










開發者朋友們大家好:
這裏是 「RTE 開發者日報」 ,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@Jerry fong,@鮑勃
01有話題的技術
1、騰訊開源 HunyuanWorld-Mirror 模型:單卡即可部署,秒級創造 3D 世界
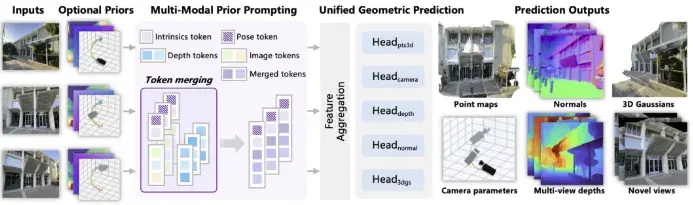
混元世界模型 1.1 版本(WorldMirror)正式發佈並開源,新增支持多視圖及視頻輸入,單卡即可部署,秒級創造 3D 世界。
作為一個統一(any-to-any)的前饋式(feedforward)3D 重建大模型,混元世界模型 1.1 解決了 1.0 版本僅支持文本或單圖輸入的侷限,首次同時支持多模態先驗注入和多任務統一輸出的端到端 3D 重建。
此外,混元世界模型 1.1 還支持額外的相機、深度等多模態先驗輸入,並基於統一架構實現點雲、深度、相機、表面法線和新視角合成等多種 3D 幾何預測,性能大幅超過現有方法。
混元世界模型 1.1(WorldMirror)已完全開源,開發者可克隆 GitHub 倉庫,按照文檔一鍵部署到本地使用。普通用户也可以直接進入 HuggingFace Space 在線體驗,支持上傳多視圖圖像或視頻,實時預覽 3DGS 渲染結果。
相關鏈接:
https://huggingface.co/tencent/HunyuanWorld-Mirror
相關鏈接:
https://github.com/Tencent-Hunyuan/HunyuanWorld-Mirror
(@騰訊混元 huggingface)
2、Decart 發佈口型實時同步 API,並開源視頻通話對話式機器人
Decart 推出了最新的 Lip Sync API,並將其集成到開源視頻通話對話式機器人 Sidekick 中。
Sidekick 是一款實時 AI 視頻通話助手,提供精準同步的口型匹配,讓你可以與歷史人物、虛構角色進行逼真的對話,甚至創造專屬的 AI 形象。
- 實時視頻對話 (Live Video Conversations):藉助 WebRTC 技術,與 AI 角色進行流暢的實時視頻通話。
- 完美唇形同步 (Perfect Lip Sync):由 Decart 領先的唇形同步技術提供支持,確保口型與聲音絲絲入扣。
- 角色定製 (Customizable Characters):通過簡單的 YAML 配置,輕鬆定義角色的個性、聲音和外觀。
- 低延遲體驗 (Low Latency):優化的處理流程,保障對話流暢,毫無卡頓。
- 智能對話管理 (Smart Interruptions):結合語音活動檢測(VAD)和智能輪次檢測,自然地處理對話中的打斷和輪替。
GitHub 地址:
https://github.com/DecartAI/sidekick
( @DecartAI @GitHub)
3、百川發佈最強循證增強大模型 M2 Plus,醫療幻覺率顯著降低
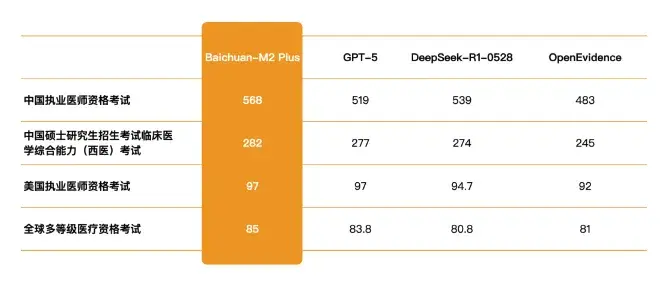
