









楔子
最近看到了一篇極具啓發性的論文:《DeepSeek-OCR: Contexts Optical Compression》, AI 大神 Andrej Karpathy 對 DeepSeek 那篇 DeepSeek-OCR 的論文評價很高,你可能以為他會説:“哇,這個 OCR 模型真厲害,識別率又提升了!”
但他沒有。相反,他幾乎是揮了揮手説:“它是個不錯的 OCR 模型,但這不重要。” 因為真正令人興奮的,是這篇論文引出的一個更具顛覆性的想法:我們是不是從一開始就餵了錯誤的“語料”給 AI 了?
Karpathy 的核心觀點是:也許,大型語言模型(LLM)的輸入端,根本就不應該是“文本”(Text),而應該永遠是“像素”(Pixels)。
這個想法聽起來有點繞。我們明明有純文本,為什麼非要先把它“渲染”成一張圖片,再餵給 AI 去看呢?

首先,這是個效率問題。
我們現在用“文本”喂 AI,是通過一個叫“Tokenizer”(分詞器)的東西,把句子切成一個個“詞元”(Token)。比如“Hello, world!”可能被切成 ["Hello", ",", " world", "!"]。問題是,這種方式可能很“浪費”。
而 DeepSeek-OCR 這篇論文無意中提供了一個佐證:它證明了,AI 可以只用 100 個“視覺詞元”(Vision Tokens),就高精度地“解壓縮”出包含 1000 個“文本詞元”的原文內容。這就像,你給AI的不是一長串囉嗦的文字,而是一小塊高密度的“信息壓縮餅乾”(圖片)。AI “吃” 下去(處理)的上下文窗口更短,效率自然更高。
信息更“保真”,不再丟失細節
想象一下,你讓 AI 幫你閲讀一個網頁。現在的“文本”輸入方式,就像是你通過電話把網頁內容念給 AI 聽。所有加粗、顏色、字體大小、排版佈局……這些視覺信息全都丟失了。
而“像素”輸入方式,就像是你直接截了一張圖發給 AI。哪個信息更全?不言而喻。Karpathy 認為,像素是一個“信息流更廣”的輸入方式。它不僅能處理純文本,還能自然地理解文本的樣式(粗體、顏色),甚至頁面上任意的圖表和圖像。
繞開 AI 分詞器
前面兩點只是鋪墊,Karpathy 真正的“怨念”在於:他想徹底幹掉“分詞器”(Tokenizer)。他直言不諱地“炮轟”:“我必須再説一次我有多討厭分詞器。分詞器是醜陋的、分離的、非端到端的。它 ‘進口’ 了所有 Unicode 編碼、字節編碼的醜陋之處,繼承了大量歷史包袱,還帶來了安全/越獄風險……它必須被淘汰。”
為什麼他這麼恨分詞器?分詞器就像是 AI 的“嘴替”和“眼替”,它強行介入在“原始文本”和“AI 大腦”之間。這個“中間商”不僅笨拙,而且會扭曲信息。
Karpathy 舉了個絕妙的例子:一個笑臉表情符號 “😀”。通過“分詞器”,AI 看到的不是一張“笑臉”,而是一個奇特的內部代碼,比如 [tok482]。AI 無法利用它在看圖時學到的關於“人臉”和“微笑”的知識(遷移學習)來理解這個符號。
但如果輸入的是一張包含“😀”的圖片,AI 的“視覺”部分會立刻認出:哦,這是一張微笑的臉。哪個更符合直覺?哪個更智能?像素輸入,讓 AI 得以“眼見為實”。
重新定義 AI 的“輸入”與“輸出”
Karpathy 的設想是,未來的 AI 模型,其“輸入端”(用户提問)應該只接收圖像(像素),而“輸出端”(AI 回答)則可以保持為文本。為什麼?因為“看懂一張圖”(視覺到文本)的任務,遠比“畫出一張逼真的圖”(文本到視覺)要容易得多,也實用得多。
這種“輸入用眼(像素),輸出用嘴(文本)”的架構,也天然契合了AI處理信息的兩種模式:輸入(Encoding):像人一樣,一口氣看完整個頁面(圖片),全盤理解(即雙向注意力)。輸出(Decoding):像人一樣,一個詞一個詞地往外説(即自迴歸)。所以,DeepSeek-OCR這篇論文的真正價值,不在於它提供了一個多好的 OCR 工具,而在於它充當了一次“概念驗證”(Proof-of-Concept)。
它用實驗數據證明了:用“看圖”的方式來“讀書”,是完全可行的,而且可能效率更高。這不僅僅是“文本到文本”(Text-to-Text)任務變成了“視覺到文本”(Vision-to-Text)任務,它暗示了一個更根本的轉變 —— AI 的主要信息入口,正在從“語言”轉向“視覺”。
這個小小的 OCR 研究,可能真的撬動了一個大大的未來。
歡迎大家關注 OceanBase 社區公眾號 “老紀的技術嘮嗑局”,在這個公眾號中,會持續為大家更新與 #數據庫、#AI、#OceanBase 相關的技術內容!
閒言少敍,正文開始
(本文的作者是來自螞蟻集團的陳梓康(庫達),前面 “楔子” 部分的內容,出自 Karpathy 和寶玉,在正文內容開始之前,先對這三位大佬表示感謝~)
今天,我不想做一次簡單的論文導讀。我希望我們能一起,從第一性原理出發,將這篇論文放置於 VLM 和 LLM 發展的宏大敍事中,解構其思想,審視其價值,並探尋其為我們揭示的未來圖景。
其中,我會在文中使用 「這是我自己的猜想」 標識來 highlight 我覺得那些重要的,並且隱藏在論文背後的故事和思考。
我們首先從信息論和系統架構的視角,來審視 DeepSeek-OCR 所解決的根本問題:計算效率與信息密度的矛盾。
但,咱們也並不是説 DeepSeek OCR 顛覆了什麼事情,例如這兩天公眾號上發佈的文章,很多都是 AI 吹出來的。所以在此我也潑一潑冷水,讓大家能夠更加謹慎卻勇敢地探索未來 AI 記憶系統的各種可能性。
1. 開篇:我需要知道什麼?
