









認識微服務
隨着互聯網行業的發展,對服務的要求也越來越高,服務架構也從單體架構逐漸演變為現在流行的微服務架構。這些架構之間有怎樣的差別呢?
單體架構
單體架構:將業務的所有功能集中在一個項目中開發,打成一個包部署。
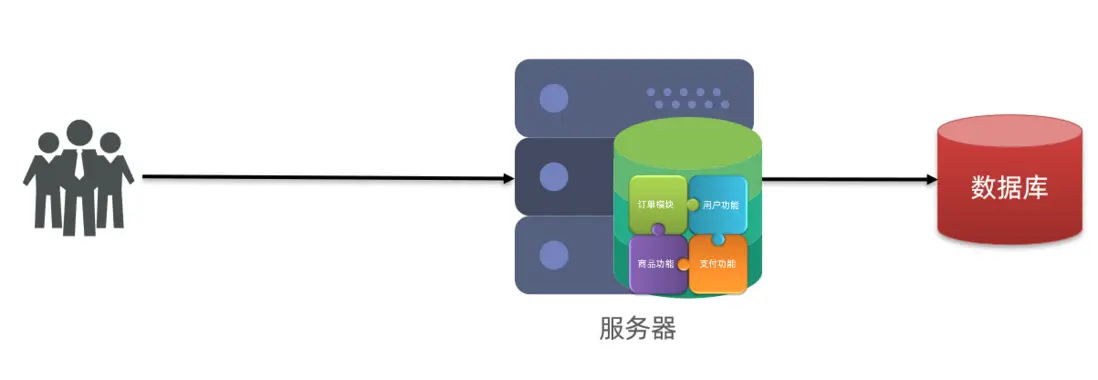
單體架構的優缺點如下:
優點:
- 架構簡單
- 部署成本低
缺點:
- 耦合度高(維護困難、升級困難)
分佈式架構
分佈式架構:根據業務功能對系統做拆分,每個業務功能模塊作為獨立項目開發,稱為一個服務。
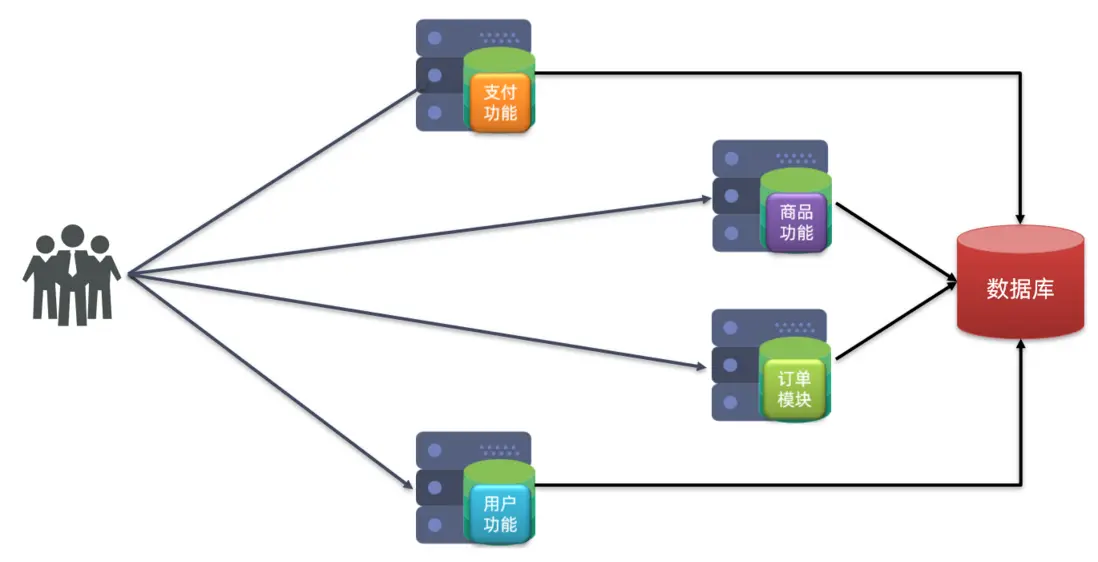
分佈式架構的優缺點:
優點:
- 降低服務耦合
- 有利於服務升級和拓展
缺點:
- 服務調用關係錯綜複雜
分佈式架構雖然降低了服務耦合,但是服務拆分時也有很多問題需要思考:
- 服務拆分的粒度如何界定?
- 服務之間如何調用?
- 服務的調用關係如何管理?
人們需要制定一套行之有效的標準來約束分佈式架構。
微服務
微服務的架構特徵:
- 單一職責:微服務拆分粒度更小,每一個服務都對應唯一的業務能力,做到單一職責
- 自治:團隊獨立、技術獨立、數據獨立,獨立部署和交付
- 面向服務:服務提供統一標準的接口,與語言和技術無關
- 隔離性強:服務調用做好隔離、容錯、降級,避免出現級聯問題
微服務的上述特性其實是在給分佈式架構制定一個標準,進一步降低服務之間的耦合度,提供服務的獨立性和靈活性。做到高內聚,低耦合。
因此,可以認為微服務是一種經過良好架構設計的分佈式架構方案 。
但方案該怎麼落地?選用什麼樣的技術棧?全球的互聯網公司都在積極嘗試自己的微服務落地方案。
其中在Java領域最引人注目的就是SpringCloud提供的方案了。
SpringCloud
SpringCloud是目前國內使用最廣泛的微服務框架。官網地址:https://spring.io/projects/spring-cloud。
SpringCloud集成了各種微服務功能組件,並基於SpringBoot實現了這些組件的自動裝配,從而提供了良好的開箱即用體驗。
其中常見的組件包括:
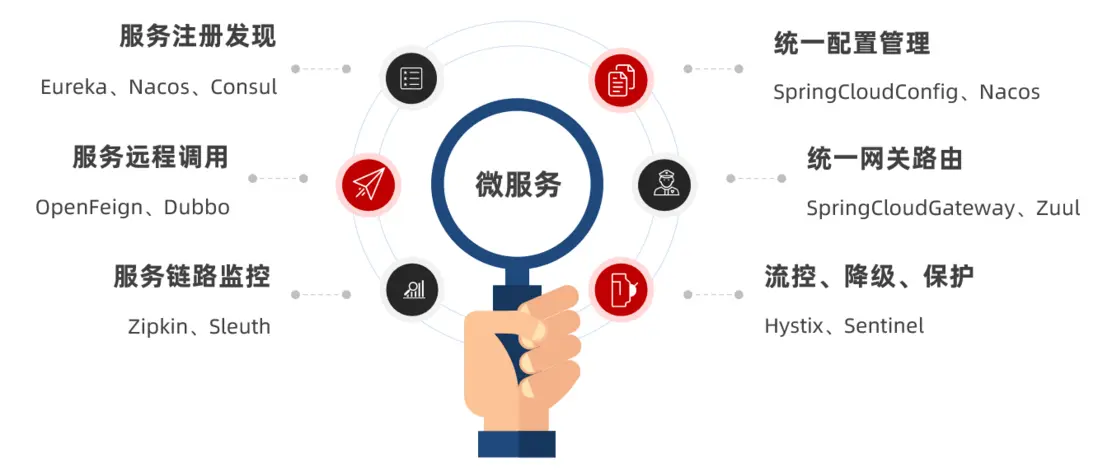
springcloud是一個基於Spring Boot實現的微服務架構開發工具。spring cloud包含多個子項目:
- Spring Cloud Config:配置管理工具,支持使用Git存儲配置內容, 可以使用它實現應用配置的外部化存儲, 並支持客户端配置信息刷新、加密/解密配置內容等。
-
Spring Cloud Netflix:核心 組件,對多個Netflix OSS開源套件進行整合。
- Eureka: 服務治理組件, 包含服務註冊中心、服務註冊與發現機制的實現。
- Hystrix: 容錯管理組件,實現斷路器模式, 幫助服務依賴中出現的延遲和為故障提供強大的容錯能力。
- Ribbon: 客户端負載均衡的服務調用組件。
- Feign: 基於Ribbon 和Hystrix 的聲明式服務調用組件。
- Zuul: 網關組件, 提供智能路由、訪問過濾等功能。
- Archaius: 外部化配置組件。
- Spring Cloud Gateway:
- Spring Cloud Bus: 事件、消息總線, 用於傳播集羣中的狀態變化或事件, 以觸發後續的處理, 比如用來動態刷新配置等。
- Spring Cloud Cluster: 針對ZooKeeper、Redis、Hazelcast、Consul 的選舉算法和通用狀態模式的實現。
- Spring Cloud Consul: 服務發現與配置管理工具。
- Spring Cloud ZooKeeper: 基於ZooKeeper 的服務發現與配置管理組件。
- Spring Cloud Security:Spring Security組件封裝,提供用户驗證和權限驗證,一般與Spring Security OAuth2 組一起使用,通過搭建授權服務,驗證Token或者JWT這種形式對整個微服務系統進行安全驗證
- Spring Cloud Sleuth:分佈式鏈路追蹤組件,他分封裝了Dapper、Zipkin、Kibana 的組件
- Spring Cloud Stream:Spring Cloud框架的數據流操作包,可以封裝RabbitMq,ActiveMq,Kafka,Redis等消息組件,利用Spring Cloud Stream可以實現消息的接收和發送
spring-boot-starter-actuator:該模塊能夠自動為Spring Boot 構建的應用提供一系列用於監控的端點。
總結
- 單體架構:簡單方便,高度耦合,擴展性差,適合小型項目。例如:學生管理系統
- 分佈式架構:鬆耦合,擴展性好,但架構複雜,難度大。適合大型互聯網項目,例如:京東、淘寶
-
微服務:一種良好的分佈式架構方案
①優點:拆分粒度更小、服務更獨立、耦合度更低
②缺點:架構非常複雜,運維、監控、部署難度提高
- SpringCloud是微服務架構的一站式解決方案,集成了各種優秀微服務功能組件
服務拆分和遠程調用
任何分佈式架構都離不開服務的拆分,微服務也是一樣。
服務拆分原則
這裏我總結了微服務拆分時的幾個原則:
- 不同微服務,不要重複開發相同業務
- 微服務數據獨立,不要訪問其它微服務的數據庫
- 微服務可以將自己的業務暴露為接口,供其它微服務調用
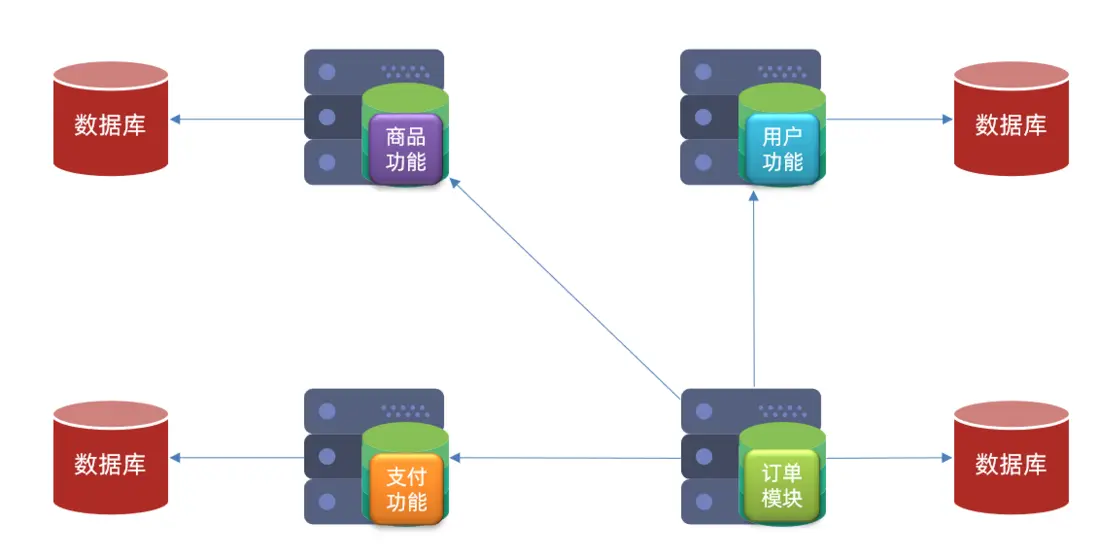
服務拆分示例
以課前資料中的微服務cloud-demo為例,其結構如下:
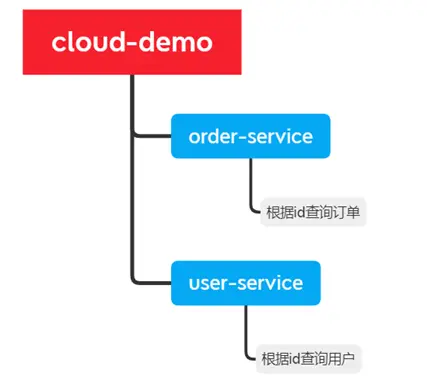
cloud-demo:父工程,管理依賴
- order-service:訂單微服務,負責訂單相關業務
- user-service:用户微服務,負責用户相關業務
要求:
- 訂單微服務和用户微服務都必須有各自的數據庫,相互獨立
- 訂單服務和用户服務都對外暴露Restful的接口
- 訂單服務如果需要查詢用户信息,只能調用用户服務的Restful接口,不能查詢用户數據庫
實現遠程調用案例
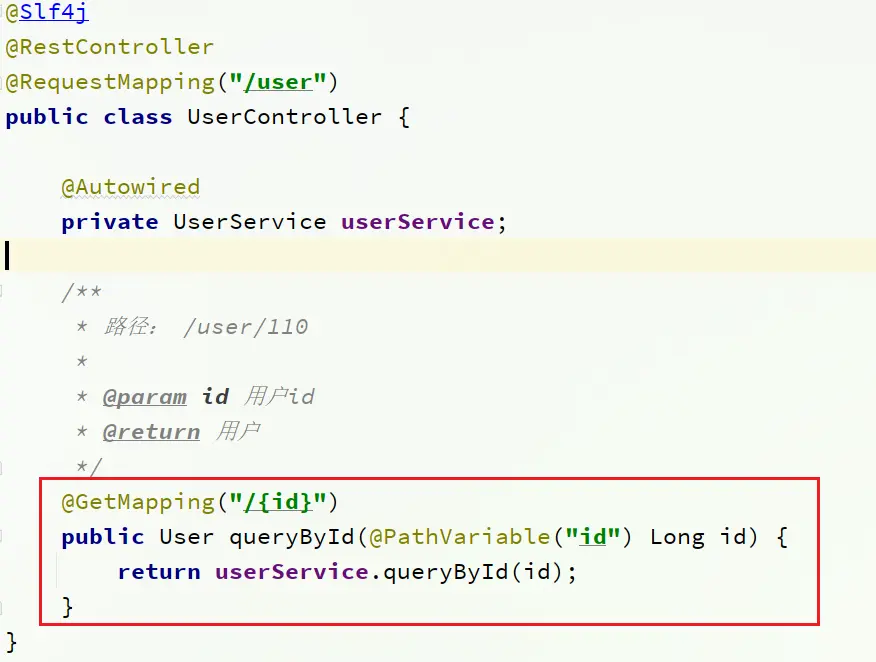
在order-service服務中,有一個根據id查詢訂單的接口:
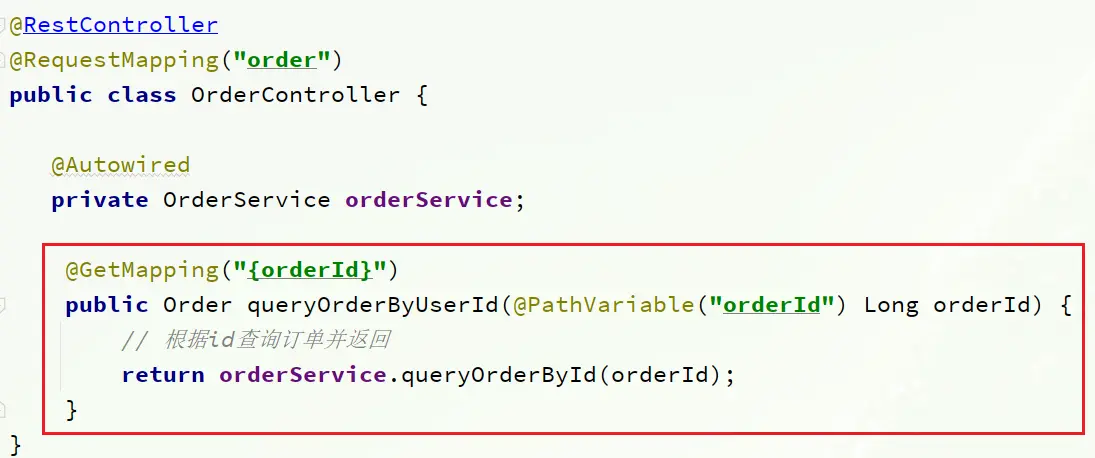
根據id查詢訂單,返回值是Order對象,如圖:
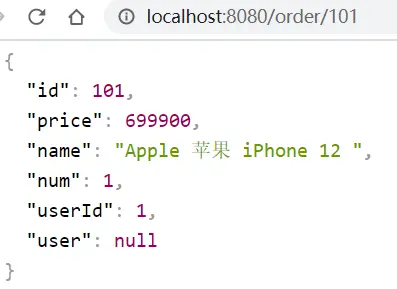
其中的user為null
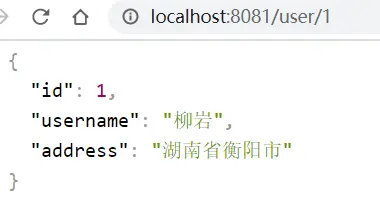
在user-service中有一個根據id查詢用户的接口:
查詢的結果如圖:
案例需求:
修改order-service中的根據id查詢訂單業務,要求在查詢訂單的同時,根據訂單中包含的userId查詢出用户信息,一起返回。
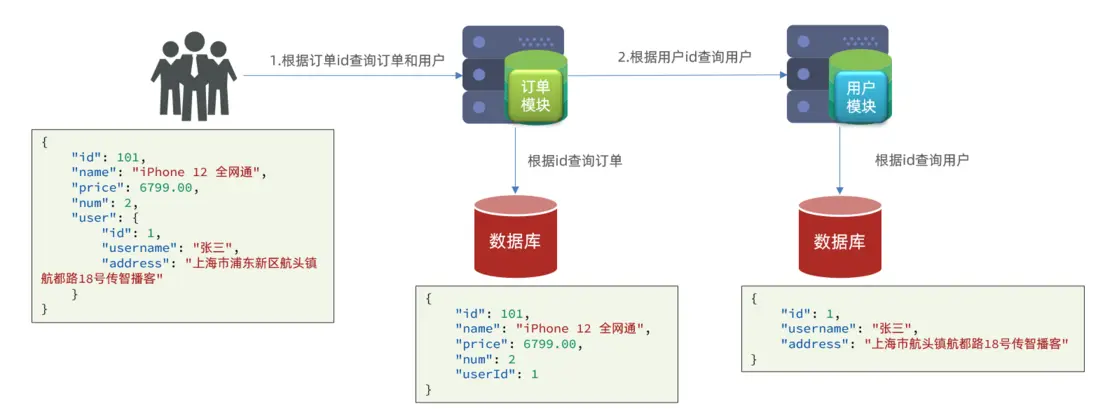
因此,我們需要在order-service中 向user-service發起一個http的請求,調用http://localhost:8081/user/{userId}這個接口。
大概的步驟是這樣的:
- 註冊一個RestTemplate的實例到Spring容器
- 修改order-service服務中的OrderService類中的queryOrderById方法,根據Order對象中的userId查詢User
- 將查詢的User填充到Order對象,一起返回
註冊RestTemplate
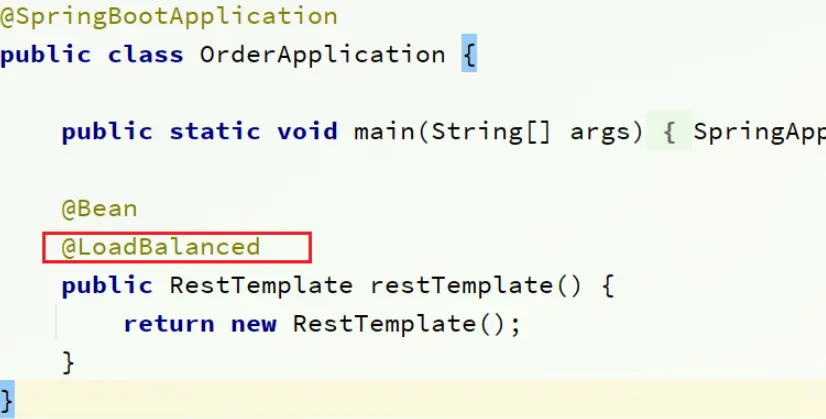
首先,我們在order-service服務中的OrderApplication啓動類中,註冊RestTemplate實例:
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("com.seven.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}實現遠程調用
