









🙌開源項目地址
🌍 GitHub 開源地址(YtyMark-java)
歡迎提交 PR、Issue、Star ⭐️!
1. 簡述
YtyMark-java項目分為兩大模塊:
-
UI界面(ytyedit-mark)
-
markdown文本解析和渲染(ytymark)
本文主要內容為核心模塊--markdown文本解析和渲染。
關於markdown文本解析器怎麼設計,渲染器怎麼實現,怎麼解耦解析和渲染。在這整個流程中,如果通過設計模式實現高內聚低耦合,可重用,易於閲讀,易於擴展,易於維護等。
該模塊的主要目錄結構:
YtyMark-java
├── ytymark/
│ ├── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ ├── annotation/ # 自定義註解
│ │ │ │ ├── enums/ # 枚舉值
│ │ │ │ ├── node/ # 樹節點(塊級和行級節點)
│ │ │ │ ├── parser/ # 解析器(塊級和行級元素)
│ │ │ │ ├── renderer/ # 渲染器(塊級和行級元素)
│ │ │ └── resources/
│ ├── README.md
│ └──pom.xml
2.解析器
目標:將 Markdown 文本解析為節點樹。
使用到的設計模式:
-
構建者模式:創建複雜解析器和渲染器。
-
狀態模式:對markdown文本不同語法做一些前置處理,裁剪成塊級元素。
-
責任鏈模式:按優先級匹配不同,處理複雜的塊級元素解析及嵌套解析。
-
策略模式:動態選擇解析器完成行內元素的解析。
-
組合模式:表示 Markdown 語法結構(如段落、標題、列表)之間的樹形結構。
-
迭代器模式:通過迭代器結合遞歸來遍歷節點樹,遍歷塊級元素進行行內元素解析。
根據使用順序逐一講述。
2.1. 構建者模式
通過構建者模式來創建複雜的解析器和渲染器,包括自定義解析器的加入。
最簡單的解析器(默認支持的語法解析器)和HTML渲染器
// 構建解析器
Parser parser = ParserBuilder.builder().build();
// 構建渲染器
Renderer renderer = RendererBuilder.builder().build(HtmlRenderer.class);
加入自定義塊級元素解析器或者行級元素的解析器:
Parser parser = ParserBuilder.builder()
.addDelimiter("_")
.addBlockParser(new ParagraphParserHandler())
.addInlineParser("_", new ItalicParser())
.build();
除此之外,程序會在啓動時,掃描org.ytymark.parser包中帶有註解BlockParserHandlerType的類,所以還可以通過註解加入新的塊級元素解析器。
比如表格解析器:只需要在塊解析器類上面加入這個註解和對應的枚舉類即可
// 枚舉類
public enum BlockParserHandlerEnum {
TABLE("TABLE",6),
// 通過註解加入塊級元素解析器
@BlockParserHandlerType(type = BlockParserHandlerEnum.TABLE)
public class TableParserHandler extends AbstractBlockParser implements ParserHandler {
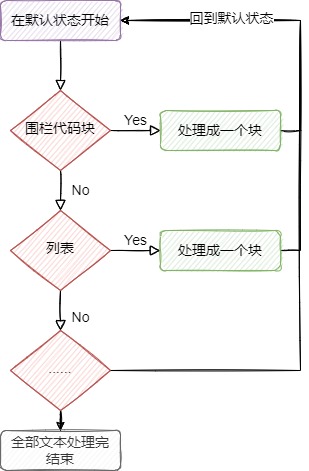
2.2. 狀態模式
對markdown文本不同語法做一些前置處理,裁剪成塊級元素。
在正式進行塊級元素解析前,對原始markdown文本進行分割,分割成一塊一塊的。
由於markdown語法很多,不進行一些設計,那將是一坨難以閲讀理解、難以維護和擴展的代碼。
通過狀態模式實現類似狀態機的機制,當狀態(語法)匹配時,自動流轉到專門處理這個語法的程序,處理完之後分割成一個“塊”(這個塊就是一個塊元素),再回到默認狀態,然後繼續處理後續的文本。具體代碼位於:org.ytymark.parser.block.state包。
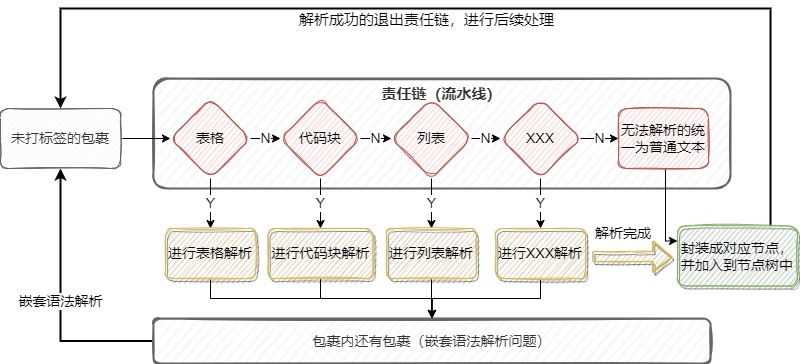
