









一、背景
隨着交易和社區搜索業務穩步快跑,基建側引擎越來越複雜,之前搜索底層索引查詢結構已經存在較為嚴重的性能瓶頸。成本和運維難度越來越高。在開發效率上和引擎的穩定性上,也暴露出了很多需要解決的運維穩定性和開發效率短板。而在引擎的業務層部分也需要逐步升級,來解決當前引擎中召回層和業務層中各個模塊強耦合,難維護,迭代效率低下等問題。

二、引擎開發技術方案
DSearch1.0索引層整體結構
DSearch1.0的索引結構比較特殊一些,總體上使用了全局rcu的設計思想,整體架構上單寫多讀,所以實現了併發高性能無鎖讀,內部數據結構都是無鎖數據結構,所以查詢性能高。在寫操作上因為rcu機制實現寫入無鎖。整體上優點讀性能高,沒有傳統段合併操作帶來的磁盤抖動。缺點是索引地址和操作系統強相關,運維複雜,熱更新受限。全局地址分配難以並行寫入,構建瓶頸明顯。無法對浪費的內存進行回收導致內存空間利用率低,索引空間佔用大。總體結構如圖所示:
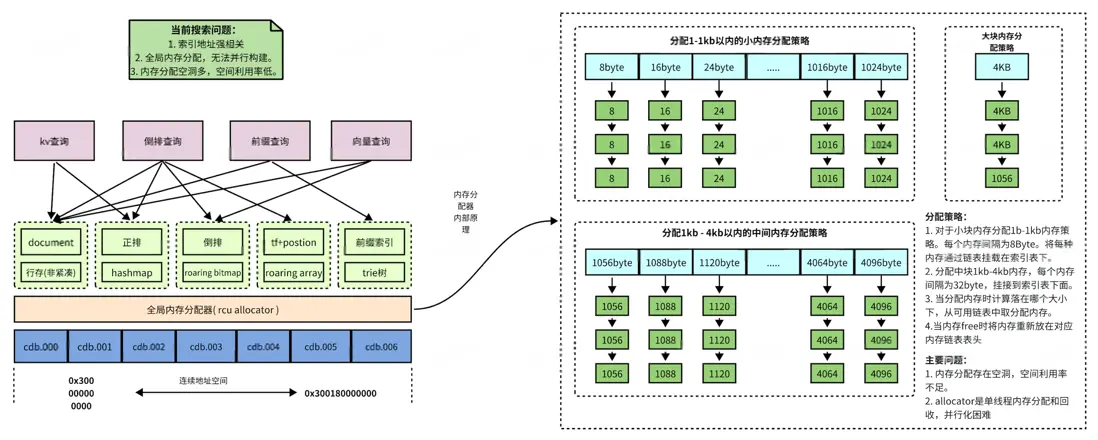
DSearch2.0的索引升級
DSearch2.0分段索引整體設計
引擎2.0索引升級採用經典段合併架構,除了繼承了段合併中優異的高性能寫入性能和查詢已經索引合併等優勢外,針對段合併中頻繁的正排字段更新等帶來的高IO缺點。我們設計了新的正排字段原地更新索引,使新的DSearch2.0引擎擁有Redis的高性能寫入和查詢,也擁有lucene的緊湊索引和索引合併帶來的內存空間節省的優勢。
※ 索引段結構
- 每個索引段包含了文檔文件,用於緊湊存放document中的各個字段的詳細信息。字符串池文件是對document中所有的字符串進行統一順序存儲,同時對字符串進行ID化,每個字符串ID就是對應於字符串池中的offset偏移。
