

原文鏈接
課程目標
- Topic & Partition
- 消息分發策略
- 消息消費原理
- 消息的存儲策略
- Partition 副本機制
關於 Topic 和 Partition
Topic
在 kafka 中,topic 是一個存儲消息的邏輯概念,可以認為是一個消息集合。每條消息發送到 kafka 集羣的消息都有一個類別。物理上來説,不同的 Topic 的消息是分開存儲的。

每個 topic 可以有多個生產者向它發送消息,也可以有多個消費者去消費其中的消息。
Partition
每個 topic 可以劃分多個分區(每個 Topic 至少有一個分區),同一 Topic 下的不同分區包含的消息是不同的。每個消息在被添加到分區時,都會被分配一個 offset(稱之為偏移量),它是消息在此分區中的唯一編號。kafka 通過 offset 保證消息在分區內的順序,offset 的順序不跨分區。即 kafka只保證在同一個分區內的消息是有序的。
分區可以理解為數據庫層面上的分表操作
如下圖中,對於名字為 test 的 topic,做了 3 個分區,分別是
p0、p1、p2
➢ 每一條消息發送到 broker 時,會根據 partition 的規則選擇存儲到哪一個 partition 。如果 partition 規則設置合理,那麼所有的消息會均勻的分佈在不同的 partition 中, 這樣就有點類似數據庫的分庫分表的概念,把數據做了分片處理。

每一個分區裏的數字就是一個 offset ,它是一個 類似於遊標的概念。這個數字不是數據,是一個 offset,通過 offset 找到對應的數據內容。每一個 分區的內容是追加的。一個順序寫入的規則。順序遞增。Kafka 可以保證它每一個 topic 裏的每一個 分區 的數據都是順序的。跨分區是不保證順序的。這是 partition 的改變。
Topic & Partition 的存儲
Partition 是以文件的形式存儲在文件系統中,比如創建一個名為 firstTopic 的 topic,其中有 3 個 partition,那麼在kafka 的數據目錄(/tmp/kafka-log)中就有 3 個目錄, firstTopic-0~3, 命名規則是<topic_name>-<partition_id> ,每一個 Topic 的存儲是以 Partition 的存儲。
[root@Darian1 bin]# sh kafka-topics.sh --create --zookeeper 192.168.40.128:2181 --replication-factor=1 --partitions 3 --topic dariantest
Created topic "dariantest".
[root@Darian1 bin]# cd /software/zookeeper-3.4.10/bin/
[root@Darian1 bin]# sh zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /brokers/topics
[dariantest]
192.168.40.129
[root@Darian3 bin]# ls /tmp/kafka-logs/
... dariantest-0 ...192.168.40.131
192.168.40.131
[root@Darian1 bin]# ls /tmp/kafka-logs/
... dariantest-1 ...192.168.40.128
[root@Darian1 bin]# ls /tmp/kafka-logs/
... dariantest-2 ....關於消息分發
kafka 消息分發策略
消息是 kafka 中最基本的數據單元,在 kafka 中,一條消息由 key、value 兩部分構成,在發送一條消息時,我們可以指定這個 key,那麼 producer 會根據 key 和 partition 機制來判斷當前這條消息應該發送並存儲到哪個 partition 中。我們可以根據需要進行擴展 producer 的 partition 機制。
自定義分區策略代碼演示
默認的 Kafka 會根據 Key 去計算,我們也可以去擴展自己的分區策略。
/***
* 自定義分區策略
*/
public class MyParitition implements Partitioner {
private final Random random = new Random();
/***
* 重寫發送的策略
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 根據消息得到具體的分區列表
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
int partitionNum = 0;
if (key == null) {
partitionNum = random.nextInt(partitionInfos.size()); // 隨機的分區
