

這是小卷對分佈式系統架構學習的第4篇文章,雖然知道大家都不喜歡看純技術文章,寫了也沒多少閲讀量,但是為了個人要成長,小卷最近每天都會更新分佈式的文章
1.概念
容錯策略,指的是“面對故障,我們該做些什麼”;而容錯設計模式,指的是“要實現某種容錯策略,我們該如何去做”。
上一篇已經講了7種容錯策略,為了實現各種策略,開發總結了一些容錯設計模式,包括微服務常見的:斷路器模式、艙壁隔離模式、超時重試模式。
2.斷路器模式
概念:借鑑了電路中的斷路器工作原理,用於防止一個子系統的故障蔓延到整個系統。通過在服務之間增加一個斷路器機制,當服務調用頻繁失敗時,斷路器會切換到OPEN狀態,拒絕進一步調用,避免浪費資源。並且斷路器會定期嘗試重連目標服務,如果服務恢復正常,則恢復調用。
斷路器本質是一種快速失敗策略的實現方式
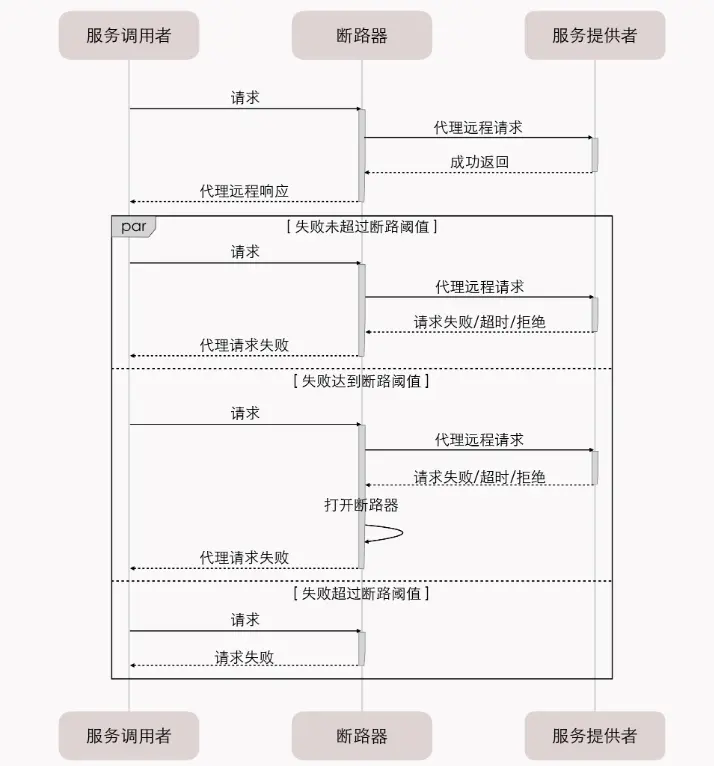
工作原理
斷路器有三種狀態:
- 關閉狀態 (Closed):斷路器關閉,請求正常調用。如果調用失敗次數超過設定閾值,斷路器會切換到打開狀態。
- 打開狀態 (Open):阻斷調用請求,直接返回失敗。此狀態下,系統不會繼續調用目標服務,避免資源浪費。
- 半開狀態 (Half-Open):是一種中間狀態,斷路器需要帶有自動故障恢復功能,進入
OPEN狀態一段時間後,斷路器會嘗試放行一次請求測試服務是否恢復。如果成功,切換回關閉狀態;否則,保持打開狀態。
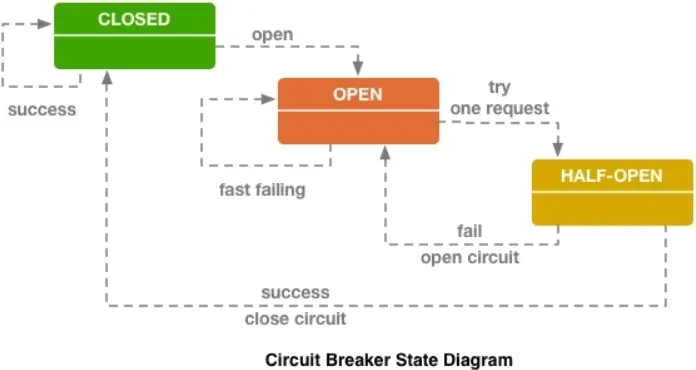
示例:
Netflix Hystrix可以設置一段時間內請求故障率達到閾值(10秒內20個請求,失敗率50%),斷路器的狀態就會變為OPEN
3.艙壁隔離模式(服務隔離)