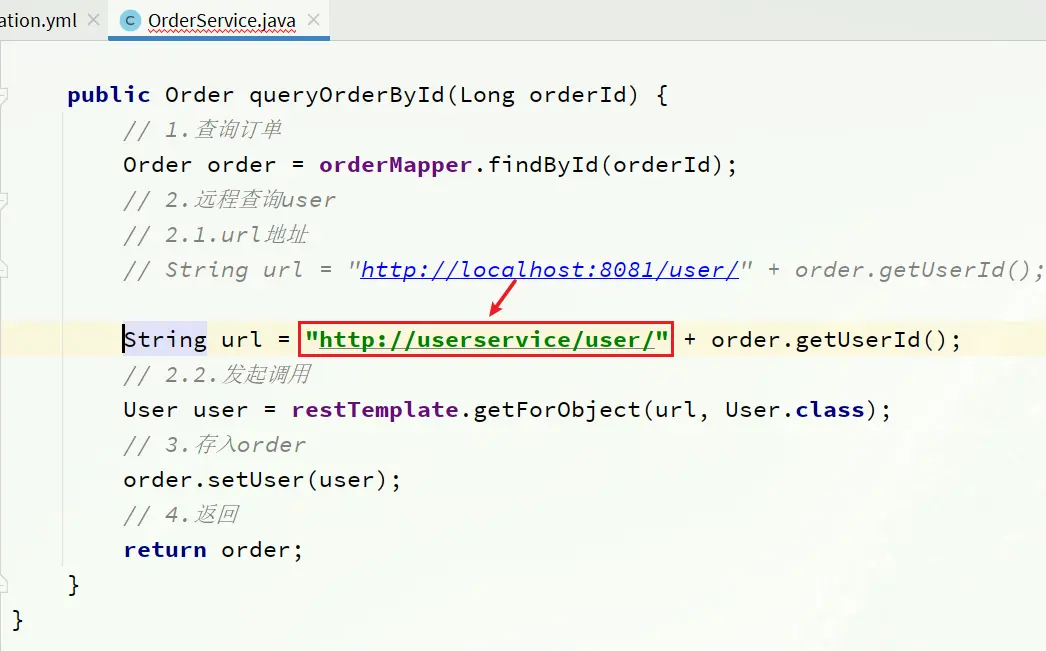
修改order-service服務中的cn.seven.order.service包下的OrderService類中的queryOrderById方法:
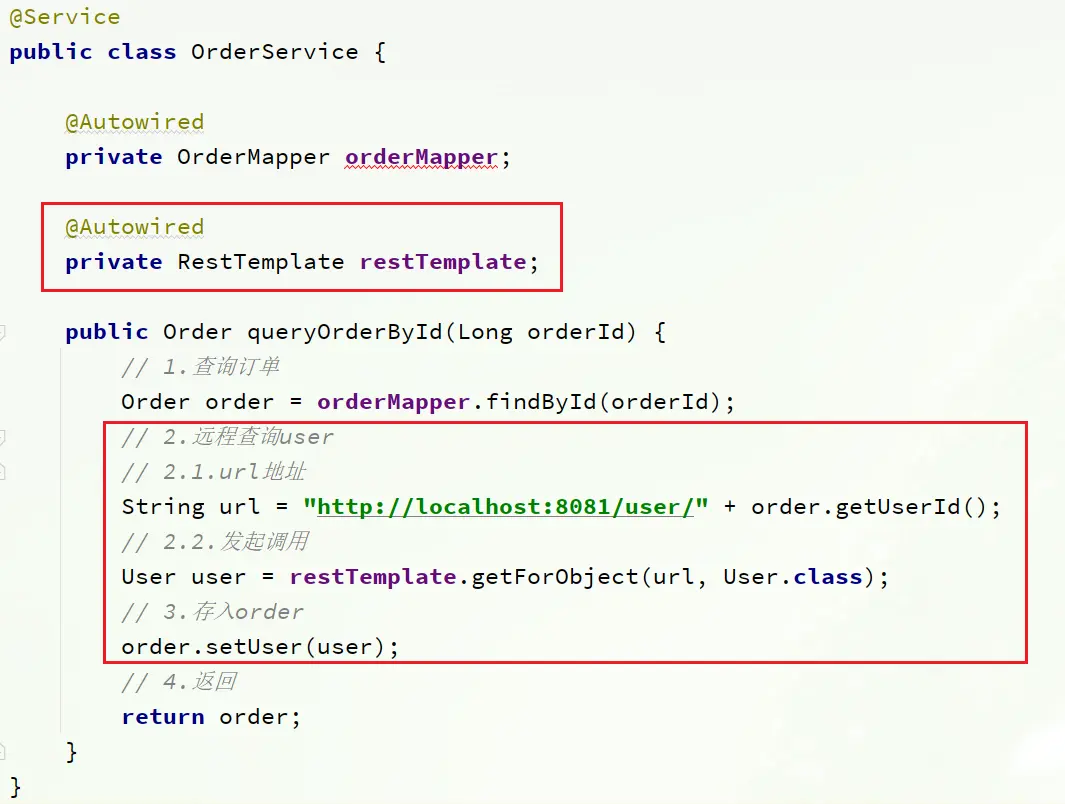
提供者與消費者
在服務調用關係中,會有兩個不同的角色:
服務提供者:一次業務中,被其它微服務調用的服務。(提供接口給其它微服務)
服務消費者:一次業務中,調用其它微服務的服務。(調用其它微服務提供的接口)

但是,服務提供者與服務消費者的角色並不是絕對的,而是相對於業務而言。
如果服務A調用了服務B,而服務B又調用了服務C,服務B的角色是什麼?
- 對於A調用B的業務而言:A是服務消費者,B是服務提供者
- 對於B調用C的業務而言:B是服務消費者,C是服務提供者
因此,服務B既可以是服務提供者,也可以是服務消費者。
Eureka註冊中心
假如我們的服務提供者user-service部署了多個實例,如圖:

大家思考幾個問題:
- order-service在發起遠程調用的時候,該如何得知user-service實例的ip地址和端口?
- 有多個user-service實例地址,order-service調用時該如何選擇?
- order-service如何得知某個user-service實例是否依然健康,是不是已經宕機?
Eureka的結構
這些問題都需要利用SpringCloud中的註冊中心來解決,其中最廣為人知的註冊中心就是Eureka,其結構如下:
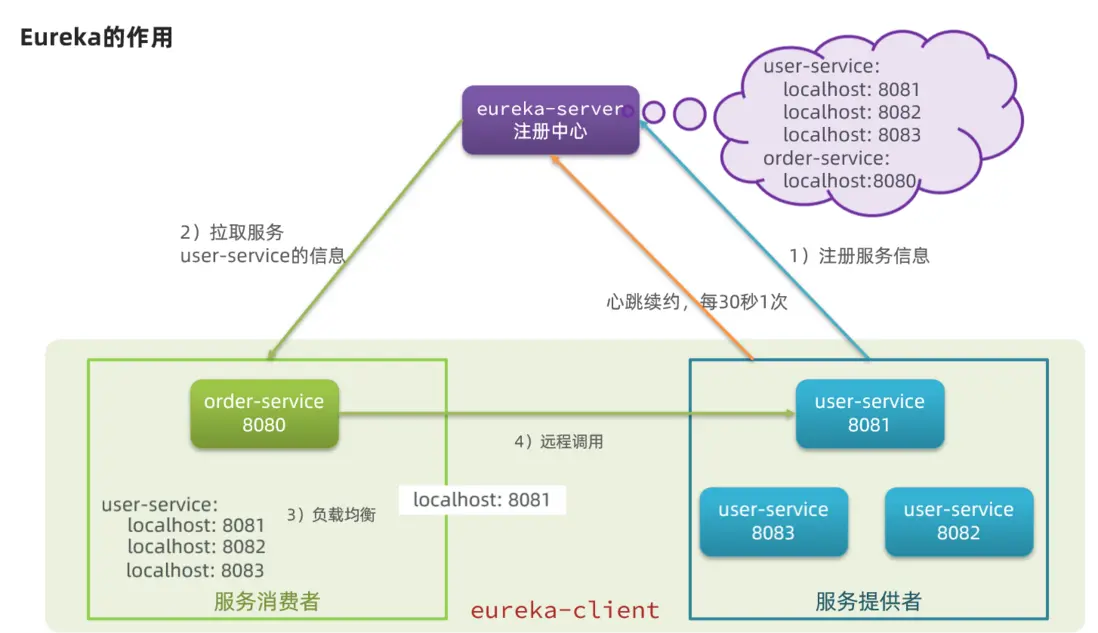
Spring Cloud Eureka實現微服務架構中的服務治理功能,使用 Netflix Eureka 實現服務註冊與發現,包含客户端組件和服務端組件。服務治理是微服務架構中最為核心和基礎的模塊。
Eureka 服務端就是服務註冊中心。Eureka 客户端用於處理服務的註冊和發現。客户端服務通過註解和參數配置的方式,嵌入在客户端應用程序的代碼中, 在應用程序運行時,Eureka客户端向註冊中心註冊自身提供的服務並週期性地發送心跳來更新它的服務租約。同時,它也能從服務端查詢當前註冊的服務信息並把它們緩存到本地並週期性地刷新服務狀態。
回答之前的各個問題。
問題1:order-service如何得知user-service實例地址?
獲取地址信息的流程如下:
- user-service服務實例啓動後,將自己的信息註冊到eureka-server(Eureka服務端)。這個叫服務註冊
- eureka-server保存服務名稱到服務實例地址列表的映射關係
- order-service根據服務名稱,拉取實例地址列表。這個叫服務發現或服務拉取
問題2:order-service如何從多個user-service實例中選擇具體的實例?
- order-service從實例列表中利用負載均衡算法選中一個實例地址
- 向該實例地址發起遠程調用
問題3:order-service如何得知某個user-service實例是否依然健康,是不是已經宕機?
- user-service會每隔一段時間(默認30秒)向eureka-server發起請求,報告自己狀態,稱為心跳
- 當超過一定時間沒有發送心跳時,eureka-server會認為微服務實例故障,將該實例從服務列表中剔除
- order-service拉取服務時,就能將故障實例排除了
注意:一個微服務,既可以是服務提供者,又可以是服務消費者,因此eureka將服務註冊、服務發現等功能統一封裝到了eureka-client端
服務註冊:在微服務架構中往往會有一個註冊中心,每個微服務都會向註冊中心去註冊自己的地址及端口信息,註冊中心維護着服務名稱與服務實例的對應關係。每個微服務都會定時從註冊中心獲取服務列表,同時彙報自己的運行情況,這樣當有的服務需要調用其他服務時,就可以從自己獲取到的服務列表中獲取實例地址進行調用。
服務發現:服務間的調用不是通過直接調用具體的實例地址,而是通過服務名發起調用。調用方需要向服務註冊中心諮詢服務,獲取服務的實例清單,從而訪問具體的服務實例。
因此,接下來我們動手實踐的步驟包括:
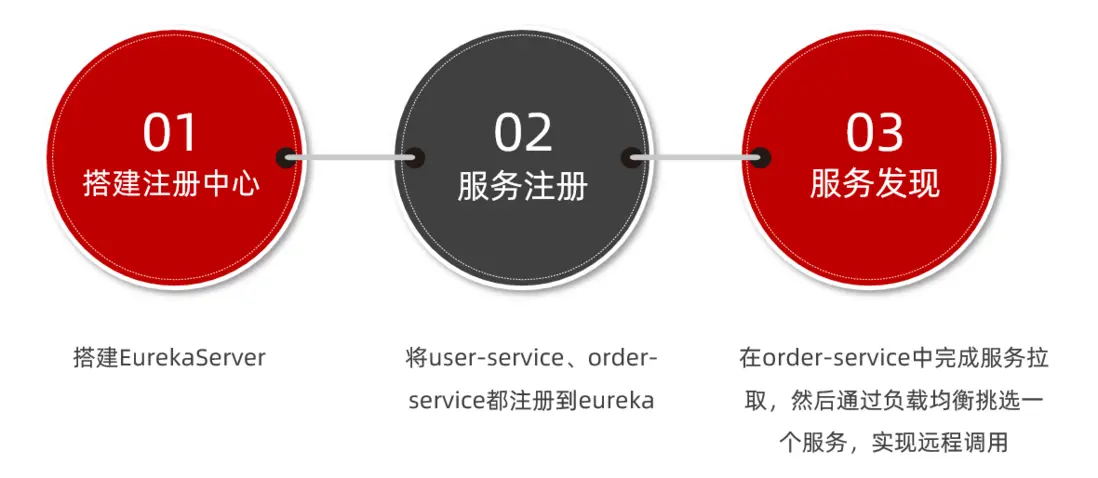
搭建eureka-server
首先大家註冊中心服務端:eureka-server,這必須是一個獨立的微服務
引入eureka依賴
引入SpringCloud為eureka提供的starter依賴:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>編寫啓動類
給eureka-server服務編寫一個啓動類,一定要添加一個@EnableEurekaServer註解,開啓eureka的註冊中心功能:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}編寫配置文件
編寫一個application.yml文件,內容如下:
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
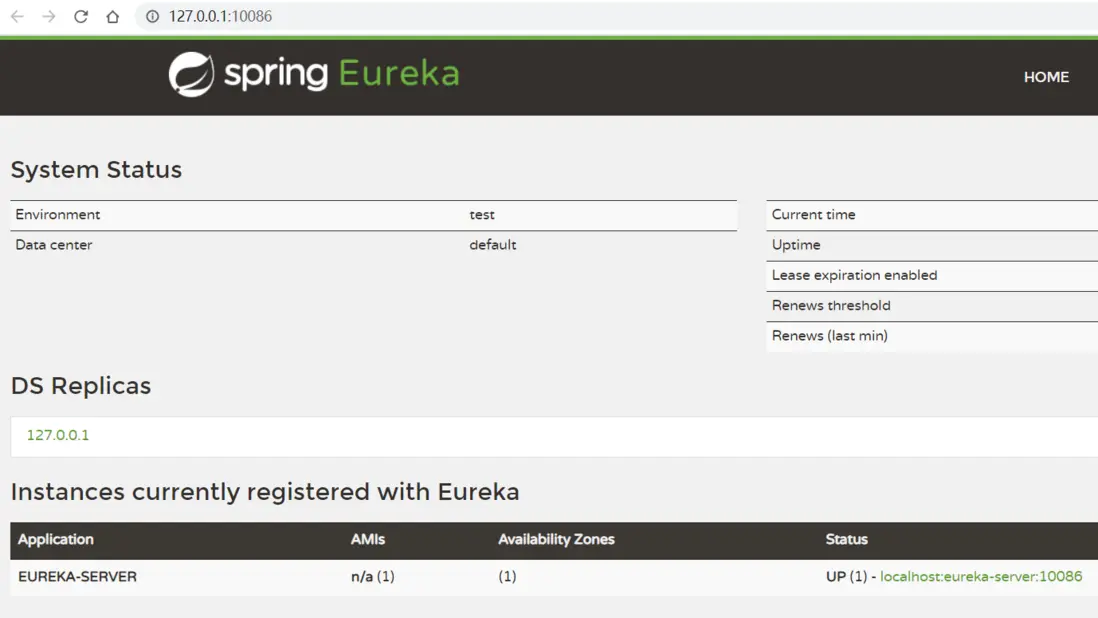
defaultZone: http://127.0.0.1:10086/eureka啓動服務
啓動微服務,然後在瀏覽器訪問:http://127.0.0.1:10086
看到下面結果就是成功了:
服務註冊
下面,我們將user-service註冊到eureka-server中去。
引入依賴
在user-service的pom文件中,引入下面的eureka-client依賴:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>配置文件
在user-service中,修改application.yml文件,添加服務名稱、eureka地址:
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka啓動多個user-service實例
為了演示一個服務有多個實例的場景,我們添加一個SpringBoot的啓動配置,再啓動一個user-service。
然後,在彈出的窗口中,填寫信息:

啓動兩個user-service實例:
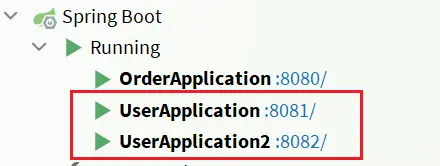
查看eureka-server管理頁面:

服務發現
下面,我們將order-service的邏輯修改:向eureka-server拉取user-service的信息,實現服務發現。
引入依賴
之前説過,服務發現、服務註冊統一都封裝在eureka-client依賴,因此這一步與服務註冊時一致。
在order-service的pom文件中,引入下面的eureka-client依賴:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>配置文件
服務發現也需要知道eureka地址,因此第二步與服務註冊一致,都是配置eureka信息:
在order-service中,修改application.yml文件,添加服務名稱、eureka地址:
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka服務拉取和負載均衡
最後,我們要去eureka-server中拉取user-service服務的實例列表,並且實現負載均衡。
不過這些動作不用我們去做,只需要添加一些註解即可。
在order-service的OrderApplication中,給RestTemplate這個Bean添加一個@LoadBalanced註解:
修改order-service服務中的cn.seven.order.service包下的OrderService類中的queryOrderById方法。修改訪問的url路徑,用服務名代替ip、端口:
spring會自動幫助我們從eureka-server端,根據userservice這個服務名稱,獲取實例列表,而後完成負載均衡。
自我保護模式
什麼是自我保護模式?
