段行外存儲的話,執行DML時OBCDC可能不吐出LOB列的前鏡像,導致下游數據不一致。具體表現為:若某行數據未對該大字段進行修改,OMS 在將變更消息下發至 Kafka 時,會將該字段內容置為空。這一行為對一般依賴全鏡像複製的數據同步工具而言並不友好。例如,如果僅修改更新時間,也可能導致大於 4K 的字段被置空,從而影響下游數據的完整性,建議使用4.2.5.2以後的版本(OMS 4.2.5.2版本已解決該問題)。
其三,OMS 下發數據變化到 Kafka,從消費角度 Hash 性能最優,但是要考慮是否存在唯一鍵的問題。
OMS 支持兩種數據變更下發方式:一種是以表維度,另一種是以主鍵 Hash 分區維度。從消費者角度考慮,主鍵 Hash 分區的性能最好。但需要考慮某些場景目標端存在的唯一鍵問題,可能會導致數據丟失。
以我們遇到的場景為例:假設有一張表(tab1),有一個主鍵(id)和一個唯一鍵(uniq_col),我們對該表依次執行以下三步操作:
- 插入一行數據:insert into tab1 values(1,'a');
- 按照唯一鍵刪除數據:delete tab1 where unique_col = 'a';
- 插入一行 ID 為 2 的數據:insert into tab1 values(2,'a');
如圖7所示,當上述變更通過 OMS 下發至 Kafka 時,若採用 ID 作為哈希值,(1,'a') 和 (2,'a') 很可能不被分發到同一個 Partition 中。在 Partition1 中,同時存在 insert 和 delete,而在 Partition2 中,只有一條 insert 記錄。
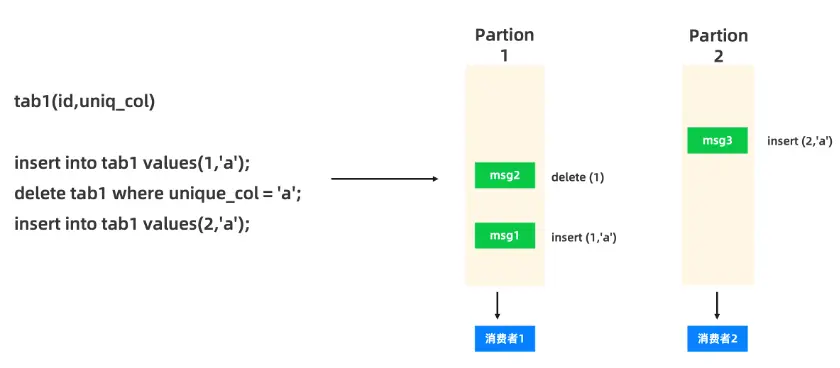
圖7 OMS 下發數據變化到 Kafka時可能存在的結果
由於下游消費者在消費消息時存在各種情況,可能不按照語句執行順序進行,無論下游的數據同步採取 insert into 模式還是 insert into ... on duplicate update... 模式,都有可能遇到 (2,'a') 數據丟失的情況。
