









語言集成查詢(LINQ)指的是基於將查詢功能直接整合到 C# 語言中而形成的一系列技術。傳統上,針對數據的查詢是以簡單的字符串形式表達的,且在編譯時沒有類型檢查,也沒有智能提示支持。此外,針對不同的數據源(如 SQL 數據庫、XML 文檔、各種 Web 服務等),您需要學習不同的查詢語言。而使用 LINQ 後,查詢就成為了一種與類、方法和事件同等重要的語言結構。
在編寫查詢語句時,LINQ 中最直觀的 “語言集成” 部分就是查詢表達式。查詢表達式採用一種聲明式的查詢語法進行編寫。通過使用查詢語法,您只需少量代碼即可對數據源執行篩選、排序和分組操作。您可以使用相同的查詢表達式模式來查詢和轉換來自任何類型數據源的數據。
以下示例展示了完整的查詢操作。整個操作包括創建數據源、定義查詢表達式以及在 “foreach” 語句中執行查詢。
// LINQ 查詢的三個部分:
// 1. 數據源
int [] zhss = [ 1, 2, 3, 4, 5, 6 , 8 , 10 ];
// 2. 建立查詢
var zhs查詢 = from z in zhss
where ( z % 2 ) == 0
select z;
// 3. 執行查詢
foreach ( int z in zhs查詢 )
{
Console . WriteLine ( $"{ z , 1 }" );
}對於前面的示例,您可能需要添加一個 “using” 指令,即 “using System.Linq;”,才能編譯。最新的 .NET 版本使用隱式 “using” 將此指令作為全局 “using” 添加。較舊的版本則需要您在源代碼中添加。
查詢表達式概述
- 查詢表達式從任何支持 LINQ 的數據源中查詢和轉換數據。例如,單個查詢可以從 SQL 數據庫中檢索數據,並生成 XML 流作為輸出。
- 查詢表達式使用許多熟悉的 C# 語言結構,這使得它們易於閲讀。
- 查詢表達式中的變量都是強類型的。
- 只有在對查詢變量進行迭代時(例如在 foreach 語句中),查詢才會執行。
- 在編譯時,查詢表達式會根據 C# 規範中定義的規則轉換為標準查詢運算符方法調用。任何可以使用查詢語法表達的查詢也可以使用方法語法表達。在某些情況下,查詢語法更易讀且更簡潔。在其他情況下,方法語法更易讀。這兩種不同形式在語義和性能上沒有區別。
- 某些查詢操作(如 Count 或 Max)沒有對應的查詢表達式子句,因此必須以方法調用的形式表達。方法語法可以以多種方式與查詢語法結合使用。查詢表達式可以編譯為表達式樹或委託,具體取決於查詢所應用的類型。對 IEnumerable < T > 的查詢會編譯為委託。對 IQueryable 和 IQueryable < T > 的查詢會編譯為表達式樹。
如何啓用對數據源的 LINQ 查詢
內存中的數據
啓用對內存中數據的 LINQ 查詢有兩種方法。如果數據的類型實現了 IEnumerable < T >,則使用 LINQ to Objects 對數據進行查詢。如果實現 IEnumerable < T > 接口來啓用枚舉沒有意義,則在該類型中定義 LINQ 標準查詢運算符方法,或者為該類型定義擴展方法。標準查詢運算符的自定義實現應使用延遲執行來返回結果。
遠程數據
實現對遠程數據源進行 LINQ 查詢的最佳選項是實現 IQueryable < T > 接口。
IQueryable LINQ 提供程序
實現 IQueryable < T > 的 LINQ 提供程序在複雜程度上可能差異很大。
一種不太複雜的 IQueryable 提供程序可能會從 Web 服務訪問單個方法。這種類型的提供程序特定於數據源,因為它期望其處理的查詢中包含特定的信息。它具有封閉的類型系統,可能只公開一種結果類型。查詢的大部分執行都在本地進行,例如通過使用標準查詢運算符的 Enumerable 實現。不太複雜的提供程序可能會僅檢查表示查詢的表達式樹中的一個方法調用表達式,並讓查詢的其餘邏輯在其他地方處理。
一箇中等複雜度的可查詢數據提供程序可能會針對具有部分表達能力的查詢語言的數據源。如果它針對的是 Web 服務,那麼它可能會訪問該 Web 服務的多個方法,並根據查詢所尋求的信息來選擇調用哪個方法。中等複雜度的提供程序會比簡單提供程序擁有更豐富的類型系統,但它仍然是一個固定類型系統。例如,該提供程序可能會公開具有可遍歷的一對多關係的類型,但它不會為用户定義的類型提供映射技術。
像 Entity Framework Core 提供程序這樣的複雜 IQueryable 提供程序可能會將完整的 LINQ 查詢轉換為一種表達式豐富的查詢語言,例如 SQL。複雜提供程序更具通用性,因為它能夠處理查詢中更廣泛的問題類型。它還具有開放的類型系統,因此必須包含大量的基礎架構來映射用户定義的類型。開發一個複雜的提供程序需要付出大量的努力。
C# 中的 LINQ 查詢簡介
查詢是一種從數據源中檢索數據的表達式。不同的數據源具有不同的原生查詢語言,例如關係型數據庫的 SQL 和 XML 的 XQuery。開發人員必須為他們必須支持的每種數據源或數據格式學習一種新的查詢語言。LINQ 通過為各種數據源和格式提供一致的 C# 語言模型來簡化這種情況。在 LINQ 查詢中,您始終處理 C# 對象。無論是在 XML 文檔、SQL 數據庫、.NET 集合還是任何其他格式中,只要存在 LINQ 提供程序,您都可以使用相同的基本編碼模式來查詢和轉換數據。
查詢操作的三個部分
所有的 LINQ 查詢操作都包含三個不同的操作步驟:
- 獲取數據源。
- 創建查詢。
- 執行查詢。
開頭的示例展示了查詢操作的三個部分在源代碼中的表達方式。該示例為了方便起見使用了一個整數數組作為數據源;然而,同樣的概念也適用於其他數據源。
以下示例展示了完整的查詢操作。在 LINQ 中,查詢的執行過程與查詢本身是分開的。換句話説,您無需通過創建查詢變量來獲取任何數據。
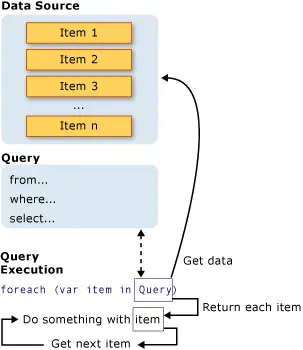
數據源
在上述示例中,數據源是一個數組,它支持通用的 IEnumerable < T > 接口。這一事實意味着它可以使用 LINQ 進行查詢。查詢是在 foreach 語句中執行的,而 foreach 要求的是 IEnumerable 或 IEnumerable < T > 類型。支持 IEnumerable < T > 或其衍生接口(如通用的 IQueryable < T >)的類型被稱為可查詢類型。
可查詢類型無需進行任何修改或特殊處理即可作為 LINQ 數據源使用。如果源數據尚未以可查詢類型的形式存儲在內存中,LINQ 提供程序必須將其轉換為這種形式。例如,LINQ to XML 會將 XML 文檔加載為可查詢的 XElement 類型:
// 從 XML 文檔創建數據源。
// 使用 System . Xml . Linq
XElement contacts = XElement . Load ( @"c:\myContactList.xml" );使用 EntityFramework,您可以創建 C# 類與數據庫模式之間的對象 - 關係映射。您針對這些對象編寫查詢語句,而在運行時,EntityFramework 將負責與數據庫進行通信。在以下示例中,KHs 表示數據庫中的一個特定表,而查詢結果的類型,即 IQueryable < T >,是 IEnumerable < T > 的子類型。
Northwnd db = new Northwnd ( @"c:\northwnd.mdf" );
// 查詢所有在倫敦的客户
IQueryable < Customer > KH查詢 = from KH in db . Customers
where KH . City == "London"
select KH;基本規則很簡單:LINQ 數據源是指任何支持泛型 IEnumerable < T > 接口(或其繼承接口,通常為 IQueryable < T >)的對象。
注意:諸如 ArrayList 這類支持非泛型 IEnumerable 接口的類型也可以用作 LINQ 數據源。
查詢
該查詢指定了從數據源或多個數據源中檢索哪些信息。此外,查詢還可以指定在返回這些信息之前應如何對其進行排序、分組和整理。查詢會被存儲在查詢變量中,並通過查詢表達式進行初始化。您使用 C# 查詢語法來編寫查詢。
在上一個示例中,該查詢會返回整數數組中的所有偶數。該查詢表達式包含三個部分:from、where 和 select(如果您熟悉 SQL,您會注意到這些部分的順序與 SQL 中的順序相反)。from 子句指定了數據源,where 子句應用過濾條件,而 select 子句指定了返回元素的類型。所有這些查詢部分在本節中都有詳細討論。目前,重要的是在 LINQ 中,查詢變量本身不會執行任何操作,也不會返回任何數據。它只是存儲在執行查詢的後續時刻時生成結果所需的必要信息。
注意:查詢也可以通過使用方法語法來表達。
按執行方式對標準查詢操作符進行分類
LINQ 到對象實現的標準查詢操作方法有兩種主要的執行方式:即時執行或延遲執行。使用延遲執行的查詢操作符還可以進一步分為兩類:流式和非流式。
“立即”
立即執行意味着會讀取數據源並執行一次操作。所有返回標量結果的標準查詢運算符都會立即執行。這類查詢的例子包括 Count、Max、Average 和 First 等方法。由於查詢本身必須使用 foreach 來返回結果,所以這些方法在執行時不會使用顯式的 foreach 語句。這些查詢返回的是單個值,而不是 IEnumerable 集合。您可以使用 Enumerable . ToList 或 Enumerable . ToArray 方法強制任何查詢立即執行。立即執行提供了查詢結果的重用功能,而非查詢聲明功能。結果僅被獲取一次,然後存儲起來以備將來使用。以下查詢返回源數組中偶數的數量:
var zhs查詢 = from z in zhss
where ( z % 2 ) == 0
select z;
int Z偶數個數 = zhs查詢 . count ( );若要強制立即執行任何查詢並緩存其結果,您可以調用 ToList 或 ToArray 方法。
var zhs查詢 =
( from z in zhss
where ( z % 2 ) == 0
select z ) . ToList ( );
var zhs查詢 =
( from z in zhss
where ( z % 2 ) == 0
select z ) . ToArray ( );您還可以通過將 foreach 循環直接置於查詢表達式之後的方式來強制執行。不過,通過調用 ToList 或 ToArray 方法,您還會將所有數據緩存在一個單一的集合對象中。
延遲執行
延遲執行意味着操作不會在聲明查詢的代碼位置立即執行。而是隻有在對查詢變量進行枚舉時(例如通過使用 foreach 語句)才會執行該操作。執行查詢的結果取決於執行查詢時數據源中的內容,而非查詢定義時的內容。如果對查詢變量進行多次枚舉,每次的結果可能會有所不同。幾乎所有返回類型為 IEnumerable < T > 或 IOrderedEnumerable < TElement > 的標準查詢運算符都是以延遲方式執行的。延遲執行提供了查詢重用的功能,因為每次迭代查詢結果時,查詢都會從數據源中獲取更新的數據。以下代碼展示了延遲執行的一個示例:
foreach ( int z in Z查詢 )
{
Console . Write ( $"{z , 1} " );
}foreach 語句也是獲取查詢結果的地方。例如,在之前的查詢中,迭代變量 z 持有返回序列中的每個值(一次一個)。
因為查詢變量本身並不保存查詢結果,所以您可以反覆執行該查詢以獲取更新的數據。例如,一個獨立的應用程序可能會持續更新數據庫。在您的應用程序中,您可以創建一個查詢來獲取最新數據,並且可以每隔一段時間執行該查詢以獲取更新後的結果。
使用延遲執行的查詢操作符還可以進一步分為流式操作符和非流式操作符。
流媒體
流式操作符在生成元素之前無需讀取所有源數據。在執行過程中,流式操作符會根據讀取到的每個源元素進行操作,並在適當的情況下生成該元素。流式操作符會持續讀取源元素,直到能夠生成一個結果元素為止。這意味着為了生成一個結果元素,可能會讀取多個源元素。
非流式
非流式操作員必須在得出結果元素之前讀取所有源數據。諸如排序或分組之類的操作就屬於這一類。在執行時,非流式查詢操作員會讀取所有源數據,將其放入數據結構中,執行操作,並生成結果元素。
分類表
以下表格根據每種標準查詢操作方法的執行方式對其進行了分類。
注意:如果一個操作符被標記在兩列中,那麼該操作涉及兩個輸入序列,並且每個序列的處理方式都不同。在這些情況下,總是參數列表中的第一個序列以延遲、流式的方式進行處理。
| 標準查詢操作 | 返回類型 | 立即執行 | 延遲流式執行 | 延遲非流式執行 |
|---|---|---|---|---|
| Aggregate | TSource | ✓ | ||
| All | Boolean | ✓ | ||
| Any | Boolean | ✓ | ||
| AsEnumerable | IEnumerable < T > | ✓ | ||
| Average | Single numeric value | ✓ | ||
| Cast | IEnumerable < T > | ✓ | ||
| Concat | IEnumerable < T > | ✓ | ||
| Contains | Boolean | ✓ | ||
| Count | Int32 | ✓ | ||
| DefaultIfEmpty | IEnumerable < T > | ✓ | ||
| Distinct | IEnumerable < T > | ✓ | ||
| ElementAt | TSource | ✓ | ||
| ElementAtOrDefault | TSource? | ✓ | ||
| Empty | IEnumerable < T > | ✓ | ||
| Except | IEnumerable < T > | ✓ | ✓ | |
| First | TSource | ✓ | ||
| FirstOrDefault | TSource? | ✓ | ||
| GroupBy | IEnumerable < T > | ✓ | ||
| GroupJoin | IEnumerable < T > | ✓ | ✓ | |
| Intersect | IEnumerable < T > | ✓ | ✓ | |
| Jion | IEnumerable < T > | ✓ | ✓ | |
| Last | TSource | ✓ | ||
| LastOrDefault | TSource? | ✓ | ||
| LongCount | Int64 | ✓ | ||
| Max | 單個數值,TSource,或者 TResult? | ✓ | ||
| Min | 單個數值,TSource,或者 TResult? | ✓ | ||
| OfType | IEnumerable < T > | ✓ | ||
| OrderBy | IOrderedEnumerable < TElement > | ✓ | ||
| OrderByDescending | IOrderedEnumerable < TElement > | ✓ | ||
| Range | IEnumerable < T > | ✓ | ||
| Repeat | IEnumerable < T > | ✓ | ||
| Reverse | IEnumerable < T > | ✓ | ||
| Select | IEnumerable < T > | ✓ | ||
| SelectMany | IEnumerable < T > | ✓ | ||
| SequenceEqual | Boolean | ✓ | ||
| Single | TSource | ✓ | ||
| SingleOrDefault | TSource? | ✓ | ||
| Skip | IEnumerable < T > | ✓ | ||
| SkipWhile | IEnumerable < T > | ✓ | ||
| Sum | 單個數值 | ✓ | ||
| Take | IEnumerable < T > | ✓ | ||
| TakeWhile | IEnumerable < T > | ✓ | ||
| ThenBy | IOrderedEnumerable < TElement > | ✓ | ||
| ThenByDescending | IOrderedEnumerable < TElement > | ✓ | ||
| ToArray | TSource [ ] 數組 | ✓ | ||
| ToDictionary | Dictionary < TKey , TValue > | ✓ | ||
| ToList | IList < T > | ✓ | ||
| ToLookup | ILookup < TKey , TElement > | ✓ | ||
| Union | IEnumerable < T > | ✓ | ||
| Where | IEnumerable < T > | ✓ |
對象型 LINQ
“對象型 LINQ” 指的是將 LINQ 查詢直接應用於任何 IEnumerable 或 IEnumerable < T > 集合的情況。您可以使用 LINQ 來查詢任何可枚舉的集合,例如 List < T >、數組或 Dictionary < TKey , TValue >。該集合可以是用户自定義的,也可以是通過 .NET API 返回的類型。在 LINQ 方法中,您編寫描述您想要檢索內容的聲明性代碼。對象型 LINQ 提供了使用 LINQ 編程的絕佳入門指南。
LINQ 查詢相較於傳統的 foreach 循環具有三大優勢:
- 它們更加簡潔易讀,尤其是在處理多個條件時更是如此。
- 它們具備強大的篩選、排序和分組功能,並且所需的應用代碼量極少或幾乎無需修改。
- 它們可以輕鬆地移植到其他數據源,無需進行大量修改。
您要對數據執行的操作越複雜,使用 LINQ 而非傳統迭代技術所帶來的好處就越多。
將查詢的結果存儲在內存中
查詢本質上是一組用於檢索和組織數據的指令。查詢是按需執行的,每次請求結果中的下一個項時才會執行一次。當您使用 “foreach” 來遍歷結果時,會按照訪問順序返回項。若要評估查詢並存儲其結果而無需執行 “foreach” 循環,請直接對查詢變量調用以下任一方法:
- ToList
- ToArray
- ToDictionary
- ToLookup
在存儲查詢結果時,您應該將返回的集合對象賦值給一個新的變量,如以下示例所示:
List < int > Zhss = [ 1 , 2 , 4 , 6 , 8 , 10 , 12 , 14 , 16 , 18 , 20 ];
IEnumerable < int > Z整除4 = from z in Zhss
where z % 4 == 0
select z;
var LB整除4 = Z整除4 . ToList ( );
Console . WriteLine ( $"LB整除4 [ 2 ]:{LB整除4 [ 2 ]}" ); // 12
LB整除4 [ 2 ] = 0;
Console . WriteLine ( $"LB整除4 [ 2 ]:{LB整除4 [ 2 ]}" ); // 0查詢表達式基礎
本文介紹了 C# 中與查詢表達式相關的基本概念。
什麼是查詢以及它有何作用?
查詢是一組指令,用於描述從給定的數據源(或多個數據源)中檢索哪些數據,以及返回的數據應具有何種形式和組織結構。查詢與它所產生的結果是不同的。
通常,源數據在邏輯上是相同類型元素的序列。例如,SQL 數據庫表包含一系列行。在 XML 文件中,存在一系列 XML 元素(儘管 XML 元素是以樹形結構分層組織的)。內存中的集合包含一系列對象。
從應用程序的角度來看,原始源數據的具體類型和結構並不重要。應用程序始終將源數據視為 IEnumerable < T > 或 IQueryable < T > 集合。例如,在 LINQ to XML 中,源數據以 IEnumerable < XElement > 的形式呈現。
對於此源序列,查詢可能會執行以下三種操作之一:
-
檢索元素子集以生成新序列,而不修改各個元素。然後,查詢可能會以各種方式對返回的序列進行排序或分組,如下例所示(假設 FSs 是一個 double 類型數組):
double [ ] FSs = [ 96 , 98.5 , 85 , 63 , 77.5 , 94.5 , 100 , 92 ]; IEnumerable < double > GY95 = from f in FSs where f > 95 orderby f descending select f; foreach ( double f in GY95 ) { Console . WriteLine ( f ); // 100,98.5,96 } -
檢索一組元素,就像前面的示例那樣,但將其轉換為一種新的對象類型。例如,查詢可能僅從數據源中的某些客户記錄中檢索姓氏。或者它可能檢索完整的記錄,然後使用它來構建另一種內存中的對象類型,甚至是 XML 數據,然後再生成最終的結果序列。下面的示例展示了從 double 到 string 的投影。請注意 GY95 的新類型。
double [ ] FSs = [ 96 , 98.5 , 85 , 63 , 77.5 , 94.5 , 100 , 92 ]; IEnumerable < string > GY95 = from f in FSs where f > 95 orderby f descending select $"高分有:{f}"; foreach ( string f in GY95 ) { Console . WriteLine ( f ); // 100,98.5,96 } -
檢索有關源數據的單個值,例如:
- 滿足特定條件的元素數量。
- 具有最大或最小值的元素。
-
第一個符合某個條件的元素,或者指定元素集合中特定值的總和。例如,以下查詢返回分數 double 數組中大於 80 的分數數量:
double [ ] FSs = [ 96 , 98.5 , 85 , 63 , 77.5 , 94.5 , 100 , 92 ]; int GY80s = ( from f in FSs where f > 80 select f ) . Count ( ); Console . WriteLine ( GY80s ); // 6在上一個示例中,請注意在調用 Enumerable . Count 方法之前,查詢表達式周圍使用了括號。您還可以使用一個新的變量來存儲具體的結果。
double [ ] FSs = [ 96 , 98.5 , 85 , 63 , 77.5 , 94.5 , 100 , 92 ]; IEnumerable < double > GY80 = from f in FSs where f > 80 select f; int GS = GY80 . Count ( ); Console . WriteLine ( GS ); // 6在上一個示例中,查詢是在調用 Count 時執行的,因為 Count 必須遍歷結果集,以便確定 GY80s 所返回元素的數量。
什麼是查詢表達式?
