









近年來,在國家推動一系列企業數據相關政策的大背景下,數據要素化改革正在全方位鋪開。數據已經從“輔助決策的信息資源”轉向“驅動新質生產力和產業變革的核心要素”。
根據《數據管理能力成熟度評估模型(DCMM)》的定義,數據治理主要包括質量、標準、組織、架構、安全五大支柱性能力。其中,“數據質量”被明確列為首要維度,其考察標準不僅包括數據本身的正確率、缺失率、重複率等指標,還關注企業是否建立起可持續的質量保障機制。
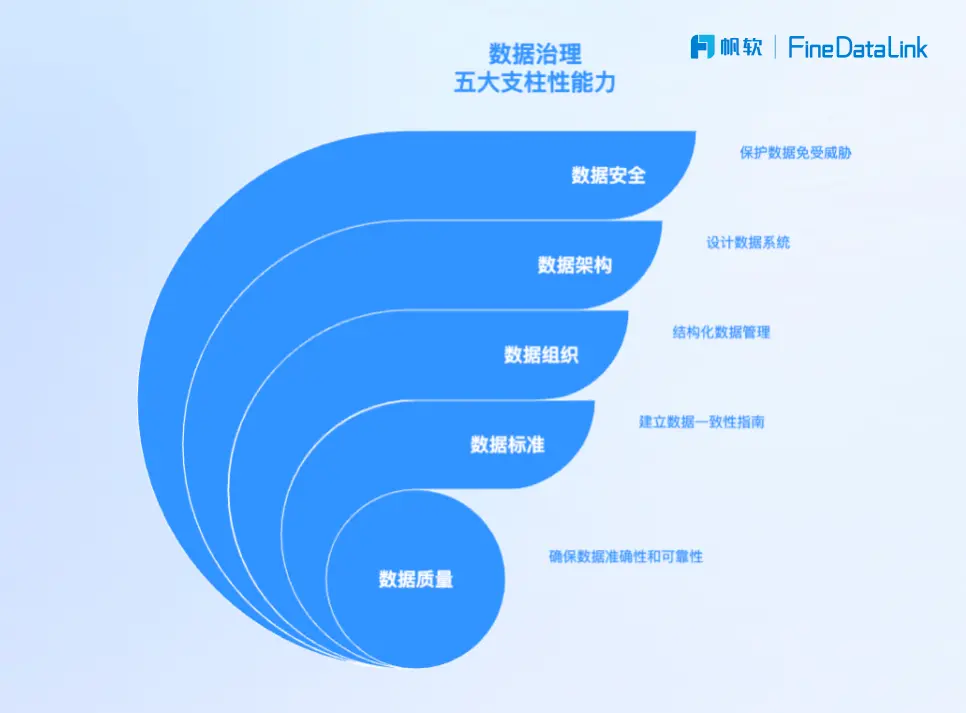
這説明,無論是設計數據架構,還是建立組織體系,最終都必須落到“提升數據質量”的實效上。否則,哪怕系統再先進、流程再完備,企業依然可能面臨“數據不可信、決策拍腦袋”的困境。
本文將聚焦企業在數據質量治理中最為關注的五個核心問題,逐一展開解析,並提供對應的實踐指導。
01 關切一:數據質量問題為何產生?
