

簡介
字符串(string)是 Go 語言提供的一種基礎數據類型。在編程開發中幾乎隨時都會使用。本文介紹字符串相關的知識,幫助你更好地理解和使用它。
底層結構
字符串底層結構定義在源碼runtime包下的 string.go 文件中:
// src/runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}str:一個指針,指向存儲實際字符串的內存地址。len:字符串的長度。與切片類似,在代碼中我們可以使用len()函數獲取這個值。注意,len存儲實際的字節數,而非字符數。所以對於非單字節編碼的字符,結果可能讓人疑惑。後面會詳細介紹多字節字符。
對於字符串Hello,實際底層結構如下:
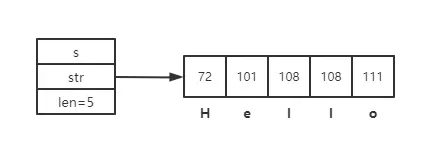
str中存儲的是字符對應的編碼,H對應編碼72,e對應101等等。
我們可以使用下面的代碼輸出字符串的底層結構和存儲的每個字節:
package main
import (
"fmt"
"unsafe"
)
type stringStruct struct {
str unsafe.Pointer
len int
}
func main() {
s := "Hello World!"
fmt.Println(*(*stringStruct)(unsafe.Pointer(&s)))
for _, b := range s {
fmt.Println(b)
}
}運行輸出:
{0x8edaff 5}由於runtime.stringStruct結構是非導出的,我們不能直接使用。所以我在代碼中手動定義了一個stringStruct結構體,字段與runtime.stringStruct完全相同。
基本操作
創建
創建字符串有兩種基本方式,使用var定義和字符串字面量:
var s1 string
s2 := "Hello World!"注意var s string定義了一個字符串的空值,字符串的空值是空字符串,即""。字符串不可能為nil。
字符串字面量可以使用雙引號或反引號定義。在雙引號中出現的特殊字符需要進行轉義,而在單引號中不需要:
s1 := "Hello \nWorld"
s2 := `Hello
World`上面代碼中,s1中出現的換行符需要使用轉義字符\n,s2中直接鍵入換行。由於單引號定義的字面量與我們在代碼中看到的完全相同,在包含大段文本(通常有換行)或比較多的特殊字符時經常使用。另外使用單引號時,注意首行後面其他行的空格問題:
package main
import "fmt"
func main() {
s := `hello
world`
fmt.Println(s)
}可能只是為了縮進和美觀,在第二行的 "world" 前面加上了兩個空格。實際上這些空格也是字符串的一部分。如果這不是有意為之,可能會造成一些困惑。上面代碼輸出:
hello
world索引和切片
可以使用索引獲取字符串對應位置上存儲的字節值,使用切片操作符獲取字符串的一個子串:
package main
import "fmt"
func main() {
s := "Hello World!"
fmt.Println(s[0])
fmt.Println(s[:5])
}輸出:
72
Hello上篇文章你不知道的 Go 之 slice中也介紹過了,字符串的切片操作返回的不是切片,而是字符串。
字符串拼接
字符串拼接最簡單直白的方式就是使用+符號,+可以拼接任意多個字符串。但是+的缺點是待拼接的字符串必須是已知的。另一種方式就是使用標準庫strings包中的Join()函數,這個函數接受一個字符串切片和一個分隔符,將切片中的元素拼接成以分隔符分隔的單個字符串:
func main() {
s1 := "Hello" + " " + "World"
fmt.Println(s1)
ss := []string{"Hello", "World"}
fmt.Println(strings.Join(ss, " "))
}上面代碼首先使用+拼接字符串,然後將各個字符串存放在一個切片中,使用strings.Join()函數拼接。結果是一樣的。需要注意的是,將待拼接的字符串放在一行中,使用+拼接,在 Go 語言內部會先計算需要的空間,預先分配這個空間,最後將各個字符串拷貝過去。這個行為與其他很多語言是不同的,所以在 Go 語言中使用+拼接字符串不會有性能損失,甚至由於內部優化比其他方式性能還要更好一些。當然前提拼接是一次完成的。下面代碼多次使用+拼接,會產生大量臨時字符串對象,影響性能:
s := "hello"
var result string
for i := 1; i < 100; i++ {
result += s
}我們來測試一下各種方式的性能差異。首先定義 3 個函數,分別用 1 次+拼接,多次+拼接和Join()拼接:
func ConcatWithMultiPlus() {
var s string
for i := 0; i < 10; i++ {
s += "hello"
}
}
func ConcatWithOnePlus() {
s1 := "hello"
s2 := "hello"
s3 := "hello"
s4 := "hello"
s5 := "hello"
s6 := "hello"
s7 := "hello"
s8 := "hello"
s9 := "hello"
s10 := "hello"
s := s1 + s2 + s3 + s4 + s5 + s6 + s7 + s8 + s9 + s10
_ = s
}
func ConcatWithJoin() {
s := []string{"hello", "hello", "hello", "hello", "hello", "hello", "hello", "hello", "hello", "hello"}
_ = strings.Join(s, "")
}然後在文件benchmark_test.go中定義基準測試:
func BenchmarkConcatWithOnePlus(b *testing.B) {
for i := 0; i < b.N; i++ {
ConcatWithOnePlus()
}
}
func BenchmarkConcatWithMultiPlus(b *testing.B) {
for i := 0; i < b.N; i++ {
ConcatWithMultiPlus()
}
}
func BenchmarkConcatWithJoin(b *testing.B) {
for i := 0; i < b.N; i++ {
ConcatWithJoin()
}
}運行測試:
$ go test -bench .
