









現在的量化交易早就不是簡單的技術指標了。真正有效的交易系統需要像一個完整的投資團隊一樣工作——有專門的分析師收集各種數據,有研究員進行深度分析和辯論,有交易員制定具體策略,還有風險管理團隊把關。問題是傳統的程序很難模擬這種複雜的協作流程。
LangGraph的多智能體架構正好解決了這個問題。我們可以構建一個像真實投資公司一樣運作的系統,每個智能體負責特定的職能,它們之間可以進行辯論、協商,最終形成完整的投資決策鏈條。
整個系統的工作流程是這樣的:
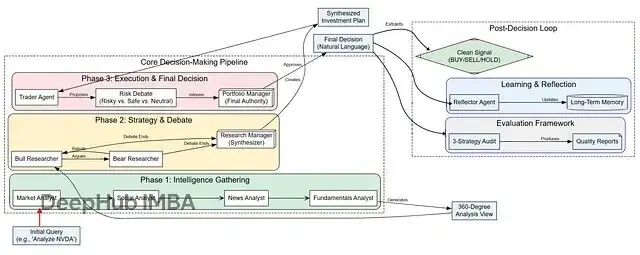
首先是數據收集階段,專門的分析師智能體會從各個維度收集市場情報,包括技術指標、新聞資訊、社交媒體情緒、公司基本面等等。然後多頭和空頭智能體會針對這些數據進行對抗性辯論,這個過程很關鍵,能夠暴露出投資邏輯中的漏洞。研究經理會綜合雙方觀點,形成最終的投資策略。
接下來交易員智能體會把策略轉化為具體的執行方案,包括進場時機、倉位大小、止損設置等細節。這個方案還要經過風險管理團隊的多重審核——激進派、保守派、中性派三個角色會從不同角度評估風險。最後由投資組合經理做出最終決策,系統會自動提取可執行的交易信號。
整個過程還有學習能力,每次交易結束後,各個智能體都會反思這次決策的得失,把經驗存儲到長期記憶中,用於優化後續的決策。
我們來看看具體怎麼實現。
環境準備和基礎配置
做多智能體系統,觀測性非常重要。LangSmith的追蹤功能可以讓我們清楚地看到每個智能體的決策過程,這對於調試和優化系統來説是必需的。
# 首先,確保你已經安裝了必要的庫
# !pip install -U langchain langgraph langchain_openai tavily-python yfinance finnhub-python stockstats beautifulsoup4 chromadb rich
import os
from getpass import getpass
# 定義一個輔助函數來安全地設置環境變量
def _set_env(var: str):
# 如果環境變量尚未設置,提示用户輸入
if not os.environ.get(var):
os.environ[var] = getpass(f"Enter your {var}: ")
# 為我們將使用的服務設置API密鑰
_set_env("OPENAI_API_KEY")
_set_env("FINNHUB_API_KEY")
_set_env("TAVILY_API_KEY")
_set_env("LANGSMITH_API_KEY")
# 啓用LangSmith追蹤以完全觀察我們的智能體系統
os.environ["LANGSMITH_TRACING"] = "true"
# 為LangSmith定義項目名稱以組織追蹤
os.environ["LANGSMITH_PROJECT"] = "Deep-Trading-System"這裏用到了幾個關鍵的API服務:OpenAI負責運行LLM(當然你也可以用其他開源模型),Finnhub提供實時股市數據,Tavily負責網絡搜索和新聞抓取,LangSmith做系統監控。
系統的核心是一個配置字典,這相當於整個系統的控制面板:
from pprint import pprint
# 為這個notebook運行定義我們的中央配置
config = {
"results_dir": "./results",
# LLM設置指定用於不同認知任務的模型
"llm_provider": "openai",
"deep_think_llm": "gpt-4o", # 用於複雜推理和最終決策的強大模型
"quick_think_llm": "gpt-4o-mini", # 用於數據處理和初始分析的快速、便宜模型
"backend_url": "https://api.openai.com/v1",
# 辯論和討論設置控制協作智能體的流程
"max_debate_rounds": 2, # 多頭vs空頭辯論將有2輪
"max_risk_discuss_rounds": 1, # 風險團隊有1輪辯論
"max_recur_limit": 100, # 智能體循環的安全限制
# 工具設置控制數據獲取行為
"online_tools": True, # 使用實時API;設置為False以使用緩存數據進行更快、更便宜的運行
"data_cache_dir": "./data_cache" # 緩存在線數據的目錄
}
# 如果緩存目錄不存在則創建它
os.makedirs(config["data_cache_dir"], exist_ok=True)
print("Configuration dictionary created:")
pprint(config)這個配置裏有個比較巧妙的設計:用兩套不同的模型。gpt-4o用來處理複雜推理和關鍵決策,gpt-4o-mini用來做數據處理這些相對簡單的任務。這樣既保證了決策質量,又控制了成本。
另外幾個參數也很重要:max_debate_rounds控制多空雙方辯論的輪數,max_risk_discuss_rounds決定風險團隊討論的深度,online_tools開關可以讓我們在實時數據和緩存數據之間切換。
from langchain_openai import ChatOpenAI
# 初始化用於高風險推理任務的強大LLM
deep_thinking_llm = ChatOpenAI(
model=config["deep_think_llm"],
base_url=config["backend_url"],
temperature=0.1
)
# 初始化用於常規數據處理的更快、更經濟的LLM
quick_thinking_llm = ChatOpenAI(
model=config["quick_think_llm"],
base_url=config["backend_url"],
temperature=0.1
)注意這裏的temperature設為0.1,這是因為金融分析需要的是穩定、可重複的輸出,而不是太多創造性。
系統狀態設計
整個多智能體系統的核心是一個共享的狀態管理機制。這就像是所有智能體共享的工作台,每個智能體都可以從中讀取信息,也可以把自己的分析結果寫入其中。

在LangGraph中,這個狀態會在所有節點之間傳遞,記錄着整個決策過程的完整信息流。我們用Python的TypedDict來定義數據結構,確保類型安全。
from typing import Annotated, Sequence, List
from typing_extensions import TypedDict
from langgraph.graph import MessagesState
# 研究團隊辯論的狀態,作為專用記事本
class InvestDebateState(TypedDict):
bull_history: str # 存儲多頭智能體的論據
bear_history: str # 存儲空頭智能體的論據
history: str # 辯論的完整記錄
current_response: str # 最近的論據
judge_decision: str # 經理的最終決定
count: int # 追蹤辯論輪數的計數器
# 風險管理團隊辯論的狀態
class RiskDebateState(TypedDict):
risky_history: str # 激進風險承擔者的歷史
safe_history: str # 保守智能體的歷史
neutral_history: str # 平衡智能體的歷史
history: str # 風險討論的完整記錄
latest_speaker: str # 追蹤最後發言的智能體
current_risky_response: str
current_safe_response: str
current_neutral_response: str
judge_decision: str # 投資組合經理的最終決定
count: int # 風險討論輪數的計數器這種設計的好處是把不同的辯論過程隔離開來,避免相互干擾。history字段會記錄完整的辯論過程,count參數幫助系統判斷什麼時候該結束辯論。
# 將通過整個圖傳遞的主要狀態
# 它從MessagesState繼承,包含聊天曆史的'messages'字段
class AgentState(MessagesState):
company_of_interest: str # 我們正在分析的股票代碼
trade_date: str # 分析的日期
sender: str # 追蹤哪個智能體最後修改了狀態
# 每個分析師將填充其自己的報告字段
market_report: str
sentiment_report: str
news_report: str
fundamentals_report: str
# 辯論的嵌套狀態
investment_debate_state: InvestDebateState
investment_plan: str # 來自研究經理的計劃
trader_investment_plan: str # 來自交易員的可執行計劃
risk_debate_state: RiskDebateState
final_trade_decision: str # 來自投資組合經理的最終決定主狀態AgentState包含了所有必要的信息:各個分析師的報告、辯論過程、投資計劃、最終決策等等。這樣設計可以清楚地追蹤信息從原始數據到最終交易信號的完整流程。
構建數據獲取工具集
智能體系統的能力很大程度上取決於它們能夠獲取什麼樣的數據。我們需要構建一套完整的工具,讓智能體能夠獲取股價數據、技術指標、新聞資訊、社交媒體情緒等各種信息。
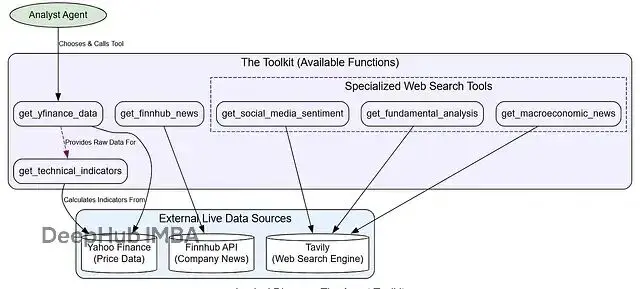
每個工具都用@tool裝飾器包裝,並且提供清晰的類型註解,這樣LLM就能理解每個工具的用途和參數。
import yfinance as yf
from langchain_core.tools import tool
@tool
def get_yfinance_data(
symbol: Annotated[str, "公司的股票代碼"],
start_date: Annotated[str, "yyyy-mm-dd格式的開始日期"],
end_date: Annotated[str, "yyyy-mm-dd格式的結束日期"],
) -> str:
"""從Yahoo Finance檢索給定股票代碼的股價數據。"""
try:
ticker = yf.Ticker(symbol.upper())
data = ticker.history(start=start_date, end=end_date)
if data.empty:
return f"No data found for symbol '{symbol}' between {start_date} and {end_date}"
return data.to_csv()
except Exception as e:
return f"Error fetching Yahoo Finance data: {e}"這裏有個小細節:我們返回CSV格式的數據,因為LLM對這種格式的解析能力很強。
技術指標的計算用stockstats庫:
from stockstats import wrap as stockstats_wrap
@tool
def get_technical_indicators(
symbol: Annotated[str, "公司的股票代碼"],
start_date: Annotated[str, "yyyy-mm-dd格式的開始日期"],
end_date: Annotated[str, "yyyy-mm-dd格式的結束日期"],
) -> str:
"""使用stockstats庫檢索股票的關鍵技術指標。"""
try:
df = yf.download(symbol, start=start_date, end=end_date, progress=False)
if df.empty:
return "No data to calculate indicators."