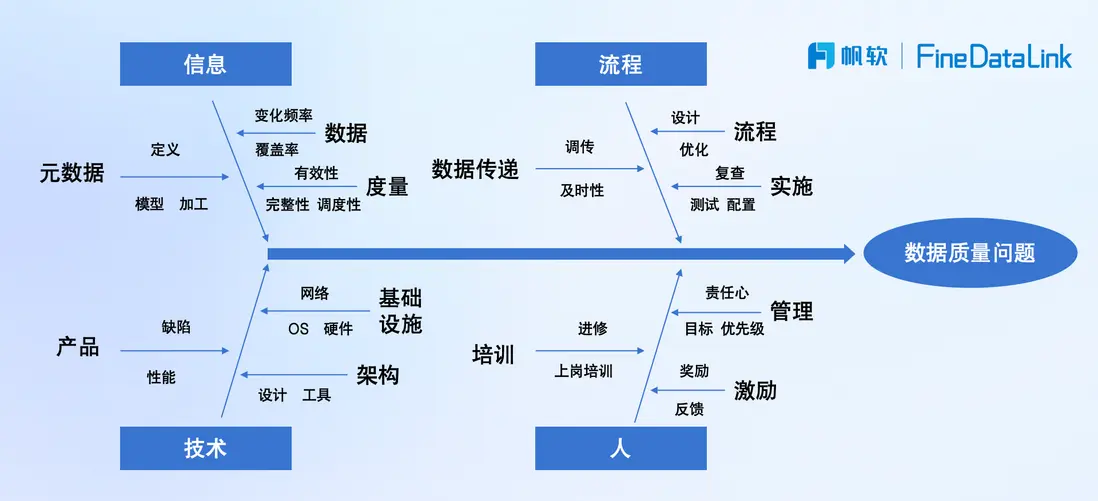
數據質量問題來源廣泛、複雜。在實際業務場景中,數據質量問題產生的主要來源有兩個:
一是長期存在的“先上車、後補票”式業務慣性;
二是各部門“各自為政”,缺乏協同。
以某客户的實際場景為例,像銷售額這樣核心的經營指標,在數據分析項目中通常首先追求“能用”——只要拉取的數據結果能對得上以往的報表或既有口徑,就會被直接投入使用,而底層數據的標準規範與口徑一致性則暫時被擱置。
結果是,在項目推進過程中,數據校驗與標準化工作反而佔據了近一半的工作量,成為拖慢進度的隱性負擔。
而另一個問題來源則是由於不同業務部門在開展類似分析任務時,如同樣計算銷售額,往往會依據各自對業務的理解,從不同系統、選取不同字段進行數據提取,缺乏統一標準。
這不僅增加了數據解釋的難度,也讓看似一致的指標在結果上出現偏差,甚至產生相互矛盾的結論。
這一現象背後,實則暴露出兩個深層問題:
其一,企業缺乏對核心績效指標(KPI)的統一管理機制,跨部門協同缺位,導致關鍵指標口徑分散、標準各異;
其二,數據開發過程中缺乏系統化的字段治理與命名規範,數據重複建設、標準不一的情況頻繁出現,信息孤島問題愈演愈烈。
02 關切二:數據質量治理應以什麼為目標?
目標一:數據質量服務業務價值
數據質量治理的根本目的,絕不是為了一份“分數更高的質量報告”,而是要切實服務於業務目標的實現。
換言之,不是為了數據本身“更乾淨”,而是為了讓乾淨的數據真正轉化為業務洞察、運營效率和決策依據,推動企業實現降本、增效、控風險。
當前不少企業在數據治理初期容易陷入“形式主義”誤區:將大量精力投入到報表評分、質量指數排名等表層指標中,卻忽視了數據對實際業務的支撐力。這種“為治理而治理”的做法,往往導致治理效果與業務場景脱節,最終難以獲得組織認可與持續投入。
真正有效的治理,應以業務牽引為出發點,從公司戰略或者核心事物出發,圍繞客户運營、產品分析、財務核算、合規報送等核心場景,聚焦那些直接影響業務決策和執行的數據質量問題,優先治理“用得上的關鍵數據”。
只有把數據治理嵌入真實的業務鏈條,讓每一條高質量數據“用得上、看得見、產生價值”,治理才不再是成本中心,而是企業運轉的效率引擎與決策底座。
目標二:打造持續可控的質量保障機制
真正有效的數據質量治理,不能止步於“集中整頓”,而應構建起一套制度化、流程化、自動化的質量保障機制,實現從源頭把控到全流程監控的閉環管理。
這一機制的核心在於:將數據質量的控制點嵌入業務流程、數據系統和平台工具中,確保數據在“產生—傳輸—存儲—使用”的每一個環節中質量可控、可見、可干預。
具體而言,企業可圍繞以下三方面構建質量保障閉環:
● 源頭防控:在數據採集或錄入環節建立標準校驗機制,例如強制字段校驗、主數據引用、標準模板輸入等,防止“髒數據”進入系統;
● 過程監控:通過規則引擎、指標體系和數據血緣圖譜,實時監控數據質量波動,及時發現問題、定位源頭;
● 異常修復:基於預設規則自動修復部分問題,或建立問題分發機制,推動責任部門閉環整改,形成“發現-修復-反饋-追蹤”的流程閉環。
通過這樣的機制設計,數據質量治理不再依賴專項項目或個人經驗,而是成為組織長期穩定運行的一部分,真正實現“治理融入流程、標準嵌入系統、責任落在業務”。
治理目標從“階段性治理”轉向“體系化管控”,也將為企業後續數據資產建設、數據中台搭建、AI模型訓練等奠定堅實的數據基礎。
03 關切三:數據質量到底誰來管?