首先,請允許我提出一個論斷:這篇論文最核心的思想貢獻,絕不是“一個更好的 OCR 模型”。如果是這樣,我們今天就不必坐在這裏。它的真正價值,在於提出了一個大膽且反直覺的範式——“上下文光學壓縮” (Contexts Optical Compression)。
它在問一個根本性的問題:當 LLM 的上下文窗口成為計算和內存的瓶頸時,我們除了在“數字域” (Digital Domain) 內卷算法和架構,是否可以另闢蹊徑,回到“模擬域”或者説“光學域”去尋找答案?
ref:數字型號和模擬信號的互搏
這篇論文的作者們,實際上是將一張包含數千個文本Token的文檔頁面,“渲染”成一張圖像,再用一個高效的視覺編碼器將其壓縮成幾百個視覺 Token。這個過程,本質上是將離散的、一維的符號序列(Text Tokens),映射為連續的、二維的像素矩陣(Image),再重新編碼為離散的、一維的特徵序列(Vision Tokens)。它完成了一次信息的跨模態轉碼和壓縮。
那麼,這種“光學壓縮”範式,與當前主流的長上下文解決方案相比,其本質區別何在?
- 對比 RAG (Retrieval-Augmented Generation):RAG 是一種“開卷考試”的策略。它將知識存儲在外部,通過檢索器動態調取。它解決的是知識的廣度問題,但沒有壓縮進入 Transformer 核心計算的上下文本身。而光學壓縮,更像是把開卷的參考書用“縮微膠捲”拍下來,然後帶着放大鏡進考場。它直接作用於進入上下文的信息本體,而非信息的獲取方式。
- 對比注意力機制創新 (FlashAttention / RingAttention): 這些是系統和算法層面的操作。它們通過優化計算和內存訪問,使得二次複雜度的 Attention 能夠處理更長的序列。但這並沒有改變 O(N^2) 的本質,只是把 N 的天花板推高了。光學壓縮的思路則完全不同,它釜底抽薪,致力於將N本身變得極小。如果能將 10,000 個文本 Token 壓縮成 500 個視覺 Token,那麼 N^2 的計算量將驟降 400 倍。這是另外一種,壓縮的思路,即 tokens 壓縮,而不是計算和存儲的優化。
- 對比狀態空間模型 (Mamba): Mamba 等線性複雜度的模型,是從架構根基上拋棄了 Attention 的二次依賴,是一種架構革命。它和光學壓縮是正交的。光學壓縮是一種編碼策略,Mamba 是一種序列處理架構。理論上,我們可以將光學壓縮後的視覺 Token 序列,餵給 Mamba 架構的解碼器,從而實現“雙重增益”。但目前,Mamba 模型並沒有廣泛受到認可,因此,未來可能不會有太多人關注這個結合。
