









隨着人工智能技術的飛速發展,用户對於搜索體驗的要求早已超越了傳統的關鍵詞匹配。我們正處在一個從文本搜索向多模態、跨模態搜索演進的時代。用户希望能夠通過圖片、甚至是自然語言描述的複雜場景,來精準地找到他們想要的商品。然而,如何理解並檢索圖片中的視覺元素?如何處理那些文本標題無法完全概括的商品特徵?這些都是傳統搜索面臨的挑戰。
本文將深入探討多模態商品檢索的通用解決方案,詳細解讀其背後的兩大核心技術:Embedding(向量化)與向量檢索。我們將從稠密與稀疏模型,到歐氏距離、餘弦相似度,再到HNSW算法與BBQ量化等關鍵技術,逐一揭開多模態搜索的神秘面紗。
更重要的是,本文將結合阿里雲的創新產品——AI搜索開放平台與Elasticsearch Serverless,展示如何將理論付諸實踐,快速、低成本地搭建一套功能強大、性能卓越的多模態商品搜索系統。我們將分享Elasticsearch Serverless在免運維、低成本、高彈性以及與AI模型無縫集成等方面的獨特優勢,並通過一個完整的Demo演示,帶你端到端地體驗從數據處理到最終檢索的全過程。
一、多模態商品檢索解決方案
1. 搜索場景的演進
在日常的電商平台中,我們對文本搜索場景非常熟悉。例如,當用户搜索“連衣裙”時,其目標明確,就是希望購買一件合適的裙子或瞭解最新款式。又如,搜索“nike澀谷限定”,這表明用户可能對耐克在特定商圈發售的某些定製款感興趣,關鍵詞中包含了品牌、地點和限定屬性。
然而,純文本搜索存在明顯的痛點。想象一個場景:你在酒店發現一款設計獨特的吹風機,卻不知道其品牌和型號。此時,你最直觀的需求是“以圖搜圖”,通過拍攝的照片來查找同款商品。這種即時性的、基於視覺的查詢需求,是傳統文本檢索難以滿足的。
另一個痛點在於商品視覺元素的缺失。例如一件印有卡通恐龍圖案的綠色兒童短褲,其標題和簡介可能只會描述為“男童短褲”,卻無法體現“綠色”、“卡通”、“恐龍”這些對消費者(尤其是給孩子買衣服的家長)極具吸引力的視覺特徵。
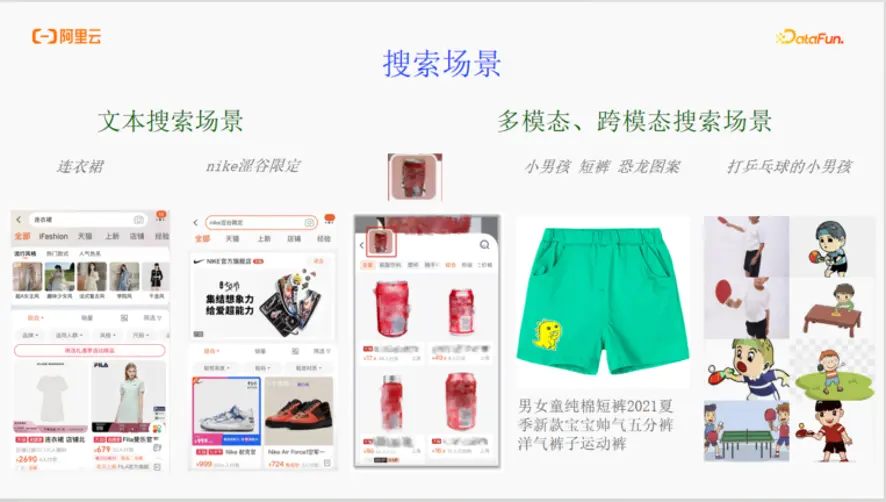
多模態與跨模態搜索正是為了解決這些問題而生。它允許用户使用更自然的、多維度的方式進行查詢。比如,用户可以直接輸入“打乒乓球的小男孩”,系統需要在海量的圖片素材中,精準地找出符合這一場景描述的圖片,這極大地提升了搜索的精準度和用户體驗。
2. 通用的商品檢索解決方案架構