數據質量的提升需要的是“全鏈條協同、全角色參與”。具體怎麼落地?行業最佳實踐已經逐漸形成了“三層職責體系”:
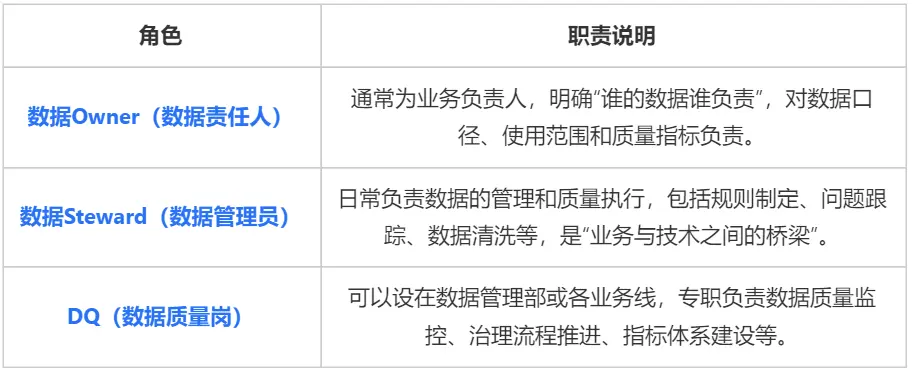
這種體系,不是新增部門,而是在原有組織上“加職責、明邊界”,避免“人人都管、人人都不管”的尷尬局面。
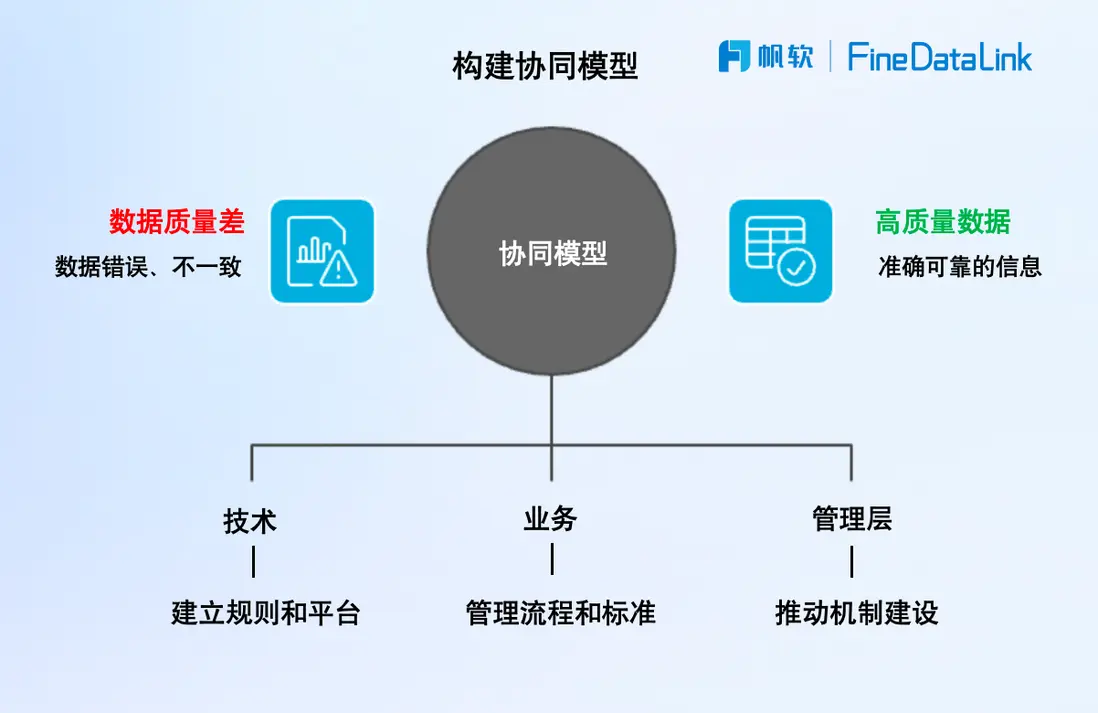
關鍵不是誰主導誰配合,而是構建“技術+業務”的協同模型,讓數據質量成為“共建共擔”的常態。
如:技術負責建規則、搭平台,提供數據血緣、校驗、監控等工具,同時業務負責管流程、管口徑,確保源頭數據“第一手就對”。對於管理層來説,則要推動機制建設,比如將數據質量納入績效指標、審計評估體系中。
04 關切四:數據質量治理是不是“動輒上千萬的大工程”?
其實,數據質量治理並非必須一開始就“大投入、大平台”,而是可以“分階段、漸進式”啓動。
一個行之有效的低成本路徑,通常可以分為以下幾個階段:
1. 梳理關鍵數據鏈路
找出企業中最重要的數據鏈條,比如訂單→支付→發貨→結算等,用80/20原則,聚焦最核心的業務流程。
2. 定義基礎質量規則
和業務部門一起明確“哪些字段出錯影響大”,先制定一批基本規則,比如客户ID不能為空、金額字段不能為負等。
3. 引入輕量級工具做監控
不一定非要採購重型平台,可以先用Excel、SQL腳本、其他工具做初步監控,建立“質量儀表盤”。
4. 再根據業務反饋逐步擴展
當初步治理開始顯效,比如報表準確率提升、客户投訴下降,再引入平台工具實現標準化、自動化。