- 可變數組文件是專門存放數組類型的數據,緊湊型連續存放,當字段更新的時候採用文件追加append進行寫。最終內存回收通過段之間的compaction進行。FST索引文件是專門存放document中全部字符串索引。每個fst的node節點存放了該字符串在字符串池中的偏移offset。而通過字符串的offset,能夠快速在倒排termoffset數組上二分查找定位到term的倒排鏈。
- 倒排文件是專門存放倒排docid,詞頻信息、位置信息等倒排信息,其中docid倒排鏈數據結構會根據生成段的時候計算docid和總doc數的密度來做具體判斷,如果密度高於一定閾值就會使用bitmap數據結構,如果小於一定閾值會使用array的數據結構。
- 標記刪除delete鏈主要是用於記錄段中被刪除的document,刪除操作是軟刪除,在最後查詢邏輯操作的時候進行最後的過濾。
- 實時增量的trie樹結構,實時增量段中的前綴檢索和靜態段中的前綴檢索數據結構不一樣,trie因為能夠進行實時更新所以在內存中使用trie樹。
- 段中的metadata文件,metadata文件是記錄每個段中的核心數據的地方,主要記錄段內doc數量,段內delete文檔比例,實時段的metadata會記錄kafka的offset等核心數據。
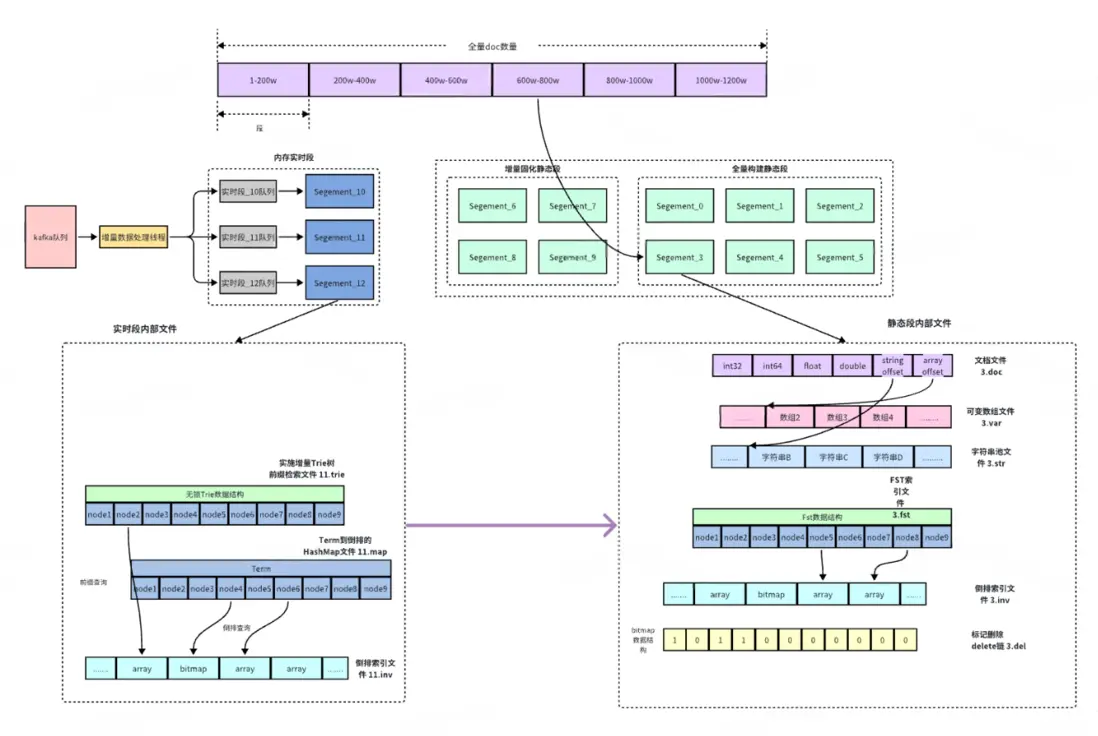
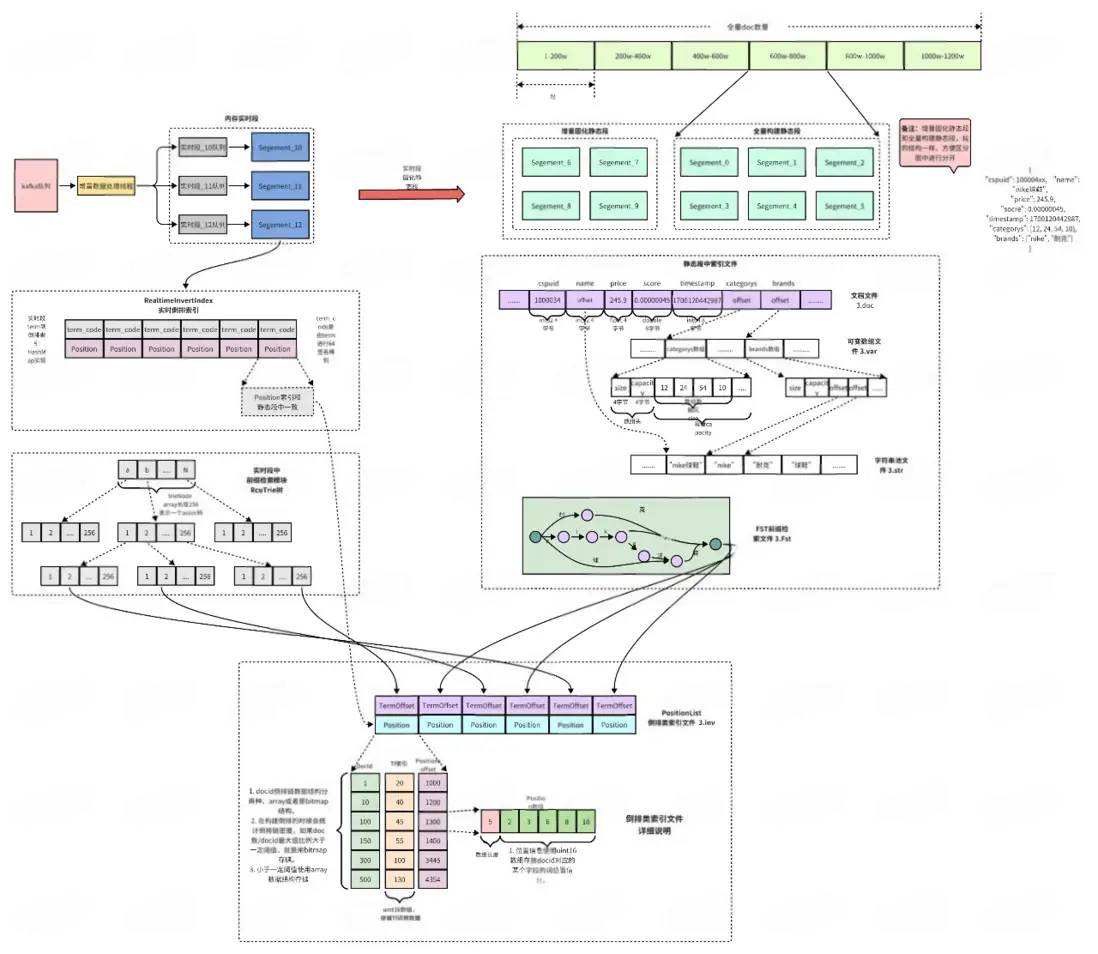
Document文檔和索引結構
※ Document文檔數據結構