查詢表達式是以查詢語法形式表達的查詢。查詢表達式是一種一等語言結構。它就像任何其他表達式一樣,可以在任何允許使用 C# 表達式的上下文中使用。查詢表達式由一組以類似於 SQL 或 XQuery 的聲明式語法編寫的子句組成。每個子句又包含一個或多個 C# 表達式,而這些表達式本身可能也是查詢表達式,或者包含一個查詢表達式。
查詢表達式必須以 “from” 子句開頭,並以 “select” 或 “group” 子句結尾。在第一個 “from” 子句與最後一個 “select” 或 “group” 子句之間,可以包含以下這些可選子句中的一個或多個:where、orderby、join、let 以及甚至另一個 “from” 子句。您還可以使用 “into” 關鍵字來使連接或分組子句的結果能夠作為同一查詢表達式中更多查詢子句的源。
查詢變量
在 LINQ 中,查詢變量是指任何用於存儲查詢結果而非查詢結果本身的數據變量。更確切地説,查詢變量始終是可枚舉類型,當在 foreach 語句中進行迭代或直接調用其 IEnumerator . MoveNext ( ) 方法時,會生成一系列元素。
注意:本文中的示例所使用的數據源及樣本數據如下所示。
record JL城市 ( string 城市名 , int 百萬人 , int 等級 );
record JL省份 ( string 省份名 , int 百萬人 , JL城市 省會 , JL城市 [ ] 重要城市 );
record JL自治區 ( string 自治區名 , int 百萬人 , JL城市 首府 , JL城市 [ ] 重要城市 );
record JL國家 ( string 國名 , int 百萬人 , JL城市 首都 , JL城市 [ ] 重要城市 );
static readonly JL城市 BJ = new ( "北京" , 20 , 0 );
static readonly JL城市 TJ = new ( "天津" , 13 , 0 );
static readonly JL城市 SHH = new ( "上海" , 27 , 0 );
static readonly JL城市 CHQ = new ( "重慶" , 13 , 0 );
static readonly JL城市 JN = new ( "濟南" , 7 , 1 );
static readonly JL省份 SD = new ( "山東" , 125 , JN , [ new JL城市 ( "青島" , 8 , 1 ) , new JL城市 ( "淄博" , 8 , 2 ) ] );
static readonly JL城市 SHJZH = new ( "石家莊" , 6 , 1 );
static readonly JL省份 HB = new ( "河北" , 105 , SHJZH , [ new JL城市 ( "滄州" , 3 , 2 ) , new JL城市 ( "承德" , 3 , 2 ) ] );
static readonly JL城市 HHHT = new ( "呼和浩特" , 8 , 1 );
static readonly JL自治區 NMG = new ( "內蒙古" , 35 , HHHT , [ new JL城市 ( "包頭" , 3 , 2 ) , new JL城市 ( "赤峯" , 2 , 2 ) ] );
static readonly JL國家 China = new ( "中國" , 1456 , BJ , CSs );
static readonly JL城市 [ ] CSs = [
BJ,
TJ,
SHH,
CHQ,
];
static readonly JL國家 [ ] GJs = [
China,
new JL國家 ( "俄羅斯" , 253 , new JL城市 ( "莫斯科" , 8 , 0 ) , [ new JL城市 ( "伏爾加格勒" , 6 , 1 ) , new JL城市 ( "聖彼得堡" , 7 , 1 ) ] ),
new JL國家 ( "蒙古" , 8 , new JL城市 ( "烏蘭巴托" , 1 , 0 ) , [ ] ),
new JL國家 ( "朝鮮" , 35 , new JL城市 ( "平壤" , 6 , 0 ) , [ new JL城市 ( "開城" , 4 , 1 ) ] ),
new JL國家 ( "韓國" , 45 , new JL城市 ( "首爾" , 6 , 0 ) , [ new JL城市 ( "漢城" , 4 , 1 ) ] ),
];以下代碼示例展示了一個簡單的查詢表達式,其中包含一個數據源、一個篩選條件、一個排序條件以及對源元素的無任何轉換操作。select 子句標誌着查詢的結束。
// LINQ 查詢的三個部分:
// 1. 數據源
int [ ] zhss = [ 1, 2, 3, 4, 5, 6 , 8 , 10 ];
// 2. 建立查詢
var zhs查詢 = // 查詢變量
from zh in zhss // 返回值
where ( zh % 2 ) == 0 // 可選的,返回值的條件
orderby zh descending // 可選的,默認不排序,可選從小到大或從大到小
select zh; // 必須以 select 或 group 結尾
// 3. 執行查詢
foreach ( int z in zhs查詢 )
{
Console . Write ( $"{ z , 1 }," );
}
Console . WriteLine ( );在上一個示例中,zh 是一個查詢變量,有時也簡稱為 “查詢”。該查詢變量並不存儲實際的結果數據,這些數據是在 foreach 循環中生成的。當 foreach 語句執行時,查詢結果不會通過查詢變量 zh 返回,而是通過迭代變量 z 返回。zh 變量可以在第二個 foreach 循環中進行迭代。只要它(即該變量)或者數據源沒有被修改,就會產生相同的結果。
查詢變量可以存儲以查詢語法或方法語法表達的查詢內容,或者這兩種語法的組合形式。在以下示例中,CHX大城市 和 CHX大城市2 都是查詢變量(四個直轄市中人口大於兩千萬的):
IEnumerable < JL城市 > CHX大城市 =
from c in CSs
where c .百萬人 >= 20
select c;
foreach ( JL城市 c in CHX大城市 )
{
Console.WriteLine ( c );
}
IEnumerable < JL城市 > CHX大城市2 = CSs . Where ( c => c . 百萬人 >= 20 );
foreach ( JL城市 c in CHX大城市2 )
{
Console . WriteLine ( c );
}另一方面,以下兩個例子展示了並非查詢變量的變量,儘管每個變量都是通過查詢進行初始化的。它們不是查詢變量,是因為它們存儲的是結果:
double [ ] FSs = [ 105 , 106.5 , 119 , 94 , 88 , 96 , 84.5 , 82.5 , 77 , 104 ];
var GF = ( from f in FSs
select f ) . Max ( );
Console . WriteLine ( GF ); // 119
IEnumerable < double > FS =
from f in FSs
select f;
var GF2 = FS . Max ( );
Console . WriteLine ( GF2 ); // 119
double GF3 = FSs . Max ( );
Console . WriteLine ( GF3 ); // 119var DCSs = (
from G in GJs
from C in G . 重要城市
where C . 百萬人 > 5 & C . 等級 == 0
select C
) . ToList ( );
Console . WriteLine ( "大城市:" );
foreach ( var DCS in DCSs )
{
Console . WriteLine ( DCS );
}
IEnumerable < JL城市 > DCSs2 =
from G in GJs
from C in G .重要城市
where C . 百萬人 > 5
select C;
var LB大城市 = DCSs2 . ToList ( );
Console . WriteLine ( "大城市2:" );
foreach ( var DCS in DCSs2 )
{
Console . WriteLine ( DCS );
}查詢變量的顯式和隱式類型
此文檔通常會提供查詢變量的顯式類型,以展示查詢變量與選擇子句之間的類型關係。然而,您也可以使用 var 關鍵字來指示編譯器在編譯時推斷查詢變量(或任何其他局部變量)的類型。例如,本文前面展示的查詢示例也可以通過使用隱式類型來表達:
var DCSs = from G in GJs
from C in G . 重要城市
where C . 百萬人 > 5 & C . 等級 == 0
select C;在上述示例中,使用 “var” 是可選的。“DCSs” 是一個 “IEnumerable < JL城市 >” 類型,無論其是隱式類型還是顯式類型。
開始查詢表達式
查詢表達式必須以 “from” 子句開頭。它會指定一個數據源以及一個範圍變量。該範圍變量在遍歷數據源時代表源序列中的每個後續元素。範圍變量的類型是根據數據源中元素的類型來確定的。在以下示例中,因為 “GJs” 是一個 JL國家 對象的數組,所以範圍變量也被指定為 JL國家 類型。由於範圍變量是強類型的,您可以使用點運算符來訪問該類型中的任何可用成員。
IEnumerable < JL城市 > CHX大城市 =
from c in CSs
where c . 百萬人 >= 20
select c;
foreach ( JL城市 c in CHX大城市 )
{
Console . WriteLine ( c );
}範圍變量在作用域內一直有效,直到查詢以分號結束或者使用延續子句結束為止。
查詢表達式可能包含多個 “from” 子句。當源序列中的每個元素本身就是一個集合或者包含一個集合時,應使用更多的 “from” 子句。例如,假設您有一個 JL國家 對象的集合,每個 JL國家 對象都包含一個名為 重要城市 的 JL城市 對象集合。要查詢每個 JL國家 中的 JL城市 對象,可以使用如下的兩個 “from” 子句:
IEnumerable < JL城市 > CHX城市 =
from G in GJs
from C in G . 重要城市
where C . 百萬人 > 10
select C;結束查詢表達式
查詢表達式必須以 group 子句或 select 子句結尾。
group 子句
使用 group 子句來生成由您指定的鍵組織的組序列。鍵可以是任何數據類型。例如,以下查詢創建了一個組序列,其中包含一個或多個 JL國家 對象,其鍵為 char 類型,值為國家名稱的首字符。
var CHX國家組 = from g in GJs
orderby g . 國名 [ 0 ]
group g by g . 國名 [ 0 ];
foreach ( var g in CHX國家組 )
Console . WriteLine ( g . Key );select 子句
使用 select 子句來生成所有其他類型的序列。簡單的 select 子句只是生成與數據源中包含的對象類型相同的對象序列。在此示例中,數據源包含 JL國家 對象。orderby 子句只是將元素排序為新的順序,而 select 子句生成重新排序後的 JL國家 對象序列。
var CHX人口 =
from g in GJs
orderby g . 百萬人
select g;
foreach ( var g in CHX人口 )
Console . WriteLine ( g . 國名 );select 子句可用於將源數據轉換為新類型的序列。這種轉換也稱為投影。在下面的示例中,select 子句投影出一個匿名類型的序列,其中僅包含原始元素中字段的一個子集。新對象通過使用對象初始化器進行初始化。
var CHX人口 =
from g in GJs
orderby g . 百萬人
select new
{
m = g . 國名,
r = g . 百萬人,
};
foreach ( var g in CHX人口 )
Console . WriteLine ( $"{g . m} => {g . r}" );因此在這一例子中,需要使用 “var” 關鍵字,因為該查詢會生成一個匿名類型。
使用 “into” 關鍵字
在 “select” 或 “group” 子句中可以使用 “into” 關鍵字來創建一個臨時標識符,用於存儲查詢結果。當您必須在 group 或 select 操作之後對查詢執行額外的操作時,請使用 “into” 子句。在以下示例中,根據人口數量將國家按 1000 萬的範圍進行分組。在創建這些組之後,會執行更多子句來過濾某些組,然後對這些組進行升序排序。要執行這些額外操作,則需要由 “GJz” 表示的延續。
var CHXDY1億 =
from g in GJs
let Yi = ( double ) g . 百萬人 / 100
group g by Yi into GJz
where GJz . Key >= 1
orderby GJz . Key
select GJz;
foreach ( var z in CHXDY1億 )
{
Console . WriteLine ( $"{z . Key}" );
foreach ( var g in z )
{
Console . WriteLine ( $"{g . 國名}:{g . 百萬人}" );
}
}篩選、排序和連接
在 from 子句與結束的 select 或 group 子句之間,其餘所有子句(如 where、join、orderby、from、let)都是可選的。在查詢主體中,這些可選子句可以零次使用,也可以多次使用。
where 子句
使用 where 子句可以根據一個或多個謂詞表達式從源數據中篩選出元素。以下示例中的 where 子句包含一個謂詞,該謂詞包含兩個條件。
IEnumerable < JL城市 > JDCSs =
from G in GJs
from C in G . 重要城市
where C . 百萬人 is > 5 and < 10
select C;orderby 子句
使用 orderby 子句按升序或降序對結果進行排序。您還可以指定次要排序順序。以下示例首先按 JL國家 對象的 國名 屬性進行主要排序(正序),然後按 百萬人 屬性進行次要排序(倒序)。
var CHX國家 =
from g in GJs
orderby g . 國名 , g . 百萬人 descending
select g;ascending 關鍵字是可選的;如果未指定排序順序則默認為升序排序。
join 子句
使用 join 子句根據每個元素中指定鍵之間的相等性比較,將一個數據源中的元素與另一個數據源中的元素關聯和/或組合。在 LINQ 中,join 操作是在元素類型不同的對象序列上執行的。連接兩個序列後,必須使用 select 或 group 語句指定要存儲在輸出序列中的元素。還可以使用匿名類型將每個關聯元素集中的屬性組合成輸出序列的新類型。以下示例將 prod 對象與 categories 字符串數組中的類別之一匹配的 Category 屬性關聯起來。不匹配 categories 中任何字符串的 prod 對象將被過濾掉。select 語句投影出一個新類型,其屬性取自 cat 和 prod。
var CHX類別 =
from LX in LXs
join CHP in CHPs on LX equals CHP . 類別
select new
{
類別 = LX,
名稱 = CHP . 名稱
};您還可以通過使用“into”關鍵字將連接操作的結果存儲到一個臨時變量中來執行分組連接。
let 子句
使用 “let” 子句可以將表達式(例如方法調用)的結果存儲在一個新的範圍變量中。在以下示例中,範圍變量 “姓” 存儲了由 “Split” 方法返回的字符串數組中的第一個元素。
string [ ] MZs = [ "Svetlana Omelchenko" , "Claire O'Donnell" , "Sven Mortensen" , "Cesar Garcia" ];
IEnumerable < string > CHX姓 =
from XM in MZs
let 姓 = XM . Split ( ' ' ) [ 0 ]
select 姓;
foreach ( var x in CHX姓 )
{
Console . Write ( x + " " );
}查詢表達式中的子查詢
在查詢語句中,某個查詢子句本身可能包含一個查詢表達式,這種表達式有時被稱為子查詢。每個子查詢都以自己的 “from” 子句開頭,而這些 “from” 子句所指向的數據源不一定與第一個 “from” 子句所指向的完全相同。例如,以下查詢展示了在 “select” 語句中使用的查詢表達式,該表達式用於執行分組操作以獲取結果。
var CHX省 =
from s in Ss
group s by s . 百萬人 into Zs
select new
{
總人口 = Zs . Key,
省會人口 = (
from s2 in Zs
select s2 . 省會 . 百萬人 ) . Max ( )
};編寫 C# LINQ 查詢以查詢數據
在介紹性的語言集成查詢(LINQ)文檔中,大多數查詢都是使用 LINQ 聲明式查詢語法編寫的。C# 編譯器會將查詢語法轉換為方法調用。這些方法調用實現了標準查詢運算符,其名稱包括 Where、Select、GroupBy、Join、Max 和 Average 等。您也可以直接使用方法語法而不是查詢語法來調用它們。
查詢語法和方法語法在語義上是相同的,但查詢語法通常更簡單且更易於閲讀。有些查詢必須以方法調用的形式表達。例如,要獲取滿足指定條件的元素數量,必須使用方法調用。要獲取源序列中具有最大值的元素,也必須使用方法調用。System . Linq 命名空間中標準查詢運算符的參考文檔通常使用方法語法。您應該熟悉如何在查詢和查詢表達式本身中使用方法語法。
標準查詢運算符擴展方法
以下示例展示了一個簡單的查詢表達式以及語義上等效的基於方法的查詢。
int [ ] numbers = [ 5 , 10 , 8 , 3 , 6 , 12 ];
// 查詢語法:
IEnumerable < int > CHX1 =
from n in numbers
where n % 2 == 0
orderby n
select n;
// 方法語法:
IEnumerable < int > CHX2 = numbers
.Where ( n => n % 2 == 0)
.OrderBy ( n => n );
foreach ( int z in CHX1 )
{
Console . Write ( i + " " );
}
Console . WriteLine ( System . Environment . NewLine );
foreach ( int z in CHX2 )
{
Console . Write ( i + " " );
}這兩個示例的輸出完全相同。兩種形式中查詢變量的類型都是:IEnumerable < T >。
在表達式的右側,請注意 where 子句現在被表示為 numbers 對象的一個實例方法,該對象的類型為 IEnumerable < int >。如果您熟悉泛型的 IEnumerable < T > 接口,您會知道它並沒有 Where 方法。然而,如果您在 Visual Studio 集成開發環境(IDE)中調用 IntelliSense 完成列表,您不僅會看到 Where 方法,還會看到許多其他方法,例如 Select、SelectMany、Join 和 OrderBy。這些方法實現了標準查詢運算符。
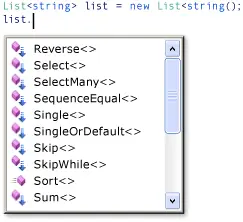
儘管看起來 IEnumerable < T > 包含了更多的方法,但實際上並非如此。標準查詢運算符是作為擴展方法實現的。擴展方法 “擴展” 了現有類型;它們可以像實例方法一樣在該類型上調用。標準查詢運算符擴展了 IEnumerable < T >,這就是為什麼您可以編寫 numbers . Where ( … ) 的原因。在調用擴展方法之前,您需要使用 using 指令將其引入作用域。
某些 LINQ 提供程序(例如 Entity Framework 和 LINQ to XML)為除 IEnumerable < T > 之外的其他類型實現了自己的標準查詢運算符和擴展方法。
Lambda 表達式
在前面的示例中,條件表達式 ( n % 2 == 0 ) 作為內聯參數傳遞給 Enumerable . Where 方法:Where ( n => n % 2 == 0 )。此內聯表達式是一個 lambda 表達式。這是一種方便的編寫代碼的方式,否則必須以更繁瑣的形式編寫。操作符左側的 n 是輸入變量,它對應於查詢表達式中的 n。編譯器可以推斷出 n 的類型,因為它知道 numbers 是泛型 IEnumerable < T > 類型。lambda 表達式的主體與查詢語法中的表達式或任何其他 C# 表達式或語句中的表達式相同。它可以包含方法調用和其他複雜邏輯。返回值是表達式的結果。某些查詢只能用方法語法來表達,其中一些查詢需要 lambda 表達式。Lambda 表達式是您 LINQ 工具箱中強大且靈活的工具。
查詢的可組合性
在前面的代碼示例中,通過在對 Where 的調用上使用點運算符來調用 Enumerable . OrderBy 方法。Where 生成一個經過篩選的序列,然後 OrderBy 對 Where 生成的序列進行排序。由於查詢返回一個 IEnumerable,因此您可以通過將方法調用鏈接在一起以方法語法組合它們。當您使用查詢語法編寫查詢時,編譯器會執行此組合操作。由於查詢變量不會存儲查詢的結果,因此您可以在任何時候對其進行修改或將其用作新查詢的基礎,甚至在執行查詢之後也是如此。
以下示例通過使用前面列出的每種方法演示了一些基本的 LINQ 查詢。
注意:這些查詢操作的是內存中的集合;不過,其語法與在 LINQ to Entities 和 LINQ to XML 中使用的語法完全相同。
示例 - 查詢語法
您通常使用查詢語法編寫查詢以創建查詢表達式。以下示例展示了三個查詢表達式。第一個查詢表達式演示瞭如何通過使用 where 子句應用條件來篩選或限制結果。它返回源序列中所有值大於 7 或小於 3 的元素。第二個表達式演示瞭如何對返回的結果進行排序。第三個表達式演示瞭如何根據鍵對結果進行分組。此查詢根據單詞的首字母返回兩個組。
List < int > ZHSs = [ 5 , 4 , 1 , 3 , 9 , 8 , 6 , 7 , 2 , 0 ];
IEnumerable < int > CHX過濾 =
from z in ZHSs
where z is > 7 or < 3
select z;
foreach ( int z in CHX過濾 )
Console . WriteLine ( z ); // 1,9,8,2,0List < int > ZHSs = [ 5 , 4 , 1 , 3 , 9 , 8 , 6 , 7 , 2 , 0 ];
IEnumerable < int > CHX排序 =
from z in ZHSs
where z is > 7 or < 3
orderby z ascending
select z;
foreach ( int z in CHX排序 )
Console . WriteLine ( z ); // 0,1,2,8,9string [ ] CXs = [ "carrots" , "cabbage" , "broccoli" , "beans" , "barley" ];
IEnumerable < IGrouping < char , string > > CHXz =
from x in CXs
group x by x [ 0 ];
foreach ( var x in CHXz )
{
Console . WriteLine ( x . Key );
foreach ( var y in x )
{
Console . WriteLine ( y );
}
}這些查詢的類型為 IEnumerable < T >。所有這些查詢都可以使用 var 來編寫,如下例所示:
var CHX = from n in numbers……
在之前的每一個示例中,只有在您在 foreach 語句或其他語句中對查詢變量進行迭代操作時,這些查詢才會真正執行。
示例 - 方法語法
某些查詢操作必須以方法調用的形式來表達。這類最常見的方法是那些返回單個數值的方法,例如 Sum(求和)、Max(最大值)、Min(最小值)、Average(平均值)等等。在任何查詢中,這些方法都必須始終放在最後進行調用,因為它們會返回一個單一的值,不能作為後續查詢操作的依據。以下示例展示了查詢表達式中的方法調用:
List < int > ZHS1 = [ 5, 4, 1, 3, 9, 8, 6, 7, 2, 0 ];
List < int > ZHS2 = [ 15, 14, 11, 13, 19, 18, 16, 17, 12, 10 ];
// 查詢 #4
double pj = ZHS1 . Average ( );
Console . WriteLine ( pj );
// 查詢 #5
IEnumerable < int > CHX串聯 = ZHS1 . Concat ( ZHS2 );
foreach ( var z in CHX串聯 )
Console . WriteLine ( z );如果該方法具有 System . Action 或 System . Func < TResult > 類型的參數,那麼這些參數將以 lambda 表達式的形式進行傳遞,如下例所示:
// 查詢 #6
IEnumerable < int > CHX較大 = ZHS2 . Where ( n => n > 15 );
foreach ( var z in CHX較大 )
Console . WriteLine ( z );在之前的查詢中,只有查詢 #4 能立即執行,因為它的返回值是一個單一的值,而非通用的 IEnumerable < T > 集合。該方法本身使用 foreach 或類似的代碼來計算其值。
之前的每個查詢都可以通過使用 var 進行隱式類型定義來編寫,如下面的示例所示:
var pj = ZHS1 . Average ( );
var CHX串聯 = ZHS1 . Concat ( ZHS2 );
var CHX較大 = ZHS2 . Where ( n => n > 15 );示例 - 混合查詢與方法語法
此示例展示瞭如何在查詢子句的結果上使用方法語法。只需將查詢表達式括在括號內,然後應用點運算符並調用該方法即可。在以下示例中,查詢 #7 返回值在 3 到 7 之間的數字的數量。
// 查詢 #7
var CHX個數1 =
( from z in ZHS1
where z is > 3 and < 7
select z ) . Count ( );
IEnumerable < int > CHX個數2 =
from z in ZHS1
where z is > 3 and < 7
select z;
int gs = CHX個數2 . Count ( );
Console . WriteLine ( $"{CHX個數1} 和 {gs}" );因為 查詢 #7 返回的是單個值而非一組值,所以該查詢會立即執行。
之前的查詢可以通過使用帶有 “var” 的隱式類型來編寫,具體如下:
var gs = ( from z in ZHS1……
它可以以方法語法的形式寫成如下這樣:
var gs = ZHS1 . Count ( n => n is > 3 and < 7 );
它可以通過使用顯式類型定義來編寫,具體如下:
int gs = ZHS1 . Count ( n => n is > 3 and < 7 );
在運行時動態指定謂詞過濾器
在某些情況下,直到運行時您才確定在 where 子句中需要應用多少個謂詞。一種動態指定多個謂詞過濾器的方法是使用 Contains 方法,如以下示例所示。當執行查詢時,根據 id 的值,該查詢會返回不同的結果。
public record JL學生 ( int ID , string 姓名 );
JL學生 [ ] XSs = // 學生的列表
[
new JL學生 ( 111 , "李玉寧" ),
new JL學生 ( 114 , "王菲" ),
new JL學生 ( 112 , "張小青" ),
new JL學生 ( 122 , "田豐收" ),
new JL學生 ( 117 , "馬思文" ),
new JL學生 ( 120 , "吳小蘭" ),
new JL學生 ( 115 , "胡建梅" ),
];
int [ ] ids;
ids = [ 111 , 114 , 112 ]; // 這三個學號
var CHX姓名 = from xs in XSs
where ids . Contains ( xs . ID )
select new
{
xs . 姓名,
xs . ID,
};
foreach ( var n in CHX姓名 )
Console . WriteLine ( $"{n . 姓名}:{n . ID}" );
Console . WriteLine ( );
ids = [ 122 , 117 , 120 , 115 ]; // 這四個學號
foreach ( var n in CHX姓名 )
Console . WriteLine ( $"{n . 姓名}:{n . ID}" );您可以使用控制流語句(如 if … else 或 switch)來從預先設定的備選查詢中進行選擇。在以下示例中,CHX學生 根據運行時 年齡 的值(為真或為假)使用不同的 where 子句,確定學生幾年級。
JL學生 [ ] XSs = // 學生的列表
[
new JL學生 ( 111 , "李玉寧" , new ( 2018 , 3 , 16 ) ),
new JL學生 ( 114 , "王菲" , new ( 2013 , 3 , 8 ) ),
new JL學生 ( 112 , "張小青" , new ( 2018 , 7 , 1 ) ),
new JL學生 ( 122 , "田豐收" , new ( 2018 , 12 , 10 ) ),
new JL學生 ( 117 , "馬思文" , new ( 2016 , 2 , 22 ) ),
new JL學生 ( 120 , "吳小蘭" , new ( 2017 , 10 , 16 ) ),
new JL學生 ( 115 , "胡建梅" , new ( 2017 , 6 , 6 ) ),
];
bool BER偶數年級 = true;
IEnumerable < JL學生 > CHX學生 = BER偶數年級
? (from xs in XSs
where FF等級 ( xs ) is 2 or 4 or 6
select xs)
: (from xs in XSs
where FF等級 ( xs ) is 1 or 3 or 5
select xs);
var sm = BER偶數年級 ? "是" : "不是";
Console . WriteLine ( $"下列學生今年{sm}偶數年級:" );
foreach ( var xs in CHX學生 )
{
Console.WriteLine ( $"{xs . ID}:{xs .姓名}" );
}
static int FF等級 ( JL學生 學生 )
{
if ( DateTime . Now . Year - 學生 . 生日 . Year == 7 )
return 1;
if ( DateTime . Now . Year - 學生 . 生日 . Year == 8 )
return 2;
if ( DateTime . Now . Year - 學生 . 生日 . Year == 9 )
return 3;
if ( DateTime . Now . Year - 學生 . 生日 . Year == 10 )
return 4;
if ( DateTime . Now . Year - 學生 . 生日 . Year == 11 )
return 5;
return 6;
}處理查詢表達式中的 null 值
此示例展示瞭如何處理源集合中可能出現的 null 值。例如,像 IEnumerable < T > 這樣的對象集合可能包含值為 null 的元素。如果源集合為 null 或包含值為 null 的元素,並且您的查詢未處理 null 值,那麼在執行查詢時就會拋出 NullReferenceException 錯誤。
以下示例使用了這些類型以及 static 數據數組:
類別? [ ] LBs =
[
new ( "大衣" , 1 ),
null,
new ( "短大衣" , 2 ),
default,
new ( "棉襖" , 3 ),
];
產品? [ ] CHPs =
[
new ( "紅唐裝" , 3 ),
new ( "黃唐裝" , 3 ),
new ( "綠唐裝" , 3 ),
null,
new ( "褐色大衣" , 2 ),
new ( "紅大衣" , 2 ),
null,
new ( "白大衣" , 1 ),
new ( "黃大衣" , 1 ),
];
var CHX1 = from l in LBs
where l != null
join c in CHPs on l . ID equals c? . 類別ID
select new
{
類別 = l . 類別名,
c . 產品名,
};
foreach ( var c in CHX1 )
{
Console . WriteLine ( c ); // 類似 { 類別 = 大衣, 產品名 = 白大衣 }
}
record 產品 ( string 產品名 , int 類別ID );
record 類別 ( string 類別名 , int ID );在上一個示例中,where 子句會過濾掉 類別 序列中的所有 null 值元素。此技術與連接子句中的 null 值檢查無關。在本示例中帶有 null 值的條件表達式能夠正常工作,是因為 c . leibieID 的類型為 int?,這是一種簡寫形式,表示 Nullable < int >。
在 join 子句中,如果比較鍵中只有一個為可為 null 值類型,則可以在查詢表達式中將另一個鍵轉換為可為 null 值類型。在以下示例中,假設 “ID僱員” 是一個包含 int? 類型值的列。
var CHX =
from d in db . 訂單
join g in db . 僱員
on d . ID僱員 equals ( int? ) e . ID僱員
select new { d . ID訂單 , g . 姓 };在每個示例中,都使用了 “equals” 查詢關鍵字。您還可以使用模式匹配,其中包括 “is null” 和 “is not null” 的模式。在 LINQ 查詢中,這些模式並不推薦使用,因為查詢提供者可能無法正確解讀新的 C# 語法。查詢提供者是一個將 C# 查詢表達式轉換為原生數據格式(例如 Entity Framework Core)的庫。查詢提供者實現 System . Linq . IQueryProvider 接口,以創建實現 System . Linq . IQueryable < T > 接口的數據源。
處理查詢表達式中的異常
在查詢表達式中調用任何方法都是可行的。但不要在查詢表達式中調用任何可能產生副作用(如修改數據源的內容或拋出異常)的方法。此示例展示瞭如何在調用查詢表達式中的方法時避免引發異常,同時又不違反 .NET 關於異常處理的一般準則。這些準則指出,當您瞭解在特定上下文中拋出異常的原因時,捕獲特定異常是可接受的。
最後一個例子展示了在執行查詢過程中必須拋出異常時應如何處理相關情況。
以下示例展示瞭如何將異常處理代碼從查詢表達式中分離出來。這種重構操作僅在該方法不依賴於查詢中局部變量的情況下可行。將異常處理放在查詢表達式之外會更便於處理。
// 這是一個極有可能引發異常的數據源!
IEnumerable < int > FF獲取數據 ( ) => throw new InvalidOperationException ( );
// 在使用可能會拋出異常的數據源時,請務必執行此操作。
IEnumerable < int >? DT源 = null;
try
{
DT源 = FF獲取數據 ( );
}
catch ( InvalidOperationException )
{
Console . WriteLine ( "無效操作" );
}
if ( DT源 is not null )
{
// 如果我們到達這裏,就可以放心繼續前行了。
var CHX = from i in DT源
select i * i;
foreach (var i in query)
{
Console . WriteLine ( i . ToString ( ) );
}
}在上述示例中的 “catch ( InvalidOperationException )” 塊中,應根據您的應用程序的實際情況來處理(或不處理)該異常。
在某些情況下,對於在查詢內部拋出的異常,最佳的應對方式可能是立即停止查詢執行。下面的示例展示瞭如何處理可能在查詢主體內部拋出的異常。假設 FF可能異常 可能會引發導致查詢執行停止的異常。
try 塊包含的是 foreach 循環,而非查詢本身。foreach 循環是執行查詢的地方。當執行查詢時會拋出運行時異常。因此,這些異常必須在 foreach 循環中進行處理。
// 作為一種通用方法來説,它並不是特別有用
string FF可能異常 ( string s ) =>
s[4] == 'C' ?
