









天天聽人説“數據架構”,是不是覺得有點懵又有點煩?別急!今天咱們就拋開那些高大上的術語,好好聊聊:數據架構到底是啥?它為啥這麼重要? 其實説白了,數據架構就是你公司裏那套管數據的“規矩”和“方法”——數據放哪?怎麼算?怎麼跑?怎麼用?全歸它管!
為啥要搞這套“規矩”?因為數據太亂了!到處是孤島,質量參差不齊,想用的時候找不着、用不好。好的數據架構,就是來解決這些頭疼事的!它能讓你公司的數據井井有條、安全可靠、隨時能用,真正支撐起業務決策。想搞明白它怎麼做到的?跟着我往下看就知道了!
一、什麼是數據架構
説白了,數據架構就是你組織和管理數據的那套方法,它管的是數據怎麼存、怎麼算、怎麼流動、怎麼用。具體點説,要考慮怎麼設計數據模型、選什麼數據庫、數據怎麼在不同系統間交換傳遞,核心目標就一個:確保你的數據有效、安全、隨時能用得上。
它的終極使命就是穩穩當當地支撐你的業務需求,把數據的質量和一致性提上去,同時讓數據能順暢地共享和整合,打破數據孤島。
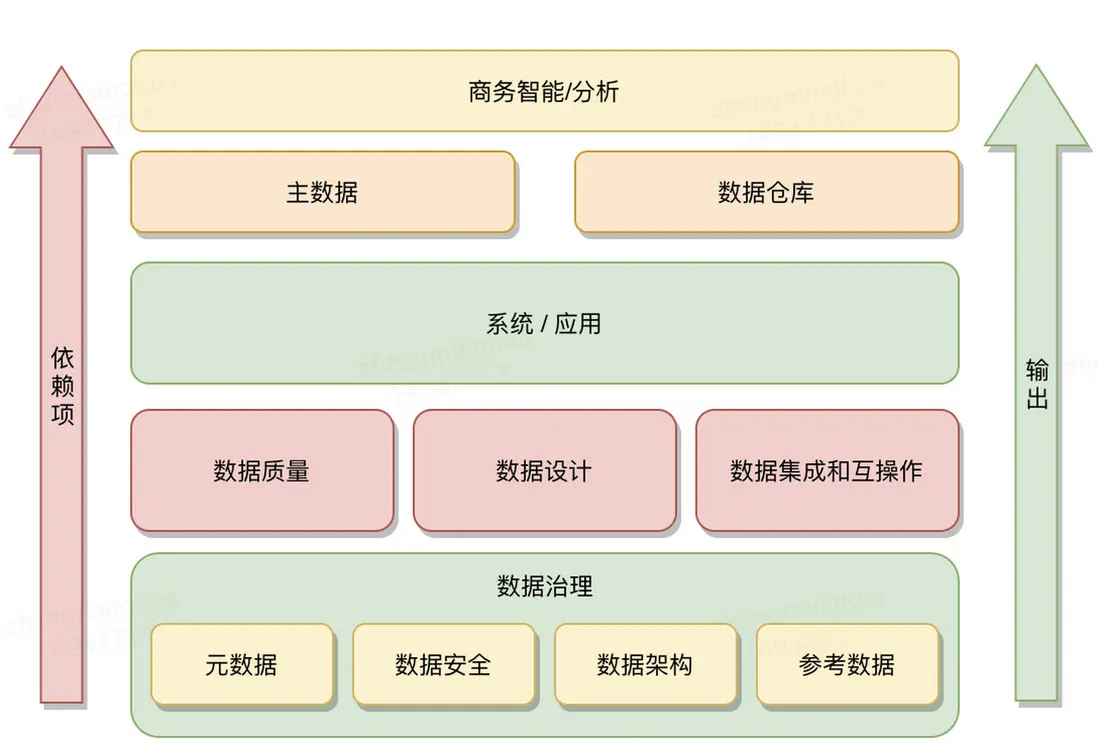
簡單來説,數據架構描繪了數據從“生”到“用”的全過程管理藍圖。它管的是數據從收集進來、經過轉換處理、再到分發出去、最終被使用的整個鏈條。它為數據本身,以及數據在各種存儲系統裏怎麼流動,定下了規矩和框架。
聽着是不是很熟?沒錯,它就是所有數據處理操作和人工智能(AI)應用的地基。我一直強調,數據架構的設計,必須從業務需求出發! 數據架構師和工程師們,就是拿着這些業務需求,比如老闆要什麼報表、業務部門想做哪些分析等等,去設計對應的數據模型,以及支撐這些模型的基礎數據結構。説白了,好的架構設計,就是為了讓業務需求能落地。
二、數據架構的用處
現在新東西太多了,像物聯網(IoT)這樣的技術,天天冒出新數據源。這時候,一個好的數據架構就顯出本事了:它能讓這些海量數據管得住、用得好,支撐整個數據的生命週期管理。具體怎麼做到呢?