stock_df = stockstats_wrap(df)
indicators = stock_df[['macd', 'rsi_14', 'boll', 'boll_ub', 'boll_lb', 'close_50_sma', 'close_200_sma']]
return indicators.tail().to_csv()
except Exception as e:
return f"Error calculating stockstats indicators: {e}"注意我們只返回最新的幾行數據,這是為了控制傳給LLM的信息量,避免不必要的token消耗。
新聞數據來自Finnhub:
import finnhub
@tool
def get_finnhub_news(ticker: str, start_date: str, end_date: str) -> str:
"""從Finnhub獲取日期範圍內的公司新聞。"""
try:
finnhub_client = finnhub.Client(api_key=os.environ["FINNHUB_API_KEY"])
news_list = finnhub_client.company_news(ticker, _from=start_date, to=end_date)
news_items = []
for news in news_list[:5]: # 限制為5個結果
news_items.append(f"Headline: {news['headline']}\nSummary: {news['summary']}")
return "\n\n".join(news_items) if news_items else "No Finnhub news found."
except Exception as e:
return f"Error fetching Finnhub news: {e}"對於更廣泛的網絡搜索,我們用Tavily:
from langchain_community.tools.tavily_search import TavilySearchResults
# 初始化Tavily搜索工具一次。我們可以為多個專用工具重用這個實例
tavily_tool = TavilySearchResults(max_results=3)
@tool
def get_social_media_sentiment(ticker: str, trade_date: str) -> str:
"""對股票的社交媒體情緒進行實時網絡搜索。"""
query = f"social media sentiment and discussions for {ticker} stock around {trade_date}"
return tavily_tool.invoke({"query": query})
@tool
def get_fundamental_analysis(ticker: str, trade_date: str) -> str:
"""對股票的最近基本面分析進行實時網絡搜索。"""
query = f"fundamental analysis and key financial metrics for {ticker} stock published around {trade_date}"
return tavily_tool.invoke({"query": query})
@tool
def get_macroeconomic_news(trade_date: str) -> str:
"""對與股市相關的宏觀經濟新聞進行實時網絡搜索。"""
query = f"macroeconomic news and market trends affecting the stock market on {trade_date}"
return tavily_tool.invoke({"query": query})雖然這些工具都用的是同一個Tavily引擎,但我們給每個工具設定了不同的查詢焦點,這樣LLM能更準確地選擇合適的工具。
最後把所有工具包裝到一個類裏:
# 工具包類將所有定義的工具聚合到一個方便的對象中
class Toolkit:
def __init__(self, config):
self.config = config
self.get_yfinance_data = get_yfinance_data
self.get_technical_indicators = get_technical_indicators
self.get_finnhub_news = get_finnhub_news
self.get_social_media_sentiment = get_social_media_sentiment
self.get_fundamental_analysis = get_fundamental_analysis
self.get_macroeconomic_news = get_macroeconomic_news
# 實例化工具包,使所有工具通過這個單一對象可用
toolkit = Toolkit(config)
print(f"Toolkit class defined and instantiated with live data tools.")這樣我們就有了一套完整的數據獲取能力,可以從多個維度收集市場信息。
實現長期記憶系統:智能體的學習與適應機制
在金融市場的複雜環境中,過往經驗往往是未來決策的重要指引。我們的多智能體系統需要具備學習和記憶能力,從歷史操作中積累經驗,在相似情況下應用過往的成功策略。
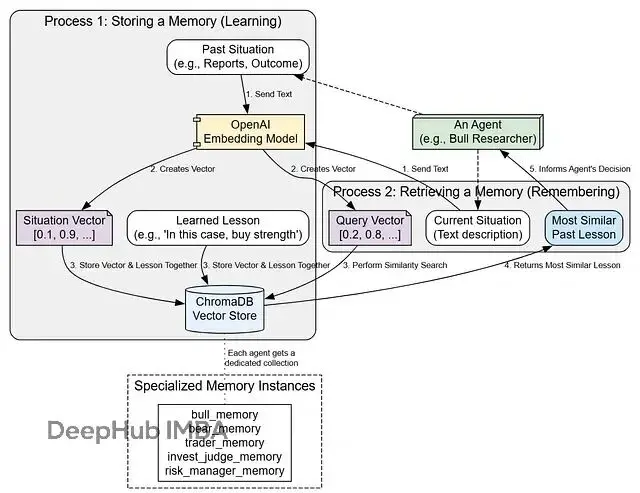
ChromaDB向量庫
我們使用ChromaDB實現一個基於向量嵌入的記憶系統,它能夠將情境和對應的經驗教訓存儲在高維向量空間中,通過語義相似性檢索相關的歷史經驗:
import chromadb
from openai import OpenAI
class FinancialSituationMemory:
"""
基於ChromaDB的金融情況記憶系統
用於存儲和檢索智能體在特定情境下的經驗教訓
"""
def __init__(self, collection_name, config):
# 初始化ChromaDB客户端和OpenAI客户端
self.client = chromadb.Client()
self.openai_client = OpenAI(api_key=config["OPENAI_API_KEY"])
# 為每個智能體創建獨立的記憶集合
self.situation_collection = self.client.get_or_create_collection(
name=collection_name
)
def get_embedding(self, text):
"""使用OpenAI API生成文本嵌入向量"""
response = self.openai_client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
def add_situations(self, situations_and_advice):
"""向記憶中添加新情況和建議"""
if not situations_and_advice:
return
# 偏移確保唯一ID(以防稍後添加新數據)
offset = self.situation_collection.count()
ids = [str(offset + i) for i, _ in enumerate(situations_and_advice)]
# 分離情況及其對應的建議
situations = [s for s, r in situations_and_advice]
recommendations = [r for s, r in situations_and_advice]
# 為所有情況生成嵌入
embeddings = [self.get_embedding(s) for s in situations]
# 將所有內容存儲在Chroma(向量數據庫)中
self.situation_collection.add(
documents=situations,
metadatas=[{"recommendation": rec} for rec in recommendations],
embeddings=embeddings,
ids=ids,
)
def get_memories(self, current_situation, n_matches=1):
"""為給定查詢檢索最相似的過去情況"""
if self.situation_collection.count() == 0:
return []
# 嵌入新的/當前情況
query_embedding = self.get_embedding(current_situation)
# 查詢集合中的相似嵌入
results = self.situation_collection.query(
query_embeddings=[query_embedding],
n_results=min(n_matches, self.situation_collection.count()),
include=["metadatas"], # 僅返回建議
)
# 從匹配中返回提取的建議
return [{'recommendation': meta['recommendation']} for meta in results['metadatas'][0]]記憶系統的設計理念
這個記憶系統的設計體現了幾個重要原則:
- 專門化記憶空間:每個智能體擁有獨立的記憶集合,確保不同角色的智能體能夠積累與其職責相關的專業經驗。
- 語義檢索機制:通過向量嵌入和相似性搜索,系統能夠找到語義上相關的歷史情況,而不僅僅是關鍵詞匹配。
- 經驗-教訓關聯:每個記憶條目都包含情境描述和對應的經驗教訓,為智能體提供完整的學習上下文。
現在讓我們為每個學習型智能體創建專用的記憶實例:
# 為每個學習的智能體創建專用記憶實例
bull_memory = FinancialSituationMemory("bull_memory", config)
bear_memory = FinancialSituationMemory("bear_memory", config)
trader_memory = FinancialSituationMemory("trader_memory", config)
invest_judge_memory = FinancialSituationMemory("invest_judge_memory", config)
risk_manager_memory = FinancialSituationMemory("risk_manager_memory", config)這種專業化的記憶分配確保了每個智能體都能積累與其特定職責相關的經驗。例如,多頭分析師學到的經驗(如"在強勁上升趨勢中,估值擔憂相對不那麼重要")可能與風險管理師的保守策略形成鮮明對比,兩者都需要在各自的決策語境中保持獨立性。
分析師團隊:360度市場情報收集系統
基礎設施搭建完成後,我們現在要構建系統的第一個核心組件——分析師團隊。這個團隊擔負着情報收集的重任,為後續的戰略決策提供全方位的市場洞察。
分析師角色設計理念
在現代金融決策中,單一維度的分析往往無法應對市場的複雜性。因此,我們設計了四個專業化的分析師角色,每個都專注於特定的信息領域:
- 市場分析師:專注於技術分析和價格行為模式
- 社交媒體分析師:捕捉公眾情緒和社交網絡討論
- 新聞分析師:分析公司特定和宏觀經濟新聞
- 基本面分析師:研究公司財務健康狀況和內在價值
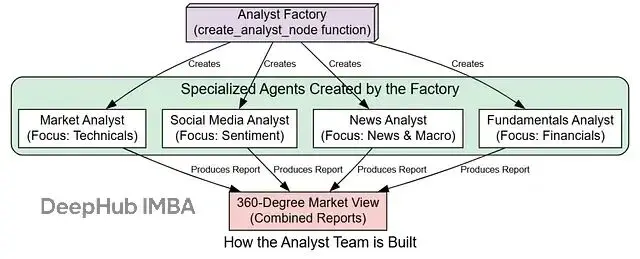
分析師工廠函數設計
為了避免代碼重複並確保一致性,我們採用工廠模式創建分析師節點。這種設計模式允許我們從通用模板生成具有特定能力的智能體:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 這個函數是一個工廠,為特定類型的分析師創建LangGraph節點
def create_analyst_node(llm, toolkit, system_message, tools, output_field):
"""
為分析師智能體創建節點
參數:
llm: 智能體使用的語言模型實例
toolkit: 智能體可用的工具集合
system_message: 定義智能體角色和目標的具體指令
tools: 此智能體被允許使用的工具包中特定工具的列表
output_field: AgentState中存儲此智能體最終報告的鍵
"""
# 為分析師智能體定義提示模板
prompt = ChatPromptTemplate.from_messages([
("system",
"You are a helpful AI assistant, collaborating with other assistants."