10 月 22 日,百川智能發佈循證增強醫療大模型 Baichuan-M2 Plus,同步升級配套應用百小應並開放 API。
據悉,本次模型的發佈是百川自 8 月開源 Baichuan-M2 以來的又一次重要動作。
評測顯示,M2 Plus 的醫療幻覺率較通用大模型顯著降低,相比 DeepSeek 低約 3 倍,優於美國最火醫療產品 OpenEvidence,可信度比肩資深臨牀醫生水準。
同時,百川 M2 Plus 首創六源循證推理(EAR)範式,打造「醫生版 ChatGPT」,讓大模型技術在輔助臨牀診療場景邁過「敢用、可用」關鍵門檻,不僅適合中國醫療環境,在美、日、英的醫療評測中均超過 OpenEvidence。
另外,M2 Plus 採用 PICO 框架(人羣 Population、干預 Intervention、對照 Comparison、結局 Outcome)思維,將查詢轉化為結構化醫學問題,並在六源數據庫中進行分層匹配。
目前,接入 M2 Plus 的百小應已在各大手機應用商店更新,成為「醫生版 ChatGPT」。為方便電腦端使用,網頁版(ying.ai)也同步上線。
Baichuan-M2 Plus 也提供了標準化 API 接口。百川方面還表示,通過開源 Baichuan-M2、發佈 Baichuan-M2 plus、百小應,開放 API,百川致力於持續提升 AI 醫療在真實臨牀場景的可用性,推動大模型在嚴肅醫療場景進入落地可用新階段。
( @APPSO)
4、手機也能跑,通義 Qwen3-VL 新增 2B
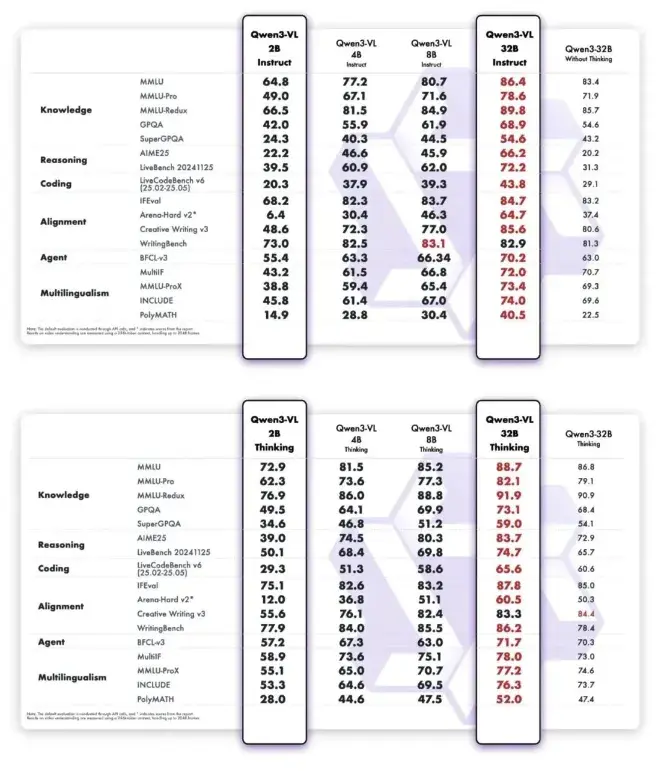
通義千問正式宣佈,旗下 Qwen3-VL 系列模型新增兩位「新成員」:2B 和 32B 兩個密集(Dense)模型尺寸。據悉,新模型均擁有兩個版本自由選擇:
- Instruct —— 響應更快、執行更穩,適合對話與工具調用;
- Thinking —— 強化長鏈推理與複雜視覺理解,能「看圖思考」,應對高難任務更出色。
性能表現上,Qwen3-VL-32B 在 STEM、VQA、OCR、視頻理解、代理任務等方面的表現優於 GPT-5 mini 和 Claude 4 Sonnet,僅使用 32B 參數即可匹敵高達 235B 的模型,甚至在 OSWorld 上擊敗了更大的模型。
而 Qwen3-VL-2B 則在小體量下釋放驚人表現,能跑在極限端側設備上,開發者實驗、部署都更輕盈。
截至目前,Qwen3-VL 共開源 2B、4B、8B、32B 四款 Dense 模型以及 30B-A3B、235B-A22B 兩款 MoE 模型,每款模型均推出 Instruct 和 Thinking 兩大版本,以及 12 個模型相應的 FP8 量化版,累計 24 個 Qwen3-VL 開源權重模型均可在魔搭社區和 Hugging Face 免費下載商用。
新模型體驗:ModelScope:
https://modelscope.cn/collections/Qwen3-VL-5c7a94c8cb144bHugging
Face:
https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8...