1.避免數據重複存: 同一份數據別到處亂存,省地方也省管理功夫。
2.提升數據質量: 通過清洗(去掉髒數據)、去重(去掉重複數據)這些操作,讓數據更乾淨、更可靠。
3.支持新應用: 新業務要上新系統?好的架構能更輕鬆地接入。
4.打通數據壁壘: 提供跨部門、跨地域整合數據的機制,打破“數據孤島”。這很重要,因為把所有數據都堆在一個地方,管理起來會複雜得要命,現在不用這麼幹了。
現代數據架構還有個趨勢:愛用雲平台。雖然看着花錢多點,但好處也實實在在:
1.算力能伸縮: 需要大量計算的任務(比如分析報表),能快速搞定。
2.存儲能伸縮: 數據量再大也不怕存不下,確保所有該有的數據都在手邊。
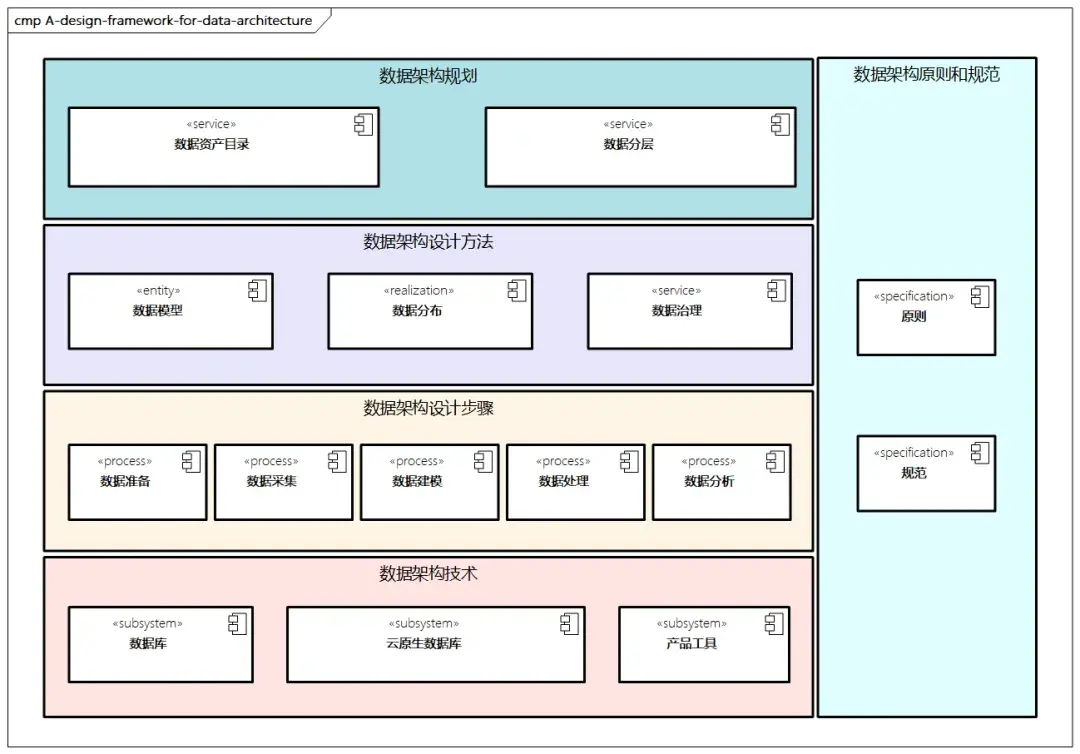
三、數據架構的發展歷程
數據架構不是一天建成的,它是跟着技術和業務需求一點點長起來的。理解它的過去,才能用好它的現在和未來。
1. 早期階段(1960年代-1970年代)
(1)文件系統管理: 最早數據就存在文件裏,一個應用管自己的數據。聽着就很麻煩吧?數據想共享?想整合?難上加難!
