










開發者朋友們大家好:
這裏是 「RTE 開發者日報」 ,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@Jerry fong,@鮑勃
01有話題的技術
1、MiniMax 開源模型 MiniMax-M2
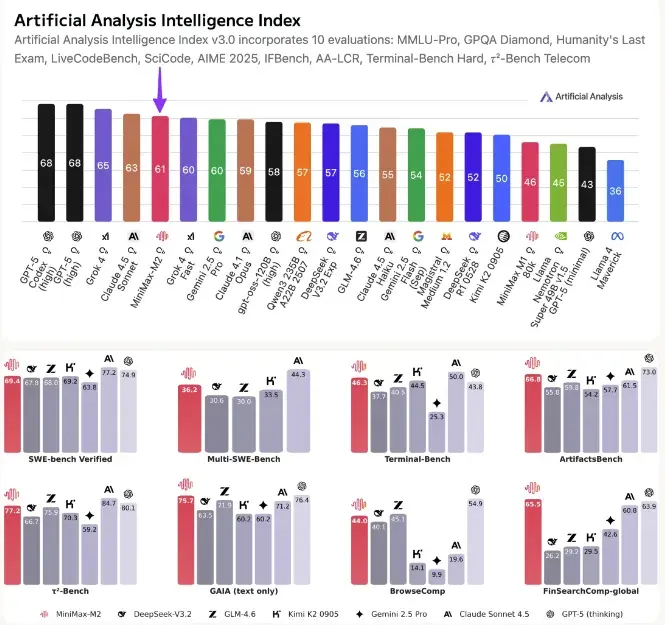
在大模型競賽從「拼參數」轉向「拼效率」的關鍵節點,MiniMax 於 10 月 27 日發佈新一代開源推理模型 M2,以精準的工程取捨,錨定智能 Agent 這一下一代 AI 應用的核心戰場。
M2 採用混合專家架構(Mixture-of-Experts, MoE),總參數量達 2300 億,但每次推理僅激活 100 億參數,實現高達每秒 100 個 token 的輸出速度——這一性能指標使其在實時交互場景中具備顯著優勢。尤為關鍵的是,M2 專為智能 Agent 設計,強化了在行為決策、多輪任務規劃與環境交互中的推理連貫性與響應效率,為構建真正自主的 AI 智能體提供底層引擎。
值得注意的是,相比前代 M1 模型,M2 在上下文窗口上做出戰略調整:從 M1 支持的 100 萬 token 大幅縮減至 20.48 萬 token。這一變化並非技術倒退,而是 MiniMax 在長文本處理、推理速度與部署成本之間做出的務實權衡。M1 雖以「百萬上下文」創下紀錄,但高資源消耗限制了實際落地;而 M2 則聚焦高頻、高響應的 Agent 任務,在保證足夠上下文長度的同時,大幅提升吞吐效率與經濟性。
作為開源模型,M2 進一步降低了開發者構建定製化智能體的門檻。無論是打造具備複雜任務鏈的虛擬助手、自動化工作流機器人,還是嵌入企業系統的決策 Agent,開發者均可基於 M2 快速迭代,靈活調優。
MiniMax 明確將 M2 定位為「Agent 時代的推理基座」。在 AI 正從「問答工具」邁向「行動代理」的浪潮中,M2 的推出不僅是一次模型升級,更是對下一代 AI 應用範式的押注——當智能體需要快速思考、持續行動、高效交互,速度與成本,或許比上下文長度更為關鍵。
相關鏈接:
https://www.minimax.io/news/minimax-m2
(@ AIBase)
2、inclusionAI 發佈 Ming-flash-omni Preview 模型
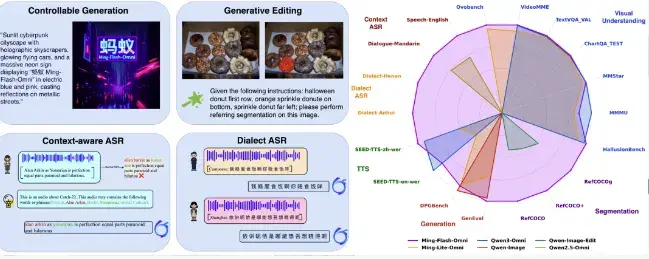
螞蟻集團 inclusionAI 發佈了 Ming-flash-omni Preview 模型,基於 Ling-Flash-2.0 構建,總參數量為 100B,其中每個 token 僅激活 6B 參數。與前代模型相比,Ming-flash-omni Preview 在多模態理解和生成方面展現出實質性提升,並在視覺-文本理解、圖像生成、音頻理解和文本轉語音能力方面表現出競爭力。
該模型在多模態能力上進行了關鍵優化,特別是在語音識別方面,實現了上下文 ASR(ContextASR)和方言感知 ASR 的 State-of-the-Art 性能,在全部 12 個 ContextASR 基準測試中均設定了新的 State-of-the-Art 性能,並顯著提升了對 15 種中文方言的識別性能。在圖像生成方面,Ming-flash-omni Preview 引入了高保真文本渲染,並在圖像編輯過程中展示了場景一致性和身份保留方面的顯著增益。此外,模型引入了生成式分割(Generative Segmentation),該能力不僅實現了強大的獨立分割性能,還增強了圖像生成中的空間控制,並改善了編輯一致性。
Ming-flash-omni Preview 支持圖像、文本、視頻和音頻作為輸入模態,並支持圖像、文本和音頻作為輸出模態,可用於流媒體視頻對話、音頻上下文 ASR 與方言 ASR、音頻語音克隆以及圖像生成與編輯等用例。該模型的預覽版本已發佈。
相關鏈接:
https://huggingface.co/inclusionAI/Ming-flash-omni-Preview
(@橘鴨 Juya)
3、谷歌推出 Earth AI 新模型,強化地理空間推理能力
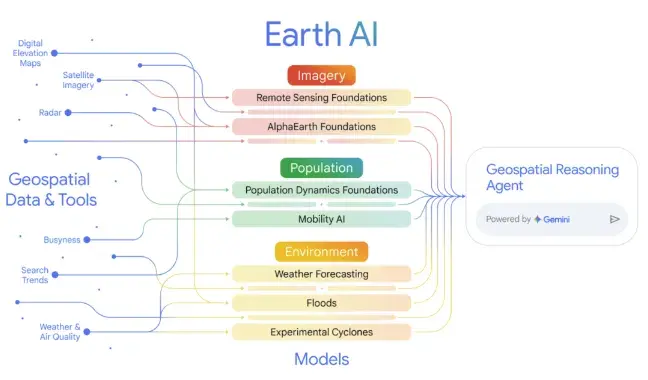
日前,谷歌宣佈在 Google Earth 和 Google Cloud 平台擴展其「Earth AI」能力,推出新一代地理空間 AI 模型與推理智能體。該系統結合基礎模型與多模態推理,旨在為複雜的全球性問題提供可行的建議。
谷歌表示,Earth AI 的核心在於將影像、人口與環境等多領域模型與推理 Agent 結合。
Agent 可將自然語言問題分解為多步計劃,調用不同模型與地理空間工具,並融合結果生成整體答案。例如,在預測颶風登陸及評估受影響社區時,系統可同時調用天氣預測、人口動態與衞星影像識別關鍵基礎設施。
據介紹,此次更新包括兩大新模型:
- 影像基礎模型:支持自然語言查詢衞星圖像,提升超過 16% 的文本檢索準確率,並在零樣本目標檢測中將基線精度提升一倍以上;
- 人口動態模型:覆蓋 17 個國家,提供月度更新的嵌入向量,用於捕捉人類活動變化。在獨立研究中,該模型將巴西登革熱長期預測的 R² 指標從 0.456 提升至 0.656。
此外,Google 強調多模型融合的預測能力。例如,將人口動態與地貌特徵結合後,對美國聯邦緊急事務管理署(FEMA)國家風險指數的預測準確率平均提升 11%,其中龍捲風風險預測提升 25%,河流洪水風險提升 17%。
在評估中,Earth AI 的地理空間推理代理在問答基準測試中取得 0.82 的整體準確率,顯著優於 Gemini 2.5 Pro 的 0.50 和 Gemini 2.5 Flash 的 0.39。
目前,Earth AI 已被聯合國 Global Pulse、GiveDirectly 等組織用於災害響應與公共健康研究,並吸引了包括 Public Storage、CARTO 和 Visiona Space Technology 在內的企業用户。
(@ APPSO)
02有亮點的產品
1、OpenAI GPT-5 強化心理健康響應,不當回答驟降 65%