如果下游的數據同步採用insert into 模式,在按照圖8的順序消費時,先插入 (1,'a'),再繼續消費 msg3 插入 (2,'a') ,此時由於 a 列衝突不再執行,最後消費 msg2,導致 (2,'a') 數據丟失。

圖8 下游的數據同步採用insert into 模式
如果下游的數據同步採用 insert into ... on duplicate update... 模式(見圖9),先插入 msg3 即 (2,'a') ,後續基於 insert into ... on duplicate update 模式,在消費 msg1 時,一旦 a 列出現衝突,會將 a 列的值更新為1,最後消費 msg2,導致 (2,'a') 數據丟失。

圖9 下游的數據同步採用insert into ... on duplicate update...模式
上述 OMS 以主鍵 Hash 分區模式下發 Kafka 在消費時可能存在的問題,本質是因為在主鍵 Hash 分區模式下,不同 Partition 存在併發修改同一行時同時疊加了唯一鍵導致的。因此在上述 OceanBase 架構下 OMS 將數據變更下發到 Kafka 的第二個方案中,消息按表還是主鍵 hash 分區取決於兩點:一是對高性能有無需求,二是如果下游的表沒有唯一鍵,也可以按照主鍵 Hash 分區方式進行。
反向同步
圖10是業務切換前後的數據鏈路,不同顏色的鏈路代表不同的數據傳輸工具:紅色鏈路代表 Otter、藍色鏈路代表 OMS、綠色鏈路代表百麗自研的數據同步工具 SQLapplier、黑色鏈路代表其他工具。
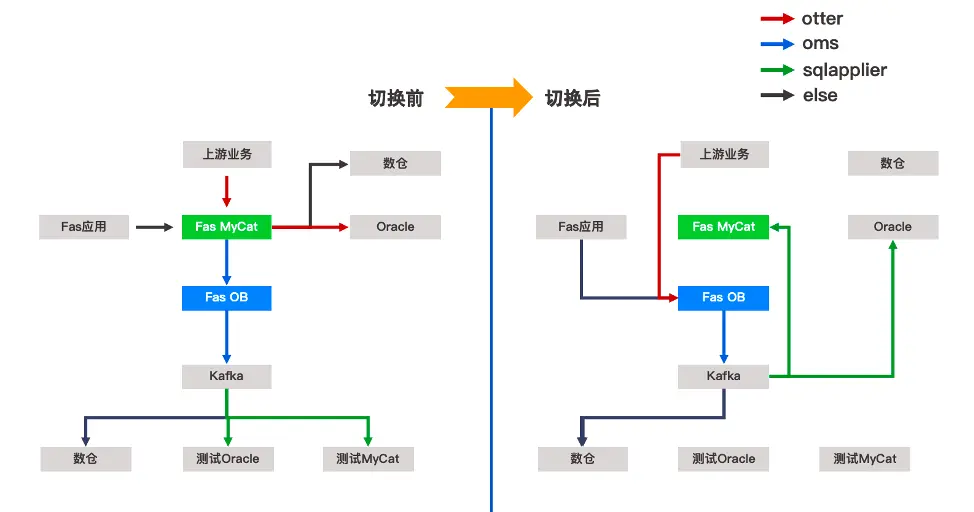
圖10 業務切換前後的數據鏈路
切換前,業務數據通過 OMS 同步到 OceanBase,OceanBase 通過 OMS 下發到 Kafka。同時在上線前需要做數據同步測試,通過 Kafka 將數據同步到測試 Oracle 和測試 MyCat,持續驗證同步工具的性能和功能適配。
數倉可以提前驗證和切換。業務切換時,需要暫停應用和上游業務的同步,此時 MyCat 和 OceanBase 處於相對靜止的狀態。然後需要停止 OMS,將 Kafka 反向同步到 MyCat 和 Oracle,再將上游業務指向 OceanBase 即完成了切換過程。反向同步的意義在於,如果在切換初期出現任何問題可以及時回切,提高系統容災能力。
