










作者 | 矩陣起源
轉載自 | InfoQ
當 NL2SQL 從 Demo 走向生產,關鍵不在"更大的模型",而是"更乾淨的數據底座 + 更小的專用模型 + 更可控的工程化流程"。
摘要
先數據、後模型:把元數據、業務語義、權限、樣例 SQL 做成"AI-ready data",是 NL2SQL 能否可靠落地的第一性問題。
小模型足夠用:以 3B-7B 級別的代碼/SQL 友好模型,配合 LoRA 微調 + 語法約束解碼 + 執行校驗,就能獲得很好的效果。
落地成本低:相比動輒 100B 參數量以上的全量大模型,小模型的實際落地可能性更大,需要的算力支撐對於企業來説更加容易投入。
評估要換維度:Execution Accuracy(執行一致性) 比 Exact Match 更接近真實可用性,應與回放/灰度一起形成閉環。
工程化路徑:建立"Schema 服務 → 計劃器(小模型)→ 安全執行沙箱 → 觀測與糾錯迴路"的最小可行系統(MVP),再逐步引入 AST 約束、檢索增強、對齊訓練。
"大模型 + 開箱即用"常常失靈
業務語義缺席:amt、dt、no 在不同庫含義不同;缺少別名詞典、指標口徑、實體映射,模型只能基於已有訓練資料進行推理。
治理與合規割裂:多租户/跨源 JOIN、限流、行列權限、審計等使"能生成 ≠ 能執行"。在真實生產環境業務流程背景來支撐查詢,而模型往往無法直接獲得這部分含義。
評估口徑失真:只看字符串級 Exact Match,忽略"結果等價"與"能否在你的庫上跑通"。
成本/延遲不可控:把大而全上下文塞給通用大模型,需要對於 prompt 做深度優化,同時過長的上下文還可能導致 Context-Rot 以及 Lost in the middle 的問題出現。
我們實際場景落地過程中發現,沒有 AI-ready data,就沒有可落地的 NL2SQL。
任務屬性決定解法:NL2SQL 更像"受限代碼生成/語義解析"
輸出是形式語言(SQL):語法強約束、詞表相對小、可執行、可驗證。
輸入可結構化:數據庫 Schema、主外鍵、候選列/表、樣例值都可作為外部信號。
所需推理是"結構性推理":列/表選擇、聚合、條件組合、時間窗,而非開放域常識。
這類問題適合通過結構化約束 + 外部知識接口來"降維",而不是單靠更大的通用常識模型"硬頂"。
為什麼選小模型:理論支持 + 工程證據
3.1 語法/AST 約束降低搜索熵
對形式語言施加語法/AST 約束解碼(如 PICARD/CFG/JSON-Schema/XGrammar 一類),在解碼每一步屏蔽不合法 token,把"自由生成"變為"受限搜索",顯著降低無效 SQL、提升可執行率。
含義:當輸出空間可被約束時,小模型 + 約束 = 大增益。
3.2 外部結構信息替代"內生常識"
引入schema linking(表/列同義詞、主外鍵、示例值)與候選集剪枝,把"隱式知識"外顯為"可調用的結構化接口"。
含義:當外部信號充足時,模型無需承載過多通用知識,合適的容量即可。
3.3 規模-性能-成本的最優點
根據 scaling laws:質量與參數/數據/算力相關,但在企業場景必須把推理成本與延遲納入目標函數。這裏我們參考了 DeepMind 的理論【Training Compute-Optimal Large Language Models】,在更高質量,更加密集的數據集上,參數較小的模型也能夠在固定任務上超越大參數量模型。