企業要認識到,數據質量治理是一項漸進的“運營機制建設”。和品牌建設、人才培養一樣,它需要長期投入、持續優化,但其帶來的價值卻是“整個企業數字化的底座”。
05 關切五:我的數據質量到底好不好?
數據質量治理不能光靠感覺,更不能只看有沒有錯——要有明確的、量化的評估體系。
在專業的數據治理框架中,如 DCMM(數據管理能力成熟度模型)、DAMA(數據管理知識體系指南) 等,都明確提出了數據質量的重要評估維度,這裏綜合提煉出五大最核心的維度:
- 準確性(Accuracy):數據值是否真實、無偏差,例如客户身份證號碼填寫是否正確;
- 完整性(Completeness):該有的數據項是否都填了,例如是否缺失關鍵字段如郵箱、金額等;
- 唯一性(Uniqueness):是否有重複數據,比如一個客户被錄入了兩次;
- 一致性(Consistency):跨系統數據是否保持一致,比如ERP和CRM中的供應商地址是否相同;
- 時效性(Timeliness):數據是否按時更新,例如庫存數據是否實時反映銷售情況。
企業可以通過這些指標構建自己的數據質量評分體系,比如為每張表、每類數據建立定期的質量檢測報告,自動算出“完整率達標率”“準確率趨勢”等,甚至可形成數據質量儀表盤,實現日常監控與趨勢追蹤。

注:本文為《數據管理治理應用白皮書》“數據質量”章節節選內容,圍繞企業最關切的5大問題進行了解答和建議。
如果你對數據治理或企業智能化轉型感興趣,敬請期待後續推文分享!