- Document文檔使用緊湊型存儲,其中array和字符串類型單獨存放,其他字段連續存放,string和array字段存放。
- array字段類型數據直接存放在可變數組文件區,連續追加寫。
- string字符串池對所有字符串進行連續存放,多個doc中同一個字符串引用同一個字符串地址,節省大量字符串存放空間。
※ 倒排索引文件結構
- 倒排索引文件存放docid倒排和Tf以及位置position數據。其中內存實時段中的倒排索引數據結構是固定一種類型array類型。而內存實時段固化為靜態段的時候,倒排數據結構會根據docid中的密度進行選擇array和bitmap存儲。當docid密度大於一定閾值是bitmap,反之是array結構。
- Tf數據結構是一個uint16的數組,數組長度和docid的數組長度一致,所以當確定了某個docid時候,也隨即確定了它的tf信息。
- postion信息存儲是一個二維數組的格式,第一層數組存放的是對應於term的在字符串池的offset,因為term在字符串池中已經ID化,所以offset可以表示唯一term。第二層數組是該term在字段中多次出現的位置,使用uint16存儲。
※ 前綴檢索文件
-
FST靜態段文件
a. 靜態段中前綴是fst的數據結構,因為fst一旦建立是不能夠進行修改的,所以在段合併的時候需要對所有term進行排序然後再構建fst結構。
b. fst的node節點存放了對應於term的字符串池的offset。當需要查詢一個term的倒排結構時候,需要先查詢該term的字符串池的offset,然後拿該offset去倒排的termoffset文件中二分查找找到對應的倒排positionlist結構拿到對應倒排。所以一次term到倒排的查詢需要查詢一次fst+一次二分查詢。