在 Closed-book question answering 場景上,70B 的 Chinchilla 甚至能夠超越 128B 的 GPT-3。
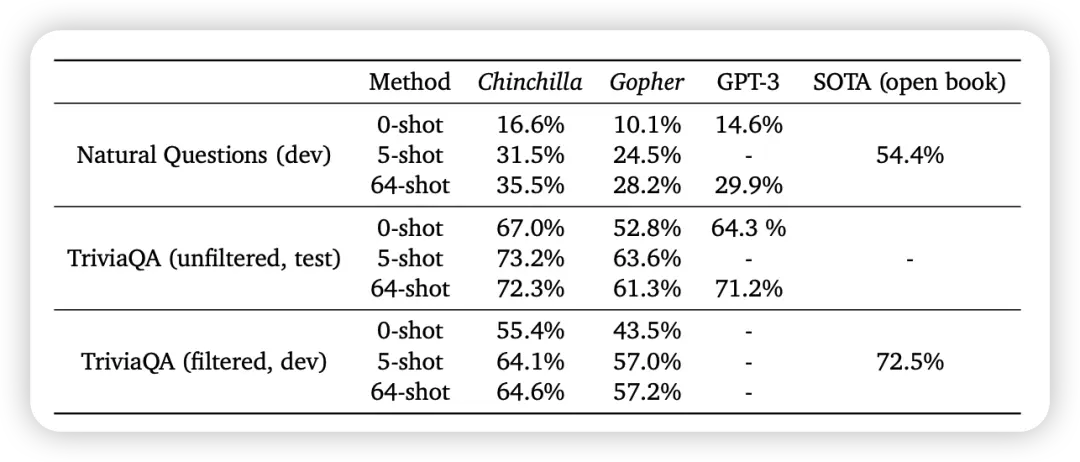
微軟的 phi 系列模型也從側面證實了這一點。
含義:在可強約束、可外接結構信息的 NL2SQL 上,最優點通常落在3B-7B 代碼向模型,而不是一味做大。
3.4 工程證據:窄域任務上,代碼向小模型常優於通用大模型
預訓練偏置:代碼/SQL 語料帶來強語法與組合性偏置,天生適配 SQL 生成。
確定性更強:配合保守解碼(低温度/不採樣/beam 可選)與固定輸出前綴,小模型更容易"按模板出活"。
延遲與成本優勢:可本地/私有化部署,甚至可以做本地化的 A/B 測試與小模型灰度上線。降低運維難度和部署成本。
實踐過程
我們在 CSpider/CSpider 衍生數據上,圍繞M-Schema 數據表示、約束池數據增強、BM25→SIC 兩級 Schema Linking與小模型 LoRA 微調,打通"從訓練到推理"的一致性鏈路,並在內部集上顯著降低結構/語義幻覺、提升執行一致性。
4.1 技術架構總覽
兩步式推理:先做Schema Linking(篩表/列/外鍵),再做SQL 生成(在精簡 schema 上生成)。這樣可在大庫上顯著降維並提升準確率。
小模型路線:以Qwen2.5-Coder-3B/7B為基座,LoRA輕量精調;用DeepSpeed做顯存/吞吐優化。
數據側增強:以M-Schema提供字段類型/中文描述/主外鍵/真實值樣例;引入約束池自動注入排序/去重/Top-K/窗口等口徑。
統一數據底座:整個流程建議構建於MatrixOne這類HTAP數據庫之上。其架構能避免"元數據在交易庫、數據在分析庫"的割裂狀態,從源頭整合 Schema、業務數據與日誌,為 AI-ready data 提供單一可信源。更進一步,Matrix Intelligence平台在此基礎上,將 Schema、元數據、業務詞典與權限等進行統一納管,形成面向 AI 的數據資產目錄,從基礎設施層面解決語義缺席問題。
4.2 數據與 Prompt:M-Schema + 約束池
M-Schema在傳統"表/列清單"之上,補充類型、主鍵、中文釋義、真實值示例,顯著提升字段語義可讀性與模型可對齊性(示例略)。
在訓練數據構造上,我們進一步將字段示例值抽取注入訓練樣本;在推理時對不可讀字段名做臨時可讀映射→後處理映回,實際提高了"表/列命中"。
約束池自動識別查詢語義類型(計數/聚合/多行)並注入去重、精度、排序、限制等約束,增強數據多樣性與魯棒性。
這一系列"AI-ready data"的準備工作,從多源異構數據到高質量的 M-Schema,恰好是MatrixOne Intelligence這類平台的價值所在。它通過以下能力,將數據準備流程從手工作坊式的腳本開發,升級為可治理、可複用的工程化體系:
統一接入與納管:通過內置連接器,自動化地從業務庫、數據湖、SaaS 應用等數據源同步數據與元數據,形成統一的數據資產視圖。