( @APPSO)
02有亮點的產品
1、雲蝠語音智能體:網頁語音客服模塊發佈
作為國內第一批直接採用大模型從事智能語音客服的企業,雲蝠智能其全棧自研的「神鶴大模型」支撐着語音智能體在 3-5 分鐘內快速構建上下文對話能力。此次發佈的 beta 版本,正是「網頁端實時語音交互+大模型智能決策」的深度融合產物——通過瀏覽器即可發起語音對話(無需安裝插件),大模型實時解析意圖並驅動業務流程,標誌着客服交互從「被動響應」向「主動服務」的關鍵跨越。
雲蝠智能實時網頁語音客服的核心競爭力,體現在對「實時性」與「精準性」的雙重突破。依託 WebRTC(網頁實時通信)技術,系統實現了網頁端語音流的端到端延遲控制在 5ms 以內,這意味着用户説話的瞬間即可得到響應,完全消除了傳統語音交互中的「卡頓感」。配合 7 年積累的 20TB 音頻數據訓練的噪聲過濾模型,以及卷積神經網絡聲學模型與流媒體降噪技術,即便在車間機械轟鳴、商場人聲嘈雜等極端複雜環境中,語音識別準確率仍能保持 97.5%,短語識別速度較傳統系統提升 30%,徹底解決了「環境嘈雜聽不清、遠程對話有延遲」的行業痛點。
動態共情交互:從機械應答到温度服務:基於聲紋情緒分析技術與 SAS/SDS 量表,系統能實時捕捉用户情緒狀態(焦慮/憤怒/平靜)並動態調整交互策略。當檢測到用户語音中帶有「很生氣」的情緒特徵時,會自動切換至安撫話術模板,如「非常理解您等待的焦急心情,我馬上為您優先核查訂單」,而非機械執行預設流程。在心理健康等特殊場景中,該技術對高危信號的識別準確率達 91%,體現 AI 服務的人文關懷。這種「情緒感知-策略調整」的閉環,讓客服交互從「解決問題」升級為「温暖服務」。
多輪對話連貫:上下文記憶降低中途掛斷率:針對用户連續提問的複雜場景(如「發貨時間-加急政策-運費險」),神鶴大模型通過 MemoryNetwork 技術實現 40+輪對話上下文記憶。從精準語義解析到情緒化交互,再到連貫多輪對話,神鶴大模型驅動的智能客服正實現從「能聽懂」到「會溝通」的質變,重新定義智能交互的温度與效率標準。
詳細鏈接:
https://mp.weixin.qq.com/s/tmobQLNbXgVcnOaoAv8QAA
(@雲蝠智能)
2、ASR 平台 Soniox v3 上線,語音識別準確率、語言檢測和翻譯質量顯著提升
語音 AI 平台 Soniox 今日發佈了其最新版本 v3,通過單一基礎模型顯著提升了語音識別的準確率、語言檢測和翻譯質量,能夠深度理解現實世界中的複雜語音場景。此舉旨在解決長期以來困擾語音驅動產品在真實環境下的準確性問題,為開發者構建更可靠、更智能的語音應用提供了全新可能。
突破性準確率: Soniox v3 在自然、快速、甚至多人交疊的語音場景下均能實現高精度識別,並覆蓋 60 多種語言,提供接近母語者的準確度。
深度語境理解: 新模型不再侷限於字面轉譯,而是能理解郵件地址拼寫、序列號、客户問題等複雜信息,內置的領域智能使其能理解跨行業術語和上下文。
即時語言檢測與智能翻譯: 能夠無縫識別並切換語言,翻譯服務也更注重捕捉深層含義,而非僅作字面轉換。
強化數字與字母識別: 對電話號碼、地址、身份證號等字母數字內容的識別精度大幅提升,解決實際應用痛點。
更大規模與實時性: 支持更長的錄音時長、更多用户併發以及實時流媒體處理,滿足大規模部署需求。
Soniox v3 已於即日起通過 Soniox API 和移動應用程序提供。新版本支持實時(real-time)和異步(asynchronous)兩種處理模式。
相關鏈接:
https://soniox.com/blog/2025-10-21-soniox-v3/
(@Soniox Blog)
3、三星 Galaxy XR 頭顯發佈:搭載驍龍 XR2+Gen 2 芯片

昨天,三星正式公佈其首款頭顯設備 Galaxy XR 以及最新 XR 穿戴計劃——AI 眼鏡。
Galaxy XR 作為 Android XR 生態系統的首台產品,售價為 1799.99 美元(約合人民幣 12827 元)。
硬件配置上,Galaxy XR 搭載高通 Snapdragon XR2+ Gen 2 芯片平台,提供 16GB+256GB,採用兩塊 4.3K 分辨率的 Micro-OLED 顯示屏和 pancake 鏡片,擁有 109 度的水平視場角和 95% 的 DCI-P3 色域覆蓋率。