- 自我保護的條件:一般情況下,微服務在 Eureka 上註冊後,會每 30 秒發送心跳包,Eureka 通過心跳來判斷服務是否健康,同時會定期刪除超過 90 秒沒有發送心跳服務。
-
有兩種情況會導致 Eureka Server 收不到微服務的心跳
- 是微服務自身的原因
- 是微服務與 Eureka 之間的網絡故障
通常(微服務的自身的故障關閉)只會導致個別服務出現故障,一般不會出現大面積故障,而(網絡故障)通常會導致 Eureka Server 在短時間內無法收到大批心跳。考慮到這個區別,Eureka 設置了一個閥值,當判斷掛掉的服務的數量超過閥值時,Eureka Server 認為很大程度上出現了網絡故障,將不再刪除心跳過期的服務。
- 那麼這個閥值是多少呢?
15 分鐘之內是否低於 85%;Eureka Server 在運行期間,會統計心跳失敗的比例在 15 分鐘內是否低於 85%,這種算法叫做 Eureka Server 的自我保護模式。
為什麼要自我保護?
- 因為同時保留"好數據"與"壞數據"總比丟掉任何數據要更好,當網絡故障恢復後,這個 Eureka 節點會退出"自我保護模式"。
- Eureka 還有客户端緩存功能(也就是微服務的緩存功能)。即便 Eureka 集羣中所有節點都宕機失效,微服務的 Provider 和 Consumer都能正常通信。
- 微服務的負載均衡策略會自動剔除死亡的微服務節點。
Ribbon負載均衡
上一節中,我們添加了@LoadBalanced註解,即可實現負載均衡功能,這是什麼原理呢?
負載均衡原理
SpringCloud底層其實是利用了一個名為Ribbon的組件,來實現負載均衡功能的。
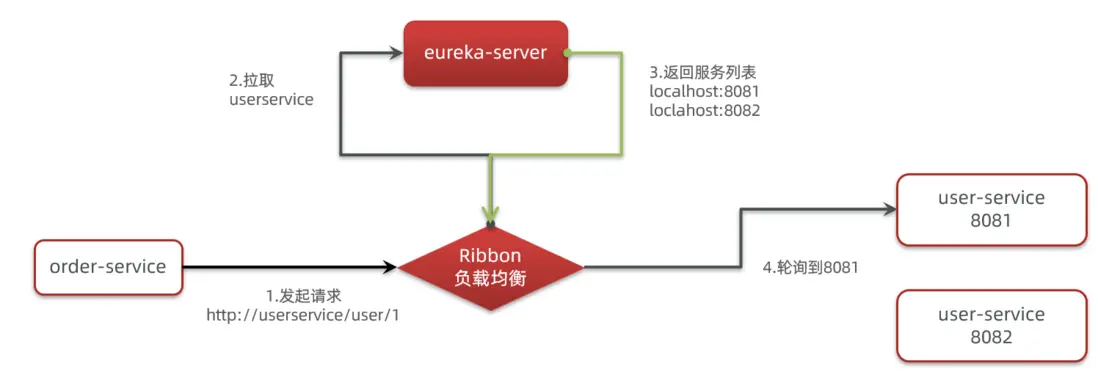
那麼我們發出的請求明明是http://userservice/user/1,怎麼變成了http://localhost:8081的呢?
什麼是 Ribbon
- Ribbon 是一個基於 Http 和 TCP 的客服端負載均衡工具,它是基於 Netflix Ribbon 實現的。
- 它不像 spring cloud 服務註冊中心、配置中心、API 網關那樣獨立部署,但是它幾乎存在於每個Spring cloud 微服務中。包括 feign 提供的聲明式服務調用也是基於該 Ribbon實現的。
- Ribbon 默認提供很多種負載均衡算法,例如 輪詢、隨機 等等。甚至包含自定義的負載均衡算法。
在客户端節點會維護可訪問的服務器清單,服務器清單來自服務註冊中心,通過心跳維持服務器清單的健康性。
開啓客户端負載均衡調用:
- 服務提供者啓動多個服務實例註冊到服務註冊中心;
- 服務消費者直接通過調用被@LoadBalanced 註解修飾過的RestTemplate 來實現面向服務的接口調用。
集中式與進程內負載均衡的區別
目前業界主流的負載均衡方案可分成兩類:
- 集中式負載均衡, 即在 consumer 和 provider 之間使用獨立的負載均衡設施(可以是硬件,如F5, 也可以是軟件,如 Nginx), 由該設施負責把 訪問請求 通過某種策略轉發至 provider;
- 進程內負載均衡,將負載均衡邏輯集成到 consumer,consumer 從服務註冊中心獲知有哪些地址可用,然後自己再從這些地址中選擇出一個合適的 provider。Ribbon 就屬於後者,它只是一個類庫,集成於 consumer 進程,consumer 通過它來獲取到 provider 的地址。
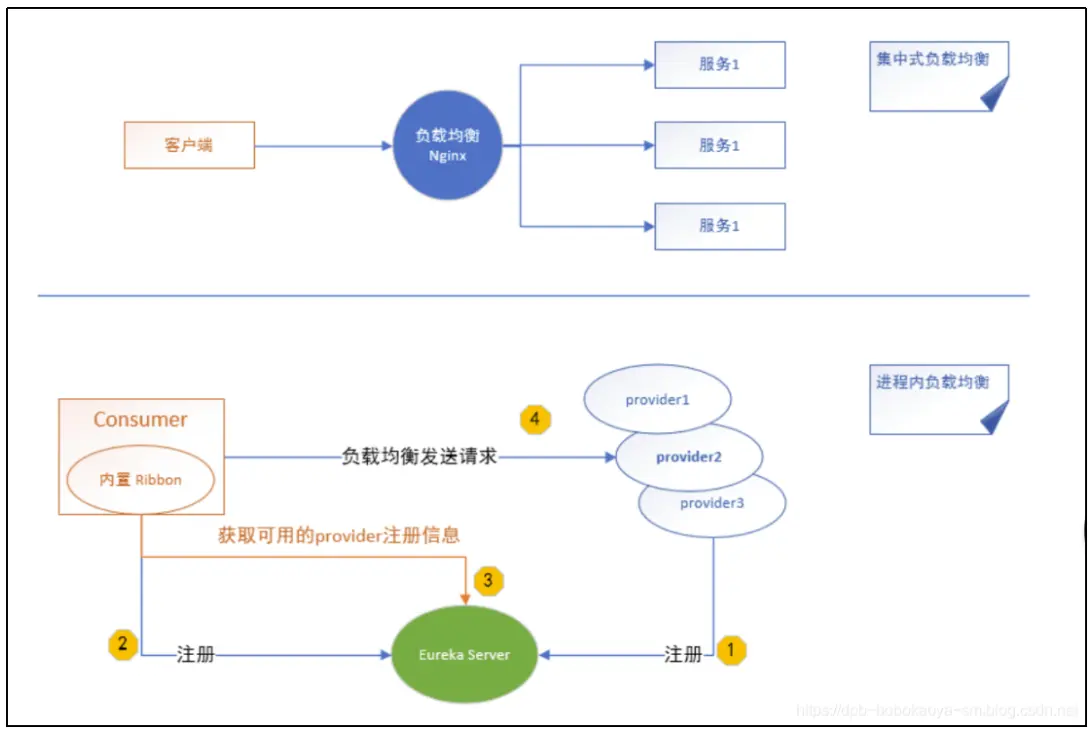
源碼跟蹤
為什麼我們只輸入了service名稱就可以訪問了呢?之前還要獲取ip和端口。
顯然有人幫我們根據service名稱,獲取到了服務實例的ip和端口。它就是LoadBalancerInterceptor,這個類會在對RestTemplate的請求進行攔截,然後從Eureka根據服務id獲取服務列表,隨後利用負載均衡算法得到真實的服務地址信息,替換服務id。
我們進行源碼跟蹤:
LoadBalancerIntercepor
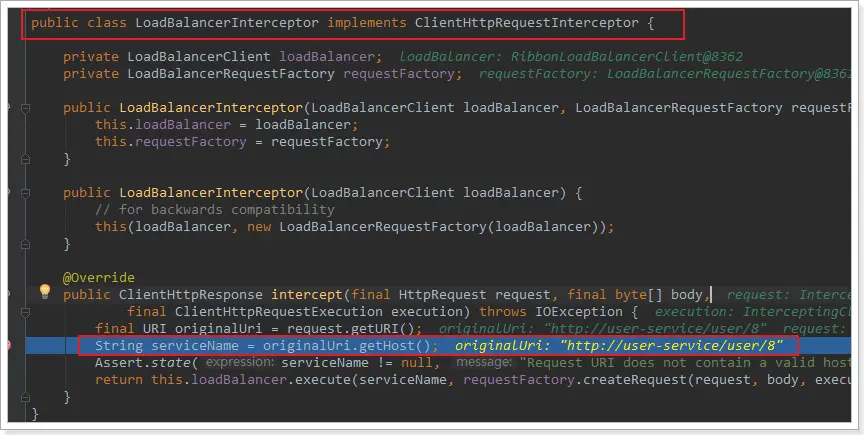
可以看到這裏的intercept方法,攔截了用户的HttpRequest請求,然後做了幾件事:
request.getURI():獲取請求uri,本例中就是 http://user-service/user/8originalUri.getHost():獲取uri路徑的主機名,其實就是服務id,user-servicethis.loadBalancer.execute():處理服務id,和用户請求。
這裏的this.loadBalancer是LoadBalancerClient類型,我們繼續跟入。
LoadBalancerClient
繼續跟入execute方法:
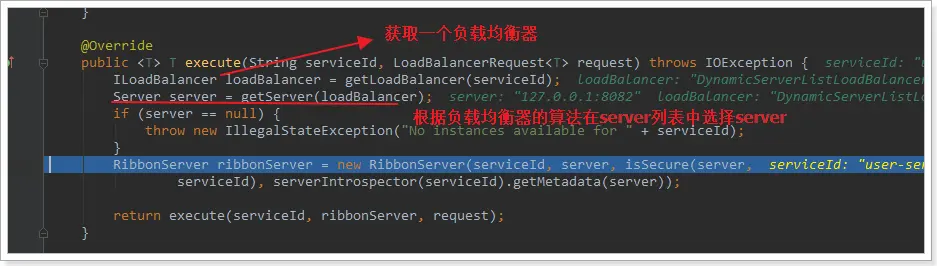
代碼是這樣的:
- getLoadBalancer(serviceId):根據服務id獲取ILoadBalancer,而ILoadBalancer會拿着服務id去eureka中獲取服務列表並保存起來。
- getServer(loadBalancer):利用內置的負載均衡算法,從服務列表中選擇一個。本例中,可以看到獲取了8082端口的服務
放行後,再次訪問並跟蹤,發現獲取的是8081:
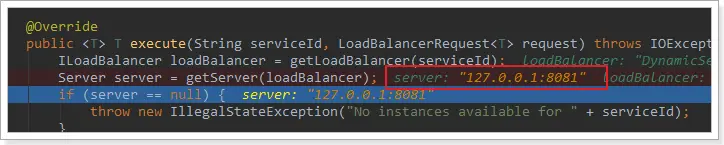
果然實現了負載均衡。
負載均衡策略IRule
在剛才的代碼中,可以看到獲取服務使通過一個getServer方法來做負載均衡:
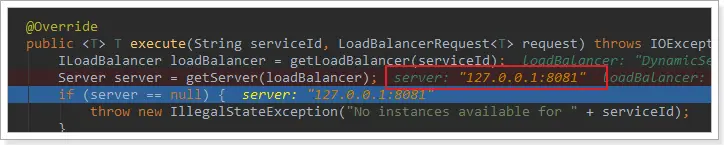
我們繼續跟入:
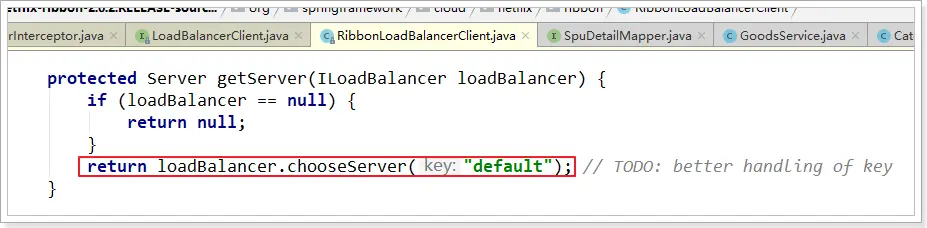
繼續跟蹤源碼chooseServer方法,發現這麼一段代碼:
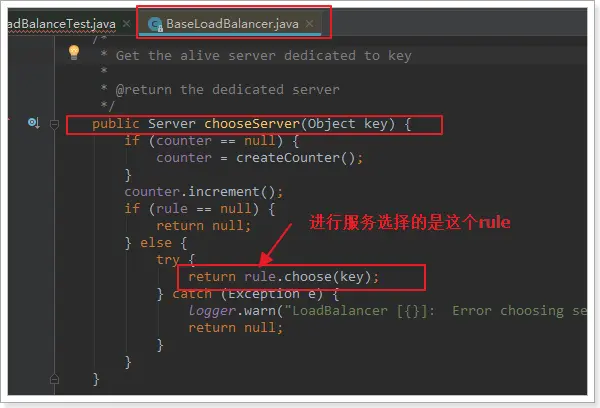
我們看看這個rule是誰:
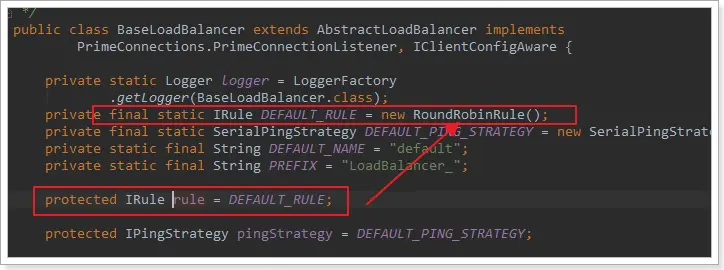