throw new InvalidOperationException ( ) :
$"""C:\newFolder\{s}""";
// 數據源
string [ ] WJs = [ "fileA.txt" , "fileB.txt" , "fileC.txt" ];
// 演示查詢出現錯誤
var CHX異常 = from WJ in WJs
let n = FF可能異常 ( WJ )
select n;
try
{
foreach ( var XM in CHX異常 )
{
Console . WriteLine ( $"處理 {XM}" );
}
}
catch ( InvalidOperationException YCH )
{
Console . WriteLine ( YCH . Message );
}
/* 輸出:
處理 C:\newFolder\fileA.txt
處理 C:\newFolder\fileB.txt
由於對象當前的狀態,操作無效。
*/請務必在 “finally” 塊中捕獲您預期會引發的任何異常,並執行任何必要的清理工作。
在 LINQ 查詢操作中的類型關係(C#)
要有效地編寫查詢,您應當瞭解完整查詢操作中變量的類型之間的相互關係。如果您理解了這些關係,您將更容易理解文檔中的 LINQ 示例和代碼示例。此外,您還將明白使用 var 顯式指定類型時會發生什麼情況。
LINQ 查詢操作在數據源、查詢本身以及查詢執行過程中都是強類型的。查詢中的變量類型必須與數據源中的元素類型以及 foreach 語句中的迭代變量類型相兼容。這種強類型機制確保在編譯時就能發現類型錯誤,從而在用户遇到這些錯誤之前就能進行修正。
為了展示這些類型關係,接下來的大多數示例都將所有變量都進行了明確的類型標註。最後一個示例展示了即使使用隱式類型(通過使用 “var” 關鍵字)時,同樣的原則也依然適用。
不改變源數據的查詢
以下示例展示了一個 “LINQ 到 object” 查詢操作,該操作對數據不做任何處理。源數據包含一系列字符串,而查詢結果也是字符串序列。
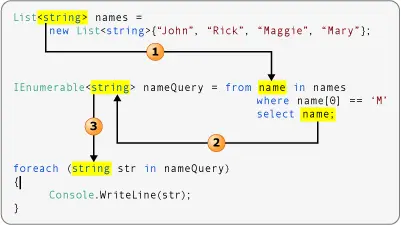
- 數據源的類型參數決定了範圍變量的類型。
- 所選對象的類型決定了查詢變量的類型。這裏 “name” 是一個字符串。因此,查詢變量是一個 IEnumerable < string >。
- 在 foreach 語句中,會遍歷查詢變量。因為查詢變量是一個字符串序列,所以迭代變量也是一個字符串。
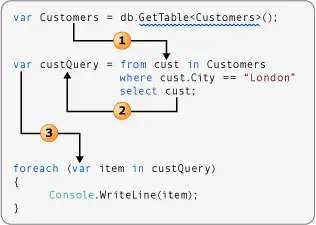
轉換源數據的查詢
以下圖示展示了一個 LINQ to SQL 查詢操作,它對數據進行了一種簡單的轉換。該查詢接受一個 Customer 對象序列作為輸入,並僅在結果中選擇 Name 屬性。因為 Name 是一個字符串,所以查詢生成一個字符串序列作為輸出。
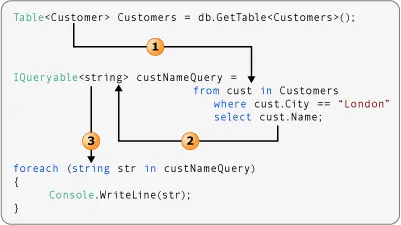
- 數據源的類型參數決定了範圍變量的類型。
- 選擇語句返回的是 “Name” 屬性,而非完整的 “Customer” 對象。因為 “Name” 是一個字符串,所以 “custNameQuery” 的類型參數應為 “string”,而非 “Customer”。
- 因為 “custNameQuery” 是一個字符串序列,所以 foreach 循環的迭代變量也必須是字符串。
以下示例展示了一個稍微複雜一些的轉換過程。選擇語句返回的是一個匿名類型,僅捕獲原始 “Customer” 對象的兩個成員。

- 數據源的類型參數始終是查詢中範圍變量的類型。
- 因為選擇語句會產生一個匿名類型,所以查詢變量必須通過使用 var 進行隱式類型定義。
- 由於查詢變量的類型是隱式的,foreach 循環中的迭代變量也必須是隱式的。
讓編譯器推斷類型信息
儘管您應該理解查詢操作中的類型關係,但您也可以選擇讓編譯器為您完成所有工作。在查詢操作中的任何局部變量都可以使用關鍵字 var。以下示例類似於前面討論的示例 2。然而,編譯器會為查詢操作中的每個變量提供強類型。
LINQ 和泛型類型
LINQ 查詢是基於泛型類型的。在開始編寫查詢之前,您無需對泛型有深入的瞭解。不過,您可能需要理解以下兩個基本概念:
- 當您創建一個泛型集合類(如 List < T >)的實例時,您需要將 “T” 替換為該列表將要存儲的對象的類型。例如,字符串列表表示為 List < string >,而客户對象列表表示為 List < LEIKH >。泛型列表是強類型的,並且比將元素存儲為 Object 的集合具有許多優勢。如果您嘗試將一個客户對象添加到一個字符串列表中,將在編譯時出現錯誤。使用泛型集合非常簡單,因為您無需在運行時進行類型轉換。
- IEnumerable < T > 是使泛型集合類能夠使用 foreach 語句進行枚舉的接口。泛型集合類支持 IEnumerable < T >,就像非泛型集合類(如 ArrayList)支持 IEnumerable 一樣。
LINQ 查詢中的變量
在 LINQ 查詢中,變量的類型被定義為 IEnumerable < T > 或其派生類型(如 IQueryable < T > )。當您看到一個被定義為 IEnumerable < KH > 的查詢變量時,這意味着該查詢在執行時將生成零個或多個 KH 對象的序列。
IEnumerable < KH > CHXKH = from kh in KHs
where kh . 城市 == "上海"
select kh;
foreach ( LEI客户 kh in CHXKH )
{
Console . WriteLine ( $"{kh . 姓} {kh . 名}" );
}讓編譯器處理泛型類型聲明
如果您願意,也可以通過使用 var 關鍵字來避免使用泛型語法。var 關鍵字會指示編譯器通過查看 from 子句中指定的數據源來推斷查詢變量的類型。以下示例生成的編譯代碼與前面的示例相同:
var CHXKH2 = from kh in KHs
where kh . 城市 == "上海"
select kh;
foreach ( var k in CHXKH2 )
{
Console . WriteLine ( $"{k . 姓} ,{k . 名}" );
}當變量的類型一目瞭然,或者當明確指定嵌套的泛型類型(例如由分組查詢生成的那些類型)並非那麼重要時,使用 “var” 關鍵字會很有用。通常情況下,我們建議如果使用 “var”,要意識到這可能會使代碼更難讓他人理解。
支持 LINQ 的 C# 特性
查詢表達式
查詢表達式採用類似於 SQL 或 XQuery 的聲明式語法,用於對 System . Collections . Generic . IEnumerable < T > 類型的集合進行查詢。在編譯時,查詢語法會被轉換為對 LINQ 提供程序實現的標準查詢方法的調用。應用程序通過使用適當的命名空間的 using 指令來控制作用域內的標準查詢操作符。以下的查詢表達式接收一個字符串數組,根據字符串中的第一個字符對它們進行分組,並對分組進行排序。
var CHX = from z in ZFC數組
group z by z [ 0 ] into ZFC組
orderby ZFC組 . Key
select ZFC組;隱式類型變量(var)
您可以使用 var 關鍵字來指示編譯器自動推斷並賦值類型,示例如下:
var number = 5;
var name = "Virginia";
var query = from str in stringArray
where str[0] == 'm'
select str;聲明為 “var” 類型的變量具有強類型特性,與您明確指定類型的變量具有相同特點。使用 “var” 可以創建匿名類型,但僅限於局部變量。
對象和集合初始化器
對象和集合初始化器使得無需顯式調用對象的構造函數即可對其進行初始化。初始化器通常在查詢表達式中使用,當它們將源數據轉換為新的數據類型時會用到。假設有一個名為 “KH” 的類,具有公共的 “姓名” 和 “電話號碼” 屬性,那麼可以像下面的代碼那樣使用對象初始化器:
var k = new KH { 姓名 = "朱" , Phone = "555-1212" };
繼續以您的 “KH” 類為例,假設存在一個名為 “新訂單” 的數據源,並且對於每個訂單(其 “訂單大小” 較大),您都希望根據該訂單創建一個新的客户。可以對這個數據源執行一個 LINQ 查詢,並使用對象初始化來填充一個集合:
var ZHS = 5;
var XM = "馬超";
var CHX = from zfc in ZFC組
where zfc [ 0 ] == 'm'
select zfc;聲明為 “var” 類型的變量是強類型的,與您明確指定類型的變量類型相同。使用 “var” 可以創建匿名類型,但僅限於局部變量。
對象和集合初始化器
對象和集合初始化器使得無需顯式調用對象的構造函數即可對其進行初始化。初始化器通常在查詢表達式中使用,當它們將源數據轉換為新的數據類型時會用到。假設有一個名為 “KH” 的類,具有公共的 “姓名” 和 “電話號碼” 屬性,那麼可以像下面的代碼那樣使用對象初始化器:
var k = new KH { 姓名 = "馬超" , 電話號碼 = "555-1212" };
繼續以您的 “KH” 類為例,假設存在一個名為 “進賬單” 的數據源,並且對於每個訂單(其 “訂單大小” 較大),您都希望根據該訂單創建一個新的客户。可以對這個數據源執行一個 LINQ 查詢,並使用對象初始化來填充一個集合:
var DKH = from k in 進賬單
where k . 入賬 >= 5000
select new KH { 姓名 = k . 姓名 , 電話號碼 = k . 電話 };數據源可能定義了比 “KH” 類更多的屬性,例如 “訂單大小”,但在對象初始化過程中,查詢返回的數據會被轉換為所需的數據類型;您可以選擇與您的類相關的數據。因此,您現在擁有了一個填充了您所期望的新客户的 “System . Collections . Generic . IEnumerable < T >” 集合。上述示例還可以使用 LINQ 的方法語法來編寫:
var DKH = 進賬單. Where ( x => x . 入賬 > 5 ) . Select ( k => new KH { 姓名 = k . 姓名 , 電話號碼 = k . 電話 } );
從 C# 12 版本開始,您可以使用集合表達式來初始化一個集合。
匿名類型
編譯器會構建一個匿名類型。該類型名稱僅對編譯器可用。匿名類型為在查詢結果中臨時對一組屬性進行分組提供了一種便捷的方式,而無需定義單獨的命名類型。匿名類型通過使用新的表達式和對象初始化器進行初始化,如下所示:
select new { 姓名 = k . 姓名 , 電話號碼 = k . 電話 };
從 C# 7 版本開始,您可以使用 tuples(元組)來創建無名稱的類型。
擴展方法
擴展方法是一種可以與某一類型相關聯的 static 方法,這樣就可以像調用該類型的實例方法一樣對其進行調用。此特性使您實際上能夠 “添加” 新方法到現有類型中,而無需實際對其進行修改。標準查詢運算符是一組擴展方法,為任何實現了 IEnumerable < T > 接口的類型提供了 LINQ 查詢功能。
Lambda 表達式
Lambda 表達式是一種內聯函數,它通過 “=>” 運算符將輸入參數與函數體分隔開,並且可以在編譯時轉換為委託或表達式樹。在 LINQ 編程中,當您直接對標準查詢操作符進行方法調用時,就會遇到 Lambda 表達式。
表達式作為數據
查詢對象是可組合的,這意味着您可以從方法中返回一個查詢。代表查詢的對象並不存儲結果集合,而是存儲在需要時生成結果的步驟。從方法中返回查詢對象的優點在於它們可以進一步組合或修改。因此,任何從方法返回的查詢的返回值或輸出參數都必須具有相同的類型。如果一個方法將查詢轉化為具體的 List < T > 或數組類型,則它返回的是查詢結果,而不是查詢本身。從方法返回的查詢變量仍然可以進行組合或修改。
在以下示例中,第一個方法 FF查詢1 以查詢的形式作為返回值返回,而第二個方法 FF查詢2 則將查詢作為輸出參數返回(在示例中為 FH值)。在這兩種情況下,返回的都是一個查詢,而非查詢結果。
static IEnumerable < string > FF查詢1 ( int [ ] ints ) =>
from i in ints
where i > 4
select i . ToString ( );
void FF查詢2 ( int [ ] ints , out IEnumerable < string > FH值 ) =>
FH值 =
from i in ints
where i > 4
select i . ToString ( );
int [ ] Zhss = [ 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ];
var c = FF查詢1 ( Zhss );
IEnumerable < string > c2;
FF查詢2 ( Zhss , out c2 );查詢語句 “c” 是在以下的 “foreach” 循環中執行的。
foreach ( var z in c )
{
Console . WriteLine ( z );
}將鼠標指針懸停在 “c”上,即可查看其類型。
您還可以直接執行從 FF查詢1 方法返回的查詢結果,而無需使用 c。
foreach ( var z in FF查詢1 ( Zhss ) )
{
Console . WriteLine ( z );
}將鼠標指針懸停在 “FF查詢1” 調用處,即可查看其返回類型。
FF查詢2 方法將一個查詢結果作為其輸出參數的值 c2 返回:
foreach ( var z in c2 )
{
Console . WriteLine ( z );
}您可以通過使用查詢組合來修改查詢。在這種情況下,之前的查詢對象會被用於創建一個新的查詢對象。這個新對象所返回的結果與原始查詢對象的結果不同。
c = from xm in c
orderby xm descending
select xm;
foreach ( var z in c )
{
Console . WriteLine ( z );
}教程:使用語言集成查詢(LINQ)在 C# 中編寫查詢語句
在本教程中,您將創建一個數據源並編寫多個 LINQ 查詢。您可以試驗查詢表達式並觀察結果的差異。此演示文稿展示了用於編寫 LINQ 查詢表達式的 C# 語言特性。您可以跟隨示例並構建應用程序並親自試驗查詢。本文假定您已安裝最新版本的 .NET SDK。如果沒有,請訪問 .NET 下載頁面並在您的機器上安裝最新版本。
首先,創建應用程序。在控制枱中,輸入以下命令:
dotnet new console -o 循着步驟編寫 LINQ 查詢
或者,如果您喜歡使用 Visual Studio,可以創建一個名為 “循着步驟編寫 LINQ 查詢” 的新控制枱應用程序。
創建內存數據源
第一步是為您的查詢創建一個數據源。查詢的數據源是一個簡單的學生記錄列表。每個學生記錄包含一個姓、名以及一個表示其在班級中測試成績的 double 數組(語、數、物、化)。創建一個名為 “LEI學生.cs” 的新文件,並將以下代碼複製到該文件中:
/// <summary>
/// 學生
/// </summary>
public record LEI學生
{
private readonly string Xing , Ming;
private readonly int id;
private readonly double ZF , PF;
public LEI學生 ( string 姓 , string 名 , int ID , 分數 分 )
{
Xing = 姓;
Ming = 名;
id = ID;
ZF = 分 . 化學 + 分 . 物理 + 分 . 數學 + 分 . 語文;
PF = ( 分 . 化學 + 分 . 物理 + 分 . 數學 + 分 . 語文 ) / 4;
}
public double 總分
{ get { return ZF; } }
public double 平均分
{ get { return PF; } }
public string 姓
{ get { return Xing; } }
public string 名
{ get { return Ming; } }
public override string ToString ( )
{
return $"{姓}{名}({id}):{總分},平均分:{平均分}";
}
}
/// <summary>
/// 學生的分數
/// </summary>
/// <param name="語文"></param>
/// <param name="數學"></param>
/// <param name="物理"></param>
/// <param name="化學"></param>
public record struct 分數 ( double 語文 , double 數學 , double 物理 , double 化學 )
{
}請注意以下特點:
- 學生記錄包含自動實現的屬性。
- 列表中的每個學生都是通過主構造函數進行初始化的。
- 每個學生的成績序列也是通過主構造函數進行初始化的。
接下來,創建一個學生記錄序列作為此查詢的來源。打開 Program.cs 文件,將其替換為以下代碼,該代碼會創建一系列的學生記錄:
IEnumerable < LEI學生 > XueShengs =
[
new LEI學生 ( "蘇" , "小丹" , 111 , new 分數 ( 96.5 , 97 , 100 , 99.5 ) ),
new LEI學生 ( "馬" , "珍美" , 112 , new 分數 ( 90.5 , 117 , 94 , 92.5 ) ),
new LEI學生 ( "黃" , "麗麗" , 113 , new 分數 ( 92 , 92 , 93 , 92 ) ),
new LEI學生 ( "肖" , "春麗" , 114 , new 分數 ( 99 , 99.5 , 103 , 102 ) ),
new LEI學生 ( "吳" , "作美" , 115 , new 分數 ( 99.5 , 99 , 101.5 , 108 ) ),
];- 學生序列是通過一個集合表達式進行初始化的。
- “學生” 記錄類型包含了所有學生的 static 列表。
- 一些構造函數調用使用命名參數來明確哪個參數對應哪個構造函數參數。
試着向學生列表中添加一些具有不同測試分數的學生,以便更熟悉目前的代碼。
創建查詢
接下來,您將創建您的第一個查詢。當您執行該查詢時,它會生成一個包含所有總分高於 400 分的學生的列表。由於選擇了整個 “LEI學生” 對象,所以該查詢的類型為 “IEnumerable < LEI學生 >”。儘管代碼也可以通過使用 “var” 關鍵字來實現隱式類型定義,但使用顯式類型是為了更清晰地展示結果。在創建學生序列的代碼之後,在 Program.cs 中添加以下代碼:
IEnumerable < LEI學生 > CHX高分 =
from xs in XueShengs
where xs . 總分 > 400
select xs;該查詢的範圍變量 “LEI學生” 用於指向源數據中的每個 “LEI學生” 對象,從而為每個對象提供了成員訪問權限。
運行查詢
現在編寫一個 “foreach” 循環,以使查詢得以執行。在 “foreach” 循環中,通過迭代變量來訪問返回序列中的每個元素。此變量的類型為 “LEI學生”,而查詢變量的類型與之兼容,均為 “IEnumerable < LEI學生>”。在添加以下代碼後,構建並運行應用程序,以便在控制枱窗口中查看結果。
foreach ( LEI學生 x in CHX高分 )
Console . WriteLine ( x . ToString ( ) );為了進一步完善查詢條件,您可以在 “where” 子句中結合多個布爾條件。以下代碼添加了一個條件,使得查詢結果僅返回那些總分超過 400 分且平均分高於 101 分的學生。“where” 子句應類似於以下代碼。
where xs . 總分 > 400 && xs . 平均分 >= 101
可以嘗試前面提到的 “where” 子句,或者自行試驗其他篩選條件。
對查詢結果進行排序
如果結果按照某種順序排列,那麼瀏覽這些結果會更加方便。您可以根據源元素中的任何可訪問字段對返回的序列進行排序。例如,以下的 “orderby” 語句根據每個學生的姓氏按拼音字母順序(從 A 到 Z)對結果進行排序。將以下 “orderby” 語句添加到您的查詢中,位置應位於 “where” 語句之後、“select” 語句之前:
orderby xs . 姓 // 省略 ascending,默認即為升序(A ~ Z)
現在修改排序條件,使其按照總分大於 390 成績對結果進行倒序排列,即從最高分到最低分。
IEnumerable < LEI學生 > CHX高分 =
from xs in XueShengs
where xs . 總分 > 390
orderby xs . 總分 descending
select xs;對結果進行分組
分組是查詢表達式中的一項強大功能。帶有 group 子句的查詢會生成一系列的分組,而每個分組自身都包含一個鍵以及該分組中所有成員的序列。下面這兩個新的查詢是按照學生姓氏的拼音首字母和總分整除 100(即 300 或 400)對其進行分組的。
IEnumerable < IGrouping < char , LEI學生 > > CHX姓氏分組 =
from x in XueShengs
group x by x . 姓 [ 0 ]; // 姓氏拼音分組
IEnumerable < IGrouping < int , LEI學生 > > CHX總分分組 =
from x in XueShengs
group x by ( int ) x . 總分 / 100; // 總分百位分組查詢的類型發生了變化。現在它會生成一系列以字符類型作為鍵、以及一系列 “LEI學生” 對象組成的組。在 foreach 執行循環中的代碼也需要進行相應修改(例如上面那個總分分組查詢):
foreach ( IGrouping < int , LEI學生 > Zu in CHX總分分組 )
{
Console .WriteLine ( Zu . Key * 100 );
foreach ( LEI學生 x in Zu )
Console . WriteLine ( x . ToString ( ) );
}運行該應用程序,並在控制枱窗口中查看結果。
顯式地對 IGroupings 的 IEnumerables 進行編碼可能會很快變得繁瑣。使用 var 關鍵字可以更方便地編寫相同的查詢和 foreach 循環。var 關鍵字並不會改變對象的類型,它只是讓編譯器自動推斷類型。將上例中的外循環變量 Zu 和內循環變量 x 聲明為 var 您會發現得到的結果完全相同。
按其鍵值對組進行排序
之前查詢中的姓氏組並非按字母順序排列。您可以在 group 子句之後添加一個 orderby 子句。但要使用 orderby 子句,您首先需要一個作為 group 子句創建的組的參考標識符。您可以通過使用 into 關鍵字來提供該標識符,如下所示:
var CHX姓氏分組 =
from xs in XueShengs
group xs by xs . 姓 into XSZH
orderby XSZH . Key
select XSZH;運行此查詢後,這些組現在已按字母順序排列好了。
您可以通過使用 “let” 關鍵字來為查詢表達式中的任何表達式結果引入一個標識符。這個標識符可以起到方便的作用,就像下面的示例中那樣。它還可以通過將表達式的結果存儲起來來提高性能,這樣就不必多次計算該結果了。
var CHX複姓 =
from xs in XueShengs
let FX = xs . 姓
where FX . Length > 1
select xs;在查詢表達式中使用方法語法
正如在 “LINQ 查詢語法與方法語法” 中所描述的那樣,某些查詢操作只能通過使用方法語法來表達。以下代碼會計算源序列中每個國家的人口,然後對該查詢的結果調用 Average ( ) 方法以計算全部國家的平均人口。
var CHX平均人口 =
from g in GJs
let RK = g . 百萬人
select RK;
Console . WriteLine ( CHX平均人口 . Average ( ) );在 select 子句中進行轉換或投影
通常情況下,查詢會生成一個與源序列中的元素不同的序列。請刪除或註釋掉您之前的查詢和執行循環,並用以下代碼替換它們。該查詢返回一個字符串序列(而非 “LEI學生” 序列),這一事實體現在 foreach 循環中。
IEnumerable < string > CHX名字 =
from xs in XueShengs
where xs . 名 . Contains ( '麗' )
select xs . 姓;
Console . WriteLine ( "名字中帶“麗”的:" );
foreach ( string zfc in CHX名字 )
{
Console . WriteLine ( zfc );
}在本教程的前面部分中提到,班級的平均成績約為 334 分。要生成一組總成績高於班級平均分的學生信息(包括他們的學號),您可以在選擇語句中使用匿名類型:
IEnumerable < LEI學生 > CHX名字 =
from xs in XueShengs
let pj = xs . 平均分
where pj > 100
select xs;
Console . WriteLine ( "平均分大於 100 的:" );
foreach ( LEI學生 x in CHX名字 )
{
Console . WriteLine ( x . ToString ( ) );
}標準查詢運算符概述
標準查詢運算符是構成 LINQ 模式的關鍵字和方法。C# 語言定義了用於最常見的查詢表達式的 LINQ 查詢關鍵字。編譯器使用這些關鍵字將表達式轉換為等效的方法調用。這兩種形式是同義的。System . Linq 命名空間中的其他方法沒有等效的查詢關鍵字。在這些情況下,您必須使用方法語法。本節涵蓋了所有的查詢運算符關鍵字。運行時和其他 NuGet 包在每次發佈時都會添加更多與 LINQ 查詢一起使用的方法。最常見的方法,包括那些具有查詢關鍵字等效項的方法,都在本節中介紹。除了這裏介紹的方法之外,這個類還包含用於連接數據源、從數據源計算單個值(例如求和、平均值或其他值)的方法。
**重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。
這些方法大多處理序列,而序列是一種其類型實現了 IEnumerable < T > 接口或 IQueryable < T > 接口的對象。標準查詢運算符提供了包括篩選、投影、聚合、排序等在內的查詢功能。每個集合中的方法分別是 Enumerable 類和 Queryable 類的 static 成員。它們被定義為它們所操作的類型的擴展方法。
“IEnumerable < T >” 序列和 “IQueryable < T >” 序列之間的區別決定了查詢在運行時的執行方式。
對於 IEnumerable < T > 類型,所返回的枚舉對象會捕獲傳遞給該方法的參數。當對該對象進行枚舉時,會運用查詢操作符的邏輯,並返回查詢結果。
對於 IQueryable < T > 來説,查詢會被轉換為一個表達式樹。當數據源能夠優化查詢時,這個表達式樹可以被轉換為原生查詢。諸如 Entity Framework 這樣的庫會將 LINQ 查詢轉換為在數據庫中執行的原生 SQL 查詢。
在可能的情況下,本節中的查詢會使用一系列詞語或數字作為輸入來源。對於涉及對象之間更復雜關係的查詢,將使用以下模擬計算機大學的模型來源:
public static class Sources
{
public static IEnumerable < LEI系 > 系 =>
[
new ( ) { 系名 = "中文", ID系 = 1, ID教授 = 901 },
new ( ) { 系名 = "數學", ID系 = 2, ID教授 = 965 },
new ( ) { 系名 = "工程學", ID系 = 3, ID教授 = 932 },
new ( ) { 系名 = "政治經濟學", ID系 = 4, ID教授 = 945 },
new ( ) { 系名 = "物理學", ID系 = 5, ID教授 = 987 },
new ( ) { 系名 = "化學", ID系 = 6, ID教授 = 988 },
new ( ) { 系名 = "文學", ID系 = 7, ID教授 = 901 }
];
// Create a data source by using a collection initializer.