(2)層次模型和網狀模型: 60年代末70年代初,為了解決文件系統的不足,出現了更復雜的模型。像IBM的IMS(層次模型)和CODASYL DBTG(網狀模型)。它們能表達更復雜的數據關係了,但説實話,用起來還是複雜,不夠靈活。
2. 關係數據庫的興起(1970年代-1980年代)
(1)關係模型: 1970年,Edgar Codd提出了關係模型,用數學理論來嚴謹地描述數據結構和操作,這下數據組織可就靈活多了。
(2)SQL和DBMS普及: 關係模型火了,SQL語言成了標準操作語言,關係數據庫管理系統(DBMS)如DB2、Oracle、MySQL也迅速崛起,成了企業管數據的頂樑柱。
3. 數據倉庫和數據挖掘(1980年代-1990年代)
(1)數據倉庫誕生: 光管業務數據不夠了,決策需要更全面的分析。90年代,Bill Inmon和Ralph Kimball提出了數據倉庫概念。核心思想就是把分散在各個業務系統的數據,整合到一個大倉庫裏,專門支持分析決策。它特別強調數據的整合、歷史數據的保存,還有查詢和報告要高效。
(2)數據挖掘起步: 數據多了,怎麼挖出數據價值?數據挖掘技術開始受到重視,用來在海量數據裏找規律、找價值。
4. 大數據和NoSQL(2000年代)
(1)大數據挑戰: 互聯網、社交媒體爆發,數據量(Volume)、種類(Variety)、速度(Velocity)猛增,傳統關係數據庫扛不住了。這時候,Hadoop、Spark這些大數據技術應運而生,專治海量數據處理分析。