} else {
partitionNum = Math.abs(key.hashCode() % partitionInfos.size()); // Hash 取模運算
}
System.err.println("[key]:\t" + key + "[partitionNum]:\t" + partitionNum + "[value]:\t" + value);
return partitionNum;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyParitition.class.getName());消息默認的分發機制
默認情況下,kafka 採用的是 hash 取模的分區算法。如果Key 為 null,則會隨機分配一個分區。這個隨機是在這個參數 metadata.max.age.ms 的時間範圍內隨機選擇一個。對於這個時間段內,如果 key 為 null,則只會發送到唯一的分區。這個值默認情況下是 10 分鐘更新一次。會保存在內存裏邊。
關於 Metadata ,這個之前沒講過,簡單理解就是 Topic/Partition 和 broker 的映射關係,每一個 topic 的每一個 partition,需要知道對應的 broker 列表是什麼,leader是誰、follower 是誰。這些信息都是存儲在 Metadata 這個類裏面。他的 broker 的 partition 的狀態可能發生變化,意味着它要更新他的狀態信息。
消費端如何消費指定的分區
通過下面的代碼,就可以消費指定該 topic 下的 0 號分區。其他分區的數據就無法接收。
// 消費指定分區的時候,不需要再訂閲
// kafkaConsumer.subscribe(Collections.singleto nList(topic));
// 消費指定的分區
TopicPartition topicPartition=new TopicPartition(topic,0);
kafkaConsumer.assign(Arrays.asList(topicPartition));他也是可以消費多個分區的消息的。
kafka 消息消費原理演示
在實際生產過程中,每個 topic 都會有多個 partitions,多個 partitions 的好處在於,一方面能夠對 broker 上的數據進行分片有效減少了消息的容量從而提升 io 性能。另外一方面,為了提高消費端的消費能力,一般會通過多個consumer 去消費同一個 topic ,也就是消費端的負載均衡機制。也就是我們接下來要了解的,在多個 partition 以及多個 consumer 的情況下,消費者是如何消費消息的。在上一節課,我們講了,kafka 存在 consumer group的概念, 也就是 group.id 一樣的 consumer ,這些 consumer 屬於一個 consumer group,組內的所有消費者協調在一起來消費訂閲主題的所有分區。當然每一個分區只能由同一個消費組內的 consumer 來消費,那麼同一個consumer group 裏面的 consumer 是怎麼去分配該消費哪個分區裏的數據的呢?如下圖所示,3 個分區,3 個消費者,那麼哪個消費者消費哪個分區?

對於上面這個圖來説,這 3 個消費者會分別消費 test 這個topic 的 3 個分區, 也就是每個 consumer 消費一個partition。
如果有三個分區,有四個消費者,會有一個消費者消費不到。
如果有三個分區,有兩個消費者,會有一個消費者消費兩個分區。
如果消費者比 partition 多的話浪費,所以我們不建議去設置多的消費者。
- 我們實際過程使用過程中,consumer 如果比 partition 數量多的話,實際上是浪費的。所以我們不建議去設置比較多的消費者。因為 Kafka 的設計是在一個 partition 上是不允許併發的。
- 如果 consumer 比 partition 數量少的話,就會有 consumer 消費多個 partition。如果,我們的消費者的能力本身就比較強的話,我就可以去合理的做一個負載。我一個消費者可以消費兩個到三個。
- consumer 最好是 partition 的整數倍。整數倍,意味着我們的消費者能夠合理的分發。
- 如果我們的 consumer 消費了多個 partition ,那麼它是不保證順序性的。他只能説對一個分區保證順序性,但是跨分區,它是不保證順序性。
增減 consumer 、broker、partition 會導致 Rebalance。重新負載。
什麼是分區分配策略
通過前面的案例演示,我們應該能猜到,同一個 group 中的消費者對於一個 topic 中的多個 partition,存在一定的分區分配策略。
在 kafka 中,存在兩種分區分配策略,一種是 Range ( 默認 ) 、另一種是 RoundRobin( 輪 詢 )。通過 partition.assignment.strategy 這個參數來設置。
Range strategy(範圍分區)