一個通用的多模態商品檢索解決方案,其核心在於如何處理和融合不同類型的數據。其整體架構可以概括如下:
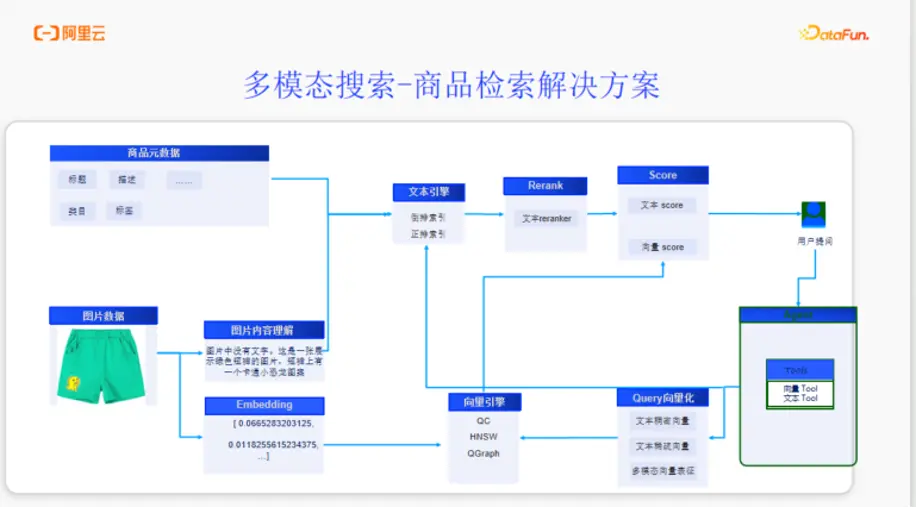
數據處理層:
- 商品元數據處理(結構化文本):
- 數據源:包括商品的標題、描述、類目、標籤等結構化文本信息。
- 處理流程:對這些文本數據進行分詞處理,然後構建倒排索引,存入文本引擎中。這是傳統搜索的基礎。
- 圖片數據處理(非結構化數據):
- 處理流程一:圖片內容理解
通過多模態大模型對圖片進行“解讀”,生成描述性文本。例如,對於上述的綠色短褲,模型可以生成描述:“這是一張展示綠色短褲的圖片,短褲上有一個卡通小恐龍圖案”。
這段生成的文本同樣可以作為結構化數據,經過分詞後存入文本引擎。
- 處理流程二:Embedding(向量化)
利用Embedding技術,將圖片本身轉換為高維度的數學向量(Vector)。
這個向量可以被認為是圖片在數學空間中的“座標”,它藴含了圖片深層次的視覺特徵。
生成的向量數據被存儲在向量引擎中。
通過以上步驟,一件商品的數據就被解構為兩部分:一部分是存儲在文本引擎中的文本信息,另一部分是存儲在向量引擎中的向量信息。
- 查詢與召回層:
當用户發起查詢時,系統會根據查詢類型進行多路召回:
文本查詢:
- 文本匹配:用户的查詢關鍵詞會直接在文本引擎中進行匹配,召回相關的商品。
- 語義匹配:同時,用户的查詢文本也會通過Embedding技術轉換為查詢向量,然後在向量引擎中尋找與之最相似的商品向量。
- 圖片查詢:
- 用户上傳的圖片會被轉換成查詢向量。
- 系統使用這個查詢向量在向量引擎中進行相似度檢索,召回視覺上最接近的商品。
- 融合與排序層:
- Rerank & Score:來自文本引擎和向量引擎的多路召回結果,會經過一個重排序(Rerank)模塊。該模塊會綜合考慮文本相關性得分和向量相似度得分,對結果進行最終排序。
- 結果返回:將排序後的Top N結果呈現給用户。
這個架構的精髓在於,它結合了文本引擎的精確匹配能力和向量引擎的語義及視覺 相似度檢索能力,從而實現了真正意義上的多模態搜索。
二、多模態商品檢索關鍵技術
要實現上述解決方案,離不開兩大核心技術:Embedding(向量化)和向量檢索。
1. 關鍵技術一:Embedding(向量化技術)
