










👋 大家好,我是遠朋。過去 3 年,我們團隊把部分調度任務從 Azkaban 逐步遷移到 DolphinScheduler,並開展了 K8s 容器化。今天把踩過的坑、攢下的經驗一次性覆盤,建議收藏!
作者介紹

王遠朋
上海奇虎科技有限公司 數據專家
商業化 SRE & 大數據團隊核心成員
長期負責 DolphinScheduler 在生產環境的部署與優化,具備豐富的容器化與大數據調度經驗。
在大數據任務調度的日常工作中,Apache DolphinScheduler 已經成為我們團隊最核心的工具之一。過去我們一直依賴物理機進行部署,例如 3.1.9 版本仍運行在物理機環境中,但這種方式在彈性擴展、資源隔離和運維效率上逐漸暴露出問題。隨着公司整體的雲原生戰略推進,我們最終在 2025 年將 DolphinScheduler 升級到 3.2.2,並部分遷移到 Kubernetes 平台。
遷移的動機非常明確:首先是彈性擴容,K8S 可以根據任務高峯快速擴展 Worker 節點;其次是資源隔離,避免不同任務相互影響;再者是自動化部署與回滾,大幅降低維護成本;最後,也是最重要的一點,這一切符合公司在技術層面的雲原生方向。
鏡像構建:從源碼到模塊
在遷移過程中,鏡像構建是第一步。
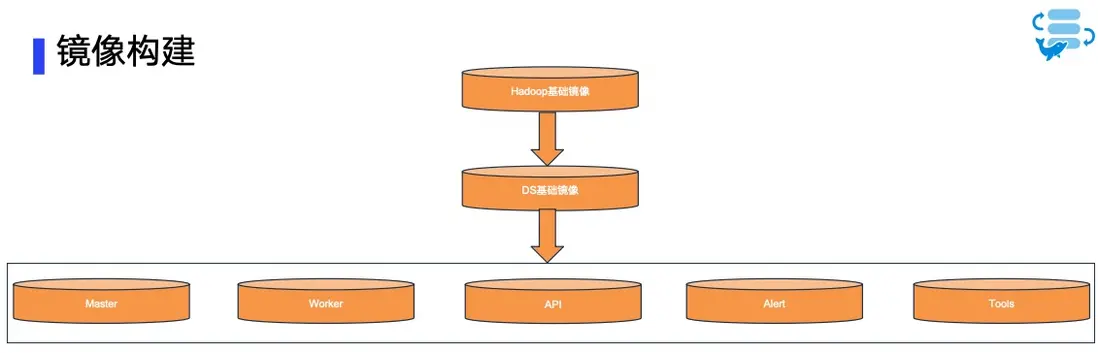
我們先準備了一個包含 Hadoop、Hive、Spark、Flink、Python 等環境的基礎鏡像,然後在此基礎上構建 DolphinScheduler 的基礎鏡像,將重新編譯的各個模塊和 MySQL 驅動打包其中。
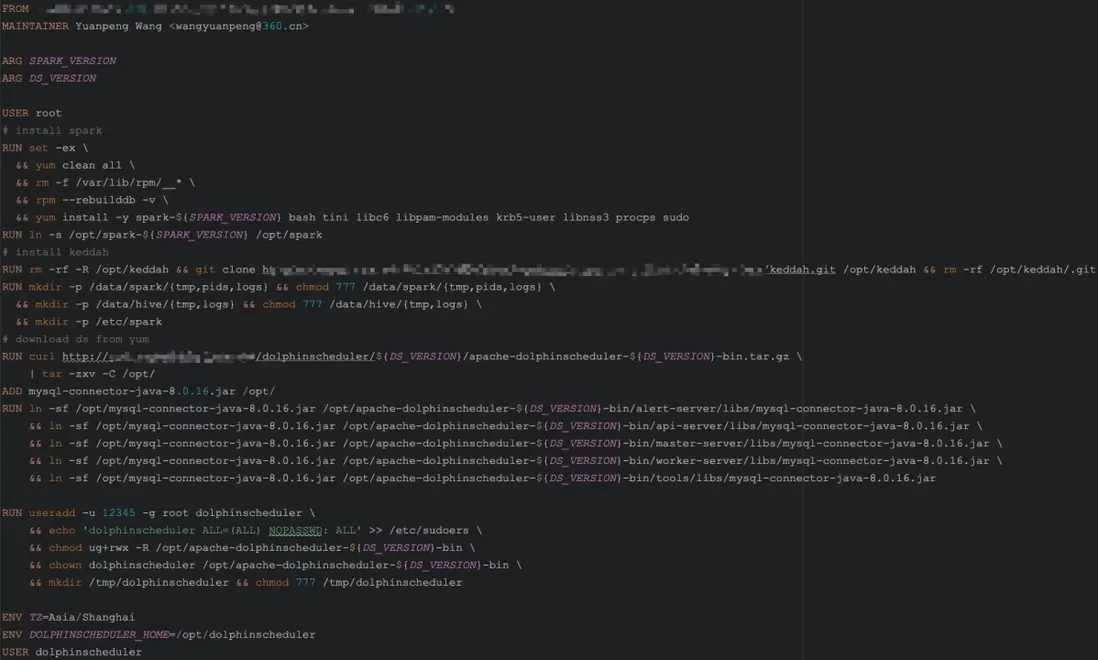
這裏需要注意的是,MySQL 被用作 DolphinScheduler 的元數據存儲,因此驅動包必須軟鏈到每一個模塊,包括 dolphinscheduler-tools、dolphinscheduler-master、dolphinscheduler-worker、dolphinscheduler-api 和 dolphinscheduler-alert-server。
