









在軟件世界中,用户的形態正在發生變化。
過去,軟件的使用者是工程師、分析師或運維人員;而如今,他們正在被一羣“數字化身”——Agent 所取代。AI 不再只是一個算法模型,而是逐漸演變為能理解業務語境、自動執行任務、並進行協同決策的智能體。
隨着大模型技術的快速成熟,這場以 “Agent 化” 為核心的軟件革命,正推動企業數據系統從傳統的自動化,走向真正的智能化。
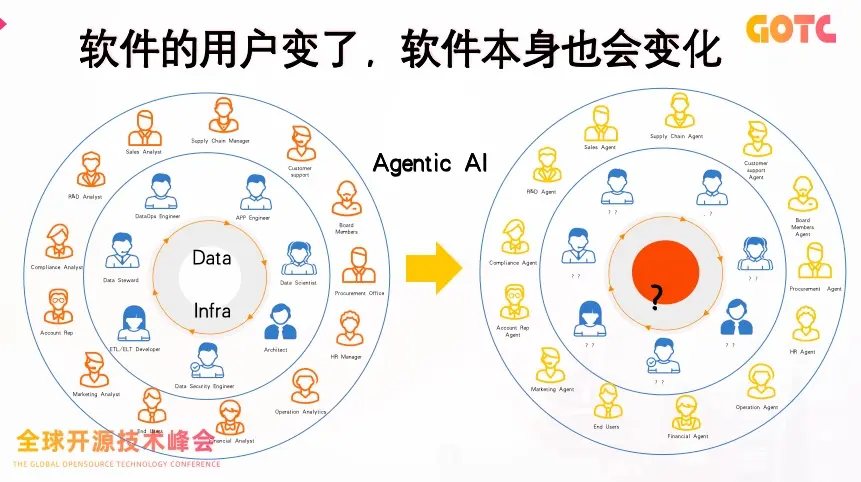
在這一趨勢中,數據基礎設施的智能升級成為關鍵。
從數據到智能:DataAgents 的崛起
如果説 ChatGPT 帶來了“文本的智能理解”,那麼 DataAgent 的出現,則代表了“數據的智能行動”。
在全球範圍內,多個頭部數據平台都已率先邁出這一步:
- 海外案例①:Snowflake Cortex 讓“問數據”變成一場自然的對話
Snowflake Cortex 內置 LLM 服務,實現自然語言至 SQL 轉化,自動生成查詢並解釋結果,並深度整合 Snowsight UI,讓“問數據”重新變成一場自然的對話。
這帶來了全新的數據分析體驗,LLM 作為數據操作入口,恢復數據分析的對話式體驗,對 WhaleStudio 來説是個很重要的啓示:對話驅動任務生成,自然語言建模入口。
- 海外案例②:Databricks AI Assistant
Databricks AI Assistant 則讓工程師在寫 SQL 或 PySpark 時,獲得代碼補全、性能優化建議與錯誤修復提示。通過智能融合,彷彿 IDE 中多了一個懂上下文的智能合作者。
- 海外案例③:MotherDuck Agent
MotherDuck Agent 以輕量化語義查詢與自動數據探索為核心,將分析從複雜系統遷移到雲端 Agent,自動生成報告、圖表與洞察。這對 WhaleStudio 來説也很有借鑑意義,將來可以計劃融合語義生成與圖形拖拽操作,SaaS 化加 AI 賦能,幫助用户零門檻獲取數據洞察,引領數據分析新趨勢。