" Use the provided tools to progress towards answering the question."
" If you are unable to fully answer, that's OK; another assistant with different tools"
" will help where you left off. Execute what you can to make progress."
" You have access to the following tools: {tool_names}.\n{system_message}"
" For your reference, the current date is {current_date}. The company we want to look at is {ticker}"),
# MessagesPlaceholder允許我們傳入對話歷史
MessagesPlaceholder(variable_name="messages"),
])
# 用這個分析師的特定系統消息和工具名稱部分填充提示
prompt = prompt.partial(system_message=system_message)
prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))
# 將指定的工具綁定到LLM。這告訴LLM它可以調用哪些函數
chain = prompt | llm.bind_tools(tools)
# 這是將作為圖中節點執行的實際函數
def analyst_node(state):
# 用當前狀態的數據填充提示的最後部分
prompt_with_data = prompt.partial(current_date=state["trade_date"], ticker=state["company_of_interest"])
# 用狀態中的當前消息調用鏈
result = prompt_with_data.invoke(state["messages"])
report = ""
# 如果LLM沒有調用工具,意味着它已經生成了最終報告
if not result.tool_calls:
report = result.content
# 返回LLM的響應和最終報告以更新狀態
return {"messages": [result], output_field: report}
return analyst_node專業化分析師實現
基於工廠函數,我們現在可以創建四個專業化的分析師:
1、市場分析師
負責技術分析和價格行為研究:
# 市場分析師:專注於技術指標和價格行動
market_analyst_system_message = """你是專門分析金融市場的交易助手。你的角色是選擇最相關的技術指標來分析股票的價格行為、動量和波動性。你必須使用你的工具獲取歷史數據,然後生成包含你的發現的報告,包括彙總表。"""
market_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
market_analyst_system_message,
[toolkit.get_yfinance_data, toolkit.get_technical_indicators],
"market_report"
)2、社交媒體分析師
專注於情緒分析和公眾討論監控:
# 社交媒體分析師:衡量公眾情緒
social_analyst_system_message = """你是社交媒體分析師。你的工作是分析過去一週特定公司的社交媒體帖子和公眾情緒。使用你的工具找到相關討論,並撰寫詳細分析報告,包括對交易者的見解和影響,以及彙總表。"""
social_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
social_analyst_system_message,
[toolkit.get_social_media_sentiment],
"sentiment_report"
)3、新聞分析師
涵蓋公司特定和宏觀經濟新聞分析:
# 新聞分析師:涵蓋公司特定和宏觀經濟新聞
news_analyst_system_message = """你是分析過去一週最新新聞和趨勢的新聞研究員。撰寫關於當前世界狀態的綜合報告,重點關注與交易和宏觀經濟相關的內容。使用你的工具進行全面分析,並提供詳細分析,包括彙總表。"""
news_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
news_analyst_system_message,
[toolkit.get_finnhub_news, toolkit.get_macroeconomic_news],
"news_report"
)4、基本面分析師
深入研究公司財務健康狀況:
# 基本面分析師:深入研究公司的財務健康狀況
fundamentals_analyst_system_message = """你是分析公司基本面信息的研究員。撰寫關於公司財務狀況、內部人員情緒和交易的綜合報告,以全面瞭解其基本面健康狀況,包括彙總表。"""
fundamentals_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
fundamentals_analyst_system_message,
[toolkit.get_fundamental_analysis],
"fundamentals_report"
)ReAct模式:推理與行動的循環
這些分析師智能體採用ReAct(推理和行動)模式工作,這不是簡單的一次性LLM調用,而是一個動態的推理-執行循環:
- 思考:分析當前任務和可用信息
- 行動:調用相應的工具獲取數據
- 觀察:分析工具返回的結果
- 推理:基於新信息調整策略
- 重複:直到完成分析任務
這種模式使每個分析師都能夠自主地收集信息、分析數據,並生成專業的分析報告,為後續的投資決策提供堅實的信息基礎。
構建多頭vs空頭研究團隊:對抗性分析機制
數據收集完成後,我們面臨一個關鍵挑戰:如何處理潛在衝突的信息。在比如説,技術面、情緒面、新聞面都顯示強烈的看漲信號,但基本面分析師卻警告了"溢價估值"的風險,這是為什麼呢?
這正是對抗性研究團隊發揮作用的時刻。
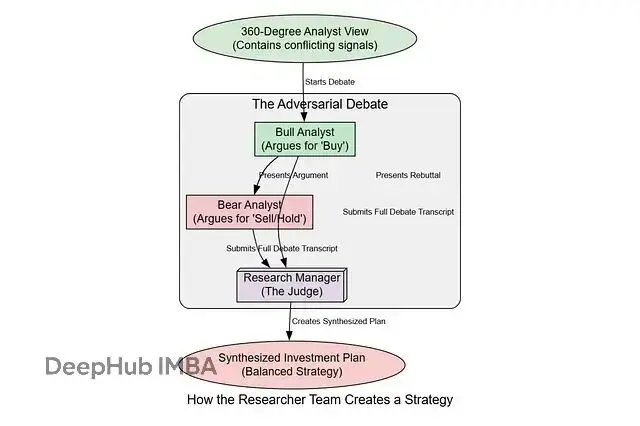
對抗性辯論的設計理念
在現實的投資決策中,最好的策略往往來自於充分的辯論和反思。通過構建多頭和空頭兩個對立觀點的智能體,我們能夠:
- 避免確認偏見:每個觀點都會受到對方的嚴格質疑
- 發現邏輯漏洞:對抗性思辨能揭示單一視角的盲點
- 壓力測試假設:通過辯論驗證投資論點的穩健性
- 綜合平衡觀點:最終形成考慮多方面因素的決策
研究員工廠函數設計
與分析師類似,我們使用工廠模式創建研究員節點,但這次加入了記憶檢索和辯論邏輯:
# 這個函數是一個工廠,為研究員智能體(多頭或空頭)創建LangGraph節點
def create_researcher_node(llm, memory, role_prompt, agent_name):
"""
為研究員智能體創建節點
參數:
llm: 智能體使用的語言模型實例
memory: 此智能體的長期記憶實例,用於從過去經驗中學習
role_prompt: 定義智能體角色(多頭或空頭)的特定系統提示
agent_name: 智能體的名稱,用於日誌記錄和識別論點
"""
def researcher_node(state):
# 首先,將所有分析師報告合併成單一摘要作為上下文
situation_summary = f"""
Market Report: {state['market_report']}
Sentiment Report: {state['sentiment_report']}
News Report: {state['news_report']}
Fundamentals Report: {state['fundamentals_report']}
"""
# 從過去相似情況中檢索相關記憶
past_memories = memory.get_memories(situation_summary)
past_memory_str = "\n".join([mem['recommendation'] for mem in past_memories])
# 為LLM構造完整提示
prompt = f"""{role_prompt}
這是當前分析的狀態:
{situation_summary}
對話歷史:{state['investment_debate_state']['history']}
你對手的最後論點:{state['investment_debate_state']['current_response']}
從類似過去情況中的反思:{past_memory_str or '沒有找到過去的記憶。'}
基於所有這些信息,以對話的方式提出你的論點。"""
# 調用LLM生成論點
response = llm.invoke(prompt)
argument = f"{agent_name}: {response.content}"
