









作者:
- 白旭:Cisco Software Engineer, Apache Amoro PPMC member
- 許鴻坤:Cisco Senior Software Engineer
導讀:本文內容整理自 白旭 與 許鴻坤 兩位嘉賓在 StarRocks Connect 2025 上的聯合演講。
基於 Cisco Webex 的核心分析場景,分享了從 Pinot 技術棧遷移至 StarRocks 的完整實踐路徑——涵蓋存算分離與存算一體架構的落地,以及多項性能與治理優化。
遷移後,系統實現多項顯著提升:
- 查詢性能提升超 50%,70% 的查詢語句優於 Trino;
- 物化視圖讓查詢加速 10 倍以上;
- Flat JSON 優化後磁盤佔用降低 80%,查詢時延減少 80%;
- 基於 Rack 的資源隔離實現多業務共集羣部署;
- 向量化引擎與倒排索引優化顯著提升複雜查詢效率。
Cisco Webex 是一款專業的視頻會議軟件,其業務範圍涵蓋語音與視頻通話、在線會議、會議設備以及即時通訊(Message)等核心功能。
在實際使用中,常見的應用場景包括:
- 問題排查(Troubleshooting):通過分析會議指標(如入會延時、通話質量等),定位並解決性能問題;
- 數據分析:數據科學家或分析師利用 OLAP 技術進行查詢與取數;
- 通過 Dashboard 做可視化報表展示。
為什麼引入 StarRocks?
原有 OLAP 技術棧概覽
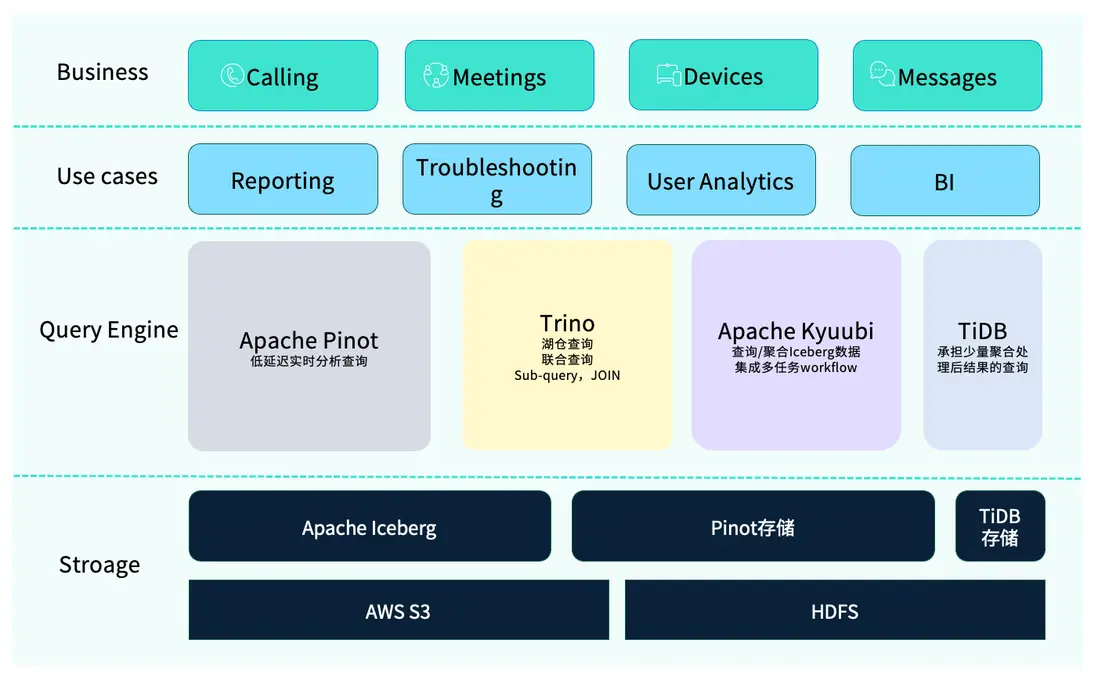
在此前的架構中,我們採用了一套相對複雜的 OLAP 技術棧。
其中使用最頻繁的是 Apache Pinot,主要用於低延時的實時查詢。然而,Pinot 也存在一些限制,例如不支持子查詢及多表 Join。為彌補這部分能力,我們引入了 Trino,用於處理複雜查詢邏輯及訪問湖倉(Iceberg)中的數據。實際業務中,Trino 與 Pinot 的聯邦查詢已成為常見的分析模式。
此外,部分經過聚合後的結果數據,工程師會通過 Python 或 Spark 寫入 TiDB,以便後續靈活取數。我們還使用 Apache Kyuubi 來處理多任務的工作流,它基於 Apache Spark 與內部數據平台協同工作,用於執行數據查詢、下游數據分發及簡單的 ETL 操作(如 Insert into)。
在存儲層面,整體架構同樣具備多元化特徵。由於 Webex 的業務覆蓋全球,不同區域的數據合規要求差異較大——例如歐盟地區對數據隱私與合規性要求更為嚴格,而北美地區部分組織則對敏感數據的管理有額外限制。因此,我們採用了混合存儲方案:部分數據存放在 AWS S3,另一部分則保存在私有 HDFS 集羣中,以滿足不同地區的安全與合規標準。
面臨的挑戰

然而,這套 OLAP 技術棧在實際使用過程中也暴露出不少問題,尤其是對 Pinot 的反饋最為集中。主要痛點包括:
- 維護與成本高:Apache Pinot 的運維複雜度更高,日常管理負擔較重。除了自身的高維護成本外,系統同時運行 Trino 與 Pinot 兩套體系,還需建立獨立或額外的監控方案,進一步加重了運維負擔。
- 節點穩定性與依賴複雜:在部分場景下,Pinot 實例可能出現宕機,需要通過雙副本機制保證數據冗餘;當節點故障時,系統會自動切換至備用節點,或執行 backfill 操作修復數據錯誤。此外,Pinot 依賴 ZooKeeper 等外部組件實現高可用(HA),使得系統結構更復雜、維護鏈條更長。
- 功能缺失:Pinot 不支持多表 Join 與子查詢。雖然可以藉助 Trino 進行聯邦查詢,但性能表現仍不理想,尤其缺乏物化視圖(Materialized View) 支持。在典型場景中,查詢過去 180 天數據時,其中大部分為重複掃描,導致計算資源浪費;若具備物化視圖能力,可通過增量計算顯著提升查詢效率。
- 數據新鮮度與 SLA 風險:對於 Pinot 的實時表,當某一時間段數據出現錯誤時,往往需要重新回放整段數據以修復,既增加了系統負擔,也影響數據時效性和穩定性。
- 用户體驗割裂:由於系統中存在多種查詢引擎,分析師需要掌握不同語法與操作方式,學習成本較高。對於性能較差的 SQL,還需工程師反覆手動優化,影響效率。
需要什麼樣的 OLAP 引擎?

