









為了提高性能,Netty對鎖也做了大量優化
1、鎖優化技術
Netty大量使用了鎖優化技術:
- 1.1 減小鎖粒度
- 1.2 減少鎖對象的空間佔用
- 1.3 提高鎖的性能
- 1.4 根據不同業務場景選擇合適鎖
- 1.5 能不用鎖則不用鎖
1.1 減小鎖粒度
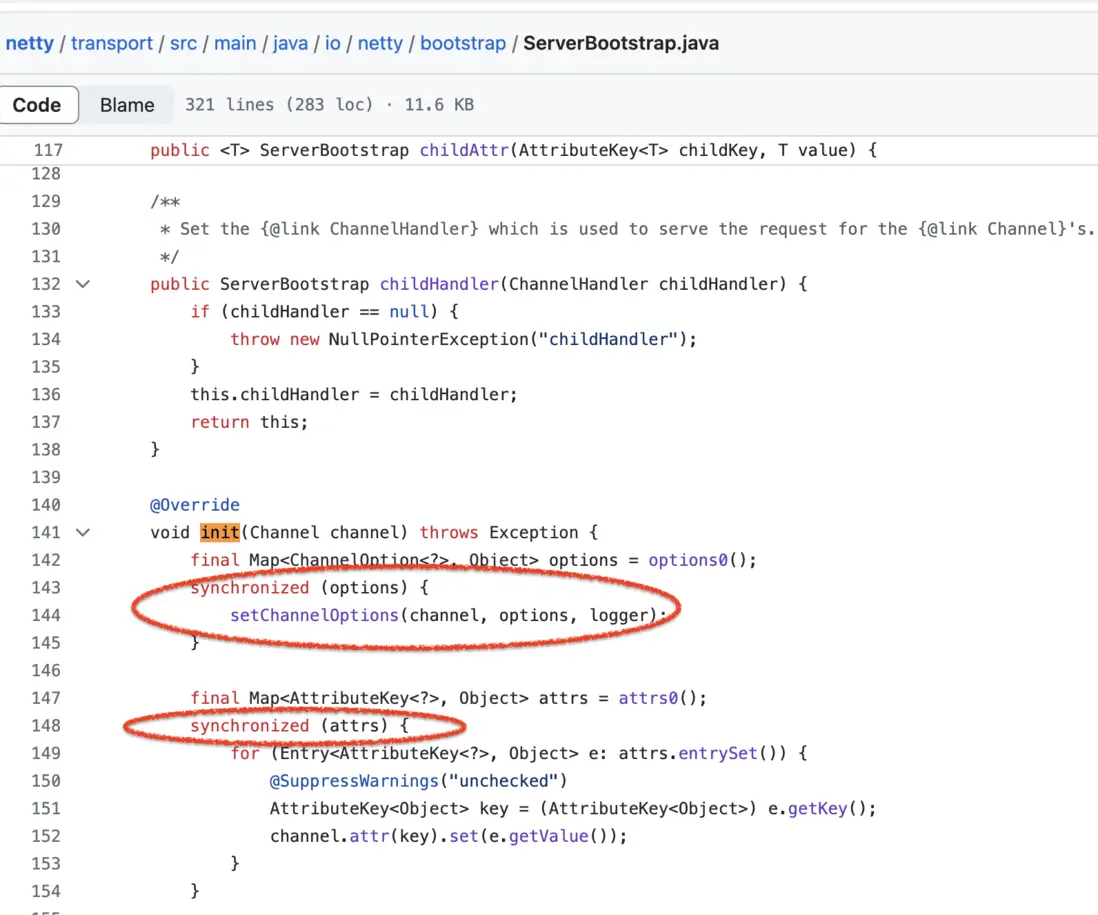
在Netty4.1.15.Final版本中ServerBootstrap.init方法中有兩個地方對對象加鎖,而不是在方法上加一個大鎖,縮小了鎖範圍,如下圖
1.2 減少鎖對象的空間佔用
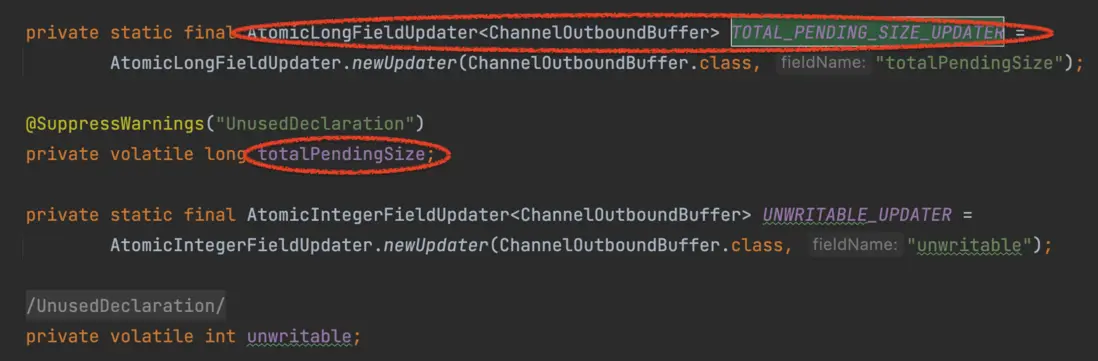
源碼ChannelOutboundBuffer類,如下圖:
totalPendingSize是用來統計待發送字節數的,上面的TOTAL\_PENDING\_SIZE\_UPDATER是AtomicLongFieldUpdater類型的,它實現對ChannelOutboundBuffer的totalPendingSize屬性進行加鎖累加,實現一個類似AtomicLong的功能。(下面的unwritable一樣的道理)
那麼為什麼要這麼做呢?為什麼不直接使用AtomicLong來定義totalPendingSize?
為了節省空間
AtomicLong VS long + AtomicLongFieldUpdater(幫助long完成原子操作)| 類型 | 佔用空間 |
|---|---|
| AtomicLong | 對象頭16B + 8B數據 + 8引用 =至少32B |
| long | 8B |
| 直接使用long,節省20多個字節,雖然很少,但是作為一個網絡工具,在大流量的情況下可以節省出很多空間,還是很有意義的 |
1.3 提高鎖性能
1.3.1 我們看一下PlatformDependent.LongCounter方法如何做的?
源碼PlatformDependent,這個類裏面有很多類似代碼