# 用新論點更新辯論狀態
debate_state = state['investment_debate_state'].copy()
debate_state['history'] += "\n" + argument
# 更新此智能體(多頭或空頭)的特定歷史
if agent_name == 'Bull Analyst':
debate_state['bull_history'] += "\n" + argument
else:
debate_state['bear_history'] += "\n" + argument
debate_state['current_response'] = argument
debate_state['count'] += 1
return {"investment_debate_state": debate_state}
return researcher_node多頭與空頭智能體創建
基於工廠函數,我們創建兩個具有對立觀點的研究員:
# 多頭的角色是樂觀的,專注於優勢和增長
bull_prompt = """你是多頭分析師。你的目標是論證應該投資這隻股票。專注於增長潛力、競爭優勢和報告中的積極指標。有效地反駁空頭的論點。在你的分析中要有邏輯性和説服力,但要承認任何重大風險,同時解釋為什麼機會超過這些風險。"""
# 空頭的角色是悲觀的,專注於風險和弱點
bear_prompt = """你是空頭分析師。你的目標是論證不應該投資這隻股票。專注於風險、挑戰和負面指標。有效地反駁多頭的論點。在你的分析中要有邏輯性和説服力,突出可能被多頭觀點忽視的關鍵風險因素。"""
# 使用我們的工廠函數創建可調用節點
bull_researcher_node = create_researcher_node(quick_thinking_llm, bull_memory, bull_prompt, "Bull Analyst")
bear_researcher_node = create_researcher_node(quick_thinking_llm, bear_memory, bear_prompt, "Bear Analyst")研究經理:辯論的仲裁者
辯論需要一個公正的仲裁者來綜合雙方觀點並形成最終決策。研究經理承擔這一重要角色:
def research_manager_node(state):
"""
研究經理審查整個辯論併產生最終的投資建議
這是一個複雜的推理任務,需要綜合多個觀點
"""
# 收集所有分析報告和辯論歷史
all_reports = f"""
市場報告:{state['market_report']}
情緒報告:{state['sentiment_report']}
新聞報告:{state['news_report']}
基本面報告:{state['fundamentals_report']}
"""
debate_history = state['investment_debate_state']['history']
# 從過去的決策中檢索相關經驗
situation_summary = all_reports + "\n" + debate_history
past_memories = invest_judge_memory.get_memories(situation_summary)
past_memory_str = "\n".join([mem['recommendation'] for mem in past_memories])
# 構建綜合分析提示
prompt = f"""你是資深投資研究經理。你的任務是審查分析師團隊的所有報告和多頭空頭研究員之間的辯論,然後做出最終的投資決定。
原始分析報告:
{all_reports}
研究團隊辯論:
{debate_history}
過去類似情況的經驗:
{past_memory_str or '沒有相關歷史經驗。'}
請提供一個全面的投資建議,包括:
1. 投資決定(買入/賣出/持有)及其理由
2. 關鍵風險因素和風險緩解策略
3. 建議的持倉規模和時間框架
4. 關鍵的監控指標
你的決定應該平衡所有觀點,承認不確定性,並提供清晰的行動計劃。"""
# 使用更強大的模型進行復雜推理
response = deep_thinking_llm.invoke(prompt)
# 更新投資辯論狀態,標記決定已做出
debate_state = state['investment_debate_state'].copy()
debate_state['judge_decision'] = response.content
return {
"investment_debate_state": debate_state,
"investment_analysis": response.content # 也單獨存儲以便訪問
}記憶學習機制
研究過程結束後,系統需要從這次決策中學習:
def store_investment_learnings(state):
"""
將本次投資決策的經驗存儲到各智能體的長期記憶中
"""
# 構建學習情境
situation = f"""
分析目標:{state['company_of_interest']}
日期:{state['trade_date']}
市場技術面:{state['market_report'][:200]}...
基本面狀況:{state['fundamentals_report'][:200]}...
"""
# 提取決策要點作為經驗教訓
final_decision = state['investment_debate_state']['judge_decision']
# 為不同智能體存儲相關經驗
bull_lesson = f"多頭觀點在此情況下的有效性:{final_decision[:300]}..."
bear_lesson = f"空頭觀點在此情況下的考慮因素:{final_decision[:300]}..."
judge_lesson = f"綜合決策邏輯:{final_decision}"
# 存儲到對應的記憶系統
bull_memory.add_situations([(situation, bull_lesson)])
bear_memory.add_situations([(situation, bear_lesson)])
invest_judge_memory.add_situations([(situation, judge_lesson)])
return state辯論工作流程設計
為了確保充分的討論,我們設計一個多輪辯論機制:
def should_continue_investment_debate(state):
"""決定是否繼續投資辯論"""
debate_count = state['investment_debate_state']['count']
# 確保至少進行2輪辯論,最多4輪
if debate_count < 2:
return "continue_debate"
elif debate_count >= 4:
return "end_debate"
else:
# 檢查辯論是否達到收斂
recent_args = state['investment_debate_state']['history'].split('\n')[-4:]
# 簡單啓發式:如果最近的論點開始重複,結束辯論
if len(set(recent_args)) < len(recent_args) * 0.7:
return "end_debate"
else:
return "continue_debate"
def route_investment_debate(state):
"""路由辯論到下一個發言者"""
count = state['investment_debate_state']['count']
# 交替進行:多頭開始,然後空頭,依此類推
if count % 2 == 0:
return "bull_researcher"
else:
return "bear_researcher"這個對抗性研究系統確保了投資決策不會被單一觀點所主導,而是經過充分辯論和多角度分析的深思熟慮的結果。通過記憶機制,系統還能從每次決策中學習,逐步提高決策質量。
交易執行與風險管理:多層決策驗證機制
完成投資策略分析後,我們進入系統的執行階段。這個階段包含兩個關鍵組件:將策略轉化為具體交易方案的交易員智能體,以及從多個風險偏好角度評估方案的風險管理團隊。
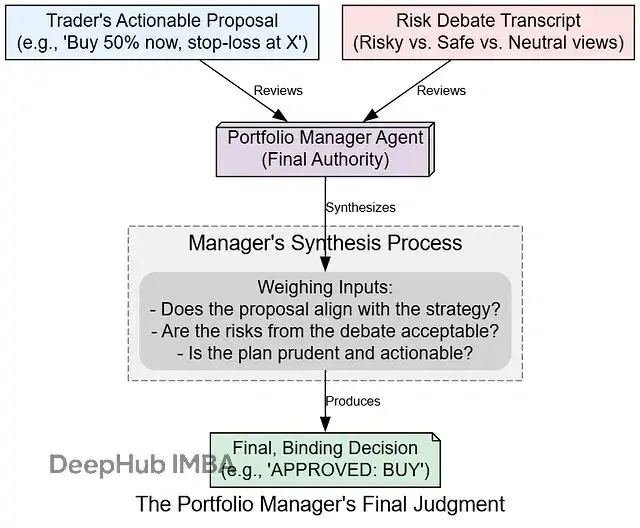
交易員智能體:策略到執行的轉換器
交易員的核心職責是將研究經理的宏觀投資策略轉化為具體的、可執行的交易指令。這個轉換過程需要考慮實際的市場條件、時機選擇和風險控制參數。
import functools
# 這個函數創建交易員智能體節點
def create_trader(llm, memory):
def trader_node(state, name):
# 從長期記憶中檢索相關的交易經驗
situation_summary = f"""
投資策略:{state['investment_analysis']}
市場環境:{state['market_report'][:200]}...