2.3. 責任鏈模式
按優先級匹配不同,處理複雜的塊級元素解析及嵌套解析。
在正式進行塊級元素解析前,狀態模式將元素文本處理成塊數據集合,這就像流水線上簡單的打了包,但並不區分包裹裏面是什麼內容。接着將這些包裹丟上流水線(責任鏈)上,責任鏈根據程序初始化時定好的順序,逐一檢測包裹裏的內容是什麼,匹配得上的就直接丟給機器處理(解析),最終給包裹打上標籤(包裝成節點對象)。對應包裹裏還有包裹的,便繼續丟迴流水線上進行打標籤。
整個處理流程,如圖:
塊解析的代碼
public void parser(String text, Node node) {
List<String> blocks = this.splitBlock(text);
// 逐塊處理文本
for (String block : blocks) {
blockParserChain.parser(block, node);
}
}
2.4. 策略模式
動態選擇解析器完成行級元素的解析。
塊級元素解析完成後,會形成塊節點的節點樹,再進行行級元素解析。
public Node parse(String markdownText) {
Node root = new DocumentNode();
// 統一換行符,替換所有 \r\n 或 \r 為 \n
String normalizedText = markdownText.replaceAll("\r\n|\r", "\n");
// 塊級元素解析
blockParserContext.parser(normalizedText, root);
// 行級元素解析
this.parseInlines(root);
return root;
}
行級元素並不是所有塊元素都需要進行處理,目前只對標題和段落塊節點進行解析,因為其它塊級元素的內容最終會通過段落節點進行保存。
根據語法特點,動態選擇解析器完成行級元素的解析,關鍵代碼如下:
// 檢查字符對或單個字符,選擇對應的解析器
String possibleDelimiter = this.getPossibleDelimiter(line, i);
InlineParser inlineParser = inlineParserMap.get(possibleDelimiter);
if (inlineParser != null) {
// 找到合適地解析器,嘗試解析
InlineNode inlineNode = inlineParser.parser(sourceLine, this);
if(inlineNode!=null){
node.addChildNode(inlineNode);
}
}
2.5. 組合模式和迭代器模式
表示 Markdown 語法結構(如段落、標題、列表)之間的樹形結構,每個語法對應一個Node節點,在塊級元素和行級元素的解析過程,最終組合成節點樹。節點和迭代器源碼位於org.ytymark.node包。
通過迭代器結合遞歸來遍歷節點樹,在解析階段,用於遍歷塊級元素進行行內元素解析。
使用迭代器完成兄弟節點的遍歷(廣度遍歷),再結合遞歸完成子節點遍歷(深度遍歷),具體源碼如下:
/**
* 行級元素解析
* @param parent 父節點
*/
@Override
public void parseInlines(Node parent) {
Iterator<Node> iterator = parent.createIterator();
while (iterator.hasNext()) {
// 獲取下一個兄弟節點
Node node = iterator.next();
// 解析子節點行
if(node instanceof ParagraphNode){
inlineParserContext.parser(((ParagraphNode) node).getText(),node);
}
if(node instanceof HeadingNode) {
inlineParserContext.parser(((HeadingNode) node).getText(), node);
}
if(node.getFirstChild()!=null)
parseInlines(node);
}
}
3. 渲染器
目標:將 AST 語法樹渲染為 HTML 文本預覽。
使用到的設計模式:
-