這裏的rule默認值是一個RoundRobinRule,看類的介紹:
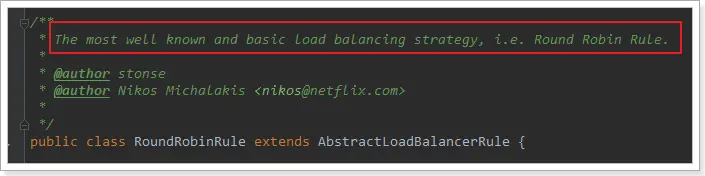
這不就是輪詢的意思嘛。
到這裏,整個負載均衡的流程我們就清楚了。
總結
SpringCloudRibbon的底層採用了一個攔截器,攔截了RestTemplate發出的請求,對地址做了修改。用一幅圖來總結一下:
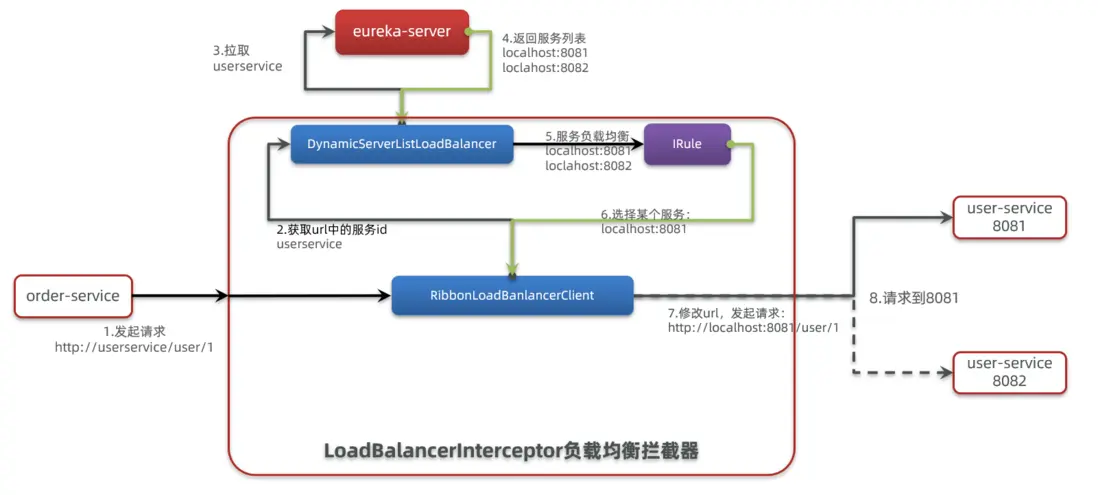
基本流程如下:
- 攔截我們的RestTemplate請求http://userservice/user/1
- RibbonLoadBalancerClient會從請求url中獲取服務名稱,也就是user-service
- DynamicServerListLoadBalancer根據user-service到eureka拉取服務列表
- eureka返回列表,localhost:8081、localhost:8082
- IRule利用內置負載均衡規則,從列表中選擇一個,例如localhost:8081
- RibbonLoadBalancerClient修改請求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,發起真實請求
負載均衡策略
負載均衡策略
負載均衡的規則都定義在IRule接口中,而IRule有很多不同的實現類:
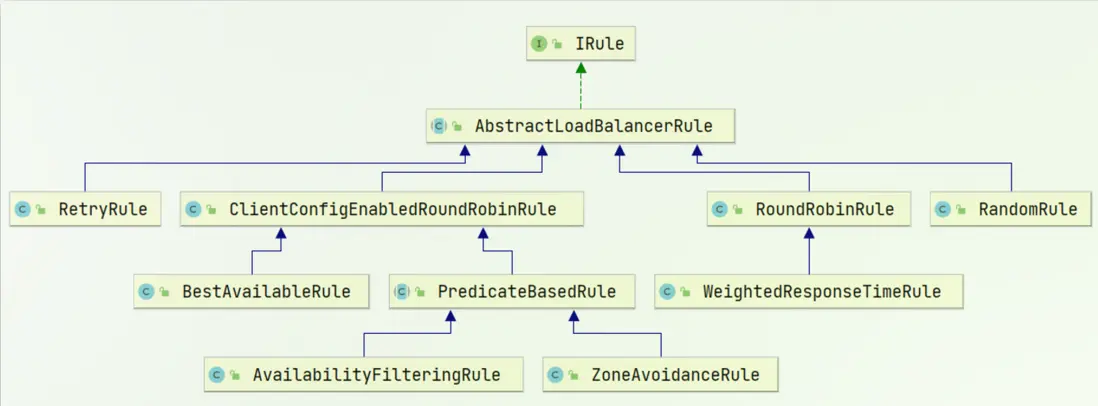
不同規則的含義如下:
| 內置負載均衡規則類 | 規則描述 |
|---|---|
| RoundRobinRule | 簡單輪詢服務列表來選擇服務器。它是Ribbon默認的負載均衡規則。 |
| AvailabilityFilteringRule | 對以下兩種服務器進行忽略:
(1)在默認情況下,這台服務器如果3次連接失敗,這台服務器就會被設置為“短路”狀態。短路狀態將持續30秒,如果再次連接失敗,短路的持續時間就會幾何級地增加。 (2)併發數過高的服務器。如果一個服務器的併發連接數過高,配置了AvailabilityFilteringRule規則的客户端也會將其忽略。併發連接數的上限,可以由客户端的 <clientName>.<clientConfigNameSpace>.ActiveConnectionsLimit屬性進行配置。 |
| WeightedResponseTimeRule | 為每一個服務器賦予一個權重值。服務器響應時間越長,這個服務器的權重就越小。這個規則會隨機選擇服務器,這個權重值會影響服務器的選擇。 |
| ZoneAvoidanceRule | 以區域可用的服務器為基礎進行服務器的選擇。使用Zone對服務器進行分類,這個Zone可以理解為一個機房、一個機架等。而後再對Zone內的多個服務做輪詢。 |
| BestAvailableRule | 忽略那些短路的服務器,並選擇併發數較低的服務器。 |
| RandomRule | 隨機選擇一個可用的服務器。 |
| RetryRule | 重試機制的選擇邏輯 |
默認的實現就是ZoneAvoidanceRule,是一種輪詢方案
自定義負載均衡策略
通過定義IRule實現可以修改負載均衡規則,有兩種方式:
- 代碼方式:在order-service中的OrderApplication類中,定義一個新的IRule:
@Bean
public IRule randomRule(){
return new RandomRule();
}- 配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改規則:
userservice: # 給某個微服務配置負載均衡規則,這裏是userservice服務
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 負載均衡規則 注意,一般用默認的負載均衡規則,不做修改。
飢餓加載
Ribbon默認是採用懶加載,即第一次訪問時才會去創建LoadBalanceClient,請求時間會很長。
而飢餓加載則會在項目啓動時創建,降低第一次訪問的耗時,通過下面配置開啓飢餓加載:
ribbon:
eager-load:
enabled: true
clients: userserviceHystrix
在微服務架構中,服務與服務之間通過遠程調用的方式進行通信,一旦某個被調用的服務發生了故障,其依賴服務也會發生故障,此時就會發生故障的蔓延,最終導致災難性雪崩效應。Hystrix實現了斷路器模式,當某個服務發生故障時,通過斷路器的監控,給調用方返回一個錯誤響應,而不是長時間的等待,這樣就不會使得調用方由於長時間得不到響應而佔用線程,從而防止故障的蔓延。Hystrix具備服務降級、服務熔斷、線程隔離、請求緩存、請求合併及服務監控等強大功能。
Hystrix介紹
什麼是災難性的雪崩效應
什麼是災難性的雪崩效應?我們通過結構圖來説明,如下
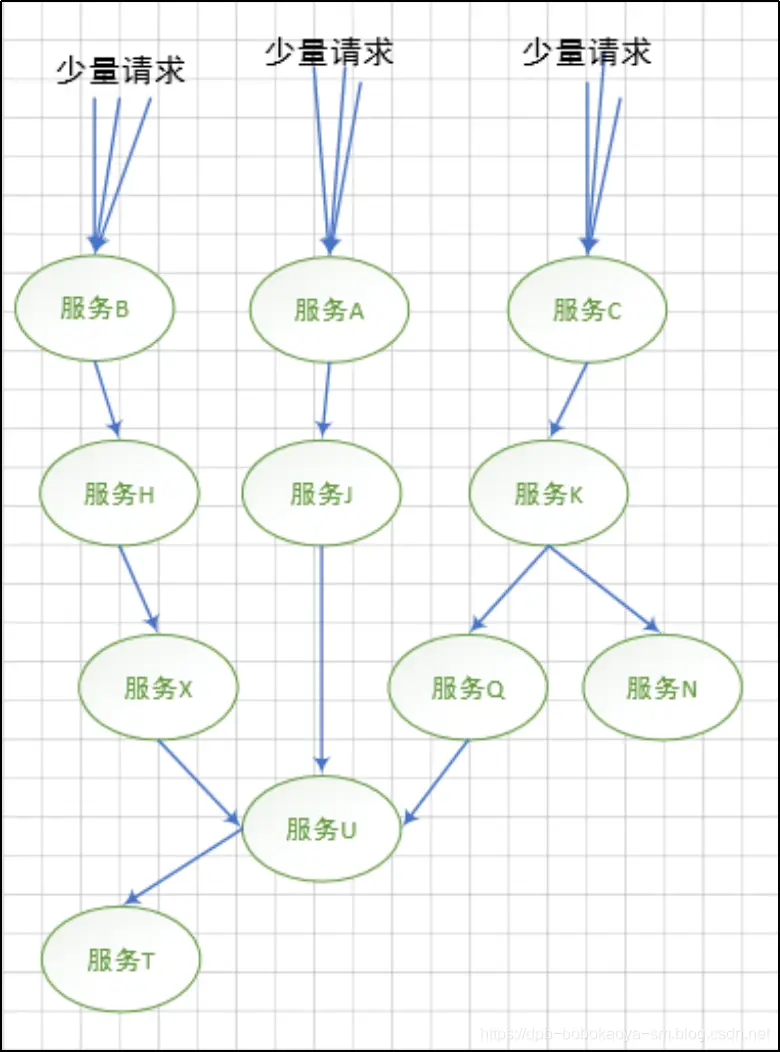
正常情況下各個節點相互配置,完成用户請求的處理工作
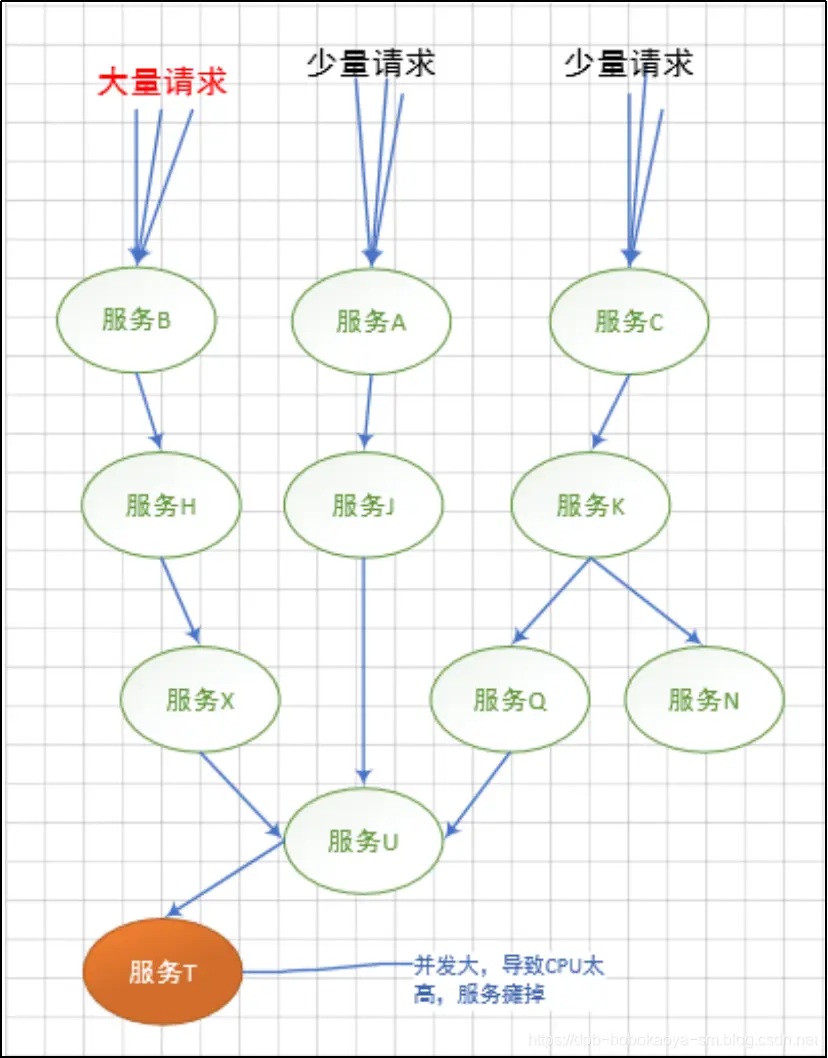
當某種請求增多,造成"服務T"故障的情況時,會延伸的造成"服務U"不可用,及繼續擴展,如下
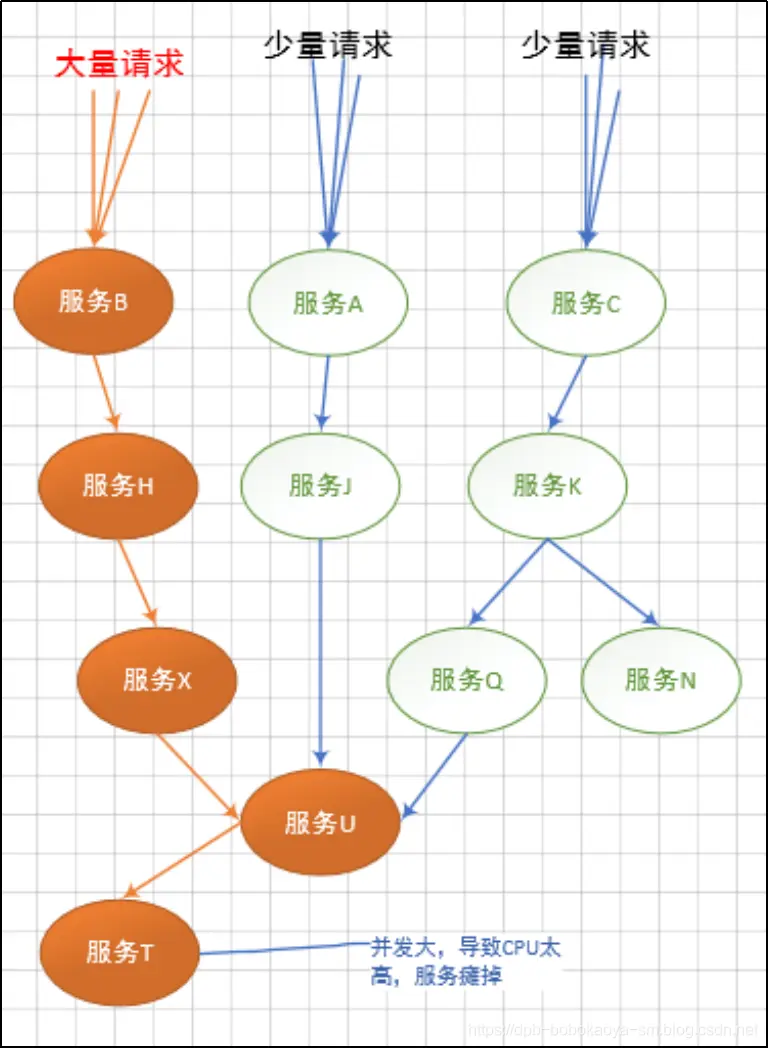
最終造成下面這種所有服務不可用的情況
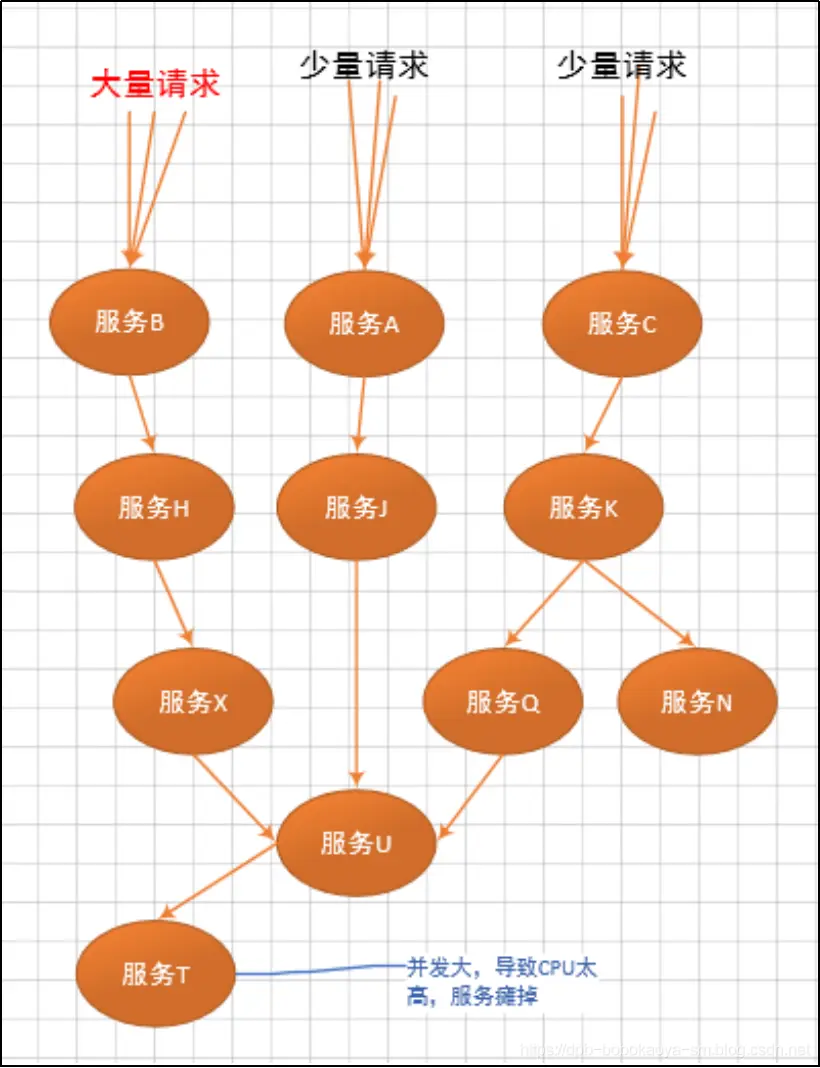
這就是我們講的災難性雪崩,造成雪崩的原因可以歸納為以下三個:
- 服務提供者不可用(硬件故障,程序Bug,緩存擊穿,用户大量請求)
- 重試加大流量(用户重試,代碼邏輯重試)
- 服務調用者不可用(同步等待造成的資源耗盡)
最終的結果就是一個服務不可用,導致一系列服務的不可用,而往往這種後果是無法預料的。
如何解決災難性雪崩效應
我們可以通過以下5種方式來解決雪崩效應
- 降級:超時降級、資源不足時(線程或信號量)降級,降級後可以配合降級接口返回託底數據。實現一個 fallback 方法, 當請求後端服務出現異常的時候, 可以使用 fallback 方法返回的值.