"""
past_memories = memory.get_memories(situation_summary)
past_memory_str = "\n".join([mem['recommendation'] for mem in past_memories])
# 提示很簡單:基於計劃創建提案
# 關鍵指令是強制性的最終標籤,便於後續解析
prompt = f"""你是交易智能體。基於提供的投資計劃,創建一個簡潔的交易提案。
你的迴應必須以'最終交易提案:**買入/持有/賣出**'結尾。
建議的投資計劃:{state['investment_analysis']}
過去類似情況的交易經驗:
{past_memory_str or '沒有相關歷史經驗。'}
請提供具體的:
1. 建議的倉位大小
2. 進場時機和條件
3. 止損和止盈設置
4. 風險控制措施
確保你的提案是實際可執行的,幷包含具體的數字參數。"""
result = llm.invoke(prompt)
# 輸出用交易員的計劃和發送者標識更新狀態
return {"trader_investment_plan": result.content, "sender": name}
return trader_node多角度風險管理辯論機制
風險管理不是單一視角的評估,而是多個具有不同風險偏好的智能體之間的結構化辯論。我們設計了三個角色:
- 激進型分析師:追求高回報,願意承擔更大風險
- 保守型分析師:優先考慮資本保護,偏好低風險策略
- 中性分析師:提供平衡視角,綜合考慮收益與風險
# 這個函數是創建風險辯論者節點的工廠
def create_risk_debator(llm, role_prompt, agent_name):
def risk_debator_node(state):
# 首先,從狀態中獲取其他兩個辯論者的論點
risk_state = state['risk_debate_state']
opponents_args = []
# 收集其他智能體的觀點用於反駁
if agent_name != 'Risky Analyst' and risk_state['current_risky_response']:
opponents_args.append(f"激進派觀點:{risk_state['current_risky_response']}")
if agent_name != 'Safe Analyst' and risk_state['current_safe_response']:
opponents_args.append(f"保守派觀點:{risk_state['current_safe_response']}")
if agent_name != 'Neutral Analyst' and risk_state['current_neutral_response']:
opponents_args.append(f"中性派觀點:{risk_state['current_neutral_response']}")
# 用交易員的計劃、辯論歷史和對手的論點構造提示
prompt = f"""{role_prompt}
這是交易員的計劃:{state['trader_investment_plan']}
辯論歷史:{risk_state['history']}
你的對手的最後論點:
{chr(10).join(opponents_args)}
從你的角度批評或支持這個計劃。要具體指出計劃中的優點和不足,並提出改進建議。"""
response = llm.invoke(prompt).content
# 用新論點更新風險辯論狀態
new_risk_state = risk_state.copy()
new_risk_state['history'] += f"\n{agent_name}: {response}"
new_risk_state['latest_speaker'] = agent_name
# 將響應存儲在此智能體的特定字段中
if agent_name == 'Risky Analyst':
new_risk_state['current_risky_response'] = response
elif agent_name == 'Safe Analyst':
new_risk_state['current_safe_response'] = response
else:
new_risk_state['current_neutral_response'] = response
new_risk_state['count'] += 1
return {"risk_debate_state": new_risk_state}
return risk_debator_node風險角色定義
三個風險智能體的角色定義體現了不同的投資哲學:
# 風險型角色主張最大化回報,即使這意味着更高的風險
risky_prompt = """你是激進型風險分析師。你主張高回報機會和大膽策略。你認為在明確的機會面前,保守是最大的風險。分析交易計劃時,重點關注:
- 是否充分利用了上漲潛力
- 倉位是否過於保守
- 是否錯過了時機窗口
但也要保持理性,不要盲目激進。"""
# 安全型角色優先考慮資本保護勝過一切
safe_prompt = """你是保守型風險分析師。你優先考慮資本保護和最小化波動性。你認為保住本金比追求高收益更重要。分析交易計劃時,重點關注:
- 下跌風險是否得到充分控制
- 止損設置是否合理
- 倉位大小是否過於激進
- 是否考慮了最壞情況的應對方案"""
# 中性角色提供平衡、客觀的觀點
neutral_prompt = """你是中性風險分析師。你提供平衡的視角,權衡收益和風險。你的目標是找到風險調整後回報的最優平衡點。分析交易計劃時,重點關注:
- 風險回報比是否合理
- 計劃是否考慮了多種市場情況
- 是否在機會和風險之間找到了合適的平衡
- 計劃的實際可執行性"""風險管理工作流程
# 創建交易員節點。我們使用functools.partial來預填'name'參數
trader_node_func = create_trader(quick_thinking_llm, trader_memory)
trader_node = functools.partial(trader_node_func, name="Trader")
# 使用特定提示創建三個風險辯論者節點
risky_node = create_risk_debator(quick_thinking_llm, risky_prompt, "Risky Analyst")
safe_node = create_risk_debator(quick_thinking_llm, safe_prompt, "Safe Analyst")
neutral_node = create_risk_debator(quick_thinking_llm, neutral_prompt, "Neutral Analyst")
def run_risk_management_debate(state, max_rounds=2):
"""運行風險管理辯論流程"""
risk_state = state
for round_num in range(max_rounds):
print(f"--- 風險管理辯論第 {round_num + 1} 輪 ---")
# 激進分析師先開始
risky_result = risky_node(risk_state)
risk_state['risk_debate_state'] = risky_result['risk_debate_state']
print(f"\n**激進分析師觀點:**")
print(risk_state['risk_debate_state']['current_risky_response'])
# 然後是保守分析師
safe_result = safe_node(risk_state)
risk_state['risk_debate_state'] = safe_result['risk_debate_state']
print(f"\n**保守分析師觀點:**")
print(risk_state['risk_debate_state']['current_safe_response'])
# 最後是中性分析師
neutral_result = neutral_node(risk_state)
risk_state['risk_debate_state'] = neutral_result['risk_debate_state']
print(f"\n**中性分析師觀點:**")
print(risk_state['risk_debate_state']['current_neutral_response'])
return risk_state投資組合經理:最終決策的權威
決策過程的最後一步由投資組合經理智能體負責。這個智能體充當公司的最高決策者,它審查交易員的計劃和整個風險辯論,然後發佈最終的、具有約束力的決策。
由於這是最關鍵的步驟,我們使用更強大的推理模型來確保最高質量的決策:
# 這個函數創建投資組合經理節點
def create_portfolio_manager(llm, memory):
def portfolio_manager_node(state):
# 收集完整的決策上下文
situation_summary = f"""
原始分析:{state.get('investment_analysis', '')}
交易員計劃:{state['trader_investment_plan']}
風險辯論:{state['risk_debate_state']['history']}
"""
# 從過去的決策中學習
past_memories = memory.get_memories(situation_summary)
past_memory_str = "\n".join([mem['recommendation'] for mem in past_memories])
# 提示要求基於所有先前工作做出最終、約束性決策
prompt = f"""作為投資組合經理,你的決策是最終的。審查交易員的計劃和風險辯論,
提供一個最終的、具有約束力的決策:買入、賣出或持有,以及簡要的理由。
交易員的計劃:
{state['trader_investment_plan']}
風險管理辯論:
{state['risk_debate_state']['history']}
過去類似決策的經驗:
{past_memory_str or '沒有相關歷史經驗。'}
請提供:
1. 明確的最終決策(買入/賣出/持有)
2. 決策理由和關鍵考慮因素
3. 批准的具體執行參數
4. 需要監控的關鍵風險指標
你的決策將直接影響公司的投資組合,請確保決策是深思熟慮和負責任的。"""
response = llm.invoke(prompt).content
# 輸出存儲在狀態的'final_trade_decision'字段中
return {"final_trade_decision": response}
return portfolio_manager_node
# 創建可調用的組合經理節點
portfolio_manager_node = create_portfolio_manager(deep_thinking_llm, risk_manager_memory)決策學習和記憶存儲
每次決策完成後,系統需要將這次經驗存儲到長期記憶中:
def store_trading_learnings(state):
"""將交易和風險管理的經驗存儲到長期記憶中"""
# 構建完整的決策情境
situation = f"""
標的:{state['company_of_interest']}
日期:{state['trade_date']}
市場狀況:{state['market_report'][:200]}...
交易計劃:{state['trader_investment_plan'][:200]}...
風險考慮:{state['risk_debate_state']['history'][:300]}...
"""
# 提取最終決策作為經驗教訓
final_decision = state['final_trade_decision']
# 為不同角色存儲相關經驗
trader_lesson = f"交易執行經驗:{final_decision[:300]}..."
risk_lesson = f"風險管理要點:{state['risk_debate_state']['history'][-200:]}..."
manager_lesson = f"組合管理決策:{final_decision}"
# 存儲到對應的記憶系統
trader_memory.add_situations([(situation, trader_lesson)])
risk_manager_memory.add_situations([(situation, manager_lesson)])
# 為風險辯論的各個角色也存儲經驗
if state['risk_debate_state']['current_risky_response']:
risk_memory = FinancialSituationMemory("risk_analyst_memory", config)
risk_memory.add_situations([(situation, f"激進派觀點效果:{final_decision[:200]}...")])