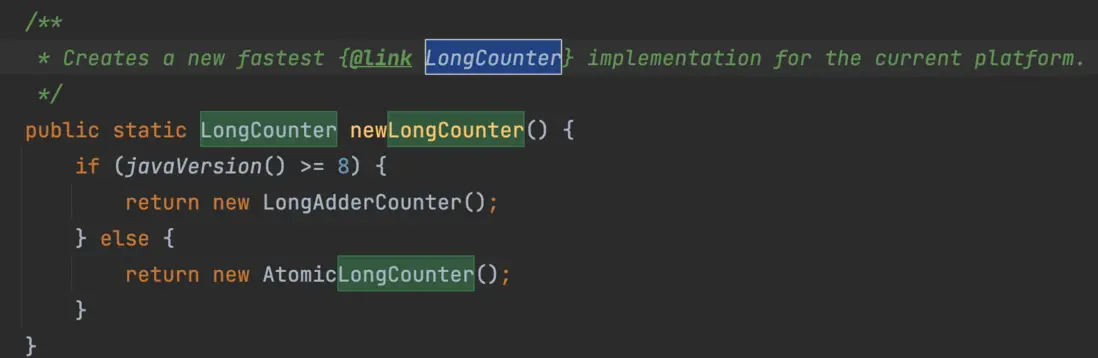
該方法提供了一個Long類型的線程安全累加器,針對java版本8以後和8以前的提供的累加器不一樣
1.8及後 LongAdder VS AtomicLong(1.8前)因為LongAdder是1.8版本開始增加的新的Long累加器,在高併發是性能要優於AtomicLong,所以1.8版本以後使用LongAdder
1.3.2 LongAdder和AtomicLong
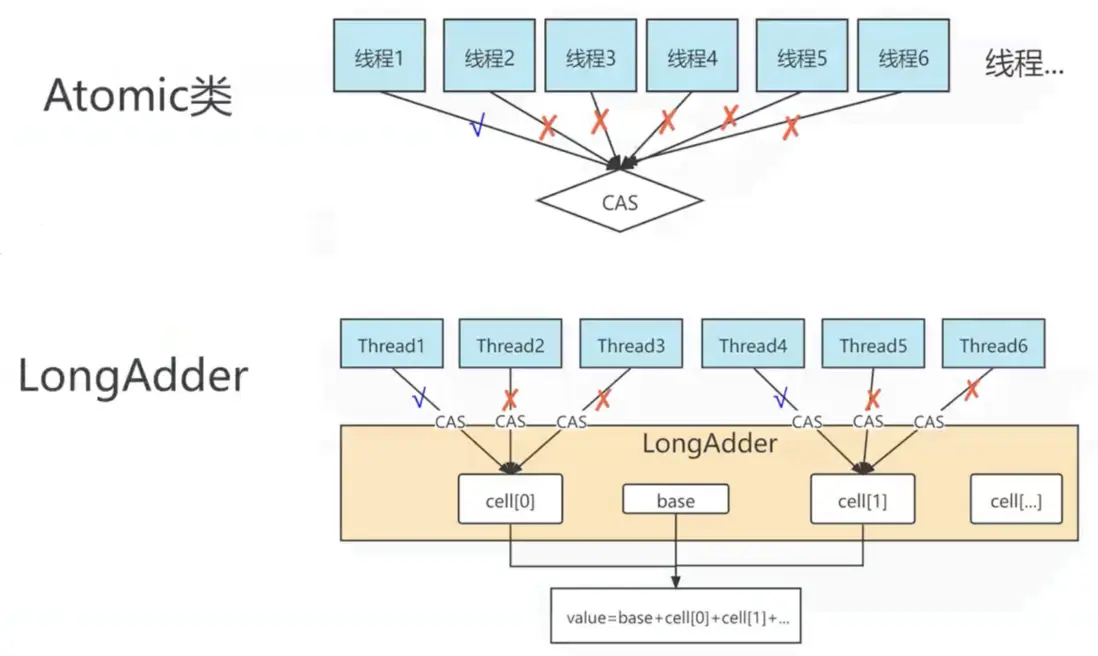
- AtomicLong 對Long類型進行原子讀寫
- LongAdder將Long的值value分成若干個cell,高併發是對某個cell的值累加,可以同時對多個cell值進行累加,能支持更高的併發。需要取到value就對所有cell進行一次sum就可以了
1.3.3 我們做一個簡單的測試看一下LongAdder和AtomicLong的性能:
public class LongAdderTest {
public static void main(String[] args) {
testAtomicLongVSLongAdder(10, 10000);
System.out.println("==================");
testAtomicLongVSLongAdder(10, 200000);
System.out.println("==================");
testAtomicLongVSLongAdder(100, 200000);
}
//AtomicLong與LongAdder多線程併發模擬及耗時統計
static void testAtomicLongVSLongAdder(final int threadCount, final int times) {
try {
long start = System.currentTimeMillis();
testLongAdder(threadCount, times);