同時,Galaxy XR 配備了兩個高分辨率透視攝像頭、六個面向外部的攝像頭以及一個位於正面的深度感應攝像頭,用於幫助頭顯瞭解用户周圍環境、動作並追蹤手部動作。此外,Galaxy XR 還有四個眼球追蹤攝像頭,可以跟蹤用户的眼睛並識別虹膜。
系統方面,Galaxy XR 所搭載的 Android XR 深度集成 Google 的 Gemini 人工智能系統,不僅能夠在設備上運行 Android 應用,更可以成為一款具備環境感知能力的 AI 驅動裝置。
另外,三星還正式宣佈,作為 XR 路線的一部分,其還將推出 AI 眼鏡。據悉,該 AI 眼鏡將由三星、Google、眼鏡品牌 Gentle Monster、Warby Parker 多方合作,後面兩個眼鏡品牌將負責 AI 眼鏡的外觀設計。
三星表示,與 Gentl Monster、Warby Parker 合作旨在將自身的 AI 技術與時尚設計融合,推出「兼具風格與前沿時尚感的眼鏡產品」,併為用户提供「卓越的客户體驗」。
據此前報道稱,三星計劃於 2026 年推出首款無顯示功能的 AI 眼鏡,並在 2027 年發佈配備增強現實(AR)顯示屏的版本。
相關鏈接:
https://mp.weixin.qq.com/s/n280BijJwT5CL92lJE7lxA
( @APPSO)
4、LiblibAI 完成 B 輪 1.3 億美元融資,今年中國 AI 應用領域公開的最大一筆融資
「暗涌 Waves」獨家獲悉,LiblibAI 已於近期完成 1.3 億美元 B 輪融資,由紅杉中國、CMC 資本及一大廠戰投聯合領投。
這是今年到目前為止中國 AI 應用領域公開的最大一筆融資——上次還要追溯至 5 億美金估值、8000 萬美金融資的 Manus。
上個月,LiblibAI 發佈了 2.0 版本,正式從模型社區進化為一站式 AI 創作 Studio。在業務上激進的 LiblibAI,匹配了同等程度的融資速度。
據「暗涌 Waves」瞭解,目前 LiblibAI 整體業務尚未實現完全盈利,這或許是他們再度選擇融資的部分原因。但有知情人士對「暗涌 Waves」解釋,在 agent 這樣一個 VC 投資紅海中,「錢是更大的壁壘。」
巨頭無邊界,在模型廠商碾壓下,AI 應用的創業者們更深刻地理解了這個商業法則。今天,資本正以史無前例的速度聚攏,OpenAI 發佈的 Sora App 下顯然讓選擇再次融資的 LiblibAI 更確信,如果你不能更快變大,你就沒有機會。
相關鏈接:
https://mp.weixin.qq.com/s/asHSBQYW3edXFCQtkwNbgA
(@暗涌 Waves)
03有態度的觀點
1、諾獎得主:AI 會推動人類學習的「第二次啓蒙」

在日前於上海舉行的 2025 可持續全球領導者大會上,新浪財經對話了諾貝爾化學獎得主、斯坦福大學教授邁克爾·萊維特(Michael Levitt),後者也分享了自己正密切關注 AI 如何改變人類學習與思考的方式。
萊維特坦言,「未來,一個聰明但沒上大學的年輕人,與名校畢業生的差距,會越來越小。」他認為,人工智能不會讓人變得懶惰,而是推動人類學習的「第二次啓蒙」。
萊維特説,「使用 AI 的人」一定會比「不用 AI 的人」更強,也會比「AI 本身」更強。人類與 AI 是互補關係,就像一部放在桌上的手機毫無用處,但放在你手裏,它立刻成為強大的工具。其以記者為例:
如果今天有人説:「我是記者,我只手寫,不用電腦,也不用錄音設備」,那當然可以,但這就像把自己困在 50 年前。AI 只是新一代工具而已。對我而言,它令人振奮而非可怕。
被問及「當人人都使用 AI 工作,學習,減輕研究負擔,會不會讓人失去創造能力,變得『更不聰明』。」時,萊維特則表示「我不這麼認為,你知道嗎,人們在互聯網剛出現時,也説過一模一樣的話。」
其指出,實際上現在人們寫作的量比以往任何時候都多——他們在拍視頻、剪影片。如今幾乎每個十幾歲的女孩都是個不錯的「小電影製作者」。而這,其實是一種極好的創作技能。
所以他並不覺得 AI 工具越來越普及是一個問題。相反的,他認為那些最反對新技術的人,其實根本沒真正用過它。
( @APPSO)


寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

素材來源官方媒體/網絡新聞