- 緩存:Hystrix 為了降低訪問服務的頻率,支持將一個請求與返回結果做緩存處理。如果再次請求的 URL 沒有變化,那麼 Hystrix 不會請求服務,而是直接從緩存中將結果返回。這樣可以大大降低訪問服務的壓力。
- 請求合併:在微服務架構中,我們將一個項目拆分成很多個獨立的模塊,這些獨立的模塊通過遠程調用來互相配合工作,但是,在高併發情況下,通信次數的增加會導致總的通信時間增加,同時,線程池的資源也是有限的,高併發環境會導致有大量的線程處於等待狀態,進而導致響應延遲,為了解決這些問題,我們需要來了解 Hystrix 的請求合併。
- 熔斷:當失敗率(如因網絡故障/超時造成的失敗率高)達到閥值自動觸發降級,熔斷器觸發的快速失敗會進行快速恢復。
- 隔離(線程池隔離和信號量隔離)
限制調用分佈式服務的資源使用,某一個調用的服務出現問題不會影響其他服務調用。
降級
場景介紹
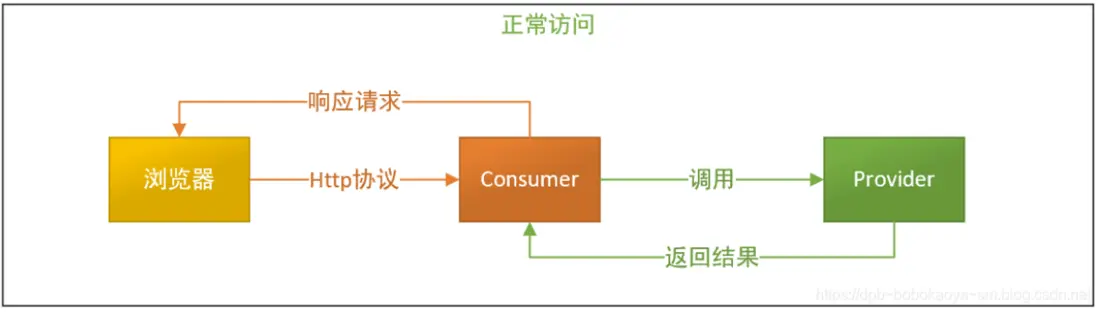
先來看下正常服務調用的情況
當consumer調用provider服務出現問題的情況下:
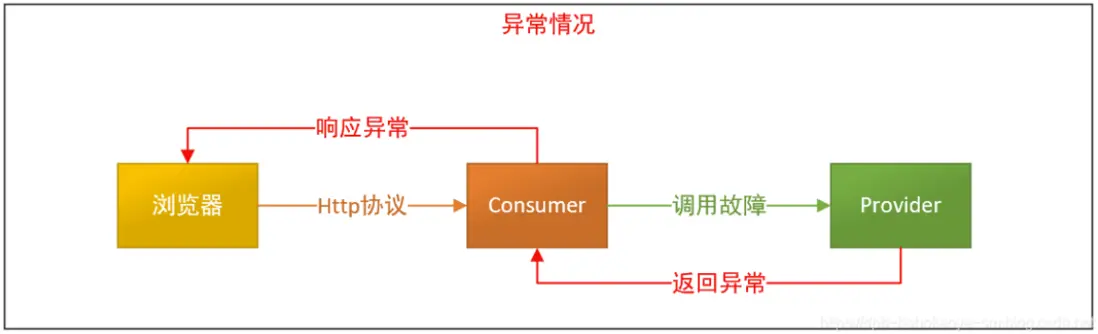
此時我們對consumer的服務調用做降級處理
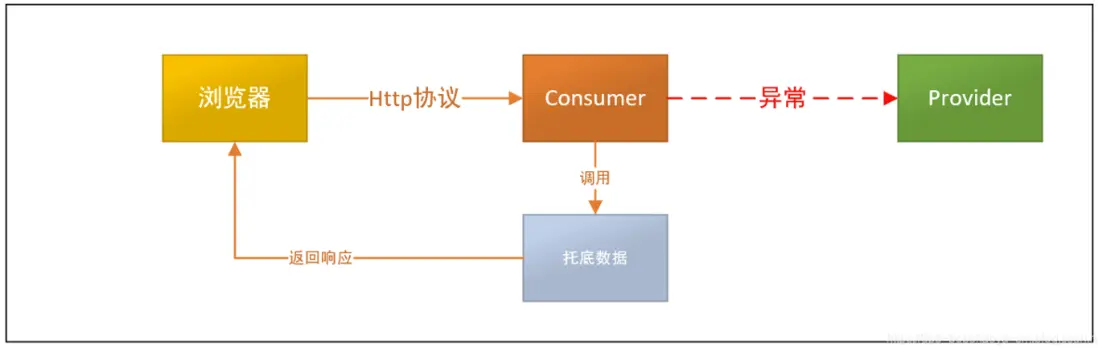
實現案例
創建一個基於Ribbon的Consumer服務,並添加對應的依賴
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<!-- 添加Hystrix的依賴 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>配置文件
spring.application.name=eureka-consumer-hystrix
server.port=9091
# 設置服務註冊中心地址 執行Eureka服務端 如果有多個註冊地址 那麼用逗號連接
eureka.client.service-url.defaultZone=http://seven:123456@192.168.100.120:8761/eureka/,http://seven:123456@192.168.100.121:8761/eureka/修改啓動類
在啓動類中添加 開啓熔斷
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
@EnableCircuitBreaker // 開啓Hystrix的熔斷
@SpringBootApplication
public class SpringcloudEurekaConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringcloudEurekaConsumerApplication.class, args);
}
}業務層修改
業務層代碼中的方法是通過Ribbon來獲取負載均衡的服務器地址的,通過RestTemplate來調用服務,在方法的頭部添加@HystrixCommand註解,通過fallbackMethod屬性指定當調用Provider方法異常的時候fallback方法請求返回託底數據
import com.seven.pojo.User;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
@Service
public class UserService {
/**
* Ribbon 實現的負載均衡
* LocadBalancerClient 通過服務名稱可以獲取對應服務的相關信息
* ip 端口 等
*/
@Autowired
private LoadBalancerClient loadBalancerClient;
/**
* 遠程調用 服務提供者獲取用户信息的方法
* 1.發現服務
* 2.調用服務
*/
@HystrixCommand(fallbackMethod = "fallBack")
public List<User> getUsers(){
// 1. 服務發現
// 獲取服務提供者的信息 ServiceInstance封裝的有相關的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println(sb.toString());
// 2. 服務調用 SpringMVC中提供的有 調用組件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
/**
* 託底方法
* @return
*/
public List<User> fallBack(){
List<User> list = new ArrayList<>();
list.add(new User(333,"我是託底數據",28));
return list;
}
}
緩存
Hystrix 為了降低訪問服務的頻率,支持將一個請求與返回結果做緩存處理。如果再次請求的 URL 沒有變化,那麼 Hystrix 不會請求服務,而是直接從緩存中將結果返回。這樣可以大大降低訪問服務的壓力。
Hystrix 自帶緩存。有兩個缺點:
- 是一個本地緩存。在集羣情況下緩存是不能同步的。
- 不支持第三方緩存容器。Redis,memcache 不支持的。
所以我們使用Spring的cache。
啓動Redis服務
使用Redis作為緩存服務器
添加相關的依賴
因為需要用到SpringDataRedis的支持,需要添加對應的依賴
<!-- 添加Hystrix的依賴 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
<!-- 添加SpringDataRedis的依賴 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>修改屬性文件
需要在屬性文件中添加Redis的配置信息
spring.application.name=eureka-consumer-hystrix
server.port=9091
# 設置服務註冊中心地址 執行Eureka服務端 如果有多個註冊地址 那麼用逗號連接
eureka.client.service-url.defaultZone=http://seven:123456@192.168.100.120:8761/eureka/,http://seven:123456@192.168.100.121:8761/eureka/
# Redis
spring.redis.database=0
#Redis 服務器地址
spring.redis.host=192.168.100.120
#Redis 服務器連接端口
spring.redis.port=6379
#Redis 服務器連接密碼(默認為空)
spring.redis.password=
#連接池最大連接數(負值表示沒有限制)
spring.redis.pool.max-active=100
#連接池最大阻塞等待時間(負值表示沒有限制)
spring.redis.pool.max-wait=3000
#連接池最大空閉連接數
spring.redis.pool.max-idle=200
#連接漢最小空閒連接數
spring.redis.pool.min-idle=50
#連接超時時間(毫秒)
spring.redis.pool.timeout=600修改啓動類
需要在啓動類中開啓緩存的使用
@EnableCaching // 開啓緩存
@EnableCircuitBreaker // 開啓Hystrix的熔斷
@SpringBootApplication
public class SpringcloudEurekaConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringcloudEurekaConsumerApplication.class, args);
}
}業務處理
import com.seven.pojo.User;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheConfig;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
@Service
// cacheNames 當前類中的方法在Redis中添加的Key的前綴
@CacheConfig(cacheNames = {"com.seven.cache"})
public class UserService {
/**
* Ribbon 實現的負載均衡
* LocadBalancerClient 通過服務名稱可以獲取對應服務的相關信息
* ip 端口 等
*/
@Autowired
private LoadBalancerClient loadBalancerClient;
/**
* 遠程調用 服務提供者獲取用户信息的方法
* 1.發現服務
* 2.調用服務
*/
@HystrixCommand(fallbackMethod = "fallBack")
public List<User> getUsers(){
// 1. 服務發現
// 獲取服務提供者的信息 ServiceInstance封裝的有相關的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println(sb.toString());
// 2. 服務調用 SpringMVC中提供的有 調用組件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
/**
* 託底方法
* @return
*/
public List<User> fallBack(){
List<User> list = new ArrayList<>();
list.add(new User(333,"我是託底數據",28));
return list;
}
@Cacheable(key="'user'+#id")
public User getUserById(Integer id){
System.out.println("*************查詢操作*************"+ id);
return new User(id,"緩存測試數據",22);
}
}
使用到了緩存,所以會對POJO對象做持久化處理,所以需要實現序列化接口,否則會拋異常
請求合併
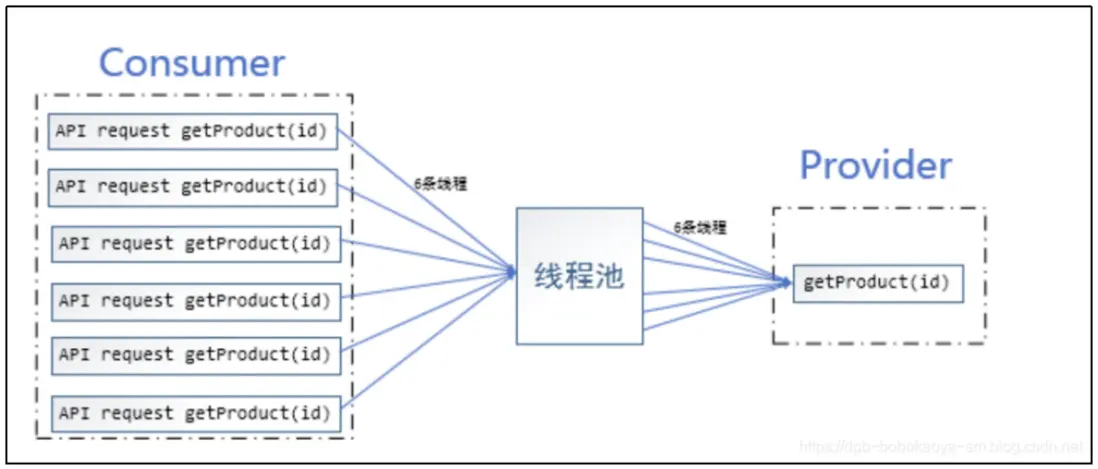