Embedding的本質,是將真實世界中非結構化的數據(如文本、圖像)映射、轉換為機器可以理解和計算的結構化數據——向量。
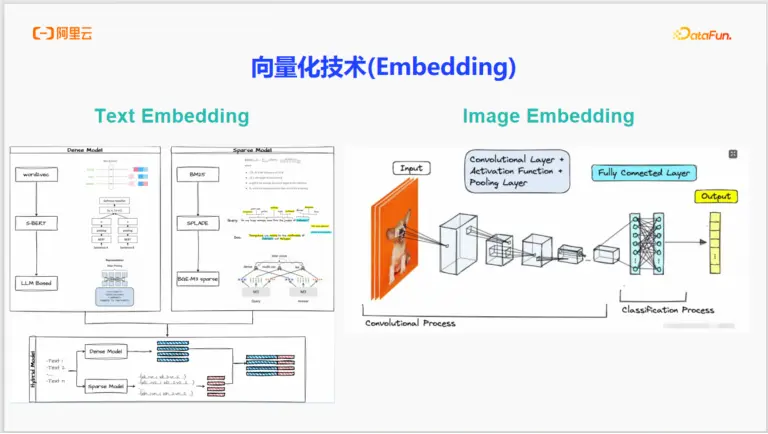
Text Embedding (文本向量化)
文本向量化技術經歷了多個發展階段,目前主流的模型可分為三類:
- Dense Model (稠密模型):
特點:將文本轉換為稠密向量,向量中的絕大多數元素都是非零值。這種向量能很好地捕捉文本的深層語義相關性。例如,“國王”和“女王”在語義上相近,它們的稠密向量在空間中的距離也會很近。
代表模型:Word2vec、S-BERT、以及基於大語言模型(LLM)的各類模型。
- Sparse Model (稀疏模型):
特點:將文本轉換為稀疏向量,向量中只有極少數元素是非零的,大部分為零。它更側重於詞彙級別的精確匹配,類似於傳統搜索中的“詞袋模型”的升級版。
代表模型:BM25、SPLADE。
- Hybrid Model (混合模型):
特點:這是當前效果最優、最受關注的模型。它巧妙地結合了稠密模型和稀疏模型的優點。對於一個輸入文本,它會同時生成一個稠密向量和一個稀疏向量。
優勢:最終得到的混合表徵既包含了語義的泛化能力(來自稠密向量),又具備了關鍵詞的精確匹配能力(來自稀疏向量),在各類評測中顯著優於單一模型。
Image Embedding (圖像向量化)
圖像向量化主要藉助深度神經網絡,特別是卷積神經網絡(CNN)。其過程可以通俗地理解為:圖片作為輸入,經過多層卷積層、激活函數和池化層的“特徵提取”,將圖片從像素矩陣一步步抽象,最終通過全連接層映射成一個低維度的特徵向量。這個向量就是這張圖片的高度濃縮的數學表達。
2. 關鍵技術二:向量檢索
向量檢索的核心思想是:在由海量向量構成的數學空間中,給定一個查詢向量,快速、準確地找到與它“距離”最近的K個鄰居(K-Nearest Neighbors, KNN)。這裏的“距離”代表了相似度。

向量相似度度量
衡量兩個向量有多“近”,主要有以下幾種方式:
- 歐氏距離 (Euclidean Distance, L2 Norm):
定義:即空間中兩點之間的直線距離。距離越小,代表兩個向量越相似。
得分轉換:在搜索引擎中,通常會將其轉換為一個0到1之間的歸一化得分,公式如1 / (1 + L2_norm^2),這樣距離越小,得分越高,更符合搜索排序的直覺。
- 點積 (Dot Product):
