









概述
緩存作為持久化存儲(如數據庫)的輔助存在,畢竟屬於兩套系統。理想情況下是緩存數據與數據庫中數據完全一致,但是業務最常使用的旁路緩存架構下,在一些分佈式或者高併發的場景中,可能會出現緩存不一致的情況。
在分佈式系統中,數據一致性是一個核心問題。根據系統的設計與需求,可以選擇實時強一致性(Strong Consistency)或最終一致性(Eventual Consistency)。
實時強一致性
定義:實時強一致性保證了任何時刻,所有的客户端看到的數據都是一樣的。在分佈式系統中實現強一致性意味着,一個操作一旦完成,所有的客户端立即都能看到這個操作的結果。
適用場景:事務性強、對數據一致性要求高的系統,如銀行系統或任何財務系統。
保障策略:
- 三階段提交(3PC)等分佈式事務協議:在分佈式系統中保證操作要麼全部成功,要麼全部失敗。
- 分佈式鎖:通過在操作前獲取全局鎖,保證同一時刻只有一個操作可以修改數據,從而保障數據一致性。
- 強一致性算法:如Paxos或Raft算法,通過一系列嚴格的消息傳遞和確認機制,確保分佈式系統中的多個副本能夠達到一致狀態。
最終一致性
定義:最終一致性是指,系統會保證在沒有新的更新操作的情況下,經過足夠的時間後,數據將達到一致的狀態。在這種模型下,數據的副本之間可能會暫時存在不一致。
適用場景:對實時性要求不高,可以容忍短時間內數據不一致的場景,如社交網絡、推薦系統等。
保障策略:
- 異步複製:當數據更新發生時,首先更新主副本,然後異步地將更新同步到其他副本,例如使用消息隊列來完成。
- 讀取修復(Read Repair):在讀取數據的時候檢測副本之間的不一致,並在後台異步修復不一致的數據。
- 後台一致性修復進程:定期在後台運行的進程檢查和同步數據副本之間的差異,以達到最終一致性。
- 版本控制:每次更新數據時附加一個時間戳或版本號,用於解決更新衝突和保持數據的最終一致性。
常見緩存更新/失效策略與一致性解決方案
緩存更新策略
- Write through cache(直寫緩存):首先將數據寫入緩存,然後立即將新的緩存數據複製到數據庫。這種方式可以保證寫操作的一致性,但可能會影響寫操作的性能。
- Write back cache(寫回緩存):數據首先寫入緩存,然後由緩存異步寫入數據庫。這種方式可以提高寫操作的性能,但增加了數據丟失的風險。
- Write around cache(饒寫緩存):繞過緩存,直接寫數據庫,然後依據需要更新緩存或使緩存失效。這適用於更頻繁讀取操作的場景。
緩存失效策略
- 主動更新:當數據庫數據變化時,主動更新緩存中的數據。這可以保持緩存數據的實時性,但可能會增加系統的複雜性。
- 定時失效:為緩存數據設置一個過期時間。定期從數據庫中重新加載數據,以保持數據的新鮮度。但這無法解決數據在兩次加載之間變化導致的一致性問題。
- 惰性加載:只有在請求特定數據且發現緩存失效或緩存中沒有該數據時,才去數據庫加載該數據。這種策略簡單,但在高併發場景下可能會導致緩存擊穿。
使用緩存一致性協議
- 基於訂閲的更新:使用消息隊列(如Kafka,RabbitMQ)來發布數據庫更新,然後相關服務訂閲這些更新消息來同步更新緩存。
- 最終一致性:採用最終一致性模型,允許系統在一段時間內是不一致的,但保證經過足夠的時間後,系統中的所有複製數據最終將達到一致的狀態。
分佈式緩存系統
使用如Redis Cluster、Apache Ignite、Tair等分佈式緩存系統,這些系統內置了處理緩存一致性的機制,(但是無法解決緩存和數據庫之間的數據一致性問題)。
最終一致性
針對如何保證緩存和數據庫的最終一致性,引出以下幾個問題:
- 到底是更新緩存還是刪緩存?