c. term到倒排的查詢一次fst+一次二分查找效率不高,所以針對term到倒排查詢,新增了第二種HashMap索引,直接通過term到倒排的offset索引,這個選項在建表的時候可以配置。
-
實時段RcuTrie樹索引
a. 實時段中需要支持邊寫邊讀,前綴檢索需要支持併發讀寫。引擎中trie樹是rcu實現,單線程更新,多線程併發讀,trie樹寫更新節點內存延遲迴收。
倒排索引和查詢樹邏輯
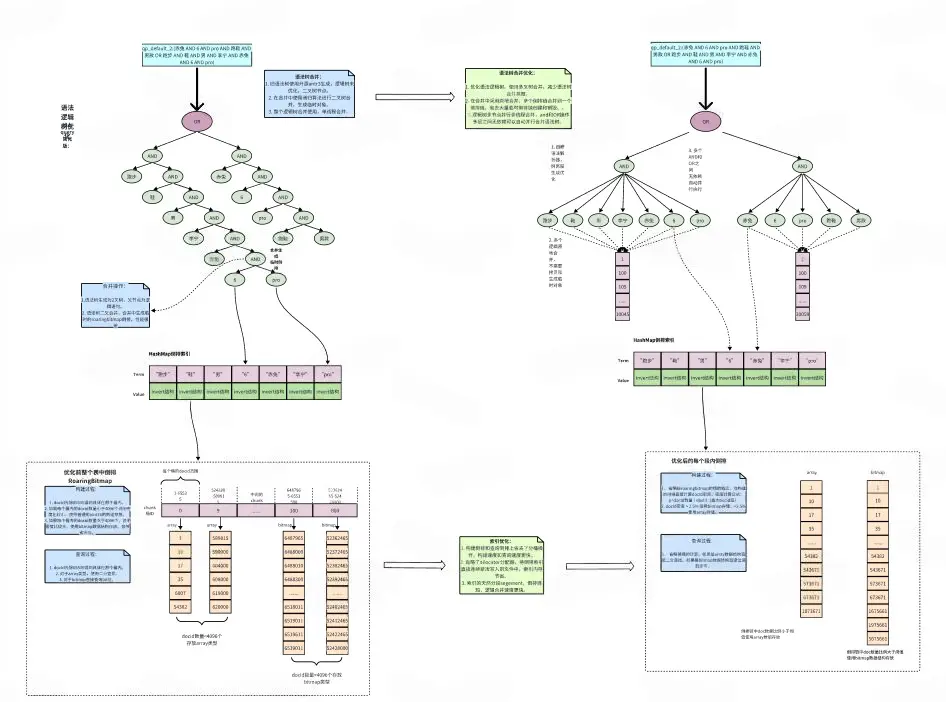
※ 倒排鏈優化
- DSearch1.0的roaringbimap倒排索引在低密度數據量上存在一些瓶頸,比如對於倒排鏈比較短的情況下,roaringbitmap的container大部分都是array結構,在倒排鏈查詢和合並都會進行一次二分查找,在大面積的倒排鏈合併中是個相當大的性能瓶頸。
- 針對上面所説的情況對roaringbitmap進行了精簡,只存array或者bitmap合併的時候不需要查找,直接鏈式合併。
※ 邏輯樹合併優化
- DSearch2.0重點從邏輯語法樹和倒排入手,優化語法樹,減少合併樹高,從二叉樹合併變成單層合併。
- 優化倒排鏈合併方式,採用原地倒排鏈合併,消除倒排合併臨時對象,同時引入多線程並行合併,減少長尾提高性能。
增量更新邏輯
※ 增量實時寫入邏輯
- 引擎支持多個併發實時段,這個由配置文件通過配置來進行配置。多個實時段能夠提升併發寫入的性能。
- 每個實時段對應一個寫入隊列,提高併發寫入吞吐。