綜合來看,我們希望新的 OLAP 引擎能夠在性能、功能、成本與運維等方面全面提升。主要訴求包括:
- 新的引擎需要在性能上具備足夠優勢,能夠支持多表 Join 與子查詢等複雜操作,確保查詢結果的準確性與響應速度。同時,應支持物化視圖以加速常見查詢。
- 對半結構化數據的良好支持:在日常業務中,我們的明細數據結構(schema)變化頻繁,例如不同日期的字段內容、統計維度都會有所調整,因此需要引擎能夠靈活處理半結構化(Semi-structured)數據,保證查詢的兼容性與穩定性。
- 統一的查詢與使用體驗:希望能夠通過統一的查詢體系,減少分析師在不同引擎間切換的學習成本,同時降低平台自身的維護負擔。
-
更低的總體成本
- 可通過將部分原存於 Pinot 的數據遷移至更經濟的存儲介質(如 S3 或 HDFS),實現顯著的存儲降本;
- 可依託自適應壓縮(ZSTD)、Compaction 等優化機制進一步提升資源利用率。
- 通過統一的告警體系和自動擴縮容能力。目前團隊在存算一體與存算分離兩種架構下,均已實現基於 StarRocks 的統一查詢能力。
存算分離架構的遷移與實踐
Trino VS StarRocks
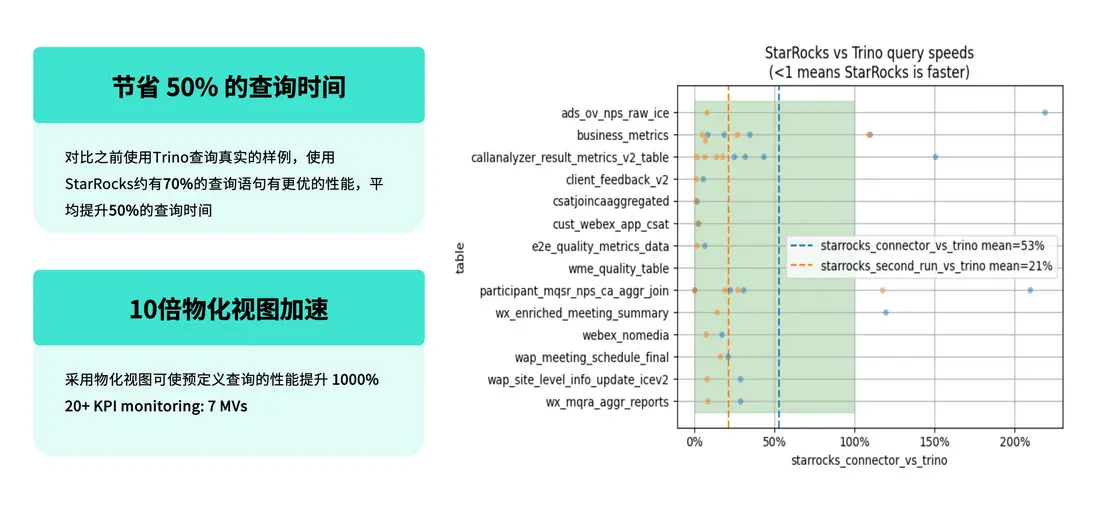
在採用存算分離架構後,我們重點評估了 StarRocks 與 Trino 在實際業務場景中的性能表現,並基於真實查詢負載進行了對比測試。
測試結果顯示:
- 在相同的業務查詢場景下,約 70% 的查詢語句在 StarRocks 上的性能優於 Trino;
- 平均查詢時延較 Trino 提升約 50%;
- 在第二次查詢(即緩存命中場景)中,StarRocks 的性能仍然領先,平均提升約 21%。
- 團隊預定義了一批通用 SQL,通過物化視圖機制統一管理,支持多種實際查詢場景的複用,使整體查詢性能提升超過 10 倍。
HPA 自動擴所容
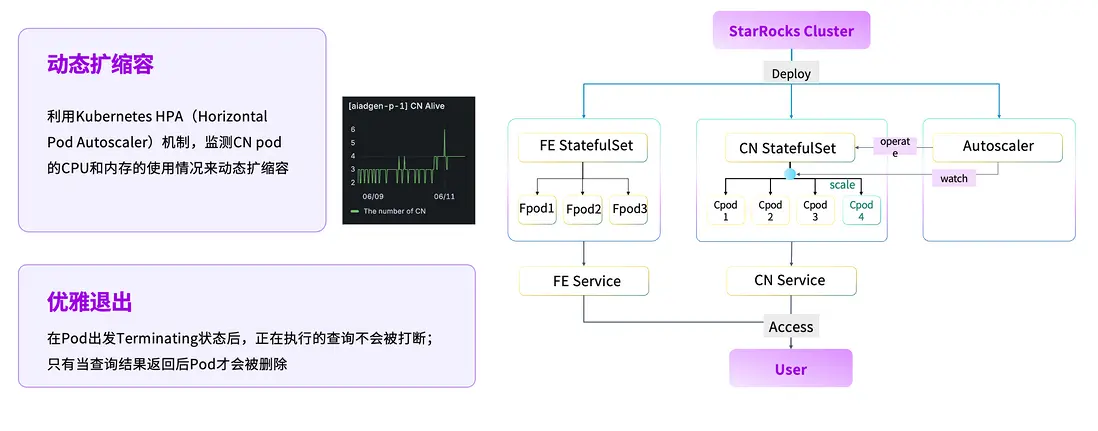