return state這個多層決策驗證機制確保了每個交易決策都經過充分的討論、質疑和驗證,從而最大程度地降低決策失誤的風險,同時通過記憶機制不斷積累和優化決策質量。
LangGraph工作流程整合:智能體協調的藝術
我們已經構建了完整的智能體生態系統,現在需要通過LangGraph將它們有機地整合成一個協調的工作流程。LangGraph的狀態圖架構能夠優雅地處理複雜的多智能體交互和條件分支。
工作流程架構設計
我們的完整工作流程可以分為幾個主要階段:
- 數據收集階段:四個分析師並行工作
- 策略研究階段:多頭空頭辯論和綜合分析
- 執行計劃階段:交易員制定具體方案
- 風險評估階段:多角度風險辯論
- 最終決策階段:投資組合經理做出約束性決定
- 信號提取和學習:反思和經驗存儲
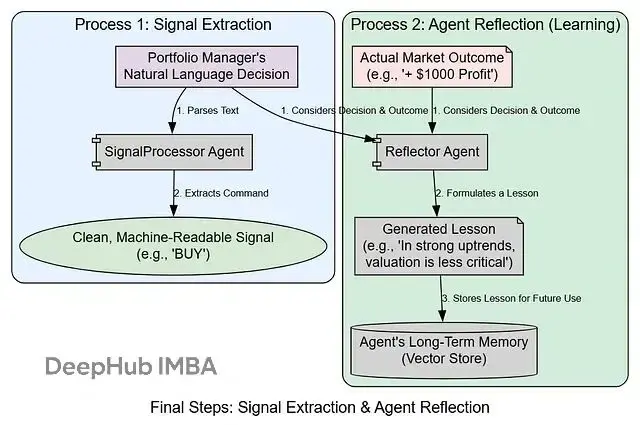
核心工作流程實現
from langgraph.graph import StateGraph, START, END
from typing import Literal
def create_trading_workflow():
"""創建完整的交易決策工作流程"""
# 初始化狀態圖
workflow = StateGraph(AgentState)
# 添加分析師節點(並行執行)
workflow.add_node("market_analyst", market_analyst_node)
workflow.add_node("social_analyst", social_analyst_node)
workflow.add_node("news_analyst", news_analyst_node)
workflow.add_node("fundamentals_analyst", fundamentals_analyst_node)
# 添加研究團隊節點
workflow.add_node("bull_researcher", bull_researcher_node)
workflow.add_node("bear_researcher", bear_researcher_node)
workflow.add_node("research_manager", research_manager_node)
# 添加交易和風險管理節點
workflow.add_node("trader", trader_node)
workflow.add_node("risky_analyst", risky_node)
workflow.add_node("safe_analyst", safe_node)
workflow.add_node("neutral_analyst", neutral_node)
workflow.add_node("portfolio_manager", portfolio_manager_node)
# 添加學習和信號處理節點
workflow.add_node("signal_processor", signal_processor_node)
workflow.add_node("reflection_learner", reflection_learner_node)
# 定義工作流程連接
workflow.add_edge(START, "market_analyst")
workflow.add_edge(START, "social_analyst")
workflow.add_edge(START, "news_analyst")
workflow.add_edge(START, "fundamentals_analyst")
# 所有分析師完成後進入研究階段
workflow.add_edge("market_analyst", "investment_debate_router")
workflow.add_edge("social_analyst", "investment_debate_router")
workflow.add_edge("news_analyst", "investment_debate_router")
workflow.add_edge("fundamentals_analyst", "investment_debate_router")
return workflow
# 條件路由函數
def investment_debate_router(state) -> Literal["bull_researcher", "research_manager"]:
"""路由投資辯論流程"""
debate_count = state['investment_debate_state']['count']
if debate_count == 0:
return "bull_researcher" # 多頭先開始
elif debate_count < 4: # 最多4輪辯論
if debate_count % 2 == 1:
return "bear_researcher" # 空頭回應
else:
return "bull_researcher" # 多頭繼續
else:
return "research_manager" # 結束辯論,進入決策
def risk_debate_router(state) -> Literal["risky_analyst", "safe_analyst", "neutral_analyst", "portfolio_manager"]:
"""路由風險管理辯論"""
risk_count = state['risk_debate_state']['count']
if risk_count >= 9: # 每個角色最多3輪
return "portfolio_manager"
# 循環順序:激進->保守->中性
order = risk_count % 3
if order == 0:
return "risky_analyst"
elif order == 1:
return "safe_analyst"
else:
return "neutral_analyst"信號處理和學習機制
交易決策完成後,系統需要提取可執行信號並進行學習:
class SignalProcessor:
"""負責將最終LLM輸出解析為清晰、機器可讀的信號"""
def __init__(self, llm):
self.llm = llm
def process_signal(self, full_signal: str) -> str:
"""從決策文本中提取BUY/SELL/HOLD信號"""
messages = [
("system", "你是一個助手,設計用於從金融報告中提取最終投資決策:賣出、買入或持有。只回應單詞決策。"),
("human", full_signal),
]
result = self.llm.invoke(messages).content.strip().upper()
# 基本驗證以確保輸出是三個預期信號之一
if result in ["BUY", "SELL", "HOLD", "買入", "賣出", "持有"]:
# 標準化為英文
signal_map = {"買入": "BUY", "賣出": "SELL", "持有": "HOLD"}
return signal_map.get(result, result)
return "ERROR_UNPARSABLE_SIGNAL"
def signal_processor_node(state):
"""信號處理節點"""
processor = SignalProcessor(quick_thinking_llm)
final_signal = processor.process_signal(state['final_trade_decision'])
return {"final_signal": final_signal}反思學習系統
class Reflector:
"""為智能體編排學習過程的類"""
def __init__(self, llm):
self.llm = llm
self.reflection_prompt = """你是專業的金融分析師。審查交易決策/分析、市場背景和財務結果。
- 首先,根據結果確定決策是否正確
- 分析導致成功或失敗的最關鍵因素
- 最後,制定一個簡潔的、一句話的經驗教訓或啓發式方法,可用於改善類似情況下的未來決策
市場背景和分析:{situation}
結果(盈利/虧損):{returns_losses}"""
def reflect(self, current_state, returns_losses, memory, component_key_func):
"""執行反思並存儲經驗教訓"""
situation = f"""報告:{current_state['market_report']} {current_state['sentiment_report']} {current_state['news_report']} {current_state['fundamentals_report']}
決策/分析文本:{component_key_func(current_state)}"""
prompt = self.reflection_prompt.format(
situation=situation,
returns_losses=returns_losses
)
result = self.llm.invoke(prompt).content
# 情況(上下文)和生成的經驗教訓存儲在智能體的記憶中
memory.add_situations([(situation, result)])
def reflection_learner_node(state):
"""反思學習節點,模擬假設性結果進行學習"""
reflector = Reflector(quick_thinking_llm)
# 在實際應用中,這裏會是真實的交易結果
# 這裏我們模擬一個假設性的盈利結果
hypothetical_returns = 1000
# 為每個有記憶的智能體運行反思過程
reflector.reflect(
state, hypothetical_returns, bull_memory,
lambda s: s['investment_debate_state']['bull_history']
)
reflector.reflect(
state, hypothetical_returns, bear_memory,
lambda s: s['investment_debate_state']['bear_history']
)
reflector.reflect(
state, hypothetical_returns, trader_memory,
lambda s: s['trader_investment_plan']
)
reflector.reflect(
state, hypothetical_returns, risk_manager_memory,
lambda s: s['final_trade_decision']
)
return {"learning_completed": True}系統評估:多維度質量驗證機制
構建一個複雜的AI交易系統後,我們需要嚴格的評估機制來驗證其決策質量。我們設計了三種互補的評估策略,從不同角度審核系統性能。
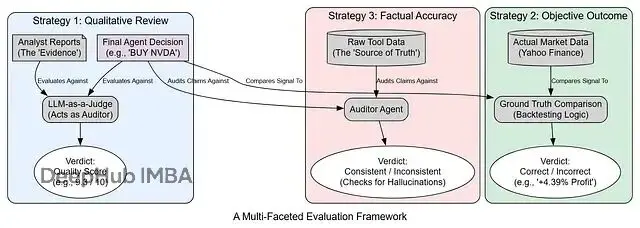
LLM-as-a-Judge:定性推理評估
使用強大的LLM作為公正的評判者,從多個維度評估決策質量:
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
class Evaluation(BaseModel):
"""評估結果的結構化模式"""
reasoning_quality: int = Field(description="推理連貫性和邏輯的1-10分評分")
evidence_based_score: int = Field(description="基於報告證據引用的1-10分評分")
actionability_score: int = Field(description="決策清晰度和可執行性的1-10分評分")
risk_assessment: int = Field(description="風險考慮充分性的1-10分評分")
justification: str = Field(description="分數的詳細理由")
# 創建評估提示模板
evaluator_prompt = ChatPromptTemplate.from_template("""
你是專業的金融審計員。請基於提供的"分析師報告"評估"最終交易決策"。
分析師報告:
{reports}
最終交易決策:
{final_decision}
請從以下維度進行評估:
1. 推理質量:邏輯是否清晰、連貫
2. 證據支撐:是否充分引用和利用了分析師報告
3. 可執行性:決策是否具體、明確、可操作
4. 風險評估:是否充分考慮了潛在風險
每個維度給出1-10分的評分,並提供詳細的評分理由。
""")
# 構建評估鏈
evaluator_chain = evaluator_prompt | deep_thinking_llm.with_structured_output(Evaluation)
def run_llm_evaluation(state):
"""執行LLM-as-a-Judge評估"""
# 構建分析師報告摘要
reports_summary = f"""
市場報告:{state['market_report']}
情緒報告:{state['sentiment_report']}
新聞報告:{state['news_report']}
基本面報告:{state['fundamentals_report']}
"""
eval_input = {
"reports": reports_summary,
"final_decision": state['final_trade_decision']
}
evaluation_result = evaluator_chain.invoke(eval_input)
print("----- LLM-as-a-Judge 評估報告 -----")
print(f"推理質量:{evaluation_result.reasoning_quality}/10")
print(f"證據支撐:{evaluation_result.evidence_based_score}/10")
print(f"可執行性:{evaluation_result.actionability_score}/10")
print(f"風險評估:{evaluation_result.risk_assessment}/10")
print(f"評估理由:{evaluation_result.justification}")
return evaluation_resultGround Truth比較:客觀性能驗證
通過比較智能體決策與實際市場表現來評估預測準確性:
import yfinance as yf
from datetime import datetime, timedelta
def evaluate_ground_truth(ticker, trade_date, signal, holding_period_days=5):
"""評估交易信號的實際市場表現"""
try:
# 解析交易日期並定義評估窗口
start_date = datetime.strptime(trade_date, "%Y-%m-%d").date()
end_date = start_date + timedelta(days=holding_period_days + 3) # 加3天緩衝
# 下載市場數據
data = yf.download(
ticker,
start=start_date.isoformat(),
end=end_date.isoformat(),
progress=False
)
if len(data) < holding_period_days:
return "數據不足,無法進行真實情況評估"
# 找到交易日對應的市場開盤價
trade_day_data = data[data.index.date >= start_date]
if len(trade_day_data) == 0:
return "交易日期無效或市場關閉"
open_price = trade_day_data['Open'].iloc[0]
# 獲取持有期結束後的收盤價
if len(trade_day_data) >= holding_period_days:
close_price = trade_day_data['Close'].iloc[holding_period_days - 1]
else:
close_price = trade_day_data['Close'].iloc[-1]
# 計算收益率
return_pct = ((close_price - open_price) / open_price) * 100
# 評估信號準確性
if signal == "BUY":
prediction_correct = return_pct > 0
expected_direction = "上漲"
elif signal == "SELL":
prediction_correct = return_pct < 0
expected_direction = "下跌"
else: # HOLD
prediction_correct = abs(return_pct) < 2 # 2%以內算持平
expected_direction = "持平"
result = {
"ticker": ticker,
"trade_date": trade_date,
"signal": signal,
"open_price": open_price,
"close_price": close_price,
"return_pct": return_pct,
"prediction_correct": prediction_correct,
"expected_direction": expected_direction,
"actual_direction": "上漲" if return_pct > 0 else "下跌" if return_pct < 0 else "持平"
}
return result
except Exception as e:
return f"Ground Truth評估錯誤:{str(e)}"
def run_ground_truth_evaluation(state):
"""執行Ground Truth評估"""
ticker = state['company_of_interest']
trade_date = state['trade_date']
signal = state.get('final_signal', 'UNKNOWN')
result = evaluate_ground_truth(ticker, trade_date, signal)
if isinstance(result, dict):