Range 策略是對每個主題而言的,首先對同一個主題裏面的分區按照序號進行排序,並對消費者按照字母順序進行排序。假設我們有 10 個分區,3 個消費者,排完序的分區將會是 0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消費者線程排完序將會是 C1-0 , C2-0 , C3-0 。然後將 partitions 的個數除於消費者線程的總數來決定每個消費者線程消費幾個分區。如果除不盡,那麼前面幾個消費者線程將會多消費一個分區。在我們的例子裏面。
-
我們有 10 個分區,3 個消費者線程, 10 / 3 = 3,而且除不盡,那麼消費者線程 C1-0 將會多消費一個分區,所以最後分區分配的結果看起來是這樣的:
-
- C1-0 將消費 0, 1, 2, 3 分區
- C2-0 將消費 4, 5, 6 分區
- C3-0 將消費 7, 8, 9 分區
-
-
假如我們有 11 個分區,那麼最後分區分配的結果看起來是這樣的:
-
- C1-0 將消費 0, 1, 2, 3 分區
- C2-0 將消費 4, 5, 6, 7 分區
- C3-0 將消費 8, 9, 10 分區
-
-
假如我們有 2 個主題 ( T1 和 T2 ) ,分別有 10 個分區,那麼最後分區分配的結果看起來是這樣的:
-
- C1-0 將消費 T1 主題的 0, 1, 2, 3 分區以及 T2 主題的 0, 1, 2, 3 分區
- C2-0 將消費 T1 主題的 4, 5, 6 分區以及 T2 主題的 4, 5, 6 分區
- C3-0 將消費 T1 主題的 7, 8, 9 分區以及 T2 主題的 7, 8, 9 分區
可以看出,C1-0 消費者線程比其他消費者線程多消費了 2 個分區,這就是 Range strategy 的一個很明顯的弊端
-
RoundRobin strategy(輪詢分區)
輪詢分區策略是把所有 partition 和所有 consumer 線程都列出來,然後按照 hashcode 進行排序。最後通過輪詢算法分配 partition 給消費線程。如果所有 consumer 實例的訂閲是相同的,那麼 partition 會均勻分佈。
-
在我們的例子裏面,假如按照 hashCode 排序完的 topic-partitions 組依次為 T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4,T1-7, T1-6, T1-9,我們的消費者線程排序為 C1-0, C1-1, C2- 0, C2-1,最後分區分配的結果為:
-
- C1-0 將消費 T1-5, T1-2, T1-6 分區;
- C1-1 將消費 T1-3, T1-1, T1-9 分區;
- C2-0 將消費 T1-0, T1-4 分區;
- C2-1 將消費 T1-8, T1-7 分區;
-
使用輪詢分區策略必須滿足兩個條件
- 每個主題的消費者實例具有相同數量的流
- 每個消費者訂閲的主題必須是相同的
什麼時候會觸發這個策略呢?
當出現以下幾種情況時,kafka 會進行一次分區分配操作, 也就是 kafka consumer 的 rebalance
- 同一個 consumer group 內新增了消費者
- 消費者離開當前所屬的 consumer group,比如主動停機或者宕機
- Topic 新增了分區(也就是分區數量發生了變化)
- 消費者主動取消訂閲 Topic。
kafka consumer 的 rebalance 機制規定了一個 consumer group 下的所有 consumer 如何達成一致來分配訂閲 topic 的每個分區。而具體如何執行分區策略,就是前面提到過的兩種內置的分區策略。而 kafka 對於分配策略這塊,提供了可插拔的實現方式, 也就是説,除了這兩種之外,我們還可以創建自己的分配機制。
誰來執行 Rebalance 以及管理 consumer 的 group 呢?
Kafka 提供了一個角色:coordinator 。來執行對於 consumer group 的管理,當 consumer group 的第一個 consumer 啓動的時候,它會去和 kafka server 確定誰是它們組的 coordinator。之後該 group 內的所有成員都會和該 coordinator 進行協調通信。
如何確定 coordinator
consumer group 如何確定自己的 coordinator 是誰呢, 消費者向 kafka 集 羣 中 的 任 意 一 個 broker 發 送 一 個GroupCoordinatorRequest 請求,服務端會返回一個負載最 小 的 broker 節 點 的 id , 並 將 該 broker 設 置 為coordinator
JoinGroup 的過程
在 rebalance 之前,需要保證 coordinator 是已經確定好了的,整個 rebalance 的過程分為兩個步驟,Join 和 Sync