第二步:數據校驗
數據流轉完成後一般需要進行數據校驗,對於單庫遷移,可以直接使用 OMS 完成數據校驗,在重複多次校驗時,可根據數據不一致情況生成訂正數據。如果源端是 MyCat 的情況,可以搭建源端為 MyCat,目標端是 OceanBase 的校驗,但由於百麗使用了很多 Otter 工具,同時有一些 MySQL、Oracle的異構數據庫校驗需求,因此使用了內部自研的工具(見圖11)。
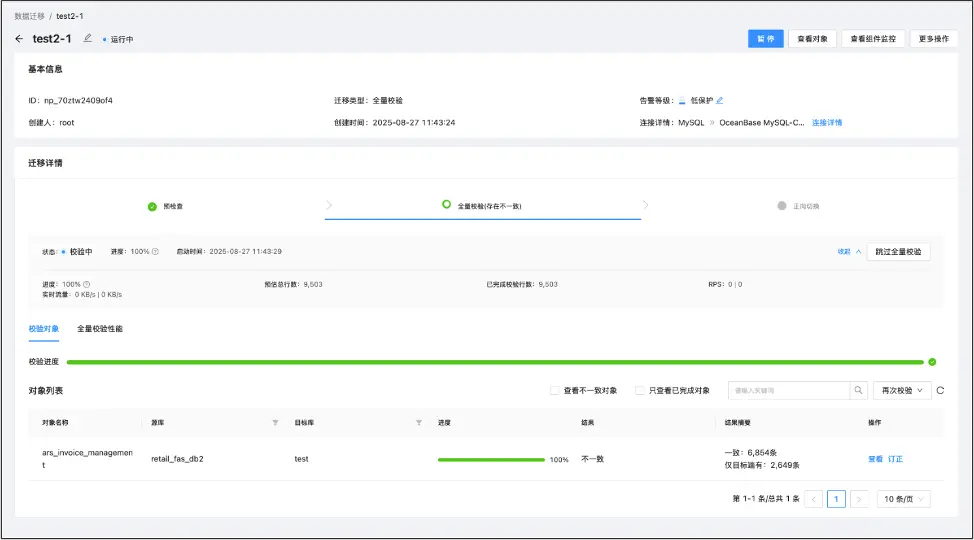
圖11 使用自研工具進行數據校驗
數據校驗基本原理
以圖12為例,如何校驗對應行數據在目標端是一致的,即把各個字段拼成一個字符串,然後做 crc32 校驗。如果兩端的 crc32 匹配,則源端和目標端的數據一致。如果對某一端的數據做簡單修改(如加一個空格),那麼數據將會有很大的變化。對於整表來説,將按照一定的行數拆成多個 chunk,以 chunk 的維度進行目標端和源端的 crc32 比對。如果出現數據不一致的情況,將進行重試,經過多次重試後數據還是不一致時,會進行分裂;如果多次分裂數據還是不一致,將最終轉換為上文行數據的暗行(字符串)來進行校驗。
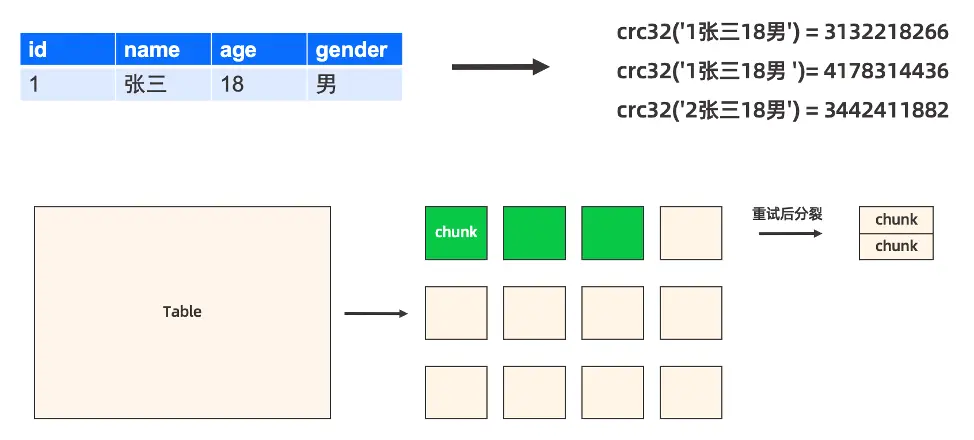
圖12 例證校驗對應行數據在目標端是一致的方法
數據校驗問題彙總
圖13是將平台中 OceanBase 作為源端,Oracle 作為目標端的數據校驗過程,在我們測試過程中一共發現了4個問題。
- 業務數據異常。由於 MyCat 約束較小,隨着長時間使用,以及有變更遷移數據等操作,可能會遺留一些歷史問題,例如 ID重複。
- 唯一鍵約束範圍差異導致數據丟數。MyCat 的唯一約束只能約束到 DB 分區維度中的約束,但在 OceanBase 中是全局約束,這種差異也會導致數據丟失。
- Kafka 消費 Hash 分區、下游唯一鍵約束丟數。
- OBServer V4.2.5.2 之前 4K 大字段丟數。
