









備選標題:
數據分層,不止分層那麼簡單!
數據為什麼要分層?三招搞定多源異構數據
數據又多又亂,用的時候:
- 找不到?
- 算得慢?
- 還容易出錯?
別頭疼了!數據分層就是解決這些問題的“法寶”。
簡單説,它就是:
給數據建個清晰有序的“家”,讓每一類數據都有固定的位置和職責。
今天,我就帶大家拆解數據分層最核心的三大層:
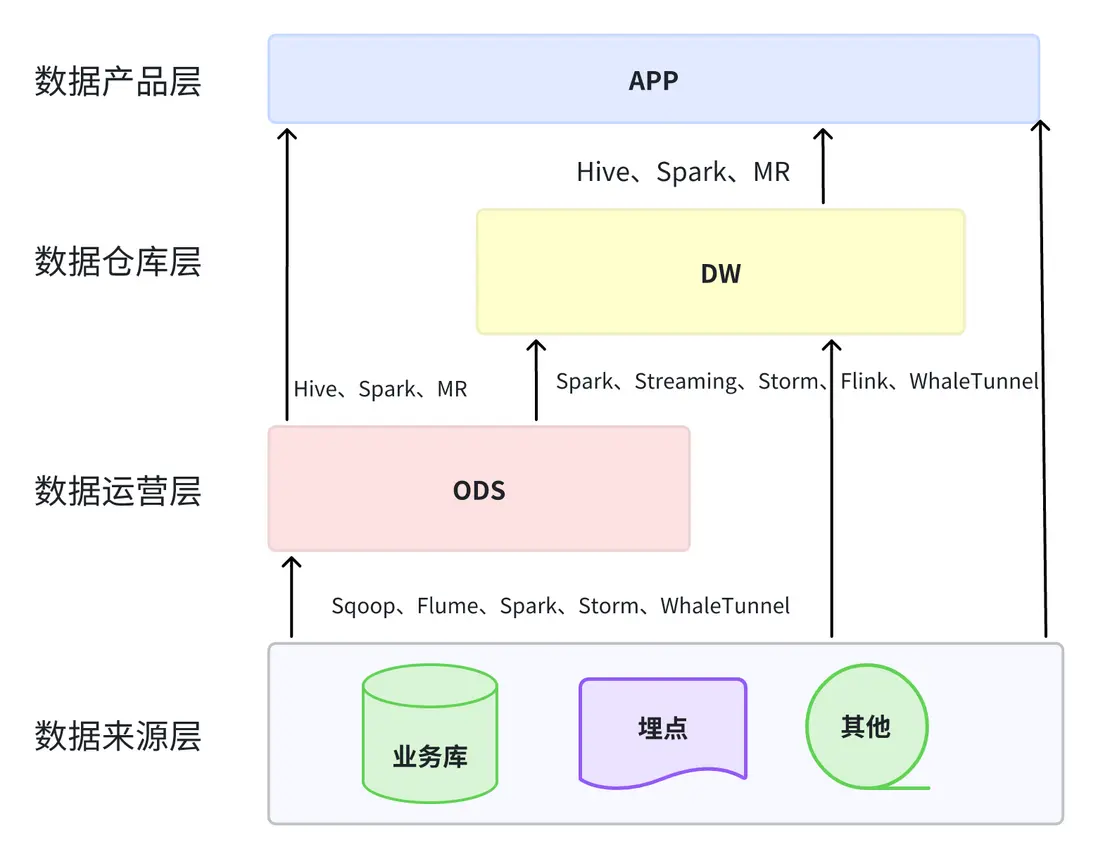
- 數據運營層(ODS)
- 數據倉庫層(DW)
- 數據應用層(ADS)
看看它們是如何分工協作,讓你的數據變得又好找又好用!