- 每個段真實寫入一條信息會同步原子更新消費的kafka的offset,用於對後面進程重啓等恢復數據做準備。
- 當進程重啓或者異常退出時候,會讀取metadata文件中的最後一條kafka offset進行重新消費增量在內存中重新構建新的正排、文檔和倒排等信息,完成數據的恢復。
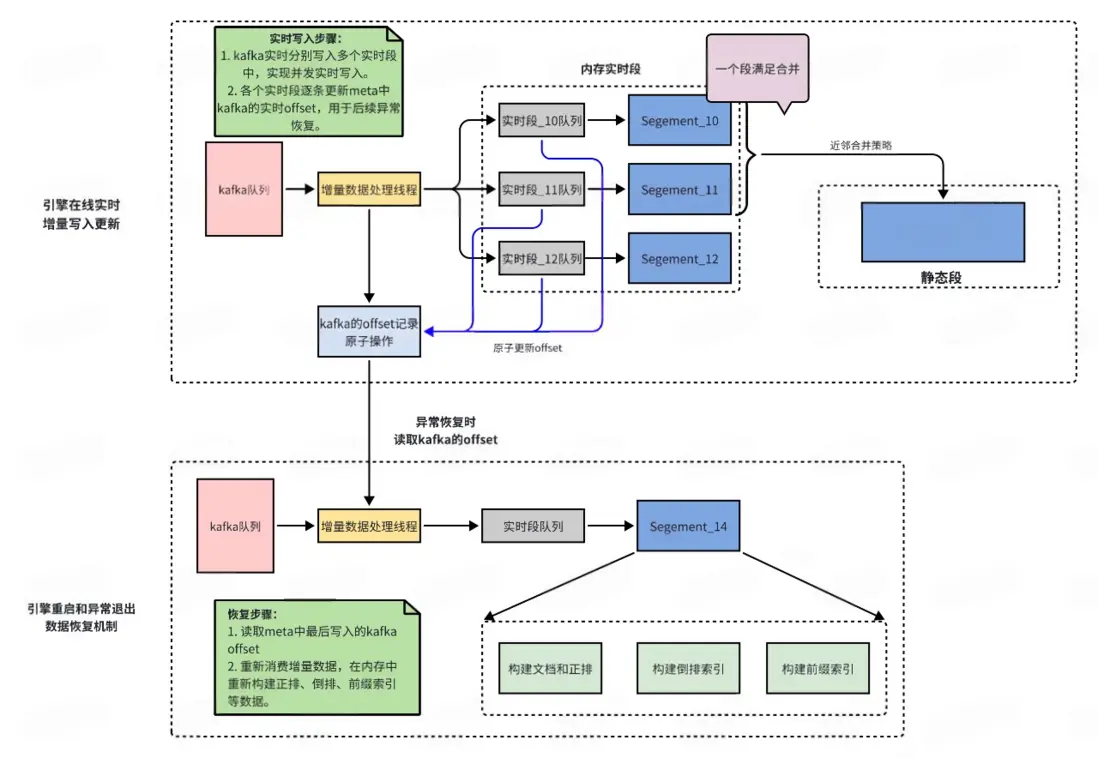
實時段固化和段合併策略
※ 實時段固化邏輯:
- 當實時段內隨着增量寫,doc文件大小超過128M時候會進行內存實時段固化操作。
- 固化操作開始時,會先生成新的內存實時段,老的內存實時段會變成只讀內存段。
- 遍歷按整個只讀內存段,構建新的索引和新的正排結構生成新的靜態段。
※ 段合併策略:
- 實時段固化的小靜態段因為大小比較小,會優先和之前固化後的小段進行合併,按照1,2,4,8進行合併,逐步合併成靜態段最大的上限。
- 靜態段的合併觸發策略是當靜態段中delete的doc比例超過了30%會觸發靜態段之間的合併,合併會按照近鄰合併原則,從左右近鄰中選取一個最小doc數的段進行合併,進而新生成一個新的段。
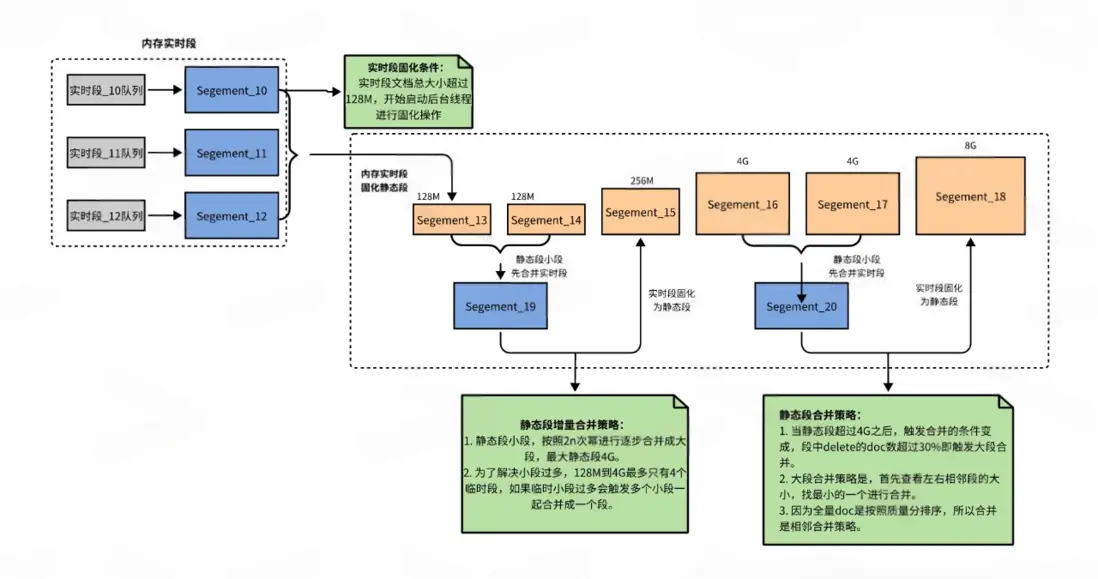
查詢和更新中的併發控制
※ 查詢流程
引擎查詢時候,先遍歷查詢實時段,然後再查詢靜態段。實時段查詢存在最大增量查詢截斷,當實時段查詢到最大增量截斷時實時段停止查詢。
實時段查詢後,查詢靜態段。靜態段中包含了全量構建索引的全量最大offset記錄同時全量的doc是通過質量分進行排序,所以在全量段查詢的時候,先遍歷質量分最大的全量段,逐步往後面靜態段查詢,直到查詢到全量截斷。
實時段查詢和靜態段查詢結果進行merge作為最終的查詢結果。
※ 更新併發控制