沒有合併請求的場景
沒有合併的場景中,對於provider的調用會非常的頻繁,容易造成處理不過來的情況
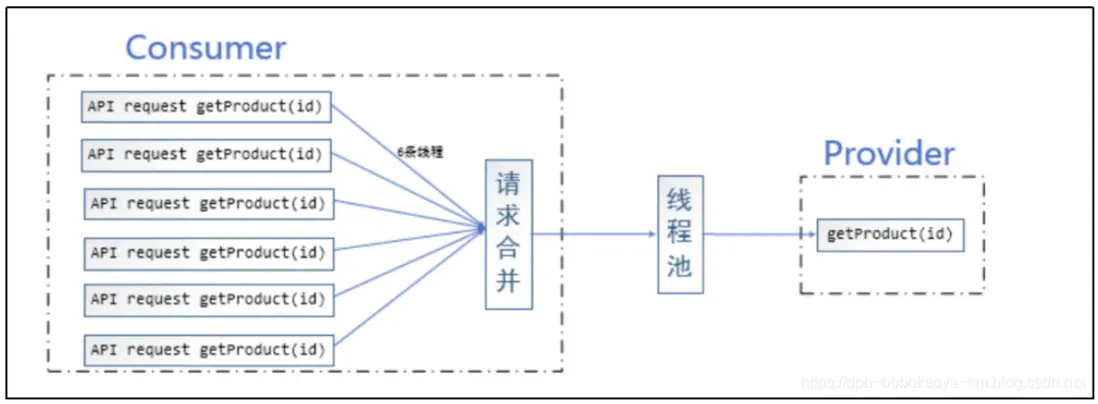
合併請求的場景
什麼情況下使用請求合併
在微服務架構中,我們將一個項目拆分成很多個獨立的模塊,這些獨立的模塊通過遠程調用來互相配合工作,但是,在高併發情況下,通信次數的增加會導致總的通信時間增加,同時,線程池的資源也是有限的,高併發環境會導致有大量的線程處於等待狀態,進而導致響應延遲,為了解決這些問題,我們需要來了解 Hystrix 的請求合併。
請求合併的缺點
設置請求合併之後,本來一個請求可能 5ms 就搞定了,但是現在必須再等 10ms 看看還有沒有其他的請求一起的,這樣一個請求的耗時就從 5ms 增加到 15ms 了,不過,如果我們要發起的命令本身就是一個高延遲的命令,那麼這個時候就可以使用請求合併了,因為這個時候時間窗的時間消耗就顯得微不足道了,另外高併發也是請求合併的一個非常重要的場景。
案例實現
業務處理代碼
import com.seven.pojo.User;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCollapser;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheConfig;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Future;
@Service
// cacheNames 當前類中的方法在Redis中添加的Key的前綴
@CacheConfig(cacheNames = {"com.seven.cache"})
public class UserService {
/**
* Ribbon 實現的負載均衡
* LocadBalancerClient 通過服務名稱可以獲取對應服務的相關信息
* ip 端口 等
*/
@Autowired
private LoadBalancerClient loadBalancerClient;
/**
* 遠程調用 服務提供者獲取用户信息的方法
* 1.發現服務
* 2.調用服務
* @return
*/
@HystrixCommand(fallbackMethod = "fallBack")
public List<User> getUsers(){
// 1. 服務發現
// 獲取服務提供者的信息 ServiceInstance封裝的有相關的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println(sb.toString());
// 2. 服務調用 SpringMVC中提供的有 調用組件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
/**
* 託底方法
* @return
*/
public List<User> fallBack(){
List<User> list = new ArrayList<>();
list.add(new User(333,"我是託底數據",28));
return list;
}
@Cacheable(key="'user'+#id")
public User getUserById(Integer id){
System.out.println("*************查詢操作*************"+ id);
return new User(id,"緩存測試數據",22);
}
/**
* Consumer中的Controller要調用的方法
* 這個方法的返回值必須是 Future 類型
* 利用Hystrix 合併請求
*/
@HystrixCollapser(
batchMethod = "batchUser"
,scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL
,collapserProperties = {
// 請求時間間隔在20ms以內的請求會被合併,默認值是10ms
@HystrixProperty(name = "timerDelayInMilliseconds",value = "20")
// 設置觸發批處理執行之前 在批處理中允許的最大請求數
,@HystrixProperty(name = "maxRequestsInBatch",value = "200")
}
)
public Future<User> getUserId(Integer id){
System.out.println("*****id*****");
return null;
}
@HystrixCommand
public List<User> batchUser(List<Integer> ids){
for (Integer id : ids) {
System.out.println(id);
}
List<User> list = new ArrayList<>();
list.add(new User(1,"張三1",18));
list.add(new User(2,"張三2",18));
list.add(new User(3,"張三3",18));
list.add(new User(4,"張三4",18));
return list;
}
}
控制器處理
@RequestMapping("/getUserId")
public void getUserId() throws Exception{
Future<User> f1 = service.getUserId(1);
Future<User> f2 = service.getUserId(1);
Future<User> f3 = service.getUserId(1);
System.out.println("*************************");
System.out.println(f1.get().toString());
System.out.println(f2.get().toString());
System.out.println(f3.get().toString());
}
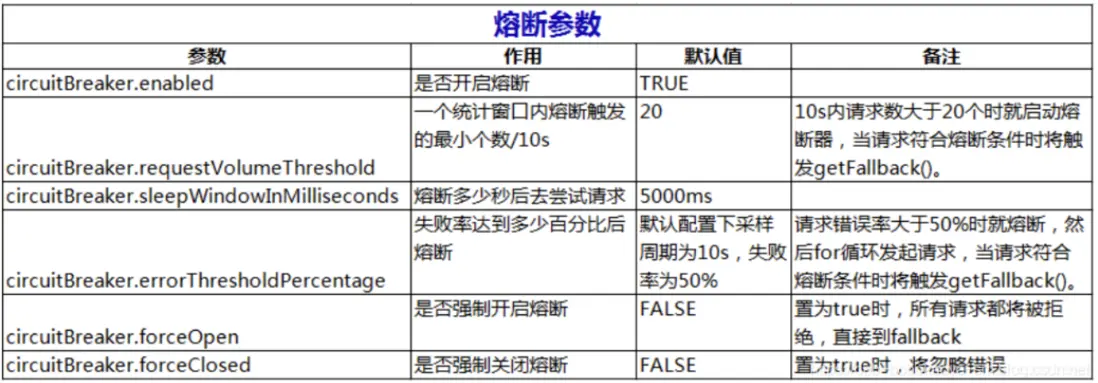
熔斷
熔斷其實是在降級的基礎上引入了重試的機制。當某個時間內失敗的次數達到了多少次就會觸發熔斷機制,具體的流程如下
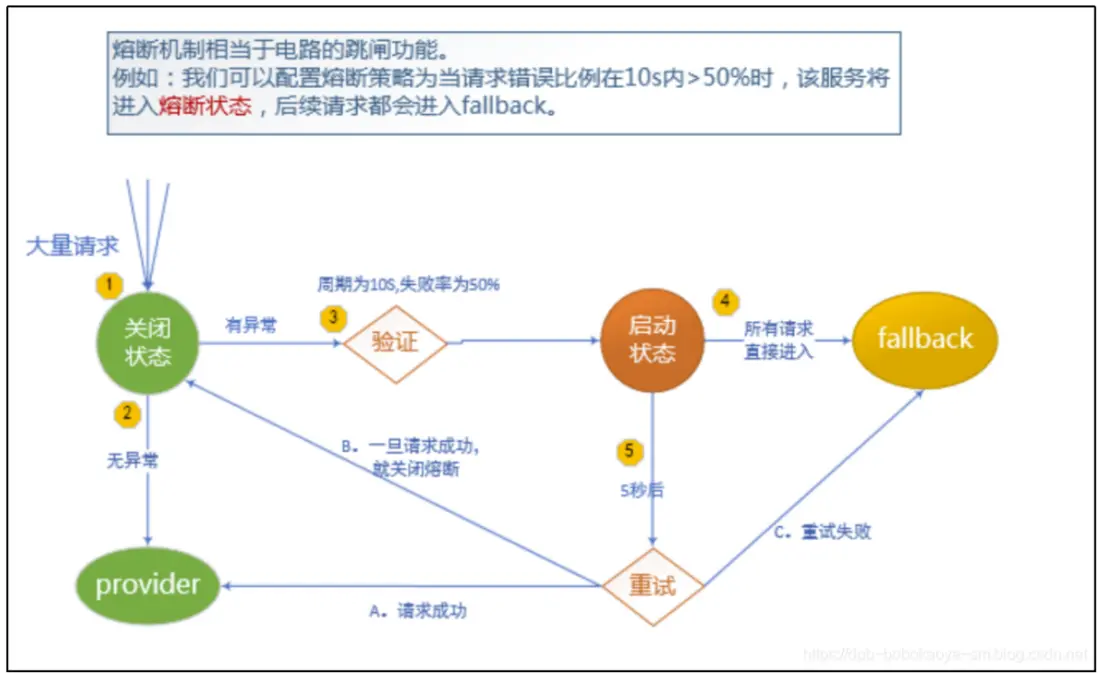
案例核心代碼
@HystrixCommand(fallbackMethod = "fallback",
commandProperties = {
//默認 20 個;10s 內請求數大於 20 個時就啓動熔斷器,當請求符合熔斷條件時將觸發 getFallback()。
@HystrixProperty(name= HystrixPropertiesManager.CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD,
value="10"),
//請求錯誤率大於 50%時就熔斷,然後 for 循環發起請求,當請求符合熔斷條件時將觸發 getFallback()。
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE,
value="50"),
//默認 5 秒;熔斷多少秒後去嘗試請求
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS,
value="5000"),
})
public List<User> getUsers(){
// 1. 服務發現
// 獲取服務提供者的信息 ServiceInstance封裝的有相關的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println("---->"+sb.toString());
// 2. 服務調用 SpringMVC中提供的有 調用組件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
隔離
在應對服務雪崩效應時,除了前面介紹的降級,緩存,請求合併及熔斷外還有一種方式就是隔離,隔離又分為線程池隔離和信號量隔離。接下來我們分別來介紹。
線程池隔離
概念介紹
我們通過以下幾個圖片來解釋線程池隔離到底是怎麼回事
在沒有使用線程池隔離時:
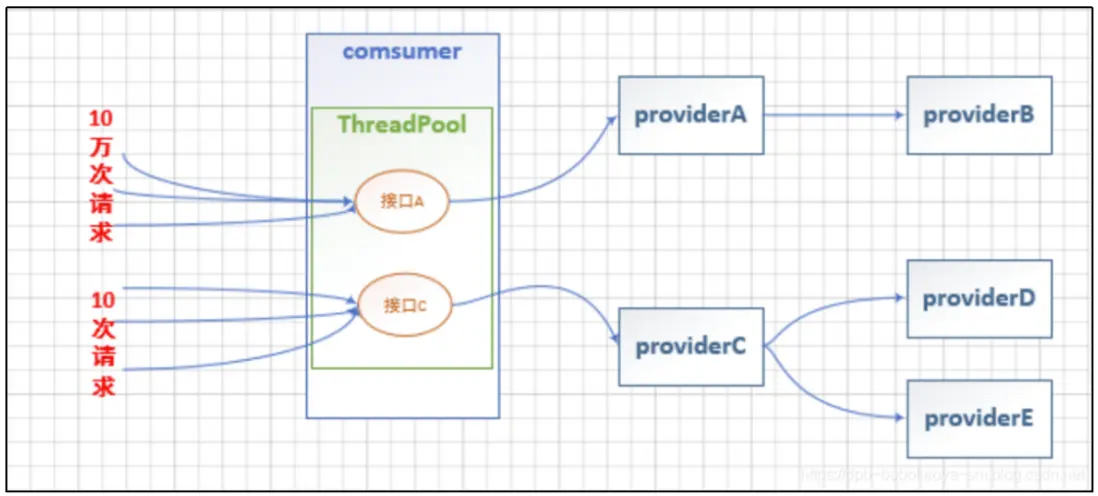
當接口A壓力增大,接口C同時也會受到影響
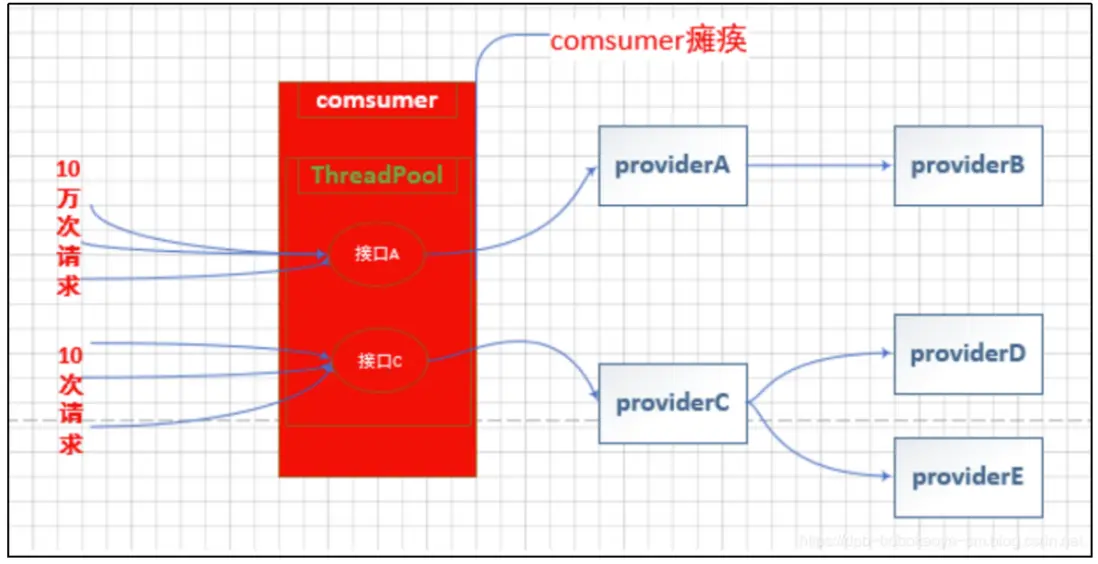
使用線程池的場景
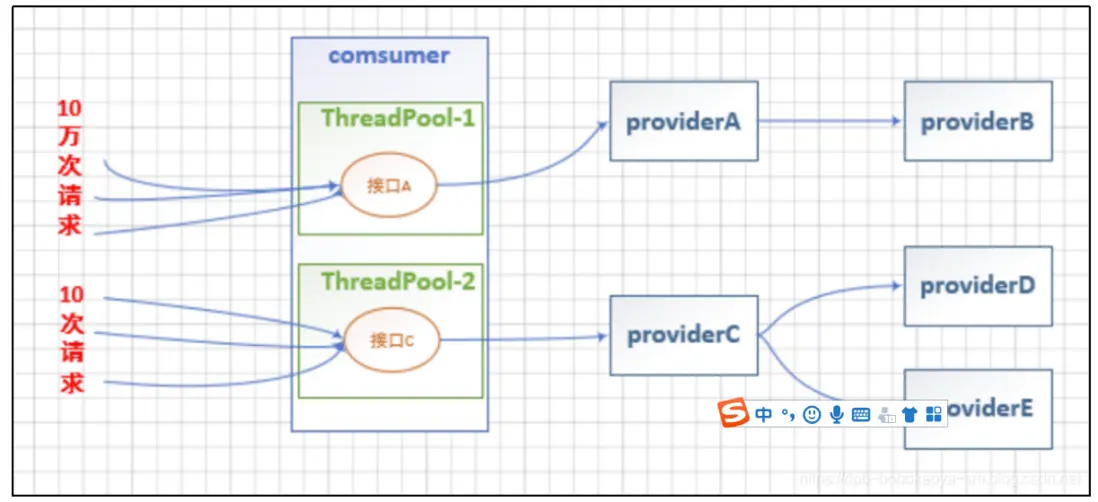
當服務接口A訪問量增大時,因為接口C在不同的線程池中所以不會受到影響

通過上面的圖片來看,線程池隔離的作用還是蠻明顯的。但線程池隔離的使用也不是在任何場景下都適用的,線程池隔離的優缺點如下:
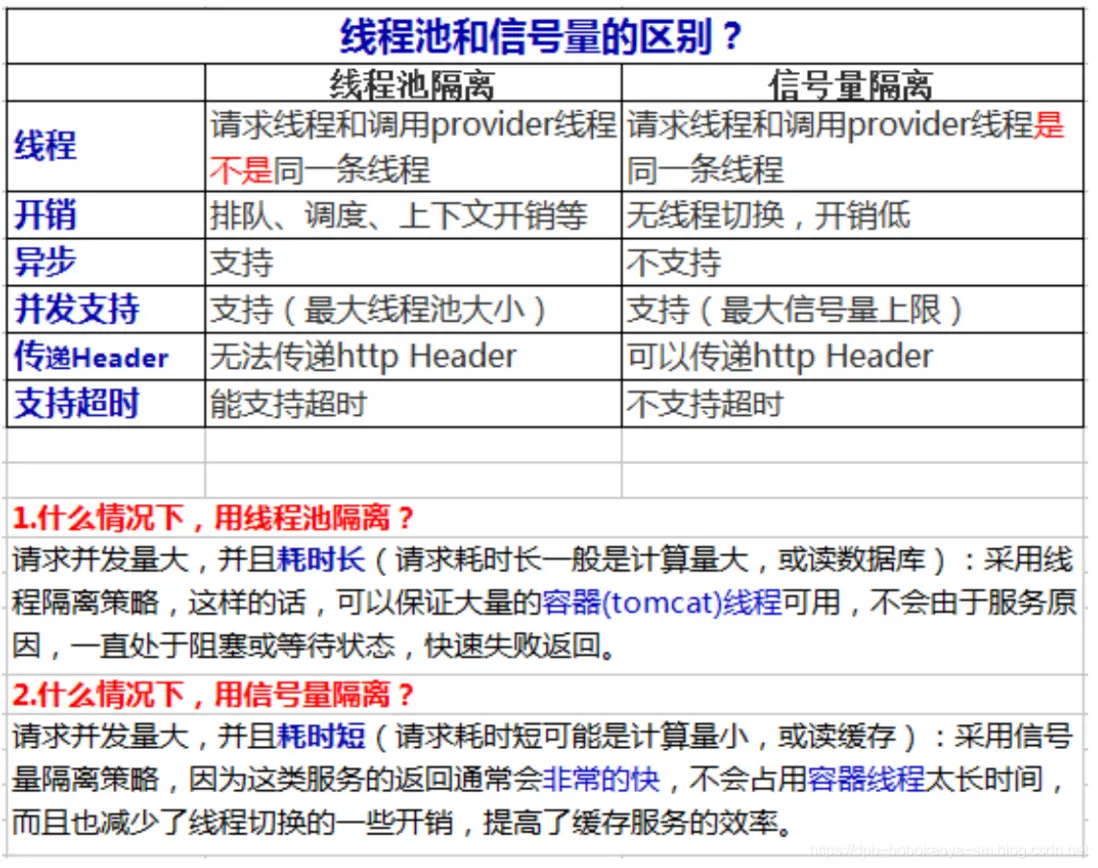
優點
- 使用線程池隔離可以完全隔離依賴的服務(例如圖中的A,B,C服務),請求線程可以快速放回
- 當線程池出現問題時,線程池隔離是獨立的不會影響其他服務和接口
- 當失敗的服務再次變得可用時,線程池將清理並可立即恢復,而不需要一個長時間的恢復
- 獨立的線程池提高了併發性
缺點:線程池隔離的主要缺點是它們增加計算開銷(CPU),每個命令的執行涉及到排隊,調度和上下文切換都是在一個單獨的線程上運行的。
案例實現
@HystrixCommand(
groupKey = "eureka-provider"
,threadPoolKey = "getUsers"
,threadPoolProperties = {
@HystrixProperty(name = "coreSize",value = "30") // 線程池大小
,@HystrixProperty(name = "maxQueueSize",value = "100") // 最大隊列長度
,@HystrixProperty(name = "keepAliveTimeMinutes",value = "2") // 線程存活時間
,@HystrixProperty(name = "queueSizeRejectionThreshold",value = "15") // 拒絕請求