- 海外案例④:Dataherald
Dataherald 的創新在於把 LLM 用作“企業數據庫翻譯器”,讓業務人員通過自然語言提問,實時獲得可驗證的 SQL 與結果解釋。這種強調準確性和上下文驗證,解釋可追溯的特點,也啓發 WhaleStudio 可以朝着優化“問題到任務”流程的方向,建立數據追溯機制。
這些案例的共同點在於:
它們都讓數據變得“可交互”、讓洞察更“實時”。
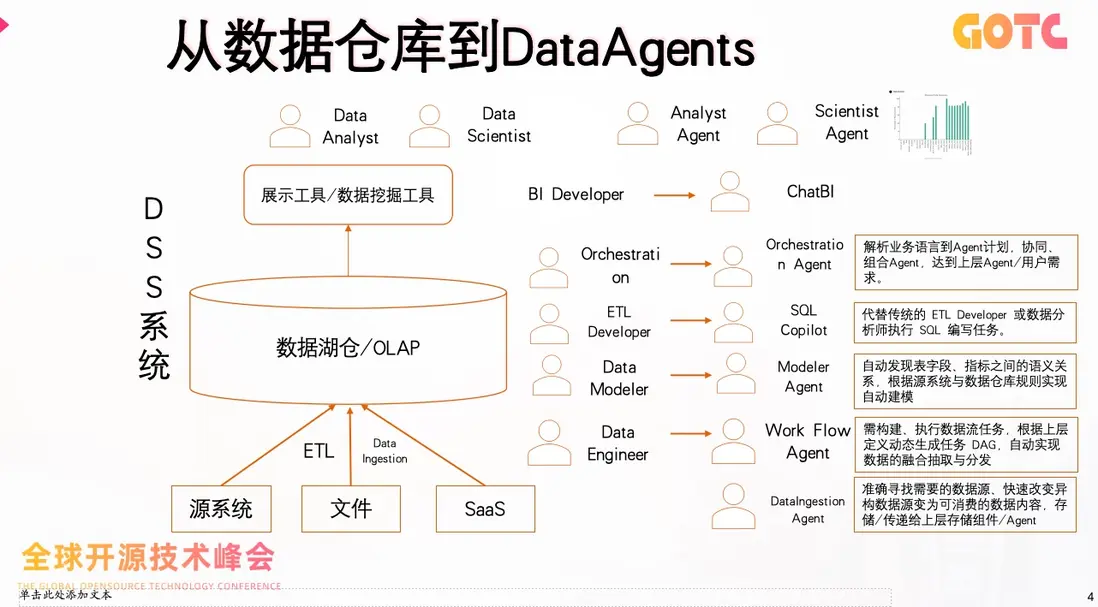
可以看到,DataAgent 的出現,使得數據分析不再是技術部門的專屬,而是企業每一個角色都可以參與的智能對話過程。它讓“數據能力”成為企業的新型生產力。
DataAgent:讓數據系統擁有“理解力”
看了這麼多案例,我們再回過頭來深度理解下,Data Agent 到底是什麼?
與傳統的數據中台或 RAG 技術不同,DataAgent 並非一個獨立模塊,而是一組協同工作的智能體體系。
它由多個 Agent 組成,覆蓋 DataFlow、ETL、Data Ingestion、SQL Copilot 等不同層面,通過編排協調機制形成自學習、自優化的執行網絡。
簡單來説,Data Agents 可以成為企業中最懂數據的“人”。
DataAgent 讓大模型理解數據,也讓數據反過來理解業務。
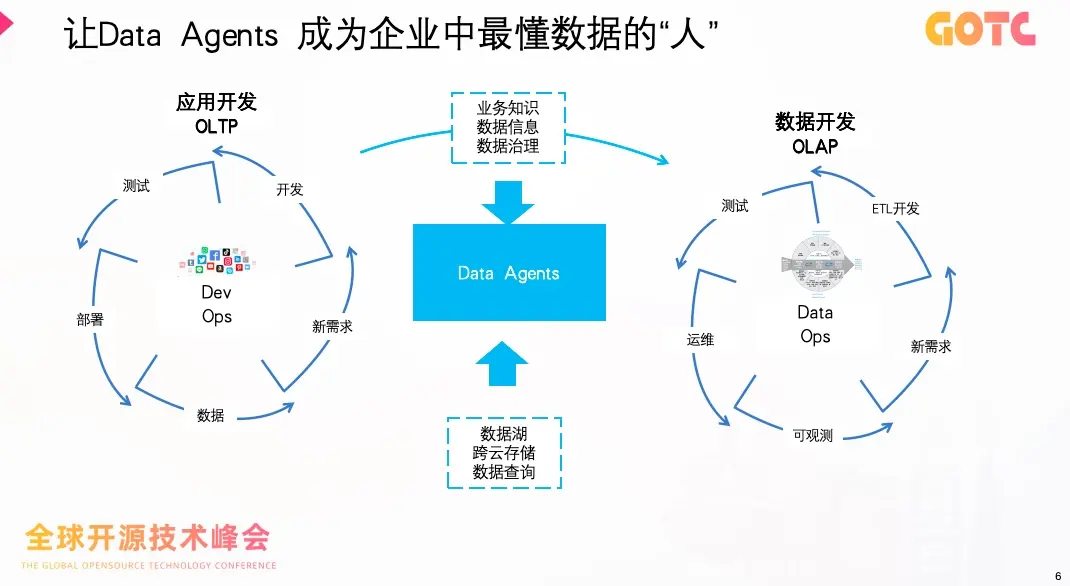
這種雙向理解,使企業能夠在數據流轉的每一個環節中嵌入智能判斷。無論是調度、抽取還是監控,系統都不再只是被動執行規則,而能主動識別模式、優化執行路徑,並基於上下文作出決策。
這正是“從自動化到智能化”的根本躍遷。
從使用場景看 DataAgent 的真實價值
DataAgent 的潛力不僅在概念層面,更體現在實際落地場景。