(2)NoSQL崛起: 處理日誌、社交內容等非結構化數據和高併發請求,靈活的非關係型數據庫(NoSQL)如MongoDB、Cassandra成了新寵。它們不依賴固定的表結構,存和取數據都更自由。
5. 數據湖和雲計算(2010年代至今)
(1)數據湖興起: 什麼數據都可能有價值,不管結構化的(表格)、半結構化的(JSON)、還是非結構化的(圖片、文本)。數據湖的理念就是把各種原始數據,按原樣先存到一個大池子裏(集中存儲)。等要用的時候再按需處理分析,非常靈活,常和大數據技術搭檔。但我一直強調,好的架構需要好工具落地。FineDataLink (FDL) 就是一個專注於一站式數據集成的平台,它操作簡單,拖拖拽拽就能完成數據抽取、清洗、轉換、整合、加載這些關鍵步驟,不用寫大量複雜代碼。而且內置豐富的數據處理能力,比如自由組合清洗規則、數據去重、合併、拆分、聚合等等。這能大大提高你處理數據的效率和準確性,讓你把精力更多放在數據分析和業務價值上。
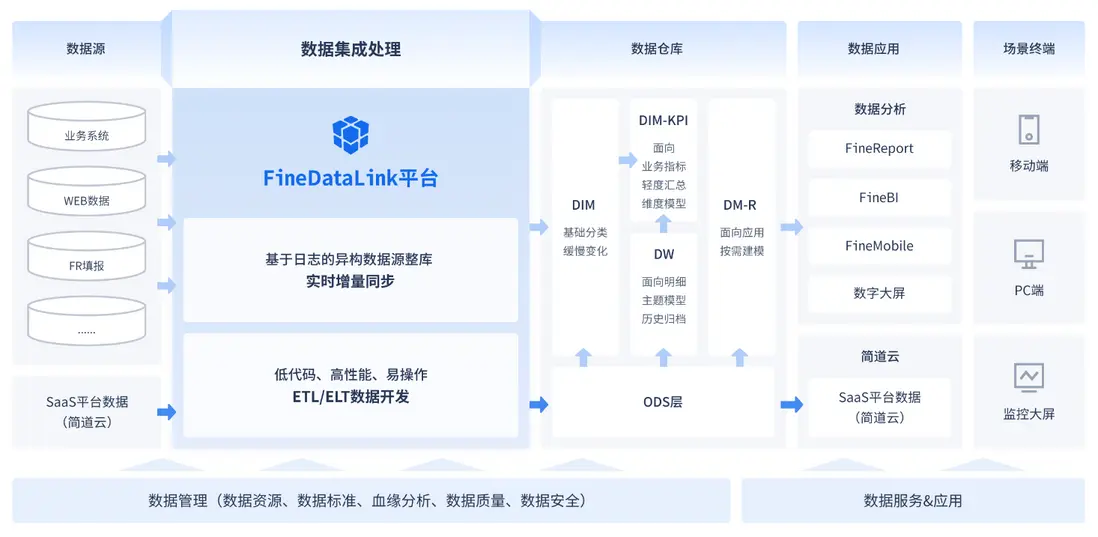
(2)雲架構成主流: 雲計算普及徹底改變了玩法,像Amazon RDS、Google BigQuery、Snowflake這些雲數據庫和數據倉庫服務,提供了彈性伸縮、按需付費的解決方案。企業不用自己買一堆硬件了,管理和分析數據的門檻和成本都大幅降低。
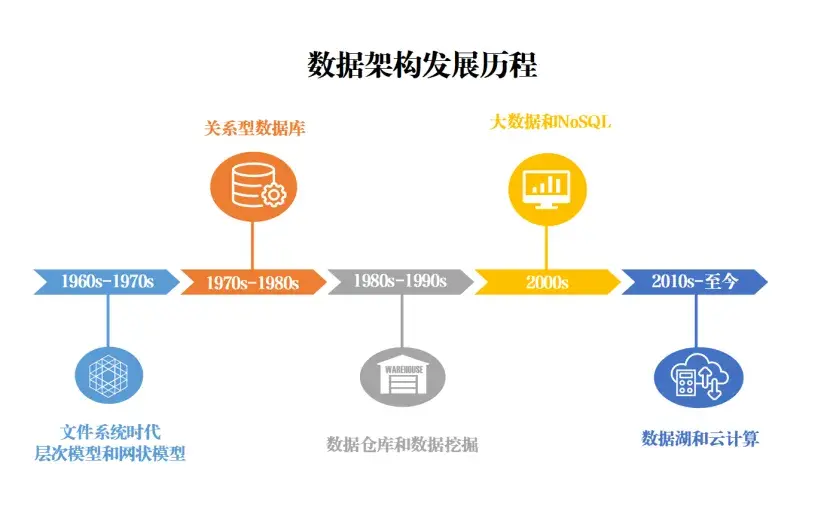