},fallbackMethod = "fallBack"
)
public List<User> getUsersThreadPool(Integer id){
System.out.println("--------》" + Thread.currentThread().getName());
// 1. 服務發現
// 獲取服務提供者的信息 ServiceInstance封裝的有相關的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println("---->"+sb.toString());
// 2. 服務調用 SpringMVC中提供的有 調用組件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}相關參數的描述
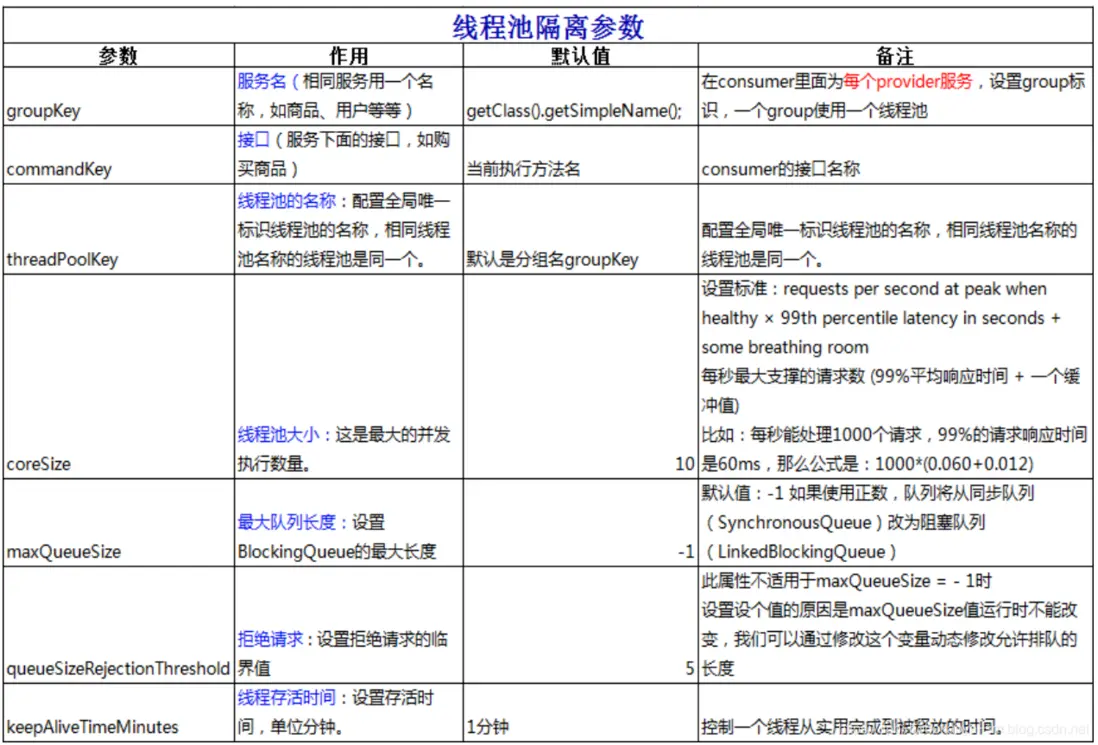
信號量隔離
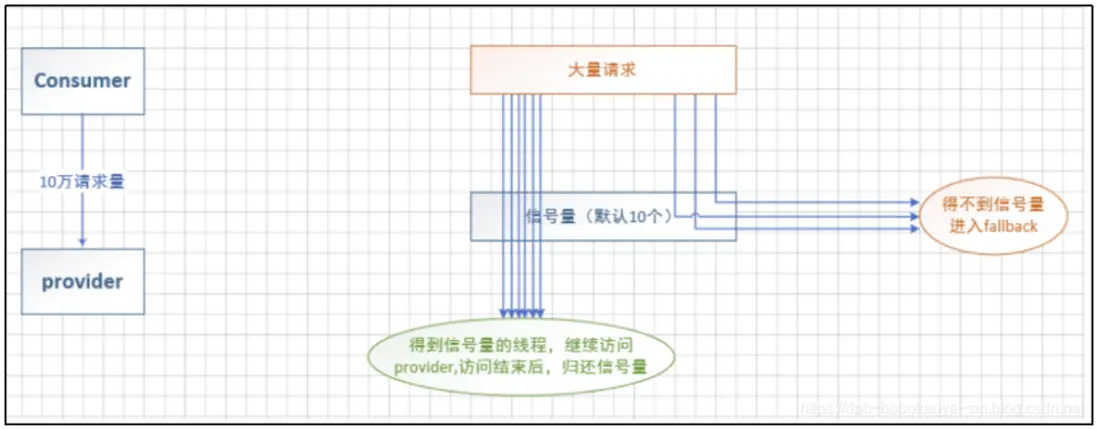
信號量隔離其實就是我們定義的隊列併發時最多支持多大的訪問,其他的訪問通過託底數據來響應,如下結構圖
@HystrixCommand(
fallbackMethod = "fallBack"
,commandProperties = {
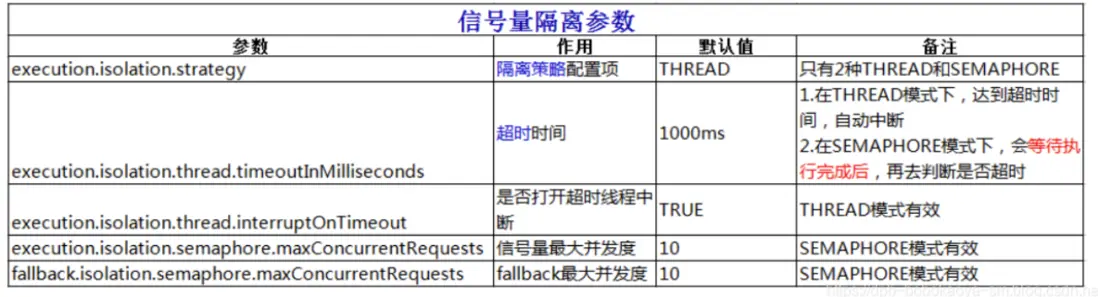
@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY
,value = "SEMAPHORE") // 信號量隔離
,@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS
,value="100" // 信號量最大併發度
)
}
)
public List<User> getUsersSignal(Integer id){
System.out.println("--------》" + Thread.currentThread().getName());
// 1. 服務發現
// 獲取服務提供者的信息 ServiceInstance封裝的有相關的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println("---->"+sb.toString());
// 2. 服務調用 SpringMVC中提供的有 調用組件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
兩者的區別
線程池隔離和信號量隔離的區別
Feign遠程調用
基於Netflix Feign 實現,整合了Spring Cloud Ribbon 與Spring Cloud Hystrix, 它提供了一種聲明式服務調用的方式。
先來看我們以前利用RestTemplate發起遠程調用的代碼:

存在下面的問題:
- 代碼可讀性差,編程體驗不統一
- 參數複雜URL難以維護
Feign是一個聲明式的http客户端,官方地址:https://github.com/OpenFeign/feign
其作用就是幫助我們優雅的實現http請求的發送,解決上面提到的問題。
什麼是聲明式,有什麼作用,解決什麼問題?聲明式調用就像調用本地方法一樣調用遠程方法;無感知遠程 http 請求。
- Spring Cloud 的聲明式調用, 可以做到使用 HTTP 請求遠程服務時能就像調用本地方法一樣的體驗,開發者完全感知不到這是遠程方法,更感知不到這是個 HTTP 請求。
- 它像 Dubbo 一樣,consumer 直接調用接口方法調用 provider,而不需要通過常規的Http Client 構造請求再解析返回數據。
- 它解決了讓開發者調用遠程接口就跟調用本地方法一樣,無需關注與遠程的交互細節,更無需關注分佈式環境開發。
Feign替代RestTemplate
Fegin的使用步驟如下:
引入依賴
我們在order-service服務的pom文件中引入feign的依賴:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>添加註解
在order-service的啓動類添加註解開啓Feign的功能,@EnableFeignClients
編寫Feign的客户端
在order-service中新建一個接口,內容如下:
import cn.seven.order.pojo.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}這個客户端主要是基於SpringMVC的註解來聲明遠程調用的信息,比如:
- 服務名稱:userservice
- 請求方式:GET
- 請求路徑:/user/{id}
- 請求參數:Long id
- 返回值類型:User
這樣,Feign就可以幫助我們發送http請求,無需自己使用RestTemplate來發送了。
測試
修改order-service中的OrderService類中的queryOrderById方法,使用Feign客户端代替RestTemplate:
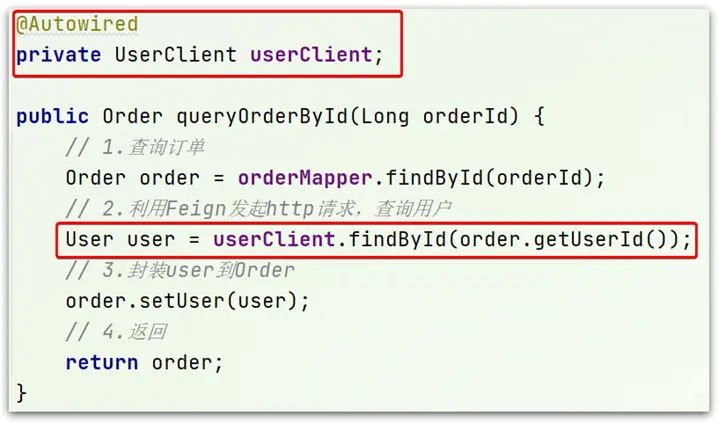
是不是看起來優雅多了。
總結
使用Feign的步驟:
- 引入依賴
- 添加@EnableFeignClients註解
- 編寫FeignClient接口
- 使用FeignClient中定義的方法代替RestTemplate
自定義配置
Feign可以支持很多的自定義配置,如下表所示:
| 類型 | 作用 | 説明 |
|---|---|---|
| feign.Logger.Level | 修改日誌級別 | 包含四種不同的級別:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 響應結果的解析器 | http遠程調用的結果做解析,例如解析json字符串為java對象 |
| feign.codec.Encoder | 請求參數編碼 | 將請求參數編碼,便於通過http請求發送 |
| feign. Contract | 支持的註解格式 | 默認是SpringMVC的註解 |
| feign. Retryer | 失敗重試機制 | 請求失敗的重試機制,默認是沒有,不過會使用Ribbon的重試 |
一般情況下,默認值就能滿足我們使用,如果要自定義時,只需要創建自定義的@Bean覆蓋默認Bean即可。
下面以日誌為例來演示如何自定義配置。
配置文件方式
基於配置文件修改feign的日誌級別可以針對單個服務:
feign:
client:
config:
userservice: # 針對某個微服務的配置
loggerLevel: FULL # 日誌級別 也可以針對所有服務:
feign:
client:
config:
default: # 這裏用default就是全局配置,如果是寫服務名稱,則是針對某個微服務的配置
loggerLevel: FULL # 日誌級別 而日誌的級別分為四種:
- NONE:不記錄任何日誌信息,這是默認值。
- BASIC:僅記錄請求的方法,URL以及響應狀態碼和執行時間
- HEADERS:在BASIC的基礎上,額外記錄了請求和響應的頭信息
- FULL:記錄所有請求和響應的明細,包括頭信息、請求體、元數據。
Java代碼方式
也可以基於Java代碼來修改日誌級別,先聲明一個類,然後聲明一個Logger.Level的對象:
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日誌級別為BASIC
}
}如果要全局生效,將其放到啓動類的@EnableFeignClients這個註解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) 如果是局部生效,則把它放到對應的@FeignClient這個註解中:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class) Feign使用優化
Feign底層發起http請求,依賴於其它的框架。其底層客户端實現包括:
- URLConnection:默認實現,不支持連接池
- Apache HttpClient :支持連接池
- OKHttp:支持連接池
因此提高Feign的性能主要手段就是使用連接池代替默認的URLConnection。
這裏我們用Apache的HttpClient來演示。
引入依賴
在order-service的pom文件中引入Apache的HttpClient依賴:
<!--httpClient的依賴 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>配置連接池
在order-service的application.yml中添加配置:
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日誌級別,BASIC就是基本的請求和響應信息
httpclient:
enabled: true # 開啓feign對HttpClient的支持
max-connections: 200 # 最大的連接數
max-connections-per-route: 50 # 每個路徑的最大連接數接下來,在FeignClientFactoryBean中的loadBalance方法中打斷點:
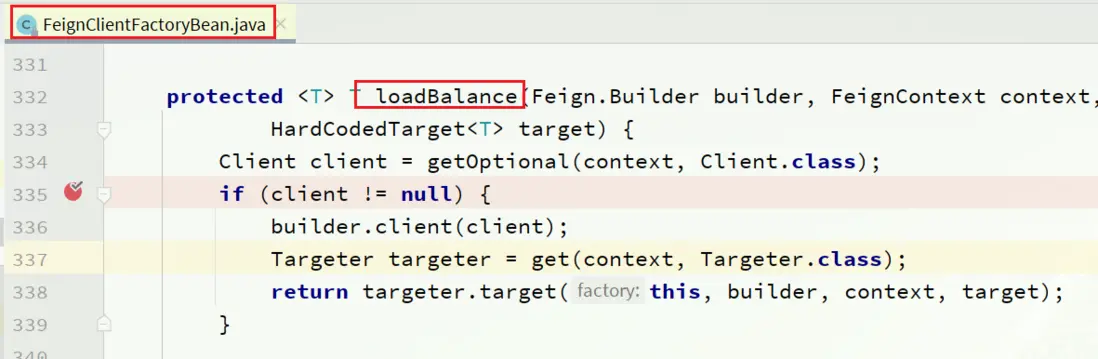
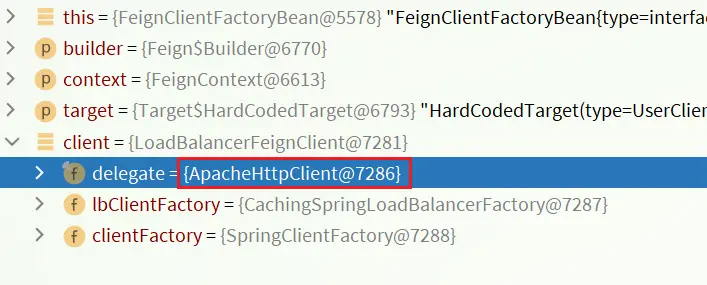
Debug方式啓動order-service服務,可以看到這裏的client,底層就是Apache HttpClient:
總結,Feign的優化:
- 日誌級別儘量用basic
-
使用HttpClient或OKHttp代替URLConnection
- 引入feign-httpClient依賴
- 配置文件開啓httpClient功能,設置連接池參數
最佳實踐
所謂最佳實踐,就是使用過程中總結的經驗,最好的一種使用方式。
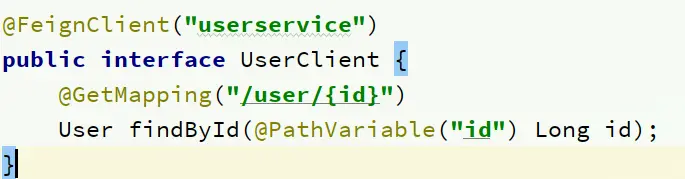
Feign的客户端與服務提供者的controller代碼非常相似:
feign客户端:
UserController:
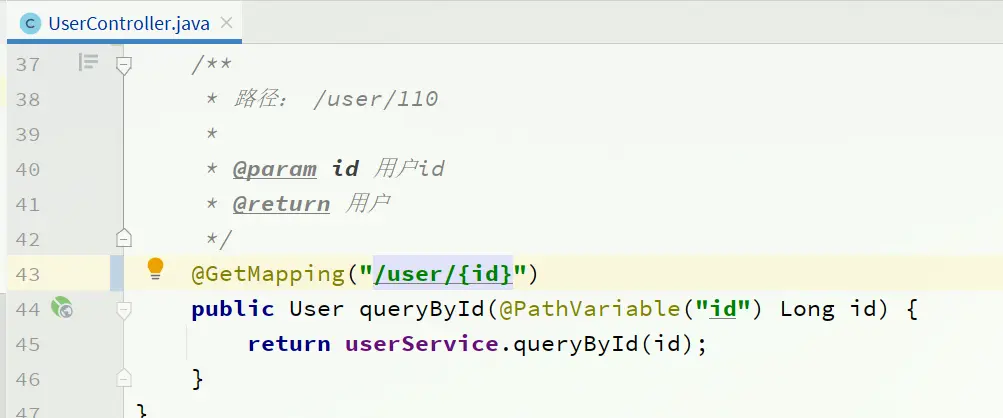
有沒有一種辦法簡化這種重複的代碼編寫呢?