- SQL → Workflow 自動生成代理
在任務生成方面,它能將 SQL 語句自動轉化為可編輯的工作流(Workflow),支持CTE、Join、Insert等複雜操作,讓技術與業務在同一視圖中協作。
它還能進行 Drag&Drop 調整,用户通過拖拽方式微調節點,靈活管理調度依賴與數據流向,實現自動化與可控性平衡。
- 對話式任務生成(Prompt → Sync Task)
在數據同步中,它能將自然語言 Prompt 自動生成 WhaleTunnel 配置文件,智能推斷字段映射與增量策略,自動生成配置後,進入圖形界面,直觀驗證與微調 DAG,實現 Prompt 到數據同步任務的平滑過渡。
同時,在開發與運維階段,DataAgent 還能充當多種角色:
- Q&A Agent 實現深度問答,提供直觀配置示例,引導用户精準操作;
- Pipeline Debug Agent 自動識別性能瓶頸,給出參數調優建議;
- Workflow Error Agent 智能定位錯誤節點並推薦修復方案;
- SQL Code Assistant Agent 像智能 IDE 一樣自動補全與校驗 SQL;
- Task Lineage & Recovery Agent 自動分析血緣與重跑路徑,保障一致性;
- Data Quality Agent 則監測異常與漂移,生成修復 SQL。
這些場景的本質,是讓系統不再需要被“操作”,而能主動地“協作”與“學習”。
它不只是提高效率,而是在重構企業的數據生產方式。
DataAgent×WhaleTunnel:讓集成更智能,讓洞察更實時
當智能 Agent 與數據集成框架結合,數據基礎設施的形態將被徹底改變。
白鯨開源WhaleTunnel 新一代實時多源數據同步引擎支持上百種數據源與跨雲環境,性能較傳統方案提升可達 30 倍。
而當 DataAgent 賦能其中,WhaleTunnel 不再只是“數據搬運工”,而是具備語義理解與自我優化能力的數據神經系統。