public static IEnumerable < LEI學生 > 學生們 =>
[
new ( ) { 姓 = "王" , 名 = "詠梅" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 111 , 分數 = [ 97 , 90 , 73 , 54 ] },
new ( ) { 姓 = "李" , 名 = "曉曉" , ID系 = -1 , 年級 = GradeLevel . 一 , XSID = 112 , 分數 = [ 56 , 78 , 95 , 95 ] },
new ( ) { 姓 = "聞" , 名 = "思思" , ID系 = 3 , 年級 = GradeLevel . 二 , XSID = 113 , 分數 = [ 61 , 52 , 48 , 72 ] },
new ( ) { 姓 = "劉" , 名 = "明娟" , ID系 = 4 , 年級 = GradeLevel . 二 , XSID = 114 , 分數 = [ 71 , 86 , 77 , 97 ] },
new ( ) { 姓 = "泰" , 名 = "山坡" , ID系 = 5 , 年級 = GradeLevel . 三 , XSID = 115 , 分數 = [ 66 , 96 , 70 , 69 ] },
new ( ) { 姓 = "法" , 名 = "愛迪" , ID系 = 6 , 年級 = GradeLevel . 三 , XSID = 116 , 分數 = [ 93 , 72 , 62 , 65 ] },
new ( ) { 姓 = "黃" , 名 = "大明" , ID系 = 1 , 年級 = GradeLevel . 四 , XSID = 117 , 分數 = [ 53 , 81 , 81 , 50 ] },
new ( ) { 姓 = "劉" , 名 = "寧寧" , ID系 = 2 , 年級 = GradeLevel . 四 , XSID = 118 , 分數 = [ 68 , 91 , 60 , 51 ] },
new ( ) { 姓 = "蘇" , 名 = "小蘭" , ID系 = -1 , 年級 = GradeLevel . 一 , XSID = 119 , 分數 = [ 83 , 42 , 68 , 63 ] },
new ( ) { 姓 = "馬" , 名 = "小凡" , ID系 = 4 , 年級 = GradeLevel . 二 , XSID = 120 , 分數 = [ 63 , 91 , 71 , 51 ] },
new ( ) { 姓 = "羅" , 名 = "星星" , ID系 = 5 , 年級 = GradeLevel . 三 , XSID = 121 , 分數 = [ 56 , 40 , 73 , 75 ] },
new ( ) { 姓 = "九" , 名 = "連環" , ID系 = 3 , 年級 = GradeLevel . 四 , XSID = 122 , 分數 = [ 85 , 82 , 81 , 70 ] },
new ( ) { 姓 = "梅" , 名 = "花開" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 123 , 分數 = [ 82 , 94 , 84 , 65 ] },
new ( ) { 姓 = "蘇" , 名 = "琴聲" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 124 , 分數 = [ 77 , 83 , 67 , 90 ] },
new ( ) { 姓 = "白" , 名 = "芙蓉" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 125 , 分數 = [ 88 , 57 , 65 , 87 ] },
new ( ) { 姓 = "黑" , 名 = "玫瑰" , ID系 = 2 , 年級 = GradeLevel . 二 , XSID = 126 , 分數 = [ 46 , 84 , 87 , 66 ] },
new ( ) { 姓 = "歐陽" , 名 = "小強" , ID系 = 6 , 年級 = GradeLevel . 二 , XSID = 127 , 分數 = [ 92 , 45 , 88 , 60 ] },
new ( ) { 姓 = "夏侯" , 名 = "敦敦" , ID系 = 2 , 年級 = GradeLevel . 二 , XSID = 128 , 分數 = [ 85 , 54 , 74 , 75 ] },
new ( ) { 姓 = "東方" , 名 = "總贏" , ID系 = 3 , 年級 = GradeLevel . 三 , XSID = 129 , 分數 = [ 51 , 78 , 54 , 49 ] },
new ( ) { 姓 = "端木" , 名 = "錯" , ID系 = 3 , 年級 = GradeLevel . 三 , XSID = 130 , 分數 = [ 46 , 73 , 93 , 68 ] },
new ( ) { 姓 = "呂" , 名 = "海珠", ID系 = 3 , 年級 = GradeLevel . 三 , XSID = 131 , 分數 = [ 85 , 60 , 85 , 56 ] },
new ( ) { 姓 = "強" , 名 = "東昇" , ID系 = 4 , 年級 = GradeLevel . 四 , XSID = 132 , 分數 = [ 54 , 98 , 56 , 61 ] },
new ( ) { 姓 = "李", 名 = "蘭英" , ID系 = 6 , 年級 = GradeLevel . 四 , XSID = 133 , 分數 = [ 63 , 57 , 69 , 70 ] },
new ( ) { 姓 = "西門", 名 = "浩強" , ID系 = 4 , 年級 = GradeLevel . 四 , XSID = 134 , 分數 = [ 85 , 60 , 80 , 73 ] },
new ( ) { 姓 = "楊" , 名 = "乃亮" , ID系 = 5 , 年級 = GradeLevel . 一 , XSID = 135 , 分數 = [ 46 , 94 , 93 , 45 ] },
new ( ) { 姓 = "Sofiya" , 名 = "王" , ID系 = 6 , 年級 = GradeLevel . 一 , XSID = 136 , 分數 = [ 74 , 45 , 87 , 55 ] },
new ( ) { 姓 = "Amy E." , 名 = "楊" , ID系 = 5 , 年級 = GradeLevel . 一 , XSID = 137 , 分數 = [ 87 , 59 , 55 , 70 ] },
new ( ) { 姓 = "Nancy" , 名 = "張" , ID系 = 3 , 年級 = GradeLevel . 一 , XSID = 138 , 分數 = [ 75 , 73 , 78 , 83 ] },
new ( ) { 姓 = "Kate" , 名 = "卡" , ID系 = 2 , 年級 = GradeLevel . 一 , XSID = 139 , 分數 = [ 44 , 50 , 47 , 41 ] },
new ( ) { 姓 = "Rose" , 名 = "Ugomma" , ID系 = 4 , 年級 = GradeLevel . 一 , XSID = 140 , 分數 = [ 84 , 82 , 96 , 80 ] },
new ( ) { 姓 = "Don" , 名 = "查" , ID系 = 5 , 年級 = GradeLevel . 一 , XSID = 141 , 分數 = [ 47 , 91 , 73 , 68 ] },
new ( ) { 姓 = "Jose" , 名 = "包" , ID系 = 6 , 年級 = GradeLevel . 二 , XSID = 142 , 分數 = [ 40 , 47 , 63 , 42 ] },
new ( ) { 姓 = "邁克" , 名 = "卡" , ID系 = -1 , 年級 = GradeLevel . 一 , XSID = 143 , 分數 = [ 97 , 92 , 69 , 77 ] },
new ( ) { 姓 = "Gaby" , 名 = "Frost" , ID系 = 2 , 年級 = GradeLevel . 一 , XSID = 144 , 分數 = [ 70 , 79 , 47 , 79 ] },
new ( ) { 姓 = "安娜" , 名 = "倪" , ID系 = 3 , 年級 = GradeLevel . 一 , XSID = 145 , 分數 = [ 56 , 52 , 51 , 51 ] },
new ( ) { 姓 = "Naima" , 名 = "拉" , ID系 = 4 , 年級 = GradeLevel . 三 , XSID = 146 , 分數 = [ 65 , 81 , 44 , 61 ] },
new ( ) { 姓 = "Donald" , 名 = "伍" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 147 , 分數 = [ 92 , 90 , 95 , 57 ] },
new ( ) { 姓 = "考" , 名 = "納德" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 148 , 分數 = [ 94 , 69 , 52 , 58 ] },
new ( ) { 姓 = "羅" , 名 = "爾森" , ID系 = 2 , 年級 = GradeLevel . 四 , XSID = 149 , 分數 = [ 66 , 49 , 82 , 74 ] },
new ( ) { 姓 = "Maria" , 名 = "Sammut" , ID系 = 2 , 年級 = GradeLevel . 一 , XSID = 150 , 分數 = [ 43 , 83 , 94 , 60 ] },
new ( ) { 姓 = "闞" , 名 = "廖亮" , ID系 = 3 , 年級 = GradeLevel . 一 , XSID = 151 , 分數 = [ 59 , 76 , 65 , 92 ] },
new ( ) { 姓 = "欒" , 名 = "明海" , ID系 = 3 , 年級 = GradeLevel . 一 , XSID = 152 , 分數 = [ 44 , 57 , 52 , 63 ] },
new ( ) { 姓 = "伍" , 名 = "柯藍" , ID系 = 4 , 年級 = GradeLevel . 二 , XSID = 153 , 分數 = [ 51 , 40 , 42 , 54 ] },
new ( ) { 姓 = "晁" , 名 = "天笑" , ID系 = 4 , 年級 = GradeLevel . 一 , XSID = 154 , 分數 = [ 44 , 70 , 98 , 56 ] },
new ( ) { 姓 = "John" , 名 = "Falzon" , ID系 = 5 , 年級 = GradeLevel . 一 , XSID = 155 , 分數 = [ 77 , 65 , 83 , 45 ] },
new ( ) { 姓 = "Martina" , 名 = "Matt" , ID系 = 5 , 年級 = GradeLevel . 三 , XSID = 156 , 分數 = [ 51 , 49 , 96 , 72 ] },
new ( ) { 姓 = "Jean" , 名 = "Berg" , ID系 = 4 , 年級 = GradeLevel . 一 , XSID = 157 , 分數 = [ 41 , 67 , 46 , 68 ] },
new ( ) { 姓 = "安麗絲" , 名 = "吉" , ID系 = 2 , 年級 = GradeLevel . 一 , XSID = 158 , 分數 = [ 53 , 96 , 76 , 49 ] },
new ( ) { 姓 = "Bruce" , 名 = "Keever" , ID系 = 3 , 年級 = GradeLevel . 一 , XSID = 159 , 分數 = [ 54 , 81 , 84 , 81 ] },
new ( ) { 姓 = "Sami" , 名 = "埃克森" , ID系 = 5 , 年級 = GradeLevel . 四 , XSID = 160 , 分數 = [ 45 , 85 , 79 , 94 ] },
new ( ) { 姓 = "Jesper" , 名 = "羅賓遜" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 161 , 分數 = [ 59 , 98 , 47 , 92 ] },
new ( ) { 姓 = "Max" , 名 = "琳達" , ID系 = 2 , 年級 = GradeLevel . 一 , XSID = 162 , 分數 = [ 86 , 88 , 96 , 63 ] },
new ( ) { 姓 = "Arina" , 名 = "愛娃" , ID系 = 1 , 年級 = GradeLevel . 一 , XSID = 163 , 分數 = [ 93 , 63 , 70 , 80 ] }
];
public static IEnumerable<LEI教授> 教授們 =>
[
new ( ) { 姓 = "國" , 名 = "大全" , JSID = 901 , 城市 = "濟南" },
new ( ) { 姓 = "孫" , 名 = "曉寧" , JSID = 910 , 城市 = "淄博" },
new ( ) { 姓 = "李" , 名 = "大明" , JSID = 921 , 城市 = "淄博" },
new ( ) { 姓 = "安" , 名 = "晶典" , JSID = 932 , 城市 = "濟南" },
new ( ) { 姓 = "貝" , 名 = "華農" , JSID = 943 , 城市 = "青島" },
new ( ) { 姓 = "艾" , 名 = "真誠" , JSID = 954 , 城市 = "青島" },
new ( ) { 姓 = "肖" , 名 = "美英" , JSID = 965 , 城市 = "濟南" },
new ( ) { 姓 = "段" , 名 = "小美" , JSID = 976 , 城市 = "淄博" },
new ( ) { 姓 = "吉" , 名 = "慶安" , JSID = 987 , 城市 = "煙台" },
new ( ) { 姓 = "圖" , 名 = "陸凡" , JSID = 998 , 城市 = "煙台" },
new ( ) { 姓 = "蘭" , 名 = "瑩瑩" , JSID = 912 , 城市 = "淄博" },
new ( ) { 姓 = "左" , 名 = "愛玲" , JSID = 923 , 城市 = "濟南" },
new ( ) { 姓 = "錢" , 名 = "自達" , JSID = 934 , 城市 = "淄博" },
new ( ) { 姓 = "張" , 名 = "典盛" , JSID = 945 , 城市 = "淄博" },
new ( ) { 姓 = "洪" , 名 = "水發" , JSID = 956 , 城市 = "煙台" },
new ( ) { 姓 = "馮" , 名 = "海英" , JSID = 967 , 城市 = "濟南" },
new ( ) { 姓 = "扈" , 名 = "十娘" , JSID = 978 , 城市 = "淄博" },
new ( ) { 姓 = "薊" , 名 = "精明" , JSID = 989 , 城市 = "青島" },
new ( ) { 姓 = "費" , 名 = "楊柳" , JSID = 991 , 城市 = "淄博" },
new ( ) { 姓 = "卡" , 名 = "道行" , JSID = 982 , 城市 = "煙台" },
new ( ) { 姓 = "惠" , 名 = "博山" , JSID = 973 , 城市 = "淄博" }
new ( ) { 姓 = "歐陽" , 名 = "小強" , JSID = 991 , 城市 = "淄博" }
];
}每個 LEI學生 都有一個年級、一個學院(XYID)以及一系列的成績。教授也有一個與所在學院相關的 “課程”,該屬性標識了教授主講課程。學院則具有本學院所擁有的教授的 JID。
您可以在源代碼庫中找到該數據集。
查詢操作符的類型
標準的查詢操作符在執行時機上有所不同,這取決於它們是否返回單個值還是多個值。那些返回單個值的操作符(例如平均值和求和)會立即執行。而那些返回序列的操作符則會推遲查詢執行,並返回一個可枚舉的對象。您可以將一個查詢的輸出序列用作另一個查詢的輸入序列。在一個查詢中,可以將對查詢方法的調用串聯起來,這樣就能使查詢變得極其複雜。
查詢操作符
在 LINQ 查詢中,第一步是指定數據源。在 LINQ 查詢中,from 子句排在首位,用於引入數據源(LEI學生)和範圍變量(XS)。
// CHX全部學生 是一個 IEnumerable < LEI學生 >
var CHX全部學生 = from XS in XSs
select XS;範圍變量類似於 foreach 循環中的迭代變量,不同之處在於在查詢表達式中不會實際進行迭代操作。當執行查詢時,範圍變量會作為對 “LEI學生” 數組中每個後續元素的引用。由於編譯器能夠推斷出 “LEI學生” 的類型,所以您無需明確指定其類型。在 let 語句中還可以引入更多的範圍變量。
注意:對於非通用數據源(如 ArrayList)而言,範圍變量必須進行明確的類型定義。
一旦您獲取了數據源,您就可以對這個數據源執行任意數量的操作:
- 使用 “where” 關鍵字對數據進行篩選。
- 使用 “orderby” 關鍵字對數據進行排序(可選地使用 “descending” 關鍵字進行降序排列)。
- 使用 “group” 關鍵字對數據進行分組(可選地使用 “into” 關鍵字進行分組操作)。
- 使用 “join” 關鍵字進行數據連接。
- 使用 “select” 關鍵字進行數據投影。
查詢表達式語法表
以下表格列出了具有等效查詢表達式語句的常用查詢運算符。
| 方法 | C# 查詢表達式語法 |
|---|---|
| Cast | 使用具有明確類型定義的範圍變量: |
| from int z in Zhss; | |
| GroupBy | group … by 或 group … by … into |
| GroupJoin < TOuter , TInner , TKey , TResult > ( IEnumerable < TOuter > , IEnumerable < TInner > , Func < TOuter , TKey > , Func < TInner , TKey > , Func < TOuter , IEnumerable < TInner > , TResult > ) | join … in … equals … into … |
| Join< TOuter , TInner , TKey , TResult > ( IEnumerable < TOuter > , IEnumerable < TInner > , Func < TOuter , TKey > , Func < TInner , TKey > , Func < TOuter , TInner , TResult > ) | join … in … on … equals … |
| OrderBy < TSource , TKey > ( IEnumerable < TSource > , Func < TSource , TKey > ) | orderby |
| OrderByDescending < TSource , TKey > ( IEnumerable < TSource > , Func < TSource , TKey > ) | orderby … descending |
| Select | select |
| SelectMany | 多個 from 語句 |
| ThenBy < TSource , TKey > ( IOrderedEnumerable < TSource > , Func < TSource , TKey > ) | orderby … , … |
| ThenByDescending < TSource , TKey > ( IOrderedEnumerable < TSource > , Func < TSource , TKey > ) | orderby … , … descending |
| Where | where |
使用 LINQ 進行數據轉換
語言集成查詢(LINQ)不僅用於檢索數據,還是一種強大的數據轉換工具。通過使用 LINQ 查詢,您可以將源序列作為輸入,並以多種方式對其進行修改以生成新的輸出序列。您可以通過排序和分組等方式直接修改序列本身,而無需修改其元素本身。但 LINQ 查詢最強大的功能可能是創建新類型的能力。選擇子句從輸入元素創建輸出元素。您使用它將輸入元素轉換為輸出元素:
- 將多個輸入序列合併為一個具有新類型的輸出序列。
- 創建僅包含源序列中每個元素的一個或幾個屬性的輸出序列。
- 創建包含對源數據執行操作的結果的輸出序列。
- 創建以不同格式呈現的輸出序列。例如,您可以將來自 SQL 行或文本文件的數據轉換為 XML 格式。
這些轉換可以在同一查詢中以各種方式組合使用。此外,一個查詢的輸出序列可以作為另一個查詢的輸入序列。以下示例將內存中數據結構中的對象轉換為 XML 元素。
// 創建查詢
var CHXxsToXML = new XElement ( "Root",
from xs in XSs
let FSs = string . Join ( "," , xs . Scores )
select new XElement ( "學生" ,
new XElement ( "姓" , xs . 姓 ),
new XElement ( "名" , xs . 名 ),
new XElement ( "分數" , FSs )
) // 結束 “學生”
); // 結束 “根”
// 執行查詢
Console . WriteLine ( CHXxsToXML );該代碼會生成以下 XML 格式的輸出:
< Root >
< 學生 >
< 姓 > 吳 < /姓 >
< 名 > 豔豔 < /名 >
< 分數 > A , A , C , E < /分數 >
< /學生 >
< 學生 >
< 姓 > 周 < /姓 >
< 名 > 美華 < /名 >
< 分數 > A , B , B , C < /分數 >
< /學生 >
…
< 學生 >
< 姓 > 馬 < /姓 >
< 名 > 春苗 < /名 >
< 分數 > B , B , C , E < /分數 >
< /學生 >
< 學生 >
< 姓 > 呂 < /姓 >
< 名 > 珍珍 < /名 >
< 分數 > B , C , A , A < /分數 >
< /學生 >
< /Root >您可以將一個查詢的結果用作後續查詢的數據源。此示例展示瞭如何對連接操作的結果進行排序。此查詢創建了一個組連接,然後根據仍在作用域內的 “LEI學院” 元素對這些組進行排序。在匿名類型初始化器內部,一個子查詢對 “LEI學生” 序列中的所有匹配元素進行排序。
var CHX排序 = from XY in XYs
join XS in XSs on XY . ID equals XS . XYID into XS組
orderby XY . 學院名
select new
{
學院名 = XY . 學院名,
學生們 = from XS in XS組
orderby XS . 姓
select XS
};
foreach ( var xy in CHX排序 )
{
Console . WriteLine ( xy . 學院名 );
foreach ( var xs in xy . 學生們 )
{
Console . WriteLine ( $"{xs . 姓 ,-10} {xs . 名 ,-10}" );
}
}使用方法語法進行等效查詢的示例如下所示的代碼中所示:
var CHX排序 =
XYs . GroupJoin ( XSs , XY => XY . ID , XS => XS . XYID,
( XY , XS組 ) => new
{
學院名 = XY . 學院名,
XSs = XS組 . OrderBy ( xs => xs . 姓 )
})
.OrderBy ( xy => xy . 學院名 );
foreach ( var XY in CHX排序 )
{
Console . WriteLine ( XY . 學院名 );
foreach ( var xs in XY . 學生們 )
{
Console . WriteLine ( $" {xs . 姓 ,-10} {xs . 名 ,-10}" );
}
}雖然您可以在連接操作之前對一個或多個源序列使用 “orderby” 子句,但通常我們並不建議這樣做。某些 LINQ 提供程序在連接操作之後可能不會保留這種排序順序。
使用 C# 中的 LINQ 進行數據過濾
過濾是指對結果集進行操作,使其僅包含滿足指定條件的那些元素。它也被稱為選擇符合指定條件的元素。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。請查閲您的數據源的文檔。
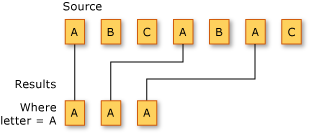
以下示例展示了對一系列字符進行篩選的結果。篩選操作的條件語句規定所篩選的字符必須為 “A”。
以下表格列出了執行篩選操作的標準查詢操作方法:
| 方法名 | 説明 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| OfType | 根據值能夠轉換為指定類型的能力來選擇這些值。 | 不適用 | Enumerable . OfType 和 Queryable . OfType |
| Where | 選擇基於謂詞函數的值。 | where | Enumerable . Where 和 Queryable . Where |
以下示例使用 “where” 子句從數組中篩選出那些長度符合特定要求的字符串。
注意:您可以參考“標準查詢操作符概述”這篇文章中關於此領域的常見數據源內容。
string [ ] Cis = [ "the" , "quick" , "brown" , "fox" , "jumps" ];
IEnumerable < string > CHX = from c in Cis
where c . Length == 3
select c;
foreach ( string c in CHX )
{
Console . WriteLine ( c );
}
/* 輸出:
the
fox
*/使用方法語法進行等效查詢的示例如下所示:
string [ ] Cis = [ "the" , "quick" , "brown" , "fox" , "jumps" ];
IEnumerable < string > CHX = words . Where ( word => word . Length == 3 );
foreach ( string c in CHX )
{
Console . WriteLine ( c );
}
/* 輸出:
the
fox
*/投影操作
投影指的是將一個對象轉換為一種新的形式的操作,這種新形式通常只包含隨後會使用的那些屬性。通過使用投影,您可以構建一個由每個對象構建而成的新類型。您可以投影一個屬性並對其執行數學函數。您還可以不改變原始對象而對其進行投影。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。
執行投影操作的標準查詢操作方法在以下部分有所列舉。
方法
| 方法名 | 説明 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| Select | 基於轉換函數獲取項目值。 | select | Enumerable.Select 和 Queryable . Select |
| SelectMany | 項目會根據一個轉換函數對一系列值進行處理,然後將這些值合併成一個序列。 | 多個查詢集的 from 方法 | Enumerable . SelectMany 和 Querable . SelectMany |
| 壓縮 | 生成包含來自兩個至三個指定序列元素的元組序列。 | 不適用 | Enumerable . Zip 和 Queryable . Zip |
以下示例使用 “select” 子句來從字符串列表中的每個字符串中提取出第一個字母。
List < string > Cis = [ "an" , "apple" , "a" , "day" ];
var CHX首字母 = from c in Cis
select c . Substring ( 0 , 1 );
foreach ( string z in CHX首字母 )
{
Console . WriteLine ( s );
}
/* 輸出:
a
a
a
d
*/使用方法語法進行等效查詢的示例如下所示的代碼中所示:
List < string > Cis = [ "an" , "apple" , "a" , "day" ];
var CHX = Cis . Select ( c => c . Substring ( 0 , 1 ) );
foreach ( string z in CHX )
{
Console . WriteLine ( z );
}
/* 輸出:
a
a
a
d
*/SelectMany
以下示例使用多個 “from” 子句來從字符串列表中的每個字符串中提取出每個單詞。
List < string > Jus = [ "an apple a day" , "the quick brown fox" ];
var CHXju = from j in Jus
from c in j . Split ( ' ' )
select c;
foreach ( string z in CHXju )
{
Console . Write ( $"{z}," );
}使用方法語法進行等效查詢的示例如下所示:
List < string > Jus = [ "an apple a day" , "the quick brown fox" ];
var CHXju = Jus . SelectMany ( j => j . Split ( ' ' ) );
foreach ( string z in CHXju )
{
Console . Write ( $"{z}," );
}“SelectMany” 方法還能將第一個序列中的每個元素與第二個序列中的每個元素進行組合:
List < int > Zhss = [ 1 , 2 , 3 ];
List < string > Zfcs = [ "牛奶" , "麪包" , "雞蛋" ];
var CHX = from zhs in Zhss
from zfc in Zfcs
select ( zhs , zfc );
foreach ( var zz in CHX )
Console . WriteLine ( zz ); // (3, 雞蛋) 類似使用方法語法進行等效查詢的示例如下所示:
List < int > Zhss = [ 1 , 2 , 3 ];
List < string > Zfcs = [ "牛奶" , "麪包" , "雞蛋" ];
var CHX = Zhss . SelectMany ( zhs => Zfcs , ( zhs , zfc ) => ( zhs , zfc ) );
foreach ( var zz in CHX )
Console . WriteLine ( zz ); // (3, 雞蛋)類似Zip
Zip 投影運算符有幾種不同的重載形式。所有的 Zip 方法都可對包含兩種或更多種可能不同類型的序列進行操作。前兩個重載形式會返回元組,其中包含給定序列中對應位置的相應類型。
考慮以下這些集合:
// 7 個元素的整數集合
IEnumerable < int > Zhss = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ];
// 6 個元素的字符集合
IEnumerable<char> ZFs = [ 'A' , 'B' , 'C' , 'D' , 'E' , 'F' ];要將這些序列組合起來,請使用 “Enumerable . Zip < TFirst , TSecond > ( IEnumerable < TFirst > , IEnumerable < TSecond > )” 操作符:
List < int > Zhss = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ];
List < char > Zfs = [ 'A' , 'B' , 'C' , 'D' , 'E' , 'F' ];
foreach ( ( int zhs , char zf ) in Zhss . Zip ( Zfs ) )
Console . WriteLine ( $"數字 {zhs} 指向(Zip)字母 ‘{zf}’" ); // 數字 4 指向(Zip)字母 ‘D’ 等……重要事項:通過 Zip 操作得到的序列的長度永遠不會超過最短序列的長度。數字和字母集合的長度不同,而得到的序列會省略數字集合中的最後一個元素,因為該元素沒有可與之進行 Zip 匹配的對象。
第二個超載功能可以接受第三個序列。接下來,讓我們創建另一個集合,即 “中文數字”:
IEnumerable < string > ZW數字 = [ "一" , "二" , "三" , "四" , "五" , "六" , "七" , "八" ];
要將這些序列組合起來,請使用 “Enumerable . Zip < TFirst , TSecond , TThird > ( IEnumerable < TFirst > , IEnumerable < TSecond > , IEnumerable < TThird > )” 操作符:
foreach ( ( int zhs , char zf , string z ) in Zhss . Zip ( Zfs , ZW數字 ) )
Console . WriteLine ( $"數字 {zhs} 指向(Zip)字母‘{zf}’ 和中文 {z}" );與之前的 “overload” 情況類似,Zip 方法會生成一個元組,不過這次的元組包含三個元素。
第三個重載方法接受一個名為 “Func < TFirst , TSecond , TResult >” 的參數,該參數用作結果選擇器。您可以從被壓縮的序列中生成一個新的結果序列。
List < int > Zhss = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ];
List < char > Zfs = [ 'A' , 'B' , 'C' , 'D' , 'E' , 'F' ];
foreach ( string JG in Zhss . Zip ( Zfs , ( zhs , zf ) => $"{zhs} = {zf}({( int ) zf})" ) )
Console . WriteLine ( JG );通過上述的 “Zip” 重載操作,指定的函數會應用於對應的元素 “編號” 和 “字母”,從而生成一系列字符串結果。
Select 與 SelectMany
“Select” 和 “SelectMany” 的工作都是從源值中生成一個(或多個)結果值。Select 操作會為每個源值生成一個結果值。因此,最終結果是一個與源集合元素數量相同的集合。相比之下,“SelectMany” 操作會生成一個單一的最終結果,該結果包含每個源值的串聯子集合。傳遞給 “SelectMany” 的轉換函數必須為每個源值返回一個可枚舉的值序列。“SelectMany” 會將這些可枚舉序列連接起來,從而形成一個大的序列。
以下兩個示例展示了這兩種方法操作方式上的概念性差異。在每種情況下,假設選擇器(轉換)函數會從每個源值中選取 花 的數組。
此圖示展示了 Select 方法是如何返回一個與源集合具有相同元素數量的集合的。

此圖示展示了 SelectMany 如何將一系列中間數組連接成一個最終的結果值,該結果值包含了每個中間數組中的每個值。

代碼示例
以下示例比較了 Select 和 SelectMany 的行為。該代碼通過從源集合中的每個 花 名列表中獲取項目,來創建一個 “花束”。在以下示例中,轉換函數 Select < TSource , TResult > ( IEnumerable < TSource > , Func < TSource , TResult > ) 所使用的 “單個值” 是一個值的集合。此示例需要額外的 foreach 循環,以便枚舉每個子序列中的每個字符串。
List < LEI花束 > HuaShus =
[
new LEI花束 { Huas = [ "向日葵" , "雛菊" , "水仙花" , "飛燕草" ] },
new LEI花束 { Huas = [ "鬱金香" , "玫瑰" , "蘭花" ] },
new LEI花束 { Huas = [ "劍蘭" , "百合" , "馬蹄蓮" , "菊屬植物" , "龍血樹" ] },
new LEI花束 { Huas = [ "金雀花" , "紫丁香" , "鳶尾花" , "大麗花" ] },
];
IEnumerable < List < string > > CHX1 = HuaShus . Select ( hs => hs . Huas );
IEnumerable < string > CHX2 = HuaShus . SelectMany ( hs => hs . Huas );
Console . WriteLine ( "使用 Select ( ):" );
foreach ( IEnumerable < string > Zus in CHX1 )
{
foreach ( string xm in Zus )
{
Console . WriteLine ( xm );
}
}
Console . WriteLine ( "\n使用 SelectMany ( ):" );
foreach ( string xm in CHX2 )
{
Console . WriteLine ( xm );
}集合操作(C#)
在 LINQ 中,集合操作指的是基於同一或不同集合中相同或不同元素的存在與否而生成結果集的查詢操作。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。
| 方法名 | 説明 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| Distinct 或 DistinctBy | 從一個集合中移除重複的值。 | 不適用 | Enumerable . Distinct、Enumerable . DistinctBy、Queryable . Distinct、 Queryable . DistinctBy |
| Except 或 ExceptBy | 返回集合的差集,即表示一個集合中那些不在另一個集合中的元素。 | 不適用 | Enumerable . Except、Enumerable . ExceptBy、Queryable . Except、 Queryable . ExceptBy |
| Intersect 或 IntersectBy | 返回集合的交集,即指同時存在於兩個集合中的元素。 | 不適用 | Enumerable . Intersect、Enumerable . IntersectBy、Queryable . Intersect、Queryable . IntersectBy |
| Union 或 UnionBy | 返回集合的並集,即指在兩個集合中都出現過的唯一元素。 | 不適用 | Enumerable . Union、Enumerable . UnionBy、Queryable . Union、Queryable . UnionBy |
Distinct 和 DistinctBy
以下示例展示了 Enumerable . Distinct 方法對字符串序列的行為。返回的序列包含了輸入序列中的唯一元素。
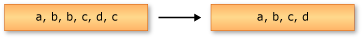
string [ ] Cis = [ "The" , "fast" , "brown" , "fox" , "jumped" , "over" , "the" , "lazy" , "dog" , "but" , "the" , "dog" , "showed" , "no" , "reaction" ];
IEnumerable < string > CHX = from c in Cis . Distinct ( )
select c;
foreach ( string c in CHX )
{
Console . WriteLine ( c );
}
/* 輸出(去掉了重複的 the 和 dog):
* The
* fast
* brown
* fox
* jumped
* over
* the
* lazy
* dog
* but
* showed
* no
* reaction