在資源管理層面,我們基於 Kubernetes 完成了自動擴縮容能力建設。當前絕大多數組件均運行在 Kubernetes 環境中,我們通過引入 HPA(Horizontal Pod Autoscaler),動態監測 CN Pod 的 CPU 與內存使用情況,實現計算資源的按需伸縮。當業務負載降低時,系統可自動釋放計算資源。同時,為確保正在執行的任務不受影響,平台會在 Pod 退出前檢測其狀態,僅在 SQL 執行完成後才允許回收資源,實現優雅退出。
Self-Help Provisioning
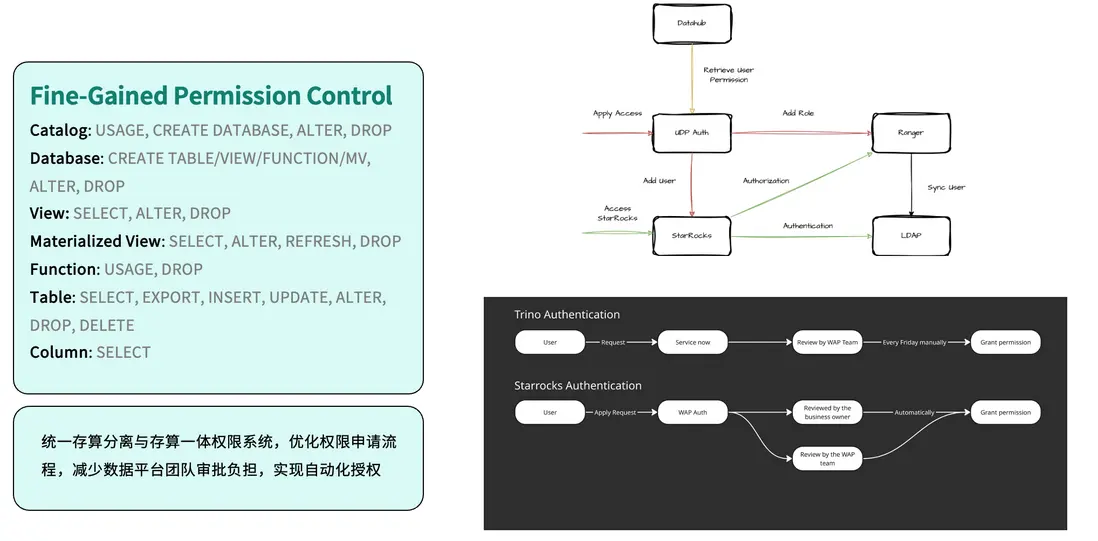
在安全與權限管理方面,我們完成了權限體系的統一整合。系統集成 Apache Ranger 進行規則配置,並通過 LDAP 實現集中身份認證,所有權限最終統一至自研平台 UDP(Unified Data Platform) Auth 進行管理。相比此前基於 Trino 的人工授權流程,如今用户申請權限後即可由業務維護者或系統自動審批,實現了授權的自動化。這不僅提升了安全與合規性,也顯著減少了人工操作與運維負擔。
統一 SQL 查詢
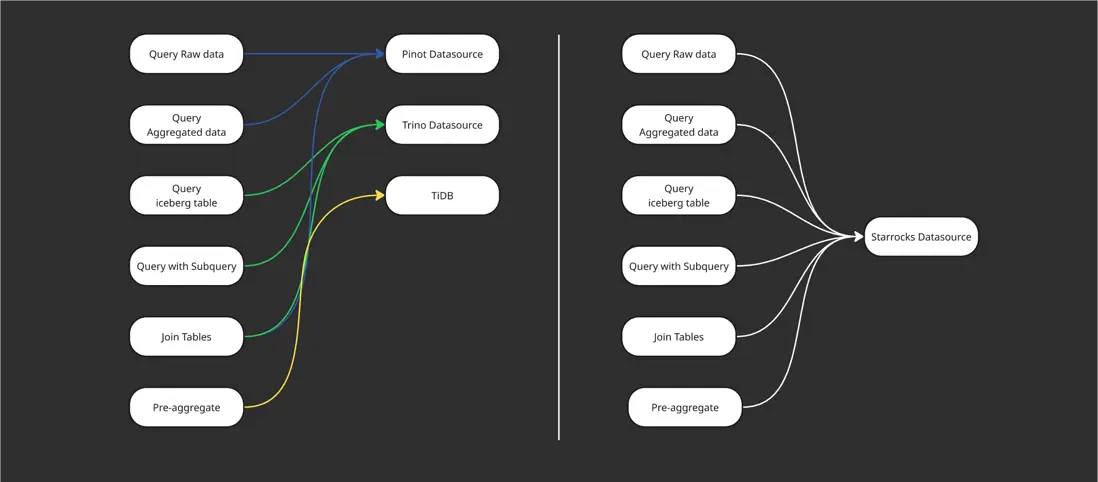
在查詢體系的統一過程中,我們也針對不同場景的語法差異進行了兼容與優化。此前,團隊會根據業務特徵選擇不同的 OLAP 引擎進行查詢;而在統一架構後,所有查詢均基於 StarRocks 進行執行。
為實現平滑遷移,我們對 Trino 與 Pinot 的查詢方言進行了適配與轉換。以 Trino 為例,團隊在內部進行了覆蓋率測試,結果顯示約 90% 的場景可通過 Trino Dialect 實現語法轉換,極大簡化了用户遷移的成本與使用難度。
與此同時,我們還針對 Pinot 的語法特性進行了系統化的方言轉換(下文將詳細介紹),確保不同架構模式下(無論是存算一體還是存算分離),均可通過 StarRocks 實現統一的查詢體驗與結果一致性。
半結構化數據類型 —— Variant
- 什麼是 VariantDataType?