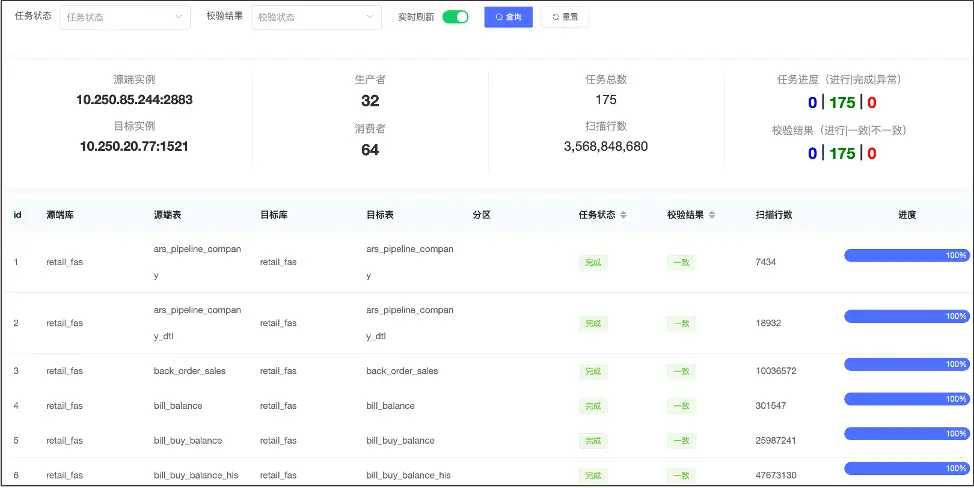
圖13 將平台中 OceanBase 作為源端,Oracle 作為目標端的數據校驗過程
數據校驗覆蓋了數據治理和數據正確性、數據一致性校驗,在上線前解決存在的數據異常問題,是一項非常重要的工作。
第三步:SQL 兼容及性能測試
在打通數據鏈路、完成數據校驗後,需要解決的就是 SQL 兼容性和性能問題,例如如何對比 MyCat 和 OceanBase 的數據庫性能差異,OceanBase 性能是否能滿足我們的業務需求等。針對上述需求,一個樸素的方法是:可以將 MyCat 中所有SQL 在 OceanBase 中實現,即可完整地測試兼容性問題以及性能表現。
為此我們開發了流量回放功能,如圖14所示,通過數據庫管理平台在各個 DB 中採集全量日誌,然後解析為 CSV 格式,最終將所有 CSV 文件整合即可形成解析報告,用於分析集羣層面的整體 SQL 分佈、DDL、DML 等情況。將 CSV 回放到 MyCat、OceanBase 後,形成回放對比報告。
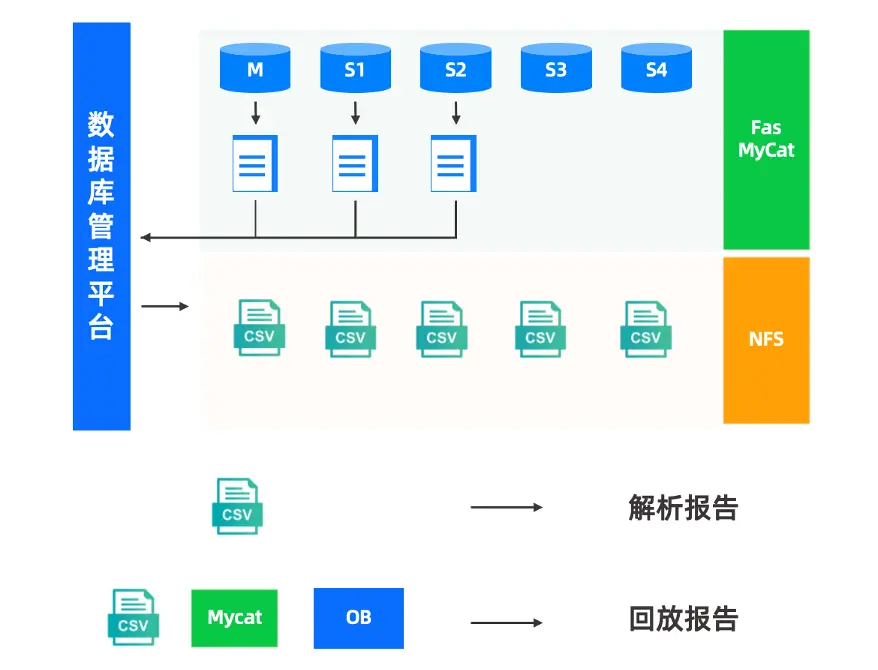
圖14 流量回放的執行過程
看到該過程的你可能會有兩個疑問:
- 為什麼用全量日誌?全量日誌的好處在於全局變量便於開關,如果發現性能有壓力,可以選擇關掉。
- 為什麼用 CSV 格式?這是因為考慮到兼容性問題。例如目前 OceanBase 能夠將 SQL 轉成 CSV 格式,後續可以直接從 OceanBase 的 SQL Audit 中撈取 SQL,並以 CSV 的格式保存,同樣可以跑通回放流程。
回放報告
回放報告中的統計信息(見圖15)包括:將所有回放 SQL 進行參數化形成模板生成對應的 SQL ID;該 SQL 使用到的表;每個 SQL ID 的最小響應時間、最大響應時間、平均響應時間、執行次數、錯誤次數、對應 SQL 等。
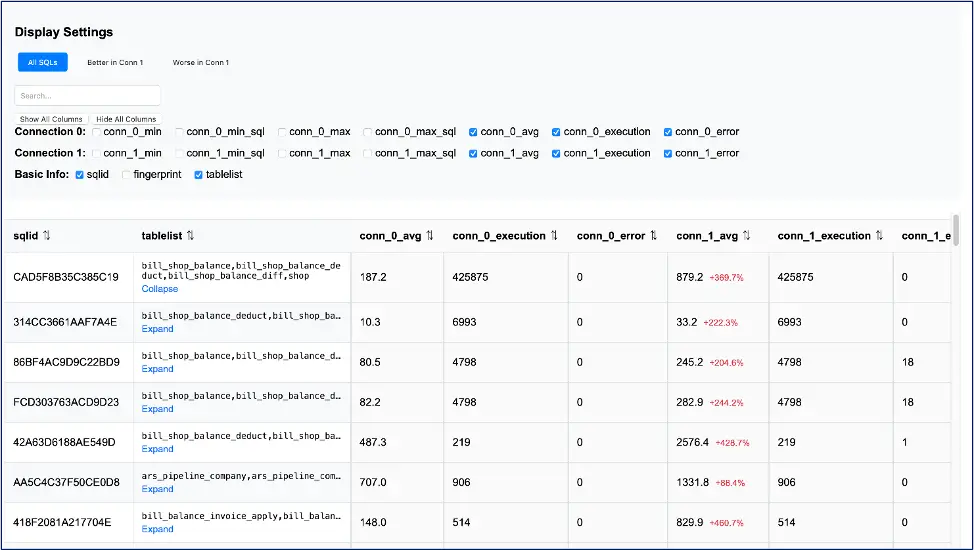
圖15 回放報告中的統計信息
通過回放報告,我們可以進行兼容性分析,確定優化範圍和任務分配,並持續進行回放,從而提升工作效率。