繼承方式
一樣的代碼可以通過繼承來共享:
- 定義一個API接口,利用定義方法,並基於SpringMVC註解做聲明。
- Feign客户端和Controller都集成改接口
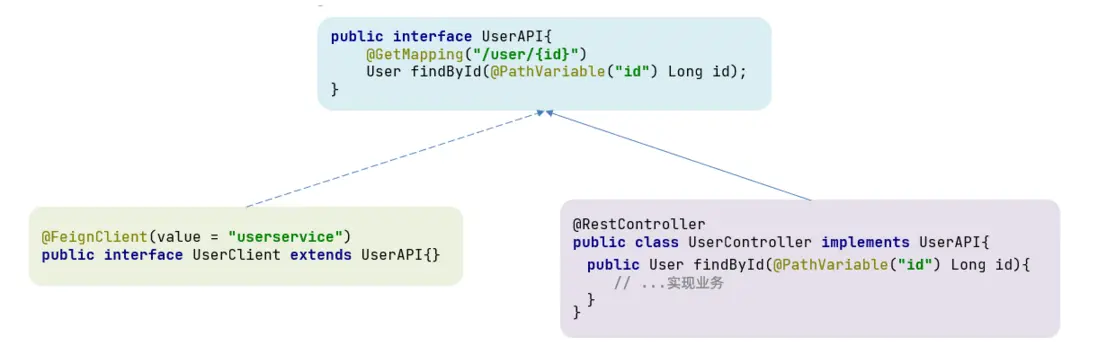
優點:
- 簡單
- 實現了代碼共享
缺點:
- 服務提供方、服務消費方緊耦合
- 參數列表中的註解映射並不會繼承,因此Controller中必須再次聲明方法、參數列表、註解
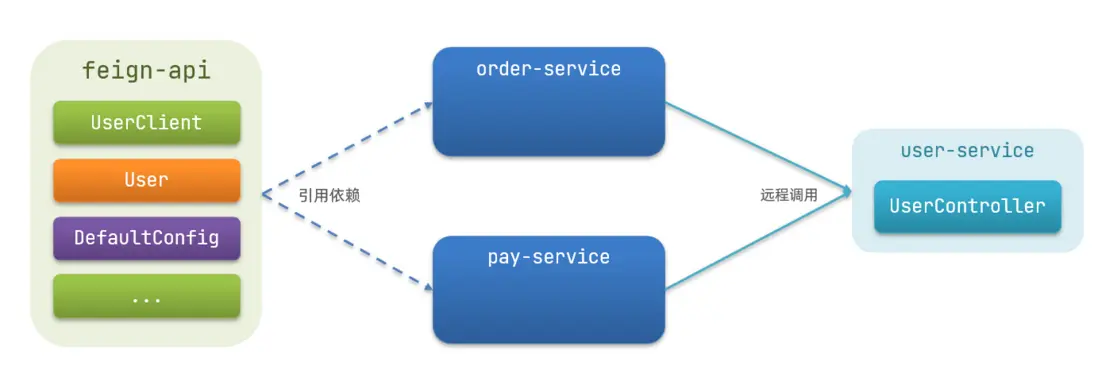
抽取方式
將Feign的Client抽取為獨立模塊,並且把接口有關的POJO、默認的Feign配置都放到這個模塊中,提供給所有消費者使用。
例如,將UserClient、User、Feign的默認配置都抽取到一個feign-api包中,所有微服務引用該依賴包,即可直接使用。
抽取
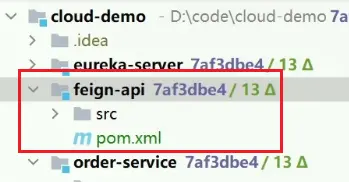
首先創建一個module,命名為feign-api,
項目結構:
在feign-api中然後引入feign的starter依賴
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>然後,order-service中編寫的UserClient、User、DefaultFeignConfiguration都複製到feign-api項目中
在order-service中使用feign-api
首先,刪除order-service中的UserClient、User、DefaultFeignConfiguration等類或接口。
在order-service的pom文件中中引入feign-api的依賴:
<dependency>
<groupId>cn.seven.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>修改order-service中的所有與上述三個組件有關的導包部分,改成導入feign-api中的包
重啓測試
重啓後,發現服務報錯了
這是因為UserClient現在在cn.seven.feign.clients包下,
而order-service的@EnableFeignClients註解是在cn.seven.order包下,不在同一個包,無法掃描到UserClient。
解決掃描包問題
方式一:
指定Feign應該掃描的包:
@EnableFeignClients(basePackages = "cn.seven.feign.clients")方式二:
指定需要加載的Client接口:
@EnableFeignClients(clients = {UserClient.class})Gateway服務網關
Spring Cloud Gateway 項目是基於 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等響應式編程和事件流技術開發的網關,它旨在為微服務架構提供一種簡單有效的統一的 API 路由管理方式。
為什麼需要網關
Gateway網關是我們服務的守門神,所有微服務的統一入口。
網關的核心功能特性:
- 請求路由
- 權限控制
- 限流
架構圖:
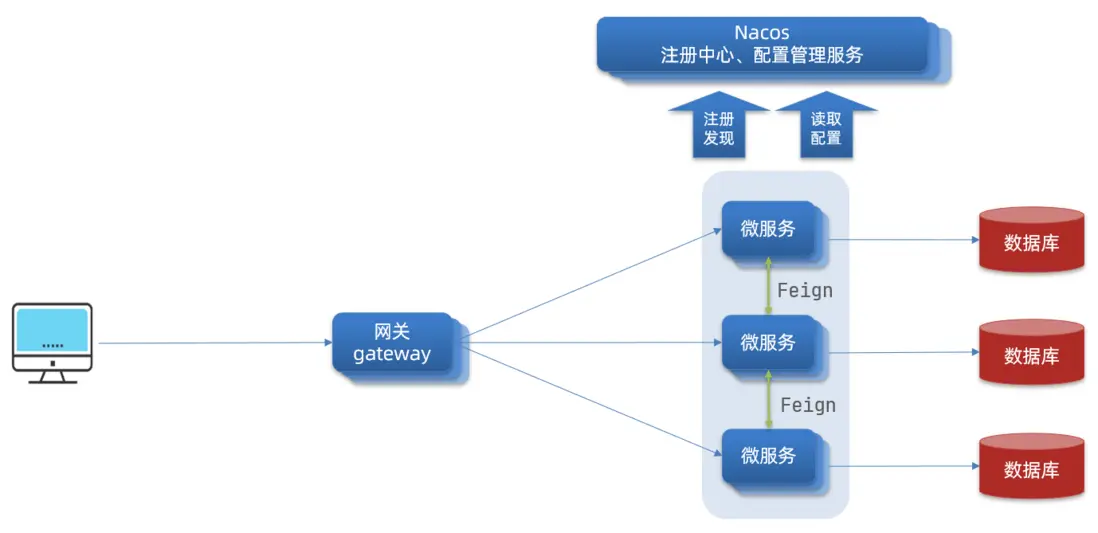
- 權限控制:網關作為微服務入口,需要校驗用户是是否有請求資格,如果沒有則進行攔截。
- 路由和負載均衡:一切請求都必須先經過gateway,但網關不處理業務,而是根據某種規則,把請求轉發到某個微服務,這個過程叫做路由。當然路由的目標服務有多個時,還需要做負載均衡。
- 限流:當請求流量過高時,在網關中按照下流的微服務能夠接受的速度來放行請求,避免服務壓力過大。
在SpringCloud中網關的實現包括兩種:
- gateway
- zuul
Zuul是基於Servlet的實現,屬於阻塞式編程。而SpringCloudGateway則是基於Spring5中提供的WebFlux,屬於響應式編程的實現,具備更好的性能。
gateway快速入門
下面,我們就演示下網關的基本路由功能。基本步驟如下:
- 創建SpringBoot工程gateway,引入網關依賴
- 編寫啓動類
- 編寫基礎配置和路由規則
- 啓動網關服務進行測試
引入依賴
<!--網關-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服務發現依賴-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>編寫啓動類
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}編寫基礎配置和路由規則
創建application.yml文件,內容如下:
server:
port: 10010 # 網關端口
spring:
application:
name: gateway # 服務名稱
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 網關路由配置
- id: user-service # 路由id,自定義,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目標地址 http就是固定地址
uri: lb://userservice # 路由的目標地址 lb就是負載均衡,後面跟服務名稱
predicates: # 路由斷言,也就是判斷請求是否符合路由規則的條件
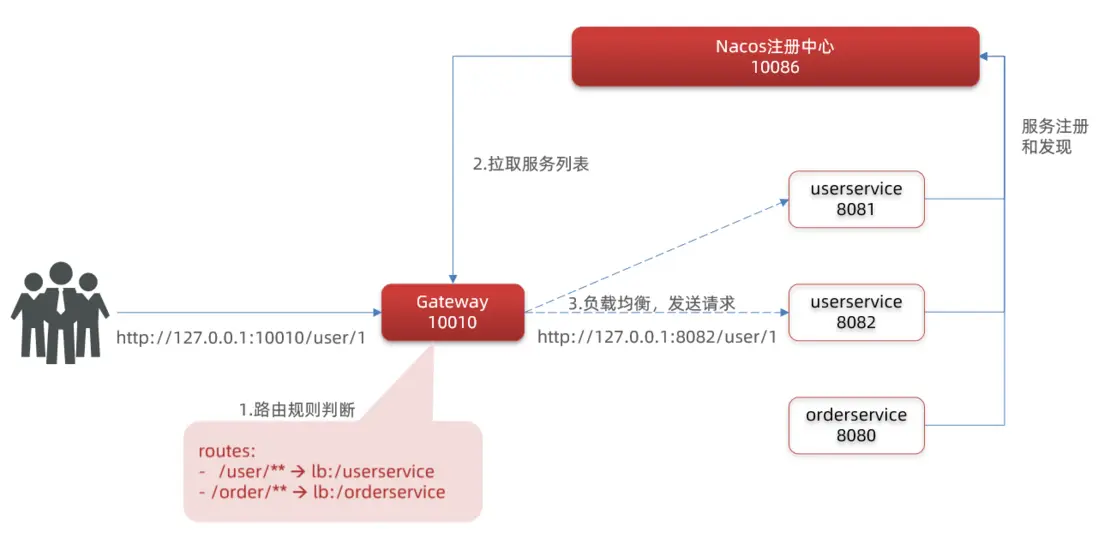
- Path=/user/** # 這個是按照路徑匹配,只要以/user/開頭就符合要求我們將符合Path 規則的一切請求,都代理到 uri參數指定的地址。
本例中,我們將 /user/**開頭的請求,代理到lb://userservice,lb是負載均衡,根據服務名拉取服務列表,實現負載均衡。
重啓測試
重啓網關,訪問http://localhost:10010/user/1時,符合/user/**規則,請求轉發到uri:http://userservice/user/1,得到了結果:

網關路由的流程圖
整個訪問的流程如下:
總結:
網關搭建步驟:
- 創建項目,引入nacos服務發現和gateway依賴
- 配置application.yml,包括服務基本信息、nacos地址、路由
路由配置包括:
- 路由id:路由的唯一標示
- 路由目標(uri):路由的目標地址,http代表固定地址,lb代表根據服務名負載均衡
- 路由斷言(predicates):判斷路由的規則,
- 路由過濾器(filters):對請求或響應做處理
接下來,就重點來學習路由斷言和路由過濾器的詳細知識
斷言工廠
我們在配置文件中寫的斷言規則只是字符串,這些字符串會被Predicate Factory讀取並處理,轉變為路由判斷的條件
例如Path=/user/**是按照路徑匹配,這個規則是由org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory類來處理的,像這樣的斷言工廠在SpringCloudGateway還有十幾個:
| 名稱 | 説明 | 示例 |
|---|---|---|
| After | 是某個時間點後的請求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某個時間點之前的請求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某兩個時間點之前的請求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 請求必須包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 請求必須包含某些header | - Header=X-Request-Id, \d+ |
| Host | 請求必須是訪問某個host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 請求方式必須是指定方式 | - Method=GET,POST |
| Path | 請求路徑必須符合指定規則 | - Path=/red/{segment},/blue/** |
| Query | 請求參數必須包含指定參數 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 請求者的ip必須是指定範圍 | - RemoteAddr=192.168.1.1/24 |
| Weight | 權重處理 |
我們只需要掌握Path這種路由工程就可以了。
過濾器工廠
GatewayFilter是網關中提供的一種過濾器,可以對進入網關的請求和微服務返回的響應做處理:
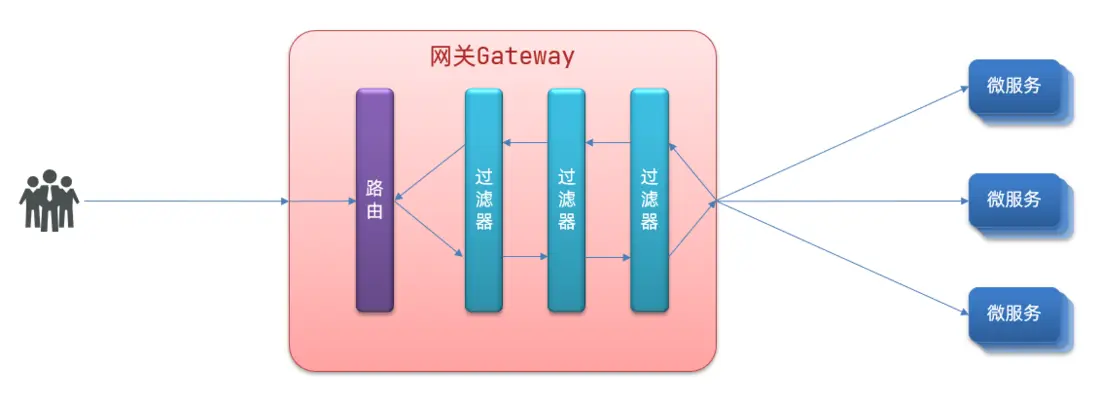
路由過濾器的種類
Spring提供了31種不同的路由過濾器工廠。例如:
| 名稱 | 説明 |
|---|---|
| AddRequestHeader | 給當前請求添加一個請求頭 |
| RemoveRequestHeader | 移除請求中的一個請求頭 |
| AddResponseHeader | 給響應結果中添加一個響應頭 |
| RemoveResponseHeader | 從響應結果中移除有一個響應頭 |
| RequestRateLimiter | 限制請求的流量 |
請求頭過濾器
下面我們以AddRequestHeader 為例來講解。
需求:給所有進入userservice的請求添加一個請求頭:Truth=seven is freaking awesome!
只需要修改gateway服務的application.yml文件,添加路由過濾即可:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 過濾器
- AddRequestHeader=Truth, seven is freaking awesome! # 添加請求頭當前過濾器寫在userservice路由下,因此僅僅對訪問userservice的請求有效。
默認過濾器
如果要對所有的路由都生效,則可以將過濾器工廠寫到default下。格式如下:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默認過濾項
- AddRequestHeader=Truth, seven is freaking awesome! 總結
過濾器的作用是什麼?
- 對路由的請求或響應做加工處理,比如添加請求頭
- 配置在路由下的過濾器只對當前路由的請求生效
defaultFilters的作用是什麼?對所有路由都生效的過濾器
全局過濾器
過濾器,網關提供了31種,但每一種過濾器的作用都是固定的。如果我們希望攔截請求,做自己的業務邏輯則沒辦法實現。
全局過濾器作用
全局過濾器的作用也是處理一切進入網關的請求和微服務響應,與GatewayFilter的作用一樣。區別在於GatewayFilter通過配置定義,處理邏輯是固定的;而GlobalFilter的邏輯需要自己寫代碼實現。
定義方式是實現GlobalFilter接口。
public interface GlobalFilter {
/**
* 處理當前請求,有必要的話通過{@link GatewayFilterChain}將請求交給下一個過濾器處理
*
* @param exchange 請求上下文,裏面可以獲取Request、Response等信息
* @param chain 用來把請求委託給下一個過濾器
* @return {@code Mono<Void>} 返回標示當前過濾器業務結束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}在filter中編寫自定義邏輯,可以實現下列功能:
- 登錄狀態判斷
- 權限校驗
- 請求限流等
自定義全局過濾器
需求:定義全局過濾器,攔截請求,判斷請求的參數是否滿足下面條件:
- 參數中是否有authorization,
- authorization參數值是否為admin
如果同時滿足則放行,否則攔截
實現:在gateway中定義一個過濾器:
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.獲取請求參數
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.獲取authorization參數
String auth = params.getFirst("authorization");
// 3.校驗
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.攔截
// 4.1.禁止訪問,設置狀態碼
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.結束處理
return exchange.getResponse().setComplete();
}
}過濾器執行順序
請求進入網關會碰到三類過濾器:當前路由的過濾器、DefaultFilter、GlobalFilter
請求路由後,會將當前路由過濾器和DefaultFilter、GlobalFilter,合併到一個過濾器鏈(集合)中,排序後依次執行每個過濾器:
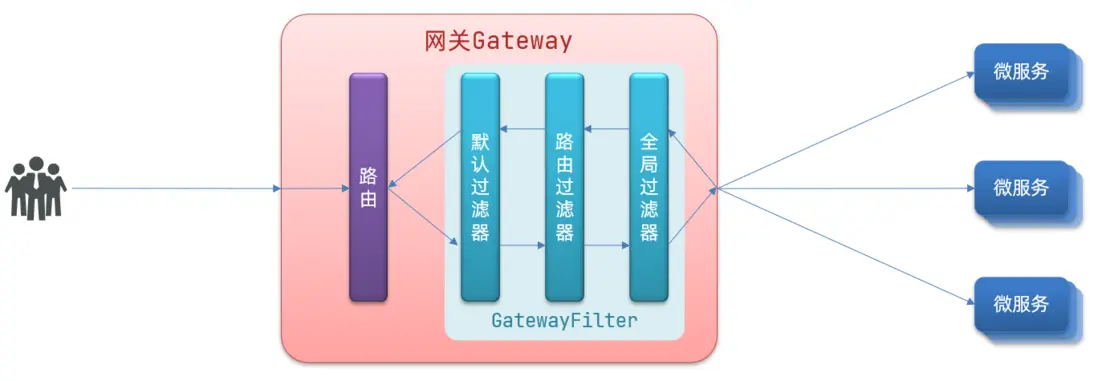
排序的規則是什麼呢?
- 每一個過濾器都必須指定一個int類型的order值,order值越小,優先級越高,執行順序越靠前。
- GlobalFilter通過實現Ordered接口,或者添加@Order註解來指定order值,由我們自己指定
- 路由過濾器和defaultFilter的order由Spring指定,默認是按照聲明順序從1遞增。
- 當過濾器的order值一樣時,會按照 defaultFilter > 路由過濾器 > GlobalFilter的順序執行。
詳細內容,可以查看源碼:
org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()方法是先加載defaultFilters,然後再加載某個route的filters,然後合併。
org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()方法會加載全局過濾器,與前面的過濾器合併後根據order排序,組織過濾器鏈
跨域問題
什麼是跨域問題
跨域:域名不一致就是跨域,主要包括:
- 域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
- 域名相同,端口不同:localhost:8080和localhost:8081
跨域問題:瀏覽器禁止請求的發起者與服務端發生跨域ajax請求,請求被瀏覽器攔截的問題
解決方案:CORS,這裏不再贅述了,不知道的小夥伴可以查看https://www.ruanyifeng.com/blog/2016/04/cors.html
模擬跨域問題
可以在瀏覽器控制枱看到下面的錯誤:

從localhost:8090訪問localhost:10010,端口不同,顯然是跨域的請求。
解決跨域問題
在gateway服務的application.yml文件中,添加下面的配置:
spring:
cloud:
gateway:
# ...
globalcors: # 全局的跨域處理
add-to-simple-url-handler-mapping: true # 解決options請求被攔截問題
corsConfigurations:
'[/**]':
allowedOrigins: # 允許哪些網站的跨域請求
- "http://localhost:8090"
allowedMethods: # 允許的跨域ajax的請求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允許在請求中攜帶的頭信息
allowCredentials: true # 是否允許攜帶cookie
maxAge: 360000 # 這次跨域檢測的有效期往期推薦
- 《SpringBoot》EasyExcel實現百萬數據的導入導出
- 《SpringBoot》史上最全SpringBoot相關注解介紹
- Spring框架IoC核心詳解
- 萬字長文帶你窺探Spring中所有的擴展點
- 如何實現一個通用的接口限流、防重、防抖機制
- 萬字長文帶你深入Redis底層數據結構
- volatile關鍵字最全原理剖析


