









本文詳細介紹瞭如何使用 PAI-LangStudio 和 Qwen3 構建基於AI搜索開放平台 x ElasticSearch 的 AI Search RAG 智能檢索應用。該應用通過使用 AI 搜索開放平台、ElasticSearch 全文檢索+向量檢索引擎的混合檢索技術配合阿里雲最新發布的 Qwen3 推理模型編排在一個 Agentic Workflow 中,為客户提供了業內領先的 AI Search RAG 檢索應用能力,使用 NLP 自然語言即可實現 AI Search 的精準查詢可靠效果。開發者可以基於該模板進行靈活擴展和二次開發,以滿足特定場景的需求。
實踐背景
本文是基於 PAI-LangStudio x AI 搜索開放平台 x ElasticSearch 來構建業內領先且功能強大的一站式 AI Search 智能混合檢索 RAG 智能應用方案。下面介紹如何完成場景實操:
前提條件
- 已創建專有網絡 VPC、交換機和安全組。具體操作,請參見搭建IPv4專有網絡和創建安全組。
- 登錄PAI 控制枱,在左側導航欄單擊工作空間列表(如無 已有工作空間列表)。在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。如您尚未創建工作空間,請創建工作空間。
- 登錄AI搜索開放平台,獲取 Endoint 和 API-Key。