兼容性分析。通過比較源端和目標端的執行結果,檢查是否存在兼容性錯誤。比如報告中顯示存在錯誤,需要進一步核實錯誤原因是超時還是 SQL 語句本身不兼容,從而準確定位 SQL 語句的兼容性問題。
確定優化範圍。回放報告可以幫助我們確定需要優化的 SQL 語句範圍。由於報告生成了大量 SQL 語句,並非所有 SQL 語句都需要優化。報告中提供了每個 SQL 語句的平均響應時間、執行次數等數據,通過這些數據可以評估 SQL 語句性能,從而明確優化範圍。
任務分配。在確定了優化範圍後,如何合理分配任務成為一個關鍵問題。最初,任務分配可以比較隨意,直接根據 SQL ID 進行分配,但在每週的慢查詢研討會中,我們逐漸發現這種分配方式可能導致工作效率低下。為了改善這種情況,我們利用之前收集的表組信息 tablelist ,以表組為維度進行任務分配,這不僅提高了慢查詢治理的效率,也避免了重複工作。
持續進行的回放。由於回放報告會多次回放,尤其是在流量變化較大的系統中,如財務系統在月初和月末的流量可能差異很大。因此,我們會從月初到月末持續抓取流量,並進行多次回放。然而隨着報告數量的增加,橫向比較越來越不方便。為了解決這個問題,我們將報告整合到平台中,並以 SQL ID 作為關鍵要素,將每次回放的報告串聯起來,以便於分析和比較。
SQL 持續治理及跟進
圖16是我們平台的 SQL 持續治理及跟進面板的截圖,可以展示每條 SQL 在每一輪迴放中的變化,每個 DBA 只需要關注自己負責的 SQL 即可。例如圖中所示的 SQL,我們在根據表組進行調優後,可以看到它的最大響應時間等數據明顯下降,證明回放報告對於 SQL 診斷和治理帶來的效率提升是非常直觀的。
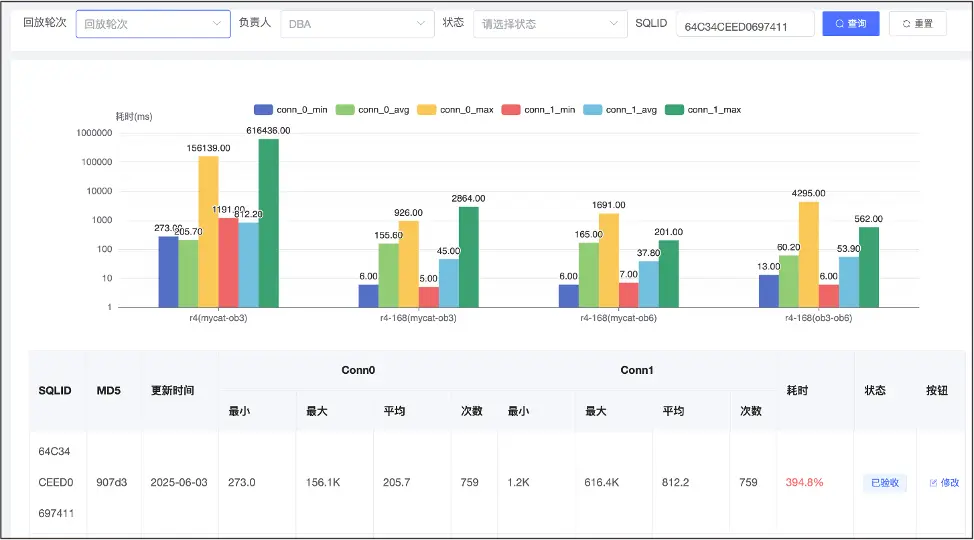
圖16 平台的 SQL 持續治理及跟進面板
此外,值得一提的是OCP 有一個非常實用的功能,可以根據特定時間點恢復數據。在進行壓力測試及流量回放過程中,可能會涉及對數據執行 DML 操作,從而對數據造成修改。面對這種情況,OCP能夠迅速將數據恢復至某一時間點的數據副本,便於我們立即將數據投入使用。使用完畢後,可以將其刪除。對此,我們認為這一功能極具價值。