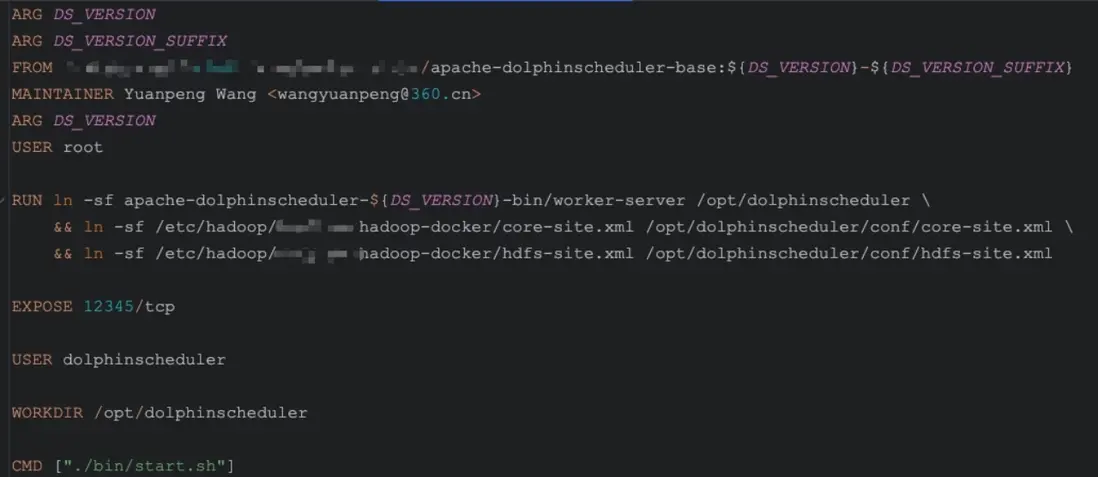
Worker鏡像
模塊鏡像則是在 DS 基礎鏡像之上進行定製,主要修改端口和配置。為了減少後續配置文件的改動,我們儘量保持模塊鏡像的名稱與官方一致。構建時既可以單獨構建某個模塊,例如:
./build.sh worker-server
單獨構建鏡像
也可以批量構建所有模塊:
./build-all.sh
批量構建鏡像
這一步裏我們遇到的典型問題包括:基礎鏡像過大導致構建時間過長,源碼改造後的 jar 包沒有覆蓋舊文件,甚至不同模塊的端口配置和啓動腳本不一致。 這些細節如果處理不當,就會在後續部署階段帶來一系列棘手的問題。
| 問題 | 解決方案 |
|---|---|
| 基礎鏡像過大、構建慢 | 把公共軟件層拆成多階段構建緩存 |
| MySQL 驅動找不到 | 建軟鏈到所有模塊 lib/ 目錄 |
| 自編譯 Jar 沒覆蓋舊包 | build.sh 里加 find -name "*.jar" -delete |
部署方案:從自制 YAML 到官方 Helm Chart
在部署初期,我們是手寫 YAML 文件來完成部署的,但這種方式在配置分散和升級維護上成本極高。後來我們改用了官方提供的 Helm Chart,這樣配置集中管理,升級也更方便。
我們使用的 K8S 集羣版本是 v1.25,部署時需要先創建命名空間 dolphinscheduler,然後拉取 helm 包,例如:
helm pull oci://registry-1.docker.io/apache/dolphinscheduler-helm --version 3.2.2在真正落地過程中,values.yaml 是最核心的文件,我們在這裏踩過很多坑。下面貼出幾個關鍵配置片段,供大家參考:
1. 鏡像配置
image:
registry: my.private.repo
repository: dolphinscheduler
tag: 3.2.2
pullPolicy: IfNotPresent👉 提示:一些前置的工具鏡像最好提前 push 到私有倉庫,避免因網絡或鏡像源問題導致部署失敗。
2. 外置數據庫配置(MySQL)