- 登錄Elasticsearch控制枱,創建 Elasticsearch 實例,並進行安全訪問配置(如可打開“使用HTTPS協議”選項以增強安全性)。
場景部署步驟
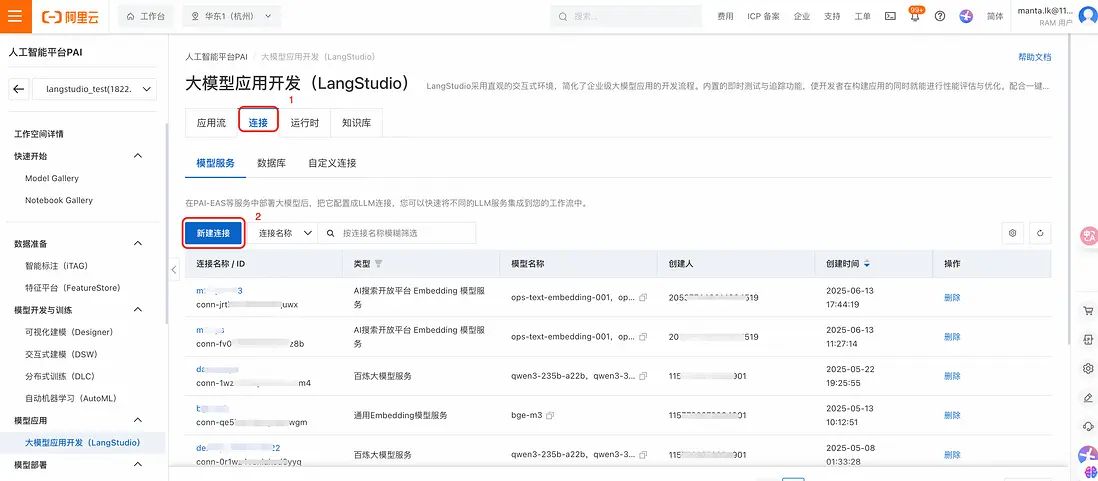
步驟一:在PAI-LangStudio中添加模型服務連接:
- 通過 PAI控制枱 > 進入PAI-LangStudio >連接 > 模型服務 >新建連接:
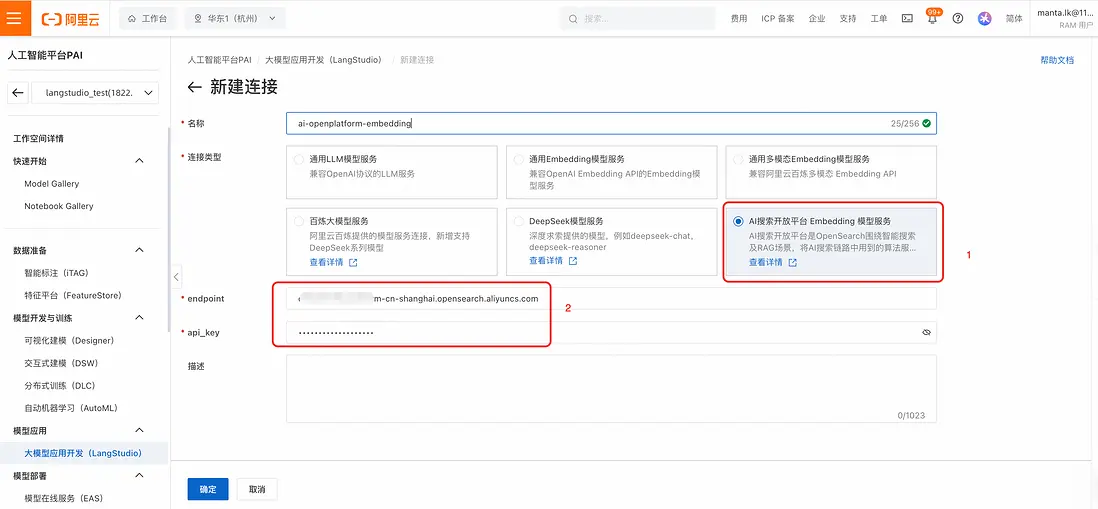
- 選擇 “AI搜索開放平台 Embedding 模型服務”,並填入從AI搜索開放平台獲取到的 Endpoint 和api_key,創建模型服務連接:
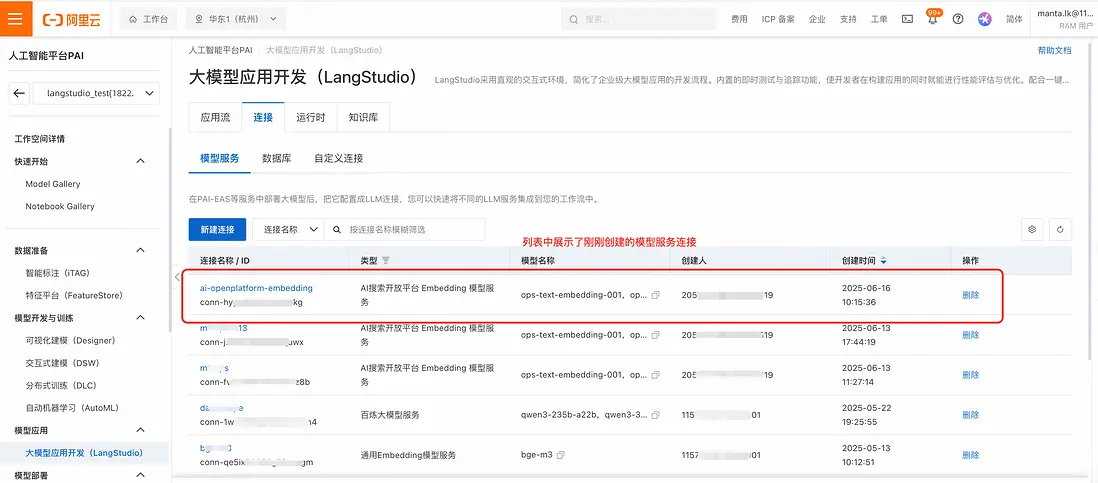
- 創建好後,可以在列表頁看到剛剛創建的AI搜索開放平台Embedding模型服務連接:
步驟二:在PAI-LangStudio中新建數據庫連接
- 在PAI-LangStudio中,選擇“連接” -> “數據庫” 標籤頁後,點擊“新建連接”:
- 填入在Elasticsearch控制枱中查看到的Elasticsearch實例的地址和用户名、密碼(注意如果Elasticsearch未開啓HTTPS連接,此處url需要填寫 http:// 頭)後,點擊確定:
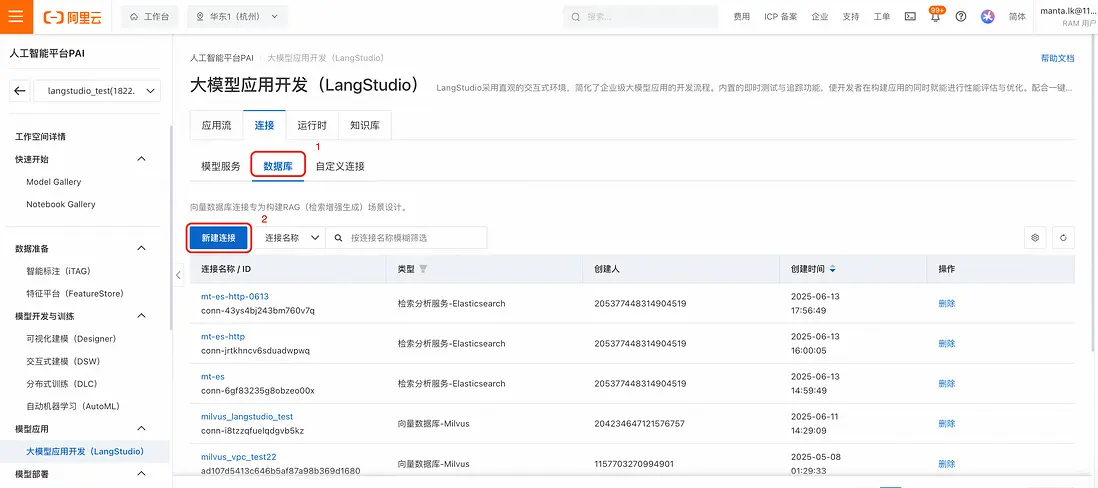
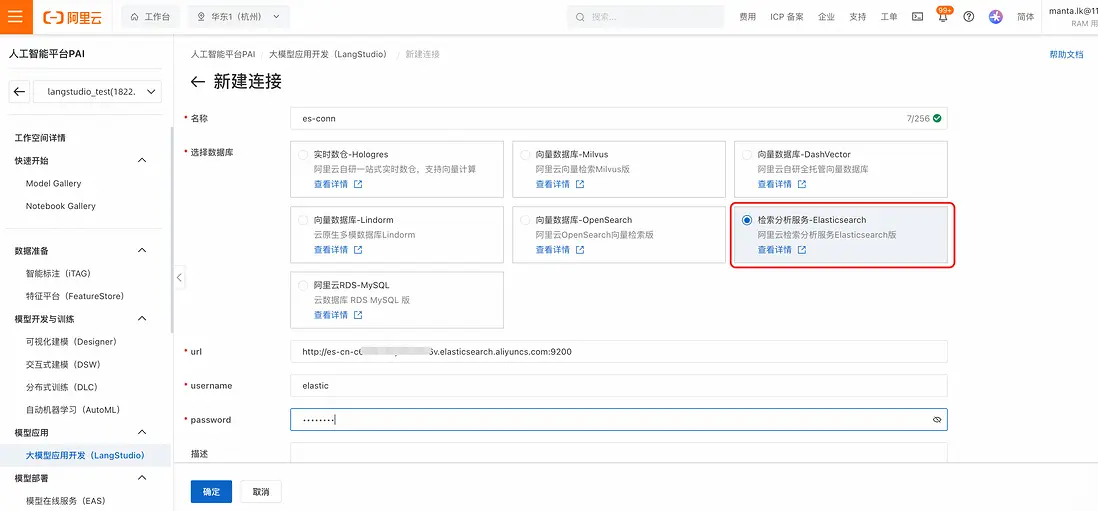