因為DSearch2.0的索引更新是直接在實時段或者靜態段進行更新,所以存在多線程讀寫問題。尤其是正排字段更新寫入量大更新頻繁。同時更新涉及到所有的實時段和靜態段,較為複雜。
為了解決正排字段和倒排的更新問題,新版本引擎引入了document文檔鎖池,對每個doc進行hash計算落到鎖池中具體一個鎖上來減少鎖衝突,當前鎖池內有多個個文檔鎖。文檔鎖在文檔進行拷貝和更新的時候會進行鎖住。
DSearch3.0搜索核心升級
異步非阻塞圖調度框架
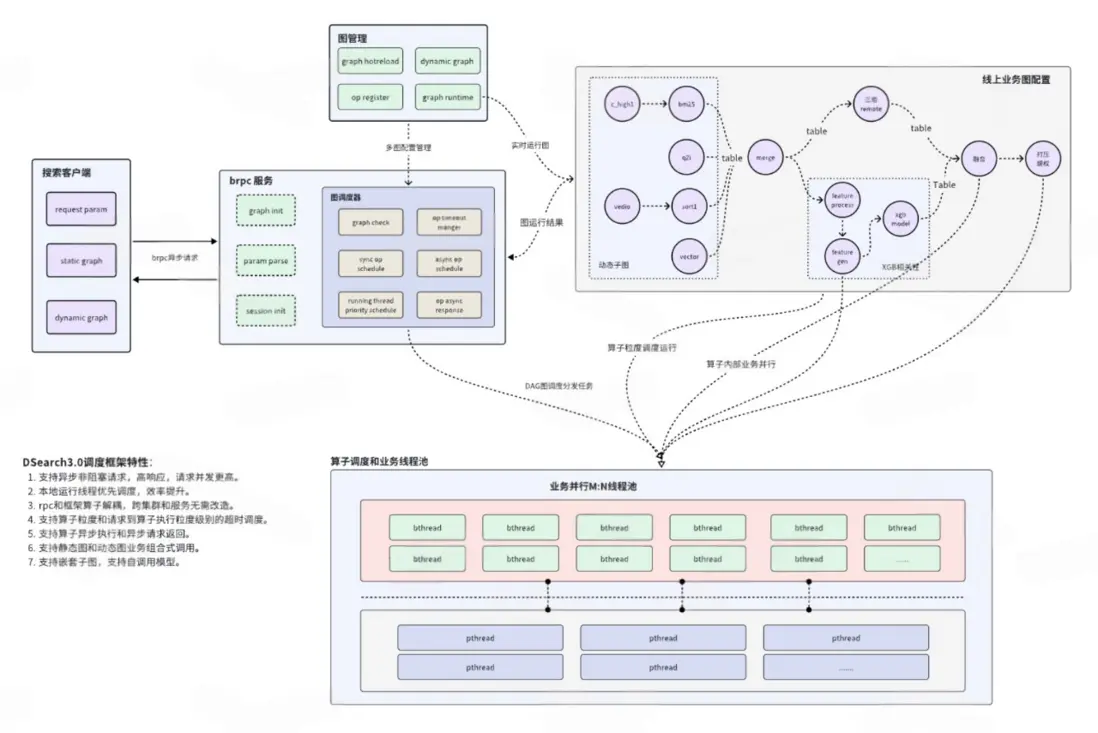
※ 引擎主要改造:
- 圖框架支持RPC異步非阻塞請求:引擎圖框架RpcServer服務使用brpc的異步處理無需同步阻塞等待調度完成,只需框架調度完算子返回結果,不阻塞RpcServer線程,例如:當前引擎調用neuron服務是同步調用,當neuron服務負載高阻塞時,同步調用會導致拖住引擎RpcServer處理線程,新的異步非阻塞模式引擎client在調用引擎後已經返回,等待引擎RpcServer中異步調度框架中remote異步算子回調,減少外部服務影響引擎。
- 減少線程切換: 圖框架調度器會優先調度當前運行線程,同時使用M:N類型的bthread線程池,線程切換會更小,執行效率高。
- RPC服務和框架算子獨立: 引擎RPC服務和框架算子完全解耦,跨集羣部署算子服務無需任何改造,實現算子脱離運行環境。
- 高效的算子異常處理和超時機制: 每個算子維護自己的運行超時時間和請求到算子調度執行的超時時間,對整個請求流程中各算子執行更加精準。
- 動態圖支持: 圖框架支持靜態圖和動態圖業務組合式調用。支持靜態子圖和動態子圖調用等複雜業務組合。