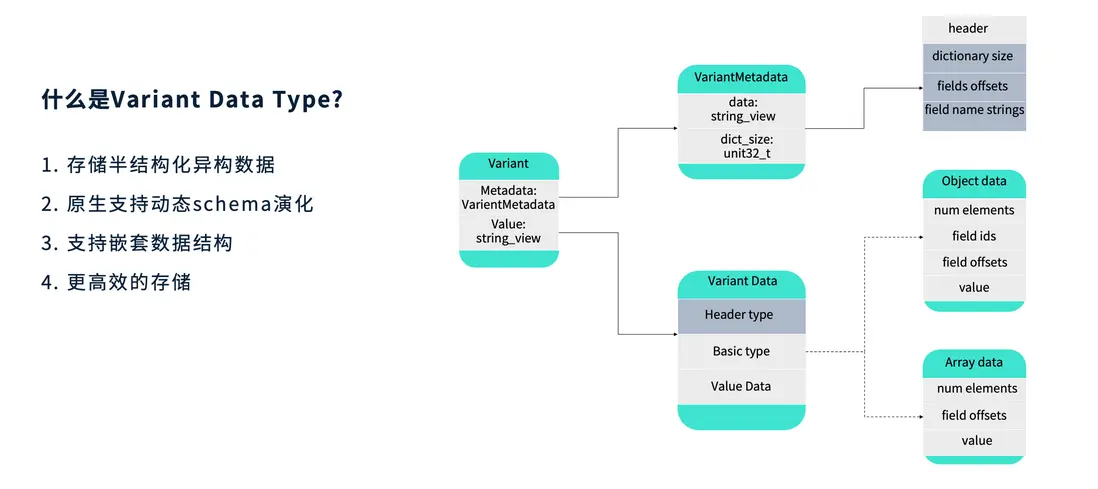
Variant 是一種用於存儲動態變化的半結構化數據的數據類型,典型應用場景是查詢 JSON。它能夠原生支持動態 Schema 演化,並具備對嵌套數據結構的識別與處理能力。由於採用了更高效的編碼方式,Variant 在性能與空間利用率之間取得了良好平衡。
- Variant Encoding

從編碼結構上看,Variant 由兩部分組成:Metadata(元數據) 與 Value(數據值)。
- Metadata 用於描述整體結構信息,如版本號、字段屬性等。在當前版本(Version 1)中,Header 中記錄了規範版本、字典是否為短字符串(short)或唯一(unique)等信息,以及便於後續讀取的 offset 索引。
- Dictionary 可理解為存儲所有 JSON 字段名稱的字符串集合;
- Value 部分保存實際數據值,支持多種基礎類型(Basic Type),例如 primitive、short string 等。針對短字符串類型,Variant 在 Value Header 中進行了特殊優化,會額外存儲字符串的長度以便快速解析。
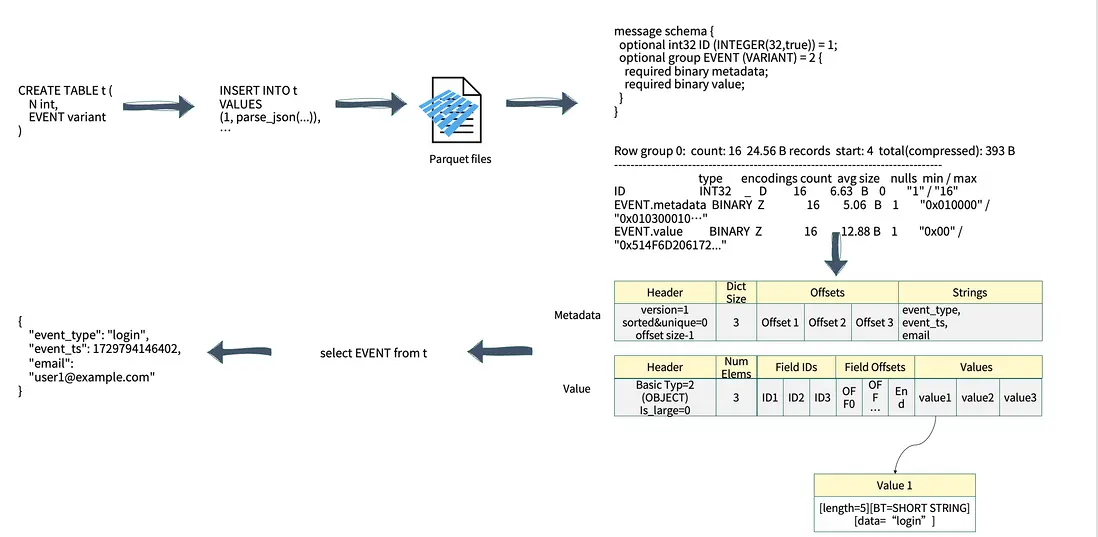
除了基礎類型外,Variant 還支持 Object 與 Array 等複雜結構。以實際應用為例,當創建包含 Variant 字段的表並將數據寫入 Parquet 文件時,其 Schema 結構會分為兩部分(如上圖右側所示):
- Metadata:使用 BINARY 類型存儲整體元數據;
- Value:同樣以 BINARY 類型存儲實際值。
在查詢一個 Object 結構 JSON 的執行過程中,用户需訪問 JSON 中的某個字段,系統會首先讀取對應的 Object 元數據信息並判斷目標 Key 是否存在。一旦定位到相應的 Key,系統會根據其 Offset 精確讀取對應的內存地址。這一機制使得 Variant 查詢的整體性能優於傳統的字符串型 JSON 查詢。