BenchmarkConcatWithOnePlus-8 11884388 170.5 ns/op
BenchmarkConcatWithMultiPlus-8 1227411 1006 ns/op
BenchmarkConcatWithJoin-8 6718507 157.5 ns/op可以看到,使用+一次拼接和Join()函數性能差不多,而多次+拼接性能是其他兩種方式的近 1/9。另外需要注意我在ConcatWithOnePlus()函數中先定義 10 個字符串變量,然後再使用+拼接。如果直接使用+拼接字符串字面量,編譯器會直接優化為一個字符串字面量,結果就沒有可比較性了。
在runtime包中,使用concatstrings()函數來處理使用+拼接字符串的操作:
// src/runtime/string.go
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
if l+n < l {
throw("string concatenation too long")
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
// If there is just one string and either it is not on the stack
// or our result does not escape the calling frame (buf != nil),
// then we can return that string directly.
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}類型轉換
我們經常需要將 string 轉為 []byte,或者從 []byte 轉換回 string。這中間都會涉及一次內存拷貝,所以要注意轉換頻次不宜過高。string 轉換為 []byte,轉換語法為[]byte(str)。首先創建一個[]byte並分配足夠的空間,然後將 string 內容拷貝過去。
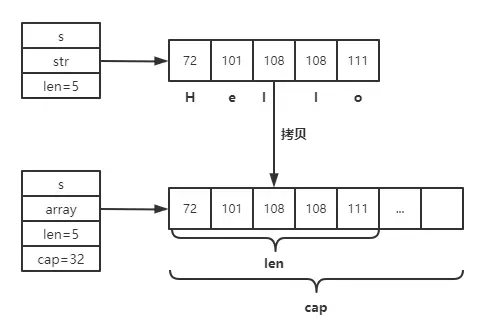
func main() {
s := "Hello"
b := []byte(s)
fmt.Println(len(b), cap(b))
}注意,輸出的cap可能與len不同,多出的容量處於對後續追加的性能考慮。
[]byte轉換為 string 轉換語法為string(bs),過程也是類似。
你不知道的 string
1 編碼
在計算機發展早期,只有單字節編碼,最知名的是 ASCII(American Standard Code for Information Interchange,美國信息交換標準代碼)。單字節編碼最多隻能編碼 256 個字符,這對英語國家可能夠用了。但是隨着計算機在全世界的普及,要編碼其他國家的語言(典型的就是漢字),單字節顯然是不夠的。為此提出了 Unicode 編碼方案。Unicode 編碼為全世界所有國家的語言符號規定了統一的編碼方案。Unicode 相關的知識請查看參考鏈接每個程序員都必須知道的 Unicode 知識。
有很多人不知道 Unicode 與 UTF8、UTF16、UTF32 這些有什麼關係。實際上可以理解為 Unicode 只是規定了每個字符對應的編碼值,實際很少直接存儲和傳輸這個值。UTF8/UTF16/UTF32 則定義這些編碼值如何在內存或文件中存儲以及在網絡上傳輸的格式。例如,漢字“中”,Unicode 編碼值為00004E2D,其他編碼如下:
UTF8編碼:E4B8AD
UTF16BE編碼:FEFF4E2D
UTF16LE編碼:FFFE2D4E
UTF32BE編碼:0000FEFF00004E2D
UTF32LE編碼:FFFE00002D4E0000Go 語言中的字符串存儲是 UTF-8 編碼。UTF8 是可變長編碼,優點是兼容 ASCII。對非英語國家的字符采用多字節編碼方案,而且對使用比較頻繁的字符采用較短的編碼,提升編碼效率。缺點是 UTF8 的可變長編碼讓我們不能直接、直觀地確定字符串的字符長度。一般的中文字符使用 3 個字節來編碼,例如上面的“中”。對於生僻字,可能採用更多的字節來編碼,例如“魋”的 UTF-8 編碼為E9AD8B20。
我們使用len()函數獲取到的都是編碼後的字節長度,而非字符長度,這一點在使用非 ASCII 字符時很重要:
func main() {
s1 := "Hello World!"