print("----- Ground Truth 評估報告 -----")
print(f"股票代碼:{result['ticker']}")
print(f"交易日期:{result['trade_date']}")
print(f"系統信號:{result['signal']} (預期{result['expected_direction']})")
print(f"實際表現:{result['return_pct']:.2f}% ({result['actual_direction']})")
print(f"預測準確性:{'✓ 正確' if result['prediction_correct'] else '✗ 錯誤'}")
# 計算絕對收益(假設$10,000投資)
investment = 10000
if signal == "BUY":
profit = investment * (result['return_pct'] / 100)
print(f"假設收益:${profit:.2f} (投資 ${investment:,})")
else:
print(f"Ground Truth評估失敗:{result}")
return result事實核查:信息準確性驗證
驗證系統使用的信息和數據的準確性:
def fact_check_analysis(state):
"""對分析報告進行事實核查"""
fact_check_results = {}
# 檢查技術指標的合理性
market_report = state['market_report']
if 'RSI' in market_report:
# 提取RSI值並檢查是否在合理範圍內(0-100)
import re
rsi_pattern = r'RSI.*?(\d+\.?\d*)'
rsi_match = re.search(rsi_pattern, market_report)
if rsi_match:
rsi_value = float(rsi_match.group(1))
fact_check_results['RSI_valid'] = 0 <= rsi_value <= 100
# 檢查新聞報告的時效性
news_report = state['news_report']
current_date = datetime.strptime(state['trade_date'], "%Y-%m-%d")
# 簡單的時效性檢查(在實際應用中,這裏會更復雜)
recent_keywords = ['本週', '最近', '今日', '昨日']
fact_check_results['news_timeliness'] = any(keyword in news_report for keyword in recent_keywords)
# 檢查基本面數據的合理性
fundamentals_report = state['fundamentals_report']
fact_check_results['fundamentals_coherence'] = len(fundamentals_report) > 100 # 基本長度檢查
# 檢查情緒分析的平衡性
sentiment_report = state['sentiment_report']
bullish_words = ['看漲', '積極', '樂觀', '買入', '上漲']
bearish_words = ['看跌', '消極', '悲觀', '賣出', '下跌']
bullish_count = sum(1 for word in bullish_words if word in sentiment_report)
bearish_count = sum(1 for word in bearish_words if word in sentiment_report)
fact_check_results['sentiment_balance'] = abs(bullish_count - bearish_count) <= 5
print("----- 事實核查報告 -----")
for check, result in fact_check_results.items():
status = "✓ 通過" if result else "✗ 存疑"
print(f"{check}: {status}")
return fact_check_results
def comprehensive_evaluation(state):
"""執行綜合評估"""
print("=" * 50)
print(" 系統綜合評估報告")
print("=" * 50)
# 1. LLM-as-a-Judge評估
llm_eval = run_llm_evaluation(state)
print("\n")
# 2. Ground Truth評估
gt_eval = run_ground_truth_evaluation(state)
print("\n")
# 3. 事實核查
fact_check = fact_check_analysis(state)
# 綜合評分
total_score = 0
max_score = 0
if hasattr(llm_eval, 'reasoning_quality'):
total_score += llm_eval.reasoning_quality + llm_eval.evidence_based_score + llm_eval.actionability_score
max_score += 30
if isinstance(gt_eval, dict) and gt_eval.get('prediction_correct'):
total_score += 10
max_score += 10
fact_checks_passed = sum(1 for result in fact_check.values() if result)
total_score += fact_checks_passed * 2
max_score += len(fact_check) * 2
final_score = (total_score / max_score) * 100 if max_score > 0 else 0
print(f"\n----- 綜合評估結果 -----")
print(f"系統綜合得分:{final_score:.1f}/100")
if final_score >= 80:
print("評級:優秀 - 系統表現卓越")
elif final_score >= 60:
print("評級:良好 - 系統表現令人滿意")
else:
print("評級:需要改進 - 系統需要進一步優化")
return {
"llm_evaluation": llm_eval,
"ground_truth": gt_eval,
"fact_check": fact_check,
"final_score": final_score
}這套多維度評估體系確保了我們能夠從不同角度全面評估系統的決策質量,為持續優化提供數據支撐。
系統部署與擴展:從概念到生產
完成了核心系統的構建和評估後,我們可以討論如何將這個多智能體交易系統擴展到生產環境,以及未來可能的改進方向。
完整的工作流程編排
將所有組件整合到最終的LangGraph工作流程中:
def create_complete_trading_system():
"""創建完整的交易決策系統"""
# 初始化狀態圖
workflow = StateGraph(AgentState)
# 數據收集階段(並行執行)
workflow.add_node("market_analyst", market_analyst_node)
workflow.add_node("social_analyst", social_analyst_node)
workflow.add_node("news_analyst", news_analyst_node)
workflow.add_node("fundamentals_analyst", fundamentals_analyst_node)
# 投資研究階段
workflow.add_node("bull_researcher", bull_researcher_node)
workflow.add_node("bear_researcher", bear_researcher_node)
workflow.add_node("research_manager", research_manager_node)
# 交易執行階段
workflow.add_node("trader", trader_node)
# 風險管理階段
workflow.add_node("risky_analyst", risky_node)
workflow.add_node("safe_analyst", safe_node)
workflow.add_node("neutral_analyst", neutral_node)
# 最終決策階段
workflow.add_node("portfolio_manager", portfolio_manager_node)
# 後處理階段
workflow.add_node("signal_processor", signal_processor_node)
workflow.add_node("evaluation", comprehensive_evaluation_node)
workflow.add_node("reflection_learner", reflection_learner_node)
# 定義邊和條件路由
workflow.add_edge(START, "market_analyst")
workflow.add_edge(START, "social_analyst")
workflow.add_edge(START, "news_analyst")
workflow.add_edge(START, "fundamentals_analyst")
# 分析師完成後的匯聚和路由
workflow.add_edge("market_analyst", "investment_debate_coordinator")
workflow.add_edge("social_analyst", "investment_debate_coordinator")
workflow.add_edge("news_analyst", "investment_debate_coordinator")
workflow.add_edge("fundamentals_analyst", "investment_debate_coordinator")
# 條件路由
workflow.add_conditional_edges(
"investment_debate_coordinator",
investment_debate_router,
{
"bull_researcher": "bull_researcher",
"bear_researcher": "bear_researcher",
"research_manager": "research_manager"
}
)
workflow.add_conditional_edges(
"bull_researcher",
lambda state: "bear_researcher" if state['investment_debate_state']['count'] < 4 else "research_manager"
)
workflow.add_conditional_edges(
"bear_researcher",
lambda state: "bull_researcher" if state['investment_debate_state']['count'] < 4 else "research_manager"
)
# 研究完成後進入交易階段
workflow.add_edge("research_manager", "trader")
# 風險管理辯論路由
workflow.add_conditional_edges(
"trader",
lambda state: "risky_analyst", # 交易員完成後開始風險辯論
)
workflow.add_conditional_edges(
"risky_analyst",
risk_debate_router,
{
"safe_analyst": "safe_analyst",
"neutral_analyst": "neutral_analyst",
"risky_analyst": "risky_analyst",
"portfolio_manager": "portfolio_manager"
}
)
workflow.add_conditional_edges(
"safe_analyst",
risk_debate_router,
{
"neutral_analyst": "neutral_analyst",
"risky_analyst": "risky_analyst",
"safe_analyst": "safe_analyst",
"portfolio_manager": "portfolio_manager"
}
)
workflow.add_conditional_edges(
"neutral_analyst",
risk_debate_router,
{
"risky_analyst": "risky_analyst",
"safe_analyst": "safe_analyst",
"neutral_analyst": "neutral_analyst",
"portfolio_manager": "portfolio_manager"
}
)
# 最終處理流程
workflow.add_edge("portfolio_manager", "signal_processor")
workflow.add_edge("signal_processor", "evaluation")
workflow.add_edge("evaluation", "reflection_learner")
workflow.add_edge("reflection_learner", END)
return workflow.compile()
# 運行完整系統
def run_trading_system(ticker: str, trade_date: str):
"""運行完整的交易決策系統"""
# 編譯工作流程
trading_system = create_complete_trading_system()
# 初始化狀態
initial_state = AgentState(
messages=[HumanMessage(content=f"分析 {ticker} 在 {trade_date} 的交易機會")],
company_of_interest=ticker,
trade_date=trade_date,
investment_debate_state=InvestDebateState({
'history': '', 'current_response': '', 'count': 0,
'bull_history': '', 'bear_history': '', 'judge_decision': ''
}),
risk_debate_state=RiskDebateState({
'history': '', 'latest_speaker': '', 'count': 0,
'current_risky_response': '', 'current_safe_response': '',
'current_neutral_response': '', 'risky_history': '',
'safe_history': '', 'neutral_history': '', 'judge_decision': ''
})
)
# 執行工作流程
final_state = trading_system.invoke(initial_state)
return final_state
# 使用示例
if __name__ == "__main__":
result = run_trading_system("NVDA", "2024-12-06")
print(f"最終交易信號:{result.get('final_signal', 'N/A')}")
print(f"系統評估得分:{result.get('evaluation_score', 'N/A')}")生產環境考慮
將系統部署到生產環境需要考慮以下關鍵因素:
可靠性和容錯性
import asyncio
from tenacity import retry, stop_after_attempt, wait_exponential
class ProductionTradingSystem:
"""生產級交易系統實現"""
def __init__(self, config):
self.config = config
self.max_retries = 3
self.timeout_seconds = 300
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
async def run_with_retry(self, ticker: str, trade_date: str):
"""帶重試機制的系統運行"""
try:
return await asyncio.wait_for(
self.run_async(ticker, trade_date),
timeout=self.timeout_seconds
)
except asyncio.TimeoutError:
raise Exception(f"系統運行超時 ({self.timeout_seconds}秒)")
except Exception as e:
print(f"系統運行失敗,正在重試... 錯誤: {str(e)}")
raise
async def run_async(self, ticker: str, trade_date: str):
"""異步運行交易系統"""
# 這裏實現異步版本的交易系統
pass
def health_check(self):
"""系統健康檢查"""
checks = {
"api_connections": self._check_api_connections(),
"memory_usage": self._check_memory_usage(),
"model_availability": self._check_model_availability()
}
all_healthy = all(checks.values())
return {"status": "healthy" if all_healthy else "unhealthy", "details": checks}
def _check_api_connections(self):
"""檢查外部API連接"""
try:
# 測試OpenAI API
quick_thinking_llm.invoke("test")
