









根據研究機構預測,全球人工智能市場規模在 2024 年的價值為 234.6 億美元。預計該市場將從 2025 年的 2,941.6 億美元增長到 2032 年的 1,7716.62 億美元,在預測期間的複合年增長率為 29.2%。到 2030 年全球 AI 推理市場規模將達到 2549.8 億美元,而推理任務將佔據 數據中心整體計算需求的 70% 以上。
AI 模型的複雜度正以指數級增長,從數億參數的語言模型到上千億參數的多模態系統。支撐這些模型的,不只是算法,還有底層的算力架構。無論是訓練、微調還是推理部署,GPU 服務器的選擇都會直接影響性能、延遲與成本。
目前市場上按照 GPU 服務器的類型來劃分包括裸金屬 GPU 服務器與虛擬化的 GPU 服務器。
在這樣的背景下,如何在性能、彈性和成本之間取得平衡,如何在兩種 GPU 服務器中進行選擇,成為 AI 團隊無法迴避的核心決策。
兩種 GPU 服務器架構的根本區別
當前主流的 GPU 服務器可分為兩類:裸金屬(Bare Metal) 和 虛擬化(Virtualized)。它們的區別不僅在資源分配方式,更體現在性能可預測性、帶寬利用率和成本模式上。
| 對比維度 | 裸金屬 GPU 服務器 | 虛擬化 GPU 服務器 |
|---|---|---|
| 架構形態 | 獨享整台物理服務器,直接訪問 GPU 資源 | 通過 Hypervisor 層共享 GPU 資源 |
| 性能開銷 | 幾乎為零,無虛擬化層損耗 | 存在 4%–25% 的“虛擬化損耗” |
| 隔離性 | 資源完全獨立,避免干擾 | 多租户共享,可能存在帶寬爭用 |
| 帶寬訪問 | 獨享 GPU 顯存與通信帶寬 | 共享通道 |
| 啓動與伸縮 | 啓動時間較長(分鐘級),不支持彈性擴展 | 快速啓動(秒級),彈性伸縮靈活 |
| 計費方式 | 多為包月或長期租用 | 按小時/秒計費,靈活付費 |
可以簡單地理解為:
- 裸金屬服務器 = 獨享整台硬件,追求極致性能;
- 虛擬化服務器 = 在共享硬件上分配算力,強調靈活與彈性。
前者是“性能主義”,後者是“資源優化派”。
虛擬化 GPU 服務器:靈活的彈性與高性價比
虛擬化 GPU 服務器的最大優勢在於靈活性。
通過 Hypervisor 層,雲服務商能把一台物理 GPU 拆分成多個虛擬 GPU(vGPU),供不同實例使用。這樣,開發者無需關心底層硬件,即可在幾秒內啓動或釋放資源。
優點:
- 快速彈性:可在秒級創建或銷燬實例,應對突發計算需求;