SQL 驅動的數據流:所有清洗、轉換、特徵構建(如拼接字段、構造 Flag)等步驟,都可以通過標準的 SQL 編排成可調度、可監控的數據工作流(Workflow),保證了過程的透明與可維護性。
向量化輔助質檢:平台內建的向量引擎不僅用於下游的語義檢索,更能在數據準備階段發揮關鍵作用。例如,可以對業務術語、字段註釋進行向量化,通過相似度計算輔助發現同義詞、識別命名不規範的"影子字段",或對歷史查詢日誌進行聚類分析,挖掘數據質量的薄弱環節。
訓練/推理輸入統一採用 ChatML 指令格式,並只在 assistant段計算損失以穩定輸出。
4.3 Schema Linking:BM25 粗排 → SIC 精排(兩級)
BM25 粗排:把"表 + 列 + 註釋"拼成文檔,對問句做 BM25 打分,取 Top-k 表;毫秒級延遲可支持在線。
SIC 精排:加載在域內數據微調過的Schema Item Classifier(Encoder+ 交互層),對錶/列逐項相關性打分,產出精簡 schema。
結果封裝:把精簡 schema 序列化回M-Schema,與問句拼裝成RESDSQL風格樣本;同一流程用於訓練與推理,保證Train-Infer 一致。
工程要點:BM25 <5 ms;SIC 批量推理單批可處理數百問句,顯存 <2 GB;Prompt 中重複注入問句降低 schema 噪聲干擾。
4.4 幻覺抑制與效果
問題刻畫:結構/語義/事實三類幻覺導致執行失敗與答案錯誤,是落地核心風險;其根因包括先驗缺失、數據稀疏、Prompt 不足、採樣過隨機、訓練數值不穩。
我們的方案:
- 兩級 Linking 從源頭壓縮搜索空間;
- 低隨機性推理(低温度/束搜索);
- 結合Executor-Guided與語法約束(訓練時語法懲罰/對比學習可選)。
實測收益:結構幻覺率7.9%→1.3%,語義誤配約-18%;在 Spider-S4 內部集Execution Accuracy +6.4%。
Key Results

流程概覽
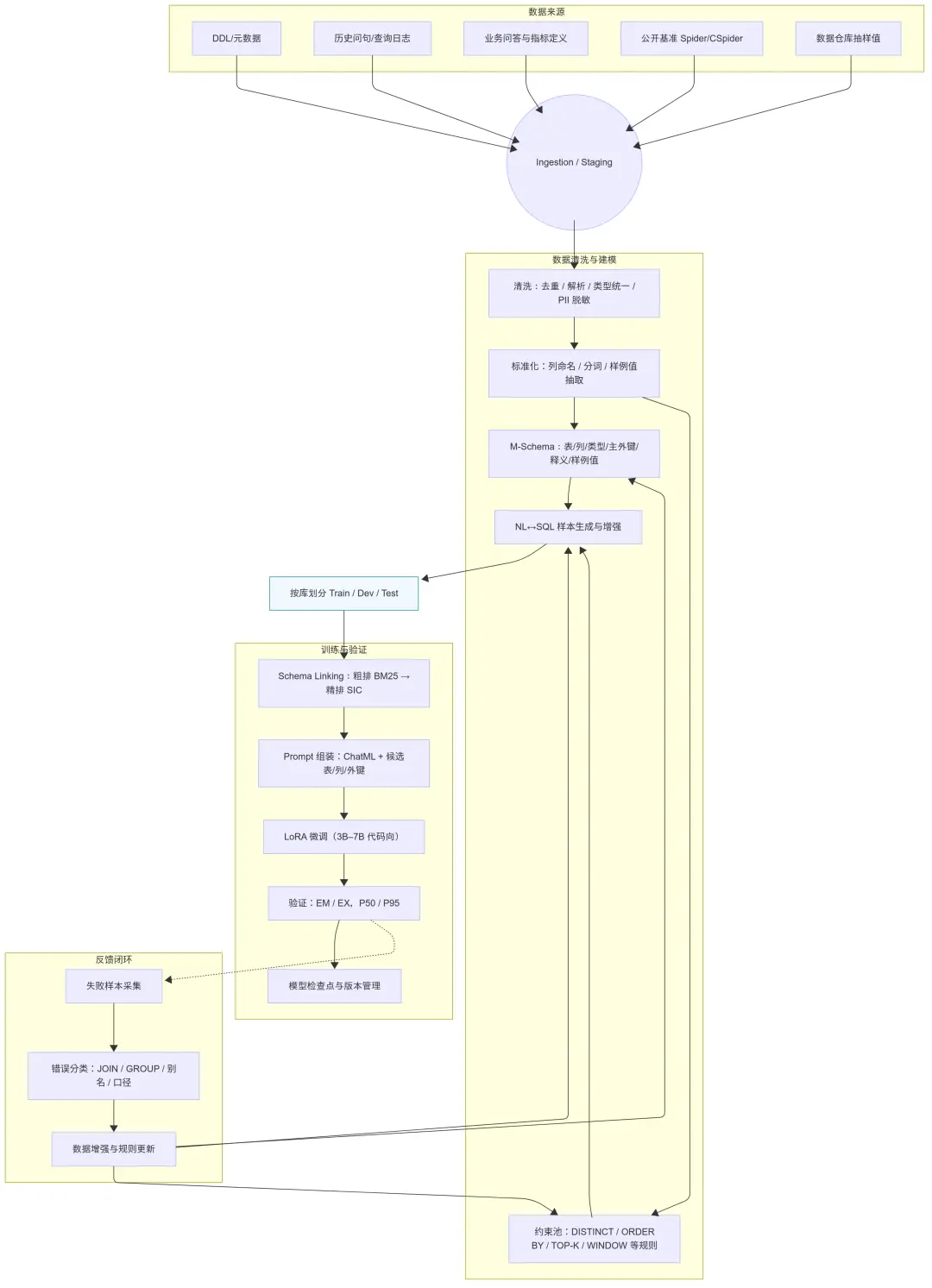
通過M-Schema(結構與示例值)、約束池(口徑與規則)、BM25→SIC 兩級 Linking與小模型 LoRA 精調 + 訓練-推理一致性,我們在不依賴超大通用模型的前提下,顯著壓降結構/語義幻覺並提升 EX 指標;在企業庫與業務小樣本上也獲得了穩定收益。
引用鏈接
- Spider:https://arxiv.org/abs/1809.08887
- wikiSQL:A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization(https://arxiv.org/pdf/1902.01069)
- Training Compute-Optimal Large Language Models(https://arxiv.org/pdf/2203.15556)
- Textbooks is all you need(https://arxiv.org/pdf/2306.11644)
- Qwen2.5-Coder Technical Report(https://arxiv.org/pdf/2409.12186)