s2 := "你好,中國"
fmt.Println(len(s1))
fmt.Println(len(s2))
}輸出:
12
15Hello World!有 12 個字符很好理解,你好,中國有 5 箇中文字符,每個中文字符佔 3 個字節,所以輸出 15。
對於使用非 ASCII 字符的字符串,我們可以使用標準庫的 unicode/utf8 包中的RuneCountInString()方法獲取實際字符數:
func main() {
s1 := "Hello World!"
s2 := "你好,中國"
fmt.Println(utf8.RuneCountInString(s1)) // 12
fmt.Println(utf8.RuneCountInString(s2)) // 5
}為了便於理解,下面給出字符串“中國”的底層結構圖:
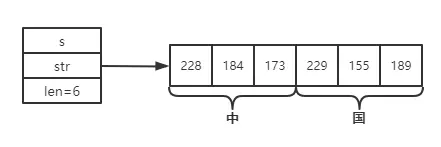
2 索引和遍歷
使用索引操作字符串,獲取的是對應位置上的字節值,如果該位置是某個多字節編碼的中間位置,可能返回的字節值不是一個合法的編碼值:
s := "中國"
fmt.Println(s[0])前面介紹過“中”的 UTF8 編碼為E4B8AD,故s[0]取第一個字節值,結果為 228(十六進制 E4 的值)。
為了方便地遍歷字符串,Go 語言中for-range循環對多字符編碼有特殊的支持。每次遍歷返回的索引是每個字符開始的字節位置,值為該字符的編碼值:
func main() {
s := "Go 語言"
for index, c := range s {
fmt.Println(index, c)
}
}所以遇到多字節字符,索引就不是連續的。上面“語”佔用 3 個字節,所以“言”的索引就是“中”的索引 3 加上它的字節數 3,結果就是 6。上面的代碼輸出如下:
0 71
1 111
2 32
3 35821
6 35328我們也可以以字符形式輸出:
func main() {
s := "Go 語言"
for index, c := range s {
fmt.Printf("%d %c\n", index, c)
}
}輸出:
0 G
1 o
2
3 語
6 言按照這個方法,我們可以編寫一個簡單的RuneCountInString()函數,就叫做Utf8Count吧:
func Utf8Count(s string) int {
var count int
for range s {
count++
}
return count
}
fmt.Println(Utf8Count("中國")) // 23 亂碼和不可打印字符
如果 string 中出現不合法的 utf8 編碼,打印時對於每個不合法的編碼字節都會輸出一個特定的符號�:
func main() {
s := "中國"
fmt.Println(s[:5])
b := []byte{129, 130, 131}
fmt.Println(string(b))
}上面輸出:
中��
���因為“國”編碼有 3 個字節,s[:5]只取了前兩個,這兩個字節無法組成一個合法的 UTF8 字符,故輸出兩個�。
另外需要警惕不可打印字符,之前有個同事請教我一個問題,兩個字符串輸出的內容相同,但是它們就是不相等:
func main() {
b1 := []byte{0xEF, 0xBB, 0xBF, 72, 101, 108, 108, 111}
b2 := []byte{72, 101, 108, 108, 111}
s1 := string(b1)
s2 := string(b2)
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(s1 == s2)
}輸出:
hello
hello
false我直接把字符串內部字節寫出來了,可能一眼就看出來了。但是我們當時遇到這個問題還是稍微費了一番功夫來調試的。因為當時字符串是從文件中讀取的,而文件採用的是帶 BOM 的 UTF8 編碼格式。我們都知道 BOM 格式會自動在文件頭部加上 3 個字節0xEFBBBF。而字符串比較是會比較長度和每個字節的。讓問題更難調試的是,在文件中 BOM 頭也是不顯示的。
4 編譯優化
[]byte轉換為 string 的場景很多,處於性能上的考慮。如果轉換後的 string 只是臨時使用,這時轉換並不會進行內存拷貝。返回的 string會指向切片的內存。編譯器會識別如下場景:
- map 查找:
m[string(b)]; - 字符串拼接:
"<" + string(b) + ">"; - 字符串比較:
string(b) == "foo"。
因為 string 只是臨時使用,期間切片不會發生變化。故這樣使用沒有問題。
總結
字符串是使用頻率最高的基本類型之一,熟悉掌握它可以幫助我們更好地編碼和解決問題。
參考
- 《Go 專家編程》
- 每個程序員都必須知道的 Unicode 知識,https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/
- 你不知道的Go GitHub:https://github.com/darjun/you-dont-know-go
我
我的博客:https://darjun.github.io
歡迎關注我的微信公眾號【GoUpUp】,共同學習,一起進步~