此時在連接列表中可以看到剛剛添加的數據庫連接:
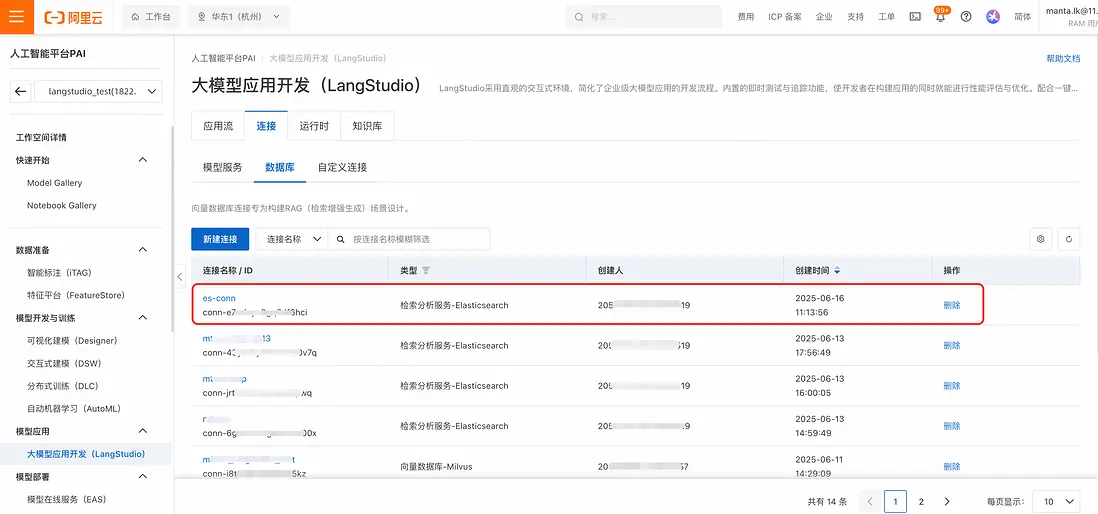
步驟三:新建PAI-LangStudio運行時相關信息
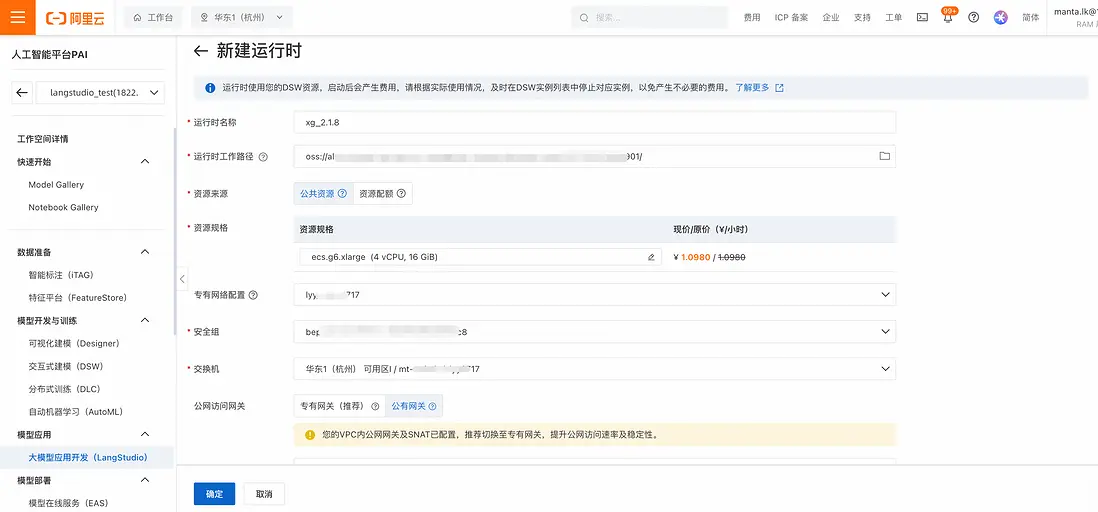
- "運行時"設置確認。在PAI-LangStudio中選擇“運行時”標籤頁,點擊“新建運行時”,填入必要的信息如:運行時工作路徑(選擇OSSbucket中一個目錄)、專有網絡、安全組與交換機信息(需要跟Elasticsearch所在網絡暢通)後點擊“確定”:
- 之後可以在運行時列表中看到該運行時。
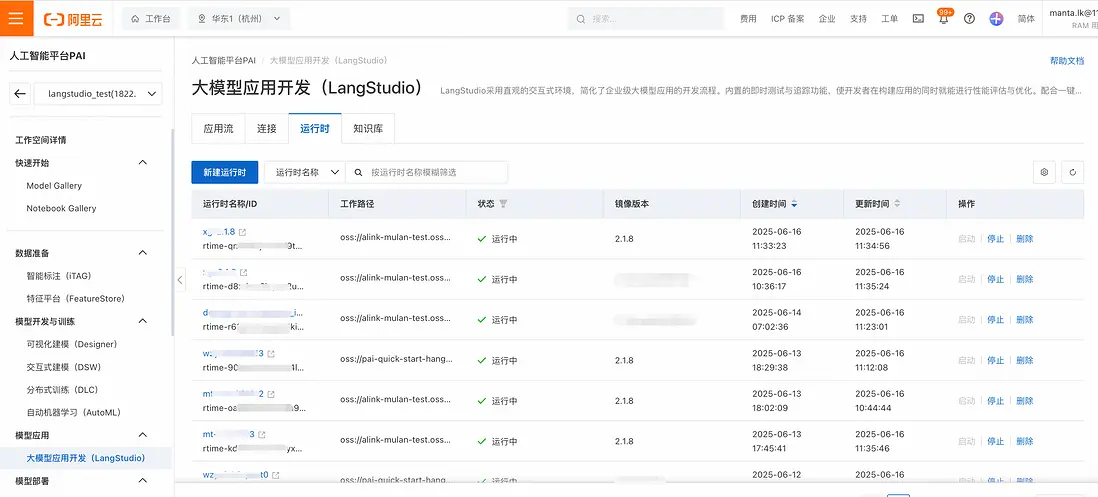
步驟四:在PAI-LangStudio中創建知識庫
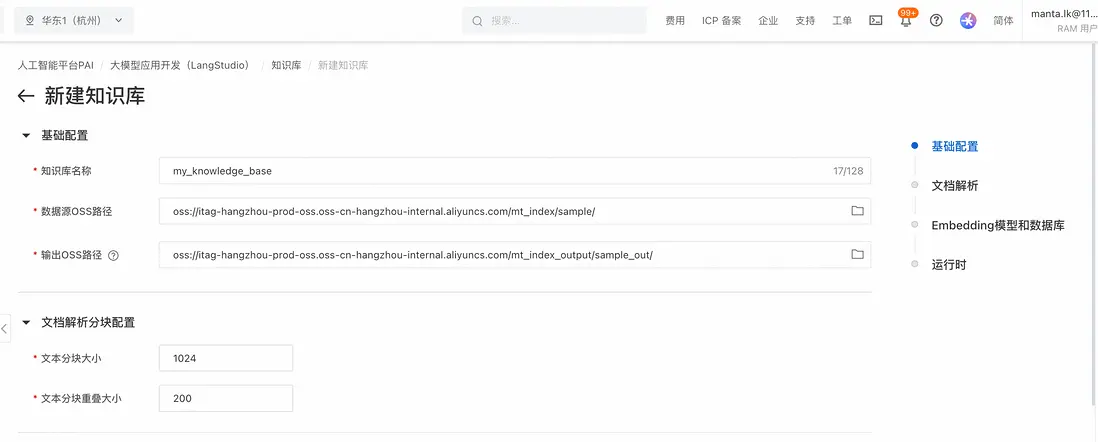
- 在PAI-LangStudio中,選擇“知識庫”標籤頁,並點擊“新建知識庫”,選擇文檔所在OSS路徑作為“數據源OSS路徑”,並選擇一個“輸出OSS路徑”用來保存文檔解析處理中間結果和索引相關信息:
- 選擇 “AI搜索開放平台 Embedding 模型服務”標籤,並選擇步驟一中創建的模型服務連接後,可以選擇具體支持的Embedding模型(其中 001模型 和 002模型維度不同,可用於不同場景選擇);選擇步驟二中創建的向量數據庫連接,並填入一個向量數據庫索引名,選擇步驟5中創建的運行時後,點擊確定:
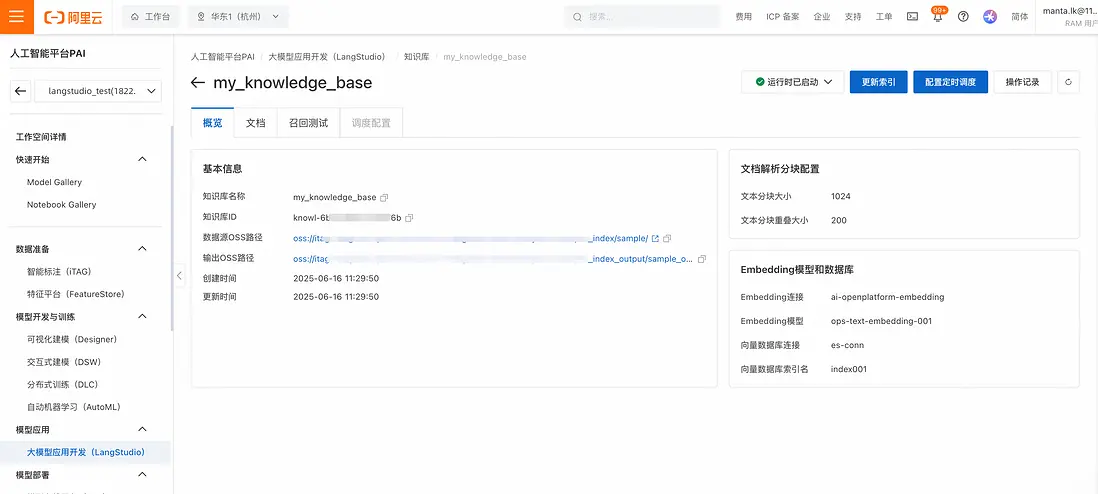
- 之後可以在知識庫列表中看到剛剛創建的知識庫。點擊知識庫名稱後,可以查看知識庫概覽、文檔查看,以及進行召回測試:
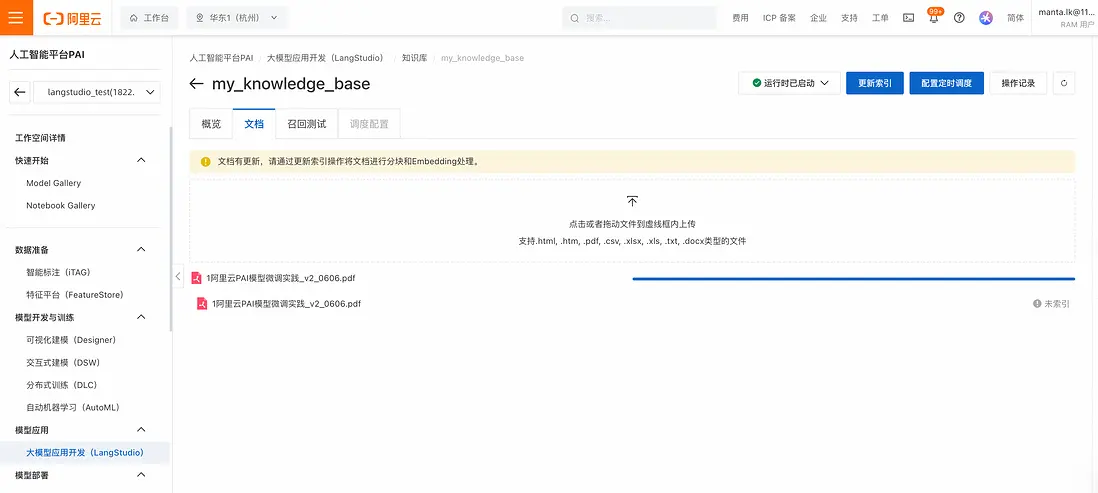
- 在“文檔”標籤頁,可以通過拖拽方式將本地文件上傳至OSS中:
- 在文檔上傳後,點擊“更新索引”按鈕,在彈出的浮窗中選擇網絡和安全組資源配置後,點擊“確定”,即可開始進行知識庫索引的更新:

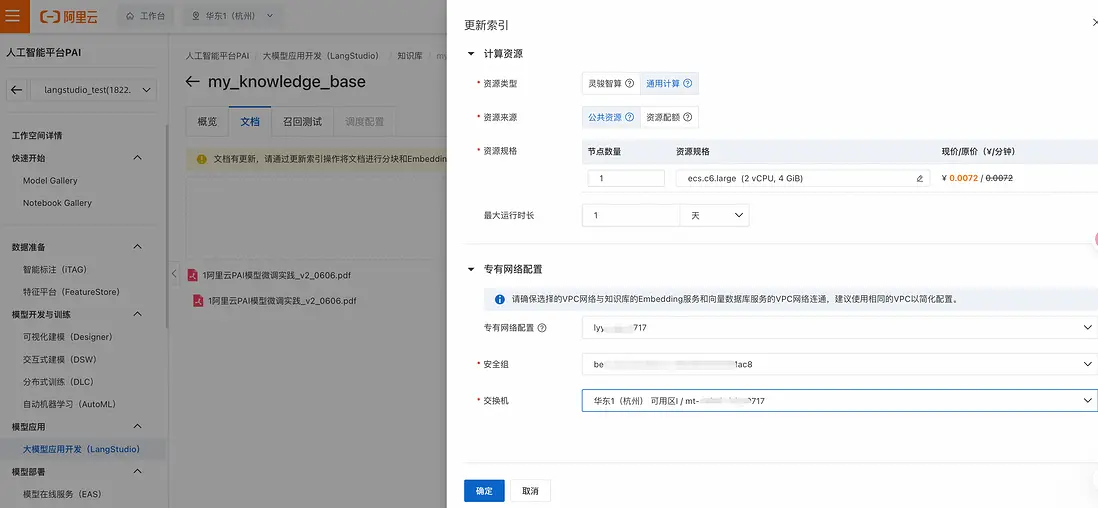
此時可以看到有一個索引創建的任務在運行中(也可以通過知識庫->操作記錄查看任務):
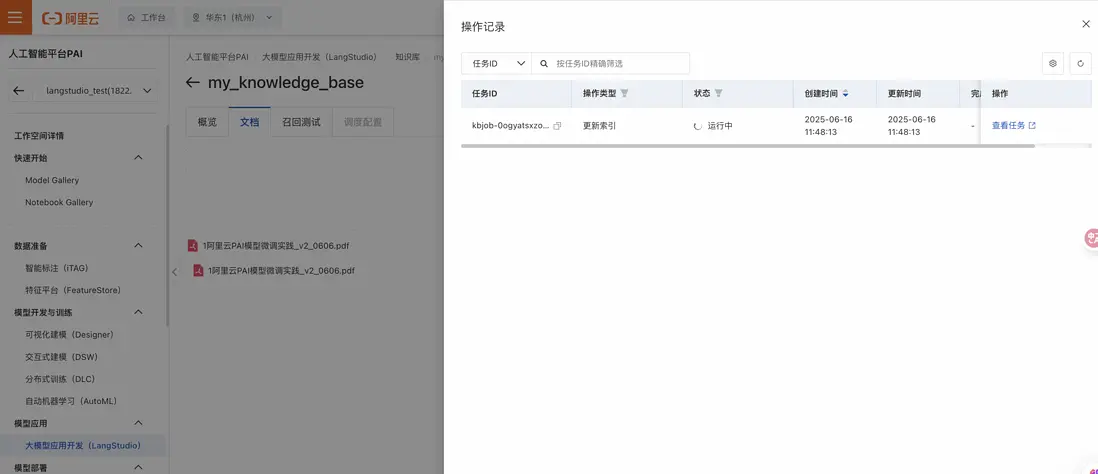
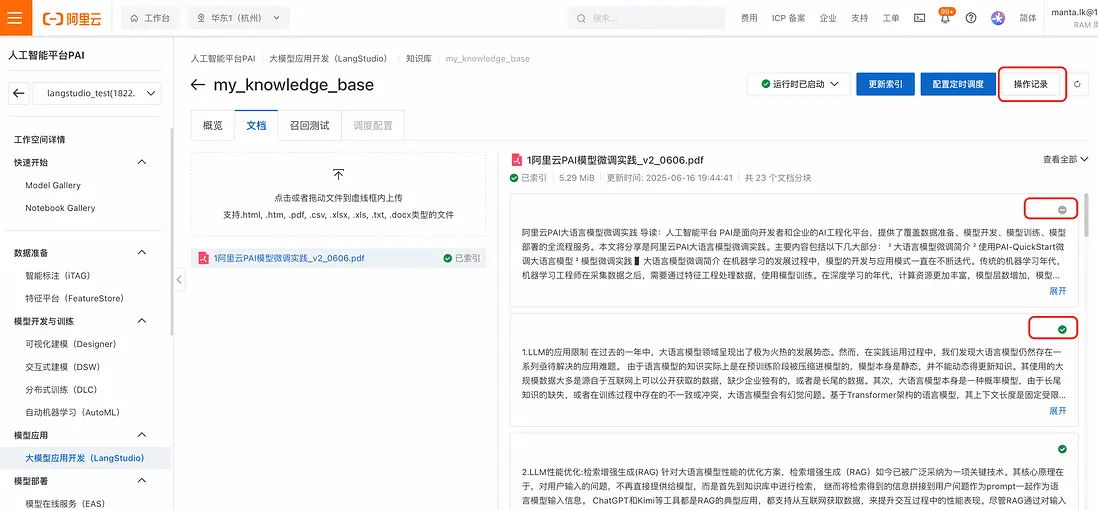
等待幾分鐘後,索引構建完畢。此時刷新文檔標籤頁,可以看到文檔從“未索引”狀態 變為“已索引”。點擊列表中的文檔名稱,可以看到該文檔的分塊情況,以及每個文檔塊的使能與否。通過點擊文檔分塊中的✅ 標記,也可以對該文檔塊進行enable/disable操作。當文檔分塊被disable後,進行召回時將忽略該文檔塊:
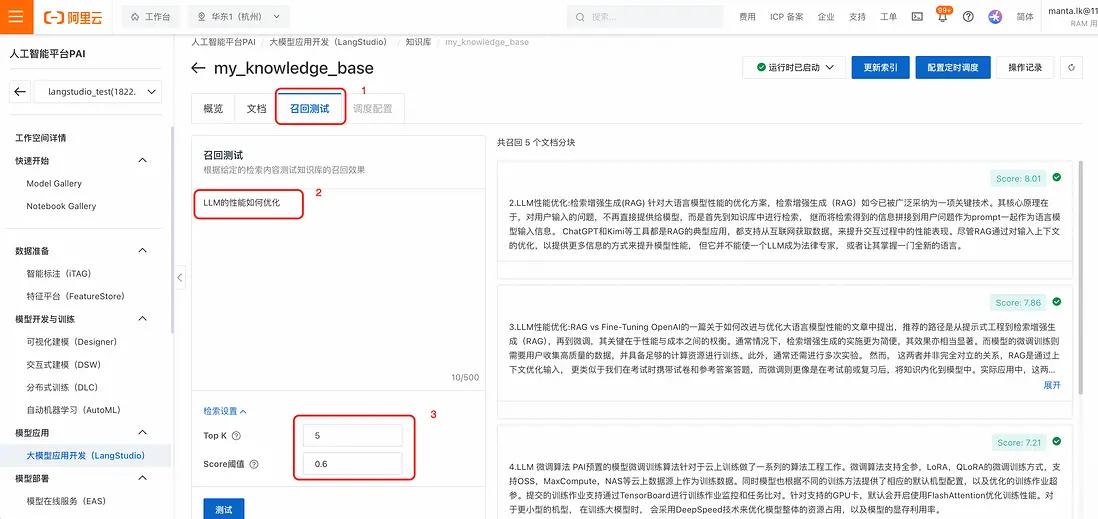