OpenAI 近日發佈了其最新模型 "gpt-5-oct-3",本次升級的核心在於對心理健康話題迴應進行了突破性的改進。OpenAI 披露的數據顯示,用户對心理健康的求助需求巨大且嚴峻:每週約有 0.15% 的活躍用户對話中出現明確的潛在自殺計劃或意圖跡象,這相當於每週約有 100 萬人正在與 ChatGPT 討論自殺相關話題。
為解決這一攸關生命的問題,OpenAI 聯合了來自全球 60 個國家的 300 位心理健康專業人士對 GPT-5 模型進行了深度優化。改進成果令人鼓舞,模型在三大關鍵領域——包括嚴重的心理健康症狀(如幻覺、躁狂、妄想)、自殺與自傷傾向,以及對 AI 的情感依賴——的表現均有大幅提升。
具體而言,相關「不安全迴應」減少了 65%;在自殺相關測試中,GPT-5 的合規率高達 91%,相較於 GPT-4o 的 77% 有了顯著飛躍;此外,經專家評估,GPT-5 的不當回答比 GPT-4o 減少了 52%。針對具體症狀,精神病與躁狂對話的不當迴應減少 65%,而 AI 情感依賴類對話的不當迴應更是大幅減少了 80%。
這次對 GPT-5 在心理健康響應上的重大升級,標誌着人工智能在處理敏感和高風險話題方面邁出了重要一步,凸顯了 OpenAI 在推動 AI 安全性和負責任部署方面的堅定承諾。
相關鏈接:
https://openai.com/index/strengthening-chatgpt-responses-in-s...
(@ AIBase)
2、前天貓精靈總裁創業:運動可穿戴 + Agent 智能體切入通用智能

