









過期刪除策略的深度剖析
Redis 可以對 key 設置過期時間的,為了防止過期的key長期佔用內存,需要相應的過期刪除策略將過期的key刪除
基礎操作
Redis設置過期時間
- setex key1 5 value1:創建記錄的時候指定過期時間,設置key1在5秒後過期
其實Redis這是一種基於創建時間來判定是否過期的機制,也即常規上説的TTL策略,當設定了過期時間之後不管有沒有被使用都會到期被強制清理掉。但有很多場景下也會期望數據能夠按照TTI(指定時間未使用再過期)的方式來過期清理,如用户鑑權場景:
假設用户登錄系統後生成token並存儲到Redis中,指定token有效期30分鐘,那麼如果用户一直在使用系統的時候突然時間到了然後退出要求重新登錄,這個體驗感就會很差。正確的預期應該是用户連續操作的時候就不要退出登錄,只有連續30分鐘沒有操作的時候才過期處理。
略有遺憾的是,Redis並不支持按照TTI機制來做數據過期處理。但是作為補償,Redis提供了一個重新設定某個key值過期時間的方法,可以通過expire方法來實現指定key的續期操作,以一種曲線救國的方式滿足訴求。
實現緩存續期
expire <key> <n>:設置 key 在 n 秒後過期,比如 expire key 100 表示設置 key 在 100 秒後過期;pexpire <key> <n>:設置 key 在 n 毫秒後過期,比如 pexpire key2 100000 表示設置 key2 在 100000 毫秒(100 秒)後過期。expireat <key> <n>:設置 key 在某個時間戳(精確到秒)之後過期,比如 expireat key3 1683187646 表示 key3 在時間戳 1683187646 後過期(精確到秒);pexpireat <key> <n>:設置 key 在某個時間戳(精確到毫秒)之後過期,比如 pexpireat key4 1683187660972 表示 key4 在時間戳 1683187660972 後過期(精確到毫秒)
對於上面説的用户token續期的訴求,可以這樣來操作:
用户首次登錄成功後,會生成一個token令牌,然後將令牌與用户信息存儲到redis中,設定30分鐘有效期。 每次請求接口中攜帶token來鑑權,每次get請求的時候,就重新通過expire操作將token的過期時間重新設定為30分鐘。 持續30分鐘無請求後,此條token緩存信息過期失效。同樣實現了TTI的效果。
ttl查看過期時間
# 查看 key1 過期時間還剩多少
> ttl key
(integer) 56
# 取消 key 的過期時間
> persist key
(integer) 1
//永不過期返回-1
> ttl key
(integer) -1如何判斷過期時間
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* 鍵值對的過期時間 */
//……
} redisDb;dict是hash表
- *dict是鍵值對,指向的是數據庫中保存的具體的key value對象,key是String類型,value是具體的數據類型
- *expires是過期字典,key與*dict中的key一致,value則是一個 long long 類型的整數,這個整數保存了 key 的過期時間;
過期字典的數據結構如下圖所示:
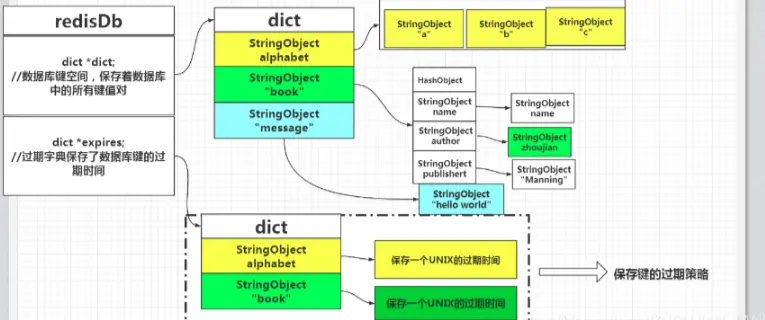
簡單地總結來説就是,設置了失效時間的key和具體的失效時間全部都維護在 expires 這個字典表中。未設置失效時間的key不會出現在expires字典表中。
所以當查詢一個 key 時,Redis 首先檢查該 key 是否存在於expires過期字典中:
- 如果不在,則正常讀取鍵值;
- 如果存在,則會獲取該 key 的過期時間,然後與當前系統時間進行比對,如果比系統時間大,那就沒有過期,否則判定該 key 已過期。
過期刪除策略
定時刪除
在設置key的過期時間的同時,為該key創建一個定時器,讓定時器在key的過期時間來臨時,對key進行刪除。
優點:保證內存被儘快釋放,對內存友好
缺點:若過期key很多,刪除這些key會佔用很多的CPU時間,在CPU時間緊張的情況下,CPU不能把所有的時間用來做要緊的事兒,還需要去花時間刪除這些key,定時器的創建耗時,若為每一個設置過期時間的key創建一個定時器(將會有大量的定時器產生),性能影響嚴重。對CPU不友好
結論:此方法基本上沒人用
惰性刪除