SQL 問題分類
在進行 SQL 治理和調優過程中,我們共發現了四個問題。
問題1:部分SQL不兼容。
在 SQL 使用過程中,我們通常用“--”進行註釋,放在 SQL 語句最後。在 MySQL 中一般不會發生報錯,但在 OceanBase 中報錯了,研發團隊直接進行了修改。值得肯定的是,在回放了大約4.5萬個 SQL ID 後,發現的不兼容問題僅有這一個,由此看出OceanBase 對 MySQL 5.7 版本的語法兼容度是非常高的,基本無需在兼容性方面投入過多的工作量。
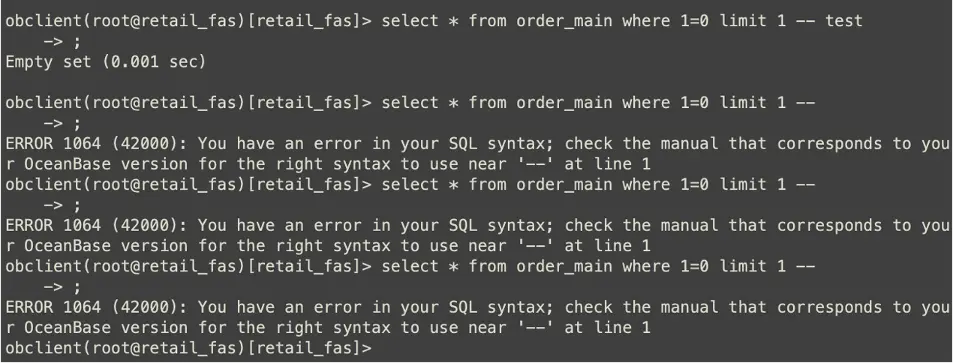
圖17 不兼容的SQL
問題2:RPC 代價高。
當使用多組模式進行查詢時,如果 SQL 涉及多個 OBServer,可能會導致網絡開銷增大,特別是在處理大量數據的情況下,可能會顯著降低查詢效率。解決該問題需要進行分片表表組設計或者對於相對穩定的主數據表,設計複製表。此外,為了快速判斷是否為 RPC 問題,可以通過恢復一個單主環境,並在該環境中執行 SQL,然後與多主環境進行性能對比,從而有效判斷問題是否由 RPC 代價引起。
問題3:分區裁剪。
分區裁剪是另一類需要花費大量時間進行調優的問題。例如,在涉及 DTL 訂單明細表的 order by 關聯查詢中,指定某個大區條件,在 MyCat 中沒有圖18所示紅框中的條件,這是因為 MyCat 的分區規則相同,即在物理層面進行了隔絕,本來就在一個大區內,所以不需要對大區進行指定。而在 OceanBase 中,如果將這個條件去掉,會引發 om 表正常進行分區裁剪,但 od 表不知道需要在這個大區內進行,因此 OceanBase 需要指定這個條件以確保分區裁剪的正確性。這是一個非常典型的分區裁剪問題,其根本原因在於 MySQL 的機制在某些方面並不完善,原本物理隔絕的 SQL 在 OceanBase 是一個完整的庫,這就需要我們在 OceanBase 中進行相應的調整和優化。
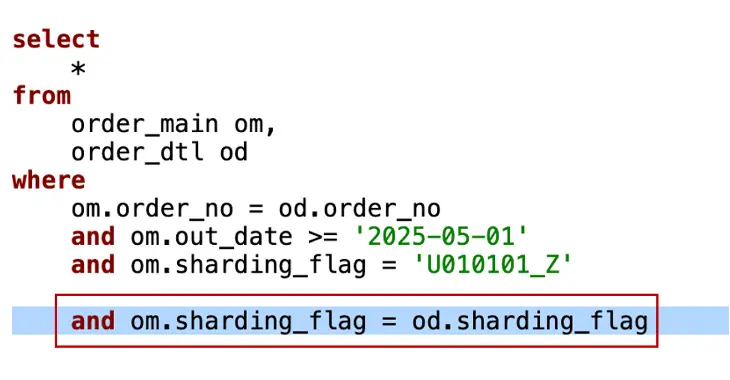
圖18 補充分區條件
問題4:執行計劃問題。
執行計劃問題涉及幾個關鍵參數。