- 如果是刪緩存,那選擇先更新數據庫,再刪除緩存,還是先刪除緩存,再更新數據庫?
- 為什麼要引入消息隊列保證一致性?
- 延遲雙刪會有什麼問題?到底要不要用?
- ……
更新緩存
由於引入了緩存,那麼在數據更新時,要想保證緩存和數據庫最終一致性,就不僅要更新數據庫,還要更新緩存
那麼數據庫和緩存都需要更新,就存在先後的問題:
- 先更新緩存,後更新數據庫
- 先更新數據庫,後更新緩存
由於操作分為了兩步,那麼就有可能出現 第一步成功,第二步失敗 的情況
第一步成功,第二步失敗
先更新緩存,後更新數據庫
如果緩存更新成功了,但數據庫更新失敗了,那麼此時緩存中是最 新值,但數據庫中是 舊值。雖然此時讀請求可以命中緩存,拿到正確的值,但是,一旦緩存失效,就會從數據庫中讀取到舊值,重建緩存也是這個舊值。
此時數據沒有更新成功,顯然就會對業務產生影響
先更新數據庫,後更新緩存
如果數據庫更新成功了,但緩存更新失敗,那麼此時數據庫中是最新值,緩存中是舊值。之後的讀請求讀到的都是舊數據,只有當緩存 失效 後,才能從數據庫中得到正確的值。
這時就會發現,自己剛剛修改了數據,但卻看不到修改後的值,一段時間過後,數據才變更過來,顯然也會對業務產生影響。
可見,無論誰先誰後,但凡後者發生異常,都會對業務造成影響。那怎麼解決這個問題呢?後面詳細描述
併發場景
先更新緩存,後更新數據庫
在併發場景下,假設有線程 A 和線程 B 兩個線程,需要更新 X這條 數據,會發生這樣的場景:
- 線程 A 更新緩存(X = 1)
- 線程 B 更新緩存(X = 2)
- 線程 B 更新數據庫(X = 2)
- 線程 A 更新數據庫(X = 1)
此時,數據庫中的 X=1,而緩存中的 X=2 ,出現了緩存和數據庫中的數據不一致的現象。
先更新數據庫,後更新緩存
同樣以上的場景,
- 線程 A 更新數據庫(X = 1)
- 線程 B 更新數據庫(X = 2)
- 線程 B 更新緩存(X = 2)
- 線程 A 更新緩存(X = 1)
此時,數據庫中的 X=2,而緩存中的 X=1 ,出現了緩存和數據庫中的數據不一致的現象。
所以,無論是先更新數據庫,再更新緩存,還是先更新緩存,再更新數據庫,這兩個方案都存在併發問題,當兩個請求併發更新同一條數據的時候,較大概率會出現緩存和數據庫中的數據不一致的現象。
解決方案:分佈式鎖
通常的解決方案是:加分佈式鎖
兩個線程要修改「同一條」數據,那麼每個線程在修改之前,先申請分佈式鎖,拿到鎖的線程才允許更新數據庫和緩存,拿不到鎖的線程,返回失敗,等待下次重試。
使用分佈式讀寫鎖可以完美解決緩存數據不一致的問題,但是想要讀數據必須等待寫數據整個操作完成。因此,這種方案造成的性能開銷有可能會超過引入緩存帶來的性能提升。