一、數據分層是什麼
簡單來説,就是把從現實世界裏收集到的有用信息,用更合理的方式整理清楚。這樣遇到問題的時候,就能更快地找到解決辦法。
你想啊:
要是一堆數據亂糟糟堆着,找的時候就得翻來翻去,用的時候也不順暢。
不管是處理什麼數據,有條理都是最基本的要求。
因為:
數據一旦有了條理,查找的時候不用浪費時間,使用的時候效率也能提高。
這就是數據分層最根本的作用:減少不必要的成本,提升處理效率。
二、為什麼要設計數據分層
剛開始接觸數據分層的時候,很多人都會有這個疑問。
就像有人會問:
“為什麼要做數據倉庫”“為什麼要做元數據管理” 一樣,這些問題本質上都是在問 “做這件事的意義是什麼”,接下來咱們就專門説説數據分層。
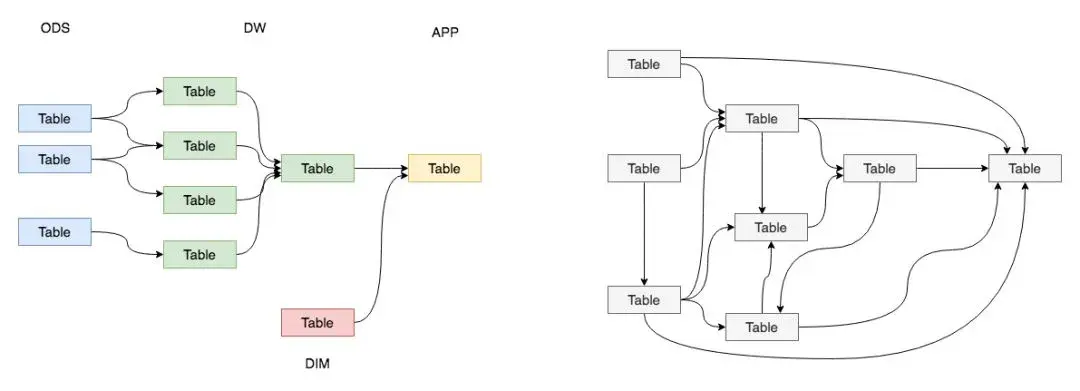
理想狀態下:
咱們肯定希望數據能規規矩矩地流轉,從產生到不用的整個過程都清清楚楚,哪部分數據依賴哪部分,層次怎麼分,一眼就能看明白。
可現實卻是:
數據體系往往不是這樣。
很多時候:
數據之間的依賴關係亂得很,層次也分不清楚,甚至還會出現 A 依賴 B、B 又依賴 A 的循環情況,到時候不管是查數據還是改數據,都特別麻煩。
所以:
數據分層其實就是給咱們一套能實際操作的方法,讓數據體系能更有條理。
三、數據分層的好處
當然了,數據分層不能解決所有數據問題,但能幫咱們解決不少關鍵問題,好處還是很明顯的。具體來説,有這些好處:
1.提高數據質量
分層處理的時候,每一層都能對數據做清洗和檢查。
具體操作是:
通過分層設置多道檢查環節,及時攔截錯誤,避免問題累積,從流程上保障數據質量。
比如:
這一層發現數據有錯,馬上就能改,不用等問題傳到後面的層。
這樣就能:
保證數據是準的、前後一致的。
2.優化性能
彙總好的數據,單獨放在一層,要查總數的時候,直接去那一層拿就行,不用再從最原始的數據裏一點點算,速度自然就快了。
具體操作是:
減少查詢時需要處理的數據量和計算步驟,縮短數據查找和計算的路徑,從而提升性能。
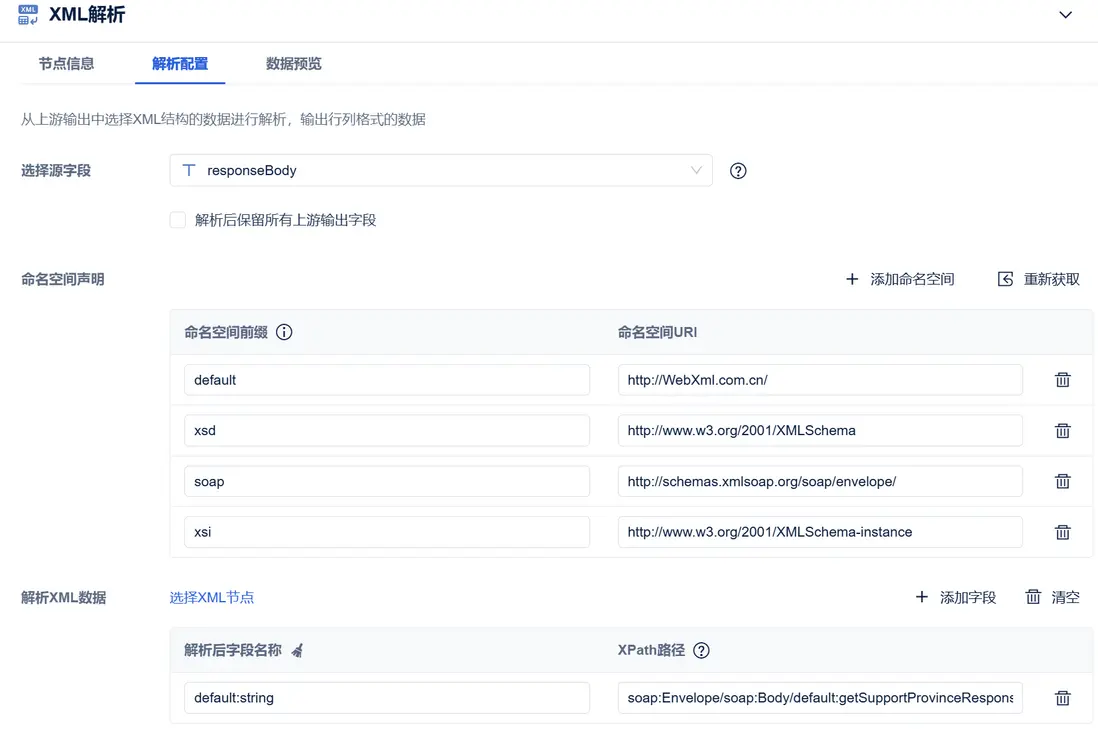
比如:
在使用 XML 解析算子時,可以通過數據集成平台FineDataLink分層解析數據,並通過其他算子進行拼接。對於 API、WebService、OData 接口中響應數據返回的 XML 格式數據、來自 XML 文件的數據,通過FineDataLink直接解析為行列格式數據,方便後續加工存儲。
3.易於維護
每一層數據都有自己要負責的事,處理邏輯也很明確。
具體操作是:
明確各層職責,把複雜的維護工作拆分成針對每一層的簡單工作,降低維護難度。
比如:
- DWD 層就是處理明細數據的
- DWS 層就是做綜合彙總的
哪一層出了問題,就針對性地去處理這一層,不用把整個數據體系都翻一遍,維護起來就省事多了。
4.靈活性高
如果想改某一層的數據,只要把這一層和上下層的銜接處理好,基本不會影響到其他層。
具體操作是:
各層相對獨立,層與層之間通過固定的方式銜接,局部修改不會引發連鎖反應,提升了數據體系的適應性。
比如:
要調整 ODS 層的數據格式,只要保證傳給 DWD 層的數據是對的,DWD 層及以上的部分就不用跟着改,這樣改起來就靈活多了。
5.支持多維數據分析