- 成本友好:按小時或秒計費,適合預算有限的團隊;
- 研發效率高:非常適合 PoC 測試、模型調參、小規模訓練等任務;
- 可選 GPU 型號多:大多數雲平台很少提供裸金屬服務器,DigitalOcean 是個例外,但該平台上的虛擬化 GPU 服務器的型號比裸金屬 GPU 服務器的型號更多,用户可選的靈活度更大。
缺點:
- 性能損耗明顯:由於虛擬化層的 CPU/I/O 開銷及帶寬爭用,實際性能可能下降 15%~25%;
- 帶寬不穩定:當多租户同時高負載時,內存帶寬和 I/O 通道可能成為瓶頸;
- 延遲波動:對實時推理類任務(如金融風控、自動駕駛)不夠友好。
因此,虛擬化 GPU 服務器非常適合研發階段、短期任務或預算受限的團隊。例如初創公司、科研機構或教育場景,都可以通過這種架構快速驗證模型想法,而無需長期綁定硬件資源。
裸金屬 GPU 服務器:為性能和確定性而生
裸金屬 GPU 服務器則完全繞過了虛擬化層,讓用户直接控制底層硬件。這種架構幾乎沒有性能開銷,是高性能 AI 訓練與推理的首選。
優勢:
- 無虛擬化損耗:CPU、內存、I/O 通道都直接連接 GPU,可用率接近 100%;
- 帶寬獨享:AI 模型訓練尤其依賴顯存帶寬。裸金屬環境下,GPU 能獲得完整、獨佔的帶寬資源;
- 性能可預測:沒有“吵鬧鄰居”問題(Noisy Neighbor),吞吐與延遲穩定;
- 數據安全性更高:裸金屬 GPU 服務器的數據屬於單一客户管理,所以數據安全性更高。
行業測試表明,在訓練大型模型時,裸金屬 GPU 服務器相比虛擬化架構,性能可提升 25%~30%,訓練時間顯著縮短。
不足:
- 啓動與部署週期較長:相對於虛擬化服務器來講,裸金屬服務器需要完整配置與環境加載;
- 成本更高:多為長期租用或包月計費;
- 靈活性不足:裸金屬服務器是不支持靈活擴展的,所以配置方案需提前規劃。
這類架構最適合對性能極度敏感的應用場景:如大語言模型訓練、高頻推理服務、實時風控、自動駕駛、或需要高帶寬吞吐的 AI 推理平台。
不同類型業務該怎麼選?
沒有一種架構能“通吃”所有任務。最優解往往取決於你的業務階段與算力需求。
| 業務類型 | 核心訴求 | 推薦架構 | 理由 |
|---|---|---|---|
| 大模型訓練(長期高負載) | 性能、穩定性 | 裸金屬服務器 | 長週期訓練對資源可預測性要求高,性能損耗會被放大。 |
| 模型微調、小樣本學習 | 彈性與靈活性 | 虛擬化服務器 | 快速啓動、短期計費,適合多實驗切換。 |