- 在PAI-LangStudio的新版知識庫中,選擇“召回測試”標籤,輸入問題,設置檢索條件(建議score閾值在0.5-0.6之間)後,點擊“測試”,可以在右側看到召回結果:
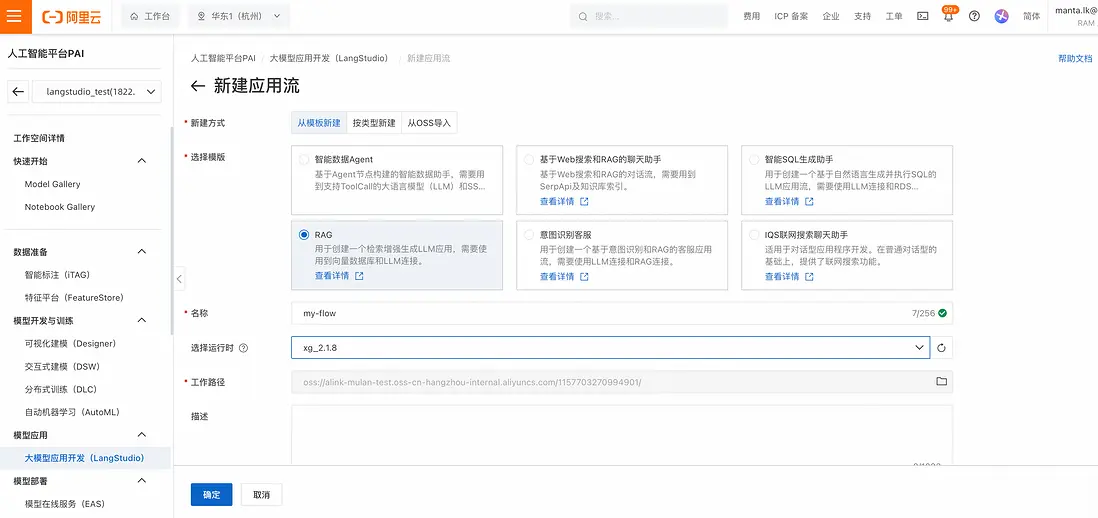
步驟五:在應用流中使用RAG知識庫
- 在PAI-LangStudio的“應用流”標籤點擊“新建應用流”,選擇“從模板新建” -> “RAG”模板,創建應用流:
之後自動跳轉至應用流界面:
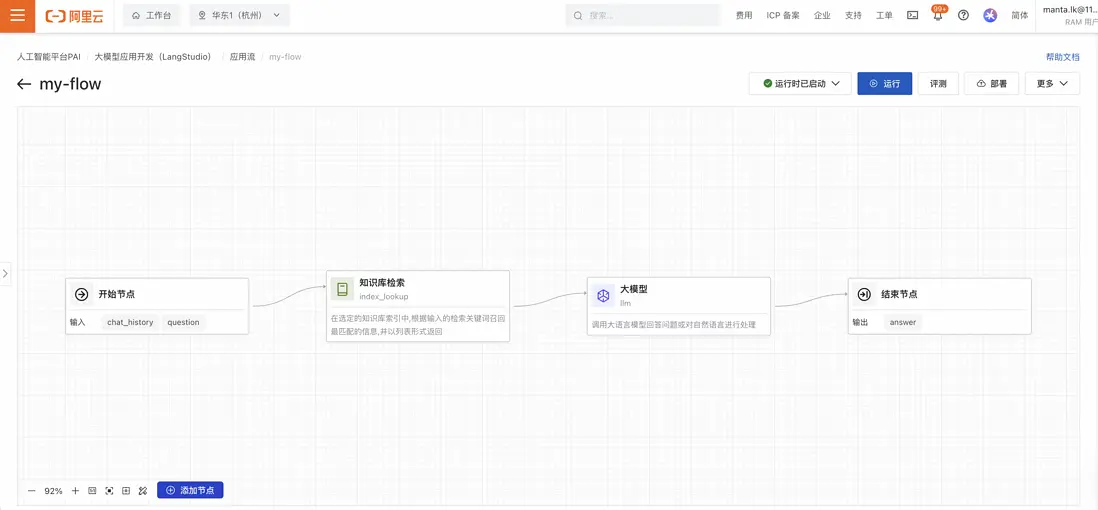
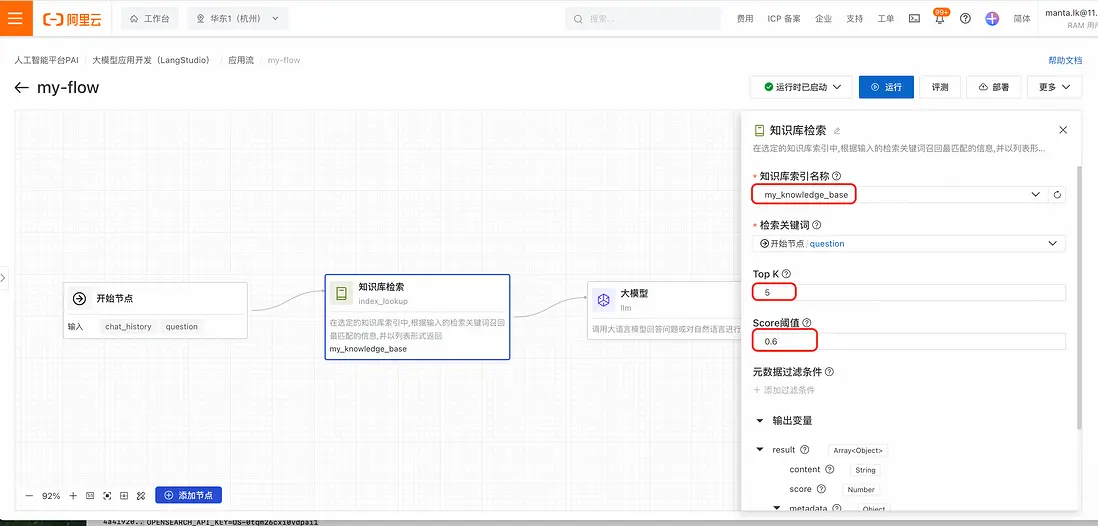
- 點擊“知識庫檢索”節點,配置檢索參數(選擇知識庫索引,設置filter):
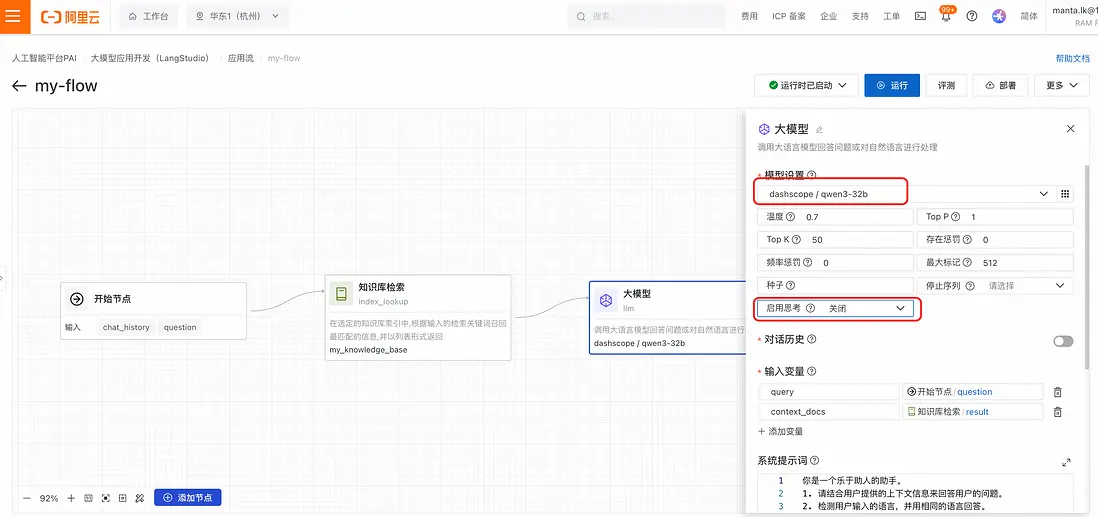
- 點擊“大模型”節點,配置“模型設置”(選擇模型、配置參數、開啓/關閉思考):
- 點擊“運行”按鈕,輸入檢索問題後,可以工作流中的運行框獲取檢索信息:
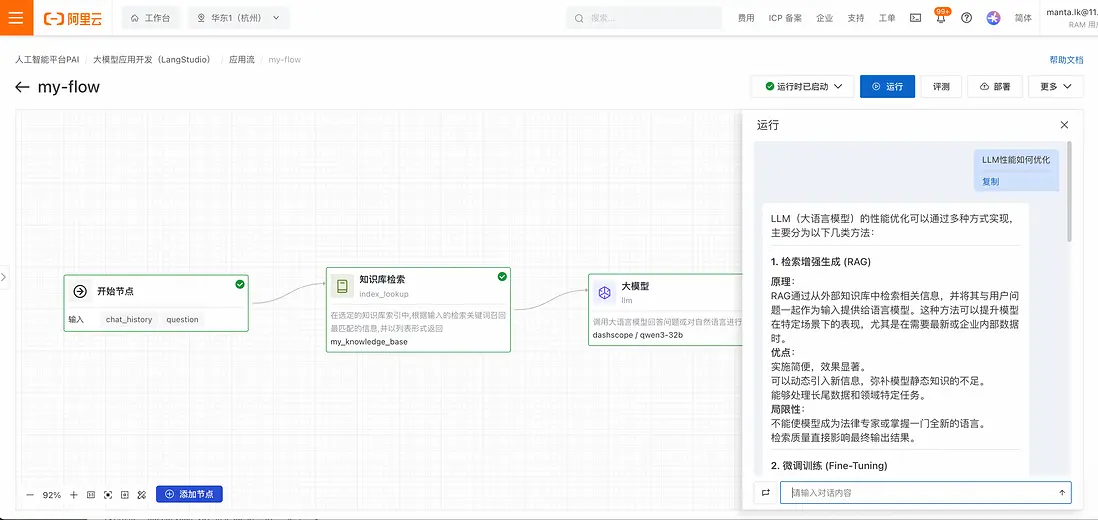
由於ElasticSearch的混合檢索能力,檢索準確率大大提升。
步驟六:通過 PAI-LangStudio部署EAS模型服務,支持API調用知識庫能力
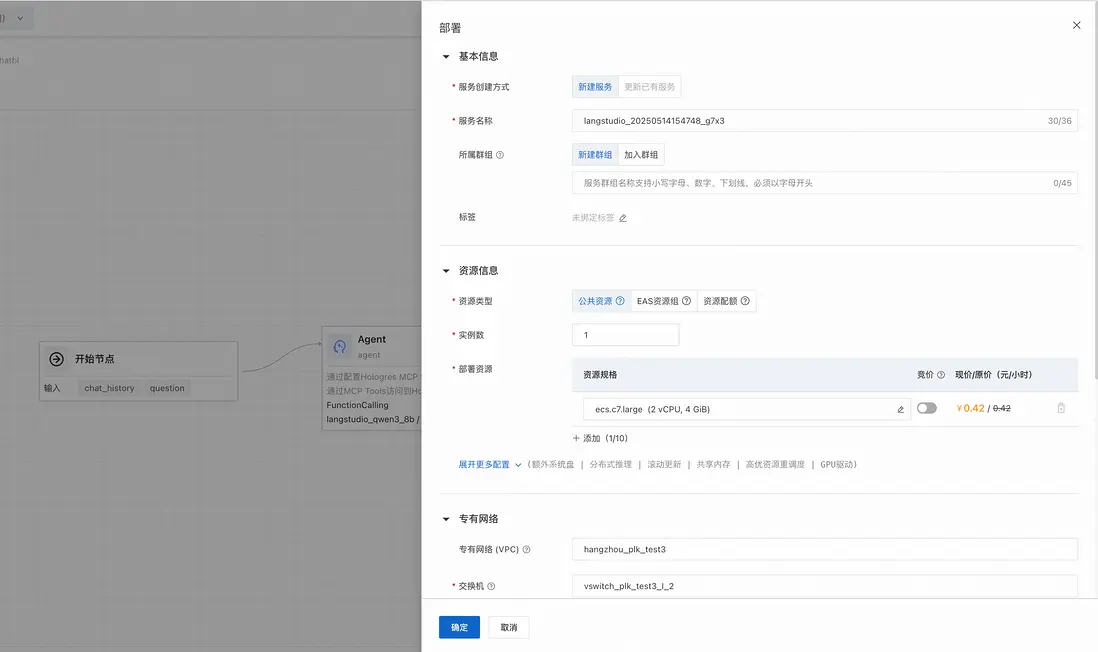