- partition_index_dive_limit 參數是 SQL 採樣分區參數,可能會影響執行計劃的評估,如果採樣分區較小且數據為空,可能會導致採樣誤判,影響代價評估,建議根據實際需求將參數調大。
- 大小參數的問題,指同一 SQL 在不同變量下讀取的數據差異較大,但使用了相同的執行計劃,可能會導致性能問題,此時可以使用 /_+USE_PLAN_CACHE(NONE)_/ 進行規避,但這會使得每次執行該SQL都硬解析,有額外的CPU開銷,需要綜合評估使用。
- 如果 in 參數過多,可能會導致硬解析時間過長,此時可以適當調整參數_inlist_rewrite_threshold,使 in 參數到達一定閾值後可以進行改寫以避免硬解析的代價。
問題彙總
在實際應用中,我們還遇到了一些其他問題:
- l- ocal rescan 計劃不優,低代價的 nlj 計劃由於 local rescan 的規則被錯誤裁剪,導致 SQL 最後走了高代價執行慢的 hash join,該問題出現在 OceanBase V4.2.5.3 之前的版本,已經在 OceanBase V4.2.5.3 版本修復。
- 調整 tablegroup,手動發起均衡,若存在空分區,均衡計算可能會導致任務卡住,該問題出現在 OceanBase V4.2.5.3 版本,已經在 OceanBase V4.2.5.4 版本修復。
- 包含複製表的 SQL,一定情況下會存在無法複用執行計劃的情況,該問題出現在 OceanBase V4.2.5.4 版本,已經在 OceanBase V4.2.5.5 版本修復。
切換收尾:平台適配
我們內部使用 Archery 工單平台完成 SQL 的管理和發佈,並且現有的 MySQL 等數據庫也都在使用 Archery 工單平台,因此我們計劃使用該平台接入 OceanBase。
目前,OceanBase 已經對接了 goInception 項目(https://github.com/whhe/goInception),可以實現 OceanBase 資源類型的工單回滾,即結合 OBServer 完成 SQL 的回滾操作。