*/DistinctBy 是一種替代的 Distinct 方法,它需要一個鍵選擇器。該鍵選擇器用作源類型的比較判別器。在以下代碼中,根據單詞的長度對其進行區分,並顯示每個長度下的第一個單詞:
string [ ] Cis = [ "The" , "fast" , "brown" , "fox" , "jumped" , "over" , "the" , "lazy" , "dog" , "but" , "the" , "dog" , "showed" , "no" , "reaction" ];
IEnumerable < string > CHX = from c in Cis . DistinctBy ( c => c . Length )
select c;
foreach ( string c in CHX )
{
Console . WriteLine ( c );
}
/* 輸出:
* The
* fast
* brown
* jumped
* no
* reaction
*/Except 和 ExceptBy
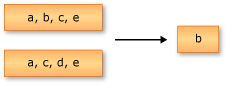
以下示例展示了 Enumerable . Except 的行為。返回的序列僅包含來自第一個輸入序列但不在第二個輸入序列中的元素。
string [ ] Cis1 = [ "那個" , "紅衣服" , "的" , "女孩" ];
string [ ] Cis2 = [ "那個" , "藍衣服" , "的" , "男孩" ];
IEnumerable < string > CHX = from c in Cis1 . Except ( Cis2 )
select c;
foreach ( string c in CHX )
{
Console . WriteLine ( c );
}
/* 輸出:
* 紅衣服
* 女孩
*/“ExceptBy” 方法是一種替代 “Except” 方法的實現方式,它接收兩個可能包含不同類型的序列以及一個 “鍵選擇器”。該鍵選擇器的類型與第一個集合的類型相同。以以下 “LEI教授” 數組和要排除的 教授ID 為例。若要找出第一個集合中不在第二個集合中的教授,可以將教授的 ID 投影到第二個集合上:
int [ ] EX教授 =
[
901,
965,
932,
945,
987,
901,
];
foreach ( LEI教授 js in 大學___C_ . Sources . 教授們 . ExceptBy ( EX教授 , js => js . JSID ) )
{
Console .WriteLine ( $"{js . 姓} {js . 名}" );
}在上述的 C# 代碼中:
- 對教授數組進行了篩選,只保留那些不在 “LEI教授排除數組” 中的教授。
- “教授排除數組” 包含了所有部門主管的 ID 值。
- 調用 “按排除條件取差集” 操作後,會得到一個新的值集合,並將其寫入控制枱。
這個新的值集合的類型為 “LEI教授”,與第一個集合的類型相同。教授數組中的每個教授,如果其在 “LEI教授排除數組” 中沒有對應的 ID 值,則會被寫入控制枱。
Intersect 和 IntersectBy
以下示例展示了 Enumerable . Intersect 方法的行為。返回的序列包含了兩個輸入序列中共同存在的元素。
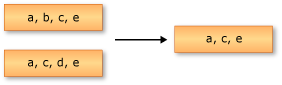
string [ ] zfc1 = [ "我" , "不怕" , "冷" ];
string [ ] zfc2 = [ "我" , "怕" , "冷" ];
IEnumerable < string > CHX = from z in zfc1 . Intersect ( zfc2 )
select z;
foreach ( string z in CHX )
{
Console . Write ( z ); // 我冷
}“IntersectBy” 方法是一種替代 “Intersect” 方法的實現方式,它接收兩個可能包含不同類型的序列以及一個鍵選擇器。該鍵選擇器將用作第二個集合類型的關鍵比較器。請看下面的 LEI學生 數組和 LEI教師 數組。該查詢會根據名稱在每個序列中匹配項,以找出那些既是學生又是教師的學生:
foreach ( LEI學生 xs in Sources . 學生們 . IntersectBy ( Sources . 教授們 . Select ( j => ( j . 姓 , j . 名 )) , x => ( x .姓 , x .名 ) ) )
{
Console . WriteLine ( $"{xs . 姓} {xs . 名}" ); // 歐陽 小強
}在上述的 C# 代碼中:
- 該查詢通過比較姓名來獲取教師們和學生們的交集。
- 只有同時存在於兩個數組中的人員才會出現在結果序列中。
- 生成的 “LEI學生” 實例會被寫入控制枱。
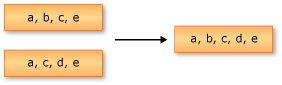
Union 和 UnionBy
以下示例展示了對兩個字符串序列進行的並集操作。返回的序列包含兩個輸入序列中的唯一元素。
string [ ] zfc1 = [ "周" , "星馳" , "的" , "電影" ];
string [ ] zfc2 = [ "周" , "星星" , "的" , "電視劇" ];
IEnumerable < string > CHX = from c in zfc1 . Union ( zfc2 )
select c;
foreach ( string z in CHX )
{
Console.WriteLine ( z );
}UnionBy 方法是 Union 方法的一種替代方式,它接收兩個相同類型的序列以及一個鍵選擇器。鍵選擇器用作源類型的比較判別器。以下查詢會生成所有既是學生又是教師的人員列表。那些既是學生又是教師的人員只會被添加到聯合集合中一次:
foreach ( var xs in Sources . 學生們 . Select ( s => ( s . 姓 , s . 名 ) ) . UnionBy ( Sources . 教授們 . Select ( t => ( 姓: t . 姓 , 名: t . 名 ) ) , s => ( s . 姓 , s . 名 ) ) )
{
Console . WriteLine ( $"{xs . 姓} {xs . 名}" );
}在上述的 C# 代碼中:
- 教師和學生的數組是通過使用他們的姓名作為關鍵選擇器而組合在一起的。
- 然後將生成的姓名寫入控制枱。
數據排序(C#)
排序操作會根據一個或多個屬性對序列中的元素進行排序。第一個排序標準會對元素進行主要排序。通過指定第二個排序標準,您可以對每個主要排序組內的元素進行排序。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。請查閲您的數據源的文檔。
以下示例展示了對一系列字符進行字母排序操作的結果:

在接下來的部分中列出了用於對數據進行排序的標準查詢操作方法。
方法
| 方法 | 説明 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| OrderBy 和 OrderByDescending | 按升序或降序排序值 | orderby 和 orderby … descending | Enumerable . OrderBy 和 Queryable . OrderBy 和 Enumerable . OrderByDescending 和 Queryable . OrderByDescending |
| ThenBy 和 ThenByDescending | 按升序或降序將值進行二次排序 | orderby … , … 和 orderby … , … descending | Enumerable . ThenBy 和 Queryable . ThenBy 和 Enumerable . ThenByDescending 和 Queryable . ThenByDescending |
| Reverse | 反轉集合中元素的順序 | 不支持 | Enumerable . Reverse 和 Queryable . Reverse |
基本升序排序
以下示例展示瞭如何在 LINQ 查詢中使用 “orderby” 子句,以按教授姓氏(升序)的順序對教授數組進行排序。
IEnumerable < string > CHX = from j in Sources . 教授們
orderby j . 姓
select j . 姓;
foreach ( string z in CHX )
{
Console . WriteLine ( z );
}使用方法語法編寫的等效查詢如下所示:
IEnumerable < string > CHX = Sources . 教授們
. OrderBy ( j => j . 姓 )
. Select ( j => j . 姓 );基本降序排序
接下來的示例展示瞭如何在 LINQ 查詢中使用 “orderby descending” 子句,按照姓氏對教授們進行降序排序。
IEnumerable < string > CHX = from j in Sources . 教授們
orderby j . 姓 descending
select j . 姓;使用方法語法編寫的等效查詢如下所示:
IEnumerable < string > CHX = Sources . 教授們
. OrderByDescending ( j => j . 姓 )
. Select ( j => j . 姓 );擴展的升序排序
以下示例展示瞭如何在 LINQ 查詢中使用 “orderby” 子句來執行主排序和次排序操作。教授們首先按城市進行升序排序,其次按姓氏進行升序排序。
IEnumerable < ( string , string ) > CHX = from j in Sources . 教授們
orderby j . 城市 , j . 姓
select ( j . 姓 , j . 城市 );
foreach ( ( string xing , string cs ) in CHX )
{
Console . WriteLine ( $"城市:{cs},姓:{xing}" );
}使用方法語法編寫的等效查詢如下所示:
IEnumerable < ( string , string ) > CHX = Sources . 教授們
. OrderBy ( j => j . 城市 )
. ThenBy ( j => j . 姓 )
. Select ( j => ( j . 姓 , j . 城市 ) );擴展的降序排序
以下示例展示瞭如何在 LINQ 查詢中使用 “orderby descending” 子句來執行主排序(升序)和次排序(降序)操作。教授們首先按城市進行升序排序,其次按姓氏進行降序排序。
IEnumerable < ( string , string ) > CHX = from j in Sources . 教授們
orderby j . 城市 , j . 姓 descending
select ( j . 姓 , j . 城市 );
foreach ( ( string xing , string cs ) in CHX )
{
Console . WriteLine ( $"城市:{cs},姓:{xing}" );
}使用方法語法編寫的等效查詢如下所示:
IEnumerable < ( string , string ) > CHX = Sources . 教授們
. OrderBy ( j => j . 城市 )
. ThenByDescending ( j => j . 姓 )
. Select ( j => ( j . 姓 , j . 城市 ) );LINQ(C#)中的量化操作
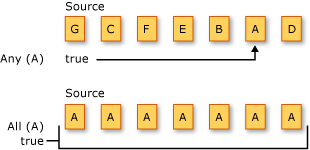
量化操作會返回一個布爾值,該值表示序列中的某些元素或所有元素是否滿足某個條件。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。請查閲您的數據源的文檔。
以下示例展示了對兩個不同源序列進行的兩種不同的量詞操作。第一種操作是詢問其中是否有任何元素是字符 “A”。第二種操作是詢問所有元素是否都是字符 “A”。在本示例中,這兩種方法的返回結果均為 “true”。
| 方法名 | 説明 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| All | 判斷序列中的所有元素是否都滿足某個條件 | 不支持 | Enumerable . All 和 Queryable . All |
| Any | 判斷序列中的任何元素是否滿足某個條件 | 不支持 | Enumerable . Any 和 Queryable . Any |
| Contains | 確定一個序列中是否包含指定的元素 | 不支持 | Enumerable . Contains 和 Queryable . Contains |
All
以下示例使用 “All” 選項來查找在所有考試中成績都超過 70 分的學生。
IEnumerable < string > CHX = from xs in Sources . 學生們
where xs . 分數 . All ( f => f > 70 )
select $"{xs . 姓}{xs . 名}:{string . Join ( "," , xs .分數 . Select ( xs => xs .ToString ( ) ) )}";
foreach ( string z in CHX )
{
Console . WriteLine ( z );
}Any
以下示例使用 “Any” 來查找在任何考試中得分超過 95 分的學生。
IEnumerable < string > CHX = from xs in Sources . 學生們
where xs . 分數 . Any ( f => f > 95 )
select $"{xs . 姓}{xs . 名}:{xs . 分數 . Max ( )}";
foreach ( string z in CHX )
{
Console . WriteLine ( z );
}Contains
以下示例使用 “Contains” 來查找在一次考試中成績恰好為 95 分的學生。
IEnumerable < string > CHX = from xs in Sources . 學生們
where xs . 分數 . Contains ( 95 )
select $"{xs . 姓}{xs . 名}:{string . Join( "," , xs . 分數 . Select ( xs => xs . ToString ( ) ) )}";
foreach ( string z in CHX )
{
Console . WriteLine ( z );
}數據分區(C#)
在 LINQ 中,分區操作是指將輸入序列劃分為兩個部分,不改變元素的順序,然後返回其中一個部分。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。請查閲您的數據源的文檔。
以下示例展示了對一系列字符執行的三種不同分區操作的結果。第一種操作返回序列中的前三個元素。第二種操作跳過前三個元素,並返回剩餘的元素。第三種操作跳過序列中的前兩個元素,並返回接下來的三個元素。

以下部分列出了用於對序列進行分區的標準查詢操作方法。
操作
| 方法名稱 | 描述 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| Skip | 跳過序列中指定位置之前的元素 | 不適用 | Enumerable . Skip 和 Queryable . Skip |
| SkipWhile | 根據謂詞函數跳過元素,直至遇到不滿足條件的元素為止 | 不適用 | Enumerable . SkipWhile 和 Queryable . SkipWhile |
| Take | 從序列中提取至指定位置的元素 | 不適用 | Enumerable . Take 和 Queryable . Take |
| TakeWhile | 根據謂詞函數選取元素,直至遇到不滿足條件的元素為止 | 不適用 | Enumerable . TakeWhile 和 Queryable . TakeWhile |
| Chunk | 將序列的元素分割成指定最大大小的塊 | 不適用 | Enumerable . Chunk 和 Queryable . Chunk |
以下所有示例均使用 Enumerable . Range ( Int32 , Int32 ) 來生成從 0 到 7 的數字序列。
注意:您可以參考 “標準查詢操作符概述” 這篇文章中關於此領域的常見數據源內容。
您使用 “take” 方法來獲取序列中的前幾個元素:
foreach ( int z in Enumerable . Range ( 0 , 8 ) . Take ( 3 ) )
{
Console . WriteLine ( z );
}您使用 “skip” 方法來跳過序列中的前幾個元素,並使用剩餘的元素:
foreach ( int z in Enumerable . Range ( 0 , 8 ) . Skip ( 3 ) )
{
Console . WriteLine ( z );
}TakeWhile 和 SkipWhile 方法也能夠在序列中選取和跳過元素。不過,這些方法並非基於固定數量的元素來實現跳過或選取操作,而是根據特定條件來決定。TakeWhile 方法會選取序列中的元素,直到遇到不符合條件的元素為止。
foreach ( int z in Enumerable . Range ( 0 , 8 ) . TakeWhile ( n => n < 5 ) )
{
Console . WriteLine ( z );
}“SkipWhile” 會跳過那些滿足條件的前幾個元素。只要條件成立,就會跳過這些前序元素,然後返回不符合條件的第一個元素以及之後的所有元素。
foreach ( int z in Enumerable . Range ( 0 , 8 ) . SkipWhile ( n => n < 5 ) )
{
Console . WriteLine ( z );
}“Chunk” 操作符用於根據給定的大小將序列中的元素進行拆分。
int ZHS分塊 = 1;
foreach ( int [ ] fk in Enumerable . Range ( 0 , 8 ) . Chunk ( 2 ) )
{
Console . WriteLine ( $"分塊 {ZHS分塊++}:" );
foreach ( int z in fk )
{
Console . WriteLine ( $" {z}" );
}
}前面的 C# 代碼:
- 通過調用 Enumerable . Range ( Int32 , Int32 ) 來生成一系列數字。
- 應用 Chunk 操作符,將序列分割成最大長度為 2 的塊。
數據類型轉換(C#)
轉換方法會改變輸入對象的類型。
重要事項:這些示例使用的是 System . Collections . Generic . IEnumerable < T > 數據源。基於 System . Linq . IQueryProvider 的數據源使用 System . Linq . IQueryable < T > 數據源和表達式樹。表達式樹在允許的 C# 語法方面存在限制。此外,每個 IQueryProvider 數據源(例如 EF Core)可能會施加更多的限制。請查閲您的數據源的文檔。
在 LINQ 查詢中進行的轉換操作在多種應用場景中都非常有用。以下是一些示例:
- “Enumerable . AsEnumerable” 方法可用於隱藏一個類型對標準查詢操作符的自定義實現。
- “Enumerable . OfType” 方法可用於使非參數化集合能夠用於 LINQ 查詢。
- “Enumerable . ToArray”、“Enumerable . ToDictionary”、“Enumerable . ToList” 和 “Enumerable . ToLookup” 這些方法可用於強制立即執行查詢操作,而不是將其推遲到查詢被枚舉時再執行。
方法
以下表格列出了用於執行數據類型轉換的標準查詢操作方法。
此表中那些名稱以 “As” 開頭的轉換方法會改變源集合的 static 類型,但不會對其進行枚舉。而那些名稱以 “To” 開頭的方法則會枚舉源集合,並將其中的項放入相應的集合類型中。
| 方法名稱 | 描述 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| AsEnumerable | 將輸入轉換為類型為 IEnumerable < T > 的對象 | 不適用 | Enumerable . AsEnumerable |
| AsQueryable | 將(通用)IEnumerable 轉換為(通用)IQueryable | 不適用 | Queryable . AsQueryable |
| Cast | 將集合中的元素轉換為指定類型 | 請使用顯式類型的範圍變量。例如:from string Ci in Cis | Enumerable . Cast 和 Queryable . Cast |
| OfType | 根據其能否轉換為指定類型的能力來篩選值 | 不適用 | Enumerable . OfType 和 Queryable . OfType |
| ToArray | 將集合轉換為數組。此方法會強制執行查詢操作 | 不適用 | Enumerable . ToArray |
| ToDictionary | 根據鍵選擇器函數將元素放入一個鍵值對 Dictionary ( TKey , TValue ) 中。此方法會強制執行查詢操作 | 不適用 | Enumerable . ToDictionary |
| ToList | 將集合轉換為 List ( T )。此方法會強制執行查詢操作 | 不適用 | Enumerable . ToList |
| ToLookup | 根據鍵選擇器函數將元素放入一個一對一 Lookup < TKey , TElement > 中。此方法會強制執行查詢操作 | 不適用 | Enumerable . ToLookup |
注意:本文中的以下示例均使用了該領域的常見數據源。
每個學生都有年級、主教學部門以及一系列成績。教師還擁有一個“城市”屬性,用於標識該教師授課的校區。部門有一個名稱,並且有一個指向擔任部門負責人的教師的引用。
查詢表達式語法示例
以下代碼示例使用了一個顯式類型的範圍變量,先將類型轉換為子類型,然後再訪問僅存在於子類型的成員。
IEnumerable XSs = Sources . 學生們;
var CHX = from LEI學生 xs in XSs
where xs . 年級 == GradeLevel . 三
select xs;
foreach ( LEI學生 x in CHX )
{
Console.WriteLine ( x . 姓 );
}可以用方法語法來表達等效的查詢,其示例如下所示:
IEnumerable XSs = Sources . 學生們;
var CHX = XSs
. Cast < LEI學生 > ( )
. Where ( xs => xs . 年級 == GradeLevel.四 );
foreach ( var x in CHX )
{
Console . WriteLine ( x . 姓 );
}在 LINQ 中的 join 操作
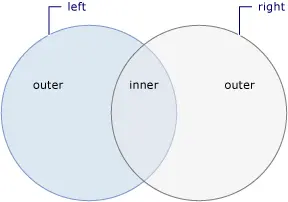
兩個數據源之間的連接是指一個數據源中的對象與另一個數據源中具有共同屬性的對象之間的關聯。
在針對那些彼此之間關係無法直接追蹤的數據源的查詢中,連接是一項重要的操作。在面向對象編程中,連接可能指的是對象之間不存在的關聯,比如單向關係的反向情況。單向關係的一個例子是 “LEI學生” 有一個類型為 “系” 的屬性,該屬性代表專業,但 “LEI系” 沒有包含一個由學生對象組成的集合的屬性。如果您有一組 “系” 對象,並且想要找到每個系中的所有學生,那麼就可以使用連接操作來實現這一目標。
LINQ 框架提供的連接方法是 “Join” 和 “GroupJoin”。這些方法執行等值連接,即根據兩個數據源的鍵是否相等來匹配這兩個數據源的連接方式(相比之下,Transact-SQL 支持除等於運算符之外的其他連接運算符,例如小於運算符)。在關係數據庫術語中,Join 實現了內連接,這是一種只返回在另一個數據集中有匹配項的對象的連接類型。GroupJoin 方法在關係數據庫術語中沒有直接對應的術語,但它實現了內連接和 left 外連接的超集。left 外連接是一種連接方式,它會返回第一個(left)數據源中的每個元素,即使在另一個數據源中沒有與其相關的元素。
以下示意圖展示了兩個集合的概念性視圖,以及這些集合中包含在內連接或左外連接中的元素。
方法
| 方法名稱 | 描述 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| 連接 | 根據鍵選擇器函數將兩個序列連接起來,並提取值對 | join … in … on … equals … | Enumerable . Join 和 Queryable . Join |
| GroupJoin | 根據鍵選擇器函數將兩個序列進行連接,並對每個元素的連接結果進行分組 | join … in … on … equals … into … | Enumerable . GroupJion 和 Queryable . GroupJoin |
以下示例使用 “join … in … on … equals …” 這一語句來根據特定值將兩個序列進行連接:
var CHX = from xs in Sources . 學生們
join x in Sources . 系 on xs .ID系 equals x .ID系
select new { 姓名 = $"{xs . 姓}{xs . 名}" , 系名 = x . 系名 };
foreach ( var s in CHX )
{
Console.WriteLine( $"{s .姓名} - {s .系名}" );
}上述查詢可以使用方法語法來表示,其示例代碼如下所示:
var CHX = Sources . 學生們 . Join ( Sources . 系 , xs => xs . ID系 , x => x .ID系 , ( xs , x ) => new { 姓名 = $"{xs . 姓}{xs .名}" , 系名 = x .系名} );
foreach ( var s in CHX )
{
Console.WriteLine( $"{s .姓名} - {s .系名}" );
}以下示例使用 “join … in … on … equals … into …” 這一語句來根據特定值連接兩個序列,並對每個元素的匹配結果進行分組:
IEnumerable < IEnumerable < LEI學生 > > XS組 = from x in Sources . 系
join xs in Sources . 學生們 on x . ID系 equals xs . ID系 into X組
select X組;
foreach ( IEnumerable < LEI學生 > xz in XS組 )
{
Console . WriteLine ( $"\n組:" );
foreach ( LEI學生 xs in xz )
{
Console . WriteLine ( $"{xs . 姓}{xs . 名}" );
}
}上述查詢可以使用方法語法來表達,其示例如下所示:
IEnumerable < IEnumerable < LEI學生 > > XS組 = Sources . 系 . GroupJoin ( Sources . 學生們 , x => x . ID系 , xs => xs .ID系 , ( x , xsZU ) => xsZU );
foreach ( IEnumerable < LEI學生 > xz in XS組 )
{
Console . WriteLine ( $"\n組:" );
foreach ( LEI學生 xs in xz )
{
Console . WriteLine ( $"{xs . 姓}{xs . 名}" );
}
}執行 inner join
在關係型數據庫術語中,inner join 會生成一個結果集,其中第一個集合中的每個元素都會與第二個集合中的每個匹配元素對應出現一次。如果第一個集合中的某個元素沒有匹配的元素,則它不會出現在結果集中。在 C# 中,通過 join 子句調用的 Join 方法實現了內連接。以下示例向您展示瞭如何執行四種不同類型的內連接:
- 一種簡單的 inner join,它根據一個簡單的鍵來關聯來自兩個數據源的元素。
- 一種基於複合鍵的 inner join。複合鍵是指由多個值組成的鍵,它使您能夠根據多個屬性來關聯元素。
- 一種將後續連接操作逐個連接在一起的多重連接。
- 通過使用組連接來實現的 inner join。
單鍵連接
以下示例將教授對象與系對象進行匹配,其中教授的 ID教授 與該教授的 JSID 相匹配。C# 中的 select 子句定義了生成的對象的外觀。在以下示例中,生成的對象是匿名類型,包含部門名稱和領導該部門的教授的姓名。
var CHX = from x in Sources . 系
join j in Sources . 教授們 on x . ID教授 equals j . JSID
select new
{
系名 = x . 系名,
教授名 = $"{j .姓}{j .名}",
};
foreach ( var x in CHX )
{
Console . WriteLine ( $"{x . 系名} → {x . 教授名}" );
}使用 “join” 方法的語法同樣可以達到相同的效果:
var CHX = Sources . 教授們 . Join ( Sources . 系 , j => j . JSID , x => x . ID教授 , ( j , x ) => new { 系名 = x . 系名 , 教授名 = $"{j . 姓}{j . 名}"} );那些並非部門負責人的教師不會出現在最終的成績表中。
複合鍵 join
與僅基於一個屬性進行元素關聯不同,您可以使用複合鍵根據多個屬性來比較元素。為每個集合指定鍵選擇器函數,以返回一個包含您要比較的屬性的匿名類型。如果為這些屬性設置了標籤,那麼它們在每個鍵的匿名類型中必須具有相同的標籤。這些屬性還必須以相同的順序出現。
以下示例使用了一個 “LEI教授” 對象列表和一個 “LEI學生” 對象列表,以確定哪些教授同時也是學生。這兩種類型的對象都具有表示每個人姓氏和名字的屬性。從每個列表的元素創建連接鍵的函數會返回一個匿名類型,該類型包含這些屬性。連接操作會比較這些複合鍵的相等性,並返回每個列表中同時滿足名字和姓氏匹配條件的對象對。
IEnumerable < string > CHX =
from js in Sources . 教授們
join xs in Sources . 學生們
on new
{
姓 = js . 姓,
名 = js . 名
}
equals new
{
xs . 姓,
xs . 名
}
select js . 姓 + js . 名;
string jg = "既是教授又是學生的:";
foreach ( string s in CHX )
{
jg += $"{s}\r\n";
}
Console . WriteLine ( jg );您可以使用 “join” 方法,如下面的示例所示:
IEnumerable < string > CHX = Sources . 教授們 . Join ( Sources . 學生們 , js => new { 姓 = js . 姓 , 名 = js . 名 }, xs => new { xs . 姓 , xs . 名 }, ( js , xs ) => $"{js . 姓}{js . 名}" );多重連接
可以在任意數量的連接操作之間進行組合,以實現多重連接。在 C# 中,每個連接子句都會將指定的數據源與前一個連接的結果進行關聯。
第一個連接子句根據 “LEI學生” 對象的 “LEI系ID” 與 “LEI系” 對象的 “XID” 進行匹配,從而將學生和部門關聯起來。它會返回一系列包含 “LEI學生” 對象和 “LEI系” 對象的匿名類型。
第二個連接子句將第一個連接操作返回的匿名類型與教師對象進行關聯,關聯依據是教授的 ID 與部門主管的 ID 相匹配。它會返回一系列包含學生姓名、部門名稱以及部門主管姓名的匿名類型。由於此操作為內連接,因此僅返回來自第一個數據源且在第二個數據源中存在匹配項的對象。
var CHX = from xs in Sources . 學生們
join x in Sources . 系 on xs . ID系 equals x . ID系
join j in Sources . 教授們 on x . ID教授 equals j . JSID
select new
{
學生名 = $"{xs . 姓}{xs . 名}",
x . 系名,
教授名 = $"{j . 姓}{j . 名}",
};
foreach ( var x in CHX )
{
Console . WriteLine ( $""""{x . 學生名}" - "({x . 系名})" 跟着 "{x . 教授名}"""" );
}使用多個 join 方法實現的效果與使用匿名類型的方法相同:
var CHX = Sources . 學生們
. Join ( Sources . 系 , xs => xs . ID系 , xi => xi . ID系, ( XS , XI ) => new { 學生 = XS , 系 = XI })
. Join ( Sources . 教授們 , 共有系 => 共有系 . 系 . ID教授 , 教授 => 教授 . JSID , ( GX , JS ) => new
{
學生名 = $"{GX . 學生 . 姓} {GX . 學生 . 名}",
GX . 系 . 系名,
教授名 = $"{JS.姓} {JS.名}"
});
foreach ( var x in CHX )
{
Console . WriteLine ( $"""""{x . 學生名}" - "({x . 系名})" 跟着 "{x . 教授名}""""" );
}通過使用分組連接實現內連接
以下示例向您展示瞭如何通過使用分組連接來實現內連接。系 對象列表與 學生 對象列表基於 “ID系” 與 “學生 . ID系” 屬性相匹配進行分組連接。分組連接會創建一箇中間組集合,其中每個組都包含一個部門對象和一系列匹配的學生對象。第二個 from 子句將這些序列序列合併(或展平)為一個更長的序列。選擇子句指定了最終序列中元素的類型。該類型是一個匿名類型,包含學生的姓名和匹配的部門名稱。
var CHX1 =
from xi in Sources . 系
join xs in Sources . 學生們 on xi . ID系 equals xs . ID系 into gj
from zxs in gj
select new
{
xi . 系名,
學生名 = $"{zxs . 姓} - {zxs .名}"
};
foreach ( var x in CHX1 )
{
Console . WriteLine ( $"{x . 系名}:{x . 學生名}" );
}同樣可以使用 “GroupJoin” 方法來實現相同的結果,具體步驟如下:
var CHX1 = Sources . 系
. GroupJoin ( Sources . 學生們 , xi => xi . ID系 , xs => xs . ID系 , ( xi , gj ) => new { xi , gj } )
. SelectMany ( xixs => xixs .gj , ( xixs , zxs ) => new
{
xixs . xi,
學生名 = $"{zxs . 姓} - {zxs .名}"
});
foreach ( var x in CHX1 )
{
Console . WriteLine ( $"{x . xi . 系名}:{x . 學生名}" );
}其結果與使用不帶 “into” 子句的連接子句來進行內連接所得到的結果集是等同的。以下代碼展示了這個等效的查詢:
var CHX2 = from xi in Sources . 系
join xs in Sources . 學生們 on xi .ID系 equals xs . ID系
select new
{
xi . 系名,
學生名 = $"{xs . 姓} - {xs . 名}"
};
foreach ( var x in CHX2 )
{
Console . WriteLine ( $"{x . 系名}:{x . 學生名}" );
}為避免鏈式調用,可以採用如上所示的單個 “join” 方法:
var CHX2 = Sources . 系 . Join ( Sources . 學生們 , xi => xi . ID系 , xs => xs . ID系 , ( XI , XS ) => new
{
XI . 系名,
學生名 = $"{XS . 姓} - {XS . 名}"
});執行分組連接
分組連接可用於生成層次化的數據結構。它會將第一個集合中的每個元素與第二個集合中的一組相關元素進行配對。
注意:在進行組連接操作時,第一個集合中的每個元素都會出現在結果集中,無論第二個集合中是否存在相關元素。如果未找到相關元素,則該元素的相關元素序列為空。因此,結果選擇器能夠訪問第一個集合中的所有元素。這與非組連接中的結果選擇器不同,在非組連接中,它無法訪問在第二個集合中沒有匹配項的第一個集合中的元素。
警告:Enumerable . GroupJoin 在傳統關係數據庫術語中沒有直接對應的概念。不過,此方法確實實現了內連接(Inner Join)和左外連接(Left Outer Join)的超集。這兩種操作都可以用分組連接的方式來表示。
本文中的第一個示例向您展示瞭如何進行組連接操作。第二個示例則向您展示瞭如何利用組連接來創建 XML 元素。
組連接
以下示例對類型為 “LEI系” 和 “LEI學生” 的對象進行了基於 “LEI系 . ID系” 與 “LEI學生 . ID系” 屬性相匹配的組連接操作。與非組連接不同,非組連接會為每次匹配生成一對元素,而組連接則會為第一個集合的每個元素僅生成一個結果對象(在本示例中為 “LEI系” 對象)。第二個集合中的對應元素(在本示例中為 “LEI學生” 對象)會組合成一個集合。最後,結果選擇器函數為每次匹配創建一個匿名類型,該類型包含 “LEI系” 名稱以及 “LEI學生” 對象的集合。
var CHX = from xi in Sources . 系
join xs in Sources . 學生們 on xi . ID系 equals xs . ID系 into XS組
select new
{
xi . 系名,
學生們 = XS組,
};
foreach ( var x in CHX )
{
Console . WriteLine ( $"{x . 系名}:" );
foreach ( LEI學生? xs in x .學生們 )
{
Console . WriteLine ( $" {xs .姓}{xs .名}" );
}在上述示例中,查詢變量包含了創建列表的查詢語句。該列表中的每個元素都是一個匿名類型,該類型包含部門名稱以及該部門內學習的學生集合。
使用方法語法進行等效查詢的示例如下所示:
var CHX = Sources . 系 . GroupJoin ( Sources . 學生們 , xi => xi . ID系 , xs => xs . ID系 , ( xi , xs ) =>
new
{
xi . 系名,
Sources . 學生們,
} );分組連接以生成 XML
分組連接非常適合通過使用 LINQ to XML 來創建 XML。以下示例與之前的示例類似,不同之處在於,結果選擇器函數不是創建匿名類型,而是創建代表連接對象的 XML 元素。
XElement XE系和學生 = new ( "系招生" ,
from xi in Sources . 系
join xs in Sources . 學生們 on xi . ID系 equals xs . ID系 into XS組
select new XElement ( "系" , new XAttribute ( "系名" , xi . 系名 ),
from xs in XS組
select new XElement ( "學生",
new XAttribute ( "姓" , xs . 姓 ),
new XAttribute ( "名" , xs . 名 ) )
)
);
Console . WriteLine ( XE系和學生 );使用方法語法進行等效查詢的示例如下所示:
XElement XE系和學生 = new ( "系招生" ,
Sources . 系 . GroupJoin ( Sources . 學生們 , xi => xi . ID系 , xs => xs . ID系 ,
( xi , xs ) => new XElement ( "系" , new XAttribute ( "系名" , xi . 系名 ) ,
from x in Sources . 學生們
select new XElement ( "學生" , new XAttribute ( "姓" , x .姓 ) , new XAttribute ( "名" , x .名 )
)
)
)
);