總結這段歷史,説白了,數據架構的演變,就是技術推着它走,業務需求牽着它走。從最開始的簡單存文件,到複雜的關係數據庫、數據倉庫,再到對付海量數據的大數據技術,直到現在靈活強大的雲架構和數據湖,每一步都是為了解決當時數據量更大、處理需求更復雜的問題。
四、流行的企業架構框架
設計企業級的數據架構,可以參考一些成熟的大框架。這裏介紹三個最主流的:
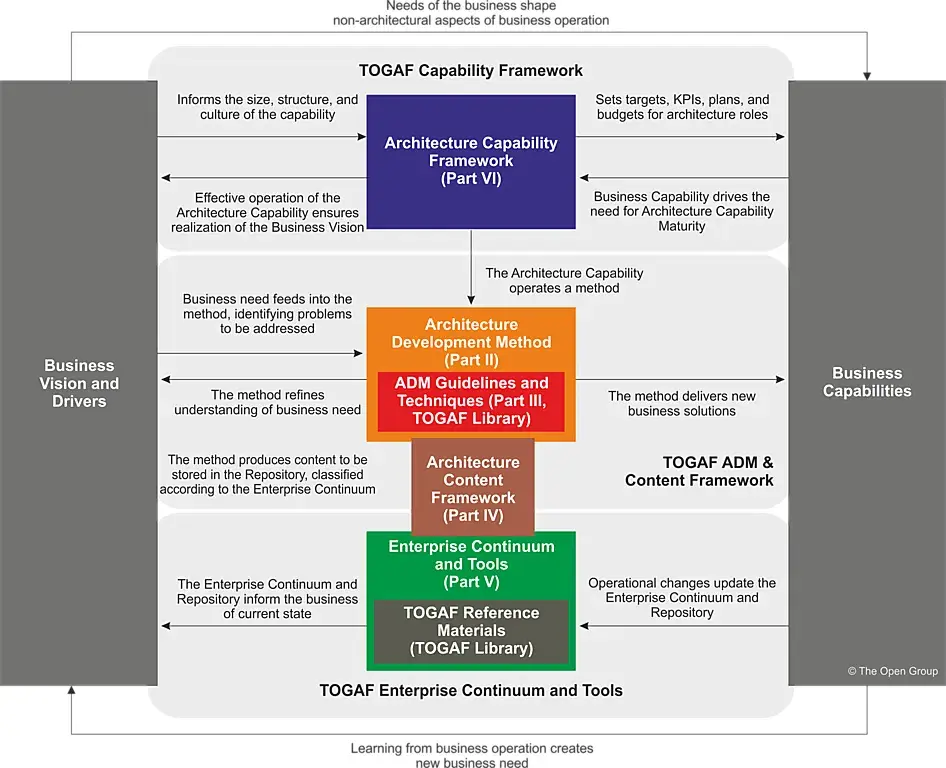
1. TOGAF (The Open Group Architecture Framework)
由The Open Group在1995年搞出來的,IBM是核心成員。四大支柱撐起整個企業架構:
(1)業務架構: 定義公司怎麼組織、業務策略和流程。
(2)數據架構: 管概念、邏輯、物理數據資產,以及它們怎麼存、怎麼管。
(3)應用架構: 描述有哪些應用系統,它們跟關鍵業務流程什麼關係,彼此之間又怎麼交互。
(4)技術架構: 説清楚支撐關鍵應用需要啥硬件、軟件、網絡(技術基礎設施)。
簡單來説,TOGAF提供了一個設計實現整個企業IT架構(當然包括數據架構)的完整“説明書”和流程。
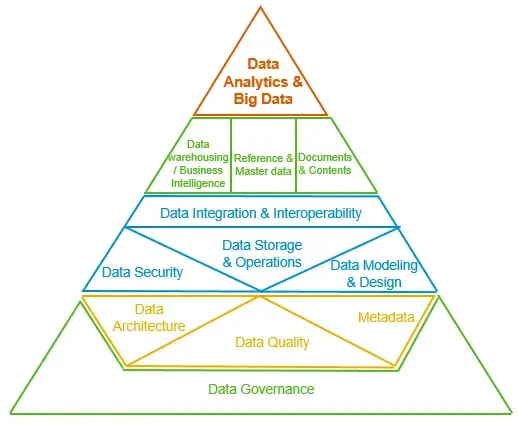
2. DAMA-DMBOK 2
DAMA International(國際數據管理協會)是個非營利組織,專注推動數據和信息管理。它做出的 DAMA-DMBOK 2(數據管理知識體系),內容非常全面。數據架構只是其中一大塊,其他還包括數據治理與倫理、數據建模與設計、數據存儲、數據安全、數據集成等等,相當於一本數據管理的百科全書。