從緩存利用率的角度來看更新緩存的方案:當每次數據發生變更,都去更新緩存,但是緩存中的數據實際上並不一定會被馬上讀取,這就會導致緩存中可能存放了很多不常訪問的數據,浪費緩存資源。
因此更新緩存的方案在未引入分佈式鎖的情況下,不僅緩存利用率不高、浪費緩存資源,還會造成數據不一致的問題。所以可以考慮刪除緩存的方案
刪除緩存
同樣的,刪除緩存方案也有兩種:
- 先刪除緩存,後更新數據庫
- 先更新數據庫,後刪除緩存
由於操作分為了兩步,那麼也有可能出現 第一步成功,第二步失敗 的情況
第一步成功,第二步失敗
先刪除緩存,後更新數據庫
如果緩存刪除成功了,但數據庫更新失敗了,數據庫沒有更新成功,那下次讀緩存發現不存在,則從數據庫中讀取,並重建緩存,此時數據庫和緩存都是舊數據。
此時數據沒有更新成功,顯然就會對業務產生影響
先更新數據庫,後刪除緩存
如果數據庫更新成功了,但緩存刪除失敗,那麼此時數據庫中是最新值,緩存中還是是舊值。之後的讀請求讀到的都是舊數據,只有當緩存 失效 後,才能從數據庫中得到正確的值。
這時就會發現,自己剛剛修改了數據,但卻看不到修改後的值,一段時間過後,數據才變更過來,顯然也會對業務產生影響。
可見,無論誰先誰後,但凡後者發生異常,都會對業務造成影響。那怎麼解決這個問題呢?後面詳細描述
併發場景
先刪除緩存,後更新數據庫
開始時 X=1,在併發場景下,假設有線程 A 和線程 B 兩個線程,A想要將 X 這條數據修改為 X = 2,B想要讀 X 這條數據,會發生這樣的場景:
- 線程 A 先刪除緩存
- 線程 B 讀緩存,發現不存在,從數據庫中讀取到舊值(X = 1)
- 線程 A 將新值寫入數據庫(X = 2)
- 線程 B 將舊值寫入緩存(X = 1)
最終,X 在緩存中是 1(舊值),在數據庫中是 2(新值),緩存和數據庫的數據不一致。
延遲雙刪
實際上,先刪除緩存,後更新數據庫方案導致緩存和數據庫的數據不一致原因在於緩存被寫回了舊值。而針對這個方案的解決方法就是延遲雙刪策略。
在線程 A 刪除緩存、更新完數據庫之後,先 休眠一會 ,再 刪除 一次緩存。偽代碼如下:
#刪除緩存
redis.delKey(X)
#更新數據庫
db.update(X)
#睡眠
Thread.sleep(N)
#再刪除緩存
redis.delKey(X)加了個睡眠時間,主要是為了確保線程 A 在睡眠的時候,線程 B 能夠在這這一段時間完成「從數據庫讀取到(舊的)數據,再把(舊的)數據寫回緩存」的操作,然後線程 A 睡眠完,再刪除緩存。
