









表格數據一直是深度學習的老大難問題。這些年CV和NLP領域被Transformer統治得服服帖帖,但在真正的業務場景裏,面對表格這類的結構化數據,XGBoost這些梯度提升樹還是穩坐釣魚台。
為什麼會這樣?問題其實很簡單。圖像的像素排列有空間位置關係,文本有上下文順序,但表格裏的列是啥順序都行——年齡放第一列和放最後一列沒區別。而且這些列的類型完全不同:有數值、有類別,有的服從正態分佈有的嚴重偏態。同樣是數字50,在年齡列和交易量列意義天差地別。
ArXiv上最近新有篇論文叫"Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning",來自Lexsi Labs的團隊,算是正面解決了這個問題。
上下文學習這條路走得通但是有坎
最近這兩年,受大語言模型啓發,研究者開始嘗試給表格數據做foundation model。核心想法是in-context learning(ICL)——不用針對每個新數據集重新訓練,直接給模型看幾個樣本示例,它就能推斷出任務模式。
TabPFN和TabICL是這方面的先驅。它們在海量合成數據集上做meta-training,讓Transformer學會表格數據的一般規律。理想情況是讓一個模型打天下,新來個表格數據,喂幾個標註樣本就能zero-shot分類。對AutoML來説這簡直是夢想場景。
但第一代模型撞上了三堵牆:
單一尺度的視野太窄。這些模型用統一的粒度處理所有特徵。就像你盯着照片看,只能選一個固定距離——湊近了看到線頭,但看不出整體是件毛衣;退遠了知道是毛衣,但抓不到細節。真實數據的結構是多層次的:底層是單個特徵的交互(比如年齡和收入的關係),中層是特徵組(人口統計信息這一塊),頂層是大的數據分區(個人屬性 vs 行為數據),單尺度模型對這種層次結構基本是盲的。
O(m²)的計算瓶頸卡死了寬表。標準的dense attention讓每個特徵token關注所有其他token,對於m個特徵,複雜度是O(m²)。幾十上百個特徵還能扛,但基因組數據、金融衍生品、傳感器陣列這種動輒上千特徵的場景就徹底歇菜了,內存爆掉是常事。
信息只能單向流動。TabICL這類模型的架構是流水線式的:先embedding列,再建模行間關係,最後ICL預測。下游發現的模式(比如數據集層面的統計特性)沒法反饋回去優化上游的表示。這就很浪費。
Orion-MSP針對這三個問題給出了對應的解法。
三個關鍵創新點
多尺度處理是第一個。Orion-MSP同時在多個粒度上處理特徵——假如一行有64個特徵,它會並行地看:全部64個單獨特徵(scale 1)、16組每組4個特徵(scale 4)、4組每組16個特徵(scale 16)。細粒度抓個體交互,粗粒度抓語義塊的關係,就像同時用不同焦距的鏡頭拍攝。
塊稀疏注意力解決效率問題。借鑑了NLP裏Longformer的做法,用structured block-sparse attention替換dense attention。通過結合局部滑動窗口(相鄰特徵互相看得見)、全局token(專門負責長距離信息傳遞)、隨機連接(保持網絡表達能力),複雜度從O(m²)降到接近O(m·log(m)),這個改進算是巨大了。
Perceiver式的跨組件內存實現雙向信息流。這個設計更巧妙:先讓訓練樣本把信息"寫入"一組可學習的latent vectors(可以理解成一個共享的備忘錄),然後所有樣本(包括測試集)都能從這個備忘錄"讀取"信息來增強自己的表示。而且寫和讀嚴格分離——測試數據只能讀不能寫,這樣就不會違反ICL的因果約束,不存在數據泄露問題。
這三個部分不是獨立的補丁,而是協同工作的系統。稀疏注意力讓多尺度計算變得可行,Perceiver內存讓不同尺度、不同組件的信息能安全地整合起來。
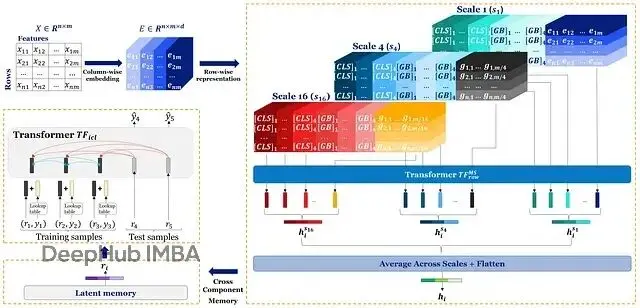
Orion-MSP的整體架構。輸入表先做column-wise embedding得到E,然後多尺度稀疏行交互模塊在不同粒度(1/4/16)上用稀疏attention處理特徵,產生行embedding H。接着跨組件Perceiver內存模塊實現雙向通信:訓練行寫內存,所有行讀內存得到增強表示R。最後ICL head一次前向傳播預測測試標籤。
架構細節
我們從頭捋一遍流程。
第一步:列的distributional embedding
跟TabICL一樣,Orion-MSP用Set Transformer給每列做embedding。這步很關鍵,因為單個cell的值脱離了列的分佈就沒意義。Set Transformer把每列當作無序集合,學習該列在訓練集上的分佈摘要,然後用這個摘要給每個cell生成context-aware的embedding。所以均值45的列裏的50和均值500的列裏的50,embedding完全不同。
第二步:多尺度稀疏行交互
拿到cell embedding之後要建模行內特徵的關係。假設一行64個特徵,Orion-MSP並行地在三個尺度上處理:
Scale 1看全部64個獨立特徵;Scale 4把特徵分成16個塊,每塊4個,看塊與塊的關係;Scale 16分成4個大塊,每塊16個,做高層推理。