Then,回答剛才的問題:DeepSeek OCR 它更接近什麼(本質)?我認為,它完美地融合/仿生了兩個概念:
- 計算機體系結構中的“內存分層” (Memory Hierarchy): 我們可以將 LLM 的注意力上下文視為 CPU 的 L1/L2 Cache,高速但昂貴。而通過光學壓縮存儲的上下文,就像是主存(DRAM)甚至硬盤(SSD)。它容量大、成本低,但訪問(解碼)時需要一次“解壓縮”操作。下圖中的模擬“記憶遺忘”機制,更是將這個比喻推向了極致。
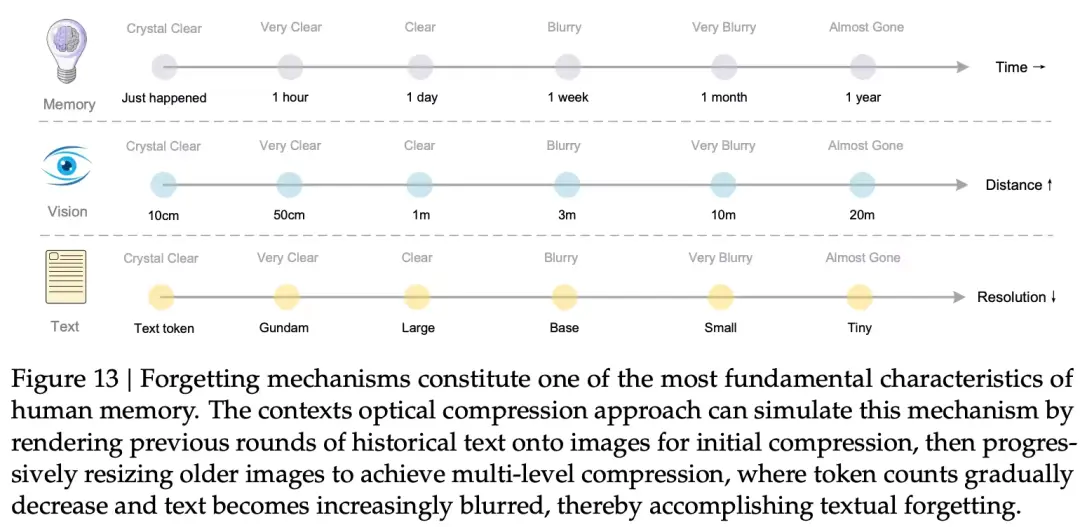
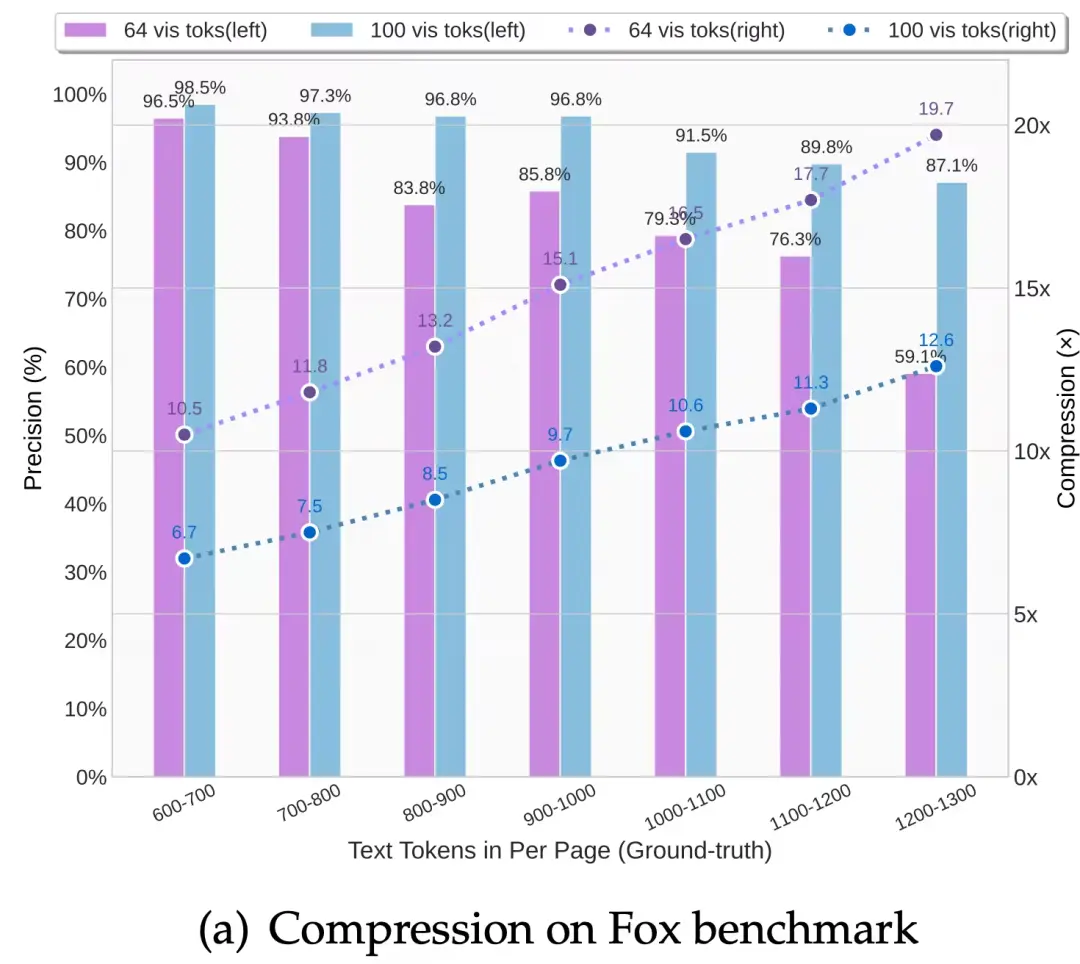
- 信息論中的“有損壓縮”: 下圖清晰地展示了,當壓縮比從 10x 提升到 20x 時,OCR 精度從 97% 下降到 60%。這表明信息是有損失的——它犧牲了完美的、比特級的文本重建能力,換取了數量級的 Token 壓縮。這對於很多不需要 100% 保真度的任務(如摘要、情感分析、甚至多輪對話歷史管理)是完全可以接受的。
2. 深入架構與算法
2.1. 論證信息瓶頸與模態協同的必要性
首先我們需要知道,LLM long context 的核心吐槽有:
- 純文本模式開銷還是太高了,平方增長。
- 當下 LLM 對於語言的解碼/編碼的信息密度太低。比如,在文檔排版中,1200 個文本 Token往往只佔據一頁(甚至半頁)的物理空間。而一個高分辨率的圖像,只需要幾百個視覺 Token 就能承載所有這些信息。( OCR 想要解決的問題就屬於這個範疇)。
正所謂 “一圖勝千言”,視覺模態本質上是一種高效的壓縮介質。我們的目標是實現視覺 Token n 數量遠小於文本 Token N 數量的“上下文光學壓縮”,即 n ≪ N。
提問:還有其他高效的介質嗎? 我認為可能是視頻介質。你可以這麼理解,就是 Image 本身是一個 2D 表徵,它似乎證明 2D 表徵的壓縮率大於平方開銷的 Text Context。那麼,3D 表徵是什麼?至少,視頻介質是 3D 的,只不過裏面的時間流向是單向的。
此外,本質上我們在尋找什麼? 我們尋找的是表徵方法,然後再尋找的才是在哪個環節藉助 NN 網絡解決我的需求。
2.2. 高效感知與信息提煉
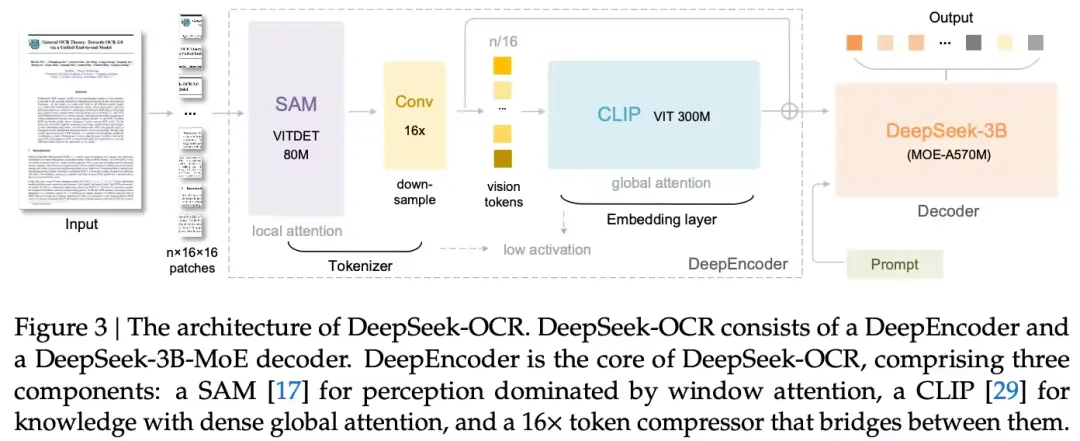
要實現高壓縮比(例如 10:1 或更高)下的無損或近無損解碼,核心在於編碼器必須具備在極低 Token 數量下捕獲高分辨率輸入的能力。這就是 DeepEncoder 的職責。