join: 表示加入到 consumer group 中,在這一步中,所有的成員都會向 coordinator 發送 joinGroup 的請求。一旦所有成員都發送了 joinGroup 請求,那麼 coordinator 會選擇一個 consumer 擔任 leader 角色,並把組成員信息和訂閲信息發送消費者。

protocol_metadata: 序列化後的消費者的訂閲信息leader_id: 消費組中的消費者,coordinator 會選擇一個座位 leader,對應的就是 member_idmember_metadata對應消費者的訂閲信息members:consumer group 中全部的消費者的訂閲信息 ,只有 leader 才會受到 members 的信息。generation_id: 年代信息,類似於之前講解 zookeeper 的時候的 epoch 是一樣的, 對於每一輪 rebalance ,generation_id 都會遞增。主要用來保護 consumer group。隔離無效的 offset 提交。也就是上一輪的 consumer 成員無法提交 offset 到新的 consumer group 中。
建立好連接以後,會發送心跳。
Synchronizing Group State 階段
完成分區分配之後,就進入了 Synchronizing Group State 階段 ,主要邏輯是向 GroupCoordinator 發 送 SyncGroupRequest 請求,並且處理 SyncGroupResponse 響應,簡單來説,就是 leader 將消費者對應的 partition 分配方案同步給 consumer group 中的所有 consumer。

每個消費者都會向 coordinator 發送 syncgroup 請求,不過只有 leader 節點會發送分配方案,其他消費者只是打打醬油而已。當 leader 把方案發給 coordinator 以後,coordinator 會把結果設置到 SyncGroupResponse 中。這樣所有成員都知道自己應該消費哪個分區。
- consumer group 的分區分配方案是在客户端執行的!Kafka 將這個權利下放給客户端主要是因為這樣做可以有更好的靈活性。
一開始是在分區分配方案是在 zookeeper 執行,後來都是 客户端執行。
如何保存消費端的消費位置
什麼是 offset
前面在講解 partition 的時候,提到過 offset, 每個 topic可以劃分多個分區(每個 Topic 至少有一個分區),同一 topic 下的不同分區包含的消息是不同的。每個消息在被添加到分區時,都會被分配一個 offset(稱之為偏移量),它 是消息在此分區中的唯一編號,kafka 通過 offset 保證消息在分區內的順序,offset 的順序不跨分區,即 kafka 只保證在同一個分區內的消息是有序的; 對於應用層的消費來説, 每次消費一個消息並且提交以後,會保存當前消費到的最 近的一個 offset。那麼 offset 保存在哪裏?

offset 在哪裏維護?
在 kafka 中,提供了一個 consumer_offsets_* 的一個topic , 把 offset 信 息 寫 入 到 這 個 topic 中 。 consumer_offsets——保存了每個 consumer group 某一時刻提交的 offset 信息。 consumer_offsets 默認有50 個分區。
[zk: localhost:2181(CONNECTED) 2] ls /brokers/topics
[test, __consumer_offsets, dariantest]
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics/__consumer_offsets
[partitions]
[zk: localhost:2181(CONNECTED) 4] ls /brokers/topics/__consumer_offsets/partitions
[44, 45, 46, 47, 48, 49, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]
[zk: localhost:2181(CONNECTED) 5] [root@Darian1 ~]# clear
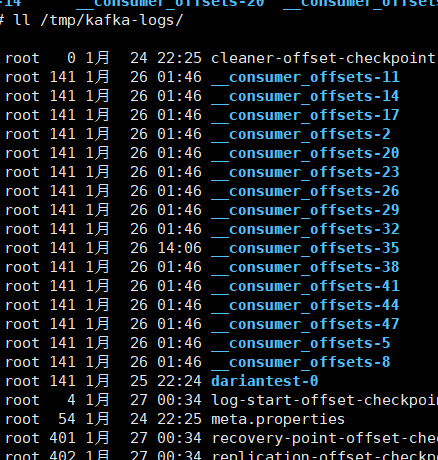
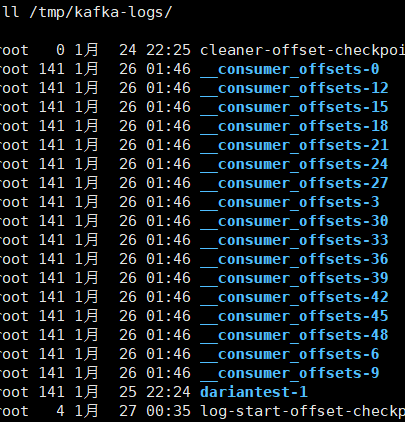
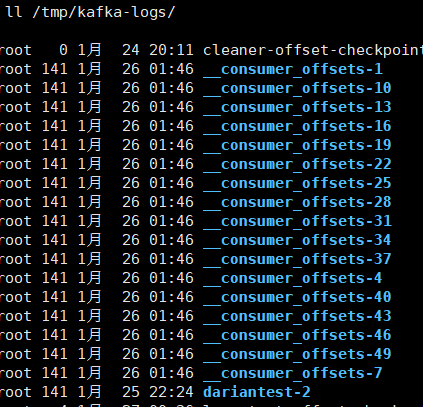
[root@Darian1 ~]# ls /tmp/kafka-logs/
cleaner-offset-checkpoint __consumer_offsets-13 __consumer_offsets-22 __consumer_offsets-31 __consumer_offsets-4 __consumer_offsets-46 dariantest-2 recovery-point-offset-checkpoint