據 36 氪報道,前阿里巴巴集團副總裁、天貓精靈總裁彭超已於近日創立新公司「雲玦科技」,並計劃通過運動 AI 硬件切入通用智能賽道。
該項目於 10 月中旬啓動,首款產品定位為運動可穿戴設備與 Agent 智能體的結合,旨在讓 AI 在高速、高頻運動場景中承擔跟蹤、規劃、分析和執行等角色,並具備自進化能力,未來可遷移至更廣泛的物理空間。
知情人士透露,「雲玦科技」的產品形態仍在設計中,但方向並非單一硬件,而是「一套產品組合」。這一思路契合 2025 年以來 AI 大模型在 Agentic use 方向的趨勢,即從被動響應指令進化為主動規劃和執行復雜任務。隨着小參數量推理模型(SLM)的成熟,AI 正逐步從工具向助理轉變。
聯合創始人齊煒禎曾是微軟與中科大聯合培養博士,提出過 MTP(Multi-token Prediction)架構,該方法已被 Deepseek V3、Qwen-3-Next 等大模型採用。他在非自迴歸生成加速、多模態智能體和端到端推理加速方面也有開源經驗。
彭超此前在華為和阿里均有豐富的硬件與 AIoT 業務經驗。在阿里任職期間,他主導將達摩院大模型引入天貓精靈,並推動集團智能互聯業務的搭建,實現硬件毛利轉正和軟件訂閲規模化收入。
(@ APPSO)
3、ListenHub :讓編輯 AI 播客像用 Word 一樣簡單

來自 ListenHub 創始人@oran\_ge:
自 ListenHub 五月上線以來,用户呼聲最高的功能就是編輯模式。
AI 生成的播客很酷,但編輯起來真的很令人沮喪。改動幾個字就可能導致聲音合成出錯,更換聲音或增加段落更是基本不可能。這就像給了你一輛跑車,卻沒有給你方向盤。
過去幾個月,我們一直在思考如何以最簡單的方式實現對 AI 音頻內容的編輯。ListenHub 全新的編輯模式正式上線。我們徹底重構了編輯體驗,目標只有一個:讓編輯 AI 播客像使用 Word 一樣簡單。
兩大核心功能:
- 像導演選角一樣分配聲音
你可以為播客設定多個角色,為每一句話單獨指定聲音。想做一期三國主題的播客?讓曹操和劉備直接對話——單擊一下即可更換人物。
- 像作家一樣自由構建故事
想增加更多內容?將鼠標懸停在兩段之間,單擊一下即可插入新素材。覺得太囉嗦?直接刪除即可,就像在 Word 裏按下刪除鍵一樣乾脆。
ListenHub 編輯模式的位置:
生成一期播客後,在播客腳本頁面的右上角,就能看到「編輯」按鈕啦。編輯功能為 ListenHub 付費用户專享功能,付費用户還可享受定製音色、API 調用等多種福利,歡迎訂閲 ListenHub Pro。
使用鏈接:
https://listenhub.ai/zh
( @oran\_ge)
03有態度的觀點
1、R 星母公司 CEO:AI 是「好事」,但永遠不具備創造力

據 PC Gamer 報道,R 星母公司 Take-Two 董事長兼 CEO Strauss Zelnick 在昨日於加州門洛帕克舉行的 Paley International Council Summit 上表示,人工智能雖能為遊戲開發帶來效率提升,但其本質是「大數據集與計算能力結合的語言模型」,無法真正創造熱門作品或展現創造力。
Zelnick 強調,AI 的預測模型依賴既有數據,因此「數據集是回顧性的,而創造力則是前瞻性的」。他指出,AI 在擁有大量清晰數據時表現出色,但在數據不足時能力有限,因此「AI 看似前瞻,實則只是預測模型」。
他進一步形容當前的 AI 熱潮為「元數據與戲法的結合」,並預測隨着時間推移,公眾會逐漸習慣其存在,就像當年對 Google 的接受過程一樣。儘管如此,Zelnick 並未否認 AI 的價值,他稱其為「對所有行業而言都是一件好事」,但明確表示「不會重現或創造天才,也不會製造爆款」。
在就業影響方面,Zelnick 認為 AI 不會減少崗位,反而會增加。他以農業為例指出,1865 年美國 65% 的勞動力從事農業,而如今僅有 2% 的勞動力即可滿足國內外需求,社會並未因此出現就業危機。
整體來看,Zelnick 的立場既非全盤否定,也非盲目樂觀,而是強調 AI 的侷限性與輔助價值,凸顯其在效率層面的潛力,而非創造力的替代。
(@ APPSO)
04社區黑板報
招聘、項目分享、求助……任何你想和社區分享的信息,請聯繫我們投稿。(加微信 creators2022,備註「社區黑板報」)
1、ErroRight 招聘







閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

素材來源官方媒體/網絡新聞