- Implementation
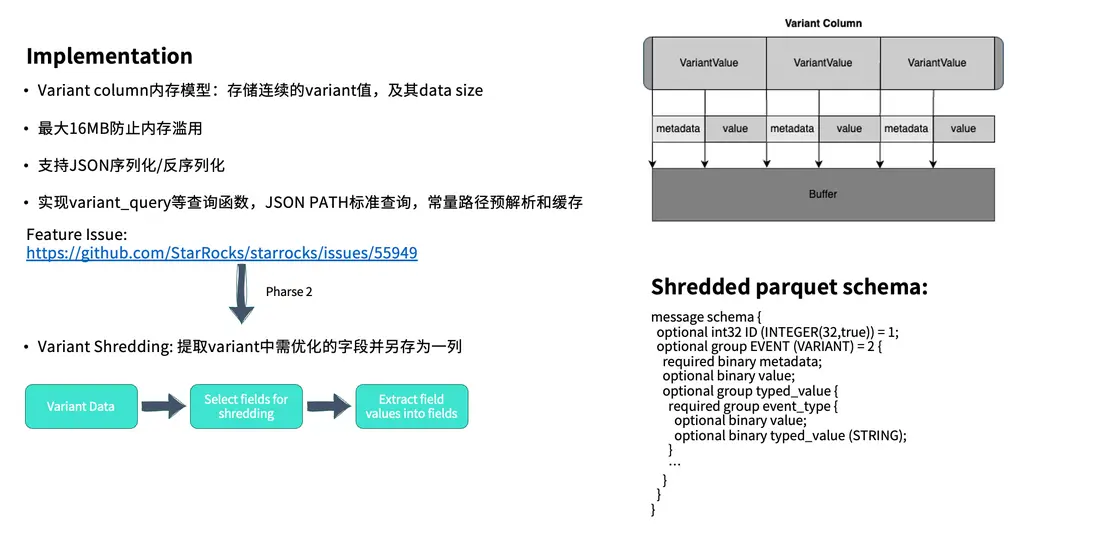
在此基礎上,系統還引入了進一步的性能優化機制 —— Variant Shredding。對於查詢頻次較高的字段,可以將其單獨拆解並存放在獨立的字段(type\_value)中。在實際查詢時,只需直接訪問 type\_value 字段即可,無需再遍歷完整的 Value 內容,從而進一步提升查詢效率。
這一過程將在後續版本的 Feature 中持續完善。目前針對篩選字段的選取策略仍在優化中。根據與 Snowflake 團隊的溝通,他們採用的方案相對直接——選擇查詢頻率最高的前 10 個字段作為 Shredding 對象。
從底層實現來看,Variant Column 實際上會存儲一系列連續的 Variant 值,其中包含完整的 Metadata 與 Value,並在最前端通過 Header 記錄數據長度,以便實現高效的序列化與反序列化。
此外,我們還擴展了 Variant Query 相關函數,實現通過 JSON path 的標準化訪問方式。
存算一體引擎的遷移與實踐
在遷移之前,我們主要使用的 OLAP 引擎是 Apache Pinot。相比之下,Pinot 在國內的應用相對較少,國內更多團隊採用的是 Apache Druid。實際上,Pinot 與 Druid 在架構設計上非常相似:
它們都依賴 ZooKeeper 進行集羣協調,並通過 DeepStore 或其他 Web 組件實現數據存儲;同時,兩者都包含類似的系統角色設計,包括 Master Server、Broker 以及負責數據存儲的 Historical 節點。
為什麼從 Pinot 升級到 StarRocks ?