- 複雜子圖支持: 圖框架支持嵌套子圖,支持自調用模型,可以實現複雜單節點多功能調用。
算子間數據交換Table設計

※ 引擎主要改造:
- 列式數據共享優化: 算子交換數據全部存放在Table列中,Table中全部共享列式數據,省去大面積數據拷貝,大幅提升引擎業務執行性能。
- 兼容引擎索引中doc數據: 引擎索引中doc行式存儲有很多優點,比如多字段訪問效率高等,Table設計中考慮了行式存儲優點,不僅存高頻的列字段也儲存了引擎內部的doc以及對應FieldDef,能直接方便訪問索引數據,接口統一,易於迭代。
- 打通FlatBuffer序列化協議: 當前引擎FlatBuffer序列化傳輸協議和引擎內部數據出口需要多次遍歷轉換,需要拷貝很多數據,新Table的設計內部數據列和FlatBuffer內部的數據列互轉互通,節省大量內部拷貝同時避免了字段兼容等問題。
- 支持原地排序和標記刪除: Table數據表,支持原地sort操作和標記刪除操作,節省數據排序時大量數據的拷貝和刪除操作中導致的數據重排等拷貝操作,提升性能。
算子間數據交換Table設計
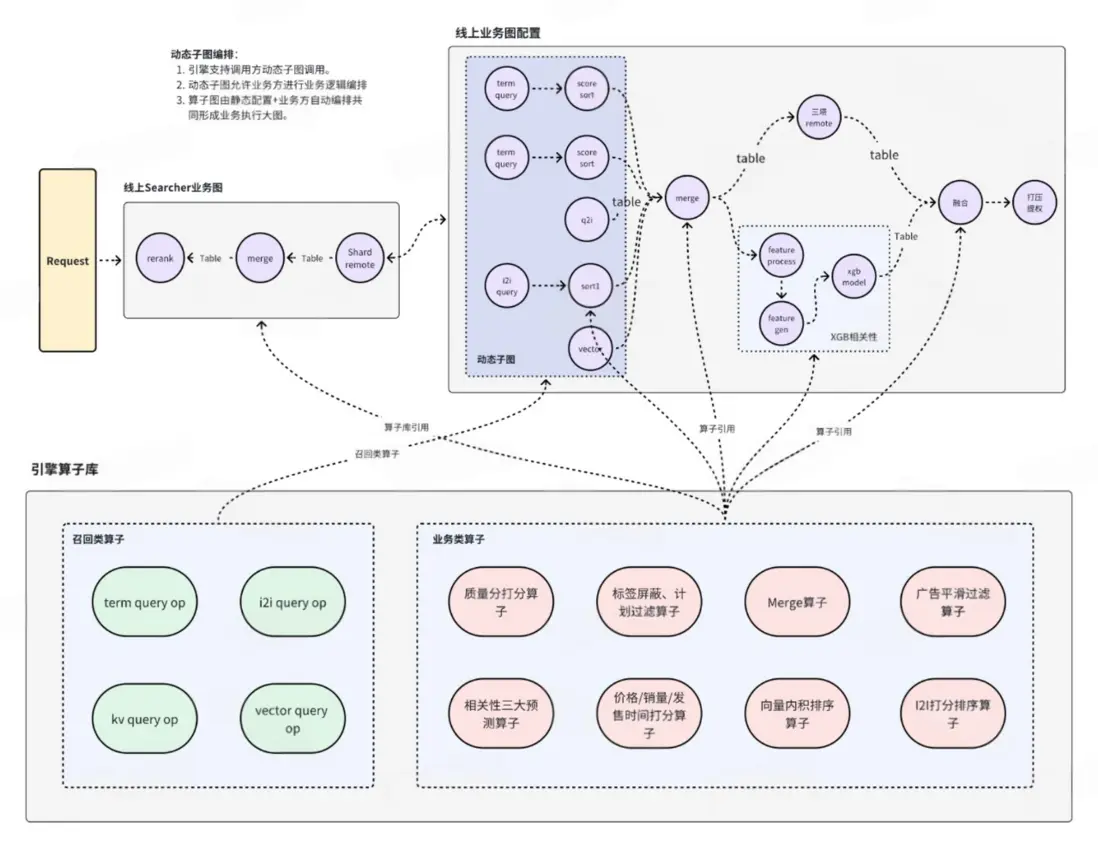
※ 引擎主要改造:
- 動態圖支持: DSsearch3.0支持動態圖編排,主要通過業務方通過動態編排請求來組織對應的算子編排邏輯,實現業務方自主編排調度邏輯,方便整體業務開發。
- Remote遠程調用支持: 通過開發遠程異步調用算子,支持DSearch3.0跨集羣調用,實現多機算子化互聯互通。提高引擎的整體縱向拓展能力。