Console . WriteLine ( XE系和學生 );執行左外連接(left outer joins)
左外連接是一種連接方式,在這種連接中,第一個集合中的每個元素都會被返回,無論其在第二個集合中是否有對應的元素。您可以使用 LINQ 來執行左外連接,方法是調用分組連接結果的 DefaultIfEmpty 方法。
以下示例展示瞭如何在組連接的結果上使用 “DefaultIfEmpty” 方法來執行左外連接操作。
對兩個集合進行左外連接的第一步是使用分組連接來執行內連接操作。在本示例中,系對象列表與學生對象列表基於系對象的 ID系(該 ID 與學生的 ID系 相匹配)進行內連接。
第二步是將第一個(左側)集合中的每個元素都包含在結果集中,即便該元素在右側集合中沒有匹配項。這是通過對組連接中每組匹配元素的序列調用 “DefaultIfEmpty” 來實現的。在本示例中,對每個匹配的學生對象序列調用 “DefaultIfEmpty” 方法。該方法返回一個集合,如果任何 “系” 對象對應的匹配學生對象序列為空,則返回一個包含單個默認值的集合,從而確保每個 “系” 對象都能在結果集中得到體現。
注意:引用類型的默認值為 “null”;因此,該示例在訪問每個 “學生” 集合中的每個元素之前都會先檢查其引用是否為 “null”。
var CHX =
from xs in Sources . 學生們
join xi in Sources . 系 on xs . ID系 equals xi . ID系 into gj
from zz in gj . DefaultIfEmpty ( )
select new
{
xs . 姓,
xs . 名,
xi = zz? . 系名 ?? string . Empty,
};
foreach ( var x in CHX )
Console . WriteLine ( $"{x . 姓:-15}{x . 名:-15}:{x . xi}" );使用方法語法進行等效查詢的示例如下所示:
var CHX =
Sources . 學生們 . GroupJoin (
Sources . 系 , xs => xs . ID系 , xi => xi . ID系 ,
( xs , LB系 ) => new { xs , zz = LB系 } )
. SelectMany ( jb => jb . zz .DefaultIfEmpty ( ) , ( xs , xi ) => new
{
xs .xs .姓,
xs .xs .名,
xi = xi? . 系名 ?? string . Empty
} );數據分組(C#)
分組指的是將數據進行分組的操作,使得每個組中的元素都具有共同的屬性。以下示例展示了對一系列字符進行分組的結果。每個組的鍵是該字符。
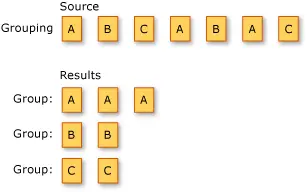
對數據元素進行分組的標準查詢操作方法列於下表中。
| 方法名 | 描述 | C# 查詢表達式語法 | 更多信息 |
|---|---|---|---|
| GroupBy | 根據具有相同屬性的元素進行分組。一個 IGrouping < TKey , TElement > 對象代表每個組 | group … by …… 或 group … by … into | Enumerable . GroupBy 和 Queryable . GroupBy |
| ToLookup | 根據鍵選擇器函數將元素插入到 Lookup < TKey , TElement >(一種一對多的字典)中 | 不適用 | Enumerable . ToLookup |
以下代碼示例使用分組語句根據整數列表中的數字是偶數還是奇數對其進行分組。
List < int > Zhss = [ 35 , 44 , 200 , 84 , 3987 , 4 , 199 , 329 , 446 , 208 ];
IEnumerable < IGrouping < int , int > > CHX =
from z in Zhss
group z by z % 2;
foreach ( var Zu in CHX )
{
Console . WriteLine ( $"{( Zu . Key == 0 ? "\n偶數" : "\n奇數" )}組:" );
foreach ( int z in Zu )
{
Console . WriteLine ( z );
}
}使用方法語法進行等效查詢的示例如下所示:
IEnumerable < IGrouping < int , int > > CHX =
Zhss .GroupBy ( z => z % 2 );分組查詢結果
分組是 LINQ 中最強大的功能之一。以下示例展示瞭如何以各種方式對數據進行分組:
- 通過單個屬性。
- 通過字符串屬性的第一個字母。
- 通過計算出的數值範圍。
- 通過布爾謂詞或其他表達式。
- 通過複合鍵。
此外,最後兩個查詢會將結果投影到一個新的匿名類型中,該類型僅包含學生的姓氏和名字。
按單個屬性分組示例
以下示例展示瞭如何根據元素的單個屬性對其進行分組,該屬性即為分組鍵。該鍵是一個枚舉類型,即學生的在校年級。分組操作使用該類型默認的相等性比較器。
var CHX年級分組 =
from xs in Sources . 學生們
group xs by xs . 年級 into nj
orderby nj . Key
select nj;
foreach ( var Zu in CHX年級分組 )
{
Console . WriteLine ( $"{Zu . Key} 組:" );
foreach ( var xs in Zu )
{
Console . WriteLine ( $"\t{xs .姓},{xs .名}" );
}
}使用方法語法的等效代碼示例如下所示:
var CHX年級分組 =
Sources . 學生們
. GroupBy ( xs => xs . 年級 )
. OrderBy ( nj => nj . Key );按值分組示例
以下示例展示瞭如何使用對象的屬性之外的其他內容作為分組鍵來對源元素進行分組。在本示例中,鍵是學生姓氏的首字母(符)。
var CHX姓氏首字符分組 =
from xs in Sources . 學生們
let szm = xs . 姓 [ 0 ]
group xs by szm;
foreach ( var Zu in CHX姓氏首字符分組 )
{
Console . WriteLine ( $"{Zu . Key} 組:" );
foreach ( var xs in Zu )
{
Console . WriteLine ( $"\t{xs .姓},{xs .名}" );
}
}需要使用嵌套的 “foreach” 語句才能訪問組中的各項內容。
使用方法語法的等效代碼示例如下所示:
var CHX姓氏首字符分組 = Sources . 學生們
. GroupBy ( xs => xs . 姓 [ 0 ] );
foreach ( var Zu in CHX姓氏首字符分組 )
{
Console . WriteLine ( $"{Zu . Key} 組:" );
foreach ( var xs in Zu )
{
Console . WriteLine ( $"\t{xs .姓},{xs .名}" );
}
}按範圍分組示例
以下示例展示瞭如何使用數字範圍作為分組鍵對源元素進行分組。然後,查詢會將結果投影到一個匿名類型中,該類型僅包含學生的姓氏和名字以及該學生所屬的百分位區間。使用匿名類型是因為沒有必要使用完整的 “LEI學生” 對象來顯示結果。FF獲取百分位數 是一個輔助函數,它根據學生的平均成績計算百分位數。該方法返回一個介於 0 到 10 之間的整數。
static int FF獲取分組區間 ( LEI學生 學生 )
{
double pjs = 學生 . 分數 . Any ( ) ? 學生 . 分數 . Average ( ) : 0;
return pjs > 0 ? ( int ) pjs / 10 : 0;
}
var CHX分組區間 =
from xs in Sources . 學生們
let qujianhao = FF獲取分組區間 ( xs )
group new
{
xs . 姓,
xs . 名,
} by qujianhao into ZU區間
orderby ZU區間 . Key
select ZU區間;
foreach ( var zu in CHX分組區間 )
{
Console . WriteLine ( $"\n{zu . Key * 10} ~ {( zu . Key + 1 ) * 10} 組:" );
foreach ( var x in zu )
{ Console . WriteLine ( $"{x . 姓},{x . 名}" ); }
}需要使用嵌套的 “foreach” 語句來遍歷組及其組內的項目。使用方法語法編寫的等效代碼如下所示:
static int FF獲取分組區間 ( LEI學生 學生 )
{
double pjs = 學生 . 分數 . Any ( ) ? 學生 . 分數 . Average ( ) : 0;
return pjs > 0 ? ( int ) pjs / 10 : 0;
}
var CHX分組區間 = Sources . 學生們
. Select ( xs => new { xs, qujianhao = FF獲取分組區間 ( xs ) } )
. GroupBy ( xs => xs . qujianhao )
. Select ( Zu區間 => new
{
Zu區間 . Key,
學生們 = Zu區間 . Select ( s => new { s . xs . 姓 , s . xs . 名 } )
})
.OrderBy ( percentGroup => percentGroup . Key );
foreach ( var zu in CHX分組區間 )
{
Console . WriteLine ( $"\n{zu . Key * 10} ~ {( zu . Key + 1 ) * 10} 組:" );
foreach ( var x in zu . 學生們 )
{ Console . WriteLine ( $"{x . 姓},{x . 名}" ); }
}按比較方式進行分組的示例
以下示例展示瞭如何使用布爾比較表達式對源元素進行分組。在本示例中,布爾表達式會檢驗學生的平均考試成績是否大於 75 分。與之前的示例一樣,結果會被投影到一個匿名類型中,因為不需要完整的源元素。匿名類型中的屬性會成為 Key 成員的屬性。
var CHX分數組 =
from xs in Sources . 學生們
let pjf = xs . 分數 . Any ( ) ? xs . 分數 . Average ( ) : 0
group new
{
xs . 姓,
xs . 名,
} by
pjf >= 90 ? "高分" : pjf >= 80 ? "中分" : "低分"
into ZU分數組
select ZU分數組;
foreach ( var zu in CHX分數組 )
{
Console . WriteLine ( $"平均分 {zu . Key}:" );
foreach ( var x in zu )
{ Console . WriteLine ( $"\t{x . 姓},{x . 名}" ); }
}使用方法語法進行等效查詢的示例如下所示的代碼中所示:
var CHX分數組 = Sources . 學生們
// 第一步:計算平均分,包裝學生信息和平均分
. Select ( xs => new
{
學生信息 = new { xs . 姓 , xs . 名 },
// 計算平均分:優先判斷是否有成績,避免空集合調用Average()報錯
// 兩種判斷方式均可:
// 1. Any ( ):檢查集合是否有任意元素,找到第一個就返回(O ( 1 ) 複雜度),對懶加載集合(如迭代器)更友好
// 2. Count ( ) > 0:檢查元素總數是否大於 0,對 List/數組 等(實現 ICollection)是直接取 Count 屬性(O ( 1 )),語義更直觀
// 兩者多數場景性能接近,根據集合類型和可讀性選擇即可
平均分 = xs . 分數 . Count != 0 ? xs . 分數 . Average ( ) : 0 // 平均分 = xs . 分數 . Any ( ) ? xs . 分數 . Average ( ) : 0
})
// 第二步:按平均分區間分組(分組鍵用嵌套三元運算符)
. GroupBy(
xs => xs . 平均分 >= 90 ? "高分" : // 先判斷是否≥90
xs . 平均分 >= 80 ? "中分" : // 否則判斷是否≥80
"低分" // 剩下的都是低分
)
// 可選:按“低分→中分→高分”排序(讓輸出更有邏輯)
. OrderBy ( zu => zu . Key switch
{
"低分" => 0,
"中分" => 1,
"高分" => 2,
_ => 3
});
// 輸出結果
foreach ( var zu in CHX分數組 )
{
Console . WriteLine ( $"平均分 {zu . Key}:" );
foreach ( var item in zu )
{
Console . WriteLine ( $"\t{item . 學生信息 . 姓},{item . 學生信息 . 名}" );
}
}按匿名類型分組
以下示例展示瞭如何使用匿名類型來封裝包含多個值的鍵。在本示例中,第一個鍵值是學生姓氏的首字母。第二個鍵值是一個布爾值,用於指示該學生在第一次考試中的得分是否超過 85 分。您可以根據鍵中的任何屬性對組進行排序。
// 匿名類型分組:按 “姓氏首字符” + “首門課是否 >90 分” 交叉分組
var CHX匿名分組 =
from xs in Sources . 學生們
// 分組依據:用匿名類型打包兩個條件(姓首、首門高分)
group xs by new
{
姓首 = xs . 姓 [ 0 ], // 條件1:姓氏首字符
首門高分 = xs . 分數 [ 0 ] >= 90 // 條件2:首門課是否 ≥ 90 分
} into XS分組
orderby XS分組 . Key . 姓首 // 按姓氏首字符排序,結果更整齊
select XS分組;
// 遍歷輸出:匿名類型的 Key 能直接訪問裏面的字段
foreach ( var zu in CHX匿名分組 )
{
var 高分説明 = zu.Key . 首門高分 ? "≥ 90 分" : "< 90 分";
// 直接用“zu . Key . 姓首”“zu . Key . 首門高分”訪問匿名類型的字段
Console . WriteLine ( $"姓氏首字符 [{zu . Key . 姓首}],首門課{高分説明}:" );
foreach ( var x in zu )
{
Console . WriteLine ( $"\t{x . 姓}{x . 名}" );
}
}使用方法語法進行等效查詢的示例如下所示:
// 匿名類型分組:按 “姓氏首字符” + “首門課是否 > 90 分” 交叉分組
var CHX匿名分組 = Sources . 學生們
// 分組依據:用匿名類型打包兩個條件(姓首、首門高分)
. GroupBy ( xs => new
{
姓首 = xs . 姓 [ 0 ], // 條件1:姓氏首字符
首門高分 = xs . 分數 [ 0 ] >= 90 // 條件2:首門課是否 ≥ 90 分
} )
. OrderBy ( XS分組 => XS分組 . Key . 姓首 ); // 按姓氏首字符排序,結果更整齊創建嵌套組
以下示例展示瞭如何在 LINQ 查詢表達式中創建嵌套組。根據學生的年級或年級水平創建的每個組,隨後還會根據個體的姓名進一步細分成不同的組。
// 嵌套組邏輯 : 先按姓氏首字符分大組 , 每個大組內再按首門課分數是否≥90分分小組
var CX嵌套組查詢 =
from xs in Sources . 學生們
// 第一步 : 按姓氏首字符分大組 , 用 “大組” 接收分組結果
group xs by xs . 姓 [ 0 ] into 大組
orderby 大組 . Key // 大組按姓氏首字符排序,結果更整齊
select new // 用匿名類型包裝 “大組信息” 和 “組內的小分組”
{
大組標識 = 大組 . Key , // 大組的唯一標識:姓氏首字符
// 第二步:在大組內部嵌套分組,按首門課是否 ≥90 分分小組
組內小分組 =
from 單個學生 in 大組 // 遍歷當前大組裏的每個學生
group 單個學生 by 單個學生 . 分數 [ 0 ] >= 90 into 小組
orderby 小組 . Key descending // 小組按 “是否高分” 排序,高分小組在前
select 小組
};
// 遍歷輸出:匿名類型的 Key 能直接訪問裏面的字段
foreach ( var zu in CX嵌套組查詢 )
{
var dz = zu . 大組標識;
Console . WriteLine ( $"大組標識 {dz}:" );
foreach ( var xz in zu . 組內小分組 )
{
var xz説明 = xz . Key ? "≥ 90 分的" : "< 90 分的";
Console . WriteLine ( $"\t{xz説明}:" );
foreach ( var xs in xz )
{
Console . WriteLine ( $"\t\t{xs . 姓}{xs . 名}" );
}
}
}需要三個嵌套的 foreach 循環來遍歷嵌套組的內部元素(將鼠標指針懸停在迭代變量 “outerGroup”、“innerGroup” 和 “innerGroupElement” 上,即可查看它們的實際類型)。
使用方法語法進行等效查詢的示例如下所示:
// 嵌套組邏輯 : 先按姓氏首字符分大組 , 每個大組內再按首門課分數是否 ≥90 分分小組
var CX嵌套組查詢 =
Sources . 學生們
// 第一步 : 按姓氏首字符分大組 , 用“大組”接收分組結果
. GroupBy ( xs => xs . 姓 [ 0 ] )
. OrderBy ( 大組 => 大組 . Key )
. Select ( 大組 => new
{
大組 . Key,
// 小組即為是否大於等於 90 分的分組
小組 = 大組
. GroupBy ( xs => xs .分數 [ 0 ] >= 90 )
. OrderByDescending ( 小組 => 小組 . Key )
} );對分組操作執行子查詢
本文展示了兩種不同的方法來創建一個查詢,該查詢會將源數據按組進行排序,然後對每個組分別執行子查詢。每個示例中的基本技術都是使用一個名為 “ZU新” 的延續來對源元素進行分組,然後針對 “ZU新” 生成一個新的子查詢。這個子查詢會針對外層查詢創建的每個新組運行。在這個特定的例子中,最終的輸出不是一組,而是一個由匿名類型組成的平鋪序列。
以下示例使用內存中的數據結構作為數據源,但這些原則適用於任何類型的 LINQ 數據源。
// 分組子查詢
var CHX =
from xs in Sources . 學生們
group xs by xs . 年級 into ZU年級
select new
{
nj = ZU年級 . Key,
fen高 =
( from xsg in ZU年級
select xsg . 分數 . Average ( ) ) . Max ( )
};
Console . WriteLine ( $"{ CHX . Count ( ) }" );
foreach ( var xs in CHX )
Console . WriteLine ( $" {xs . nj} 高分 = {xs . fen高}" );上述代碼片段中的查詢也可以使用方法語法來書寫。下面的代碼片段中使用了方法語法來編寫一個語義上等效的查詢。
var CHX方法 = Sources . 學生們
. GroupBy ( xs => xs . 年級)
. Select ( zu => new
{
nj = zu . Key,
fen高 = zu . Select ( xsg => xsg . 分數 . Average ( ) ) . Max ( )
} );如何:使用 LINQ 來查詢文件和目錄
許多文件系統操作本質上都是查詢操作,因此非常適合使用 LINQ 方法。這些查詢是非破壞性的。它們不會改變原始文件或文件夾的內容。查詢不應產生任何副作用。一般來説,任何修改源數據的代碼(包括執行創建/更新/刪除操作的查詢)都應與僅僅查詢數據的代碼分開。
創建一個能夠準確反映文件系統內容並能妥善處理異常情況的數據源涉及一定的複雜性。本節中的示例創建了一個 FileInfo 對象的快照集合,該集合代表指定根文件夾及其所有子文件夾下的所有文件。在執行查詢期間,每個 FileInfo 的實際狀態可能會發生變化。例如,您可以創建一個 FileInfo 對象列表用作數據源。如果在執行查詢的開始和結束之間嘗試訪問 Length 屬性,那麼 FileInfo 對象會嘗試訪問文件系統以更新 Length 的值。如果文件已不存在,您在查詢中就會收到一個 FileNotFoundException 異常,儘管您並非直接查詢文件系統。
如何查詢具有特定屬性或名稱的文件
此示例展示瞭如何在指定的目錄樹中查找具有特定文件名擴展名(例如 “.txt”)的所有文件。它還展示瞭如何根據創建時間返回樹中的最新或最舊文件。對於在 Windows、Mac 或 Linux 系統上運行此代碼的情況,您可能需要修改許多示例中的第一行內容。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
var wj所有 = wjj . GetFiles ( "*.*" , SearchOption . AllDirectories );
var CHX文本文件 = from wb in wj所有
where wb . Extension == ".txt"
orderby wb . Name
select wb;
foreach ( var wb in CHX文本文件 )
Console . WriteLine ( wb . Name );
var wb最新的 = ( from x in CHX文本文件
orderby x . CreationTime
select new { x . FullName , x . CreationTime } )
. LastOrDefault ( );
if ( wb最新的 != null )
Console . WriteLine ( $"\r\n最新的文本文件是 {wb最新的 . FullName},創建於 {wb最新的 . CreationTime}" );
else
Console . WriteLine ( "沒找到文本文件" );如何按擴展名對文件進行分組
此示例展示瞭如何使用 LINQ 在文件或文件夾列表上執行高級分組和排序操作。它還展示瞭如何通過使用 Skip 和 Take 方法在控制枱窗口中分頁顯示輸出。
以下示例展示瞭如何根據文件名擴展名對指定目錄樹中的內容進行分組。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
var wj所有 = wjj . GetFiles ( "*.*" , SearchOption . AllDirectories );
int Z縮減長度 = wjj . FullName . Length;
var CHX擴展名分組 =
from wj in wj所有
group wj by wj . Extension . ToLower ( ) into ZU擴展名
orderby ZU擴展名 . Count ( ) , ZU擴展名 . Key
select new
{
kzhm = ZU擴展名 . Key,
shl = ZU擴展名 . Count ( ),
wjlb = ZU擴展名,
};
foreach ( var z in CHX擴展名分組 . Take ( 5 ) ) // 僅選取前 5 個擴展名
{
Console . WriteLine ( $"擴展名:{z . kzhm}" );
Console . WriteLine ( $"具有該擴展名的文件總數:{z . shl}" );
var jg = z . wjlb . Take ( 20 ); // 每個擴展名僅列舉前 20 個文件
foreach ( var w in jg )
{
Console . WriteLine ( $"\t{w . FullName [ Z縮減長度.. ]}" );
}
}該程序的輸出結果可能會很長,這取決於本地文件系統的具體細節以及你列舉的 wjj 設置的值。為了能夠查看所有結果,此示例展示瞭如何分頁查看結果。由於每個組都是單獨進行枚舉的,所以需要一個嵌套的 foreach 循環。
如何查詢一組文件夾中的總字節數
此示例展示瞭如何獲取指定文件夾及其所有子文件夾中所有文件所佔用的總字節數。Sum 方法會將選擇子句中所選項目的值相加。您可以修改此查詢,通過調用 Min 或 Max 方法來獲取指定目錄樹中的最大或最小文件,而不再是使用 Sum 方法。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
var wj所有 = Directory . GetFiles ( wjj . FullName , "*.*" , SearchOption . AllDirectories );
var CHX文件長度 =
from wj in wj所有
let CD = new FileInfo ( wj ) . Length
where CD > 0
select CD;
long [ ] L文件長度s = [ .. CHX文件長度 ];
long D文件 = L文件長度s . Max ( );
long L總長度 = L文件長度s . Sum ( );
Console . WriteLine ( $"共有 {L總長度} 字節數({L文件長度s . Count ( )} 個文件)在 {wjj .FullName} 下:" );
Console . WriteLine ( $"最大的文件字節數是:{D文件}" );此示例是對前一個示例進行了擴展,其功能為:
- 如何獲取最大文件的字節數。
- 如何獲取最小文件的字節數。
- 如何從指定根文件夾下的一個或多個文件夾中檢索出最大或最小的 FileInfo 對象所代表的文件。
- 如何檢索諸如前 10 個最大文件這樣的序列。
- 如何根據文件的字節數(忽略小於指定大小的文件)將文件分組。
以下示例包含五個獨立的查詢,展示瞭如何根據文件的字節數(以 FileInfo 對象的形式)來查詢和分組文件。您可以修改這些示例,以便根據 FileInfo 對象的其他屬性來設置查詢條件。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
var wj所有 = Directory . GetFiles ( wjj . FullName , "*.*" , SearchOption . AllDirectories );
var CHX文件長 =
( from wj in wj所有
let w = new FileInfo ( wj )
where w . Length > 0
orderby w . Length descending
select w ) . FirstOrDefault ( );
if ( CHX文件長 != null )
Console . WriteLine ( $"在 {wjj . FullName} 文件夾中,最大的文件是:{CHX文件長 . Name},長度是:{FF轉換文件大小 ( CHX文件長 . Length)}" );
var CHX文件短 =
( from wj in wj所有
let w = new FileInfo ( wj )
where w . Length > 0
orderby w . Length
select w ) . FirstOrDefault ( );
if ( CHX文件短 != null )
Console . WriteLine ( $"在 {wjj . FullName} 文件夾中,最小的文件是:{CHX文件短 . Name},長度是:{FF轉換文件大小 ( CHX文件短 . Length)}" );
var CHX最大的10個文件 =
( from wj in wj所有
let w = new FileInfo ( wj )
let cd = w . Length
orderby cd descending
select w
) . Take ( 10 );
Console . WriteLine ( "最大的十個文件:" );
foreach ( var w in CHX最大的10個文件 )
Console . WriteLine ( $"{w . Name} - {FF轉換文件大小 ( w . Length )}" );
var CHX最小的10個文件 =
( from wj in wj所有
let w = new FileInfo ( wj )
let cd = w . Length
orderby cd
select w
) . Take ( 10 );
Console . WriteLine ( "最小的十個文件:" );
foreach ( var w in CHX最小的10個文件 )
Console . WriteLine ( $"{w . Name} - {FF轉換文件大小 ( w . Length )}" );
var CHX最小的10個有內容文件 =
( from wj in wj所有
let w = new FileInfo ( wj )
let cd = w . Length
where cd > 0
orderby cd
select w
) . Take ( 10 );
Console . WriteLine ( "最小的十個有內容的文件:" );
foreach ( var w in CHX最小的10個有內容文件 )
Console . WriteLine ( $"{w . Name} - {FF轉換文件大小 ( w . Length )}" );
var CHX組大小 =
from wj in wj所有
let w = new FileInfo ( wj )
let cd = w . Length
where cd > 0
group w by ( cd / ( 1024 * 1024 ) ) into ZU文件
where ZU文件 . Key >= 3
orderby ZU文件 . Key descending
select ZU文件;
foreach ( var z in CHX組大小 )
{
long L總大小 = z . Sum ( w => w . Length );
Console . WriteLine ( $"{FF轉換文件大小 ( z . Key * 1024 * 1024 )} ~ {FF轉換文件大小 ( ( z . Key + 1 ) * 1024 * 1024 )} - 共 {z . Count ( )} 個文件,總大小({FF轉換文件大小 ( L總大小 )})" );
foreach ( var w in z )
Console . WriteLine ( $"\t{w . Name} - {FF轉換文件大小 ( w . Length )}" );
}
long L所有文件空間 = CHX組大小 . SelectMany ( z => z ) . Sum ( w => w . Length );
int Z文件總數 = CHX組大小 . SelectMany ( z => z ) . Count ( );
Console . WriteLine ( $"\n總計:共 {Z文件總數} 個文件,總佔用空間 {FF轉換文件大小 ( L所有文件空間 )}。" );
static string FF轉換文件大小 ( long 字節數 )
{
if ( 字節數 >= Math . Pow ( 1024 , 3 ) )
return $"{字節數 / 1024.0 / 1024 / 1024:F2} 吉字節";
else if ( 字節數 >= Math . Pow ( 1024 , 2 ) )
return $"{字節數 / 1024.0 / 1024:F2} 兆字節";
else if ( 字節數 >= 1024 )
return $"{字節數 / 1024.0:F2} 千字節";
else
return $"{字節數} 字節";
}若要返回一個或多個完整的 FileInfo 對象,查詢首先必須在數據源中檢查每個對象,然後根據其 Length 屬性的值對它們進行排序。然後,它可以返回長度最大(小)的單個對象或一組對象。使用 First 可以返回列表中的第一個元素。使用 Take 可以返回前 n 個元素。指定降序排序順序,以便將最小的元素置於列表的開頭。
如何在目錄樹中查找重複文件
有時,具有相同名稱的文件可能會存在於多個文件夾中。此示例展示瞭如何在指定的根文件夾下查找此類重複文件名。第二個示例展示瞭如何查找大小和最後寫入時間也相同的文件。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
IEnumerable < FileInfo > lbwj = wjj . GetFiles ( "*.*" , SearchOption . AllDirectories );
int Z截取字符 = wjj . FullName . Length;
var CHX重名 = from wj in lbwj
group wj by wj . Name into ZU文件
where ZU文件 . Count ( ) > 1
select ZU文件;
foreach ( var z in CHX重名 )
{
Console . WriteLine ( $"重複文件 = {( z . Key == string . Empty ? "【無】" : z . Key )}" );
foreach ( var wj in z )
{
string LJ = wj . FullName . Substring ( Z截取字符 );
Console . WriteLine ( $" {LJ} - {FF轉換文件大小 ( wj . Length )}({wj . Length} 字節)" );
}
}第一個查詢通過一個關鍵字來確定匹配項。它會找出名稱相同但內容可能不同的文件。第二個查詢使用複合關鍵字來與 FileInfo 對象的三個屬性進行匹配。這個查詢更有可能找到名稱相同且內容相似或完全相同的文件。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
IEnumerable < FileInfo > lbwj = wjj . GetFiles ( "*.*" , SearchOption . AllDirectories );
int Z截取字符 = wjj . FullName . Length;
var CHX重名 = from wj in lbwj
group wj by new { 文件名 = wj . Name , 最後修改時間 = wj . LastWriteTime , 文件長度 = wj . Length } into ZU文件
where ZU文件 . Count ( ) > 1
select ZU文件;
foreach ( var z in CHX重名 )
{
Console . WriteLine ( $"重複文件 = {( z . Key . ToString ( ) == string . Empty ? "【無】" : z . Key )}" );
foreach ( var wj in z )
{
string LJ = wj . FullName . Substring ( Z截取字符 );
Console . WriteLine ( $" {LJ}" );
}
}如何查詢文件夾中文本文件的內容
此示例展示瞭如何查詢指定目錄樹中的所有文件,打開每個文件並檢查其內容。這種技術可用於創建目錄樹內容的索引或逆索引。在此示例中執行的是簡單的字符串搜索。然而,還可以使用正則表達式執行更復雜的模式匹配。
DirectoryInfo wjj = new ( @"F:\測試文件夾" );
IEnumerable < FileInfo > lbwj = wjj . GetFiles ( "*.*" , SearchOption .AllDirectories );
int Z截取字符 = wjj . FullName . Length;
string Zfc查找文本 = "我";
var CHX包含文本 = lbwj
. Where ( wj => wj . Extension . Equals ( ".txt" , StringComparison . OrdinalIgnoreCase ) ) // 忽略大小寫,匹配 .TXT/.Txt 等
. Where ( wj =>
{
using ( var wb = wj . OpenText ( ) ) // using 自動釋放文件流,避免佔用
{
return wb . ReadToEnd ( ) . Contains ( Zfc查找文本 );
}
} )
. ToList ( ); // 立即執行查詢,後續判斷是否有結果
if ( CHX包含文本 . Any ( ) )
{
Console . WriteLine ( $"包含 ‘{Zfc查找文本}’ 的文件有下列:" );
foreach ( var wj in CHX包含文本 )
{
string LJ = wj . FullName [ Z截取字符 .. ];
Console . WriteLine ( $" {LJ}" );
}
}
else
Console . WriteLine ( $"未找到包含‘{Zfc查找文本}’的文件。" );如何比較兩個文件夾中的內容
此示例展示了三種比較兩個文件列表的方法:
- 通過查詢一個布爾值,該值用於指定這兩個文件列表是否完全相同。
- 通過查詢交集來獲取同時存在於兩個文件夾中的文件。
- 通過查詢集合差集來獲取一個文件夾中但另一個文件夾中沒有的文件。
這裏展示的技術可以應用於比較任何類型的對象序列。
這裏展示的 “LEI比較文件” 類演示瞭如何將自定義比較器類與標準查詢運算符結合使用。該類並非為實際應用場景而設計。它只是根據每個文件的名稱和字節數來判斷每個文件夾的內容是否完全相同。在實際場景中,您應該修改這個比較器以執行更嚴格的相等性檢查(例如區別某兩個文本文件雖然文件名和大小都一致,但內容一個是 “你的”,一個是 “我的”)。
internal class LEI比較文件 : IEqualityComparer<FileInfo>
{
// 把根路徑變量名換成 Me/Lo 前綴(即第一個文件和另一個文件)
private readonly string _Me根路徑;
private readonly string _Lo根路徑;
// 構造函數參數名也對應調整,和變量名呼應
public LEI比較文件 ( string Me根路徑 , string Lo根路徑 )
{
// 標準化根路徑:確保以目錄分隔符結尾,避免計算相對路徑時出錯
_Me根路徑 = Path . GetFullPath ( Me根路徑 ) . TrimEnd ( Path . DirectorySeparatorChar )
+ Path . DirectorySeparatorChar;
_Lo根路徑 = Path . GetFullPath ( Lo根路徑 ) . TrimEnd ( Path . DirectorySeparatorChar )
+ Path . DirectorySeparatorChar;
}
public bool Equals ( FileInfo? Me , FileInfo? Lo )
{
if ( Me == null || Lo == null )
return Me == null && Lo == null;
// 計算相對路徑
string me相對路徑 = Path.GetRelativePath(_Me根路徑, Me.FullName);
string lo相對路徑 = Path.GetRelativePath(_Lo根路徑, Lo.FullName);
// 計算相對路徑時,用 Me/Lo 對應根路徑。統一路徑分隔符(避免 Windows 和 Linux 的斜槓差異,雖然多是 Windows,但保險)
string Me相對路徑 = Path . GetRelativePath ( _Me根路徑 , Me . FullName ) . Replace ( Path . DirectorySeparatorChar , '/' );
string Lo相對路徑 = Path . GetRelativePath ( _Lo根路徑 , Lo . FullName ) . Replace ( Path . DirectorySeparatorChar , '/' );
// 僅比較 Name 和 Length 的邏輯,只加了相對路徑判斷
bool xt = string . Equals ( Me相對路徑 , Lo相對路徑 , StringComparison . OrdinalIgnoreCase )
// && Me . Name == Lo . Name
&& Me . Length == Lo . Length;
return xt;
}
public int GetHashCode ( FileInfo 文件 )
{
// 計算文件相對於“自己所屬的根路徑”的相對路徑(關鍵!)