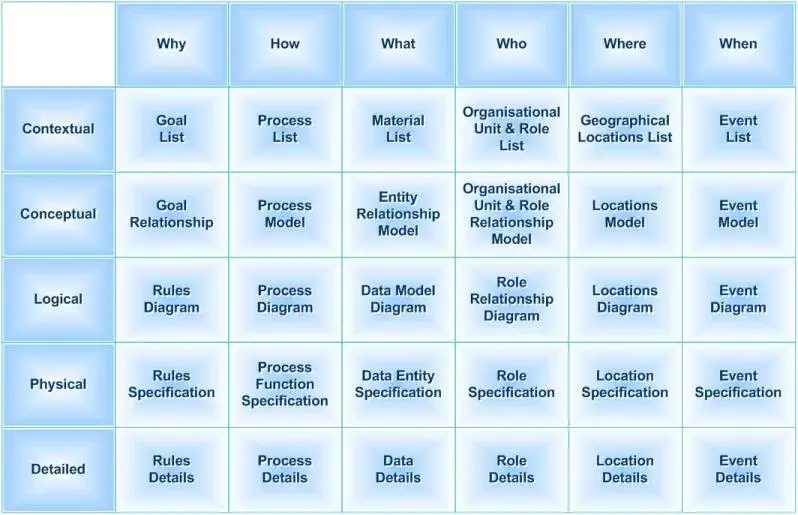
3. Zachman 企業架構框架
最早是IBM的John Zachman在1987年提出的,它的特點是用一個6x6的矩陣來組織架構。行代表不同視角(從最宏觀的“老闆視角”到最細節的“開發視角”),列代表核心問題(What東西、How怎麼工作、Where在哪用、Who誰負責、When什麼時候、Why為什麼)。它提供了一種非常嚴謹、正式的方式來梳理和組織企業架構,告訴你該考慮哪些方面,但它本身不規定具體怎麼做。
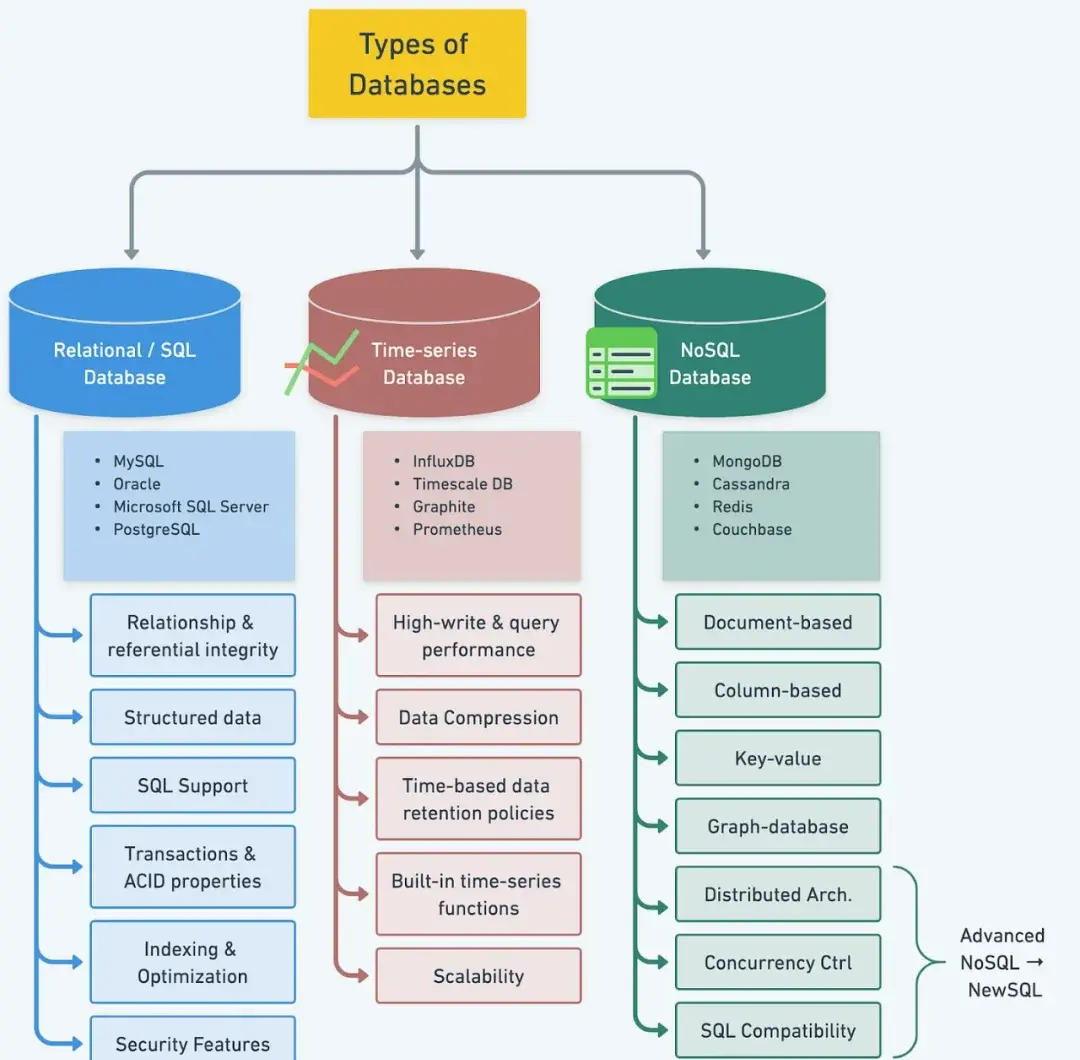
五、數據管理系統及數據架構的類型
數據最終得落地存起來、用起來。根據不同的需求和場景,演化出了幾種主流的數據存儲和管理模式:
1. 數據倉庫
(1)核心任務: 把企業裏各個業務系統,通常是關係型數據庫的數據,抽出來,清洗轉換整合好,然後集中存到一個地方。
(2)關鍵過程: 數據通過 ETL管道(抽取Extract、轉換Transform、加載Load)進來,經過各種清洗轉換,變成符合預定數據模型的樣子,再存進倉庫。
(3)用途: 存好、整理好的數據,主要用來支持商業智能(BI)報表、儀表盤和數據科學分析。
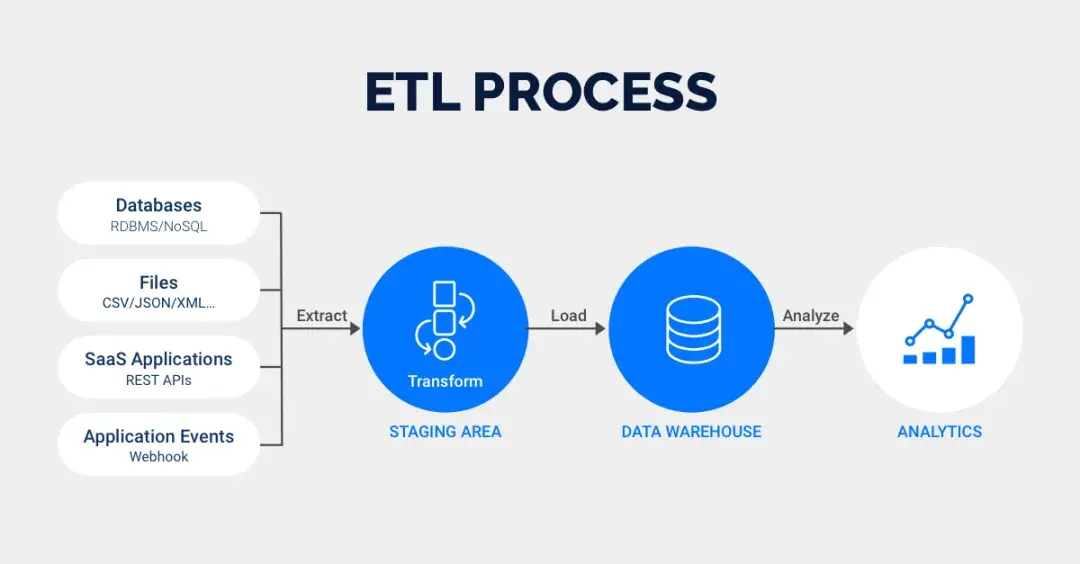
2. 數據集市