# 測試其他API...
return True
except:
return False
def _check_memory_usage(self):
"""檢查內存使用情況"""
import psutil
memory_percent = psutil.virtual_memory().percent
return memory_percent < 85 # 內存使用率低於85%
def _check_model_availability(self):
"""檢查模型可用性"""
try:
# 簡單的模型響應測試
response = quick_thinking_llm.invoke("Hello")
return len(response.content) > 0
except:
return False監控和日誌
import logging
from datetime import datetime
import json
class TradingSystemMonitor:
"""交易系統監控類"""
def __init__(self):
self.logger = self._setup_logger()
self.metrics = {}
def _setup_logger(self):
"""設置日誌記錄器"""
logger = logging.getLogger('TradingSystem')
logger.setLevel(logging.INFO)
# 文件處理器
file_handler = logging.FileHandler(f'trading_system_{datetime.now().strftime("%Y%m%d")}.log')
file_handler.setFormatter(logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
))
logger.addHandler(file_handler)
return logger
def log_decision(self, ticker, date, decision, confidence, execution_time):
"""記錄交易決策"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"ticker": ticker,
"trade_date": date,
"decision": decision,
"confidence": confidence,
"execution_time": execution_time,
"event_type": "trading_decision"
}
self.logger.info(json.dumps(log_entry))
def log_error(self, error_type, error_message, context):
"""記錄錯誤"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"error_type": error_type,
"error_message": str(error_message),
"context": context,
"event_type": "error"
}
self.logger.error(json.dumps(log_entry))
def update_metrics(self, metric_name, value):
"""更新系統指標"""
self.metrics[metric_name] = {
"value": value,
"timestamp": datetime.now().isoformat()
}
def get_system_status(self):
"""獲取系統狀態"""
return {
"metrics": self.metrics,
"last_update": datetime.now().isoformat()
}擴展能力和未來發展
多資產支持
class MultiAssetTradingSystem(ProductionTradingSystem):
"""多資產交易系統"""
def __init__(self, config):
super().__init__(config)
self.supported_assets = ["stocks", "crypto", "forex", "commodities"]
async def analyze_portfolio(self, assets: list, trade_date: str):
"""分析整個投資組合"""
results = {}
# 並行分析多個資產
tasks = [
self.run_with_retry(asset, trade_date)
for asset in assets
]
portfolio_results = await asyncio.gather(*tasks, return_exceptions=True)
for asset, result in zip(assets, portfolio_results):
if isinstance(result, Exception):
results[asset] = {"error": str(result)}
else:
results[asset] = result
# 投資組合級別的風險管理
portfolio_decision = self._make_portfolio_decision(results)
return {
"individual_decisions": results,
"portfolio_decision": portfolio_decision
}
def _make_portfolio_decision(self, individual_results):
"""基於個別資產決策做出投資組合級決策"""
# 這裏實現投資組合優化邏輯
pass實時數據流集成
import websocket
import threading
class RealtimeDataIntegration:
"""實時數據流集成"""
def __init__(self, config):
self.config = config
self.data_buffer = {}
self.callbacks = []
def start_realtime_feed(self, symbols):
"""啓動實時數據流"""
for symbol in symbols:
thread = threading.Thread(
target=self._connect_websocket,
args=(symbol,)
)
thread.daemon = True
thread.start()
def _connect_websocket(self, symbol):
"""連接WebSocket數據流"""
def on_message(ws, message):
data = json.loads(message)
self._process_realtime_data(symbol, data)
def on_error(ws, error):
print(f"WebSocket錯誤 {symbol}: {error}")
ws = websocket.WebSocketApp(
f"wss://api.example.com/stream/{symbol}",
on_message=on_message,
on_error=on_error
)
ws.run_forever()
def _process_realtime_data(self, symbol, data):
"""處理實時數據"""
self.data_buffer[symbol] = data
# 觸發註冊的回調函數
for callback in self.callbacks:
callback(symbol, data)
def register_callback(self, callback):
"""註冊數據更新回調"""
self.callbacks.append(callback)機器學習增強
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
import numpy as np
class MLEnhaniedTradingSystem:
"""機器學習增強的交易系統"""
def __init__(self, config):
self.config = config
self.ml_model = RandomForestClassifier(n_estimators=100)
self.scaler = StandardScaler()
self.is_trained = False
def extract_features(self, state):
"""從智能體狀態中提取特徵"""
features = []
# 技術指標特徵
market_report = state.get('market_report', '')
features.extend(self._extract_technical_features(market_report))
# 情緒特徵
sentiment_report = state.get('sentiment_report', '')
features.extend(self._extract_sentiment_features(sentiment_report))
# 基本面特徵
fundamentals_report = state.get('fundamentals_report', '')
features.extend(self._extract_fundamental_features(fundamentals_report))
return np.array(features).reshape(1, -1)
def train_model(self, historical_data):
"""訓練機器學習模型"""
X = []
y = []
for record in historical_data:
features = self.extract_features(record['state'])
X.append(features.flatten())
y.append(record['actual_outcome']) # 1: profit, 0: loss
X = np.array(X)
y = np.array(y)
# 標準化特徵
X_scaled = self.scaler.fit_transform(X)
# 訓練模型
self.ml_model.fit(X_scaled, y)
self.is_trained = True
def predict_outcome(self, state):
"""預測交易結果"""
if not self.is_trained:
return None
features = self.extract_features(state)
features_scaled = self.scaler.transform(features)
# 預測概率
probability = self.ml_model.predict_proba(features_scaled)[0][1]
return {
"success_probability": probability,
"confidence": "high" if probability > 0.7 else "medium" if probability > 0.5 else "low"
}
def _extract_technical_features(self, report):
"""提取技術分析特徵"""
# 這裏實現技術指標的數值提取
return [0.5, 0.6, 0.7] # 示例
def _extract_sentiment_features(self, report):
"""提取情緒分析特徵"""
# 這裏實現情緒指標的數值提取
return [0.8, 0.2] # 示例
def _extract_fundamental_features(self, report):
"""提取基本面特徵"""
# 這裏實現基本面指標的數值提取
return [1.2, 0.9, 1.5] # 示例總結
我們構建的這個基於LangGraph的多智能體量化交易系統代表了AI在金融決策領域的一個重要進展。該系統通過模擬真實投資機構的協作模式,實現了從數據收集、深度分析、策略制定到風險管理的完整閉環。
核心優勢
- 多視角決策:通過不同專業背景的智能體協作,避免了單一視角的侷限性
- 對抗性驗證:多頭空頭辯論機制確保投資邏輯經過充分質疑和驗證
- 層次化風險管理:多層次的風險評估機制最大化降低決策風險
- 持續學習能力:基於向量記憶的經驗積累,使系統能夠不斷改進
- 可解釋性:每個決策步驟都有明確的推理過程,便於審計和優化
這個系統不僅是一個技術演示,更是一個可實際部署的交易決策輔助工具。它能夠:
- 為量化基金提供智能化的研究支持
- 幫助個人投資者做出更理性的投資決策
- 為金融機構提供風險管理的自動化工具
- 作為金融AI研究的基礎平台
隨着大語言模型能力的不斷提升和多智能體框架的成熟,這樣的系統將在不久的將來成為金融決策的重要工具,為投資者和金融機構創造更大的價值。本文展示的完整實現代碼已經為讀者提供了一個可運行的起點。
https://avoid.overfit.cn/post/6f67fb0ff12c4453b1ecaf402c3dac5c
作者:Fareed Khan