mysql:
enabled: false # 關閉內置 MySQL
externalMysql:
host: mysql.prod.local
port: 3306
username: ds_user
password: ds_password
database: dolphinscheduler👉 內置數據庫務必關閉,生產環境統一接入外部 MySQL(未來我們將切換到 PostgreSQL)。
3. LDAP 登錄認證
ldap:
enabled: true
url: ldap://ldap.prod.local:389
userDn: cn=admin,dc=company,dc=com
password: ldap_password
baseDn: dc=company,dc=com👉 我們接入了公司 LDAP,統一用户認證,方便權限管理。
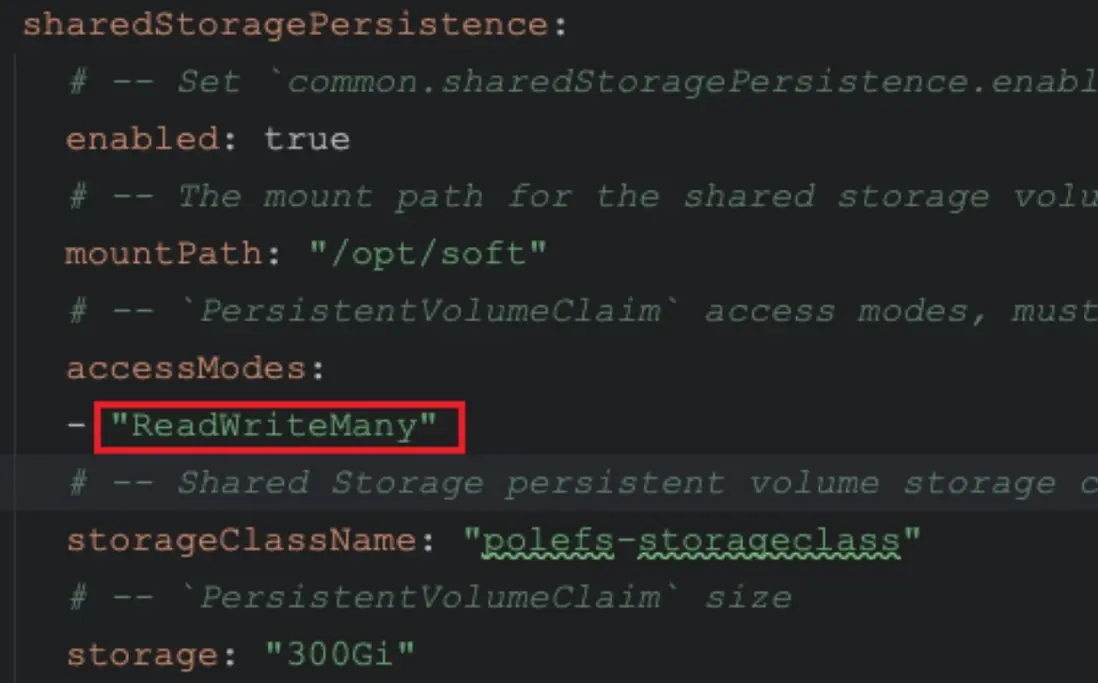
4. 共享存儲配置
sharedStoragePersistence:
enabled: true
storageClassName: nfs-rwx
size: 100Gi
mountPath: /dolphinscheduler/shared👉 注意:storageClassName 必須支持 ReadWriteMany,否則多個 Worker 節點無法同時訪問共享目錄。
5. HDFS 配置
hdfs:
defaultFS: hdfs://hdfs-nn:8020
path: /dolphinscheduler
rootUser: hdfs👉 所有大數據相關組件路徑需要提前準備好,例如 /opt/soft。
6. Zookeeper 配置
zookeeper:
enabled: false # 關閉內置 ZK
externalZookeeper:
quorum: zk1.prod.local:2181,zk2.prod.local:2181,zk3.prod.local:2181👉 使用外置 Zookeeper 時,記得關閉內置配置,同時確認 ZK 版本符合官方最低要求。
踩坑經驗與維護挑戰