應用流開發調試完成後,單擊右上角的部署,根據需要選擇合適的機型以及專有網絡,注意EAS實例需要使用與應用流中其他服務實例相同的VPC,以保證安全和網絡連通。點擊確定>跳轉到PAI-EAS模型服務查看部署任務。
場景方案價值 - ES + RAG Agent應用
在PAI- LangStudio 中, 使用AI搜索開放平台提供原子化Embeding/Rerank模型能力和Elasticsearch向量數據庫,高效地處理大規模數據,結合大模型LLM分析能力,以快速構建一站式AI Search RAG增強搜索/混合檢索的全棧應用能力。將AI智能信息檢索與智能問答效率與準確率大大提升。
通過以上步驟,您可快速使用PAI-LangStudio構建基於 AI搜索開放平台 和Elasticsearch引擎優勢實現AI Search RAG應用,滿足專業知識庫場景AI Search需求。
更多介紹
Qwen3
作為Qwen 系列最新一代的大語言模型,提供了一系列密集(Dense)和混合專家(MOE)模型。基於廣泛的訓練,Qwen3 在推理、指令跟隨、代理能力和多語言支持方面取得了突破性的進展,具有以下關鍵特性:
獨特支持在思考模式(用於複雜邏輯推理、數學和編碼)和 非思考模式(用於高效通用對話)之間無縫切換,確保在各種場景下的最佳性能。
顯著增強的推理能力,在數學、代碼生成和常識邏輯推理方面超越了之前的 QwQ (在思考模式下)和 Qwen2.5 指令模型(在非思考模式下)。