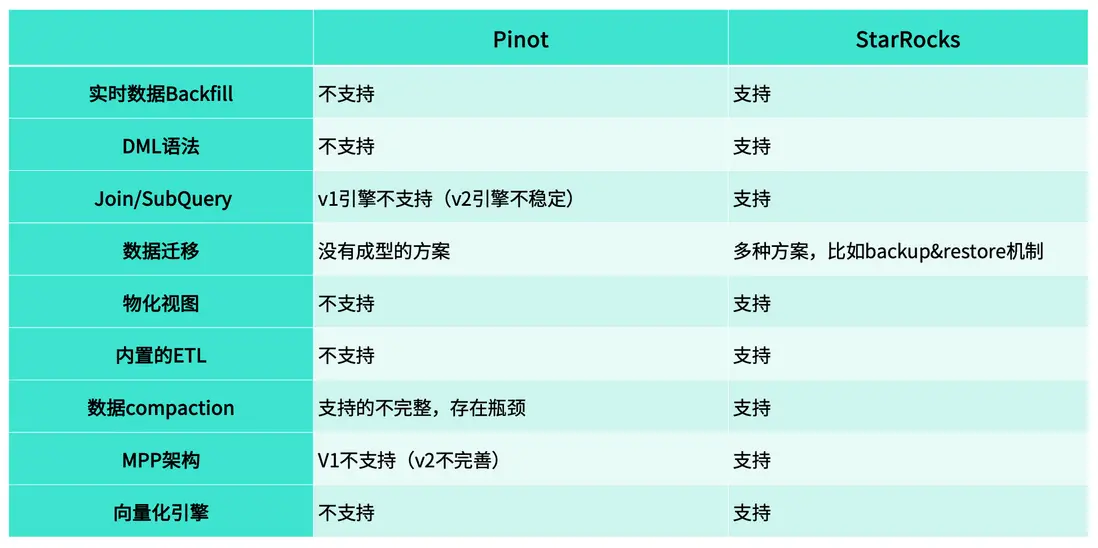
主要原因在於,Pinot 在實際使用中暴露出一系列結構性限制與痛點。
- 實時數據 Backfill
對於 Pinot 而言,它並不支持分區機制。這意味着,當實時數據不斷寫入時,單個 Segment 內往往會混雜多天的數據,因此無法實現精確的 Backfill 操作。
相比之下,StarRocks 原生支持分區管理,我們在實際使用中通常以“天”為分區單位。這種設計使得數據修復與回補更加靈活高效:當某一天的數據出現異常時,只需重新加載對應分區即可完成 Backfill,避免了重複處理歷史數據。
- DML 語法
在 Pinot 中,系統並不支持常見的 DML 操作,如 INSERT、DELETE 或 UPSERT / UPDATE。這意味着,一旦數據出現問題,即便只是個別記錄出錯,也必須依賴完整的 Backfill 流程來重新加載數據,操作繁瑣且成本較高。
而 StarRocks 原生支持多種 DML 操作,用户可以根據實際情況靈活地進行數據插入、刪除或更新。
這種能力在小規模數據修正場景中尤為高效——例如,當僅有少量記錄(幾十條甚至更少)需要修改時,無需重新執行大規模的回填操作,只需通過簡單的 UPDATE 即可完成數據修復。
- Join/SubQuery
我們使用 Pinot 的時間較早,從 0.8 版本開始部署。當時系統尚不支持 Subquery(子查詢) 和 Join 操作。
雖然在 1.1 版本之後,Pinot 官方引入了新的查詢引擎,開始支持這兩類操作,但在實際使用中,我們發現其穩定性仍然不足——SQL 查詢容易報錯,內存佔用高,整體運行不夠穩定。
為彌補這些限制,我們曾使用 Trino 作為中間層,與 Pinot 進行聯合查詢。然而,這種組合在實踐中也存在明顯問題。首先,Trino 的算子下推受限。在訪問半結構化數據時,部分函數無法下推至 Pinot 層執行,導致大量數據被 Trino 拉取到上層處理,不僅查詢效率低下,也對 Pinot 集羣造成較大壓力。
其次,當 Trino 訪問 Pinot 的數據量較大時,常常無法走通用的 HTTP Pipeline,而需要改用 gRPC 方式。但在這種模式下,Trino 的查詢日誌無法與 Pinot 的 Audit Log 系統對接,導致無法完整記錄查詢信息,不利於產線問題的排查。
這種分離式架構給運維帶來了顯著挑戰。當 Pinot 出現異常時,我們無法通過 Query Metrics 快速定位問題,也無法進行有效的故障排查。而在 StarRocks 中,算子可直接下推至存儲層執行,查詢性能更優,且所有的查詢有統一的管理位置,便於產線問題的排查和定位。
- 數據遷移
在實際業務中,我們經常會有數據遷移的需求。例如,原先部署在物理機上的集羣,可能由於公司合規要求需要遷移至 S3;而當 S3 成本超出預算時,又需要將數據遷回本地集羣。這類遷移任務頻繁發生,但 Pinot 並未提供完善的遷移方案,缺乏統一的工具和流程支持。
為了解決這一問題,我們團隊曾基於 Trino 自行開發了一套 Migration Task 機制,用於在不同存儲介質之間轉移數據。然而,由於自研方案在設計時難以覆蓋所有異常場景,在實際運行中仍會遇到穩定性與一致性問題。