在整個遷移過程中,我們踩過的坑不少。比如,鏡像製作問題、Helm values.yaml 修改的坑,以及定製化升級和維護成本過高等。
鏡像製作相關問題
- 鏡像製作時因為基礎鏡像太大,導致構建過程漫長;
- 模塊依賴差異導致重複安裝;
- 有時候 MySQL 驅動包路徑不正確,模塊啓動時報錯;
- 源碼改造後的 jar 包忘記覆蓋舊文件,也曾造成過運行時異常,不同模塊端口與啓動腳本不一致,導致啓動不順利。
Helm values.yaml注意點
- sharedStoragePersistence.storageClassName 必須支持 ReadWriteMany存儲類
- storage 大小
- mountPath 與配置文件不一致
- 配置項路徑縮進
- 關閉默認配置以及一些不需要的配置,例如Zookeeper 外置時需關閉內置選項,同時注意zk需要的版本
維護升級成本
更大的挑戰來自後續維護。因為我們對源碼和鏡像做過定製化修改,所以每當 DolphinScheduler 發佈新版本,我們都需要重新對比修改點,重新構建並測試全部模塊鏡像。
同時,由於不同版本之間配置項差異較大,升級和回滾的過程都容易出錯。這些問題導致我們的升級週期變長,維護難度加大,團隊人力成本也顯著上升。
未來規劃與思考
為了降低長期的運維成本,我們已經在逐步推進標準化。未來計劃包括:
將 DolphinScheduler 的元數據庫從 MySQL 切換到 PostgreSQL,全面採用社區官方鏡像而非自研鏡像,生產任務也會逐步遷移到 K8S 環境中。
同時,我們會引入 CI/CD 流程,並結合 Prometheus 與 Grafana 做可觀測性建設,提升部署效率與監控能力。
總的來説,K8S 部署讓 DolphinScheduler 在擴展性、彈性和遷移性上具備了遠超物理機的優勢。雖然鏡像定製化和配置修改帶來了不小的挑戰,但隨着我們逐漸迴歸社區版本和標準化運維,維護成本會越來越低,部署效率會越來越高。
我們的長期目標,是構建一個高可用、易擴展、統一化的調度平台,真正釋放雲原生的價值。如果你也在考慮把調度系統搬上 K8s,歡迎評論區交流,或加入 DolphinScheduler 社區一起搬磚!