__consumer_offsets-1 __consumer_offsets-16 __consumer_offsets-25 __consumer_offsets-34 __consumer_offsets-40 __consumer_offsets-49 log-start-offset-checkpoint replication-offset-checkpoint
__consumer_offsets-10 __consumer_offsets-19 __consumer_offsets-28 __consumer_offsets-37 __consumer_offsets-43 __consumer_offsets-7 meta.properties 根 據 前 面 我 們 演 示 的 案 例 , 我 們 設 置 了 一 個 KafkaConsumerDemo 的 groupid。首先我們需要找到這個 consumer_group 保存在哪個分區中。
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerDemo");-
計算公式
-
Math.abs(“groupid”.hashCode())%groupMetadataTopi cPartitionCount ; // Math.abs("consumerDemo".hashCode % 50 );由於默認情況下
groupMetadataTopicPartitionCount有 50 個分區,計算得到的結果為:35, 意味着當前的consumer_group的位移信息保存在consumer_offsets的第 35 個分區 -
執行如下命令,可以查看當前
consumer_goup中的 offset 位移信息sh kafka-simple-consumer-shell.sh --topic consumer_offsets --partition 5 --broker-list 192.168.40.128:9092,192.168.40.129:9092,192.168.40.131:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"[root@Darian3 bin]# sh kafka-consumer-groups.sh --bootstrap-server 192.168.40.128:9092,192.168.40.129:9092,192.168.40.131:9092 --describe --group KafkaConsumerDemo Consumer group 'KafkaConsumerDemo' has no active members. TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID test 0 115 115 0 - - -[root@Darian3 bin]# sh kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list '192.168.40.128:9092,192.168.40.129:9092,192.168.40.131:9092' --topic 'test' --time -1
-
從輸出結果中,我們就可以看到 test 這個 topic 的 offset的位移日誌。
| 192.168.40.129 | 192.168.40.130 | 192.168.40.131 |
|--------------------------------------------------------------------------|--------------------------------------------------------------------------| ------------------------------------------ |
|  |  | |
# 消息的存儲
### 消息的保存路徑
消息發送端發送消息到 broker 上以後,消息是如何持久化的呢?那麼接下來去分析下消息的存儲。
首先我們需要了解的是,kafka 是使用日誌文件的方式來保存生產者和發送者的消息,每條消息都有一個 offset 值來表示它在分區中的偏移量。Kafka 中存儲的一般都是海量的消息數據,為了避免日誌文件過大,Log 並不是直接對應在一個磁盤上的日誌文件,而是對應磁盤上的一個目錄, 這個目錄的命名規則是<topic_name>_<partition_id>
比如創建一個名為 firstTopic 的 topic,其中有 3 個 partition,那麼在 kafka 的數據目錄(/tmp/kafka-log)中就有 3 個目錄,firstTopic-0~3
### 多個分區在集羣中的分配
如果我們對於一個 topic,在集羣中創建多個 partition,那麼 partition 是如何分佈的呢?