但是具體睡眠多久其實很難評估,所以這個方案也只是儘可能保證一致性,極端情況下,依然也會出現緩存不一致的現象。
但是延遲時間最大的問題不在於此,而是兩次刪除緩存數據引起的緩存穿透,短時間對數據庫(主副本)造成的流量與負載壓力。絕大多數應用系統本身流量與負載並不高,使用緩存通常是為了提升系統性能表現,數據庫(主副本)完全可以承載一段時間內的負載壓力。對於此類系統延遲雙刪是一個完全可以接受的高性價比策略。
現實世界中的系統響應慢所帶來的卻是流量的加倍上漲。回想一下當你面對 App 響應慢的情況,是如何反應與對待便能明白,幾乎所有用户的下意識行為都是如出一轍。
所以對於那些流量巨大的應用系統而言,短時的訪問流量穿透緩存訪問數據庫(主副本),恐怕很難接受。為了應對這種流量穿透的情況,通常需要增加數據庫(主副本)的部署規格或節點。而且這類應用系統的響應變慢的時候,會對其支持系統產生影響,如果其支持系統較多的情況下,會存在影響的增溢。相比延遲雙刪在技術實現上帶來高效便捷而言,其對系統的影響與副作用則變得不可忽視。
因此,還是比較建議用以下 先更新數據庫,再刪除緩存 的方案。
先更新數據庫,再刪除緩存
同樣的以上的場景:但 X 在緩存中不存在,在數據庫中 X = 1
- 線程 A 讀取數據庫,得到舊值(X = 1)
- 線程 B 更新數據庫(X = 2)
- 線程 B 刪除緩存
- 線程 A 將舊值寫入緩存(X = 1)
最終,X 在緩存中是 1(舊值),在數據庫中是 2(新值),緩存和數據庫數據不一致。
顯然先更新數據庫,再刪除緩存也是會出現數據不一致性的問題,但是在實際中,這個問題出現的概率並不高。出現這個場景,要同時滿足三個條件:
- 緩存剛好已失效
- 讀請求 + 寫請求併發
- 更新數據庫 + 刪除緩存的時間(步驟 2-3),要比讀數據庫 + 寫緩存時間短(步驟 1 和 4)
實際上,寫數據庫一般會先加鎖,所以寫數據庫,通常是要比讀數據庫的時間更長的。也就是説,通常情況下,更新數據庫 + 刪除緩存的時間(步驟 2-3),都是要比讀數據庫 + 寫緩存時間 長的
因此,可以説,先更新數據庫 + 再刪除緩存的方案,是可以保證數據一致性的。
如何保證兩步都執行成功
前面的方案,都是兩步執行的操作,都有可能出現第一步成功,第二步失敗的情況,這種情況下都會導致數據問題,導致業務受到影響,因此,需要保證兩步都執行成功。
對於單體項目,可使 第一步和第二步 都在同一個事務中執行,使更新數據庫和刪除緩存是原子性操作
@Transactional //同一個事務中執行,保證同時成功
public Result update(Shop shop){
Long id = shop.getId();