string 相對路徑 = FF關聯根目錄 ( 文件 );
var HX = $"{相對路徑}|{文件 . Length}" . GetHashCode ( );
return HX;
}
// 輔助方法:判斷文件屬於哪個根路徑,然後計算相對路徑
public string FF關聯根目錄 ( FileInfo 文件 )
{
string 完整路徑 = 文件 . FullName;
// 判斷文件屬於 Me根路徑 還是 Lo根路徑
if ( 完整路徑 . StartsWith ( _Me根路徑 , StringComparison . OrdinalIgnoreCase ) )
{
return Path . GetRelativePath ( _Me根路徑 , 完整路徑 ) . Replace ( Path . DirectorySeparatorChar , '/' );
}
else if ( 完整路徑 . StartsWith ( _Lo根路徑 , StringComparison . OrdinalIgnoreCase ) )
{
return Path . GetRelativePath ( _Lo根路徑 , 完整路徑 ) . Replace ( Path . DirectorySeparatorChar , '/' );
}
else
{
// 既不屬於 Me 也不屬於 Lo,直接返回完整路徑(避免異常)
return 完整路徑;
}
}
}
}如何對分隔文件中的字段進行重新排列
逗號分隔值(CSV)文件是一種常用於存儲電子表格數據或其他由行和列構成的表格數據的文本文件。通過使用 “拆分” 方法來分離字段,就可以使用 LINQ 來輕鬆查詢和處理 CSV 文件。實際上,同樣的技術也可以用於對任何結構化的文本行中的部分進行重新排列;它並不侷限於 CSV 文件。
在以下示例中,假設這三列分別代表學生的 “姓”、“名” 和 “ID”。這些字段是按照學生的姓氏進行字母排序的。該查詢會生成一個新的序列,其中 “ID” 列排在首位,隨後是另一個將學生的名字和姓氏組合在一起的列。各行按照 “ID” 字段進行重新排序。結果被保存到一個新的文件中,而原始數據不會被修改。以下文本展示了在上述示例中所使用的 “我的學生.csv” 文件的內容:

以下代碼會讀取源文件,並對 CSV 文件中的每一列進行重新排列,從而改變列的排列順序:
string [ ] zfc行 = File . ReadAllLines ( @"F:\測試文件夾\我的學生.csv" );
// 創建查詢。將字段 2 置前,並逆序排列。將字段 0 與字段 1 合併
var CHX學號排序 = from h in zfc行
let ls = h . Split ( ',' )
where !string . IsNullOrWhiteSpace ( h ) && ls . Length >= 3 // 確保行有效且字段足夠
orderby ls [ 2 ]
select $"{ls [ 2 ]},{ls [ 1 ]}{ls [ 0 ]}";
File . WriteAllLines ( @"F:\測試文件夾\我的學生(學號排序).csv" , [ .. CHX學號排序 ] , Encoding . UTF8 );
foreach ( var xs in CHX學號排序 )
Console . WriteLine ( xs );如何通過分組將一個文件拆分成多個文件
此示例展示了將兩個文件的內容合併,並創建一組以新方式組織數據的新文件的一種方法。該查詢使用了兩個文件的內容。以下文本展示了第一個文件 “mingzi 1.txt” 的內容:
an,ma
ma,an
li,jian
jian,li
wang,ming
ming,wang第二個文件 “mingzi 2.txt” 中包含了一組不同的名字,其中有一些與第一個名字列表中的名字是相同的:
ta,ke
ke,ta
li,jian
jian,li
dou,mei
mei,dou以下代碼會查詢這兩個文件,將兩個文件的內容進行合併,然後為每個以姓氏首字母為分組依據的組創建一個新的文件:
string wjA = @"F:\測試文件夾\mingzi 1.txt";
string wjB = @"F:\測試文件夾\mingzi 2.txt";
string [ ] wbA = File . ReadAllLines ( wjA );
string [ ] wbB = File . ReadAllLines ( wjB );
var CHX合併 = wbA . Union ( wbB );
var CHX組 = from mz in CHX合併
let m = mz . Split ( ',' ) [ 0 ]
group mz by m [ 0 ] into ZU
orderby ZU . Key
select ZU;
foreach ( var z in CHX組 )
{
string zfc文件名 = $@"F:\測試文件夾\mingzi {z .Key}.txt";
Console . WriteLine ( z . Key . ToString ( ) );
using StreamWriter xr = new ( zfc文件名 );
foreach ( var xm in z )
{
xr . Write ( xm );
Console . WriteLine ( $" {xm}" );
}
}如何合併來自不同文件的內容
此示例展示瞭如何將來自兩個以逗號分隔的文件中的數據進行合併,這兩個文件共享一個共同的值,該值用作匹配的關鍵字。如果需要將來自兩個電子表格的數據,或者來自電子表格和具有其他格式的文件的數據合併到一個新的文件中,此技術會很有用。您可以修改此示例以適用於任何類型的結構化文本。
以下文本展示了 fenshu.csv 文件的內容。該文件為電子表格數據。第 1 列是學生的學號,第 2 列至第 5 列分別是測試成績。
111, 97, 92, 81, 60
112, 75, 84, 91, 39
113, 88, 94, 65, 91
114, 97, 89, 85, 82
115, 35, 72, 91, 70
116, 99, 86, 90, 94
117, 93, 92, 80, 87
118, 92, 90, 83, 78
119, 68, 79, 88, 92
120, 99, 82, 81, 79
121, 96, 85, 91, 60
122, 94, 92, 91, 91以下文本展示了 mingzis.csv 文件的內容。該文件是一個電子表格,其中包含了學生的姓氏、名字以及學號。
Omelchenko,Svetlana,111
O'Donnell,Claire,112
Mortensen,Sven,113
Garcia,Cesar,114
Garcia,Debra,115
Fakhouri,Fadi,116
Feng,Hanying,117
Garcia,Hugo,118
Tucker,Lance,119
Adams,Terry,120
Zabokritski,Eugene,121
Tucker,Michael,122將包含相關信息的不相同文件中的內容進行合併。文件 “mingzis.csv” 包含了學生的姓名以及一個 ID 號碼。文件 “fenshu.csv” 包含了 ID 號碼和一組四門測試成績。以下查詢通過使用 ID 作為匹配鍵將成績與學生姓名進行合併。代碼如下所示:
string wjA = @"F:\測試文件夾\mingzis.txt";
string wjB = @"F:\測試文件夾\fenshu.txt";
string [ ] xzs = File . ReadAllLines ( wjA );
string [ ] fss = File . ReadAllLines ( wjB );
var CHX分數 = from mz in xzs
let ml = mz . Split ( ',' )
from id in fss
let fl = id . Split ( "," )
where Convert . ToInt32 ( ml [ 2 ] ) == Convert . ToInt32 ( fl [ 0 ] )
select $"{ml [ 0 ]},{fl [ 1 ]}{fl [ 2 ]}{fl [ 3 ]}{fl [ 4 ]}";
Console . WriteLine ( "\r\n合併兩個電子表格:" );
foreach ( string xm in CHX分數 )
{
Console . WriteLine ( xm );
}
Console . WriteLine ( $"總共 {CHX分數 . Count ( )} 個名字在列表中。" );如何在 CSV 文本文件中計算列值
此示例展示瞭如何對 .csv 文件中的列執行諸如求和、平均值、最小值和最大值等聚合計算。這裏展示的原則也可應用於其他類型的結構化文本。
以下文本展示了 fenshu.csv 文件的內容。假設第一列代表學生編號,後續各列則分別代表四次考試的成績。
111, 97, 92, 81, 60
112, 75, 84, 91, 39
113, 88, 94, 65, 91
114, 97, 89, 85, 82
115, 35, 72, 91, 70
116, 99, 86, 90, 94
117, 93, 92, 80, 87
118, 92, 90, 83, 78
119, 68, 79, 88, 92
120, 99, 82, 81, 79
121, 96, 85, 91, 60
122, 94, 92, 91, 91以下文本展示瞭如何使用 “Split” 方法將每行文本轉換為一個數組。每個數組元素代表一個列。最後,每個列中的文本會被轉換為其數值表示形式。
internal static class LEI計算列
{
public static void FF計算列 ( string 文件路徑 , string 分隔符 )
{
var CHX分列計算 = from h in FF矩陣 ( 文件路徑 , 分隔符 )
where h != null && h . Length > 1 // 過濾無效行
// 1. 先處理每行的每個元素:拆分成“內容、列索引、轉換後的數值、是否轉換成功”
from 元素 in h . Select ( ( item , index ) =>
{
// 在這裏完成數值轉換,並存到匿名對象裏
bool 轉換成功 = double . TryParse ( item , out double 數值 );
return new
{
內容 = item,
列索引 = index,
數值, // 轉換後的數值(無效時為0,但會被過濾)
轉換成功
};
} )
where 元素 . 列索引 > 0 // 只處理第2列及以後
where 元素 . 轉換成功 // 只保留轉換成功的數值
// 2. 按列索引分組,直接用匿名對象裏的“數值”
group 元素 . 數值 by 元素 . 列索引 into g
select new
{
標題 = $"例子#{g . Key}",
最低分 = g . Min ( ),
最高分 = g . Max ( ),
平均分 = Math . Round ( g . Average ( ) , 2 ),
總分 = g . Sum ( ),
};
foreach ( var e in CHX分列計算 )
{
Console . WriteLine ( $"{e . 標題}\t"
+ $"平均分:{e . 平均分 , 6}\t"
+ $"最高分:{e . 最高分 , 3}\t"
+ $"最低分:{e . 最低分 , 3}\t"
+ $"總 分:{e . 總分 , 5}" );
}
}
private static IEnumerable<string [ ]> FF矩陣 ( string 文件路徑 , string 分隔符 )
{
if ( !File . Exists ( 文件路徑 ) )
{
Console . WriteLine ( $"文件不存在:{文件路徑}" );
yield break;
}
// 若文件是 GB2312 編碼(比如中文 Excel 導出的 CSV),可換成 Encoding . Default
using StreamReader du = new ( 文件路徑 , Encoding . UTF8 );
for ( string? h = du . ReadLine ( ) ; h != null ; h = du . ReadLine ( ) )
{
if ( string . IsNullOrWhiteSpace ( h ) )
continue;
yield return h . Split ( 分隔符 , StringSplitOptions . TrimEntries );
}
}
}如何:使用 LINQ 查詢字符串
字符串是以字符序列的形式存儲的。作為字符序列,它們可以使用 LINQ 進行查詢。在本文中,有幾條示例查詢分別針對不同的字符或單詞查詢字符串、過濾字符串,或者將查詢與正則表達式相結合。
如何查詢字符串中的字符
以下示例會查詢一個字符串,以確定其中包含的數字字符數量。
string 目標字符串 = "Abc123Def45Ghi6!789";
Console . WriteLine ( $"原始字符串:{目標字符串}" );
int 數字字符數量 = 目標字符串
. Where ( 單個字符 => char . IsDigit ( 單個字符 ) )
. Count ( );
var 所有數字字符 = 目標字符串
. Where ( 單個字符 => char . IsDigit ( 單個字符 ) )
. Select ( 單個字符 => 單個字符 );
Console . WriteLine ( $"\n字符串中數字字符的總數:{數字字符數量}" );
Console . WriteLine ( $"字符串中的數字字符:{string . Join ( " , " , 所有數字字符 )}" );上述查詢展示瞭如何將一個字符串視為一系列字符。
如何統計字符串中某個單詞的出現次數
以下示例展示瞭如何使用 LINQ 查詢來統計指定單詞在字符串中的出現次數。要執行計數操作,首先調用 Split 方法來創建一個單詞數組。Split 方法存在一定的性能開銷。如果字符串上的唯一操作是統計單詞數量,那麼可以考慮使用 Matches 或 IndexOf 方法來替代。
string 目標文本 = "Hello hello! This is a test. Hello world, hello everyone.";
string 要統計的單詞 = "hello";
Console . WriteLine ( $"目標文本:{目標文本}\n" );
// 自定義分隔符(包含所有標點和空白字符)
char [ ] 分隔符 = new char [ ] { ' ' , ',' , '.' , '!' , '?' , ';' , ':' , '"' , '\'' , '\t' , '\n' };
// 方法 2 :先按分隔符拆分,再清理空項,確保 “hello!” 拆成 “hello”
int 忽略大小寫次數 = 目標文本
. Split ( 分隔符 , StringSplitOptions . RemoveEmptyEntries ) // 按標點和空格拆分
. Where ( 單詞 => string . Equals ( 單詞 , 要統計的單詞 , StringComparison . OrdinalIgnoreCase ) )
. Count ( );
// 方法 2 :先按分隔符拆分,再清理空項,確保 “hello!” 拆成 “hello”
int 不忽略大小寫次數 = 目標文本
. Split ( 分隔符 , StringSplitOptions . RemoveEmptyEntries ) // 按標點和空格拆分
. Where ( 單詞 => string . Equals ( 單詞 , 要統計的單詞 , StringComparison . Ordinal ) )
. Count ( );
// 方法 3(正則)本質是通過 “單詞邊界” 自動排除標點,結果更精準
string 正則表達式 = $@"\b{Regex . Escape ( 要統計的單詞 )}\b";
int 正則忽略大小寫匹配次數 = Regex . Matches ( 目標文本 , 正則表達式 , RegexOptions . IgnoreCase ) . Count;
int 正則不忽略大小寫匹配次數 = Regex . Matches ( 目標文本 , 正則表達式 , RegexOptions .None ) . Count;
Console . WriteLine ( $"優化後忽略大小寫統計(排除標點):{忽略大小寫次數} 次" );
Console . WriteLine ( $"不忽略大小寫統計(排除標點):{不忽略大小寫次數} 次" );
Console . WriteLine ( $"正則精準統計(自動排除標點,忽略大小寫):{正則忽略大小寫匹配次數} 次" );
Console . WriteLine ( $"正則精準統計(自動排除標點,不忽略大小寫):{正則不忽略大小寫匹配次數} 次" );上述示例展示瞭如何在將字符串拆分成一系列單詞之後,將字符串視為一系列單詞的形式進行查看。
如何根據任何單詞或字段對文本數據進行排序或篩選
以下示例展示瞭如何根據文本行中的任何字段對結構化文本(例如逗號分隔值)進行排序。該字段可以在運行時動態指定。假設 fenshu.csv 文件中的字段 1 代表學生的學號,隨後是四組測試成績:
string [ ] ZFC分數 = File . ReadAllLines ( @"F:\測試文件夾\fenshu.txt" );
int ZHS排序列 = 1;
Console . WriteLine ( $"從高到低排序的列 【{ZHS排序列}】" );
var CHX = from h in ZFC分數
let l = h . Split ( ',' )
where l . Length > ZHS排序列 && int . TryParse ( l [ZHS排序列] , out _ ) // 確保該行第一列存在並且可以轉換為 int
orderby int . Parse ( l [ ZHS排序列 ] ) descending // 確保是按照數值排序而不是字符串(否則可能會把 99 排在 100 前面)
select h;
foreach ( string z in CHX )
Console . WriteLine ( z );
Console . WriteLine ( );
// 統計並輸出無效行數量
int 無效行數 = ZFC分數 . Count ( h =>
{
var l = h . Split ( ',' );
return l . Length <= ZHS排序列 || !int . TryParse ( l [ ZHS排序列 ] , out _ );
} );
if ( 無效行數 > 0 )
Console . WriteLine ( $"(注:跳過 {無效行數} 行無效數據)\n" );上述示例展示瞭如何通過將字符串拆分成字段來對其進行處理,並對各個字段進行查詢。
如何查詢包含特定詞彙的句子
以下示例展示瞭如何在文本文件中查找包含指定詞彙集合中每個詞彙的句子。儘管搜索詞的數組是硬編碼的,但也可以在運行時動態填充。該查詢會返回包含 “Historically”、“data” 和 “integrated” 這些詞彙的句子。
string ZFC = """
Historically, the world of data and the world of objects
have not been well integrated. Programmers work in C# or Visual Basic
and also in SQL or XQuery. On the one side are concepts such as classes,
objects, fields, inheritance, and .NET APIs. On the other side
are tables, columns, rows, nodes, and separate languages for dealing with
them. Data types often require translation between the two worlds; there are
different standard functions. Because the object world has no notion of query, a
query can only be represented as a string without compile-time type checking or
IntelliSense support in the IDE. Transferring data from SQL tables or XML trees to
objects in memory is often tedious and error-prone.
""";
string [ ] Jus = ZFC . Split ( [ '.' , '?' , '!' ] );
string [ ] Ci匹配 = [ "Historically", "data", "integrated" ];
char [ ] ZF分隔符 = [ '.' , '?' , '!' , ' ' , ';' , ':' , ',' ];
var CHX = from j in Jus
let ci = j . Split ( ZF分隔符 , StringSplitOptions.RemoveEmptyEntries )
where ci . Distinct ( ) . Intersect ( Ci匹配 ) . Count ( ) == Ci匹配 . Count ( )
select j;
foreach ( string j in CHX )
Console . WriteLine ( j );該查詢首先將文本拆分成句子,然後將每個句子拆分成一個包含每個單詞的字符串數組。對於這些數組中的每一個,Distinct 方法會去除所有重複的單詞,然後該查詢會對單詞數組和 Ci匹配 數組執行交集操作。如果交集的單詞數量與 Ci匹配 數組的單詞數量相同,則表示所有單詞都已找到,並返回原始句子。
在調用 “Split” 函數時,會使用標點符號作為分隔符,以將這些標點符號從字符串中去除。例如,如果您沒有去除標點符號,那麼比如字符串 “Historically” 就無法與 “Ci匹配” 數組中的 “Historically” 相匹配。根據源文本中所包含的標點類型,您可能需要使用額外的分隔符。
如何將 LINQ 查詢與正則表達式相結合
以下示例展示瞭如何使用 Regex 類來創建用於文本字符串中更復雜匹配的正則表達式。通過 LINQ 查詢,您可以輕鬆地僅篩選出您希望用正則表達式進行搜索的文件,並對結果進行定製。
string zfc文件夾 = @"C:\Program Files\dotnet\sdk";
// 創建文件系統的快照
var CHX文件列表 = from zfcwj in Directory . GetFiles ( zfc文件夾 , "*.*" , SearchOption . AllDirectories )
let wj = new FileInfo ( zfcwj )
select wj;
// 創建正則表達式以查找所有包含“Visual”字樣的內容
Regex chazhaoxiang = ZZX ( );
/*
* 搜索每個 .htm 文件的內容。
* 刪除“where”子句以找到更多的匹配值!