相比之下,StarRocks 在數據遷移與備份方面提供了更成熟的體系。一方面,系統支持 Backup & Restore 功能,可在集羣間快速恢復數據;另一方面,Sync Tool 工具能夠實現數據的自動化同步與恢復,幫助我們在遷移任務中更高效地保障數據完整性與業務連續性。
- 物化視圖
Pinot 至今仍未支持物化視圖功能,在過去的使用中,我們只能通過外部服務實現替代方案:通常的做法是按天聚合原始數據,生成新的聚合表,再將結果寫回系統中。這種方式不僅實現複雜,而且只能滿足 “T-1” 的聚合需求。
而在 StarRocks 中,我們可以直接利用物化視圖機制實現高效的實時聚合。無論是 15 分鐘級還是 1 小時級的增量刷新,都能得到良好支持。
- 內置的 ETL
Pinot 並未提供直接的數據處理與重構功能,這在數據研究和生產應用中帶來了較多不便。
在 StarRocks 中,這類需求可以通過簡單的 SQL 實現——例如使用 INSERT INTO SELECT,即可基於現有錶快速生成新的數據集,用於測試、驗證或遷移。
而在 Pinot 中,即便僅需構建一份測試數據,也必須重建表結構、重新 Backfill 數據,操作繁瑣且耗時。
- 數據 Compaction
在使用 Pinot 時,這一問題尤為明顯。Pinot 的 Upsert 表雖然名義上支持更新操作,但實際上並不具備真正的 Compaction 能力——系統無法自動清理重複的 Key。因此,當同一主鍵下存在多條重複記錄時,這些冗餘數據仍會被完整保留,久而久之造成磁盤佔用顯著增加。
相比之下,StarRocks 的主鍵表原生支持 Compaction,能夠自動合併重複數據、保留最新版本。
- MPP 架構
Pinot 的 V1 引擎不支持 MPP,V2 雖開始支持但穩定性較弱;而 StarRocks 原生採用 MPP 架構,分佈式計算能力更成熟、性能更穩定。
- 向量化引擎
Pinot 不支持向量化計算,而 StarRocks 原生具備這一能力。在我們的測試中,一張包含 80 億行數據的表,即便未建立任何索引,也能在 約 1 秒內完成查詢,性能優勢十分顯著。
SQL Dialect Transformer
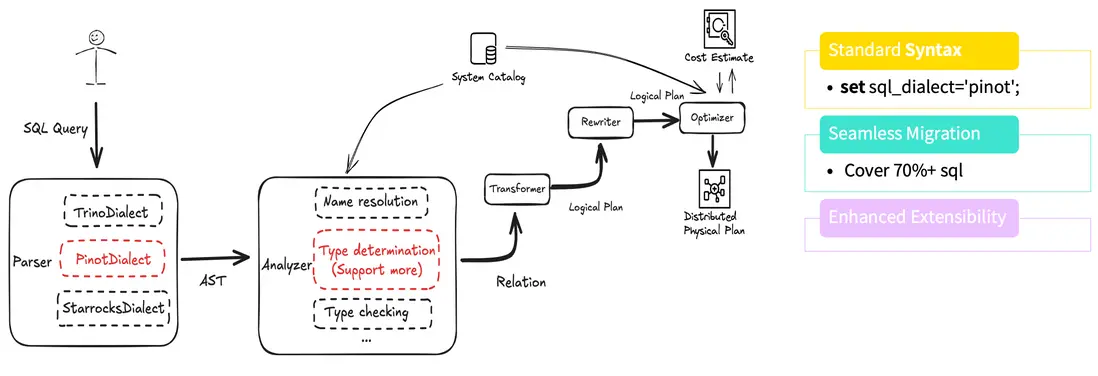
在遷移過程中,我們首先開展的工作是 SQL Dialect Transformer(SQL 方言轉換)。如前所述,業務團隊通常不希望修改已有 SQL 來適配新引擎。
一方面,SQL 改造對他們而言沒有直接業務價值;另一方面,Pinot 本身在索引和內存利用方面表現良好,即使切換引擎,性能提升也未必直觀,因此業務方缺乏改造動力。
為此,我們開發了 Pinot Dialect Transformer,讓用户在無感知的情況下即可將原有 SQL 無縫遷移至 StarRocks。
在實現上,我們參考了 Trino Dialect 的設計思路,對函數名、參數位置及參數數量等差異進行了自動轉換與重建。
在 SQL 解析階段,系統能夠自動識別並轉換成 StarRocks 支持的語法,從而兼容原有查詢邏輯。經過測試,目前該方案可自動覆蓋約 70% 以上的 SQL 語句,大幅降低了人工修改與溝通成本。同時,該架構具備良好的可擴展性,後續只需擴展新的函數,即可快速支持新的語法特性。
基於 Rack 的資源隔離實踐
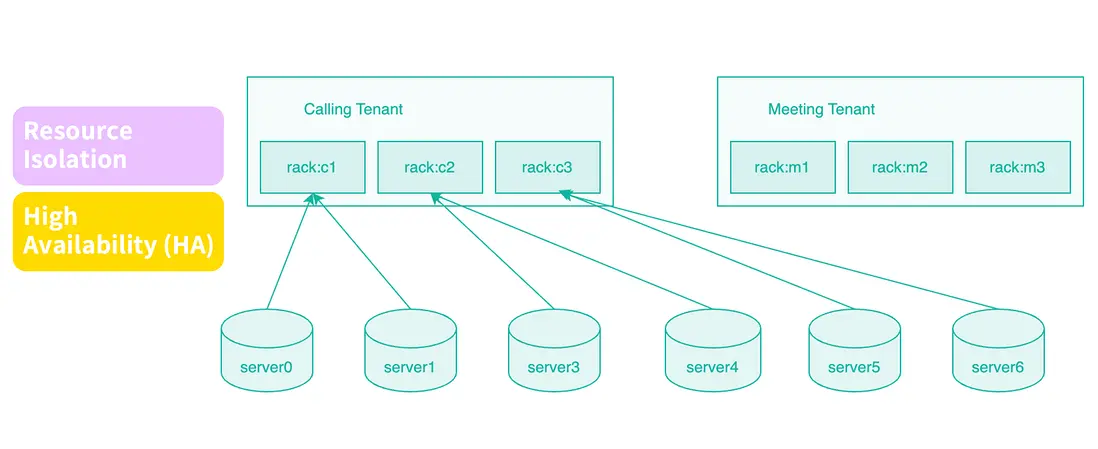