在設計上,DataAgent × WhaleTunnel 體現了四個核心理念:
- 交互層設計:通過自然語言與圖形界面結合,讓業務與數據團隊協同構建任務;
- 意圖解析與任務構建:基於 LLM 語義解析自動生成數據同步邏輯;
- Agent 編排與執行:各類 Agent 協同執行,實現任務自調度與自修復;
- 知識與安全治理:結合知識圖譜與合規策略,確保數據可追溯、安全可信。
這種融合,讓 WhaleTunnel 從“高速數據管道”進化為“智能數據中樞”——數據不僅被傳輸,更被理解與優化。
每一次變更、每一條日誌、每一組指標,都能被 LLM 實時“翻譯”為洞察。
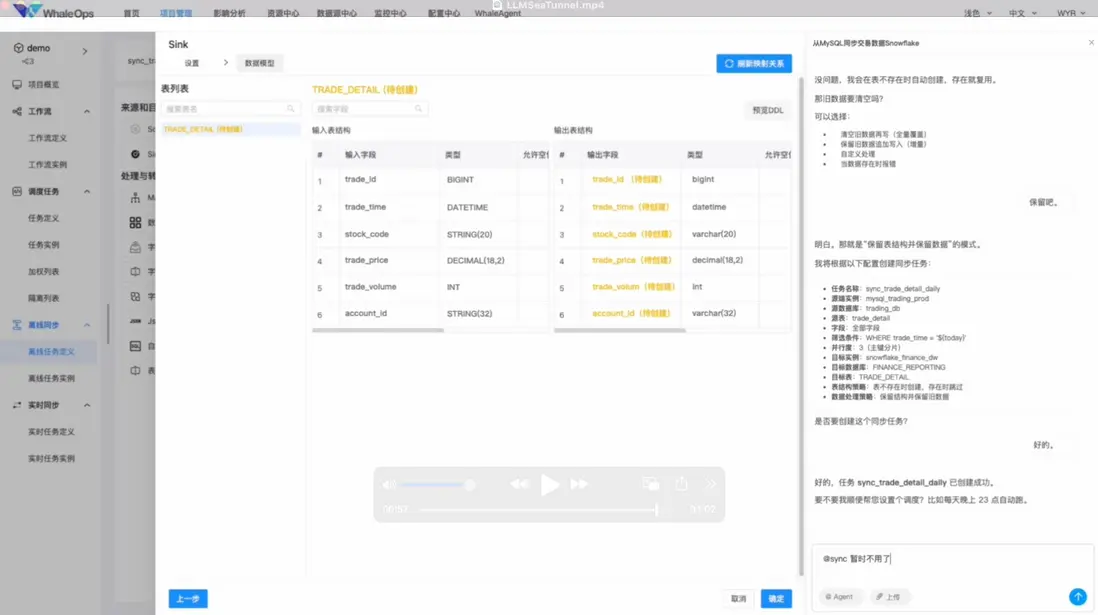
WhaleTunnel融合DataAgents設計(內測中)
未來展望:從 DataFlow 到 DataAgents 網絡
未來的企業數據架構,將不再以“ETL 流程”為中心,而是以“Data Agents 網絡”為核心。
WhaleOps 正在探索這一方向:
通過 語義生成 + 拖拽操作 的模式,讓每一個用户都能零門檻構建智能數據任務;
讓數據流動的每一個節點,都擁有自主決策與優化能力。
當自然語言成為新的數據編排接口,當 WhaleTunnel 的數據流由智能 Agent 實時調度與解釋,我們將迎來一個前所未有的時代:
數據不再只是被“使用”,而是能主動“思考”。
DataAgent × SeaTunnel,讓數據庫變更實時“翻譯”為洞察。
這是數據集成的未來,也是智能基礎設施的起點。
歡迎思考與討論
Agent 正在重塑數據世界的邊界:它不僅能執行任務,更能理解意圖、優化過程、生成洞察。
👉 你認為未來的企業數據平台,會如何與智能 Agent 共生?
👉 你希望哪類數據任務最先被“智能化”接管?
歡迎在評論區分享你的看法,讓我們一起探索 “智能化數據基礎設施” 的下一步。