解碼的方案有千千萬,比如:InternVL 的瓦片方法或 Qwen-VL 的自適應分辨率編碼。但是它們的問題在於,傳統 VLM 編碼器在高分辨率下要麼產生過多 Token,要麼導致激活內存爆炸,影響訓練和推理效率。
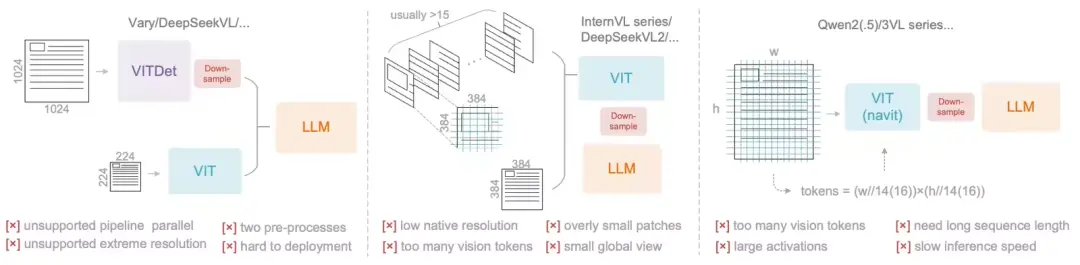
顯然 DeepSeek 也意識到了這個問題,於是,他們設計出了:DeepEncoder——其,串行混合注意力機制 (Serial Hybrid Attention)。分三步走:
-
局部感知與高分辨率輸入 (Window Attention Dominance): DeepEncoder 的前半部分採用了以窗口注意力為主導的 SAM-base 結構「著名的由 MetaAI 提出的 Segment Anything(SAM)」(約 80M 參數)。
- 作用:它能夠處理高分辨率輸入(如 1024×1024 或更高),將圖像切分成大量的初始 Patch Token(例如 4096 個)。由於採用局部窗口注意力(或者可以理解成滑動窗口),即使在如此多的 Patch Token 下,其激活內存消耗依然保持在可接受的低水平。這模擬了人類視覺系統對局部細節的精細聚焦。
-
16倍 Token 壓縮器 (The Information Bottleneck): 這是 DeepEncoder 的核心。在局部注意力之後,他們串聯了一個 2 層的卷積模塊,執行16倍的 Token 下采樣。
- 結果:4096 個 Token 瞬間被壓縮至 256 個 Token。這極大地減少了後續全局注意力層的計算負擔,實現了高效的 Token 壓縮和內存控制。
- 問題:如何巧思想到需要加入一個這樣的模塊呢?
-
全局知識與語義整合 (Dense Global Attention): 壓縮後的少量 Token 進入基於 CLIP-large(300M 參數)的組件。
- 作用:CLIP 預訓練帶來的視覺知識使其能夠高效地整合壓縮後的視覺特徵,將純粹的像素感知轉化為具有更高語義密度的“知識特徵”。
結論:DeepEncoder 成功地將高分辨率輸入的挑戰轉化為一個可控的、低激活內存的壓縮問題,輸出的是一組高度提煉的潛在視覺 Token:
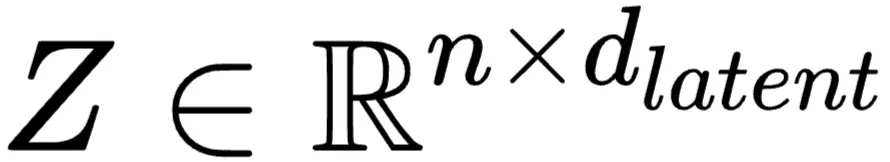
2.3. 高效解碼與知識重構 (MoE Decoder: Decompression and Retrieval)
經過前面的壓縮操作,那麼接下來,壓縮後的視覺 Token Z 現在需要被 LLM 解碼器 f 重新構建成原始的長文本 X。
目標:如何讓一個緊湊的語言模型,從如此少量的視覺信息中,準確地“幻想”出並輸出長達 10 倍的文本內容?
