









本文首發於公眾號:Hunter後端
原文鏈接:MySQL面試必備一之索引
在面試過程中,會有一些關於 MySQL 索引相關的問題,以下總結了一些:
- MySQL 的數據存儲使用的是什麼索引結構
- B+ 樹的結構是什麼樣子
- 什麼是複合索引、聚簇索引、覆蓋索引
- 什麼是最左匹配原則
- 數據 B+ 樹中是如何查詢的
- 回表是什麼操作
- B+ 樹的查詢有什麼優勢
- 索引下推是什麼意思
對於上面這幾個問題,看完這篇筆記你應該就會明白這些問題應該如何作答。
這篇筆記將從以下幾個方面開始介紹:
- B+樹
- 查詢數據的過程
- 覆蓋索引
- 聯合索引
- MyISAM 的存儲結構
- InnoDB 與 MyISAM 的區別
- B 樹與 B+ 樹
1、B+樹
MySQL 的存儲引擎包括 InnoDB、MyISAM、Memory 等,其中 InnoDB 是默認的表存儲引擎,InnoDB 和 MyISAM 的數據都存儲在 B+ 樹這種結構中。
首先來了解下 B+ 樹的結構。
1. B+ 樹結構
與二叉樹一樣,B+ 樹也是一種樹結構,與之不同的點在於每一層並非只有左右兩個子結點,而是可以有多個結點,而在 InnoDB 中,數據都是存儲在葉子結點上,現在假設我們有一張 user 表,以 id 為主鍵,有 name、age 這兩個字段,那麼數據的存儲示意圖則如下:
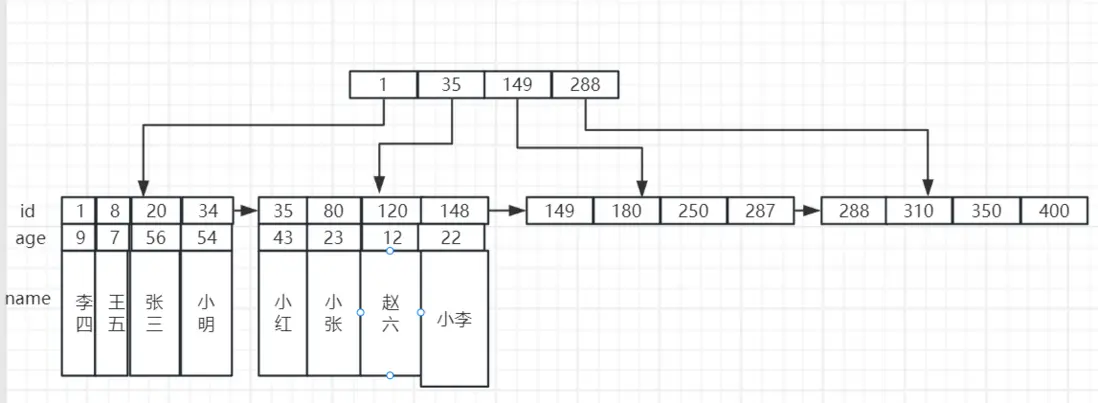
在上圖中,只展示了 B+ 樹的兩層,每一層有四個子結點,所有的數據都存儲在葉子結點上。
在 InnoDB 中,B+ 樹的高度通常為 2 到 4 層,假設每一層我們有 1000 個結點,那麼如果樹有 4 層,那麼在第四層的葉子結點我們可以存儲 1000 的三次方條數據,那麼就可以存儲 10 億條數據。
2. 主鍵索引與聚簇索引
當我們創建一張表,並往裏面添加數據,數據存儲的格式就是上面這張圖的形式,默認以主鍵作為索引,也就是 B+ 樹的非葉子結點,所以又稱其為主鍵索引。
對於這張表,除了 id 字段,還有 age 和 name 字段,這幾個表字段是一起存放在葉子結點的,因此這種存儲方式也稱為聚簇索引。
3. 非聚簇索引與二級索引
在 InnoDB 中,除了主鍵索引外,我們還可以為表的某個或者某些字段創建索引,對於這些索引,我們稱其為非聚簇索引或者二級索引。
二級索引的存儲結構也是 B+ 樹,不一樣的點在於非葉子結點的值是創建了索引的字段值,葉子結點就不再是這條表數據了,而是這個索引字段所在的數據的主鍵值。
還是以前面的 user 表為例,我們在 name 字段上創建索引,那麼 InnoDB 會額外創建一個 B+ 樹,B+ 樹的結構大致如下:
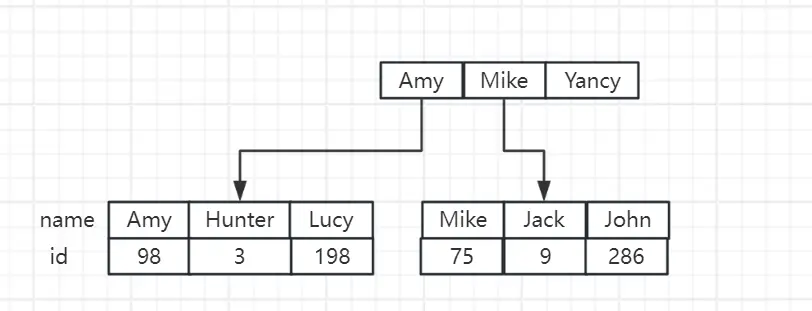
這裏為了更直白的表示字段值的排序,用了英文名字來表示,如上就是一個二級索引的存儲形式。