- 引擎算子庫複用: 通過設計統一的算子接口,開發基礎的可複用框架算子,支持配置化組合運行圖,實現業務邏輯快速複用和開發,提高整體引擎開發效率。
三、性能和效果提升
DSearch在2024年Q1季度索引升級開發完成後逐步推全到交易和社區等各個主場景業務中,最後拿到了很多超預期結果:
索引內存優化超出預期: 社區搜索和交易搜索總索引單分片優化60%。
構建和寫入性能優化超出預期: 社區搜索和交易搜索主表寫入性能提升10倍。
索引更新優化超預期: 社區和交易主表更新時間提升接近10倍。
性能優化符合預期: 社區搜索平均rt降低一倍,P99晚高峯降低2倍。
四、總結
DSearch引擎從開始的DSearch1.0的搜索引擎逐步經歷了DSearch2.0的分段式索引改造升級,又經歷了DSearch3.0的全圖化引擎升級。逐步將DSearch引擎升級到業界較為領先的支持內存型、磁盤型多段式搜索引擎,為支持得物業務的發展做出了重要的貢獻,後續DSearch會圍繞着通用化、自迭代、高性能等多個方向繼續升級,將DSearch引擎迭代到業界領先的引擎。
算法團隊大量HC,歡迎加入我們:得物技術大量算法崗位多地上線,“職”等你來!
往期回顧
1. 以細節詮釋專業,用成長定義價值——對話@孟同學 |得物技術
2. 最近爆火的MCP究竟有多大魅力?MCP開發初體驗|得物技術
3. 得物可觀測平台架構升級:基於GreptimeDB的全新監控體系實踐
4. 得物自研DGraph4.0推薦核心引擎升級之路
5. 大語言模型的訓練後量化算法綜述 | 得物技術
文 / 蘇黎
關注得物技術,每週更新技術乾貨
要是覺得文章對你有幫助的話,歡迎評論轉發點贊~
未經得物技術許可嚴禁轉載,否則依法追究法律責任。