過期的key並不一定會馬上刪除,還會佔用着內存。 當你真正查詢這個key時,redis會檢查一下,這個設置了過期時間的key是否過期了? 如果過期了就會刪除,返回空。這就是惰性刪除。
優點:刪除操作只發生在從數據庫取出key的時候發生,而且只刪除當前key,所以對CPU時間的佔用是比較少的,對 CPU友好
缺點:若大量的key在超出超時時間後,很久一段時間內,都沒有被獲取過,那麼可能發生內存泄露。對內存不友好
定期刪除
每隔一段時間,程序就對數據庫進行一次檢查,刪除裏面的過期鍵,至於要刪除多少過期鍵,以及要檢查多少個數據庫,由算法決定
優點:通過限制刪除操作執行的時長和頻率,來減少刪除操作對 CPU 的影響,同時也能刪除一部分過期的數據減少了過期鍵對空間的無效佔用。
缺點:
- 內存清理方面沒有定時刪除效果好,同時沒有惰性刪除使用的系統資源少。
- 難以確定刪除操作執行的時長和頻率。如果執行的太頻繁,定期刪除策略變得和定時刪除策略一樣,對CPU不友好;如果執行的太少,那又和惰性刪除一樣了,過期 key 佔用的內存不能及時得到釋放
Redis的過期刪除策略
redis實際使用的過期鍵刪除策略是定期刪除策略和惰性刪除策略:
- 定期刪除策略:redis 會將每個設置了過期時間的 key 放入到一個獨立的字典中,以後會定時遍歷這個字典來刪除到期的 key。
- 惰性刪除策略:只有當訪問某個key時,才判斷這個key是否已過期,如果已經過期,則從實例中刪除
定時刪除是集中處理,惰性刪除是零散處理。
定期刪除策略
Redis內部維護一個定時任務,默認每秒進行10次(也就是每隔100毫秒一次)過期掃描,過期掃描不會遍歷過期字典中所有的 key,而是採用了一種簡單的貪心策略。
- 從過期字典中隨機取出20個key
- 刪除這 20 個 key 中已經過期的 key;
- 如果這20個key中過期key的比例超過了25%,則重複步驟1
為了保證過期掃描不會出現循環過度,導致線程卡死現象,算法還增加了掃描時間的上限,默認不會超過 25ms。
為什麼key集中過期時,其它key的讀寫效率會降低?
Redis的定期刪除策略是在Redis
主線程中執行的,也就是説如果在執行定期刪除的過程中,出現了需要大量刪除過期key的情況,那麼在業務訪問時,必須等這個定期刪除任務執行結束,才可以處理業務請求。此時就會出現,業務訪問延時增大的問題,最大延遲為25毫秒。為了儘量避免這個問題,在設置過期時間時,可以給過期時間設置一個隨機範圍,避免同一時刻過期。
惰性刪除策略
int expireIfNeeded(redisDb *db, robj *key, int flags) {
//檢查是否開啓惰性刪除策略
if (server.lazy_expire_disabled) return 0;
if (!keyIsExpired(db,key)) return 0;//檢查key是否過期,沒過期不用刪除
//……
//刪除失效key
deleteExpiredKeyAndPropagate(db,key);
return 1;
}
int keyIsExpired(redisDb *db, robj *key) {
//假如Redis服務器正在從RDB文件中加載數據,暫時不進行失效主鍵的刪除,直接返回0
if (server.loading) return 0;
//獲取主鍵的失效時間 get當前時間-創建時間>ttl
mstime_t when = getExpire(db,key);
mstime_t now;
//假如失效時間為負數,説明該主鍵未設置失效時間(失效時間默認為-1),直接返回0
if (when < 0) return 0; /* No expire for this key */
now = commandTimeSnapshot();
//如果以上條件都不滿足,就將主鍵的失效時間與當前時間進行對比,如果發現指定的key還未失效就返回0
return now > when;
}過期key對持久化的影響
RDB:
- 生成rdb文件:生成時,程序會對key進行檢查,過期key不放入rdb文件。
- 載入rdb文件:載入時,如果以主服務器模式運行,程序會對文件中保存的key進行檢查,未過期的key會被載入到數據庫中,而過期key則會忽略;如果以從服務器模式運行,無論鍵過期與否,均會載入數據庫中,過期key會通過與主服務器同步而刪除。
AOF:
- 當服務器以AOF持久化模式運行時,如果數據庫中的某個key已經過期,但它還沒有被惰性刪除或者定期刪除,那麼AOF文件不會因為這個過期key而產生任何影響
- 當過期key被惰性刪除或者定期刪除之後,程序會向AOF文件追加一條DEL命令,來顯示的記錄被該key已經發被刪除