每個尺度用的都是block-sparse attention。
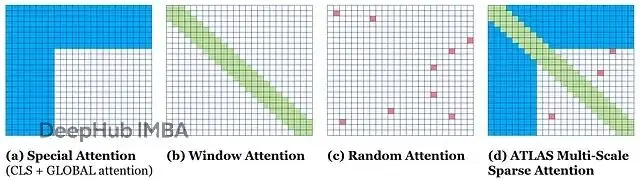
注意力機制的構成。白色表示沒有attention。(a)特殊attention,包括CLS=4和global attention GB=4;(b)滑動窗口attention,w=8;(c)隨機attention,r=2;(d)Orion-MSP的組合行表示。
這個稀疏模式保證了局部交互(滑動窗口)、長程依賴(global tokens)和網絡表達力(隨機連接)的平衡。最後把所有尺度的表示aggregate起來,得到每行的最終embedding。
代碼邏輯大概是這樣:
// Algorithm 1: Multi-Scale Sparse Row-Wise Interaction (Simplified)
function MultiScaleSparseAttention(E, scales=[1, 4, 16]):
all_scale_outputs = []
for scale in scales:
// 1. Group features into blocks of size 'scale'
grouped_features = GroupFeatures(E, size=scale)
// 2. Prepend special CLS and GLOBAL tokens
sequence = [CLS, GLOBAL, ...grouped_features]
// 3. Build the sparse attention mask
// - GLOBAL tokens attend to everything
// - Other tokens use sliding window + random links
sparse_mask = BuildBlockSparseMask(sequence_length)
// 4. Process with a Transformer encoder using the sparse mask
processed_sequence = TransformerEncoder(sequence, mask=sparse_mask)
// 5. Extract the output CLS token, which summarizes the row at this scale
scale_output = processed_sequence[CLS_token_position]
all_scale_outputs.append(scale_output)
// 6. Aggregate the outputs from all scales (e.g., by averaging)
final_row_embedding = Aggregate(all_scale_outputs)
return final_row_embeddingTransformer encoder這步因為用了稀疏mask,複雜度是O(m * window_size)而不是O(m²)。位置編碼用的RoPE,幫助模型理解特徵在序列中的相對位置。
第三步:Perceiver內存做迭代refinement
行embedding現在已經包含了多尺度信息但還能更進一步。Cross-Component Perceiver Memory模塊的工作方式:
寫階段(只有訓練樣本參與):訓練樣本的行embedding去"寫"一組learnable latent vectors。這個過程把訓練集的核心模式壓縮成一個summary。
讀階段(所有樣本):latent memory被凍結,然後所有樣本(訓練+測試)的embedding都去"讀"這個memory,通過cross-attention獲取全局context來refine自己的表示。
測試樣本能利用訓練集的全局信息,但不會反向影響訓練表示。因果約束得到嚴格保證。
// Algorithm 2: ICL with Perceiver Memory (Simplified)
function PerceiverMemoryRefinement(H_all_samples, H_train_samples):
// 1. Initialize a learnable latent memory (the "cheat sheet")
latent_memory = InitializeMemory()
// --- WRITE PHASE (TRAIN ONLY) ---
// 2. The memory attends to the training samples to encode global patterns
for i in 1..N_write_layers:
latent_memory = CrossAttention(query=latent_memory, key_value=H_train_samples)
// At this point, latent_memory is a summary of the training set. It is now frozen.