概念:靈感來源於船舶設計,通過為每個模塊或服務分配獨立的資源池,防止一個模塊的故障或資源耗盡影響整個系統。其核心思想是“隔離問題”。簡而言之就是:避免某一個遠程服務的局部失敗影響到全局
具體場景
主流的網絡訪問大多是基於 TPR 併發模型(Thread per Request)來實現的,只要請求一直不結束(無論是以成功結束還是以失敗結束),就要一直佔用着某個線程不能釋放。
比如:“服務 I”發生了超時,假設平均 1 秒鐘內會調用這個服務 50 次,就意味着該服務如果長時間不結束的話,每秒會有 50 條用户線程被阻塞。
Tomcat默認HTTP超時時間是20秒,20秒內會阻塞1000條用户線程,而java應用的線程池通常最大設置為200~400,且Java本身是將線程映射為操作系統內核線程來實現的語言環境。這就意味着從外部看,服務已經全面癱瘓了。不僅是服務1,而是整個Tomcat服務。
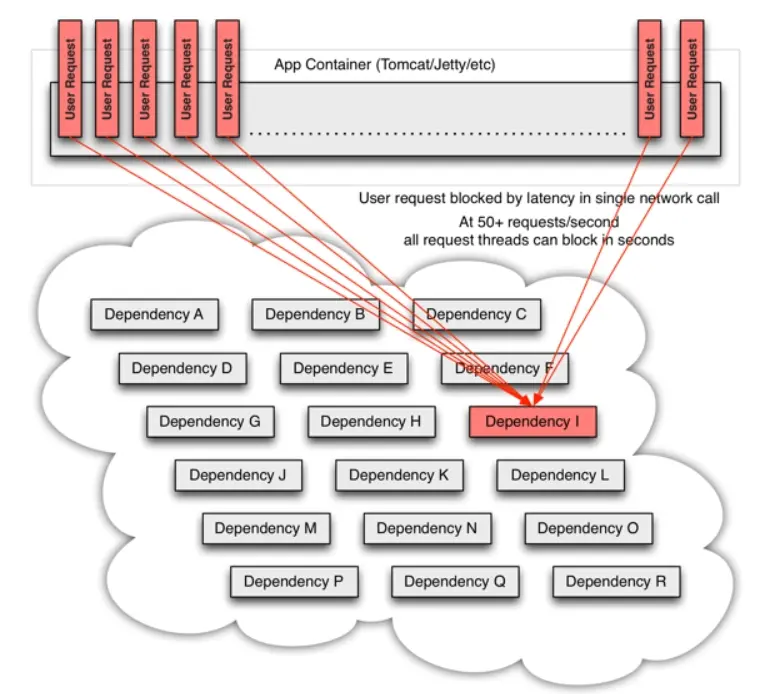
工作原理
解決辦法就是為每個服務設立單獨的線程池,這樣服務1即使阻塞了,比如阻塞5條用户線程,也不影響全局。
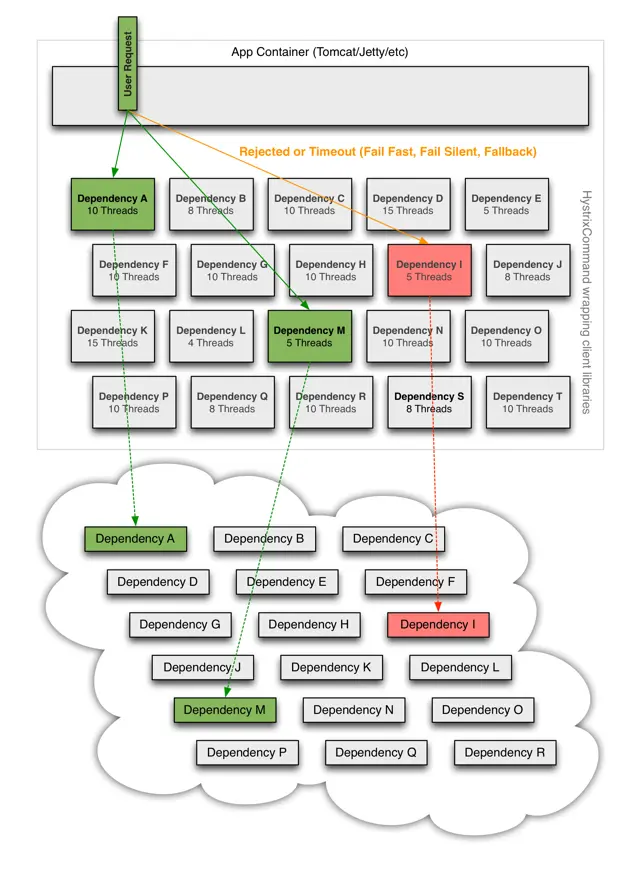
應用案例:阿里內部RPC中間件的HSF線程池隔離
適用場景:系統中存在多個高併發調用的服務,需根據用户等級、用户VIP、用户來訪區域等因素隔離到不同的服務實例的場景。
4.重試模式
概念:適用於解決系統的瞬間故障,如:網絡抖動、服務臨時過載問題。通過設定調用超時時間和重試次數,在調用失敗後自動重試,提升服務調用成功率。
使用重試模式時,實現很簡單,需避免濫用,適用場景的條件:
- 只在主路關鍵服務上進行同步重試
- 僅瞬間故障引起的失敗進行重試
- 僅對冪等性服務進行重試
- 重試需要有明確終止條件
5.容錯設計模式對比