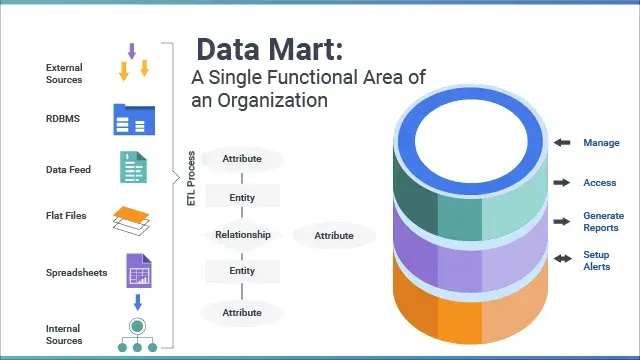
(1)是什麼: 你可以把它看成數據倉庫的“精簡版”或“部門專屬版”,它只包含某個特定團隊或用户組真正需要的那一小塊數據。
(2)好處: 因為數據量小、範圍聚焦,部門自己用起來更快、更靈活,能更快找到自己關心的洞察。90年代搞全公司大倉庫太難,數據整合耗時耗力,數據集市這種“小而美”的方案就流行起來了,它比大倉庫更容易、更快建成。
3. 數據湖
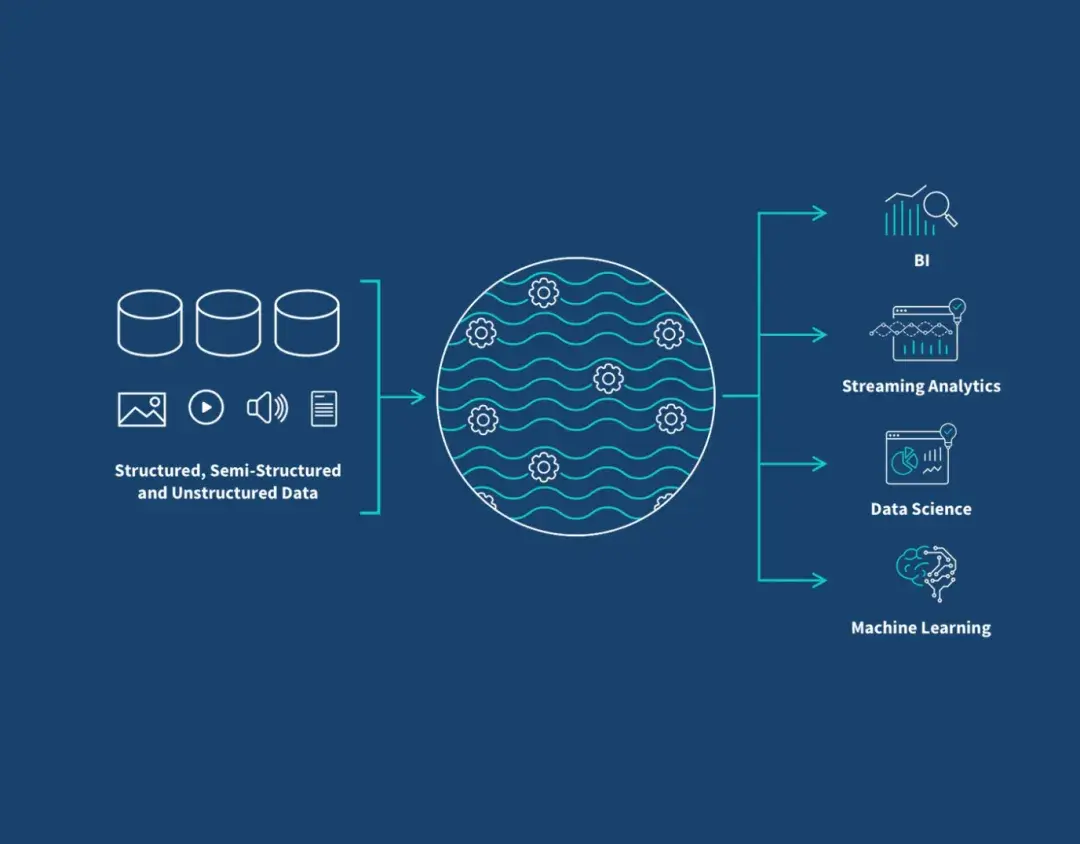
(1)核心區別: 數據倉庫存的是處理好的、規整的數據。數據湖呢?它存的是最原始、未經處理的數據。
(2)包容性強: 結構化的、半結構化的、非結構化的數據,統統都能往裏扔。這個特點對數據科學家、工程師特別有用,他們需要原始數據做探索分析。
(3)出現原因: 因為數據倉庫搞不定大數據時代海量、多樣、高速的新數據了。雖然數據湖查詢分析通常比數據倉庫慢(因為數據沒預先處理好),但它構建和存原始數據的成本更低,數據進來前幾乎不用準備。
4. 數據結構
這是一種比較新的架構理念,核心是自動化數據集成、數據工程和數據治理流程,尤其關注數據提供者和使用者之間的這條“數據價值鏈”。利用知識圖譜、語義分析、數據挖掘、機器學習(AI)等技術,去分析各種類型的元數據,從中發現模式和洞察。目標是把這些洞察用來自動化和優化數據價值鏈。比如,讓需要數據的人能輕鬆找到“數據產品”,系統還能自動把數據提供給他。這樣能大大減少數據孤島,讓企業看到一個更完整的數據全景圖。在客户畫像、欺詐檢測、預測性維護等場景很有前景,大大減少集成設計、部署和維護的時間。