定義:兩個向量對應維度相乘後求和。
特點:如果所有向量都經過歸一化(長度為1),點積的結果等價於餘弦相似度。通常,點積越大,相似度越高。
- 餘弦相似度 (Cosine Similarity):
定義:計算兩個向量在方向上的夾角的餘弦值。它衡量的是方向上的一致性,而不在乎絕對大小。
特點:取值範圍在-1到1之間。值為1表示方向完全相同,為-1表示方向完全相反,為0表示正交(不相關)。這是向量檢索中最常用的相似度度量之一。
ES對向量功能的支持
Elasticsearch作為業界領先的搜索引擎,近年來在向量檢索領域發展迅猛,提供了全方位的支持:

- 字段類型:
dense_vector:用於存儲稠密向量。
sparse_vector:用於存儲稀疏向量,能夠高效處理高維、稀疏的數據。
semantic_text:一個更高級的抽象類型,可以根據配置的推理模型,自動將文本輸入映射為相應的向量類型。
原生AI能力:
Inference API:允許ES直接調用外部的AI模型(如Embedding模型),實現數據在索引或查詢時的實時向量化。
Ingest Pipeline:在數據寫入時,可以通過text_embedding處理器或inference處理器,自動將文本字段轉換為向量並存入索引,極大地簡化了數據處理流程。
- 檢索語法:
kNN Search:原生的近似最近鄰搜索API,用於在dense_vector字段上進行高效的向量檢索。
混合搜索 (Hybrid Search):允許在一次查詢中同時執行傳統的全文檢索(如match查詢)和kNN向量檢索。但一個挑戰是如何平衡兩種不同來源、不同度量衡的分數。
RRF (Reciprocal Rank Fusion):為了解決混合搜索中的分數融合難題,ES引入了RRF。RRF不關心原始分數的大小,只關心文檔在不同召回結果集中的“排名”。它通過對排名的倒數進行加權求和,來得到最終的融合排序,是一種更魯棒的混合排序策略。
3. 向量檢索的性能優化:量化技術
向量檢索,尤其是處理海量數據時,最大的瓶頸之一是內存消耗。一個高維(如1024維)的float32向量本身就佔用大量空間,而用於加速檢索的HNSW圖索引也需要消耗可觀的內存。因此,向量量化技術應運而生。
- 標量量化 (Scalar Quantization, SQ):
