









1.暴力破解
暴力破解是一種最直接、最笨拙的攻擊方式,見名知意,就是攻擊者通過窮舉所有可能的密鑰、口令或輸入組合,直到找到正確答案為止。
這種攻擊方式看起來很low,但在現實中卻屢見不鮮,因為許多用户仍然習慣使用過於簡單的弱口令,比如像什麼123456,或者是password或是生日、手機號等。
極易猜測的信息,一旦系統沒有設置登錄嘗試次數限制,攻擊者就可以藉助自動化工具快速完成大規模的密碼測試。
常見的暴力破解目標:
密碼,像登錄口令、Wi-Fi密碼、數據庫口令之類的。加密密鑰,如對稱加密中的密鑰。驗證碼/Token,如短信驗證碼、驗證碼圖片等。
暴力破解的分類
1. 純暴力破解 從所有可能的字符組合開始嘗試,例如: 嘗試 "a"、"b"、"c" … 然後 "aa"、"ab"、"ac" …
2. 字典攻擊,這個也比較常用 使用常見密碼字典,比如 123456、password、qwerty 等進行嘗試。 比純暴力破解快,因為大部分用户喜歡用弱口令。
3. 混合攻擊 字典 + 規則,例如: 在字典詞後加數字password123 首字母大寫Qwerty
2.隨機森林
森林中的每個樹就是決策樹。
使用決策樹的組合,可以提升其性能和準確率。隨機森林是一種基於決策樹的集成學習方法,它通過構建多個決策樹模型,然後使用投票的方式進行預測,來減少過擬合的風險。
在實現隨機森林時,需要對決策樹的構建、特徵選擇、模型訓練和預測等方面進行優化。
森林中的每一棵樹都有很多葉子,在計算機中可以理解為很多節點,比如什麼二叉樹。
在決策樹的每個節點,算法需要選擇一個特徵來進行分割,目的是最大化節點的純度,即減少子節點中類別的不確定性。
舉個例子來説:
首先要下載matplotlib,Scikit-learn和pandas
import pandas as pd
# 創建一個包含年齡和類別標籤的Data
data = {
'Age': [25, 30, 35, 40, 45, 50, 55, 60, 65, 70],
'Category': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'A', 'B', 'C']
}
df = pd.DataFrame(data)
# 顯示原始數據
df這是一一對應的,比如説25對應A, 35對應B
現在我們去自定義一個分類:
# 根據年齡是否大於30來分割數據 gini = 0.2
df['Age_GreaterThan_30'] = df['Age'] > 30
# 根據年齡是否大於20來分割數據 gini = 0.1
# 顯示分割後的數據
df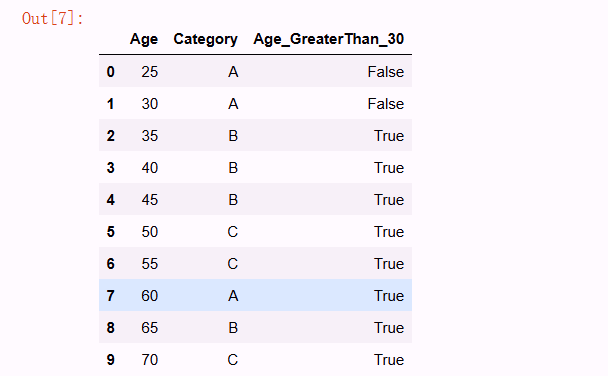
這樣數據就可以分成小於30就是false,大於30就是true,這樣就是把葉子做了一個特徵分類。
所以當有這麼一棵樹的時候,有數據進來,就可以以此判斷它的類別是什麼。
【----幫助網安學習,以下所有學習資料免費領!加vx:YJ-2021-1,備註 “博客園” 獲取!】
① 網安學習成長路徑思維導圖
② 60+網安經典常用工具包
③ 100+SRC漏洞分析報告
④ 150+網安攻防實戰技術電子書
⑤ 最權威CISSP 認證考試指南+題庫
⑥ 超1800頁CTF實戰技巧手冊
⑦ 最新網安大廠面試題合集(含答案)
⑧ APP客户端安全檢測指南(安卓+IOS)
那麼隨機森林就是很多棵決策樹,但是每棵樹略有不同,比如説取的數據不同。
比如説100個數據,使用10棵樹,10棵樹產生的分類也有所不同,這樣就可以避免產生過擬合。
3.使用隨機森林識別暴力破解
注意:這裏的代碼有些沒有完全展示,因為太長了,只截取重要部分。
這裏使用的數據是一些檢測函數調用和攻擊最後的結果之間的對應關係,用這些數據做特徵。
數據下載地址
...