long end = System.currentTimeMillis() - start;
// System.out.println("條件>>>>>>線程數:" + threadCount + ", 單線程操作" + times);
System.out.println("LongAdder--count" + (threadCount * times) + ",time:" + end);
long start2 = System.currentTimeMillis();
testAtomicLong(threadCount, times);
long end2 = System.currentTimeMillis() - start2;
System.out.println("Atomic--count" + (threadCount * times) + ",time:" + end2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//使用AtomicLong模擬i++多線程併發:threadCount線程數、times每個線程運行多少次
static void testAtomicLong(final int threadCount, final int times) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(threadCount);//發令槍:確保多線程同時運行
AtomicLong atomicLong = new AtomicLong();
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < times; j++) {
atomicLong.incrementAndGet(); //++操作
}
countDownLatch.countDown();
}
}, "my-thread" + i).start();
}
countDownLatch.await();
}
//使用LongAdder模擬i++多線程併發:threadCount線程數、times每個線程運行多少次
static void testLongAdder(final int threadCount, final int times) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
LongAdder longAdder = new LongAdder();
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < times; j++) {
longAdder.add(1);//是原子操作,多線程安全 //++操作
}
countDownLatch.countDown();
}
}, "my-thread" + i).start();
}
countDownLatch.await();
}
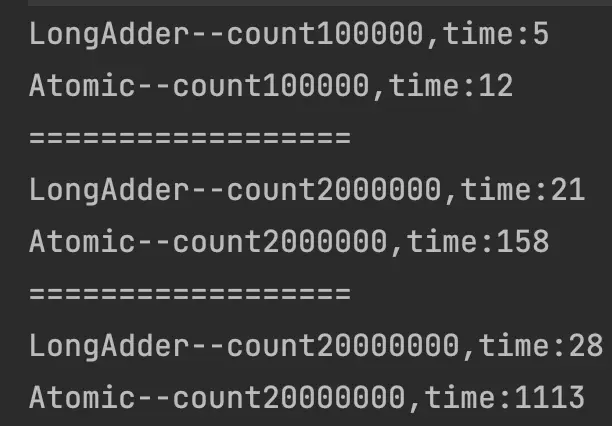
}運行結果:
如下圖,高併發情況下LongAdder性能顯著高於AtomicLong
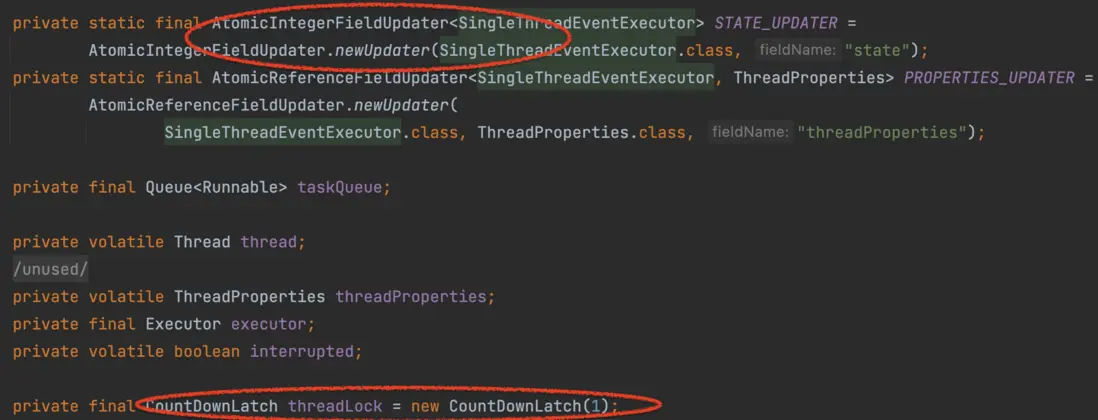
1.4 根據不同的業務場景選擇合適的鎖
SingleTreadEventExecutor中定義了Atomic...類型、CountDownLatch形式的鎖在不同的地方使用
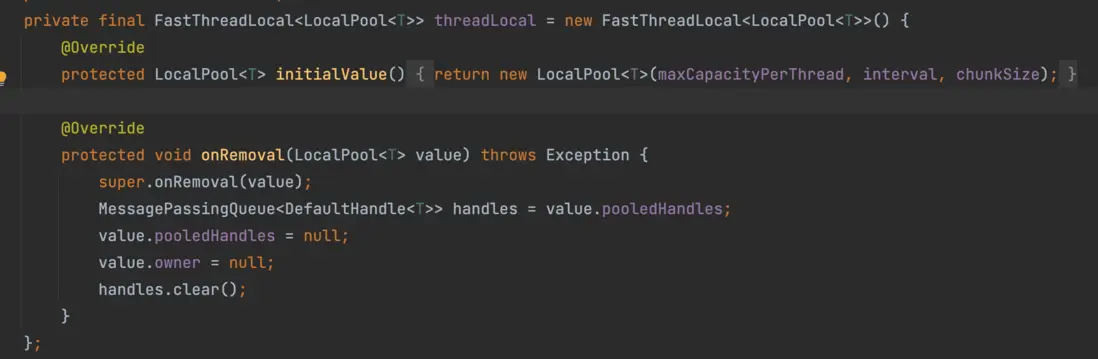
1.5 能不用鎖就不用鎖
我們Netty源碼的Recycler類裏面有一個屬性threadLocal,他是FastThreadLocal類型,該來對jdk提高的ThreadLocal做了一層包裝,該類有一個虛方法onRemoval,使用該類必須實現這個方法,避免內存泄露。
ThreadLocal是線程私有的,使用這個東西可以避免線程操作共享變量的併發競爭。
總結
從上面的討論的五種鎖優化技術可以看出來,Netty對鎖的優化可以説做到極致,各種場景下都對鎖做了優化,這些值得我們學習在項目中使用。
