









作者:京東科技 孫曉軍
1. GDB介紹
GDB是GNU Debugger的簡稱,其作用是可以在程序運行時,檢測程序正在做些什麼。GDB程序自身是使用C和C++程序編寫的,但可以支持除C和C++之外很多編程語言的調試。GDB原生支持調試的語言包含:
•C
•C++
•D
•Go
•Object-C
•OpenCL C
•Fortran
•Pascal
•Rust
•Modula-2
•Ada
此外,通過擴展GDB,也可以用來調試Python語言。
使用GDB,我們可以方便地進行如下任務:
•如果程序崩潰後產生了core dump文件,gdb可以通過分析core dump文件,找出程序crash的位置,調用堆棧等用於找出問題原因的關鍵信息
•在程序運行時,GDB可以檢測當前程序正在做什麼事情
•在程序運行時,修改變量的值
•可以使程序在特定條件下中斷
•監視內存地址變動
•分析程序Crash後的core文件
GDB是瞭解三方中間件,無源碼程序,解決程序疑難雜症的利器。使用GDB,可以瞭解程序在運行時的方方面面。尤其對於在測試(Test),集成(SIT),驗收(UAT),預發佈(Staging)等環境下的問題調查和解決,GDB有着日誌無法比擬的優勢。此外,GDB還非常適合對多種開發語言混合的程序進行調試。
GDB不適合用來做什麼:
•GDB可以用來輔助調試內存泄露問題,但GDB不能用於內存泄露檢測
•GDB可以用來輔助程序性能調優,但GDB不能用於程序性能問題分析
•GDB不是編譯器,不能運行有編譯問題的程序,也不能用來調試編譯問題
2. 安裝GDB
2.1. 從已發佈的二進制包安裝
在基於Debian的Linux系統,可以使用apt-get命令方便地安裝GDB
apt-get update
apt-get install gdb
2.2. 從源代碼安裝
前置條件
# 安裝必要的編譯工具
apt-get install build-essential
首先,我們需要下載GDB的源碼。官網下載源碼的地址是:
https://ftp.gnu.org/gnu/gdb/
# 下載源代碼
wget http://ftp.gnu.org/gnu/gdb/gdb-9.2.tar.gz
# 解壓安裝包
tar -xvzf gdb-9.2.tar.gz
# 編譯GDB
cd gdb-7.11
mkdir build
cd build
../configure
make
# 安裝GDB
make install
# 檢查安裝結果
gdb --version //輸出
3. 準備使用GDB
3.1. 在docker容器內使用GDB
GDB需要使用ptrace 方法發送PTRACE_ATTACH請求給被調試進程,用來監視和控制另一個進程。
Linux 系統使用
/proc/sys/kernel/yama/ptrace\_scope設置來對ptrace施加安全控制。默認ptrace\_scope的設置的值是1。默認設置下,進程只能通過PTRACE\_ATTACH請求,附加到子進程。當設置為0時,進程可以通過PTRACE\_ATTACH請求附加到任何其它進程。
在docker容器內,即使是root用户,仍有可能沒有修改這個文件的權限。使得在使用GDB調試程序時會產生“ptrace: Operation not permitted “錯誤。
為了解決docker容器內使用GDB的問題,我們需要使用特權模式運行docker容器,以便獲得修改
/proc/sys/kernel/yama/ptrace_scope文件的權限。
# 以特權模式運行docker容器
docker run --privileged xxx
# 進入容器,輸入如下指令改變PTRACE_ATTACH請求的限制
echo 0 > /proc/sys/kernel/yama/ptrace_scope
3.2. 啓用生成core文件
默認情況下,程序Crash是不生成core文件的,因為默認允許的core文件大小為0。
為了在程序Crash時,能夠生成core文件來幫助排查Crash的原因,我們需要修改允許的core文件大小設置
# 查看當前core文件大小設置
ulimit -a
# 設置core文件大小為不限制
ulimit -c unlimited
# 關閉core文件生成功能
ulimit -c 0