- 壓縮-解壓映射的學習: 解碼器需要學習非線性映射

- 數據工程的支撐:注意到大模型**已經隱式地學習了這種隱射關係**。因為其訓練數據不僅包括傳統的 OCR 1.0 數據(多語言、粗/細粒度文檔標註),還包括複雜的 OCR 2.0 數據(圖表解析、化學公式、平面幾何)。這確保了模型學到的視覺 Token 不只是像素的表示,而是**高層次的、結構化的語義信息**。-
解碼器的選擇。我們容易注意到,顯然:
- 考慮 1:MoE 架構適合進行高通量、大規模的 OCR 解碼和數據生產(比如,每天 200k+ 頁面)(DeepSeek 團隊真的很喜歡「降本增效」哈哈哈)。
- 考慮 2:OCR 1.0 數據也好,OCR 2.0 數據也好,都説明了數據的分佈是稀疏的(因為數據是容易被分類的),因此猜測模型的參數也應該是稀疏的。而 MoE 本身就是稀疏模型。我認為,這是使用 MOE 模型來表達 f 映射的效果如此之好的關鍵原因「這是我自己的猜想😄」。
- 因此,DeepSeek-OCR 採用 DeepSeek-3B-MoE(激活參數約 570M)作為解碼器。
- 思考:更大的參數量,是不是能夠解決更多模態的數據呢?(比如,幫助合成前端生成任務的訓練數據?「這是我自己的猜想😄」)
- 問題: 我調研了社區使用 OCR 的體感,發現 MoE 對於圖片的理解能力,更多還只是體現在一個“內容提取”的能力上。但是在其他方面的能力,一個是,幻覺率大概是 80%,另一個是該 MoE 對於指令遵循的能力還是不夠。因此,我認為在這一塊,我們仍舊有很多可以提升,畢竟還只是 3B 模型。或者可能有其他新的架構創新來解決這個問題。
- 變更:底層的 vllm、sglang 也許儘快跟進,並且支持未來多模態的解碼和推理。
-
壓縮邊界的驗證: 實驗證明,光學壓縮的潛力驚人。
- 當文本 Token 數量是視覺 Token 的 10 倍以內(壓縮比 < 10x)時,模型可以達到約 97% 的 OCR 解碼精度。
- 即使在極端的 20 倍壓縮比下,OCR 精度仍能保持在約 60%。
- 學術價值: 這一結果提供了經驗指導,證明了緊湊語言模型能夠有效地從壓縮的視覺表徵中解碼信息。它為未來 VLM Token 分配優化和 LLM 上下文壓縮提供了理論基礎和實踐界限。
2.4. 從 OCR 到未來認知 Beyond the Document
DeepSeek-OCR 不僅僅是一個高效的 OCR 模型,它更是基於信息壓縮第一性原理,探索視覺與語言模態(VLM/LLM)協同的先驅性工作。其核心算法流程,從 DeepEncoder 的低激活內存高壓縮架構,到 MoE 解碼器的高效知識重構,為我們提供了一套將長文本信息轉化為計算高效的視覺潛在表徵的完整範式。值得借鑑學習的地方很多。
-
深度解析 (Deep Parsing) 與結構化提取OCR 任務不再是簡單的文本識別。DeepSeek-OCR 具備深層解析能力(Deep parsing)。通過統一的提示,模型能夠:
- 將文檔中的圖表轉化為 HTML 表格(金融報告中的關鍵能力)。
- 識別化學公式並轉化為 SMILES 格式。
- 解析平面幾何圖形的結構。
- ……




毋庸置疑,這種“OCR 1.0 + 2.0”技術是 VLM/LLM 在 STEM 領域發展的基石。並且,它其實超過了我們對於 OCR 的定義範圍。它是一種端到端的數據識別和數據清洗的算法(nlp instructions + pdf -> structured data)。發散來講,我覺得這種思路,可以解決 80% LLM 語料清洗的各種疑難雜症問題。不知道 LLM 數據團隊是不是有可能改造 DeepSeek OCR 框架,來做出一個基於視覺的通用的語料數據清洗框架呢?(3B 模型的消耗還是很誘人的哈哈哈)「這是我自己的猜想😄」
- 模擬記憶與遺忘機制
上下文光學壓縮提供了一個模擬人類記憶衰退的優雅方案。該學術問題的背景:在一個多輪對話系統中,我們如何管理歷史上下文,以防止計算開銷爆炸?
- 人類記憶的映射:人類對近期事件記憶清晰,對遙遠事件記憶模糊。這種衰減機制與視覺感知中信息隨距離或分辨率下降的模式相似。
-
光學實現(視覺實現):
- 近期上下文:渲染成高分辨率圖像,使用 DeepEncoder 的高保真模式(例如 Gundam 或 Large 模式)進行編碼,保留高保真度。
- 遠期上下文:通過漸進式縮小渲染的圖像(對應 Tiny 或 Small 模式,即通過窗口注意力),可以進一步減少視覺 Token 消耗。Token 數量的減少,導致了文本的“模糊化”和信息精度的自然衰減,從而實現了記憶的漸進式遺忘。
- 但是,我覺得 DeepSeek OCR 還有一點可以考慮得更加周到的是,我們如何恢復那些逐漸被遺忘的記憶,即「記憶再水化」(我對於記憶的機制的廣義定義是:記憶淡化,並且可在特定時機回想起某個東西)。雖然有一些工程性的辦法解決,比如,“當模型需要精確引述或代碼/公式高保真時,對目標頁‘局部升採樣’或二次 OCR,臨時把該片段放回文字上下文”。但 OCR 架構本身不是這種所謂的有點類似於 self-reference 的架構,因此缺乏一點完美感。「這是我自己的猜想😄」
論文展望:這一機制為構建理論上無限上下文的 LLM 架構提供了潛在途徑,它巧妙地在信息保留和計算約束之間取得了平衡。DeepSeek-OCR 的研究表明,這種通過視覺模態進行長上下文壓縮的方法,是未來 VLM/LLM 協同發展的一個極具前景的新方向。