原理:其核心思想是“降維打擊”,將高精度的float32(4字節)數值,量化為低精度的int8(1字節)甚至更低。它通過分析一個數據段(Segment)內某一維度上所有向量值的最大值和最小值,然後按比例將float32值映射到int8的-127到127範圍內。
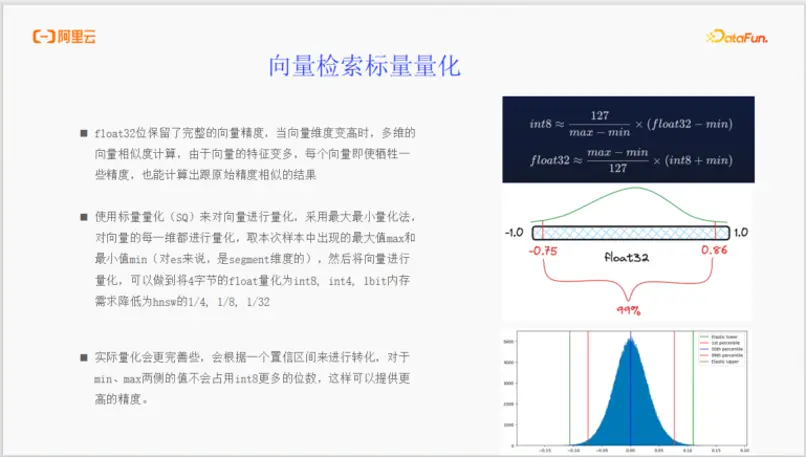
效果:通過SQ,向量本身佔用的內存可以輕鬆降低為原來的1/4(int8)或1/8(int4),在犧牲可控精度的前提下,大幅節省內存。
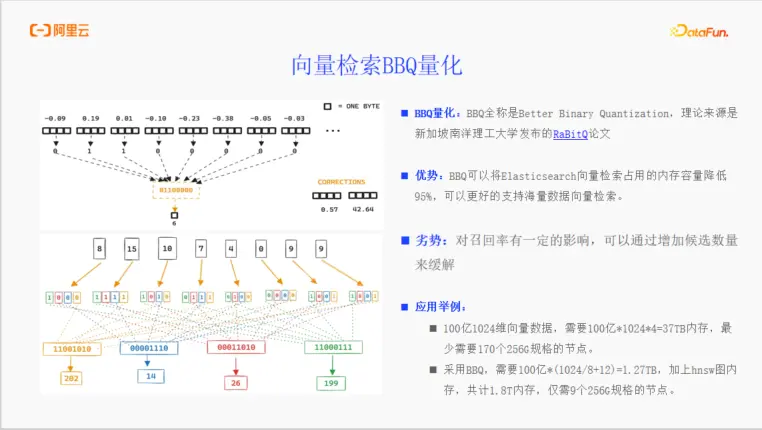
- BBQ (Better Binary Quantization):
背景:BBQ技術源自南洋理工大學的研究論文,是ES在向量量化領域的又一重大突破。
優勢:BBQ可以在SQ的基礎上,將向量檢索佔用的內存再降低高達95%。這使得在Elasticsearch中進行百億級別的海量向量檢索成為可能。
劣勢與應對:天下沒有免費的午餐。BBQ以極低的內存佔用為代價,犧牲了一定的召回率。但在實際應用中,可以通過適度增加kNN查詢的候選集數量(num_candidates)等方法,來有效緩解召回率的下降。
應用舉例:一個100億條1024維float32向量的數據集,原始存儲需要約37TB內存。而採用BBQ量化後,加上HNSW圖內存,總內存需求可降至約1.8TB,所需計算節點數量從170個驟降至9個,成本效益極高。在BBQ的加持下,HNSW圖索引的內存佔比反而成為了主要部分。
三、基於Elasticsearch Serverless的最佳實踐
理論的先進性最終要通過實踐來檢驗。我們將介紹如何基於阿里雲的兩大產品——AI搜索開放平台和Elasticsearch Serverless,構建一套高效、易用的多模態商品搜索系統。
1. 整體實踐架構
我們的最佳實踐架構如下:
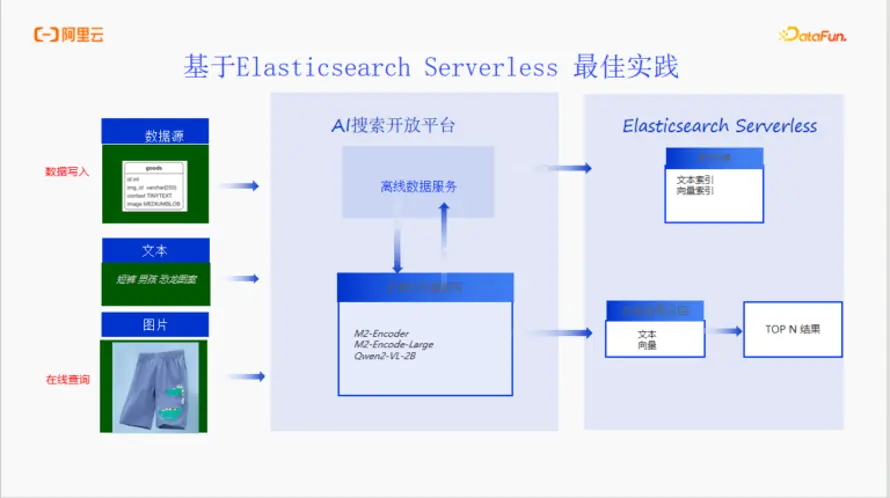
數據源:商品數據存儲在雲數據庫RDS中,包含商品ID、文本描述和圖片信息。
AI搜索開放平台:
離線數據服務:負責從RDS中抽取數據。
多模態向量服務:調用平台內置的AI模型(如M2-Encoder、Qwen2-VL等),將商品的文本和圖片數據統一轉換為多模態向量。
數據寫入:將處理好的文本數據和向量數據寫入Elasticsearch Serverless。
Elasticsearch Serverless:
作為核心的文本引擎和向量引擎,存儲商品的文本索引和向量索引。
在線查詢:
用户通過前端應用發起查詢(文本或圖片)。
查詢請求經過AI搜索開放平台的多模態向量服務進行向量化。
向量化的查詢請求被髮送到Elasticsearch Serverless進行多路召回(文本+向量)。
ES返回Top N結果,最終呈現給用户。
2. 阿里雲AI搜索開放平台
這是一個一站式的、企業級的AI搜索解決方案平台,其分層架構清晰,功能強大:

底層(數據源與管理):支持多種數據源接入,包括對象存儲(OSS)、數據庫(MySQL)、數據湖(Hudi, Iceberg)和大數據計算平台(MaxCompute)等。
中層(核心服務與生態):
搜索微服務:提供文檔解析、多模態解析、向量化、Rerank、LLM推理、LLM Agent等一系列原子化的AI能力。
開放框架與生態:無縫對接LangChain、LlamaIndex等主流開發框架,並支持集成多種向量數據庫(如Milvus、Havenask以及Elasticsearch)。
上層(應用開發與部署):提供AI搜索應用場景的快速開發能力,並支持通過函數計算(FC)、PAI等多種方式進行應用部署。
該平台預置了豐富的AI模型,如文檔解析、圖片解析、文本向量化、多模態向量化、Reranker、大模型生成等,並且提供了“體驗中心”,讓開發者可以快速驗證模型效果,例如輸入文本或上傳圖片,即可看到其生成的向量結果。
3. Elasticsearch Serverless
這是阿里雲上的一種全託管、智能化的Elasticsearch服務形態,它與傳統的IaaS/PaaS模式有着本質區別,為多模態搜索場景提供了極致的便利。
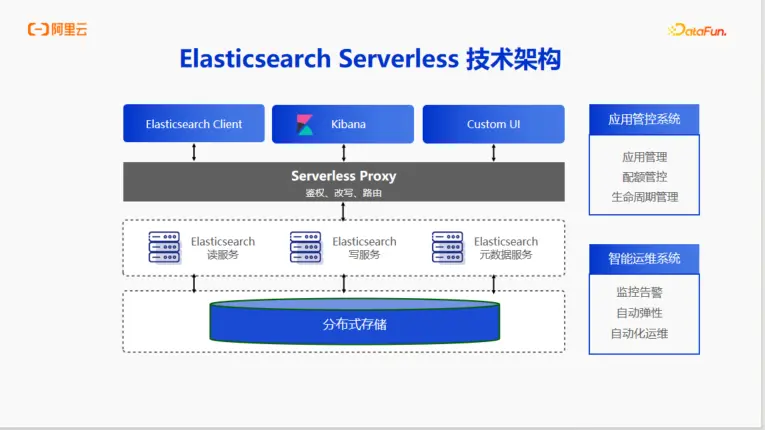
技術架構
其核心是一個Serverless Proxy,它對用户屏蔽了底層集羣的複雜性,負責鑑權、路由和請求改寫。Proxy後面是讀寫分離的Elasticsearch服務集羣和元數據服務,底層基於分佈式存儲。整個系統由應用管控系統和智能運維繫統進行管理和調度,實現了從資源到運維的全方位自動化。
核心優勢
優勢一:免運維
版本無感:用户無需再為追趕ES社區日新月異的向量功能版本而煩惱,也無需擔心安全漏洞。Serverless平台會自動保持內核的最新和最優化。
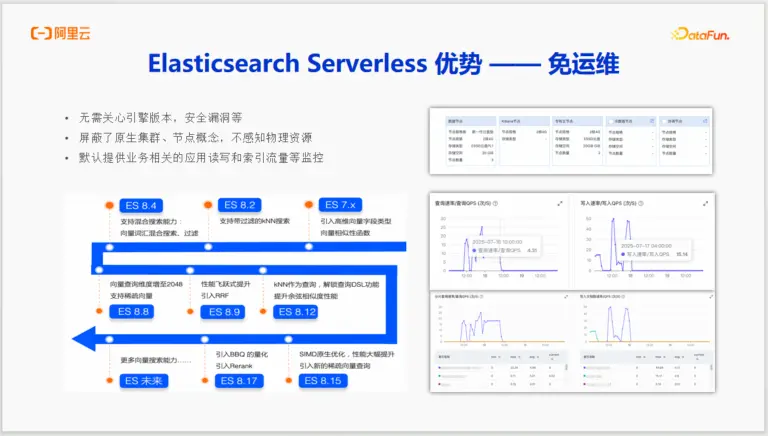