分層之後,數據的結構更清晰,想從不同角度分析數據就很方便。
比如:
分析一筆銷售數據,既可以看不同地區的情況,也可以看不同時間段的情況,還能看不同產品的情況,這些都能在分層的基礎上實現。
6.降低數據冗餘
合理分層之後,同一批數據不用重複存在好幾層裏。
具體操作是:
通過規劃數據的存儲位置,避免重複存儲,提高存儲空間的使用效率。
比如:
客户的基本信息,在需要的層裏直接引用就行,不用每層都存一份,這樣就能節省存儲空間。
7.歷史數據管理
數據分層的時候,會規劃好歷史數據怎麼存、存多久、怎麼調出來用。
這樣一來:
想分析過去幾個月或者幾年的數據變化,就能很方便地找到對應的歷史數據,不用到處找。
具體操作是:
為歷史數據設定明確的管理規則和存儲位置,讓歷史數據的調用和分析有章可循。
8.提高可擴展性
數據量總會越來越大,分層的體系就能跟着慢慢擴展。
具體操作是:
分層形成的模塊化結構,讓體系可以按需逐步擴展,適應數據量增長的需求。
比如:
數據多了,可以在現有層次基礎上加一層專門處理新增數據的,或者調整某一層的結構,不用把整個體系推翻重來,這樣擴展起來就容易多了。
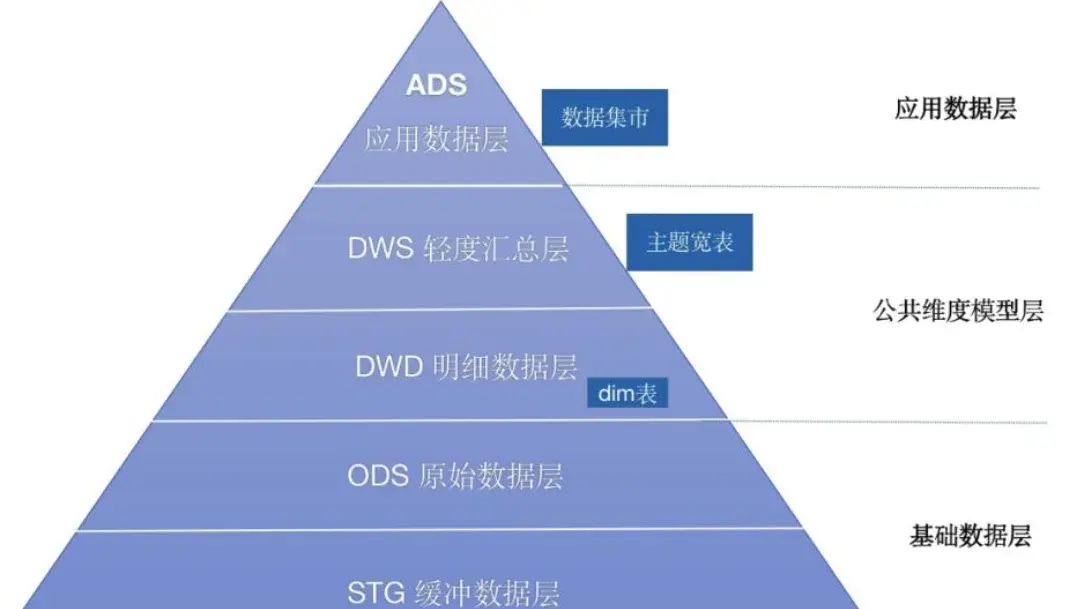
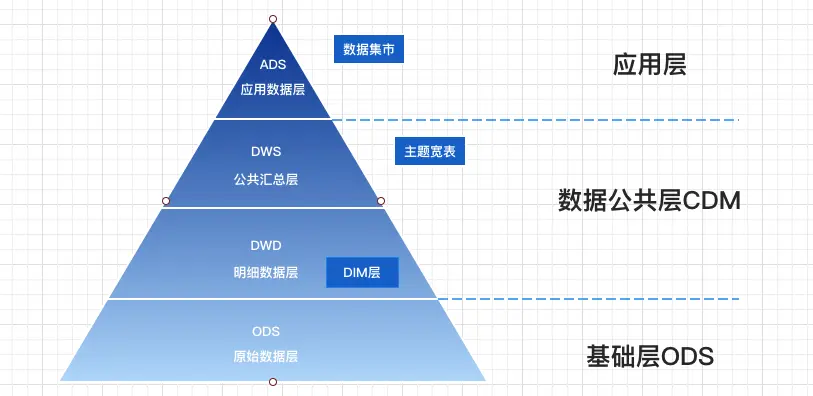
三、通用的數據分層方法
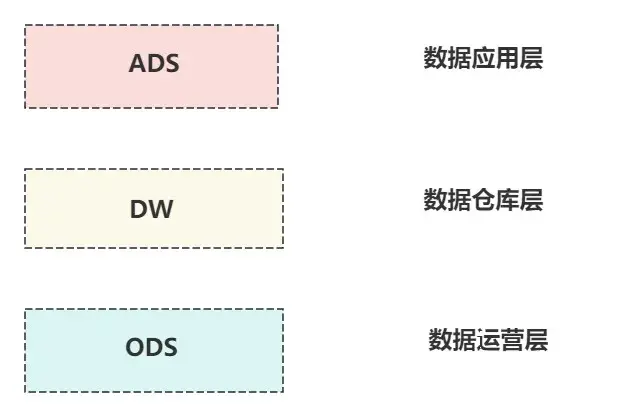
為了達到上面説的這些效果,一般我們會把數據分成三層:
- 數據運營層(ODS)
- 數據倉庫層(DW)
- 數據應用層(ADS)
這三層各司其職,一步步把數據處理好。