1. 將所有 N Broker 和待分配的 i 個 Partition 排序
2. 將第 i 個 Partition 分配到第(i mod n)個 Broker 上
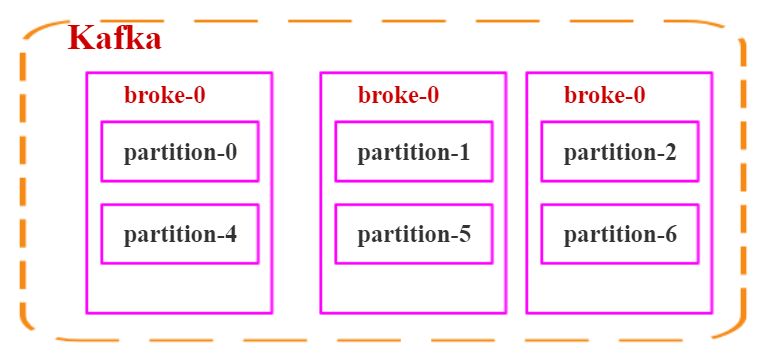
瞭解到這裏的時候,大家再結合前面講的消息分發策略, 就應該能明白消息發送到 broker 上,消息會保存到哪個分區中,並且消費端應該消費哪些分區的數據了。
### 消息寫入的性能
我們現在大部分企業仍然用的是機械結構的磁盤,如果把消息以隨機的方式寫入到磁盤,那麼磁盤首先要做的就是尋址,也就是定位到數據所在的物理地址,在磁盤上就要找到對應的柱面、磁頭以及對應的扇區;這個過程相對內存來説會消耗大量時間,為了規避隨機讀寫帶來的時間消耗,kafka 採用順序寫的方式存儲數據。即使是這樣,但是頻繁的 I/O 操作仍然會造成磁盤的性能瓶頸,所以 kafka 還有一個性能策略。
#### 零拷貝
消息從發送到落地保存,broker 維護的消息日誌本身就是文件目錄,每個文件都是二進制保存,生產者和消費者使用相同的格式來處理。在消費者獲取消息時,服務器先從硬盤讀取數據到內存,然後把內存中的數據原封不動的通過 socket 發送給消費者。雖然這個操作描述起來很簡單, 但實際上經歷了很多步驟。
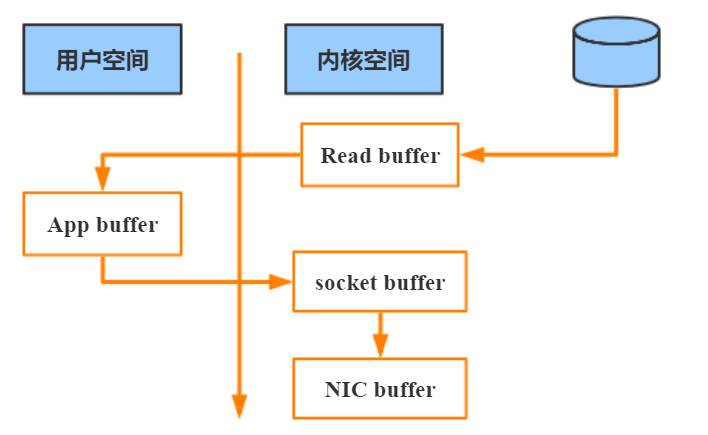
▪ 操作系統將數據從磁盤讀入到內核空間的頁緩存
▪ 應用程序將數據從內核空間讀入到用户空間緩存中
▪ 應用程序將數據寫回到內核空間到 socket 緩存中
▪ 操作系統將數據從 socket 緩衝區複製到網卡緩衝區,以便把數據經網絡發出
這個過程涉及 4 次上下文切換以及 4 次數據複製,並且有兩次複製操作是由 CPU 完成。但是這個過程中,數據完全沒有進行變化,僅僅是從磁盤複製到網卡緩衝區。
通過“零拷貝”技術,可以去掉這些沒必要的數據複製操作,同時也會減少上下文切換次數。現代的 unix 操作系統提供一個優化的代碼路徑,用於將數據從頁緩存傳輸到 socket; 在 Linux 中,是通過 sendfile 系統調用來完成的。Java 提供了訪問這個系統調用的方法:`FileChannel.transferTo API` 。
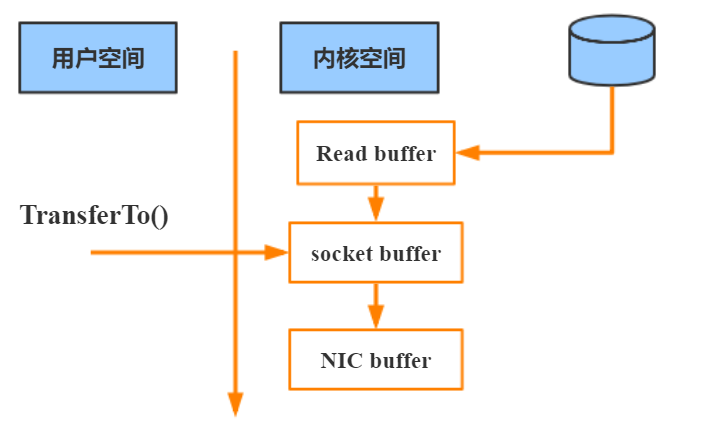
使用 sendfile,只需要一次拷貝就行,允許操作系統將數據直接從頁緩存發送到網絡上。所以在這個優化的路徑中, 只有最後一步將數據拷貝到網卡緩存中是需要的。
https://www.cnblogs.com/dadonggg/p/8205302.html kafka 管理工具。