擅長 Agent 能力,可以在思考和非思考模式下精確集成外部工具,在複雜的基於代理的任務中在開源模型中表現領先。可與PAI-LangStudio 大模型開發平台無縫集成:結合MCP Server服務,增強智能數據分析能力。
支持 100 多種語言和方言,具有強大的多語言理解、推理、指令跟隨和生成能力。
PAI-LangStudio - 大模型Agent應用開發平台
大模型&Agent應用開發平台(PAI-LangStudio)是依託阿里雲PAI產品核心能力構建的面向企業級用户的一站式大模型應用開發平台。簡化了企業級大模型應用的開發流程,同時提供了靈活的可編程能力、實時調試能力與鏈路追蹤的能力,幫助開發者快速構建端到端的AI應用。原生兼容支持通義系列Qwen系列大模型。PAI-LangStudio專注於提供LLM全鏈路開發部署能力,可支持發佈有狀態、多Agent的複雜工作流發佈部署成PAI-EAS模型服務,並在生產環境提供API應用服務。
參考:https://help.aliyun.com/zh/pai/user-guide/langstudio/
AI搜索開放平台
AI搜索開放平台圍繞智能搜索及RAG場景,將AI搜索鏈路中用到的算法服務以組件化形式提供,內置文檔解析、文檔切片、文本向量化、查詢分析、召回、排序、效果評估以及LLM模型服務,開發者根據自身情況靈活選擇組件服務進行搜索業務開發。
AI搜索開放平台-聯網搜索
AI搜索開放平台提供聯網搜索功能,支持直接調用聯網搜索API或調用內容生成服務時啓用聯網搜索。
ElasticSearch混合檢索