- 在執行AOF重寫的過程中,程序會對數據庫中的key進行檢查,已過期的key不會被保存到重寫後的AOF文件中
主從複製:當服務器運行在複製模式下時,從服務器的過期刪除動作由主服務器控制:
- 主服務器在刪除一個過期key後,會顯式地向所有從服務器發送一個del命令,告知從服務器刪除這個過期key;
- 從服務器在執行客户端發送的讀命令時,即使碰到過期key也不會將過期key刪除,而是繼續像處理未過期的key一樣來處理過期key;
- 從服務器只有在接到主服務器發來的del命令後,才會刪除過期key。
內存淘汰策略
過期刪除策略,是刪除已過期的 key,而當 Redis 的運行內存已經超過 Redis 設置的最大內存之後,則會使用內存淘汰策略刪除符合條件的 key,以此來保障 Redis 高效的運行。這兩個機制雖然都是做刪除的操作,但是觸發的條件和使用的策略都是不同的。
- 數據過期,是符合業務預期的一種數據刪除機制,為記錄設定過期時間,過期後從緩存中移除。
- 數據淘汰,是一種“有損自保”的
降級策略,是業務預期之外的一種數據刪除手段。指的是所存儲的數據沒達到過期時間,但緩存空間滿了,對於新的數據想要加入內存時,為了避免OOM而需要執行的一種應對策略。
基礎操作
設置 Redis 最大運行內存
在配置文件redis.conf 中,可以通過參數 maxmemory <bytes> 來設定最大內存,當數據內存達到 maxmemory 時,便會觸發redis的內存淘汰策略
不進行數據淘汰
noeviction:不會淘汰任何數據。
當使用的內存空間超過 maxmemory 值時,也不會淘汰任何數據,但是再有寫請求時,則返回OOM錯誤。
進行數據淘汰
- volatile-lru:針對設置了過期時間的key,使用lru算法進行淘汰。
- allkeys-lru:針對所有key使用lru算法進行淘汰。
- volatile-lfu:針對設置了過期時間的key,使用lfu算法進行淘汰。
- allkeys-lfu:針對所有key使用lfu算法進行淘汰。
- volatile-random:針對設置了過期時間的key中使用隨機淘汰的方式進行淘汰。
- allkeys-random:針對所有key使用隨機淘汰機制進行淘汰。
- volatile-ttl:針對設置了過期時間的key,越早過期的越先被淘汰。
Redis對隨機淘汰和LRU策略進行的更精細化的實現,支持將淘汰目標範圍細分為全部數據和設有過期時間的數據,這種策略相對更為合理一些。因為一般設置了過期時間的數據,本身就具備可刪除性,將其直接淘汰對業務不會有邏輯上的影響;而沒有設置過期時間的數據,通常是要求常駐內存的,往往是一些配置數據或者是一些需要當做白名單含義使用的數據(比如用户信息,如果用户信息不在緩存裏,則説明用户不存在),這種如果強行將其刪除,可能會造成業務層面的一些邏輯異常。
Redis的內存淘汰算法
操作系統本身有其內存淘汰算法,針對內存頁面淘汰,詳情請看 內存的頁面置換算法
LRU 算法
LRU( Least Recently Used,最近最少使用)淘汰算法:是一種常用的頁面置換算法,也就是説最久沒有使用的緩存將會被淘汰。
傳統的LRU 是基於鏈表結構實現的,鏈表中的元素按照操作順序從前往後排列,最新操作的key會被移動到表頭,當需要進行內存淘汰時,只需要刪除鏈表尾部的元素即可,因為鏈表尾部的元素就代表最久未被使用的元素。
但是傳統的LRU算法存在兩個問題:
- 需要用鏈表管理所有的緩存數據,這會帶來額外的空間開銷;
- 當有數據被訪問時,需要在鏈表上把該數據移動到頭端,如果有大量數據被訪問,就會帶來很多鏈表元素的移動操作,會很耗時,進而會降低 Redis 緩存性能。
Redis 使用的是一種近似 LRU 算法,目的是為了更好的節約內存,它的實現方式是給現有的數據結構添加一個額外的字段,用於記錄此key的最後一次訪問時間。Redis 內存淘汰時,會使用隨機採樣的方式來淘汰數據,它是隨機取 5 個值 (此值可配置) ,然後淘汰一個最少訪問的key,之後把剩下的key暫存到一個池子中,繼續隨機取出一批key,並與之前池子中的key比較,再淘汰一個最少訪問的key。以此循環,直到內存降到maxmemory之下。
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; //記錄 Key 的最後被訪問時間
int refcount;
void *ptr;
};在 LRU 算法中,Redis 對象頭的 24 bits 的 lru 字段是用來記錄 key 的訪問時間戳,因此在 LRU 模式下,Redis可以根據對象頭中的 lru 字段記錄的值,來比較最後一次 key 的訪問時間長,從而淘汰最久未被使用的 key。