| 模式 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 斷路器模式 | 防止服務雪崩,保護系統穩定性 | 服務恢復檢測需要額外開銷 | 服務調用失敗率高,可能影響全局性能的場景 |
| 艙壁隔離模式 | 故障隔離,防止系統資源被耗盡 | 增加系統設計複雜性 | 多模塊、多服務共享資源的場景 |
| 重試模式 | 提高服務調用成功率,適應短期故障 | 可能增加系統負載,不適合高實時性場景 | 臨時網絡波動、偶發性調用失敗 |
其他問題
1. 服務熔斷和服務降級之間的聯繫與差別?
服務熔斷:一種保護機制,用於防止一個服務的連續失敗導致整個系統的崩潰,屬於一種快速失敗的容錯策略的實現方法。當失敗率達到一定閾值時,斷路器會“熔斷”請求,直接返回錯誤響應或默認值
服務降級:通過降低非核心服務的優先級、簡化服務邏輯或直接返回備用響應,保證核心服務和主要業務功能的穩定性。通常是基於業務優先級主動觸發的
| 維度 | 服務熔斷 | 服務降級 |
|---|---|---|
| 觸發方式 | 被動觸發:根據失敗率、超時或異常次數達到閾值後觸發 | 主動觸發:根據系統壓力、業務優先級或異常情況手動觸發 |
| 作用範圍 | 面向單個服務的調用鏈,避免單點問題影響全局 | 面向全局系統,通過調整業務優先級釋放資源 |
| 目標 | 保護目標服務及調用方的資源,避免雪崩效應 | 保護核心服務的穩定性,儘量降低對用户的影響 |
| 恢復機制 | 自動恢復:斷路器從打開到半開,再到關閉狀態逐步恢復 | 手動恢復:根據系統壓力或異常消失後調整業務優先級 |
| 實現複雜度 | 需要監控調用失敗率、超時等數據並動態調整 | 需要結合業務場景設計具體的降級策略 |
| 典型場景 | 下游服務超時、故障,調用方通過熔斷保護自己 | 高併發、大流量或下游服務不可用時主動釋放資源 |