if(id == null){
return "商品id不能為空";
}
//更新數據庫
updateById(shop);
//刪除緩存
redisTemplate(id);
}而對於分佈式項目,要保證第二步執行成功,則有兩種方案:
- 重試
- 訂閲MySQL binlog,再操作緩存
重試方案
同步重試
同步重試會一直佔用這個線程資源,無法服務其它客户端請求。因此同步重試不可取
異步重試
異步重試就是把重試請求寫到消息隊列中,然後由專門的消費者來重試,直到成功。
消息隊列也有可能失敗?實際上由於消息隊列的特性,不會失敗:
消息隊列保證可靠性:寫到隊列中的消息,成功消費之前不會丟失。
消息隊列能保證消息的成功投遞:下游從隊列拉取消息,成功消費後才會刪除消息,否則還會繼續投遞消息給消費者
方案過程如下:
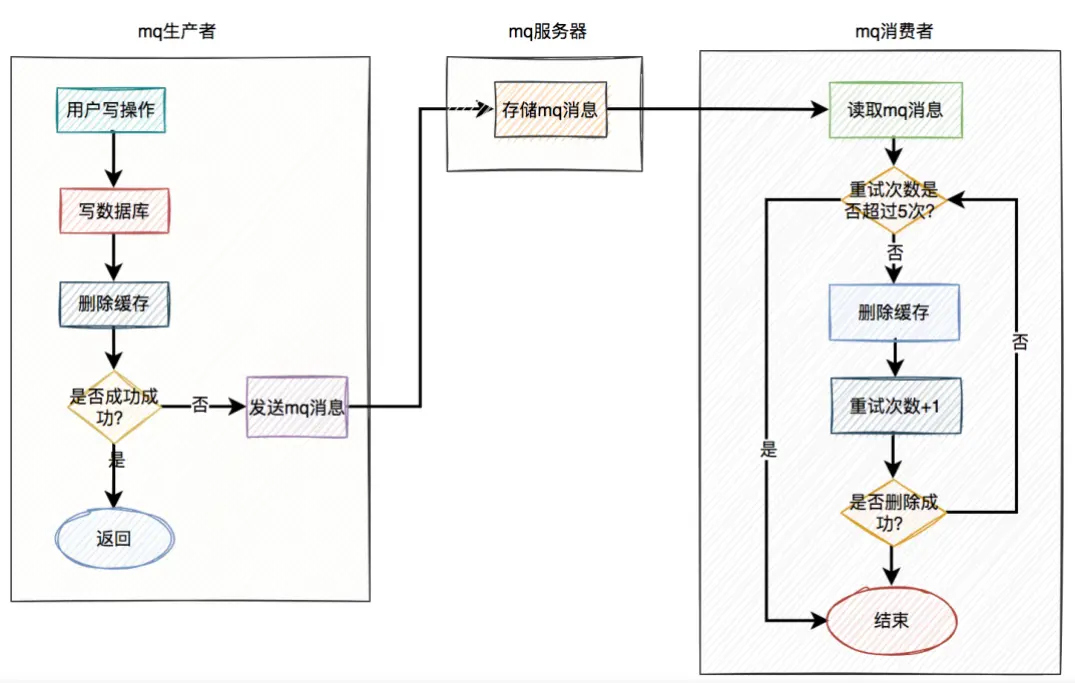
訂閲MySQL binlog,再操作緩存
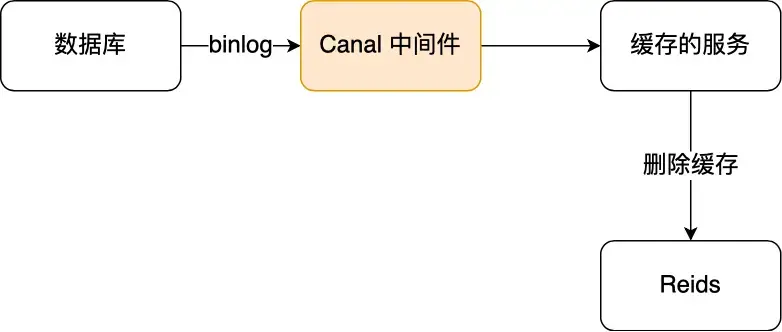
在Mysql中,當一條數據發生修改時,MySQL 就會產生一條變更日誌(binlog),binlog日誌用於複製,在主從複製中,從庫可以利用主庫上的binlog進行重放,實現主從同步。
那麼我們就可以偽裝成從服務器,對binlog日誌進行訂閲,拿到具體操作的數據,然後再根據這條數據,去刪除對應的緩存。阿里巴巴開源的 Canal 中間件就是基於這個實現的。
Canal 模擬 MySQL 主從複製的交互協議,把自己偽裝成一個 MySQL 的從節點,向 MySQL 主節點發送 dump 請求,MySQL 收到請求後,就會開始推送 Binlog 給 Canal,Canal 解析 Binlog 字節流之後,轉換為便於讀取的結構化數據,供下游程序訂閲使用。
小結
至此,可以得出結論,想要保證數據庫和緩存的最終一致性,推薦採用先更新數據庫,再刪除緩存方案,並配合消息隊列或訂閲變更日誌的方式來做
實時強一致性
其實在最終一致性提到的方案中,説的都是 最終一致性,這個最終一致性是能保證緩存和數據庫的最終一致性的,並且接近實時。
但是想讓緩存和和數據庫強一致,是很難的。最有效的方案先更新數據庫,再刪除緩存也是存在不一致性的可能的,只是概率較低。
要想做到強一致性,那就可以加鎖,分佈式鎖可以完美解決緩存數據不一致的問題,但想要讀取數據就必須等待寫數據整個操作完成。這就會造成併發上的性能問題
但是,引入緩存的目的就是為了提升性能,決定了使用緩存,那必然就要面臨數據一致性問題。性能和一致性無法做到都滿足要求。只能儘量降低問題出現的概率,減小對業務的影響