接下來,我就把各層的功能給大家詳細拆解一下:
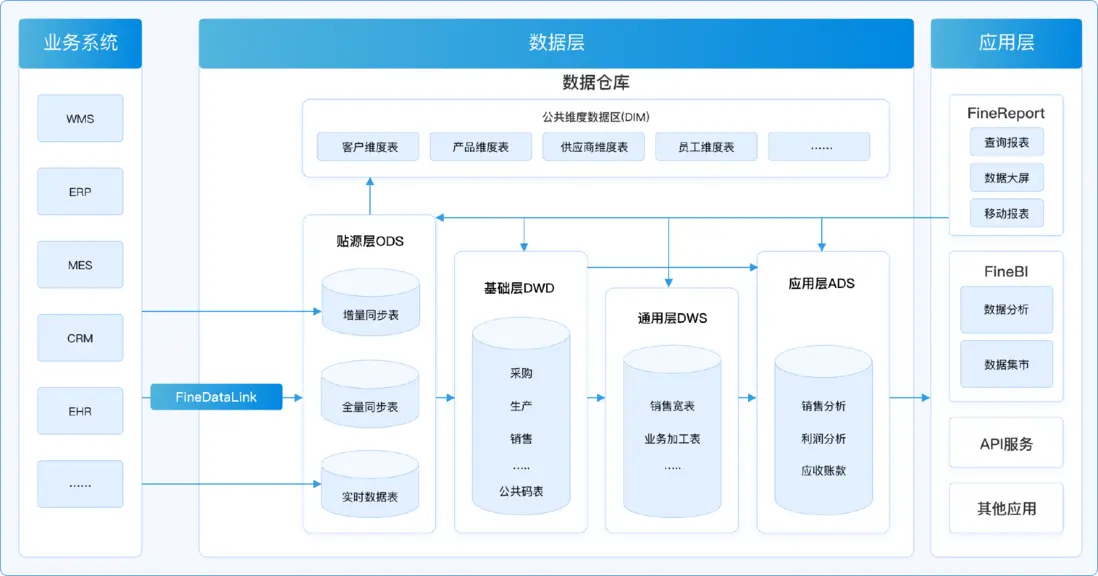
第一層:數據運營層(ODS)
作為數據的入口,直接從各種業務系統裏拿過來的。
比如:
- 銷售系統裏的銷售記錄
- 客户關係管理系統裏的客户信息
都是從這些地方直接獲取的。
這一層的數據:
基本能保持業務系統裏的數據原樣,不過拿過來之前得先做些清洗和檢查,確保能用。
裏面的表一般分兩種:
- 一種存現在正要處理的數據,
- 另一種存已經處理完的歷史數據。
而且:
這是整個分層裏最細的一層數據,從業務系統拿過來後,簡單處理一下就放在這兒。
第二層:數據倉庫層(DW)
這一層是核心,又能分成三個小層:
- DWD
- DWM
- DWS
1.數據明細層(DWD)
這一層的數據和 ODS 層差不多細,不過會更注重數據質量,有問題的會在這裏處理掉。
而且:
為了用起來方便,會把一些相關的維度信息直接放進事實表裏,同一類主題的數據也會彙總到一張表裏。
比如:
訂單表會把客户的一些基本信息加進去,這樣查訂單的時候就不用再去關聯客户表了。
這樣做的好處:
在保留明細數據的基礎上,優化數據結構,提升數據可用性,為中間層處理提供清晰的數據源。
2.數據中間層(DWM)
這一層是在 DWD 層數據的基礎上做些簡單的彙總。
比如説:
用户每天登錄多少次,不用每次用的時候都從 DWD 層的明細數據裏算,在這裏提前算好存起來,後面再用直接拿就行。
這樣做的好處:
減少重複計算,提高那些常用指標的複用性。
具體操作是:
對高頻使用的指標提前計算並存儲,減少重複勞動,提升後續處理的效率。