但是 LRU 算法有一個問題,無法解決緩存污染問題,比如應用一次讀取了大量的數據,而這些數據只會被讀取這一次,那麼這些數據會留存在 Redis 緩存中很長一段時間,造成緩存污染。Redis利用LFU解決這個問題
LFU 算法
最不常用的算法是根據總訪問次數來淘汰數據的,它的核心思想是“如果數據過去被訪問多次,那麼將來被訪問的頻率也更高”。
Redis 的 LFU 算法也是通過 robj 對象的 lru 字段來保存 Key 的訪問頻率的,LFU 算法把 lru 字段分為兩部分,如下圖:

- 0 ~ 7 位:用於保存 Key 的訪問頻率計數器。
- 8 ~ 23 位:用於保存當前時間(以分鐘計算)。
由於訪問頻率計數器只有8個位,所以取值範圍為 0 ~ 255,如果每訪問 Key 都增加 1,那麼很快就用完,LFU 算法也就不起效果了。所以 Redis 使用了一種比較複雜的算法了計算訪問頻率,算法如下:
- 先按照上次訪問距離當前的時長,來對 logc 進行衰減;
- 然後,再按照一定概率增加 logc 的值
具體為:
- 在每次 key 被訪問時,會先對 訪問頻率 做一個衰減操作,衰減的值跟前後訪問時間的差距有關係,如果上一次訪問的時間與這一次訪問的時間差距很大,那麼衰減的值就越大,這樣實現的 LFU 算法是根據訪問頻率來淘汰數據的,而不只是訪問次數。訪問頻率需要考慮 key 的訪問是多長時間段內發生的。key 的先前訪問距離當前時間越長,那麼這個 key 的訪問頻率相應地也就會降低,這樣被淘汰的概率也會更大。
- 對 訪問頻率 做完衰減操作後,就開始對 訪問頻率 進行增加操作,增加操作並不是單純的 + 1,而是根據概率增加,如果 訪問頻率 越大的 key,它的 訪問頻率 就越難再增加。
訪問頻率衰減算法:原理就是,Key 越久沒被訪問,衰減的程度就越大。
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;// 獲取 Key 最後訪問時間(單位為分鐘)
unsigned long counter = o->lru & 255;// 獲取 Key 訪問頻率計數器的值
// 下面是計算要衰減的數量
// LFUTimeElapsed 函數用於獲取 Key 沒被訪問的時間(單位為分鐘)
// lfu_decay_time 是衰減的力度,通過配置項 lfu-decay-time 設置,值越大,衰減力度越小
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
// 對訪問頻率計數器進行衰減操作
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}從 LFUDecrAndReturn 函數可知,lfu-decay-time 設置越大,衰減的力度就越小。如果 lfu-decay-time 設置為1,並且 Key 在 10 分鐘內沒被訪問的話,按算法可知,訪問頻率計數器就會被衰減10。
訪問頻率增加算法:
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;// 獲取隨機數r
double baseval = counter - LFU_INIT_VAL;// 計數器舊值
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);// 根據計數器舊值與影響因子來計算出p
if (r < p) counter++;// 如果 p 大於 r, 那麼對計數器進行加以操作
return counter;
}LFU 算法更新 lru 字段和LRU 算法更新lru字段都是在 lookupKey 函數中完成的
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
robj *val = NULL;
if (de) {
val = dictGetVal(de);
//……
}
if (val) {
//……
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {// 如果配置的是LFU淘汰算法
updateLFU(val);// 更新LFU算法的統計信息
} else {// 如果配置的是LRU淘汰算法
val->lru = LRU_CLOCK();// 更新 Key 最後被訪問時間
}
}
//……
} else {
//……
}
return val;
}