在使用 Archery 平台管理 MySQL 時,我們通常通過 ptosc或 gos 等方式實現 Online DDL 操作。然而,這種方式對於 OceanBase 的離線操作,可能會直接鎖表。
針對這種情況,我們期望達到的效果是:提交工單時,無論是 DBA 還是研發人員都能夠識別出操作是 Online 還是Offline。過去我們依賴於肉眼判斷,為了改進這一流程,我們增加了一項小功能:在提交工單時,我們會在測試環境中的 OceanBase 中運行一遍,檢查 Table ID 是否發生變化。如果 Table ID 發生變化,則表明操作是 Offline 的;如果沒有變化,則表明操作是 Online 的,告警信息如圖19所示。

圖19 告警信息
這一設計雖然簡單,但效果顯著,研發人員在提交工單時可以一目瞭然地知道操作是在線還是離線,大大提高了工作效率。
百麗核心系統為什麼選擇OceanBase?
以上就是百麗財務系統從MyCat遷移至OceanBase的技術經驗總結,在此過程中,非常感謝 OceanBase 社區團隊在我們項目測試及切換過程中的密切關注與大力支持。 那麼,為什麼我們會選擇OceanBase,而不是同樣作為開源分佈式數據庫的TiDB、PolarDB……呢?
理由可以歸納為三個方面。
第一方面是OceanBase的技術優勢:
- 可靠。Paxos 多副本機制,RPO=0,故障自動切換,數據零丟失。
- 彈性。單機型與分佈式模式可在線互轉;多租户隔離;高壓縮比降低存儲成本;容量可按需橫向擴展,無需提前重度預估。
- 統一。原生 HTAP,同一套引擎同時支撐 TP、AP、KV 及向量檢索,後續引入新負載無需新增技術棧。
- 易用。提供 OCP、OMS、ODC、OBAgent 等完整工具鏈,顯著降低部署、遷移、監控、運維門檻。
第二方面是社區活躍,OceanBase保持完全開源與快速迭代的風格,對於用户的問題及時響應,確保了用户的技術交流渠道暢通。同時,社區經常開展技術交流活動與培訓課程,不斷加強用户對於問題的解決能力。此外,用户對於其版本發佈節奏也是可預期的。
第三方面是行業驗證,OceanBase在金融、運營商、零售等高要求行業規模化上線,歷經核心系統長時間運行考驗,穩定性已經得到大量企業的充分證明。