阿里雲檢索服務Elasticsearch版(簡稱ES)結合了AI搜索開放平台的組件化模型能力,提供全文檢索+向量檢索引擎的混合檢索技術, 可用於構建高效、精準的複雜語義搜索系統。通過搭建AI語義搜索的方法,帶用户體驗AI技術如何提升搜索的準確性和用户體驗。
RAG 檢索增強 簡介
隨着AI技術的飛速發展,生成式人工智能在文本生成、圖像生成等領域展現出了令人矚目的成就。然而,在廣泛應用大語言模型(LLM)的過程中,以下固有侷限性問題逐漸顯現:
領域知識侷限:大語言模型通常基於大規模通用數據集訓練而成,難以針對專業垂直領域提供深入和針對性處理。
信息更新滯後:由於模型訓練所依賴的數據集具有靜態特性,大模型無法實時獲取和學習最新的信息與知識進展。
模型誤導性輸出:受制於數據偏差、模型內在缺陷等因素,大語言模型可能會出現看似合理實則錯誤的輸出,即所謂的“大模型幻覺”。
為克服這些挑戰,並進一步強化大模型的功能性和準確性,檢索增強生成技術RAG(Retrieval-Augmented Generation)應運而生。這一技術通過整合外部知識庫,能夠顯著減少大模型虛構的問題,並提升其獲取及應用最新知識的能力,從而實現更個性化和精準化的LLM定製。
相關鏈接
- LangStudio產品文檔
- AI搜索開放平台
- 檢索分析服務Elasticsearch版
- 阿里雲Elasticsearch AI場景語義搜索
- 基於阿里雲Elasticsearch使用RAG搭建知識庫在線問答