2、查詢數據的過程
1. 根據主鍵查詢
比如我們要查詢 id = 80 的數據,sql 語句如下:
select id, name, age from user where id = 80;這裏是針對 id 字段進行查詢,所以可以直接查詢主鍵索引,根據上面主鍵索引的示意圖,其查詢步驟如下:
- 根據 id = 18 逐層找到 B+ 樹的對應非葉子結點,比如這裏就到了圖裏的最上層結點
- 根據 id = 18,判斷 1 <18 < 35,所以查詢進入的葉子結點將會進入最左側往下
- 在最左側的葉子結點,找到 id = 18 的葉子結點,然後這個節點對應的 id,name,age 字段獲取然後返回
以上就是一次根據主鍵進行查詢的過程
2. 根據二級索引查詢
還是 user 表,在 name 字段上建立了一個二級索引,我們想要找到 name = "Hunter" 的 id,name,age 字段:
select id, name, age from user where name = "Hunter";其查詢過程如下:
- 根據 name="Hunter" 查詢二級索引的 B+ 樹,也就是我們的第二張圖,根據非葉子結點的值找到最左側的數據
- 根據 "Hunter" 可以找到這條數據的主鍵 id = 3
- 根據 id = 3 去主鍵索引的 B+ 樹裏查詢對應的字段(這裏的查詢操作就是根據主鍵查詢數據了)
回表:上面的查詢過程中,根據二級索引獲取到的主鍵 id,到主鍵索引裏查詢對應的數據,這個過程就稱為回表。
3、覆蓋索引
對上面二級索引查詢的過程,我們有一個回表的操作,即根據二級索引獲取到的主鍵 id 再去主鍵索引獲取相應的字段數據,這部分的查詢過程是會影響查詢效率的。
那麼針對這種回表的情況,我們可以在某些情況下使用覆蓋索引來對其進行優化。
所謂覆蓋索引,並非某種實際的索引結構,而應該算得上是一種思想或者優化手段。其主要思想為在二級索引中就可以拿到查詢所需的全部字段,而不需要進行回表操作。
針對前面我們對 name 加了索引的情況,如果我們的 SQL 語句如下,那麼即可使用覆蓋索引,而不需要再到主鍵索引裏回表查詢:
select id, name from user where name = "Hunter";在上面這個語句中,我們查詢的是 id 和 name 兩個字段,這兩個字段在 name 字段的二級索引的查詢中即可獲取所需的字段值,那麼則不需要進行回表操作,這個過程就相當於使用了覆蓋索引。
而如果我們所需要的字段並不只是這兩個字段,比如我們還要查詢 age 字段,針對這種情況,如果要用覆蓋索引的話,就需要引入下一節的內容,聯合索引,或者叫複合索引。
4、聯合索引
複合索引,或者叫聯合索引,指的是針對多個字段創建的索引,常常適用於多個字段進行查詢的場景。
1. 聯合索引的結構
聯合索引也是二級索引,不過它的非葉子結點的值是多個字段組合的。