資源無感:徹底屏蔽了集羣、節點、分片、規格配置等複雜的物理概念。用户面對的只是一個邏輯上的“應用”,無需進行容量規劃。
開箱即用的監控:默認提供面向業務的應用讀寫QPS、索引流量等核心指標監控。
優勢二:低成本
極低的接入成本:創建一個Serverless應用僅需數秒,即可獲得訪問地址和配套的Kibana。對於需要快速迭代驗證算法的開發者來説,這是巨大的便利。
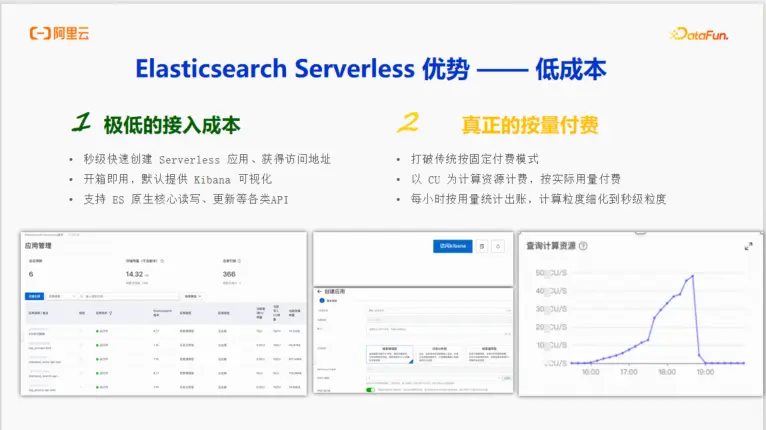
真正的按量付費:打破了傳統包年包月的固定付費模式。以CU(Compute Unit)為計算資源單位,按實際使用量計費,計費粒度細化到秒級,完美匹配業務流量的潮汐變化,杜絕資源浪費。
優勢三:高彈性
資源自動擴縮:系統會根據應用的實時和歷史負載水位,動態、透明地調配底層資源。當業務高峯來臨時,資源會自動擴容以支撐流量;當流量回落時,資源會自動縮減以節約成本。
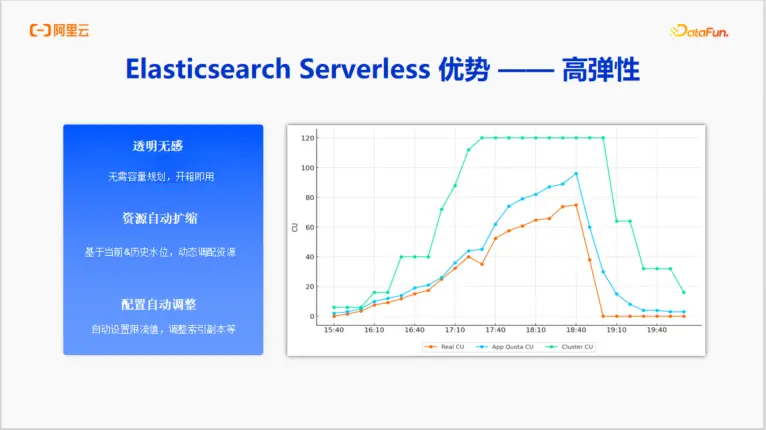
配置自動調整:除了計算資源,系統還會智能地調整索引副本數、限流閾值等配置,以達到最佳性能和穩定性的平衡。
優勢四:無縫集成AI模型
AI模型開箱即用:Serverless應用無縫集成了AI搜索開放平台上的所有模型,用户可以直接在ES內部通過Inference API調用它們。

支持自定義模型:更強大的是,它允許用户接入自己的、或第三方的優秀模型。只需通過簡單的API配置,即可將任意外部模型集成到ES的Inference體系中,這為算法的靈活性和先進性提供了無限可能。
優勢五:向量場景深度優化
智能過濾向量字段:默認在_source中排除向量字段,節省存儲和傳輸資源,避免不必要的數據暴露。

向量默認量化策略:用户可以一鍵開啓int8或BBQ等默認量化策略,無需關心底層實現細節,即可享受量化帶來的內存和成本優勢。
向量自適應預熱:系統會自動將不同類型的向量索引文件(HNSW圖、量化向量等)預加載到文件系統緩存中,減少首次查詢的冷啓動延遲,提升高併發場景下的響應穩定性和吞吐量。
四、Demo演示(視頻)
下面,我們將通過一個端到端的Demo,展示如何利用上述技術和產品,快速搭建一個多模態商品搜索應用。
https://cloud.video.taobao.com/vod/tdfPHRjQuVpfWaqoT6HSJx-4ZBge4dydtV_RcBUWl5s.mp4