3.數據服務層(DWS)
這一層也叫寬表或者數據集市,是按業務來分的,比如專門處理流量數據的表、專門處理訂單數據的表。
一般來説:
這些表字段多,但數量不多,業務查詢的時候、做 OLAP 分析的時候都能用。
所以:
這一層的數據是把 DWM 層的多箇中間表拼起來的。
否則:
直接從 DWD 層或者 ODS 層算,計算量太大,而且能分析的角度也少。
具體操作是:
整合中間層數據,形成面向業務的綜合數據集,簡化業務查詢和分析的流程。
注意點:
如果不好區分中間層和服務層,也可以把 DWM 層去掉,數據都放在 DWS 層。
第三層:數據應用層(ADS)
是給數據產品和做數據分析的人用的。
存儲位置:
- 一般會存在 ES、PostgreSql、Redis 這些系統裏,供線上系統調用;
- 也可能存在 Hive、Druid 這些地方,方便做數據分析和挖掘。
咱們平時看的各種報表數據,基本都在這一層。
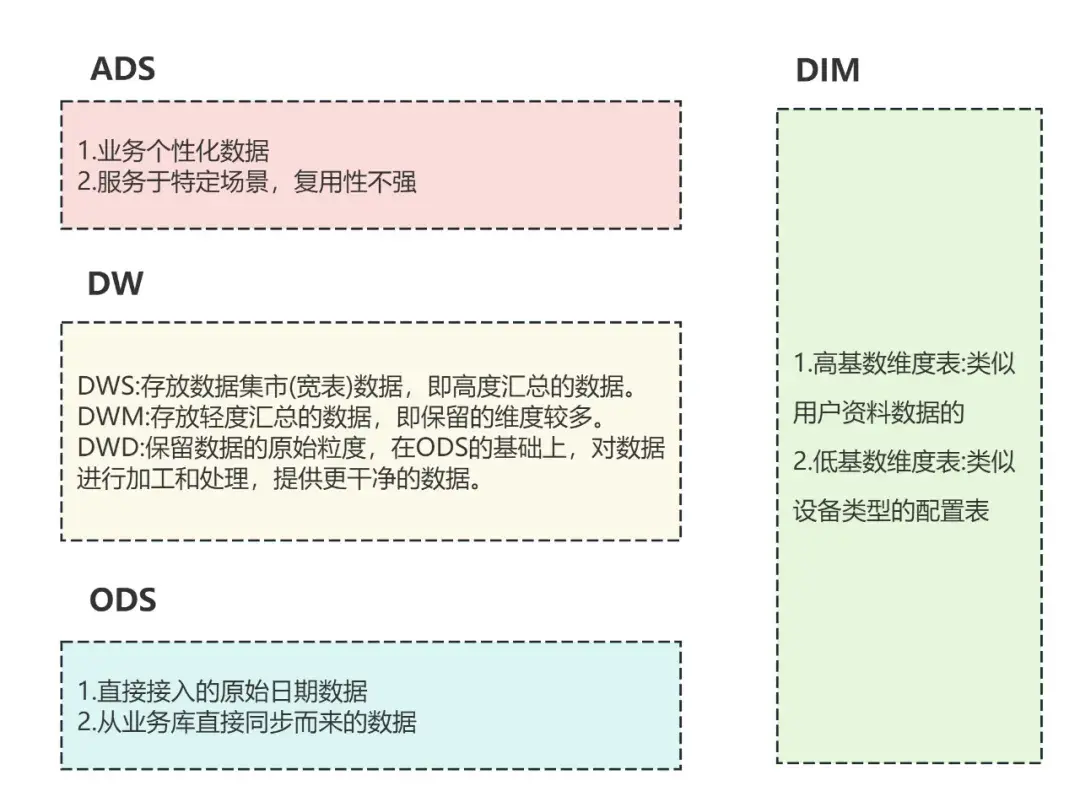
最後補充一個:維表層(Dimension)
這一層專門存維度數據,分兩種:
- 高基數維度數據:像用户資料表、商品資料表,這些表裏的數據量大,可能有幾千萬甚至上億條。
- 低基數維度數據:比如配置表,裏面存着狀態碼對應的中文意思,還有日期表,這些表的數據量少,可能就幾條、幾千條或者幾萬條。
具體操作是:
單獨存儲維度數據,與業務數據分離,方便維度信息的統一管理和複用。
四、數據分層的原則
説到這裏,可能有小夥伴好奇:
- 數據分層的原則到底是什麼?
- 為什麼要這麼分層?
- 每層之間的界限又該怎麼劃?