3. 論文之外 —— 談談 DeepSeek OCR 對於記憶機制設計的啓發和外推
我們知道,傳統的記憶框架,大都是個閉環記憶系統:每次交互後,新記憶被壓縮 C(一般是向量壓縮 RAG、或者一些所謂的 NN 模型壓縮比如 MemGen)並分級存儲,供未來檢索。
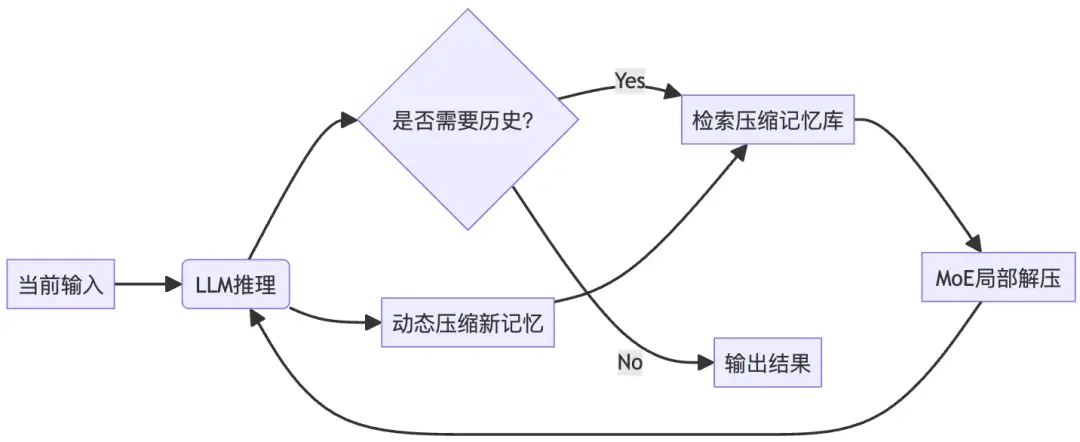
但是現在壓縮 C 的方法多了一種,即上下文光學壓縮。
DeepSeek OCR 它真正想説的,是如何用光學-視覺通道,重新設計大型語言模型的「記憶系統」。論文用 OCR 這個概念掩蓋了 DeepSeek 的真實目的,那就讓我來推演「技術的下一步」吧。下面我按照“記憶”而非“OCR”的主線,結合我對於大模型記憶的理解和經驗,給出一條在大模型記憶這個方向的思維推演。
3.1. 概念再次對齊
| 層級 | 人類對照 | LLM 對照 | 經典解決方案 | DeepSeek-OCR 的切入點 |
|---|---|---|---|---|
| 1. Sensory memory | 0.1 s 視網膜殘影 | 原始 10K-100K token 直送 Attention | —— | 把“文本像素化”→ 視覺 token,用光學把感官緩衝壓縮一個數量級 |
| 2. Working memory | 7±2 組塊 | kv-cache常駐GPU HBM | 滑動窗口 / 稀疏 attn | 用圖像分辨率當“光圈”<br/>,動態調節 cache 大小 |
| 3. Long-term memory | 海馬-皮層固化 | 外存 RAG / 參數記憶 | 向量庫 / LoRA | 把“遺忘”做成可微的光學降採樣<br/>,而不是手動閾值 |
DeepSeek-OCR 的核心創意,是讓第 1→2 層的壓縮過程,從“數字-序列”域搬到“光學-像素”域,從而把「記憶容量」與「計算開銷」解耦。下面所有外推,我都是在放大這一思想。
3.2. 探索-1 把“上下文”當一張可微調的「全息底片」
3.2.1. 直觀類比
- 傳統 Transformer:像把一本書撕成 10 000 張小紙條,每張紙條必須與所有其餘紙條做一次“兩兩握手”,O(n²) 次握手。
- DeepSeek-OCR:把整本書一次性拍成一張“微縮全息底片”,只讓幾百個“光斑”(vision token) 進入握手區;握手次數驟降 400×。
3.2.2. 壓縮方式
既然 DeepEncoder 對於圖像的壓縮效果顯著,那麼我會選擇採用「文本 → 圖像 → vision token」這條通道。其本質上,其實在做一次可控的有損編碼:
- H(text) ≈ 8 bit/char × 6 char/token ≈ 48 bit/token
- H(image) 在 1024×1024×3×8 ≈ 25 Mbit 量級,但經過 DeepEncoder 後只剩 256×d 維浮碼,假設 d=1024、FP16,≈ 0.5 Mbit。壓縮比 50× 時,信息熵損失 ≈ 3 %(參考論文 97 %→60 % 的實驗曲線)。
- 但是,對於「文本 → 圖像」這個過程的具體實現細節,我個人暫時也辦法定奪。可能需要做很多實驗,來驗證/分析「文本 → 圖像」對於後續步驟的上下文光學壓縮的實際影響。
這麼操作的關鍵是:把“遺忘”預先 baked in 到編碼器權重裏,讓模型學會哪些視覺紋理對應“可丟”的排版空白,哪些對應“必保”的語義 token——這比事後用啓發式閾值剪枝要優雅,因為:
- 可微:梯度可反向穿透 CNN-ViT;
- 統一:同一條 loss 既管 OCR 精度也管壓縮率。這裏源於我在 Nano-Banana 訓練思路中得到的啓發。就是,用文字/字母生成的準確性來衡量 Nano-Banana 的 image edit 功能的精度和質量。解釋一下就是,如果我們同時最優化 OCR 準確率 & 降低 tokens 數量這個帕累託條件,那麼我們最終能夠得到一個,既不丟失語義/視覺信息,tokens 數量又少的,(多模態)大模型。
3.2.3. 實現 sketch:一張「可編程光圈」驅動記憶閘門
因為在 LLM 記憶之中,我們希望模型能夠動態的調整壓縮率。因此,或許我可以大膽嘗試把 DeepEncoder 的 16× Conv 下采樣改成一個可學習的、內容依賴的“光圈模塊”:
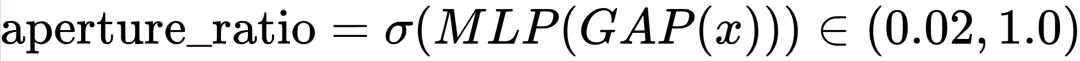
基於這樣的設計,或許我們能夠在未來的 LLM 中實現一個這樣的 feature:
- 訓練階段:在 loss 里加一項 λ·aperture_ratio,讓模型自己權衡“記多少”。
- 推理階段:用户用一條 system prompt 即可把 aperture 調到 0.1,實現“只記得大意”。或者用户説,“請幫我仔細回憶”,那麼就是把 aperture 調到 1.0。
你看,是不是很有意思?
3.2.4. 開放問題
- 光圈可解釋性:能否把 σ(·) 的觸發模式反向映射到人類可讀的“遺忘規則”? 它和遺忘會有什麼關係呢?這個或許只有等到這套系統實現的那一天,才能夠知道了。
- 與 KV-cache 的聯動:光圈輸出能否直接預測哪些 layer/head 可以跳過?