x1,y1 = load_adfa_training_files("./data/ADFA-LD/Training_Data_Master/")
x2,y2 = load_adfa_hydra_ftp_files("./data/ADFA-LD/Attack_Data_Master/")先去加載數據,把數據分成兩份,訓練數據和攻擊數據。
這裏選擇的就是hydra_ftp,暴力破解數據。
hydra是滲透過程中常用工具,這裏就不展開解釋了 hydra
然後對訓練數據和攻擊數據都打上標籤,也就是x1,y1 x2,y2
把x1,x2加起來進行一個拼接,y1和y2也是一樣。
然後需要拿去做一個向量化,因為讀取的數據都是字符串。
x1,y1 = load_data.x1,load_data.y1
x2,y2 = load_data.x2,load_data.y2
x = x1+x2
y = y1+y2
vectorizer = CountVectorizer(min_df=1)
x = vectorizer.fit_transform(x)
x = x.toarray()
print(type(x))
print(y)
# [1,2,3]
np.savetxt("../model/data_x.csv", x, delimiter=",")
np.savetxt("../model/data_y.csv", y, delimiter=",")用CountVectorizer將讀取的數據轉換為numpy格式,轉換完成就可以使用np.savetxt方式把x和y的數據導入到csv文件。
數據處理完之後,接下來就是模型,直接簡短代碼就行。
rf = RandomForestClassifier(n_estimators=model_param.rf_params["n_estimators"],
max_depth=model_param.rf_params["max_depth"],
min_samples_split=model_param.rf_params["min_samples_split"],
random_state=model_param.rf_params["random_state"])使用隨機森林模型
n_estimators: 這個參數指定了要構建的決策樹的數量。
max_depth: 這個參數定義了樹的最大深度,太小了容易欠擬合,不限制又容易過擬合。
min_samples_split: 這個參數指定了在樹的節點上進行分裂所需的最小樣本數,最少都需要兩個,增加這個值可
以使樹更加保守,減少過擬合的風險,但可能降低模型的複雜度和準確性。
這樣模型就構建好了,接下來就是訓練了。
x = np.genfromtxt("data_x.csv",delimiter=",")
y = np.genfromtxt("data_y.csv",delimiter=",")
x_train, x_test , y_train, y_test = train_test_split(x, y, test_size = 0.3)
save_model = model_struct.rf.fit(x_train, y_train)
# 模型的保存
with open('rf.pickle','wb') as f:
pickle.dump(save_model,f) #將訓練好的模型clf存儲在變量f中,且保存到本地把剛才導出來x,y導入,將其分成測試集和訓練集,將模型保存下來,用於接下的測試。
首先是得分測試:
with open('../rf.pickle', 'rb') as f:
clf_load = pickle.load(f) # 將模型存儲在變量clf_load中
x = np.genfromtxt("../data_x.csv",delimiter=",")
y = np.genfromtxt("../data_y.csv",delimiter=",")
# 交叉驗證
scores = cross_val_score(clf_load, x, y, cv=10, scoring='accuracy')
# 11111
# 00001
print(scores.mean())
plt.bar(np.arange(10),scores,facecolor='yellow',edgecolor='white') # +表示向上顯示
for x,y in zip(np.arange(10),scores):
plt.text(x,y+0.05, '%.2f' % y,ha='center',va= 'bottom') # '%.2f' % y 保留y的兩位小數 ha='center' 居中對齊 va= 'bottom' 表示向下對齊 top向上對齊
plt.ylim(0,1.1)
plt.show()用十字交叉驗證去做一個驗證,去跑一下模型:
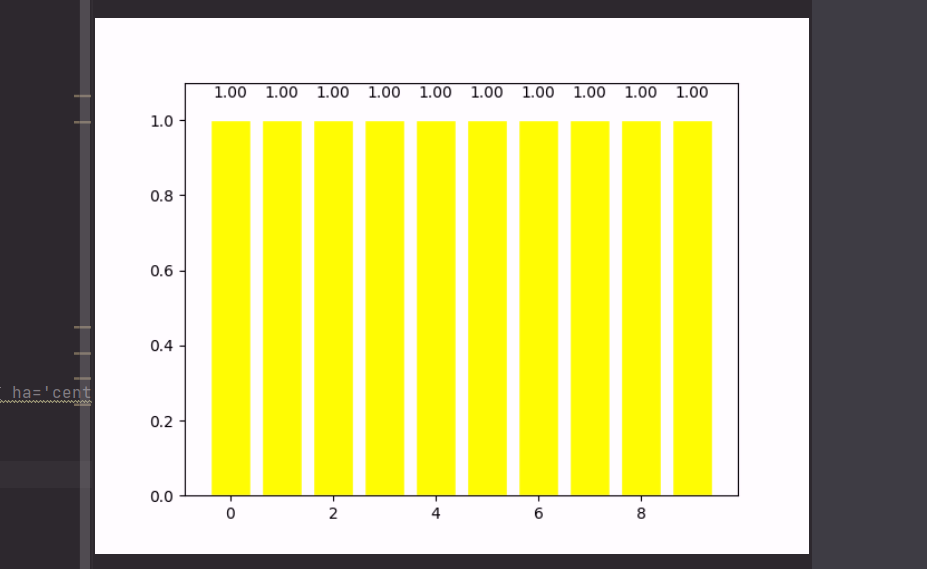
10次跑分的成績
然後是使用的測試:
sys.path.append(config.syspath)
import config
import pickle
import numpy as np
def load_data(filename):
with open(filename, 'r') as f:
first_line = f.readline().strip('\n')
features = [float(feature) for feature in first_line.split()]
return np.array(features) # 確保返回的是一維數組
if __name__ == '__main__':
# 加載數據
data = load_data(config.syspath + "/model/model_test/UAD-Hydra-FTP-1-1613.txt")
# 獲取實際特徵數量
actual_features = data.shape[0]
# 模型期望的特徵數量
expected_features = 142
# 根據特徵數量決定如何處理
if actual_features < expected_features:
# 填充缺失的特徵
padding = np.zeros(expected_features - actual_features)
data_padded = np.hstack([data, padding]).reshape(1, expected_features)
elif actual_features > expected_features:
# 截斷多餘的特徵
data_padded = data[:expected_features].reshape(1, expected_features)
else:
# 特徵數量匹配,無需修改
data_padded = data.reshape(1, expected_features)
# 加載模型
with open('../rf.pickle', 'rb') as f:
clf_load = pickle.load(f)
# 使用模型進行預測
prediction = clf_load.predict(data_padded)
print("預測結果:", prediction)注意,這裏模型是一個支持固定長度的特徵輸入,但是實戰中經常會遇到各種不同長度特徵的輸入。
可以根據特徵數量去進行一個處理,比如説這個特徵是一個連續的特徵,這裏用到的數據都是函數的調用序列。
不管它們在什麼位置,它們所代表的實際含義都是一樣的,都是這個函數在哪個位置被調用了。
6 63 6 5 221 141 141 6 5 221 6 ....比如説上述一部分數據,第一次調用了6號函數,第二次調用了63號函數,以此類推。
也就是特徵和特徵之間都是統一的內容,也就是連續的而不是離散的,那麼就可以使用上述代碼進行一個處理。
接下來去跑測試模式就可以了。
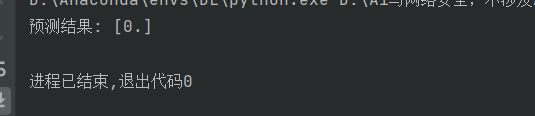
如果預測結果不太準確,那麼就需要在模型參數那裏進行一個調整,當然每一次調整參數都需要把原先的模式刪除。
rf_params = {
'n_estimators':10,
'max_depth':None,
'min_samples_split':2,
'random_state':0
}總之,使用隨機森林去識別暴力破解,就是導入一些安全產品記錄了一些時間段某些函數的調用的數據。
把數據進行一個預處理,就是把函數名稱做一個排序,然後對應到序號上,生成上述的那一部分數字。
接下來就可以重複剛剛的步驟,轉換,構建,訓練,測試。
這個數據是函數調用序列,可能比較抽象,或者用網絡數據包數據或許會更好,但是模型構建的方法是一樣的。
更多網安技能的在線實操練習,請點擊這裏>>