中介者模式思想:加入AST節點樹解耦解析器和渲染器,使其靈活地渲染成不同的文檔。
-
迭代器模式:通過迭代器結合遞歸來遍歷節點樹,比如遍歷節點樹完成渲染操作。
-
訪問者模式:負責分離節點數據與渲染操作,提高渲染的擴展性。
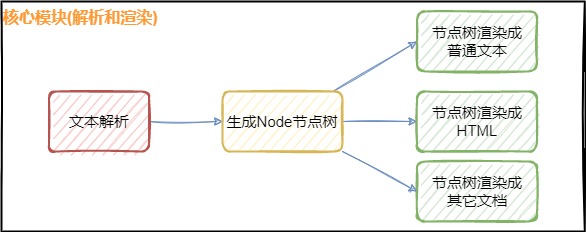
3.1. 中介者模式思想
在解析和渲染中間加入AST節點樹,解耦解析器和渲染器,使得一次解析可以靈活地渲染成不同的文檔。為了將低耦合,常常會在兩者間多加一層。
3.2. 迭代器模式
通過迭代器結合遞歸來遍歷節點樹,在渲染階段,遍歷節點樹完成渲染操作。
/**
* 循環渲染兄弟節點
* 在實現這個抽象類的渲染器中,如果存在子節點行為就需要調用這個方法實現遞歸遍歷子節點
*/
protected void renderChildren(Node parent) {
Iterator<Node> iterator = parent.createIterator();
while (iterator.hasNext()) {
// 獲取下一個兄弟節點
Node next = iterator.next();
// 渲染節點
next.render(this);
}
}
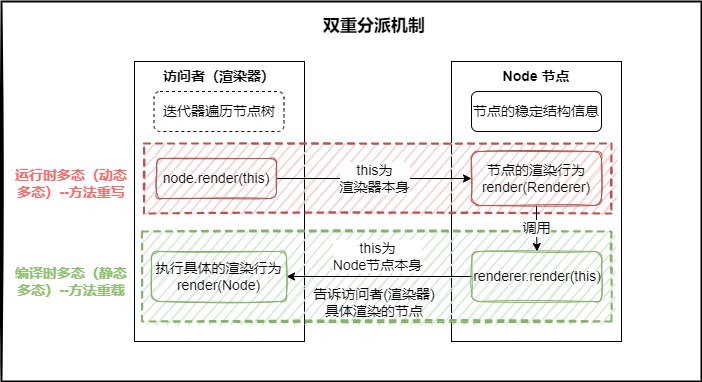
3.3. 訪問者模式
負責分離Node節點數據與渲染操作行為,提高渲染的擴展性。在每個節點類中,實現渲染邏輯時只需要編寫以下代碼:
@Override
public void render(Renderer renderer) {
renderer.render(this);
}
將渲染邏輯抽離出來,由渲染器接口實現類來實現具體的渲染邏輯,不同的實現類對應不同的渲染行為,目前只實現了HTML的渲染。
在構建器中選擇渲染器類型:
Renderer renderer = RendererBuilder.builder().build(HtmlRenderer.class);
解決渲染的擴展性(多樣性)問題
如果需要將markdown文本渲染成普通文本,則只需要繼承AbstractRenderer 抽象類,實現Renderer接口中所有方法即可。並且實現渲染邏輯非常簡單,只需要關注當前節點要做的事情即可。
比如,表格最外層的渲染源碼
@Override
public void render(TableNode tableNode) {
sbHTML.append("<table>\n");
renderChildren(tableNode);
sbHTML.append("</table>\n");
}
而兄弟節點(廣度遍歷)和嵌套子節點(深度遍歷),只需要調用抽象類AbstractRenderer的 renderChildren(Node parent)方法即可完成渲染,使得渲染邏輯只需要關注當前節點的行為即可。比如上面的表格渲染代碼renderChildren(tableNode);。
🚀4. 項目亮點
-
💡 高度模塊化,任何 Markdown 語法都能獨立添加/修改。
-
🧠 設計模式實戰,適合做設計模式學習的項目。
-
🖥️ 可按需獲取,用户界面和文本解析渲染分為兩個模塊
-
只使用用户界面源碼,然後輕鬆切換成熟的解析器依賴,開發一個完整的markdown文本編輯器;
-
僅學習文本解析渲染模塊源碼,不用關注用户界面源碼。
-
-
🧪 解析性能毫秒級,確保解析效率。
-
🎯 輕鬆上手,使用JDK8 自帶JavaFX模塊,無需做額外處理。
-
📦 開源項目,文檔完善,方便學習和貢獻。
✏️5. 總結
markdown 文本解析和渲染將多種設計模式融入到實際應用中,是一次系統性的 設計模式實踐或架構設計實踐。
更多詳細內容可以前往筆者微信公眾號回覆:設計模式,來獲取,後續有關設計模式的新資料都可以從這個入口獲取到。
-
秘籍1設計模式手冊:《掌握設計模式:23種經典模式實踐、選擇、價值與思想》
-
秘籍2練手項目:設計模式實戰項目--markdown文本編輯器軟件開發(已開源)

查看往期設計模式文章的:設計模式
超實用的SpringAOP實戰之日誌記錄
2023年下半年軟考考試重磅消息
通過軟考後卻領取不到實體證書?
計算機算法設計與分析(第5版)
Java全棧學習路線、學習資源和麪試題一條龍
軟考證書=職稱證書?
軟考中級--軟件設計師毫無保留的備考分享
三連支持!!!