3.3. 探索-2 把 RAG 做成「光學+向量雙路召回」
3.3.1. 傳統 RAG 的盲區
- 檢索器只看「語義向量」,不管「排版結構」——於是表格、公式、分欄 pdf 常被攔腰截斷;
- 召回後仍需把整段文字重新 tokenize,沒有壓縮,context 長度瓶頸未解決。
3.3.2. 光學雙路相機
把 DeepEncoder 當成一枚「光學視網膜」,與語義向量並行工作:
doc → ┌── semantic encoder → 256 d 向量 ─┐
└── DeepEncoder → 128 vis tokens ─┤
↑ |
+–––––––– fuse –––––––––+- 召回階段:兩路索引同時建庫,語義向量管“含義”,vis token 管“版面”。
- 閲讀階段:把召回的 vis token 直接塞進 LLM 的 vision slot,無需再展開成文本 token。
-
預期結果:
- 版面完整性 ↑(表格不脱線);
- 上下文長度 ↓(128 vs 800+ text token);
- 複雜度仍是 O(n²),但 n 已經 6× 更小。
3.3.3. 一個可運行的“小目標”
我們可以基於上面的想法(光學雙路相機),來改進 RAG 系統。比如,可以在某個 8B-Instruct 上插 64 個 vision slot,用 DeepSeek-3B-MoE 當“光學解碼頭”,做金融年報 QA。
- 數據集:FinQA-scan(把原版表格全部渲染成 1024×1024 png)。
- 指標:Exact-Match & Token-Latency。
-
預期:
- EM 提升幾個點(版面不再被破壞);
- 端到端 latency ↓ 30 %(128 vs 800 token)。
3.3.4. 開放問題
- 如何給「光學索引」做 ANN(向量檢索召回)?但是 vis token 是 2-D 特徵圖,扁平化後 L2 距離意義不大……
- 多頁文檔跨頁對齊:當表格橫跨 3 頁,vis token 如何跨頁複用?
3.4. 探索-3 統一的記憶框架可能是什麼?(既不是長上下文,也不是 RAG)
3.4.1. 架構總覽
我覺得未來的記憶框架,肯定不只是長上下文,也不只是 RAG,因此我嘗試提煉探索 1 和探索 2 中的思想和架構,來找到一種能夠統一不同框架的統一框架。
我想這樣設計,就是它只有三個可執行二進制:optix-encode、optix-cache、optix-recall,卻同時替代了
- 長上下文 KV-cache
- RAG 向量庫
- 多輪對話歷史管理
- 甚至 LoRA 權重倉庫(為什麼不呢?)
不妨把整個系統叫做 Optix-Memory Stack(簡稱 OMS),一句話總結:
「任何長度的文本、權重、對話,一律先拍成一張 1024×1024 灰度圖,再壓成 128 個 vision-token,成為唯一尋址單位;Attention 永遠只在這 128×128 的“光斑”裏做二次運算。」
下面給出細節的統一架構、數據流、訓練-推理一體配方。
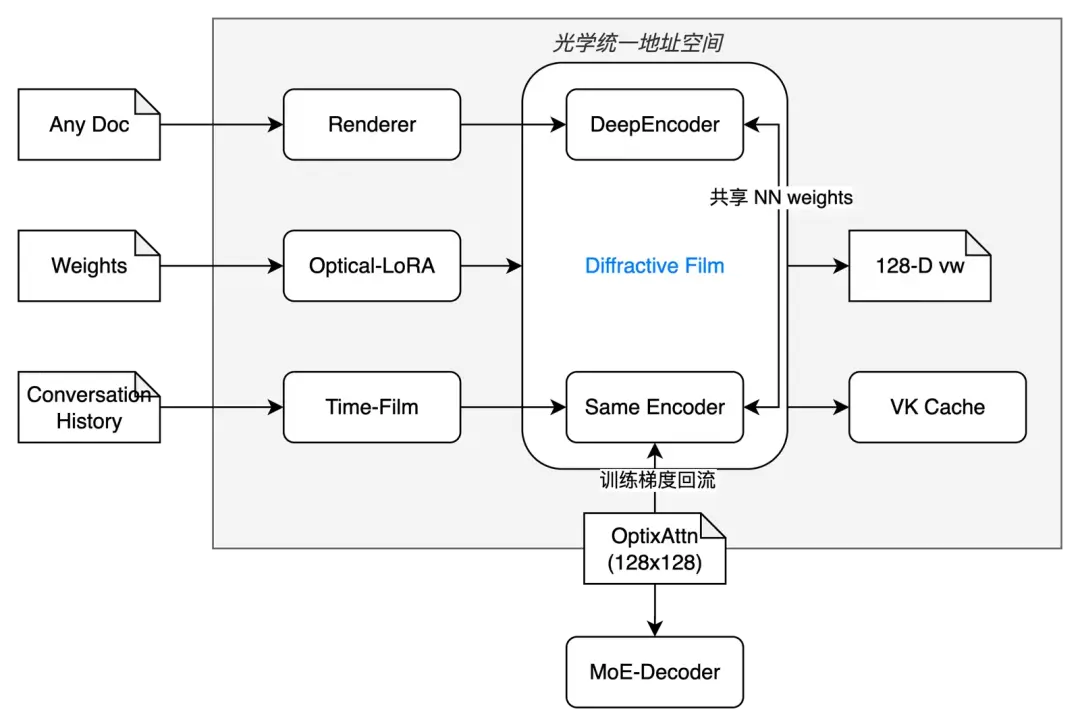
- 數據流:三次「拍照」,一次「衍射」
| 模態 | 輸入 | 拍照參數 | 輸出 visual-key | 駐留位置 |
|---|---|---|---|---|
| A. 長文檔 | PDF/N 頁 | 光圈=0.1(10×壓縮) | 128 vk / 每 1024×1024 圖 | optix-cache(vis-k) |
| B. 多輪歷史 | 文本 | 窗口注意力 | 128 vk / 每 100 輪 | 同上,LRU 鏈 |
| C. 權重補丁 LoRA | ΔW ∈ ℝ^(d×r) | reshape→灰度→衍射層 | 128 vw / 每 LoRA | optix-cache(vis-w) |
| D. 推理 | 問題 q | 文字→渲染→同Encoder | 128 vq | 不進cache,直接 attend |
- 文檔輸入流

- 權重入口(比如 LoRA)

4. 在對話歷史中

- 最後一步:MoE-Decode (3B)

對於架構,我們需要注意到:
- 所有異構數據(doc、weight、history)先成像、後編碼,得到同構的 128-D visual-key;
- 自此以後,系統裏只有一種 token = visual-key;
- Attention 複雜度永遠 128² = 16 384 FLOPs,與原始長度、權重秩、對話輪數無關;輸入總是
[batch, 128, dim],不管你來的是文檔、權重還是歷史。 - 訓練、推理、熱更新、回滾,全部在「圖空間」完成,零浮點權重下發。
這個框架的作用就是,能夠把三種原本異質的數據(文檔、權重、對話歷史)先強行拍成「同一張 1024×1024 灰度圖」,再壓成同形狀的 128-D 向量,以後系統裏只認這 128-D 向量,別的統統不存在。
為什麼非得“統一”?