修改core文件設置後,再次查看core文件的設置時,會看到下面的結果
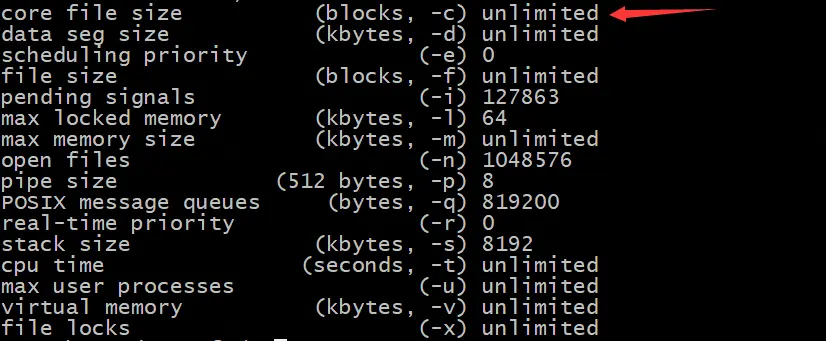
這樣,當程序Crash時,會在程序所在的目錄,生成名稱為core.xxx的core文件。
當程序運行在Docker容器內時,在容器內進行上述設置後,程序Crash時仍然無法生成core文件。這時需要我們在Docker容器的宿主機上,明確指定core文件的生成位置。
# 當程序Crash時,在/tmp目錄下生成core文件
echo '/tmp/core.%t.%e.%p' > /proc/sys/kernel/core_pattern
設置中的字段的含義如下:
•/tmp 存放core文件的目錄
•core 文件名前綴
•%t 系統時間戳
•%e 進程名稱
•%p 進程ID
3.3. 生成調試符號表
調試符號表是二進制程序和源代碼的變量,函數,代碼行,源文件的一個映射。一套符號表對應特定的一套二進制程序,如果程序發生了變化,那麼就需要一套新的符號表。
如果沒有調試符號表,包含代碼位置,變量信息等很多調試相關的能力和信息將無法使用。在編譯時加入-ggdb編譯選項,就會在生成的二進制程序中加入符號表,此時生成的二進制程序的大小會有顯著的增加。
-ggdb 用來生成針對gdb的調試信息,也可以使用-g來代替
另外,只要條件允許,建議使用-O0來關閉編譯優化,用來避免調試時,源代碼和符號表對應不上的奇怪問題。
-O0 關閉編譯優化
3.4. 使用screen來恢復會話
GDB調試依賴於GDB控制枱來和進程進行交互,如果我們的連接終端關閉,那麼原來的控制枱就沒有辦法再使用了。此時我們可以通過開啓另一個終端,關閉之前的GDB進程,並重新attach到被調試進程,但此時的斷點,監視和捕獲都要重新設置。另一種方法就是使用screen。使用screen運行的程序,可以完全恢復之前的會話,包括GDB控制枱。
# 安裝screen
apt install screen
# 查看安裝結果
screen -v //output: Screen version 4.08.00 (GNU) 05-Feb-20
# 使用screen啓動調試
screen gdb xxx
# 查看screen會話列表
screen -ls
# 恢復screen會話
screen -D -r [screen session id]
4. 啓動GDB的幾種方式
4.1. 使用GDB加載程序,在GDB命令行啓動運行
這是經典的使用GDB的方式。程序可以通過GDB命令的參數來加載,也可以在進入GDB控制枱後,通過file命令來加載。
# 使用GDB加載可執行程序
gdb [program]
# 使用GDB加載可執行程序並傳遞命令行參數
gdb --args [program] [arguments]
# 開始調試程序
(gdb) run
# 傳遞命令行參數並開始調試程序
(gdb) run arg1 arg2
# 開始調試程序並在main函數入口中斷
(gdb) start
# 傳遞命令行參數,開始調試程序並在main函數入口中斷
(gdb) start arg1 arg2
4.2. 附加GDB到運行中的進程
GDB可以直接通過參數的方式,附加到一個運行中的進程。也可以在進入GDB控制枱後,通過attach命令附加到進程。
需要注意的是一個進程只允許附加一個調試進程,如果被調試的進程當前已經出於被調試狀態,那麼要麼通過detach命令來解除另一個GDB進程的附加狀態,要麼強行結束當前附加到進程的GDB進程,否則不能通過GDB附加另一個調試進程。
# 通過GDB命令附加到進程
gdb --pid [pid]
# 在GDB控制枱內,通過attach命令附加的進程
gdb
(gdb) attach [pid]
4.3. 調試core文件
在程序Crash後,如果生成了core文件,我們可以通過GDB加載core文件,調試發生異常時的程序信息。core文件是沒有限制當前機器相關信息的,我們可以拷貝core文件到另一台機器進行core分析,但前提是產生core文件的程序的符號表,需要和分析core文件時加載的程序的符號表保持一致。
使用GDB調試core文件
# 使用GDB加載core文件進行異常調試
gdb --core [core file] [program]
4.4. 使用GDB加載程序並自動運行