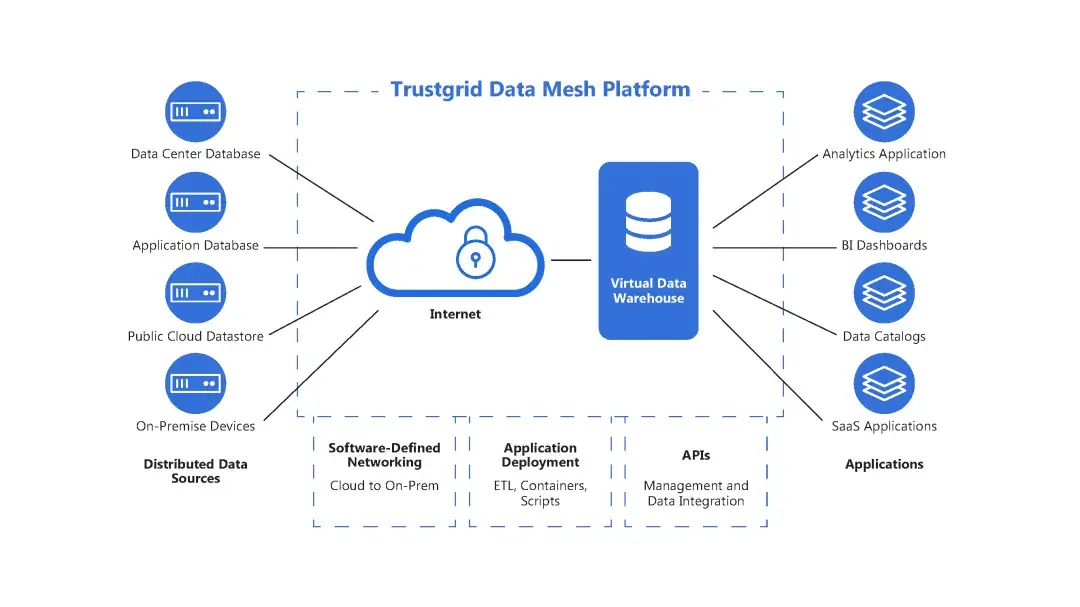
5. 數據網格
(1)核心理念: 去中心化,按業務領域來管數據。 它要求企業別再把數據當作流程的“副產品”,而要把它當成有價值的“產品”來對待。
(2)誰負責:各個業務領域的數據生產者,就變成“數據產品負責人”。他們是業務專家,最懂自己領域的數據該怎麼用、主要用户(消費者)需要啥,由他們來設計提供數據的API。
(3)如何訪問:這些設計好的API,不僅供本領域使用,也開放給公司其他部門。這樣就提供了一種受控的、更廣泛的數據訪問渠道。
(4)和傳統存儲的關係: 像數據湖、數據倉庫這些,可以作為多個去中心化數據存儲的底層技術,來實現數據網格。
(5)和數據結構結合:數據結構的自動化能力,能加速新數據產品的創建,也能更高效地執行全局性的數據治理規則。
六、總結
咱們一路從數據架構是啥、有啥用,聊到它是怎麼一步步進化來的,再到TOGAF, DAMA, Zachman那些經典框架和各種管數據的“倉庫”、“湖”、“網格”、“結構”,是不是感覺對數據架構這個大概念清晰多了?
但記住它的核心目標是把亂糟糟的數據管好、用好! 不管你是選傳統的數據倉庫、靈活的數據湖,還是試試新潮的數據網格、數據結構,關鍵是要找到最適合你公司業務和數據的那個“管家”方案,讓你的數據“規矩”更快落地,真正跑起來為業務服務。