// --- READ PHASE (ALL SAMPLES) ---
// 3. All samples attend to the memory to enrich their representations
refined_embeddings = H_all_samples
for i in 1..N_read_layers:
refined_embeddings = CrossAttention(query=refined_embeddings, key_value=latent_memory)
return refined_embeddings這個refined representation R既有行本身的信息,又融入了訓練集的distributional knowledge,預測自然更穩。
第四步:split-masked Transformer做zero-shot預測
最後refined embeddings進ICL prediction head。這裏用標準Transformer但加了split attention mask來enforce ICL規則:
訓練樣本可以互相attend;測試樣本可以attend訓練樣本(學任務)和其他測試樣本(利用query set的pattern);訓練樣本絕對不能attend測試樣本。
然後一次forward pass輸出測試label。沒有gradient更新,純inference。
實驗結果
作者在三個主要benchmark上測試了Orion-MSP:TALENT、OpenML-CC18、TabZilla,幾百個不同的數據集,對手包括XGBoost、CatBoost這些傳統方法,還有TabPFN、TabICL、TabDPT這些新的foundation models。
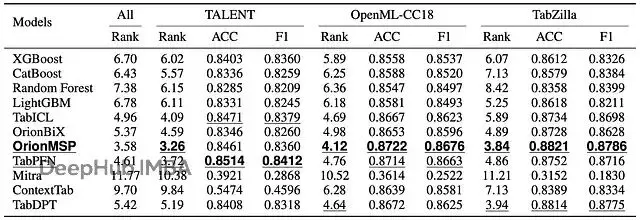
三個benchmark suite的性能對比。Rank是mean rank(越小越好)。Metrics包括準確率(ACC)和加權F1。"All"列是所有suite的彙總rank。第一名和第二名用不同格式標註。
Orion-MSP拿到了3.58的overall zero-shot rank,所有benchmark裏最好。準確率和F1上持續match或超過TabPFN和TabICL。
高維數據的碾壓優勢
按特徵數量分組看性能,差異就出來了。
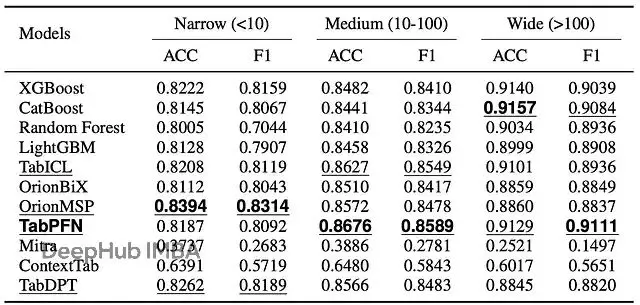
按特徵維度(數據集寬度)的性能變化。ACC是準確率,F1是加權F1分數,範圍0-1越高越好。模型按adaptation策略分組。每組內第一名第二名有格式標記。
窄表和中等寬度表上大家都還行,但到了寬表(100+特徵),dense attention模型的O(m²)複雜度就成了致命傷。很多Transformer-based的模型直接OOM崩掉。Orion-MSP的稀疏attention讓它在這個區間依然保持強勁性能。
金融和醫療領域表現突出
在數據天然具有層次結構的領域,多尺度架構的優勢更明顯。
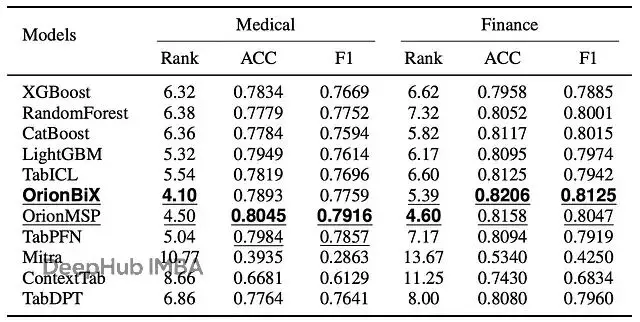
醫療和金融數據集的性能。Rank是域內mean rank(越低越好)。ACC和F1都是0-1範圍,越高越好。
醫療數據集上準確率0.8045最高。醫療數據本來就是分層的:實驗室檢查、生命體徵、人口學信息,多尺度架構正好match這種結構。
金融數據集上mean rank 4.60排第一。金融數據也是多層次的:市場指標、工具屬性、宏觀經濟因素,Perceiver memory幫忙整合不同scale和context的信息效果很好。
模型在不平衡的數據集上上表現也不錯。多尺度attention似乎能放大minority class的信號——細粒度scale捕捉少數類的subtle pattern,粗粒度scale提供global context防止對多數類過擬合。
為什麼這個工作重要
Orion-MSP不只是刷了個榜,它代表了表格數據建模思路上的轉變。從單一尺度、dense attention的架構,轉向hierarchical、efficient、context-aware的設計。
這也説明表格數據這個戰場還沒打完。但Orion-MSP至少證明了,深度學習如果properly designed,是可以在結構化數據上超越傳統方法的。關鍵是要respect數據本身的結構特點,設計既powerful又efficient的架構。
總結
之前的tabular foundation models被三個問題限制住了——單尺度處理看不到層次結構,O(m²)的dense attention在寬表上爆炸,單向信息流浪費了context。
Orion-MSP通過多尺度處理捕獲不同粒度的特徵交互;塊稀疏attention把複雜度降到接近線性;Perceiver-style memory實現ICL-safe的雙向信息共享。
作者自己承認,在非常簡單的低維數據集上,Orion-MSP的複雜架構優勢不明顯。小表格可能簡單模型就夠了。不過這個論文可以説是很炸裂了,能比XGBoost效果要好的話應該有點説法。
論文地址:https://avoid.overfit.cn/post/53f34259ddaa4ed7a0337b1c1b447107