- 只有同形狀才能塞進同一個 Attention 矩陣;否則要寫三套 CUDA kernel。
- 一旦統一,複雜度就恆定為 128×128=1.6 萬 FLOPs,跟原始長度、權重秩、對話輪數再無關係——這是整個 Stack 能“恆定”的根基。
- 以後做緩存、做召回、做熱更新,只需要比較/替換 128-D 向量,工程界面極度簡化。
3.4.2. 訓練 =「image 空間」裏的單一 loss
目標函數只留兩項:
L = L_task + λ · aperture- L_task:下游目標(OCR 字符交叉熵、QA 的 EM、對話回覆困惑度);
- λ·aperture:迫使光圈縮小→壓縮率上升,讓模型自己學會「哪些像素該被遺忘」;
訓練流程(偽代碼):
for batch in loader:
img = Renderer(batch, aperture=uniform(0.02,1.0))
vk = DeepEncoder(img) # 128
vw = DiffractiveFilm(LoRA_png) # 128
out = OptixAttn(v_q, v_k, v_w) # 128 × 128 恆定
loss = CrossEntropy(out, target) + λ*aperture
grad = loss.backward() # 梯度穿透 CNN + 衍射層
opt.step()所有參數(CNN、衍射層、MoE)聯合更新,一次收斂;收斂後,把 aperture 固化成 3 個離散檔位:
- Gundam(光圈 1.0) → 高保真,用於代碼/公式;
- Small(0.1) → 日常對話;
- Tiny(0.02) → 極長記憶倉庫。
3.4.3. 推理引擎:0 浮點權重、0 KV-cache

- 無傳統 KV-cache,顯存佔用 = 128×dim×layer = 常數(8 層 1024 dim ≈ 32 MB);
- 若命中 vis-w(LoRA),直接把 128 vw 當「衍射權重」喂入 Attention,不需要下發浮點 ΔW;
- 若 cache miss,從磁盤讀取 png→衍射層→vw,耗時 < 1 ms;
- 整個推理過程 batch-size 可線性放大,無長序列爆炸。
3.4.4. 一句話收束
Optix-Memory Stack 讓「上下文長度」「權重大小」「對話輪數」這三個曾經各自膨脹的維度,全部坍縮成一張 1024×1024 的灰度圖;自此,LLM 的記憶問題被轉譯成可調光圈、可衍射、可遺忘的光學系統——不再問“能裝多少 token”,而只需問“想保留多少像素”。
當然,再次強調,整個 Section 3 都是一些思維實驗上的探索,時間短,可能有很多考慮不周甚至錯誤的想法。
4. 更多的問題
-
視覺 token 拼接上限
- 目標:測 Nvisual 對回答質量和顯存的臨界點。
- 做法:固定總 Context ≈16 K token,逐步用視覺 token 替換文本 token;比較 OpenBook QA / 對話跟蹤指標。
-
“增量壓縮”記憶曲線
- 目標:驗證多分辨率壓縮是否優於一次性丟棄。
- 做法:對同一段歷史上下文,分別做 {1×, 5×, 10×, 20×} 壓縮序列;讓模型在之後若干輪隨機提問細節,測回答精度隨時間衰減。
-
Expert-Type 自發現
- 目標:驗證佈局類別 ↔ MoE-routing 的自動對齊。
- 做法:初始化 8-expert ViT-Decoder,不加任何人工 rule,讓 Router 根據 token route;監控每個 expert 的激活類型(公式 / 表格 / 純文本 / 圖像)聚類情況。
其他開放問題:
- “視覺 token + 語言 token”混合序列的 Positional Encoding 如何共享?
- 在線場景下,DeepEncoder 的前向成本如何做到 <1× GPT-3.5 token 生成?
- 當需要修改或刪除歷史記憶時,如何級聯地更新 hash / 索引,使得“可遺忘性”符合法規要求(GDPR right-to-be-forgotten)?
- 視覺壓縮對於多語言(尤其非拉丁字母、豎排文本)是否有偏置?需要 language-aware screen renderer 嗎?
- ……
5. 總結
DeepSeek ORC 讓我們再一次有機會審視信息的表徵與計算的邊界。
或許未來,評價一個模型的記憶能力,我們不再問“它能容納多少 Token”,而是問:“在一張代表着記憶的底片上,我們應該選擇保留多少像素?”
參考資料
[1]
《DeepSeek-OCR: Contexts Optical Compression》: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
[2]
著名的由 MetaAI 提出的 Segment Anything(SAM): https://segment-anything.com/