在自動化測試場景中,需要程序能夠以非中斷的方式流暢地運行,同時又希望附加GDB,以便隨時可以瞭解程序的狀態。這時我們可以使用--ex參數,指定GDB完成程序加載後,自動運行的命令。
# 使用GDB加載程序,並在加載完成後自動運行run命令
gdb --ex r --args [program] [arguments]
5. 使用GDB
5.1. 你好,GDB
我們先從一個Hello world的例子,通過GDB設置斷點來調試程序,近距離接觸下GDB。
首先使用記事本或其它工具編寫下面的main.cc代碼:
#include <iostream>
#include <string>
int main(int argc, char *argv[]) {
std::string text = “Hello world”;
std::cout << text << std::endl;
return 0;
}
接下來我們使用g++編譯器編譯源碼,並設置-ggdb -O0編譯選項。
g++ -ggdb -O0 -std=c++17 main.cc -o main
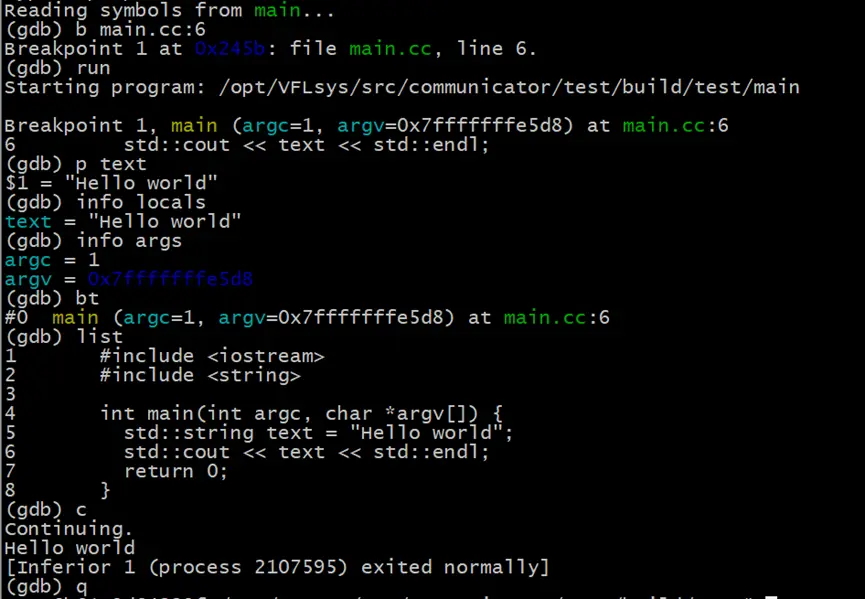
生成可執行程序後,我們使用GDB加載可執行程序,並設置斷點。
# 使用gdb加載main
gdb main
# 在main.cc源文件的第六行設置斷點
(gdb) b main.cc:6
# 運行程序
(gdb) run
之後,程序會運行到斷點位置並停下來,接下來我們使用一些常用的GDB指令來檢查程序的當前狀態
# 輸出text變量數據 “Hello world“
(gdb) p text
# 輸出局部變量列表,當前斷點位置只有一個text局部變量
(gdb) info locals
# 輸出當前棧幀的方法參數,當前棧幀函數是main,參數包含了argc和argv
(gdb) info args
# 查看堆棧信息,當前只有一個棧幀
(gdb) bt
# 查看當前棧幀附近的源碼
(gdb) list
# 繼續運行程序
(gdb) c
# 退出GDB
(gdb) q
5.2. Segmentation Fault問題排查
Segmentation Fault是進程訪問了由操作系統內存保護機制規定的受限的內存區域觸發的。當發生Segmentation Fault異常時,操作系統通過發起一個“SIGSEGV”信號來終止進程。此外,Segmentation Fault不能被異常捕捉代碼捕獲,是導致程序Crash的常見誘因。
對於C&C++等貼近操作系統的開發語言,由於提供了靈活的內存訪問機制,所以自然成為了Segmentation Fault異常的重災區,由於默認的Segmentation Fault異常幾乎沒有詳細的錯誤信息,使得開發人員處理此類異常時變得更為棘手。
在實際開發中,使用了未初始化的指針,空指針,已經被回收了內存的指針,棧溢出,堆溢出等方式,都會引發Segmentation Fault。
如果啓用了core文件生成,那麼當程序Crash時,會在指定位置生成一個core文件。通過使用GDB對core文件的分析,可以幫助我們定位引發Segmentation Fault的原因。
為了模擬Segmentation Fau我們首先在main.cc中添加一個自定義類Employee
class Employee{
public:
std::string name;
};
然後編寫代碼,模擬使用已回收的指針,從而引發的Segmentation Fault異常
void simulateSegmentationFault(const std::string& name) {
try {
Employee *employee = new Employee();
employee->name = name;
std::cout << "Employee name = " << employee->name << std::endl;
delete employee;
std::cout << "After deletion, employee name = " << employee->name << std::endl;
} catch (...) {
std::cout << "Error occurred!" << std::endl;
}
}
最後,在main方法中,添加對simulateSegmentationFault方法的調用
在main方法中,添加對simulateSegmentationFault方法的調用
int main(int argc, char *argv[]) {
std::string text = "Hello world";
std::cout << text << std::endl;
simulateSegmentationFault(text);
return 0;
}
編譯並執行程序,我們會得到如下的運行結果
$ ./main
Hello world
Employee name = Hello world
Segmentation fault (core dumped)
從結果上來看,首先我們的異常捕獲代碼對於Segmentation Fault無能為力。其次,發生異常時沒有打印任何對我們有幫助的提示信息。
由於代碼非常簡單,從日誌上很容易瞭解到問題發生在”std::cout << "After deletion, employee name = " << employee->name << std::endl;” 這一行。在實際應用中,代碼和調用都非常複雜,很多時候僅通過日誌沒有辦法準確定位異常發生的位置。這時,就輪到GDB出場了
# 使用GDB加載core文件
gdb --core [core文件路徑] main
//對於沒有生成core文件的情況,請參考3.2. 啓用生成core文件

注意其中的”Reading symbols from main..”,如果接下來打印了找不到符號表的信息,説明main程序中沒有嵌入調試符號表,此時變量,行號,等信息均無法獲取。若要生成調試符號表,可以參考 “3.3. 生成調試符號表”。
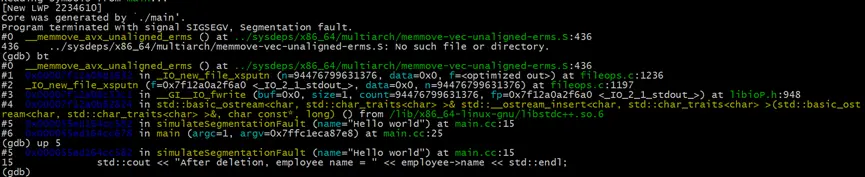
成功加載core文件後,我們首先使用bt命令來查看Crash位置的錯誤堆棧。從堆棧信息中,可以看到\_\_GI\_\_IO_fwrite方法的buf參數的值是0x0,這顯然不是一個合法的數值。序號為5的棧幀,是發生異常前,我們自己的代碼壓入的最後一個棧幀,信息中甚至給出了發生問題時的調用位置在main.cc文件的第15行(main.cc:15),我們使用up 5 命令向前移動5個棧幀,使得當前處理的棧幀移動到編碼為5的棧幀。
# 顯示異常堆棧
(gdb) bt
#向上移動5個棧幀
(gdb) up 5
此時可以看到傳入的參數name是沒有問題的,使用list命令查看下問題調用部分的上下文,再使用info locals命令查看調用時的局部變量的情況。最後使用 p *employe命令,查看employee指針指向的數據
# 顯示所有的參數
(gdb) info args
# 顯示棧幀所在位置的上下文代碼
(gdb) list
# 顯示所有的局部變量
(gdb) info locals
# 打印employee指針的數據
(gdb) p *employee
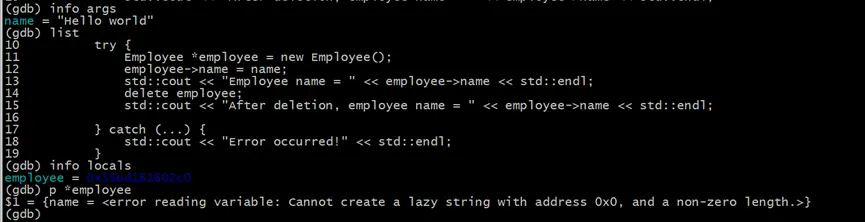
此時可以看到在main.cc代碼的第15行,使用std::cout輸出Employee的name屬性時,employee指針指向的地址的name屬性已經不再是一個有效的內存地址(0x0)。
5.3. 程序阻塞問題排查
程序阻塞在程序運行中是非常常見的現象。並不是所有的阻塞都是程序產生了問題,阻塞是否是一個要解決的問題,在於我們對於程序阻塞的預期。比如一個服務端程序,當完成了必要的初始化後,需要阻塞主線程的繼續執行,避免服務端程序執行完main方法後退出。就是正常的符合預期的阻塞。但是如果是一個客户端程序,執行完了所有的任務後在需要退出的時候,還處於阻塞狀態無法關閉進程,就是我們要處理的程序阻塞問題。除了上面提到的程序退出阻塞,程序阻塞問題一般還包括:
•併發程序中產生了死鎖,線程無法獲取到鎖對象
•遠程調用長時間阻塞無法返回
•程序長時間等待某個事件通知
•程序產生了死循環
•訪問了受限的資源和IO,出於排隊阻塞狀態
對於大多數阻塞來説,被阻塞的線程會處於休眠狀態,放置於等待隊列,並不會佔用系統的CPU時間。但如果這種行為不符合程序的預期,那麼我們就需要查明程序當前在等待哪個鎖對象,程序阻塞在哪個方法,程序在訪問哪個資源時卡住了等問題.
下面我們通過一個等待鎖釋放的阻塞,使用GDB來分析程序阻塞的原因。首先引入線程和互斥鎖頭文件
#include <thread>
#include <mutex>
接下來我們使用兩個線程,一個線程負責加鎖,另一個線程負責解鎖
std::mutex my_mu;
void thread1_func() {
for (int i = 0; i < 5; ++i) {
my_mu.lock();
std::cout << "thread1 lock mutex succeed!" << std::endl;
std::this_thread::yield();
}
}
void thread2_func() {
for (int i = 0; i < 5; ++i) {
my_mu.unlock();
std::cout << "thread2 unlock mutex succeed!" << std::endl;
std::this_thread::yield();
}
}
void simulateBlocking() {
std::thread thread1(thread1_func);
std::thread thread2(thread2_func);
thread1.join();
thread2.join();
}
最後,重新編譯main程序,並在g++編譯時,加入lpthread鏈接參數,用來鏈接pthread庫
g++ -ggdb -O0 -std=c++17 main.cc -o main -lpthread
直接運行main程序,此時程序大概率會阻塞,並打印出類似於如下的信息
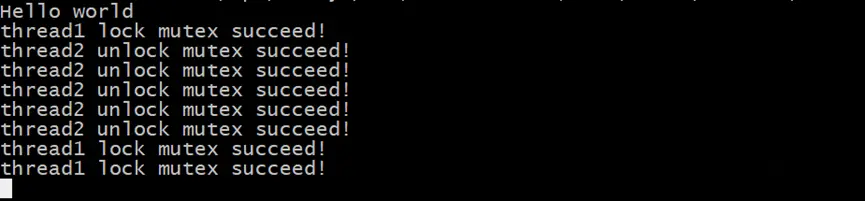
為了調查程序阻塞的原因,我們使用命令把gdb關聯到運行中的進程
gdb --pid xxx
進入GDB控制枱後,依舊是先使用bt打印當前的堆棧信息
# 打印堆棧信息
(gdb) bt
# 直接跳轉到我們的代碼所處的編號為2的棧幀
(gdb) f 2
# 查看代碼
(gdb) list
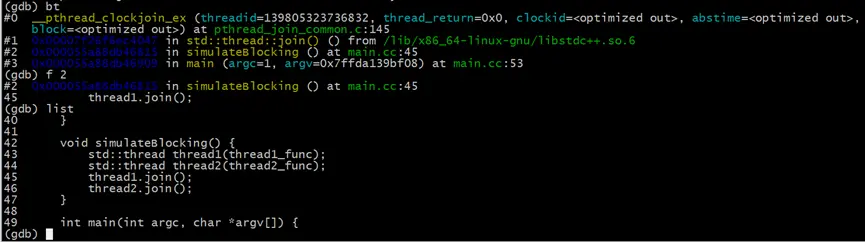
此時我們通過查看堆棧信息,知道阻塞的位置是在main.cc的45行,即thread1.join()沒有完成。但這並不是引發阻塞的直接原因。我們還需要繼續調查為什麼thread1沒有結束
# 查看所有運行的線程
(gdb) info threads
# 查看編號為2的線程的堆棧
(gdb) thread apply 2 bt
# 切換到線程2
(gdb) thread 2
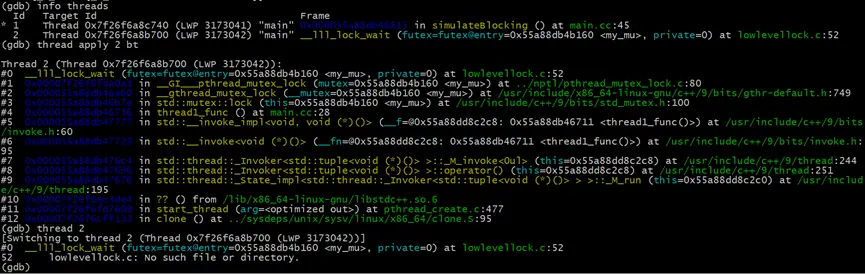
由於示例程序比較簡單,所有運行的線程只有兩個,我們可以很容易地找到我們需要詳細調查的thread1所在的線程。
當進程當前運行較多線程時,想找到我們程序中的特定線程並不容易。info threads中給出的線程ID,是GDB的thread id,和thread1線程的id並不相同。而LWP中的線程ID,則是系統賦予線程的唯一ID,同樣和我們在進程內部直接獲取的線程ID不相同。這裏我們通過thread apply命令,直接調查編號為2的線程的堆棧信息,確認了其入口函數是thread1_func,正是我們要找到thread1線程。我們也可以通過thread apply all bt命令,查看所有線程的堆棧信息,用來查找我們需要的線程。更簡單的方式是調用gettid函數,獲取操作系統為線程分配的輕量進程ID(LWP)。
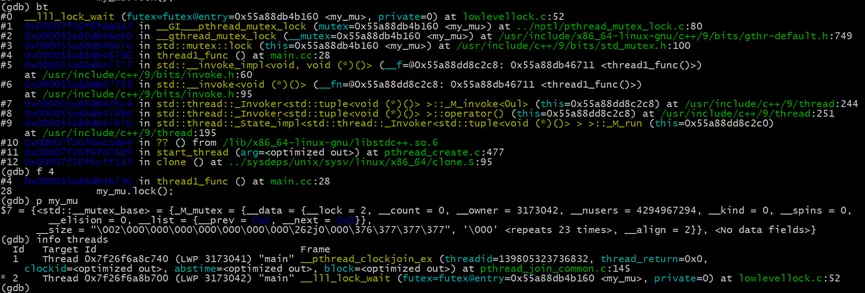
接下來,我們調查thread1的堆棧,找到阻塞的位置並調查阻塞的互斥鎖my\_mu的信息,找到當前持有該鎖的線程id(Linux系統線程ID),再次通過info threads查到持有鎖的線程。最後發現是因為當前線程持有了互斥鎖,當再次請求獲取鎖對象my\_mu時,由於my_mu不可重入,導致當前線程阻塞,形成死鎖。
# 查看thread1的堆棧
(gdb) bt
# 直接跳轉到我們的代碼所處的棧幀
(gdb) f 4
# 查看鎖對象my_mu
(gdb) p my_mu
# 確認持有鎖的線程
(gdb) info threads
5.4. 數據篡改問題排查
數據篡改不一定會引發異常,但很可能會導致業務結果不符合預期。對於大量使用了三方庫的項目來説,想知道數據在哪裏被修改成了什麼,並不是一件容易的事。對於C&C++來説,還存在着指針被修改後,導致指針原來指向的對象可能無法回收的問題。單純使用日誌,想要發現一個變量在何時被哪個程序修改成了什麼,幾乎是不可能的事,通過使用GDB的監控斷點,我們可以方便地調查這類問題。
我們仍然使用多線程模式,一個線程模擬讀取數據,當發現數據被修改後,打印一條出錯信息。另一個線程用來模擬修改數據。
這裏我們使用的Employee對象的原始的name和修改後的name都大於15個字符,如果長度小於這個數值,你將會觀察到不一樣的結果。
void check_func(Employee& employee) {
auto tid = gettid();
std::cout << "thread1 " << tid << " started" << std::endl;
while (true) {
if (employee.name.compare("origin employee name") != 0) {
std::cout << "Error occurred, Employee name changed, new value is:" << employee.name << std::endl;
break;
}
std::this_thread::yield();
}
}
void modify_func(Employee& employee) {
std::this_thread::sleep_for(std::chrono::milliseconds(0));
employee.name = std::string("employee name changed");
}
void simulateDataChanged() {
Employee employee("origin employee name");
std::thread thread1(check_func, std::ref(employee));
std::thread thread2(modify_func, std::ref(employee));
thread1.join();
thread2.join();
}
在main方法中,加入simulateDataChanged方法的調用,之後編譯並運行程序,會得到如下的結果:

現在,我們假設修改了name屬性的modify_func在一個三方庫中,我們對其內部實現不瞭解。我們需要要通過GDB,找到誰動了employee對象的name屬性
# 使用gdb加載main
(gdb) gdb main
# 在進入gdb控制枱後,在simulateDataChanged方法上增加斷點
(gdb) b main.cc:simulateDataChanged
# 運行程序
(gdb) r
# 連續執行兩次下一步,使程序執行到employee對象創建完成後
(gdb) n
(gdb) n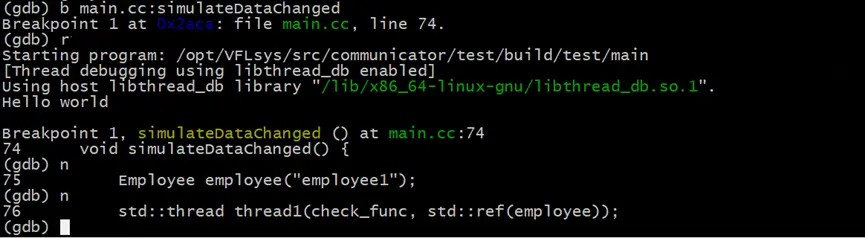
之後,我們對employee.name屬性進行監控,只要name屬性的值發生了變化,就會觸發GDB中斷
# 監視employee.name變量對應的地址數據
(gdb) watch -location employee.name
# 繼續執行
(gdb) c
# 在觸發watch中斷後,查看中斷所在位置的堆棧
(gdb) bt
#直接跳轉到我們的代碼所處的棧幀
(gdb) f 1
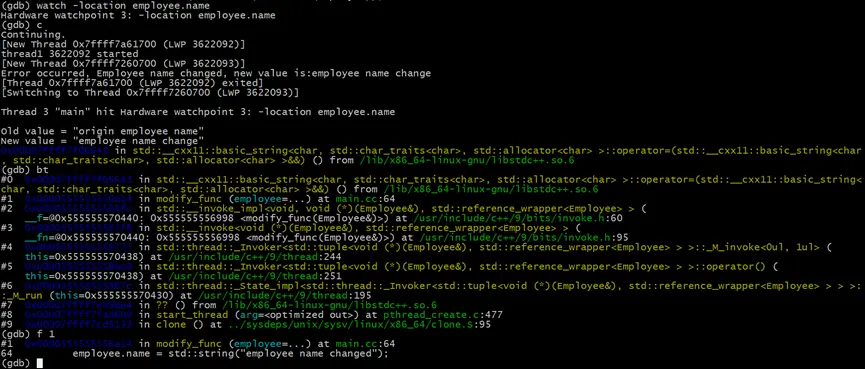
在觸發中斷後,我們發現是中斷位置是在modify_func方法中。正是這個方法,在內部修改了employee的name屬性。至此調查完畢。
5.5. 堆內存重複釋放問題排查
堆內存的重複釋放,會導致內存泄露,被破壞的內存可以被攻擊者利用,從而產生更為嚴重的安全問題。目標流行的C函數庫(比如libc),會在內存重複釋放時,拋出“double free or corruption (fasttop)”錯誤,並終止程序運行。為了修復堆內存重複釋放問題,我們需要找到所有釋放對應堆內存的代碼位置,用來判斷哪一個釋放堆內存的操作是不正確的。
使用GDB可以解決我們知道哪一個變量產生了內存重複釋放,但我們不知道都在哪裏對此變量釋放了內存空間的問題。如果我們對產生內存重複釋放問題的變量一無所知,那麼還需要藉助其它的工具來輔助定位。
下面我們使用兩個線程,在其中釋放同一塊堆內存,用來模擬堆內存重複釋放問題
void free1_func(Employee* employee) {
auto tid = gettid();
std::cout << "thread " << tid << " started" << std::endl;
employee->name = "new employee name1";
delete employee;
}
void free2_func(Employee* employee) {
auto tid = gettid();
std::cout << "thread " << tid << " started" << std::endl;
employee->name = "new employee name2";
delete employee;
}
void simulateDoubleFree() {
Employee *employee = new Employee("origin employee name");
std::thread thread1(free1_func, employee);
std::thread thread2(free2_func, employee);
thread1.join();
thread2.join();
}
編譯程序並運行,程序會因為employee變量的double free問題而終止

現在我們使用GDB來找到所有釋放employee變量堆內存的代碼的位置,以便決定那個釋放操作是不需要的
# 使用GDB加載程序
gdb main
# 在employee變量創建完成後的位置設置斷點
(gdb) b main.cc:101
# 運行程序
(gdb) r
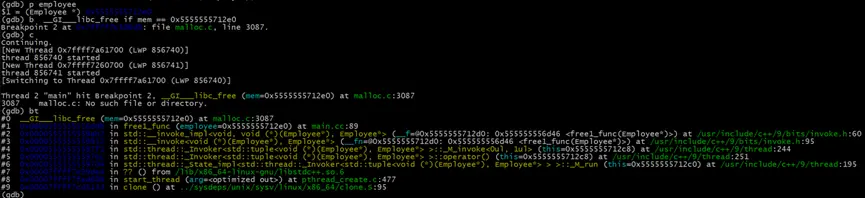
在程序中斷後,我們打印employee變量的堆內存地址,並在所有釋放此內存地址的位置添加條件斷點之後繼續執行程序
# 查看employee變量
(gdb) p employee //$1 = (Employee *) 0x5555555712e0
# 在釋放employee變量時,增加條件斷點
(gdb) b __GI___libc_free if mem == 0x5555555712e0
# 繼續運行程序
(gdb) c
在程序中斷時,我們找到了釋放employee變量堆內存的第一個位置,位於main.cc文件89行的delete employee操作。繼續執行程序,我們會找到另一處釋放了employee堆內存的代碼的位置。至此,我們已經可以調整代碼來修復此double free問題
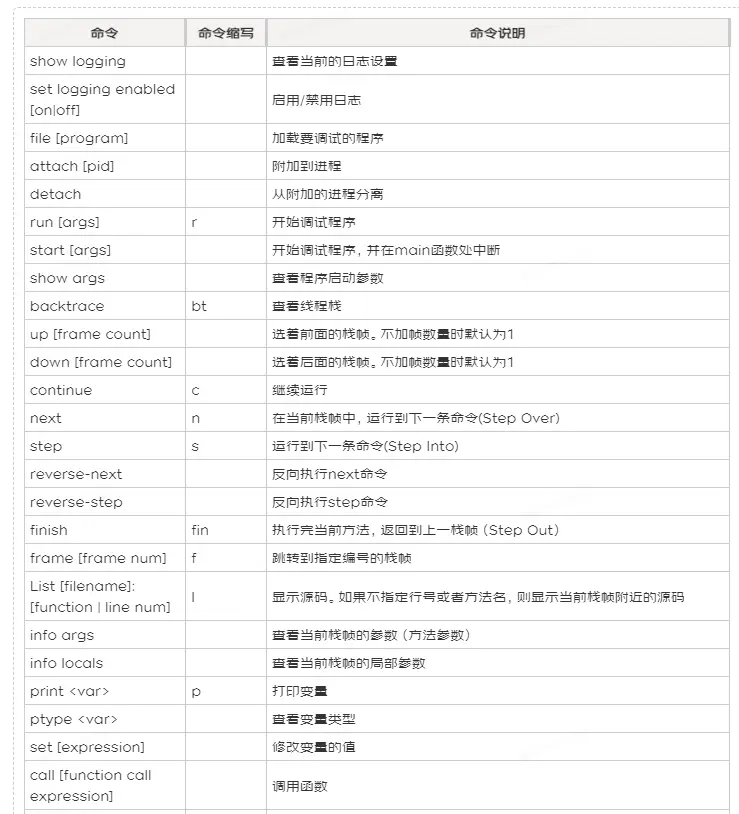
6. 常用的GDB命令
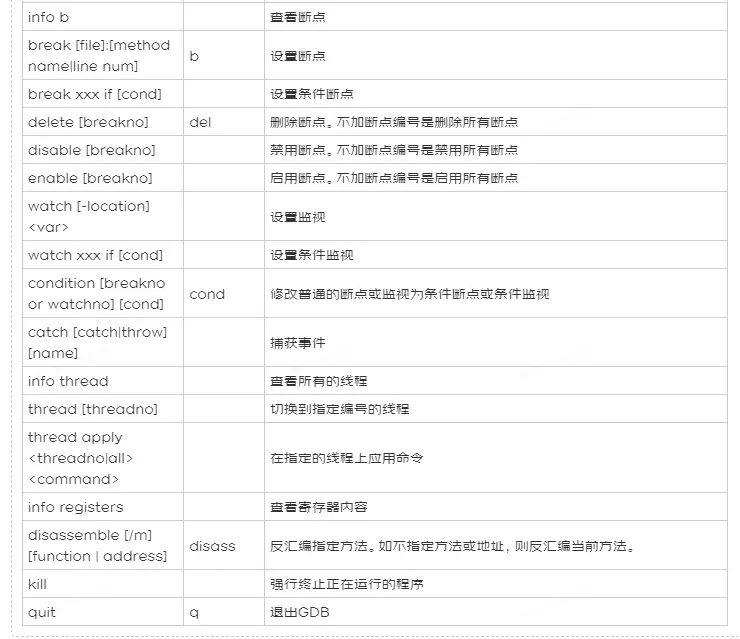
總結
GDB是探查查詢運行中各種疑難問題的利器。在實際應用中,問題產生的原因通常要複雜得多。程序可能在標準庫中產生了Crash,整個堆棧可能都是標準庫代碼;程序可能由於我們的代碼的操作,最終在三方中間件中產生了問題;整個異常堆棧可能都不包含我們自己開發的代碼;面對被三方庫不知以何種方式使用的變量。我們除了需要熟悉GDB的使用之外,在這些複雜的實際問題上,我們還需要儘可能多地瞭解我們使用的其它庫的機制和原理。