還是以 user 表為例,我們在 age 和 name 上創建一個聯合索引:
CREATE INDEX age_name_idx ON user (age, name);那麼,在 MySQL 中,這個二級索引的存儲結構大致如下:
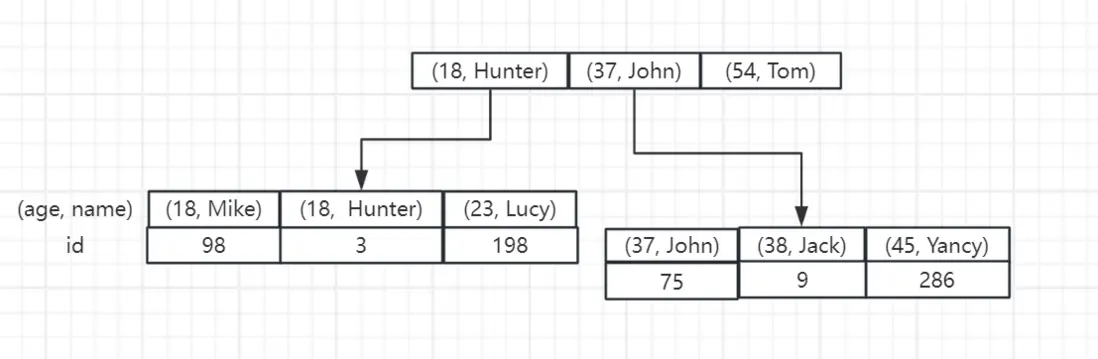
根據上面的這個結構,我們可以知道,字段的順序是十分重要的,如果我們 SQL 語句的使用不當可能就會用不上聯合索引。
2. 聯合索引生效的情況
根據上圖可以看到非葉子結點的值由兩部分組成,分別是 age 和 name 的值,那麼我們在進行查詢的時候,也應該遵循這個順序才可能使得索引生效。
1) 單個字段查詢
如果我們要查詢單個字段,比如 age,那麼下面的條件都可以使得索引生效:
where age = 23;
where age > 25;但是如果 where 後面的條件是針對 name 字段,那麼下面的條件則不會使得這個聯合索引生效:
where name = "Hunter";2) 多個字段查詢
如果是多個字段查詢,那麼則使用的時候一定要注意查詢的順序,下面的條件的是可以生效的:
where age = 23 and name = "Hunter";
where age = 24 and name like "Hun*";而如果是 age 是一個範圍查找,則不管 name 字段是什麼條件,這個索引也可以生效,但僅僅是 age 字段會用到索引,name 字段的則不會用到索引,比如:
where age > 34 and name = "Hunter";上面這個 SQL 語句,索引則只會對 age 字段生效進行範圍查找,name 字段不用用到索引的精確匹配。
3) 最左匹配原則
基於聯合索引的結構,如上圖,最左匹配原則的概念其實就顯而易見了,即聯合索引只會從建立了索引的最左字段開始匹配,直到遇到範圍查詢則停止,就比如上面提到的這條:
where age > 34 and name = "Hunter";它匹配到 age 就停止了,因為 age 是一個範圍查詢。
再來一種情況,如果我們的聯合索引字段有三個,按照順序為 age, name 和 field_3,下面的語句則會分別匹配到 age、name 和 field_3:
where age > 4 and name = "Hunter" and field_3 = 45;
where age = 34 and name like "Hun*" and field_3 = 45;
where age = 34 and name = "Hunter" and field_3 > 45;下面這幾種針對後面幾個字段的查詢聯合索引都是不生效的:
where name = "Hunter" and field_3 = 45;
where field_3 = 45;因為他們都沒有從聯合索引的最左字段字段開始查詢。
3. 索引下推