這些問題,估計不少剛開始接觸數據分層的同學都會琢磨,對吧?
所以下面,我就從這幾個角度,好好聊聊數據分層到底是怎麼劃分的。
1.按照對應用的支持
越往上的層,數據越好用。
比如:
- ADS 層是完全照着業務應用設計的,一看就懂;
- DWS 層稍微要理解一下;
- DWM 和 DWD 層維度多,很多時候一個需求得用好幾張表,經過複雜的計算才能完成。
2.按照能力範圍
大部分人都希望 80% 的需求能靠 20% 的表來支持。
説白了:
- 大部分需求,用 DWS 層的表就行;
- DWS 層滿足不了的,再用 DWM 和 DWD 層的表;
- 極少數情況,才需要從最原始的日誌裏找數據。
結合上一點來説,就是 80% 的需求,都要用對業務友好的方式來支持,不能直接把原始數據扔給用的人。
3.按照數據聚合程度
越往上的層,數據彙總得越厲害。
比如:
- ODS 層和 DWD 層的數據都是很細的,基本沒做什麼彙總;
- DWM 層做了點簡單彙總,只留下那些常用的維度;
- DWS 層彙總得更厲害,可能只留下一兩個能説明主體情況的維度。
所以從這一點來看,數據分層也是按數據彙總的程度來分的。
五、總結
説到底,數據分層就是要做到:
- 怎麼讓數據更好用
- 怎麼能滿足大部分需求
- 怎麼合理彙總數據
最後,讓整個數據體系更有序、更高效地運轉。
通過ODS(原始數據入口)、DW(核心加工區)、ADS(直接應用層),這三大核心層的合理劃分與緊密配合,不僅能讓你告別數據混亂,更能大大提升數據質量、處理速度和維護效率。
現在就動手實踐分層設計,解鎖數據的強大潛能吧!