* 此查詢會生成一個包含已找到匹配項的文件列表,以及該文件中的匹配值列表。
* 注意:在選擇子句中明確指定“Match”。
* 這是必需的,因為 匹配集合 不是通用的 IEnumerable 集合。
*/
var CHX匹配文件 =
from wj in CHX文件列表
where wj . Extension == ".txt"
let wb文本文件 = File . ReadAllText ( wj . FullName )
let pipeis = chazhaoxiang . Matches ( wb文本文件 )
where pipeis . Count > 0
select new
{
文件名 = wj . FullName,
匹配值 = from Match pp in pipeis
select pp . Value
};
Console . WriteLine ( $"""“{chazhaoxiang}” 被找到,在:""" );
foreach ( var v in CHX匹配文件 )
{
string z = v . 文件名 . Substring ( zfc文件夾 .Length - 1 );
Console . WriteLine ( z );
foreach ( var zhi in v . 匹配值 )
{
Console . WriteLine ( $" {zhi}" );
}
}
partial class Program
{
[GeneratedRegex ( @"microsoft.net.(sdk|workload)" )]
private static partial Regex ZZX ( );
}您還可以查詢由正則表達式搜索返回的 匹配集合 對象。在結果中僅會生成每個匹配項的值。不過,也可以使用 LINQ 對該集合進行各種篩選、排序和分組操作。由於 匹配集合 是一個非泛型的 IEnumerable 集合,所以在查詢中您必須明確指定範圍變量的類型。
LINQ 與集合
大多數集合都表示一系列元素。您可以使用 LINQ 來查詢任何集合類型。其他 LINQ 方法可在集合中查找元素、根據集合中的元素計算值,或者修改集合或其元素。這些示例將幫助您瞭解 LINQ 方法以及如何將它們與您的集合或其他數據源一起使用。
如何找出兩個列表之間的集合差值
此示例展示瞭如何使用 LINQ 來比較兩個字符串列表,並輸出那些在第一個列表中存在但在第二個列表中不存在的行。第一個包含姓名的列表存儲在文件 “mingzi 1.txt” 中,第二個姓名列表存儲在文件 “mingzi 2.txt” 中(隨意寫幾個名字):
劉備、關羽、張飛、曹操、孫權……
string [ ] mingzi1 = File . ReadAllLines ( @"F:\測試文件夾\mingzi 1.txt" );
string [ ] mingzi2 = File . ReadAllLines ( @"F:\測試文件夾\mingzi 2.txt" );
// 創建查詢。此處必須使用方法語法
var CHX差別1 = mingzi1 . Except ( mingzi2 );
var CHX差別2 = mingzi2 . Except ( mingzi1 );
// 執行查詢
Console . WriteLine ( "第一個名字列表中有但第二個沒有的:" );
foreach ( string z1 in CHX差別1 )
Console . WriteLine ( z1 );
Console . WriteLine ( "第二個名字列表中有但第一個沒有的:" );
foreach ( string z2 in CHX差別2 )
Console . WriteLine ( z2 );某些類型的查詢操作,例如 “差集(Except)”、“去重”(Distinct)、“並集”(Union) 和 “連接(Concat)”,只能以基於方法的語法形式來表達。
如何合併和比較字符串集合
此示例展示瞭如何合併包含文本行的文件,並對結果進行排序。具體而言,它展示瞭如何對這兩組文本行執行連接、並集和交集操作。它使用了與前面示例中相同的兩個文本文件。代碼展示了Enumerable . Concat、Enumerable . Union 和 Enumerable . Except 的示例。
string [ ] mingzi1 = File . ReadAllLines ( @"F:\測試文件夾\mingzi 1.txt" );
string [ ] mingzi2 = File . ReadAllLines ( @"F:\測試文件夾\mingzi 2.txt" );
var CHX連接 = mingzi1 . Concat ( mingzi2 ) . OrderBy ( m => m );
FF輸出查詢結果 ( CHX連接 , "單純的連接並排序。保留重複項:" );
var CHX並集 = mingzi1 . Union ( mingzi2 ) . OrderBy ( m => m );
FF輸出查詢結果 ( CHX並集 , "並集並移除重複項:" );
var CHX重複 = mingzi1 . Intersect ( mingzi2 );
FF輸出查詢結果 ( CHX重複 , "基於交集進行合併:" );
// 在每個列表中找到對應的字段。使用 “Concat” 函數將兩個結果合併起來,然後使用默認的字符串比較器進行排序。
string zfc匹配名字 = "曹";
var CHX1 = from xm in mingzi1
let x = !string . IsNullOrEmpty ( xm ) && xm . Length > 0 ? xm [ 0 ] . ToString ( ) : ""
where x == zfc匹配名字
select xm;
var CHX2 = from xm in mingzi2
let x = !string . IsNullOrEmpty (xm ) && xm . Length > 0 ? xm [ 0 ] . ToString ( ) : ""
where x == zfc匹配名字
select xm;
var CHX連接12 = CHX1 . Concat ( CHX2 ) . OrderBy ( m => m );
FF輸出查詢結果 ( CHX連接12 , $"基於姓名中的姓匹配進行連接操作(兩個列表中的):{zfc匹配名字}" );
static void FF輸出查詢結果 ( IEnumerable < string > 查詢 , string 信息 )
{
Console . WriteLine ( $"{Environment . NewLine}{信息}" );
foreach ( var xm in 查詢 )
{
Console . WriteLine ( xm );
}
Console . WriteLine ( $"總共 {查詢 . Count ( )} 名字被列出" );
}如何從多個來源填充對象集合
此示例展示瞭如何將來自不同來源的數據合併到一系列新的類型中。
注意:切勿將內存中的數據、文件系統中的數據與仍存於數據庫中的數據進行跨域連接。由於數據庫查詢和其他類型數據源的連接操作定義方式可能存在差異,這種跨域連接可能會導致結果不明確。此外,如果數據庫中的數據量過大,這種操作還可能引發內存不足的異常。要將數據庫中的數據與內存中的數據進行連接,首先對數據庫查詢調用 ToList 或 ToArray 方法,然後在返回的集合上執行連接操作。
此示例使用了兩個文件。其中第一個文件名為 “names.csv”,其中包含了學生的姓名和學生編號。另一個文件名為 “fenshus.txt”,其中包含了學生的編號和四門功課的成績。
string [ ] mingzis = File . ReadAllLines ( @"F:\測試文件夾\mingzis.txt" );
string [ ] fenshus = File . ReadAllLines ( @"F:\測試文件夾\fenshus.txt" );
IEnumerable<LEI學生> CHX名字和分數 = from mzh in mingzis
let mz分隔 = mzh . Split ( ',' )
from fsh in fenshus
let fs分隔 = fsh . Split( "," )
where mz分隔 [ 2 ] == fs分隔 [ 0 ]
select new LEI學生
{
姓 = mz分隔 [ 0 ],
名 = mz分隔 [ 1 ],
XSID = mz分隔 [ 2 ],
分數 = fs分隔 . Skip ( 1 ) // 跳過第一個(XSID),取後面的分數
. Select ( fs => int . TryParse ( fs , out int num ) ? num : 0 ) // 加個轉換保護
. ToList ( ),
年級 = default, // 非必需屬性,給默認值
ID系 = 0 // 非必需屬性,給默認值
};
foreach ( var xs in CHX名字和分數 )
{
Console .WriteLine ( $"{xs . 姓}{xs . 名},平均分:{xs .分數 . Average ( )}" );
}在 “select” 子句中,每個新的 “LEI學生” 對象都是根據這兩個數據源中的信息進行初始化的。
如果您無需存儲查詢的結果,那麼使用元組或匿名類型會比使用命名類型更為便捷。以下示例與上一個示例執行的任務相同,但使用了元組而非命名類型:
string [ ] mingzis = File . ReadAllLines ( @"F:\測試文件夾\mingzis.txt" );
string [ ] fenshus = File . ReadAllLines ( @"F:\測試文件夾\fenshus.txt" );
var CHX名字和分數 = from nameLine in mingzis
let splitName = nameLine . Split ( ',' )
from scoreLine in fenshus
let splitScoreLine = scoreLine . Split ( ',' )
where Convert . ToInt32 ( splitName [ 2 ] ) == Convert . ToInt32 ( splitScoreLine [ 0 ] )
select ( 姓: splitName [ 0 ],
名: splitName [ 1 ],
分數: ( from scoreAsText in splitScoreLine . Skip ( 1 )
select Convert . ToInt32 ( scoreAsText ) )
. ToList ( )
);
foreach ( var student in CHX名字和分數 )
{
Console . WriteLine ( $"{student . 姓}{student . 名} 的平均分:{student . 分數 . Average ( )}" );
}如何使用 LINQ 查詢 ArrayList
在使用 LINQ 來查詢非泛型的 IEnumerable 集合(例如 ArrayList)時,您必須明確聲明範圍變量的類型,以反映集合中對象的具體類型。如果您有一個包含 Student 對象的 ArrayList,您的 from 子句應如下所示:
var CHX = from LEI學生 xs in arrList
通過指定範圍變量的類型,您正在將 ArrayList 中的每個元素轉換為 “LEI學生” 類型。
在查詢表達式中使用具有明確類型定義的範圍變量相當於調用 Cast 方法。如果指定的轉換無法執行,Cast 會拋出異常。Cast 和 OfType 是兩個作用於非通用的 IEnumerable 類型的標準查詢操作方法。
// 模擬可能包含空值的數據(比如 名 為 null、分 為空)
List < LEI學生 > xs = new ( )
{
new LEI學生 ( "Svetlana" , "Omelchenko" , [ 98 , 92 , 81 , 60 ] ),
new LEI學生 ( "Claire" , null , [75, 84, 91, 39] ), // 名 為 null
new LEI學生 ( null , "Mortensen" , null ), // 姓 為 null,分數 為 null
new LEI學生 ( "Cesar" , "Garcia" , [ ]) // 分數 為 null 數組
};
// 增加空值檢查:篩選第一門分數>95的學生,同時處理各種空值情況
var query = xs
.Where(s => s != null // 確保學生對象不為 null
&& s.考試分數 != null // 確保分數數組已初始化
&& s.考試分數 . Length > 0 // 確保數組有元素
&& s.考試分數 [ 0 ] > 95 ); // 分數條件
foreach ( LEI學生 s in query )
Console . WriteLine ( s . 姓 + ": " + s . 考試分數 [ 0 ] );如何擴展 LINQ
所有基於 LINQ 的方法都遵循兩種類似模式之一。它們接收一個可枚舉序列。它們要麼返回一個不同的序列,要麼返回一個單個值。這種形狀的一致性使您能夠通過編寫具有類似形狀的方法來擴展 LINQ。實際上,自 LINQ 首次推出以來,.NET 庫在許多 .NET 版本中新增了新的方法。在本文中,您將看到通過編寫遵循相同模式的自定義方法來擴展 LINQ 的示例。
為 LINQ 查詢添加自定義方法
您通過向 IEnumerable < T > 接口添加擴展方法來擴展您用於 LINQ 查詢的方法集。例如,除了標準的平均值或最大值操作之外,您還可以創建一個自定義聚合方法,以從一系列值中計算出一個單一值。您還創建了一個作為自定義篩選器或特定數據轉換的、針對一系列值的方法,並返回一個新的序列。此類方法的示例包括 Distinct、Skip 和 Reverse。
當您擴展了 IEnumerable < T > 接口後,就可以將您自定義的方法應用於任何可枚舉的集合。
聚合方法會從一組值中計算出一個單一的值。LINQ 提供了多種聚合方法,包括平均值、最小值和最大值。您可以通過向 IEnumerable < T > 接口添加擴展方法來創建自己的聚合方法。
從 C# 14 版本開始,您可以聲明一個擴展塊來包含多個擴展成員。通過使用關鍵字 “extension” 並後跟括號中的接收參數來聲明擴展塊。以下代碼示例展示瞭如何在一個擴展塊中創建一個名為 “FF中位數” 的擴展方法。該方法用於計算雙精度數值序列的中位數。
double [ ] yuan = [ 2.5 , 60.2 , 1.4 , 7.6 , 3.6 , 3.4 ];
if ( yuan is null || yuan . Length == 0 )
{
throw new InvalidOperationException ( "無法計算一個空表的中位數。" );
}
var px = yuan . OrderBy ( z => z ) . ToList ( );
int sy = px . Count / 2;
if ( px . Count % 2 == 0 )
{
Console . WriteLine ( ( px [ sy ] + px [ sy + 1 ] / 2 ) );
}
else
{
Console . WriteLine ( px [ sy ] );
}您還可以將 “this” 修飾符添加到靜態方法中,以聲明擴展方法。以下代碼展示了等效的 “FF中位數” 擴展方法:
double [ ] yuan = [ 2.5 , 60.2 , 1.4 , 7.6 , 3.6 , 3.4 ];
if ( yuan is null || yuan . Length == 0 )
{
throw new InvalidOperationException ( "無法計算一個空表的中位數。" );
}
var px = yuan . OrderBy ( z => z ) . ToList ( );
int sy = ( px . Count ) / 2;
Console . WriteLine ( $"{( sy % 2 == 0 ? px [ sy ] : ( px [ sy ] + px [ sy - 1 ]) / 2 )}" );對於任何可枚舉集合,您都可以像調用 IEnumerable < T > 接口中的其他聚合方法那樣調用這兩種擴展方法。
以下代碼示例展示瞭如何對類型為 double 的數組使用 “中位數” 方法。
static void Main ( string [ ] args )
{
double [ ] yuan = [ 2.5 , 60.2 , 1.4 , 7.6 , 3.6 , 3.4 ];
Console . WriteLine ( FF中位數 ( yuan ) );
}
public static double FF中位數 ( this IEnumerable < double >? 源 )
{
if ( 源 is null || !源 . Any ( ) )
{
throw new InvalidOperationException ( "無法計算一個空表的中位數。" );
}
var px = 源 . OrderBy ( z => z ) . ToList ( );
int 長度 = px . Count;
int sy = 長度 / 2;
// 用數組長度判斷奇偶,更準確
return ( 長度 % 2 == 1 ? px [ sy ] : ( px [ sy - 1 ] + px [ sy ] ) / 2 );
}您可以對聚合方法進行重載,使其能夠接受各種類型的序列。標準的方法是為每種類型創建一個重載版本。另一種方法是創建一個重載版本,該版本接受一個泛型類型,並通過使用委託將其轉換為特定類型。您還可以將這兩種方法結合起來使用。
您可以為想要支持的每種類型創建一個特定的重載方法。以下代碼示例展示了針對整型類型“Median”方法的一個重載版本。
public static double Median ( this IEnumerable < double > yuan )
{
return ( from z in yuan select ( double ) z ) . FF中位數 ( );
}現在您可以對整型和雙精度型數據調用中位數的重載函數,如以下代碼所示:
double [ ] yuan = [ 2.5 , 60.2 , 1.4 , 7.6 , 3.6 , 3.4 ];
Console . WriteLine ( yuan . FF中位數 ( ) );
int [ ] yuan1 = [ 2 , 4 , 5 , 8 , 10 ];
Console . WriteLine ( yuan1 . FF中位數 ( ) );您還可以創建一個能夠接受泛型對象序列的重載方法。這個重載方法將一個委託作為參數,並使用該委託將泛型類型的對象序列轉換為特定類型。
以下代碼展示了 “FF中位數” 方法的一個重載版本,該版本將 Func < T , TResult > 委託作為參數。此委託接收具有通用類型 T 的對象,並返回類型為 double 的對象。
public static double FF中位數 < T >
(
this IEnumerable < T > SJDs , Func < T , double > xzq ) =>
( from s in SJDs select xzq ( s )
) . FF中位數 ( );現在,您可以對任何類型的對象序列調用 “FF中位數” 方法。如果該類型沒有自身的方法重載,則您必須傳遞一個委託參數。在 C# 中,您可以使用 lambda 表達式來實現此目的。此外,在 Visual Basic 中,僅當您使用 “Aggregate” 或 “GroupBy” 子句而非方法調用時,您可以傳遞此子句作用域內的任何值或表達式。
以下示例代碼展示瞭如何對整數數組和字符串數組調用 “FF中位數” 方法。對於字符串,會計算數組中字符串長度的中位數。該示例展示瞭如何為每種情況將 Func < T , TResult > 委託參數傳遞給 “FF中位數” 方法。
/*
您可以將 num => num 這樣的 lambda 表達式用作 FF中位數 方法的參數,這樣編譯器會自動將其值轉換為 double 類型。
如果沒有自動轉換,則編譯器會顯示錯誤消息。
*/
int [ ] ZHSs = [ 1 , 2 , 3 , 4 , 5 ];
var CHX中位數數值 = ZHSs . FF中位數 ( z => z );
Console . WriteLine ( $"int:中位數 = {CHX中位數數值}" );
string [ ] ZFCs = [ "One" , "Two" , "Three" , "Four" , "Five" ];
var CHX中位數字符串 = ZFCs . FF中位數 ( z => z . Length );
Console . WriteLine ( $"string:中位數 = {CHX中位數字符串}" );您可以通過自定義查詢方法來擴展 IEnumerable < T > 接口,該方法會返回一系列值。在這種情況下,該方法必須返回類型為 IEnumerable < T > 的集合。此類方法可用於對一系列值應用篩選或數據轉換操作。
以下示例展示瞭如何創建一個名為 “FF交替元素” 的擴展方法,該方法能夠從集合中的第一個元素開始,返回每個間隔一個的元素。
static void Main ( string [ ] args )
{
int [ ] ZHSs = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ];
foreach ( int z in FF替代元素 ( ZHSs ) )
{
Console . WriteLine ( z );
}
}
public static IEnumerable < T > FF替代元素 < T > ( this IEnumerable < T > 源 )
{
int sy = 0;
foreach ( T ys in 源 )
{
if ( sy % 2 == 0 )
{
yield return ys;
}
sy++;
}
}您可以對任何可枚舉集合調用此擴展方法,就像調用 IEnumerable < T > 接口中的其他方法一樣,如以下代碼所示:
string [ ] ZFCs = [ "a" , "b" , "c" , "d" , "e" , "f" , "g" ];
foreach ( string z in FF替代元素 ( ZFCs ) )
{
Console . WriteLine ( z );
}本文中所展示的每個示例都有不同的接收方。這意味着每個方法都必須在不同的擴展塊中聲明,並且這些擴展塊需明確指定唯一的接收方。以下代碼示例展示了一個單一的 static 類,其中包含三個不同的擴展塊,每個擴展塊都包含本文中定義的其中一個方法:
public static class EnumerableExtension
{
extension ( IEnumerable < double >? source )
{
public double FF中位數 ( )
{
if (source is null || !source.Any ( ) )
{
throw new InvalidOperationException ( "不能計算 null 或空表的中位數。" );
}
var sortedList =
source . OrderBy ( n => n ) . ToList ( );
int itemIndex = sortedList . Count / 2;
if ( sortedList . Count % 2 == 0 )
{
// Even number of items.
return ( sortedList [ itemIndex ] + sortedList [ itemIndex - 1 ]) / 2;
}
else
{
// Odd number of items.
return sortedList [ itemIndex ];
}
}
}
extension ( IEnumerable < int > source )
{
public double FF中位數 ( ) =>
( from n in source select ( double ) number ) . FF中位數 ( );
}
extension < T > ( IEnumerable < T > source )
{
public double FF中位數 ( Func < T , double > selector ) =>
( from n in source select selector ( n ) ) . FF中位數 ( );
public IEnumerable < T > AlternateElements ( )
{
int index = 0;
foreach ( T element in source )
{
if ( index % 2 == 0 )
{
yield return element;
}
index++;
}
}
}
}最後的擴展塊定義了一個通用的擴展塊。接收者的類型參數是在擴展塊自身中聲明的。
上述示例中,在每個擴展塊中都聲明瞭一個擴展成員。在大多數情況下,您會為同一個接收者創建多個擴展成員。在這些情況下,您應當在一個單獨的擴展塊中為這些成員聲明擴展內容。
基於運行時狀態的查詢
在大多數 LINQ 查詢中,查詢的總體結構是在代碼中設定的。您可能會使用 where 子句進行篩選,使用 orderby 對輸出集合進行排序,對項目進行分組,或者執行一些計算。您的代碼可能會為過濾器提供參數,或者為排序鍵提供參數,或者提供查詢中的其他表達式。然而,查詢的整體結構不能改變。在本文中,您將學習使用 System . Linq . IQueryable < T > 接口及其實現類型來在運行時修改查詢的結構的技術。
您利用這些技術在運行時構建查詢,此時某些用户輸入或運行時狀態會改變您希望用於查詢的查詢方法。您需要通過添加、刪除或修改查詢條款來編輯查詢。
注意:請務必在您的.cs 文件頂部添加以下語句:using System . Linq . Expressions; 和 using static System . Linq . Expressions . Expression;。
考慮一下這樣一段代碼:它針對某個數據源定義了一個 IQueryable 或者是一個 IQueryable < T > 。
string [ ] ZFC公司名s = [
"Consolidated Messenger" , "Alpine Ski House" , "Southridge Video" , "City Power & Light" , "Coho Winery" , "Wide World Importers" , "Graphic Design Institute" , "Adventure Works" , "Humongous Insurance" , "Woodgrove Bank" , "Margie's Travel" , "Northwind Traders" , "Blue Yonder Airlines" , "Trey Research" , "The Phone Company" , "Wingtip Toys" , "Lucerne Publishing" , "Fourth Coffee"
];
// 使用內存中的數組作為數據源,但這個 IQueryable 可以來自任何地方 - 可以是基於數據庫的 ORM、網絡請求,或者任何其他的 LINQ 提供者。
IQueryable < string > CHX公司名源 = ZFC公司名s . AsQueryable ( );
var CHX修復查詢 = ZFC公司名s . OrderBy ( x => x );
foreach ( var g in CHX修復查詢 )
{
Console . WriteLine ( g );
}每次運行上述代碼時,都會執行完全相同的查詢。讓我們來學習如何修改、擴展或調整這個查詢。從根本上説,IQueryable 有兩個組成部分:
- 表達式 - 一種與語言無關且與數據源無關的、以表達式樹形式呈現的當前查詢組件的表示形式。
- 提供者 - 一種 LINQ 提供程序的實例,它知道如何將當前查詢轉換為一個值或一組值。
在動態查詢的上下文中,提供者通常是固定的;但查詢的表達式樹會因查詢的不同而有所差異。
表達式樹是不可變的;如果您想要一個不同的表達式樹(從而實現一個不同的查詢),則需要將現有的表達式樹轉換為新的表達式樹。以下各節將介紹針對運行時狀態進行不同查詢的具體技術:
- 在表達式樹中使用運行時狀態
- 調用更多的 LINQ 方法
- 改變傳遞給 LINQ 方法的表達式樹
- 使用 Expression 工廠方法構建 Expression < TDelegate > 表達式樹
- 向 IQueryable 的表達式樹添加方法調用節點
- 構造字符串,並使用動態 LINQ 庫
每種技術都能實現更多的功能,但都會帶來複雜度的增加。
在表達式樹中使用運行時狀態
進行動態查詢最簡單的方法是通過一個閉包變量直接在查詢中引用運行時狀態,例如在以下代碼示例中的 “CD”:
string [ ] ZFC公司名s = [
"Consolidated Messenger" , "Alpine Ski House" , "Southridge Video" , "City Power & Light" , "Coho Winery" , "Wide World Importers" , "Graphic Design Institute" , "Adventure Works" , "Humongous Insurance" , "Woodgrove Bank" , "Margie's Travel" , "Northwind Traders" , "Blue Yonder Airlines" , "Trey Research" , "The Phone Company" , "Wingtip Toys" , "Lucerne Publishing" , "Fourth Coffee"
];
int CD = 1;
var CHX = ZFC公司名s . Select ( g => g [ ..CD ] ) . Distinct ( );
Console . WriteLine ( string . Join ( "," , CHX ) );
CD = 2;
Console . WriteLine ( string . Join ( "," , CHX ) );內部的表達式樹(以及整個查詢)並未發生任何改變;查詢返回不同的值僅僅是因為長度的值發生了變化。
調用更多 LINQ 方法
通常,Queryable 中的內置 LINQ 方法會執行兩個步驟:
- 將當前表達式樹包裹在一個表示方法調用的 MethodCallExpression 中。
- 將包裹後的表達式樹返回給提供者,要麼通過提供者的 IQueryProvider . Execute 方法返回一個值;要麼通過 IQueryProvider . CreateQuery 方法返回一個轉換後的查詢對象。
您可以用一個返回 System . Linq . IQueryable < T > 類型結果的方法的結果來替換原始查詢,以獲得一個新的查詢。您可以使用運行時狀態,如下例所示:
string [ ] ZFC公司名s = [
"Consolidated Messenger" , "Alpine Ski House" , "Southridge Video" , "City Power & Light" , "Coho Winery" , "Wide World Importers" , "Graphic Design Institute" , "Adventure Works" , "Humongous Insurance" , "Woodgrove Bank" , "Margie's Travel" , "Northwind Traders" , "Blue Yonder Airlines" , "Trey Research" , "The Phone Company" , "Wingtip Toys" , "Lucerne Publishing" , "Fourth Coffee"
];
var CHX = ZFC公司名s . Select ( g => g ) . Distinct ( );
var CHXCD = CHX . OrderBy ( g => g . Length );
foreach ( var g in CHXCD )
{
Console . WriteLine ( g );
}改變傳遞給 LINQ 方法的表達式樹
您可以根據運行時狀態向 LINQ 方法傳入不同的表達式:
string [ ] ZFC公司名s = [
"Consolidated Messenger" , "Alpine Ski House" , "Southridge Video" , "City Power & Light" , "Coho Winery" , "Wide World Importers" , "Graphic Design Institute" , "Adventure Works" , "Humongous Insurance" , "Woodgrove Bank" , "Margie's Travel" , "Northwind Traders" , "Blue Yonder Airlines" , "Trey Research" , "The Phone Company" , "Wingtip Toys" , "Lucerne Publishing" , "Fourth Coffee"
];
// 可自定義過濾條件(示例:以 "T" 開頭或以 "s" 結尾)
string? ZFC起始 = "T"; // 如不需要開頭過濾,可設為 null 或空字符串
string? ZFC結束 = "s"; // 如不需要結尾過濾,可設為 null 或空字符串
// 根據過濾條件動態生成表達式
Expression < Func < string , bool > > bds = ( ZFC起始 , ZFC結束 ) switch
{
( "" or null , "" or null ) => x => true, // 無過濾條件時匹配所有
( _ , "" or null ) => x => x . StartsWith ( ZFC起始 ), // 僅開頭過濾
( "" or null , _ ) => x => x . EndsWith ( ZFC結束 ), // 僅結尾過濾
( _ , _ ) => x => x . StartsWith ( ZFC起始 ) || x . EndsWith ( ZFC結束 ) // 開頭或結尾過濾
};
// 應用過濾、去重、按長度排序並輸出
var qry = ZFC公司名s . AsQueryable ( ) . Where ( bds ) . Distinct ( );
var result = qry . OrderBy ( g => g . Length );
foreach ( var item in result )
{
Console . WriteLine ( item );
}您或許還希望使用諸如 LinqKit 的 PredicateBuilder 這樣的其他庫來組合各個子表達式:
string [ ] ZFC公司名s = [
"Consolidated Messenger" , "Alpine Ski House" , "Southridge Video" , "City Power & Light" , "Coho Winery" , "Wide World Importers" , "Graphic Design Institute" , "Adventure Works" , "Humongous Insurance" , "Woodgrove Bank" , "Margie's Travel" , "Northwind Traders" , "Blue Yonder Airlines" , "Trey Research" , "The Phone Company" , "Wingtip Toys" , "Lucerne Publishing" , "Fourth Coffee"
];
// 可自定義過濾條件(示例:以 "T" 開頭或以 "s" 結尾)
string? ZFC起始 = "T"; // 如不需要開頭過濾,可設為 null 或空字符串
string? ZFC結束 = "s"; // 如不需要結尾過濾,可設為 null 或空字符串
// 根據過濾條件動態生成表達式
Expression < Func < string , bool > > ? bds = PredicateBuilder . New < string > ( false );
var yuanshi = bds;
if ( !string . IsNullOrEmpty ( ZFC起始 ) )
{
bds = bds . Or ( x => x . StartsWith ( ZFC起始 ) );
}
if ( !string . IsNullOrEmpty ( ZFC結束 ) )
{
bds = bds . Or ( x => x . EndsWith ( ZFC結束 ) );
}
if ( bds == yuanshi )
{
bds = x => true;
}
var CHX = ZFC公司名s . AsQueryable ( ) . Where ( bds ) . Distinct ( );
// 應用過濾、去重、按長度排序並輸出
var result = CHX . OrderBy ( g => g . Length );
foreach ( var item in result )
{
Console . WriteLine ( item );
}使用工廠方法(通過方法生成對象)構建表達式樹和查詢
在上述所有示例中,您在編譯時就已經知道了元素類型(即字符串),因此也知道查詢的類型(即 IQueryable < string >)。您可以向任何元素類型的查詢中添加組件,或者根據元素類型添加不同的組件。您可以從頭開始使用 System . Linq . Expressions . Expression 中的工廠方法創建表達式樹,從而在運行時根據特定的元素類型定製表達式。
構建表達式 < TDelegate >
當您構建一個要傳遞給 LINQ 方法的表達式時,實際上您是在構建 System . Linq . Expressions . Expression < TDelegate > 的實例,其中 TDelegate 是某種委託類型,例如 Func < string , bool >、Action 或自定義委託類型。
System . Linq . Expressions . Expression < TDelegate > 類繼承自 LambdaExpression 類,後者代表一個完整的 lambda 表達式,如下例所示:
Expression < Func < string , bool > > bds x => x . StartWith ( “a” )
一個 Lambda 表達式包含兩個組成部分:
- 一個參數列表 - (string x) - 由 “Parameters” 屬性表示。
- 一個主體 - x . StartWith ( “a” ) - 由 “Body” 屬性表示。
構建 Expression < TDelegate > 的基本步驟如下:
- 針對 lambda 表達式中的每個參數(如果有的話),使用 “Parameters” 工廠方法來定義相應的參數表達式對象。
ParameterExpression x = Parameter ( typeof ( string ) , "x" ); -
使用所定義的參數表達式以及 Expression 中的工廠方法來構建您的 Lambda 表達式主體。例如,表示 “x 開頭為 'a'” 的表達式可以這樣構建:
Expression 表達式主體 = Expression . Call ( 參數_x, typeof ( string ) . GetMethod ( "StartsWith" , [ typeof( string ) ] )!, Expression . Constant ( "a" ) ); // 包裝成 Lambda 表達式 Expression < Func < string , bool > > 檢查是否以a開頭 = Expression . Lambda < Func < string , bool > > ( 表達式主體 , 參數_x ); // 執行測試 Func < string , bool > 執行檢查 = 檢查是否以a開頭 . Compile ( ); bool 結果 = 執行檢查( "apple" ); // 返回 true("apple" 以 "a" 開頭) Console . WriteLine ( 結果 );將參數和主體封裝在一個具有編譯時類型約束的 Expression < TDelegate > 對象中,使用相應的 Lambda 工廠方法重載形式:
Expression < Func < string , bool > > bds = Lambda < Func < string , bool > > ( body , x );
以下各節描述了一個場景,在該場景中您可能需要構建一個 “Expression < TDelegate >” 對象,以便將其傳遞給 LINQ 方法。它提供了一個使用工廠方法進行此操作的完整示例。在運行時構建完整的查詢
您希望編寫能夠處理多種實體類型的查詢:
record JL人 ( string 姓 , string 名 , DateTime 生日 ); record JL車 (string 型號 , int 出廠年份 );對於任何此類實體類型,您都需要篩選並僅返回那些在其字符串字段中包含特定文本的實體。對於“Person”類型,您需要搜索“FirstName”和“LastName”屬性:
JL人 [ ] yuangong = [ new JL人 ( "李" , "秀玲" , new DateTime (2002 , 12 , 15 ) ), new JL人 ( "李" , "壽芸" , new DateTime (2003 , 2 , 5 ) ), new JL人 ( "梅" , "花開" , new DateTime (2008 , 8 , 9 ) ), new JL人 ( "張" , "綵鳳" , new DateTime (2006 , 3 , 3 ) ), ]; string CZ = "李"; var CHX = yuangong . AsQueryable ( ) . Where ( x => x . 姓 . Contains ( CZ ) || x . 名 . Contains ( CZ ) ); foreach ( JL人 r in CHX ) Console . WriteLine ( r );但對於 JL車 而言,您只需搜索 “型號” 這一屬性即可:
JL車 [ ] wodeche = [ new JL車 ( "沃爾沃 S80" , 2005 ), new JL車 ( "比亞迪 漢" , 2022 ), new JL車 ( "比亞迪 唐" , 2021 ), new JL車 ( "小刀" , 2023 ), ]; string CZ = "比"; var CHX = wodeche . AsQueryable ( ) . Where ( x => x . 型號 . Contains ( CZ ) ); foreach ( JL車 ch in CHX ) Console . WriteLine ( ch ); }雖然您可以為 IQueryable < JL人 > 編寫一個自定義函數,同時為 IQueryable < JL車 > 編寫另一個函數,但以下這個函數能夠將這種篩選功能添加到任何現有的查詢中,而無需考慮具體的數據類型。
var CHX人 = FF文本過濾 ( yuangong . AsQueryable ( ), "李" ) . Where ( x => x . 生日 < new DateTime ( 2003 , 1 , 1 ) ); foreach ( JL人 r in CHX人 ) Console . WriteLine ( r ); var CHX車 = FF文本過濾 ( wodeche . AsQueryable ( ), "比" ) . Where ( x => x . 出廠年份 < 2022 ); foreach ( JL車 che in CHX車 ) Console . WriteLine ( che );向 IQueryable < TDelegate > 的表達式樹中添加方法調用節點
如果您擁有的是 IQueryable 而不是 IQueryable < T >,則無法直接調用泛型 LINQ 方法。一種替代方法是按照前面的示例構建內部表達式樹,並使用反射來調用相應的 LINQ 方法,並將表達式樹作為參數傳入。
您還可以通過將整個樹包裹在一個表示對 LINQ 方法調用的 FF方法調用表達式 中來實現與 LINQ 方法相同的功能:
static IQueryable FF文本過濾無類型 ( IQueryable yuan , string chazhao )
{
if ( string . IsNullOrEmpty ( chazhao ) )
{
return yuan;
}
Type LX元素類型 = yuan . ElementType;
( Expression? ZhuTi, ParameterExpression? CS表達式 ) = FF結構主體 ( LX元素類型 , chazhao );
if ( ZhuTi is null )
{
return yuan;
}
Expression Shu過濾 = Call (
typeof ( Queryable ),
"Where",
[ LX元素類型 ],
yuan . Expression,
Lambda ( ZhuTi , CS表達式! )
);
return yuan . Provider . CreateQuery ( Shu過濾 );
}
static ( Expression? 主體, ParameterExpression? 參數 ) FF結構主體 ( Type 元素類型 , string 查詢詞 )
{
// 找出所有字符串屬性
PropertyInfo [ ] 字符串屬性 = [ .. 元素類型
. GetProperties ( )
. Where ( prop => prop . PropertyType == typeof ( string ) ) ];
if ( 字符串屬性 . Length == 0 )
{
return (null , null); // 沒有字符串屬性,無法篩選
}
// 獲取 string . Contains 方法
MethodInfo contains方法 = typeof ( string )
. GetMethod ( "Contains" , [ typeof ( string ) ] )!;
// 創建參數(代表集合中的每個元素,類型是元素類型)
ParameterExpression 參數 = Expression . Parameter ( 元素類型 , "x" );
// 構建每個屬性的條件:x . 屬性 . Contains ( 查詢詞 )
IEnumerable<Expression> 條件列表 = 字符串屬性
. Select ( prop => Expression . Call (
Property ( 參數 , prop ), // x . 屬性名
contains方法,
Constant ( 查詢詞 ) // 查詢詞
) );
// 用 || 連接所有條件
Expression 主體 = 條件列表
. Aggregate( ( 前一個 , 當前 ) => Expression . Or ( 前一個 , 當前 ) );
return ( 主體 , 參數 );
}在這種情況下,您沒有編譯時的 T 類型通用佔位符,因此您使用了不需要編譯時類型信息的 Lambda 重載方法,該方法會生成 LambdaExpression 而非 Expression < TDelegate >。
動態 LINQ 庫
使用工廠方法構建表達式樹相對複雜;使用字符串來組合表達式則更為簡便。動態 LINQ 庫在 IQueryable 上提供了與 Queryable 中的標準 LINQ 方法相對應的一組擴展方法,這些方法接受以特殊語法表示的字符串,而非表達式樹。該庫會從字符串生成相應的表達式樹,並能夠返回轉換後的 IQueryable 結果。
例如,前面的例子可以這樣改寫:
static IQueryable FF文本過濾_strings ( IQueryable yuan , string chazhao )
{
if ( string . IsNullOrEmpty ( chazhao ) )
{
return yuan;
}
var LX元素類型 = yuan . ElementType;
// 獲取此特定類型的所有字符串屬性名稱
var ZFC屬性s =
LX元素類型 . GetProperties ( )
. Where ( x => x . PropertyType == typeof ( string ) )
.ToArray ( );
if ( !ZFC屬性s . Any ( ) )
{
return yuan;
}
// 創建 string 表達式
string BDS過濾 = string . Join (
" || ",
ZFC屬性s . Select ( prp => $"{prp . Name} . Contains(@0)" )
);
return yuan . Where ( BDS過濾 , chazhao );
}