索引下推是 MySQL 5.6 版本及以上引入的一個特性,主要用於減少回表的次數,從而實現提高查詢性能的效果。
還是以前面 age 和 name 這個複合索引為例,SQL 如下:
where age > 30 and name like "Hun*";如果沒有索引下推,那麼它的查詢流程是根據 age > 30 這個條件,查詢主鍵 id,逐個回表去主鍵索引裏查詢 name 字段的值是否滿足 "Hun*" 這個條件。
而如果有索引下推這個優化,那麼在二級索引裏,查找出 age > 30 的值後,會直接根據複合索引中 name 的值來判斷是否滿足 "Hun*" 這個特性,滿足的話就去回表查詢,不滿足則在當前複合索引裏直接將這條數據過濾掉。
所謂的索引下推就是通過這個流程來減少回表的次數,以提高查詢的性能。
5、MyISAM 的存儲結構
MyISAM 的數據存儲結構也是 B+ 樹,但有一點不同,那就是 InnoDB 的葉子結點存儲的是完整的一條數據,而 MyISAM 的葉子結點存儲的數據的指針,通過指針指向底層存儲的數據,其大概示意圖如下:
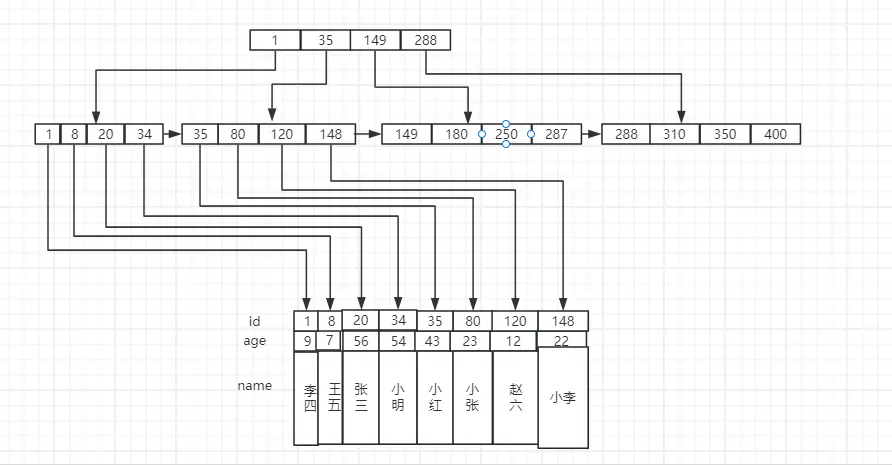
同理,MyISAM 的二級索引的葉子結點也是直接指向存儲的數據。
因此,MyISAM 在底層存儲的表文件有三個,一個是 frm,是表的定義文件,一個 MYD,用於存儲數據的文件,一個是 MYI,用於存儲索引的文件。
相對來説,InnoDB 就只有兩個,一個是 frm,一個是 IBD,用於存儲索引和數據,因為 InnoDB 的葉子結點即存儲了數據。
6、InnoDB 與 MyISAM 的區別
這裏總結一下 InnoDB 與 MyISAM 的區別:
-
InnoDB 是聚簇索引,MyISAM 是非聚簇索引
- 即 InnoDB 的主鍵索引是數據和索引放在一起的,而 MyISAM 是索引和數據分離的
- InnoDB 支持外鍵,MyISAM 不支持外鍵
- InnoDB 支持事務,MyISAM 不支持事務
- InnoDB 默認支持到行級鎖,而 MyISAM 支持表級鎖
7、B 樹與 B+ 樹
B 樹和 B+ 樹是很相似的樹結構,都是每個結點都有多個子結點,不一樣的在於 B 樹的非葉子結點也存有數據,而 B+ 樹只有葉子結點才有數據,非葉子結點都是索引數據,且 B+ 樹的葉子結點之間也形成有序鏈表。
針對以上這個不同點,在 MySQL 中使用 B+ 樹有如下優點:
- B+ 樹在非葉子結點不包含數據,因此在內存頁可以存放更多 key,從而在查詢的時候可以減少 IO 次數
- B+ 樹的葉子結點之間形成鏈表,遍歷操作會更方便,而 B 樹需要從根節點從上往下遍歷
- B+ 樹的數據都存放在葉子結點,而 B 樹的非葉子結點也都有數據,所以查詢的過程中 B+ 樹總是需要訪問到葉子結點,所以 B+ 樹的查詢效率會更穩定
如果想獲取更多後端相關文章,可掃碼關注閲讀:











