









sjmj 《數據密集型應用系統設計》 - 數據編碼和演化
前言
本章的前半部分提到的編碼框架目前在GO領域如魚得水,並且有不少成熟的產品誕生,如果是GO工作者必然會接觸,如果僅僅是試圖瞭解該領域設計的一些技術架構,這一章更多的是掃盲和拓展眼界。
本章節的後半部分討論的RPC和SOAP,以及基於WebService服務跨語言通信服務,和RPC通信協議,但是WebService這東西現在用的人越來越少,反觀微服務才是當前的主流。
雖然需要住的是雖然HTTP/2已經出來不少年頭的了,但是RPC依然佔有重要的比重,所以也是值得關注的,最為典型的當然是Dubbo框架。
為什麼HTTP2.0都出來了,RPC還在繼續發展呢?
因為HTTP2.0 剛剛發佈的時候,RPC已經具備相當的發展,技術也相對成熟,另外很多項目系統架構已經完全搭建,換回HTTP2費力不討好,本身也沒有必要,因為RPC協議沒有特別大的缺陷。並且擁有不錯的特性 。
章節介紹
從歷史的演化的角度來看,雖然過去出現過許多嘗試替代HTTP協議的WEB通信框架,但是市場總是需要穩定成熟的架構,這些新興通信協議最終都默默黯淡在歷史的長河之中。
系統的演進除了數據結構和數據模型本身的演變之外,數據編碼和數據之間的交互模式也在不斷的進行演變,數據模式和格式改變的時候,通常需要應用程序的對應改變,而應用系統的痛點如下:
- 新版本的部署需要滾動升級(分階段下線節點然後有序上線),通過這樣的方式可以對於大規模升級的系統可以實現不暫停升級。
- 客户端應用程序需要依賴用户自行進行更新,或者使用強制更新手段強制升級。
這樣的應用程序調整不可避免的帶來關鍵性問題:前後兼容。
什麼是前後兼容?
向後兼容:較新的代碼由舊代碼編寫的數據。
向前兼容:比較舊的代碼可以讀取新編寫的數據。
向後兼容不是難事,因為在原有的基礎上擴展。向前兼容比較難,需要對於舊代碼忽略新代碼的添加。
雖然現在主流的傳輸結構是使用JSON,但是在這一章節將會擴展更多的數據編碼格式介紹,前面兩種無需過多介紹,這一章節主要介紹了後面三種針對數據編碼而存在類似中間件的框架:
- JSON
- XML
- Protocol Buffer
- Thrift
- Avro
數據編碼格式
數據表現形式無非兩種:
- 內存中數據保存對象,結構體、列表、數組、哈希表和樹結構等等,傳統的數據結構對於CPU高效訪問優化。
- 數據寫入文件通過網絡發送,必須要編碼為某種字節序列,但是由於一些虛擬字節比如指針的存在所以和內存的表現形式有可能不一樣。
術語問題,這裏的編碼其實就是指的“序列化”,但是序列化在不同的結構中意義不同,所以書中用了編碼解釋這一概念。
語言特定格式
通常有不少的編程語言支持把內存的對象編碼為字節序列碼,比如經典的Java.io.Serializable,Ruby的 Marshal,Python的 picle ,還有一些第三方庫比如 Kryo。
但是語言的特定格式帶來下面的一些問題:
- 編碼和特定語言綁定,無法完成不同編程語言互通。
- 恢復數據的時候需要解碼並且實例化對應實現類,序列化存在序列化攻擊隱患,比如通過實例化異常對象的方式找到系統的漏洞攻擊手段。
- 簡單快速編碼在編程語言常常導致前後兼容問題。
- JAVA的官方序列化低效被人詬病等。
JSON、XML以及二進制
二進制編碼
目前系統較為主流的形式是JSON, 而過去XML也流行過一段時間,但是後來很快被更為輕便的JSON取代,JSON最早是出現在JS上的一種數據結構,後來被廣泛採用在不同系統之間的通信格式,至今依然盛行。
XML和JSON的最大好處是使用字符串進行傳輸,並且JSON是JS內置的瀏覽器支持,具備很強的兼容性。
但是XML和JSON也暴露出不少問題:
- 數字編碼問題:JSON中無法區分數字和碰巧是數字的字符串,雖然JSON能識別出數字和字符串,但是無法區分數字的精度,也就是浮點數。
- 針對浮點數問題,IEEE 754 雙精度浮點數在JS上精度不佳。在推特中曾經有精度丟失的例子,2的53次方會導致一部分數據丟失而產生數據不準確問題,根本問題是使用了64位的數字去表示推文內容在JS中產生溢出!為了解決此問題推特最終使用了拆分小數位和整數位,以及使用字符串代替數字的方式表示一個數字,避開了JS語言的缺陷問題。
- JSON和XML對於文本支持較好,可閲讀性很強,BASE64編碼之後可以解除數據傳輸丟失的風險,但是與此同時也會帶來數據大小膨脹問題。
- XML和JSON都有模式可選支持,通常情況下大部分的編程語言可以通用編解碼方式,但是對於不使用這兩種編碼格式的則需要自己編寫。
- CSV沒有模式,他只是介於二進制和文本之間的一種特殊狀態,每一次數據改動都需要手動改動文件。
下面來討論二進制編碼問題。
二進制編碼的優勢在於數據體積小並且傳輸快,但是二進制真的和JSON文本的差異很大麼?
我們可以看到下面的編碼案例:
原始字符串內容如下,如果是傳統的編碼格式,下面的JSON字符串去掉空格需要80多個字節

在書中的案例中,經過二進制編碼的數據僅僅比JSON編碼格式縮小了10幾個字節,比如下面的編碼格式,僅僅比上面的原始JSON縮短了10多個字節,是否意味着在較小文本傳輸的時候優化編碼大小的性價比是很低的?

經過二進制編碼框架處理之後,可以精簡到32個字節甚至更小,約等於壓縮了50%甚至更高的內容。
二進制編碼框架定位
為了解決二進制編碼的性能遠不如文本JSON的問題,在數據編碼和模式出現了演進和深入研究。要更好地理解二進制編碼框架,我們需要了解他們的定位。
模式框架的設計理解基本和TCP/IP協議面對的問題類似,在差異不同的應用系統之間如何完成統一格式通信,並且在不同應用系統升級之後能以最小的成本完成向前兼容。
為了更加透徹的瞭解Thirft以及一系列數據編碼框架的設計定位,我們來看看Thrift的設計思想:
Thrift軟件棧分層從下向上分別為:傳輸層(Transport Layer)、協議層(Protocol Layer)、處理層(Processor Layer)和服務層(Server Layer)。
- 傳輸層(
Transport Layer):傳輸層負責直接從網絡中讀取和寫入數據,它定義了具體的網絡傳輸協議;比如説TCP/IP傳輸等。 - 協議層(Protocol Layer):協議層定義了數據傳輸格式,負責網絡傳輸數據的序列化和反序列化;比如説JSON、XML、二進制數據等。
- 處理層(Processor Layer):處理層是由具體的IDL(接口描述語言)生成的,封裝了具體的底層網絡傳輸和序列化方式,並委託給用户實現的Handler進行處理。
- 服務層(Server Layer):整合上述組件,提供具體的網絡線程/IO服務模型,形成最終的服務。
Thrift 和 Protocol Buffer
Apache Thrift 和 Protocol Buffer 基於相同原理二進制編碼,而Protocol 最開始由谷歌開發, Thrift 最初由 Facbook 開發,後面被 Apach 引進並且成為頂級項目。(老接盤俠了)
Thrift是Facebook於2007年開發的跨語言的rpc服框架,提供多語言的編譯功能,並提供多種服務器工作模式;用户通過Thrift的IDL(接口定義語言)來描述接口函數及數據類型,然後通過Thrift的編譯環境生成各種語言類型的接口文件,用户可以根據自己的需要採用不同的語言開發客户端代碼和服務器端代碼。
兩者的共同點是都需要使用模式進行編碼,所謂模式就是指如果通過語法來描述數據結構,需要按照指定的規範。
另外經過模式定義之後兩者都可以通過代碼生成器生成相關的對象代碼,支持多種編程語言,應用代碼生成器生成的代碼可以完成對應的編碼和解碼操作。
在Thirft 介紹一句話可以看到它最為基本的限制:
To generate the source from a thrift file run
有時候編碼框架可能具備多種編碼方式,比如Thrift 分為BinaryProtocol和 CompareProtocol。
實際上Thrift 還有DenseProtocol,但是因為只能支持 C++ 所以這裏並沒有算進去。
首先是傳統的BinaryProtocol方式,最終發現需要 59個字節進行編碼。
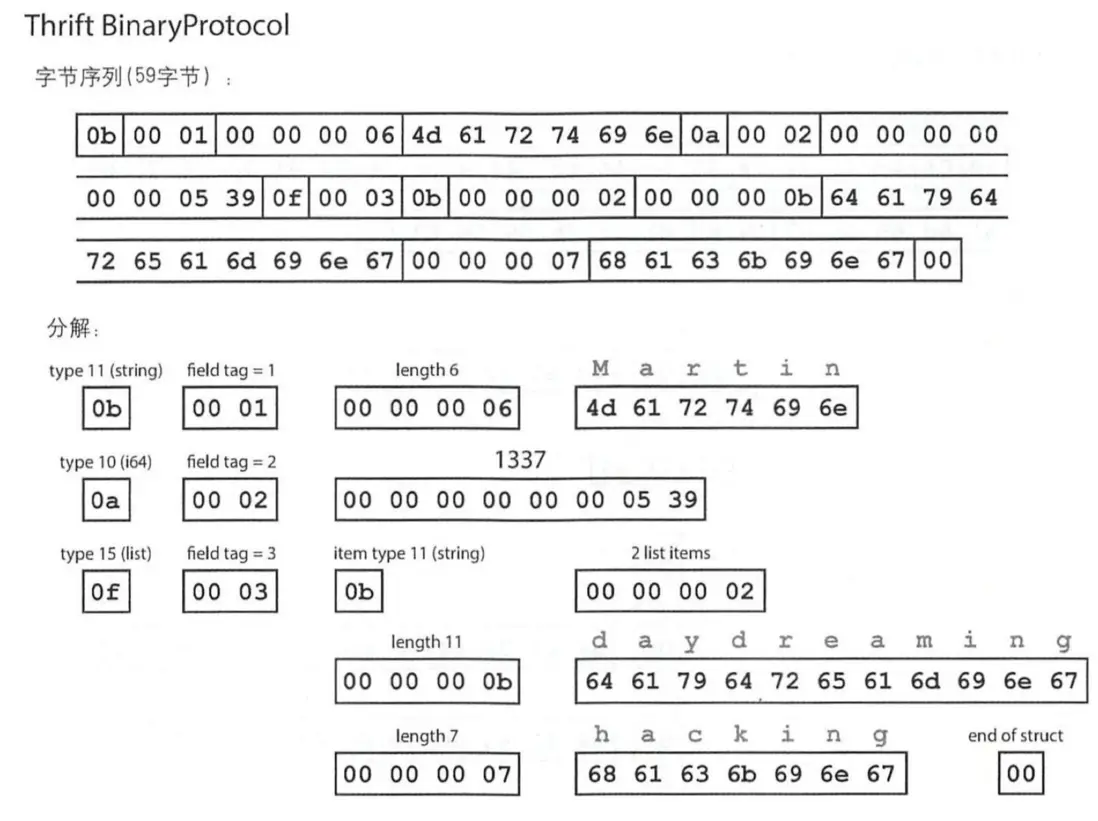
與上面的編碼方式類似的是對於字段的內容進行了ASCII編碼,區別是在字段名稱上的編碼方式存在區別,字段名會使用類似Tag的字段給字段名進行分類,這些數字主要用於模式定義。
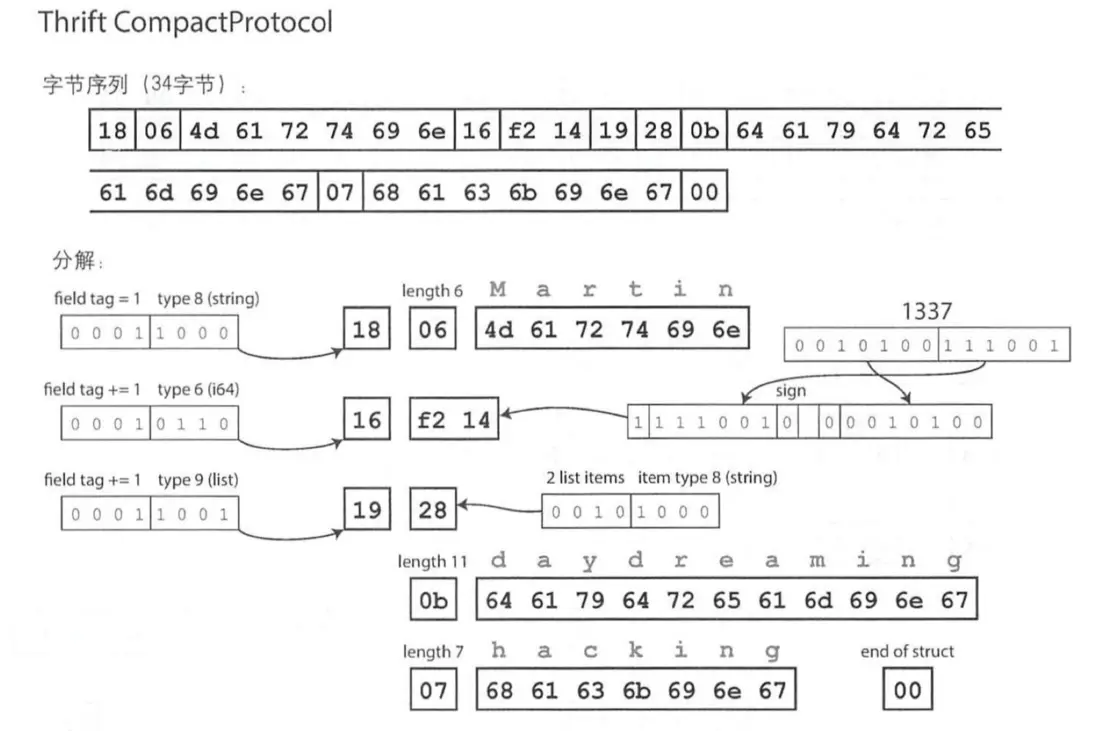
使用 CompareProtocol ,把相同信息縮減到34個字節完成表示,主要區別是字段類型和標籤號打包到單個字節當中,並且用變長整數實現。
Protocol Buffer 則只有一種編碼方式,打包格式粗略看上去和 CompareProtocol 比較像,只使用了33個字節表示重複的記錄。
這樣的區別來自於兩個模式對待重複字段的前後兼容的處理方式不太一樣。
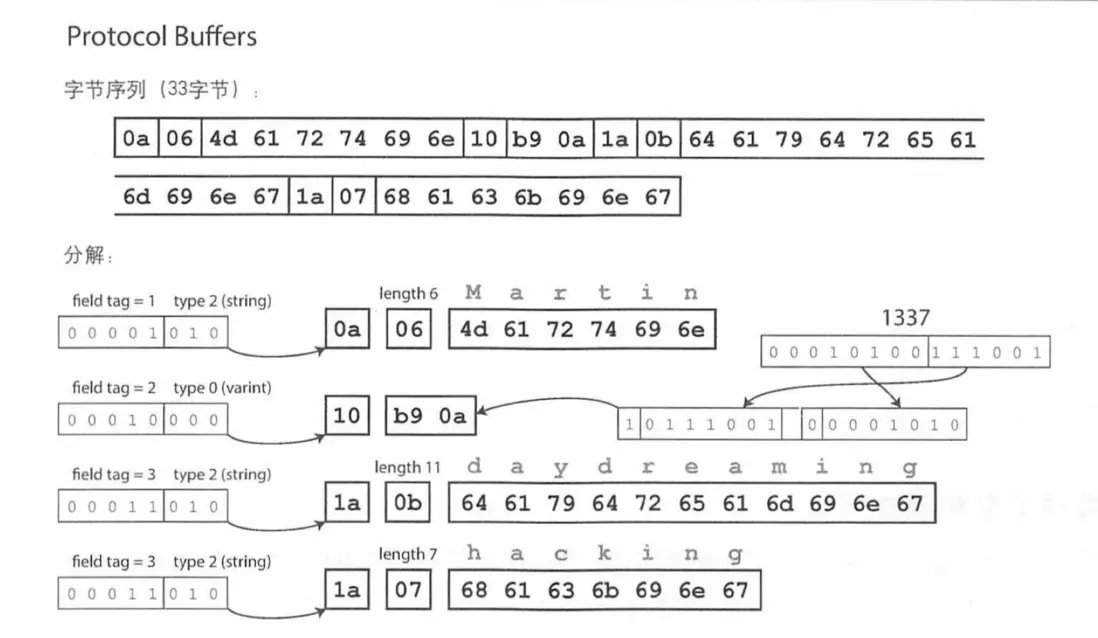
需要注意前面設置的模式當中可以標記為 required 和 optional ,這種標記對於編碼沒任何影響,但是如果 required 字段沒有填充數據,則會拋出運行時異常,這對於大型系統龐大數據系統檢查數據格式是非常有幫助的。
字段標籤和模式演化
瞭解完格式定義,接着便是編碼格式的模式演化。
通常一條編碼記錄是一組編碼字段的拼接,數據格式使用標籤號+數據類型(字符串或者整數)並以此作為編碼引用,編碼引用不會直接引用字段名稱,不能隨意的更改字段標籤,因為這樣處理容易導致編碼內容失效。
如果字段沒有設置字段值,則編碼記錄中將會直接忽略
添加字段兼容
為了實現向前兼容性,字段字段名稱可以隨意更改,標籤卻不能隨意更改。如果舊代碼視圖讀取新代碼的數據,如果程序視圖讀取新代碼寫入的數據,或者不能識別的標記代碼,可以通過類型註釋通知字段解析器跳過新增內容的解析。
而想要實現向後兼容性,因為新的標記號碼總是可以被新代碼閲讀的,所以通常不會有太大問題。但是有一個細節是新增的字段不能是必填的,這有點類似給數據庫新增必填字段,如果舊代碼不進行改動則業務整個鏈路會崩潰,相信大家都有這樣的體驗。所以保持向後兼容性初始化部署需要塞入默認值或者直接是選填字段。
刪除字段兼容
刪除字段的前後兼容剛好相反,向前兼容通常不會有多少影響,但是向後兼容必須是刪除非必填的字段,同時舊的標籤號碼需要永久廢棄,因為使用完全不同的數據類型標籤,新標籤覆蓋舊標籤號碼會導致程序出現奇怪現象。
字段標籤改變
如果是字段的刪減似乎問題並不會很大,使用標籤在引用之間再套一層的方式可以解決這個問題。
但是如果是字段本身改變要如何處理?比如把一個32位的整數轉為64位的整數,如果是新結構的代碼可以通過填充 0 的方式讓數值對齊,但是如果是舊代碼讀取到新結構的代碼,顯然會出現位截斷的問題。
現在來看 Thrift 和Protocol Buffer是如何解決這個問題的。
Protocol Buffer:利用字段重複標記(repeated,表示可選之外的第三個選項),用於標記同一個字段標籤總是重複的多次出現在記錄當中。
通過設置可選字段為重複字段,讀取舊代碼的新代碼可以看到多個元素的列表(前提是元素確實存在),新代碼可以挑選符合的值處理。而讀取新代碼的字段則只允許讀取列表的最後一個元素。
這種處理方案有點類似數據庫的版本快照,
Thrift:處理方式是使用列表對於字段標籤參數化,雖然沒有靈活的多版本變化,但是列表可以進行嵌套可以有更多靈活組合。
這種方式是類似用句柄的方式,利用“中間層”專門管理參數化標籤。
Avro
同樣是 Apach 的另一個二進制編碼,Avro 是 Hadoop 的一個子項目,同樣通過模式指定編碼的一種數據結構,主要的進攻方向有兩條:
- Avro IDL 人工編譯。

- JSON 利於機器讀取

這裏再一次用到之前的案例,Avro 對於同樣的內容僅僅使用32個字節的編碼。
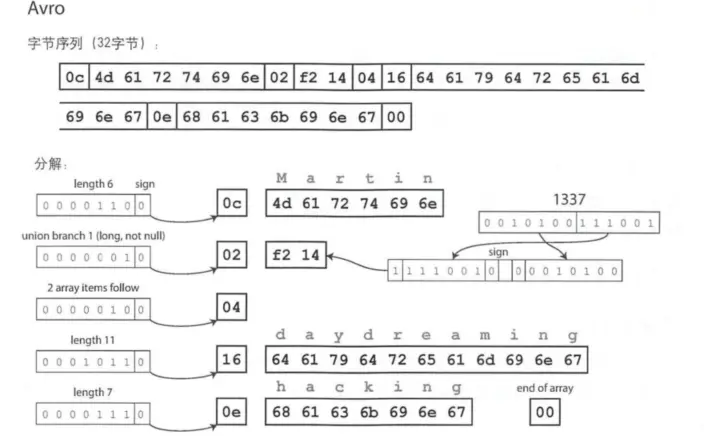
這種二進制編碼並沒有顯著的指示字段和數據類型,只是簡單的連接列值而已,字符串僅僅為長度前綴,只有整數使用了可變長度編碼。
這樣的靈活度不是依靠數據結構本身支撐,而是換了一種思路,對於二進制數據的讀寫制定一套規則,在Avro中被叫做讀寫模式。
寫模式和讀模式
- 寫模式:指的是對於任意數據可以使用已知模式的所有版本編碼,比如編譯到應用程序的模式。
- 讀模式:需要根據模式解碼某種數據的時候,期望數據符合某種模式。
和傳統的編解碼不一樣,Avro 讀寫模式之間是可以進行相互轉化的。
讀寫模式特點
最大的特點是讀寫模式不需要完全一致,只需要保持兼容即可,數據被解碼讀取的時候,通過對比查看讀寫模式,同時將寫模式轉為讀模式進行兼容,而主要的限制是讀寫模式的轉變需要符合Avro 的規範。
此外寫模式和讀模式的字段順序不一樣也是沒有問題的,因為模式解析會通過字段名稱對於字段進行匹配,如果讀模式碰到了出現在寫模式不存在讀模式的字段就會執行過濾,反過來如果讀模式需要字段寫模式沒有提供會使用默認值轉化。
模式演化規則
Avro的模式演化規則意味,在向前兼容中把新版本的模式作為write,把舊版本的模式設置為reader,向後兼容則是新代碼實現reader,舊版本模式為write。
這樣實際上就是實現了新版本的寫入會被新版本看到,但是舊版本不認識的數據就會被過濾掉。
Avro為了保持兼容性,只提供了默認值字段的增刪權限,比如新增帶有默認值的字段,使用新模式reader讀取會使用默認值(如果讀模式需要字段寫模式沒有提供會使用默認值轉化),使用舊模式write則會直接過濾,並且只在新模式中可以看見新增默認值字段。
下面是模式演化的一個案例。
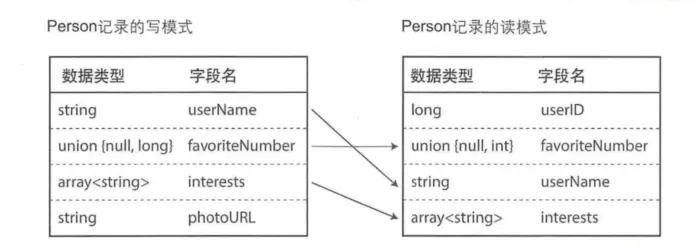
Avro 的前後兼容實質就是利write和reader這兩個模式切換,利用新舊版本屏蔽的方式兼容代碼。
Avro 除了這兩個模式的特點之外,還有一種非常特殊的情況,對於 null 內容的處理,這和多數編程語言不同,如果 Avro 中聲明 允許為null值,必須要是聯合類型。
聯合類型就像是下面這樣的格式:
union {null, long, string}和 ProtocolBuff 和 Thrift 都不太一樣只有當null是聯合分支的時候才允許作為默認值,此外它沒有默認標籤或者列表維護的方式可選(由於特殊數據格式設計導致的)。
write 模式選擇問題
Avro 還存在比較疑惑的問題,如何選擇 reader模式如何選擇write的版本?關鍵在於使用的上下文。
比如有很多記錄的大文件:因為Hadoop中所有的記錄都使用相同編碼,所以在這種上下文中只需要開頭包括write模式信息即可表示。
具有單獨寫入記錄的數據庫:不同的記錄需要不同的模式和不同的版本處理,處理這種情況最簡單的方式是每一個記錄編碼的開頭記錄一個版本號,並且在數據庫中保留一個模式版本列表。
reader模式通過從記錄的“數據庫”中提取write模式完成對應的操作,例如Espresso就是這樣工作的。
這個名字起的有點意思,翻譯過來叫做濃縮咖啡,在軟件領域是安卓的一款輕量級框架,詳細瞭解具體可以看看這個網站:Espresso 基礎知識 | Android 開發者 | Android Developers
網絡連接發送記錄,在建立連接的時候建立模式建立版本,然後在生命週期當中完成工作,Avro RPC的工作原理就是如此的。
動態生成模式
動態生成模式是 Avro 的另一項特點,動態生成對於模式兼容性更好,因為不帶任何的標點符號,可以快速完成不同模式之間的轉化。
比如如果數據庫模式轉為 Avro 模式,只需要根據關係模式作為中轉即可快速完成轉化,同時根據write和read模式的轉變快速完成被改變字段的同步工作。
這意味着 Avro的模式轉化似乎是其原生內容。如果使用 Thrift 或者 Protocol Buffers,則需要額外維護一套映射規則,同時維護模式生成器要特別小心錯誤分配標籤的問題。
因為動態生成模式是 Avro 的設計目標之一,所以它在這一塊表現十分出色。
代碼生成和動態類型語言
傳統思維上我們認為編碼框架比較常用於靜態語言,對於動態類型編程語言實際上並沒有太多的意義,但是Avro卻走了一條特殊的路。
但是對於Avro的動態生成模式,使用固定格式框架代碼反而是累贅,因為本身就可以通過動態模式完成模式轉化。
Avro的動態生成模式經常和動態類型數據處理語言結合使用,可以認為此編碼框架本身就具備代碼生成器的功能。
總之,不能帶着刻板印象看待編碼框架,有時候不同的設計思路,同樣的賽道上會出現特殊的產品,就好比圖數據庫走了以前的網絡編程模型的老路,卻開闢一條特殊的路徑。
動態類型語言是指在運行期間才去做數據類型檢查的語言, 動態類型語言的數據類型不是在編譯階段決定的,而是把類型綁定延後到了運行階段。 主要語言:Python、Ruby、Erlang、JavaScript、swift、PHP、Perl。
模式的優點
通過上面的一系列對比討論,我們發現模式對比JSON和XML格式相比,使用獨特的框架設計以及簡單易懂、可維護的特點,被廣泛的編程語言支持。
實際上模式框架本身的思想並不是什麼新東西,ASN.l 在 1984年首次被標準化的模式定義語言中可以看到類似的影子,ASN.I 本身也被用於SSL證書的二進制編碼(DER)當中。
對比模式和XML以及JSON,它們通常具備下面的特點:
- 數據更加緊湊,甚至可以省略數據當中的字段名。
- 模式本身具備文檔化價值 ,可維護性要強於XML和JSON。
- 模式具備前後兼容性的檢查,對於大系統的升級維護這是非常有必要的。
- 對於靜態類型編程語言的用户來説,從模式生成代碼的能力是有用的,它能夠在編譯時進行類型檢查。
數據流模式
編碼模式解決了不同架構之間的數據交流問題,為了實現這一目標,它需要具備簡單的同時包含自動前後兼容的特徵,所以歸根結底模式是解決系統變更困難的問題。
流模式則討論另一個話題,數據流動的過程,在軟件系統生態架構中數據流動無非下面幾種形式:
- 通過數據庫(實際上依然可以認為是中間件)。
- 通過異步服務調用。
- 通過異步消息傳遞。
基於數據庫流動
寫模式對數據庫編碼,讀模式對數據庫解碼。數據庫通常需要保證向後兼容,否則後面的版本無法讀取之前的內容。
由於併發性問題不同的進程看到的數據狀態可能具備差別,意味着數據庫的數值可以被新版本寫入,同時要兼容舊版本繼續讀取,説明數據庫也需要向前兼容性能。
基於數據庫的流動\問題和模式類似,新增一個字段容易導致數據讀取的問題,理想情況下是舊版本代碼保持新版本字段的不變,哪怕完全無法解釋。
首先需要注意是新舊版本轉化問題,有時候在應用程序讀取新對象進行解碼,之後在重新編碼的過程中可能會遇到未知字段丟失的問題。

為了解決上面提到的向前兼容問題,數據往往採用的方式是把磁盤編碼的所有數據填充空數值。
注意一些文檔數據庫本身會利用模式來完成向前兼容,比如 Linkedln 的文檔數據庫Espresso使用,Avro進行存儲,並支持的Avro的模式過渡規則。
歸檔存儲
所謂的歸檔存儲指的是對於數據庫存儲快照,由於使用快照對於數據進行恢復,所以需要對於數據副本進行統一編碼。
像Avro對象容器文件這樣的對象容器文件十分合適,因為沒有額外的模式字段維護,只需要利用框架本身的模式完成轉化。
歸檔存儲在本書第十章“批處理系統”有更多討論。
基於服務數據流:REST和RPC
REST和RPC的概念
在系統應用中WEB應用是最多的,而關於WEB的傳輸API包括(HTTP、URL、SSL/TLS、HTML)等,這些協議在過去受到廣泛認可,現在已經成為大多人同意的標準。
通常情況下HTTP可以用作傳輸協議 ,但是在頂層實現的API是特定於應用程序的,客户端和服務器需要就API的細節達成一致。
RPC的概念通常和微服務做比較,現代的系統設計更加傾向於細化分工和服務職責拆分,就算是簡單的系統也會按照分模塊的方式進行職權拆分,獨立部署和快速演化是微服務的目標。
實際微服務也誕生這樣的問題,不同的團隊持有不同的微服務模塊,這帶來了API兼容以及數據編碼的問題,這也是為什麼編碼框架和異步通信框架的誕生。
網絡服務
針對WEB服務有兩種流行的處理方法:REST 和 SOAP,這兩個都不算是新東西。REST是基於HTTP協議的設計而改造的另一種概念 和強化,SOAP是基於XML的協議。
REST 的概念是利用URL標識資源,通過HTTP協議本身完成緩存控制,身份驗證和內容類型協商。不同的是為資源定義更為明顯的標記和界限。REST原則所設計的API稱為RESTful Api。
SOAP用於發送API請求,但是由於龐大複雜的多重相關標準,這幾年逐漸被REST簡單風格替換。SOAP WEB服務的API叫做WSDL。支持代碼生成和訪問遠程服務,但是同樣針對動態編程語言的生成效果很弱。
儘管SOAP及其各種擴展表面上是標準化的,但是不同廠商的實現之間的交互操作性往往存在一些問題,SOAP雖然依然被一些大廠商使用,但是針對小公司來説已經不再受到歡迎,而到了現在整個WebService的使用範圍也在不斷縮小。
需要注意這些討論都是基於作者是外國人對於國外編程環境的探討,到了國內則是完全不同的另一番景象。
最後,ResultFul 的API生成工具目前較為主流的是使用 Swagger,Swagger組件也是目前對外文檔的一種優秀格式,雖然註解和文本描述會讓接口變得“複雜”,但是確實十分好用。
遠程調用RPC
在過去許多的編程語言的遠程方法調用大肆宣揚,但是它們多少都存在缺陷或者一些明顯的短板,比如:
- JAVA的EJB遠程方法調用僅限於JAVA;
- 分佈式組件對象模型 DCOM 適用於微軟平台;
- 請求代理體系 CORBA 缺乏前後兼容被放棄;
遠程方法調用的思想從上世紀70年代就已經出現了,RPC起初看起來很方便,但這種方法在根本上有明顯缺陷, 網絡請求與本地函數調用的巨大差別:
- 本地函數調用可控可維護。
- 本地函數調用的結果基本可以預知,比如超時和進程崩潰都可以通過各種手段排查。
- 每一次重試失敗需要花費相同的時間繼續重試,如果一個任務總是在將要完成的時候崩潰,不僅佔用資源還容易導致系統的各種複雜情況。
- 本地函數可以借用內存完成對象的之間的高速傳遞。
- 本地和遠程調用端用不同語言實現,所以中間需要進行轉化,或者藉助編碼框架完成前後兼容。
RPC發展
個人接觸微服務比較多,對於RPC瞭解不是很足,目前的看法是不温不火但是並沒有完全消失。Thrift和Avro帶有RPC支持, gRPC是使用 Protocol Buffers的RPC實現, Finagle也使用 Thrift , RestFul 使用 HTTP上 的JSON。
RPC框架還在繼續發展,新一代框架更加明確RPC和本地函數調用。
- Finagle 和 RestFul 使用 Futures 封裝失敗異步操作。
- Futres 簡化多項服務結果合併。
- gRPC支持流。
此外二進制編碼格式也支持自定義的RPC協議,對於一些REST和JSON的協議具有更好的性能。RESTFUL的設計風格現在看來反而有點脱褲子放屁,因為不過是包裝了一層HTTP協議而已,似乎SOAP的設計才是符合RPC的定義,這個話題也經常被放上來進行討論。
RPC 的數據編碼和演化
由於是遠程調用,涉及不同服務之間的通信,必然涉及到編碼演進和前後兼容問題,而針對前後兼容問題,RPC出現制定了下面一些方案:
- Thrift 、 gRPC (Protocol Buffers )和Avro RPC可以根據各自編碼格式的兼容性規則處理。
- SIAO XML 雖然是可以演化的,但是有陷阱。
- RESTFul 使用JSON格式保持兼容性。
此外對於RESTful API ,常用的是在URL或HTTP Accept頭中使用 版本號限定調用和兼容性保持。另一種選擇是客户端請求的API版本存儲服務器,同時提供多版本的接口管理調用功能。
異步消息
RPC 和數據庫之間的異步數據消息傳遞,是本章的最後一個話題,和RPC調用類似,客户端的請求同樣低延遲推送到另一個服務進程。消息隊列通過暫存消息的方式,嫁接生成者和消費者。
和RPC相比的消息隊列有下面幾個特點:
- 消息隊列可以充當緩衝照顧雙方的處理能力。
- 避免發送方需要知道接收方IP和地址的問題。
- 支持一個消息發給多個接收方。
- 邏輯上的發送方和接收方分離。
消息隊列比較顯著的問題是消息傳遞是單向的,同時並不在意消費方是否進行迴應。發送者發送之後通常會忘記它的存在。
消息隊列
消息隊列最早是由一些商用收費軟件控制,之後才出現各種開源流行軟件kafka、activeMQ、HornetQ、RabbitMQ等。
同一個主題上可以綁定多個生產者和消費者,消息隊列不會強制任何數據類型,消息傳遞的元數據都是一些字節數據。
此外,主題通常只指定單向流,但是消息本身會發給另一個主題和可能存在的多個消費者綁定。
消息隊列的另一顯著優勢是前後兼容很容易實現,最大靈活的調整雙方即可。消息隊列的內容在12章會繼續進行闡述。
分佈式Actor框架
Actor模型是1973年提出的一個分佈式併發編程模式,在Erlang語言中得到廣泛支持和應用,Erlang是啥這裏讀者有可能忘了,簡單關聯一下:JVM實現的主要編程語言。
Actor是基於單進程的併發編程模型,所有的邏輯被封裝到Actor而不是現成當中,每個Actor代表客户端的一個實體,也就是可以把每一個線程等同於一個進程看待。由於是單進程的設計,不需要線程問題,每個Actor都可以自由調度。
Actor 模型的計算方式與傳統面向對象編程模型(Object-Oriented Programming,OOP)類似,一個對象接收到一個方法的調用請求(類似於一個消息),從而去執行該方法。
Actor的最大特點是可以編程模型可以跨越多個節點擴展應用程序,無論發送和接收方是否在一個節點。換種説法是在不同的節點上消息被透明封裝為字節序列並且通過網絡傳遞,同時在另一端解碼。
分佈式Actor實際上就是把消息隊列和Actor的編程模型綁定到單進程當中,可以簡單看作是特殊版本的消息隊列,這樣有一個好處是屏蔽了複雜性,但是壞處是程序無法細粒度的控制編程模型和函數,所有的規則都被Actor牢牢控制,此外Actor的明顯缺陷是具備前後兼容性的問題,因為新版本的節點可能被送到舊節點可能無法正常工作。(這和JAVA的版本一樣存在問題)
下面是Actor處理消息編碼的方式實際應用:
- 使用Akka抽象讓JAVA內置序列化,可以利用Protocol Buffers完成前後兼容。
- Orleans 使用自定義編碼格式,需要部署新版本應用程序,同樣可以支持序列化插件。
- 在Erlang OTP 當中,但是很難對於記錄模式更改。
Akka:
對並行程序的簡單的高層的抽象;異步非阻塞、高性能的事件驅動的編程模型;非常輕量的事件驅動處理(1G內存可容納270萬個Actors)。
小結
本章內容量比較龐大。第一個維度是討論了數據格式的編碼問題,以此產生了內存結構轉為網絡或磁盤字節流的方法,第二個維度是基於數據格式編碼的前後兼容問題而誕生的不同框架對比:Thirft、Protocol Buffer、Avro,其中Avro花了很多的篇幅講述,顯然是本章的重點之一。
而最後一個維度則換到了另一面,從數據流動的方式看問題,和前面維度不同的是它如果把前兩個看作設計一艘好船(數據格式)能停到不同的港口(服務),而數據流則是載着這些數據以何種形式流動,數據流的正常流動是目前的核心,現代是高可用為王。
在編碼的細節內部可以看到哪怕是一個字節的變動都有可能帶來性能影響,同時不同的設計理念直接影響系統的部署方式。
在許多服務需要滾動升級的情況下,新版本需要依次部署到幾個節點,滾動升級是在不損害舊版本正常運行下“不停機”升級系統版本的通用手段,同時有效降低部署上線的風險。
滾動升級需要考慮最大問題是數據格式的前後兼容問題,在微服務和模塊更加細化的今天,這樣的情況更加頻繁出現,哪怕是小項目也可以實現分佈式部署,這樣也帶來了編碼框架的前後兼容影響。
至於Avro,這一章作者對它他吹特吹,但是個人並沒有使用過類似的編碼框架經驗,關於各種體驗筆記也只有個大概印象。
接着本章討論了下面這些問題,首先是關於編碼問題的討論:
- 特定語言只在特定的領域適用,雖然JVM的野心是統合所有的編程語言,但是顯然還有漫漫長路要走。
- JSON、XML是經典的通用兼容模式語言,但是因為廣泛使用的JSON誕生於JS在數字類型上存在明顯紕漏。
- Thirft、Protocol Buffers 和 Avro 遵循二進制編碼的原則,對於數據進行前後兼容和高效編碼,靜態編程語言對於這樣的框架十分受用,得到廣泛的編程語言的認可和支持。尤其是在GO的領域大放異彩。
之後是數據流的討論,數據流目前已經非常成熟:
- 數據庫,因為存在“舊版本”數據讀取的場景,通常使用特殊方式對於數據進行編解碼,保證數據向前兼容讀取。
- RPC以及RESTFUL,RPC依然在蓬勃發展。
- 消息隊列,高可用和高性能的代表產物,也是現代架構設計的三大馬車之一(緩存、消息隊列、數據庫),現代項目的三馬車則是微服務、消息隊列和定時任務。
- 分佈式Actor框架,大數據中重要框架,如果是接觸大數據的相關人員,Actor框架顯然佔有重要的一席之地。
寫在最後
這一章節均為理論和視野拓展,個人來看並不算是非常重要的章節(主要是沒有實際接觸),當然也寫不出多少東西,感興趣可以針對某一個話題深入瞭解。
參考資料
Actor 分佈式並行計算模型: The Actor Model for Concurrent Computation - 騰訊雲開發者社區-騰訊雲 (tencent.com)
深入解析actor 模型(一): actor 介紹及在遊戲行業應用 - 知乎 (zhihu.com)
聊聊日常開發中,如何對接WebService協議? - 掘金 (juejin.cn)