| 實時推理(自動駕駛、金融交易) | 亞毫秒響應 | 裸金屬服務器 | 去除虛擬化層,降低延遲波動。 |
| 研發與測試 | 成本控制 | 虛擬化服務器 | 成本低、啓動快,滿足靈活實驗需求。 |
一個常見的做法是:
在早期實驗和開發階段使用虛擬化的 GPU 服務器,可以節省成本;當模型進入穩定生產後遷移到裸金屬環境,獲得確定的高性能與更低延遲。
兼得之道:雲平台的雙架構支持
如今,主流雲平台開始同時提供這兩種類型的 GPU 基礎設施。例如 DigitalOcean 就在其 GPU Droplet 產品中同時支持:
- 虛擬化 GPU 按需實例:方便快速迭代與按需部署;
- 裸金屬 GPU 服務器:為生產級 AI 訓練與推理提供獨享算力。
這種“雙架構”支持,讓團隊可以在同一平台上完成從模型原型到生產部署的全流程,既能保持靈活性,又能在關鍵時刻釋放全部性能潛力。
目前,DigitalOcean 可提供的裸金屬 GPU 服務器型號包括:NVIDIA HGX H100、NVIDIA HGX H200、AMD MI300X。DigitalOcean 裸金屬 GPU 服務器是按照合約價格來計算的,詳情可與 DigitalOcean 中國區獨家戰略合作伙伴卓普雲 aidroplet.com 直接諮詢。
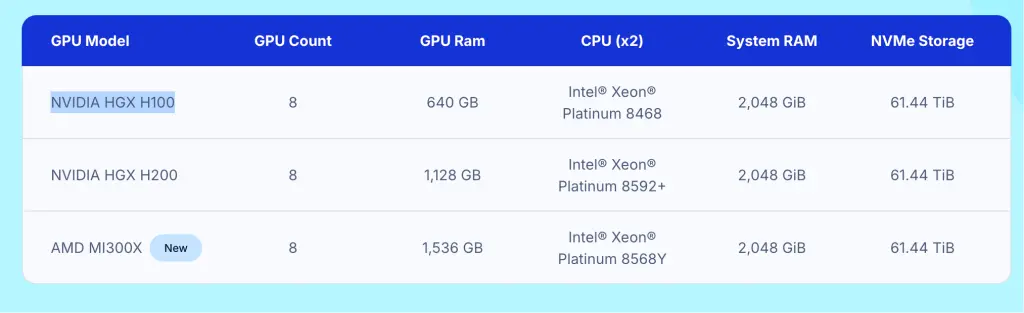
DigitalOcean Gradient AI 平台可提供的 GPU Droplet 按需實例則支持更多 GPU 型號,包括:AMD Instinct™ MI325X、AMD Instinct™ MI300X,以及 NVIDIA 旗下的 H200、H100、RTX 6000 Ada、 RTX 4000 Ada、A100、L40S 等。
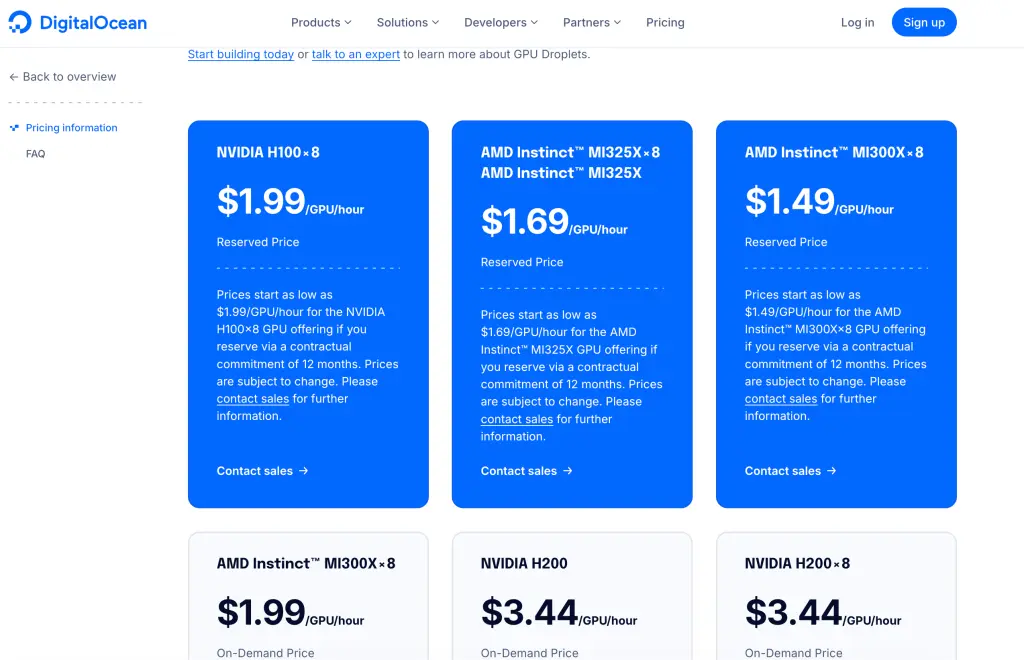
同時,DigitalOcean 還通過中國區獨家戰略合作伙伴卓普雲 aidroplet.com 提供技術支持服務,如果你需要了解這些虛擬化的 GPU 服務器的詳細配置,以及裸金屬 GPU 服務器的價格,可與卓普雲直接諮詢。
結語
AI 基礎設施的選擇,本質上是“性能”與“彈性”的權衡。裸金屬服務器代表確定性與極致算力,虛擬化服務器代表敏捷與成本效率。成熟的團隊會根據任務階段動態切換兩種架構——在開發階段快步試錯,在生產階段穩定提速。當 AI 成為業務的核心生產力,算力架構的每一個選擇,都將成為你競爭力的放大器。