在 Pinot 中,我們長期使用 Tenant(租户)機制來實現多業務共存與資源隔離。StarRocks 目前尚未原生支持 Tenant 概念。為此,我們經過調研與驗證,發現可以通過 Rack(機架)策略實現類似的隔離效果。
具體做法是:在同一集羣中,為不同業務分配不同的機器組。例如,在一套包含 30 台節點的集羣中,可將前 10 台用於 Device 服務,中間 10 台用於 Meeting,其餘節點用於 Calling。
通過這種物理級別的資源劃分,即便某個業務(如 Calling)執行了重負載或高頻查詢,也不會影響到其他服務的運行。這種設計在多業務共用集羣的場景中尤為關鍵。根據我們在 Pinot 運維中的經驗,如果缺乏明確的資源隔離,一個業務的異常常常會拖垮整個集羣。
在真實生產環境中也遇到了一些問題。以我們當前的部署為例,共有 30 台機器,計劃將前 10 台劃分為 Device 業務節點。
理論上,我們希望只需在這 10 台機器上統一設置相同的 Rack 標籤(例如“rack:device”),系統即可在該範圍內自動分配副本,實現高可用。但在當時的版本中並不支持這種邏輯,必須將這 10 台機器進一步細分為多個 Rack(如 device1、device2、device3),系統才能正確分配副本。
針對這一問題,我們與社區深入討論後,增加了一個可選參數,用於在調度過程中顯式強調高可用性優先,從而實現 Rack 級別的副本控制。
此外,我們還優化了 BE 節點擴容時觸發的 Rebalance(數據再均衡) 邏輯,並在內部調度算法中引入對 Rack 信息的識別與權重考慮。
Flat JSON 的使用與優化 1
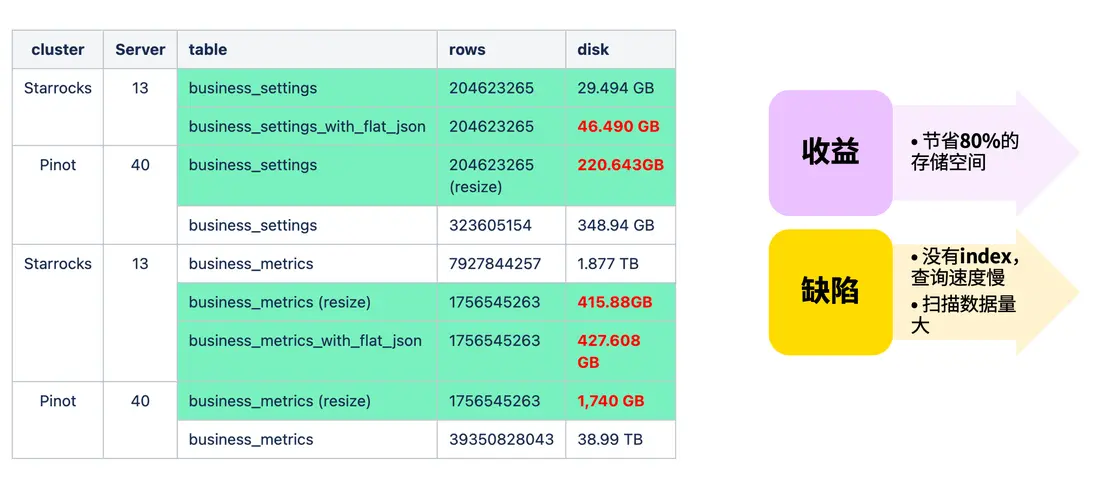
在 Pinot 中,我們主要通過基礎方式處理半結構化數據;而遷移至 StarRocks 後,第一個業務場景就包含大量 Semi-Structured 數據,因此重點探索了 Flat JSON 的使用與優化。
我們在實際數據上進行了測試。通過將 JSON 字段展開為物化子列,存儲空間顯著減少。結果顯示,使用 Flat JSON 後磁盤佔用可降低約 80%,帶來了非常可觀的收益。
不過,目前的 Flat JSON 也存在一些侷限:由於暫不支持建立索引,查詢和掃描時仍會產生一定的性能損耗。為此,我們結合業務特性進行了進一步優化。
Flat JSON 的使用與優化 2

在 Pinot 中,我們主要通過基礎方式處理半結構化數據;而遷移至 StarRocks 後,第一個業務場景就包含大量 Semi-Structured 數據,因此重點探索了 Flat JSON 的使用與優化。
我們在實際數據上進行了測試。通過將 JSON 字段展開為物化子列,存儲空間顯著減少。結果顯示,使用 Flat JSON 後磁盤佔用可降低約 80%,帶來了非常可觀的收益。
不過,目前的 Flat JSON 也存在一些侷限:由於暫不支持建立索引,查詢和掃描時仍會產生一定的性能損耗。為此,我們結合業務特性進行了進一步優化。
Flat JSON 的使用與優化 2

由於同一張表中往往同時存儲多家公司的數據,不同業務的數據結構差異較大,這會削弱 Flat JSON 的效果——當多種 JSON 結構混合在同一表中時,物化子列的提取效率會顯著下降。
為此,我們採用了更合理的分桶鍵(Bucket Key) 與排序鍵(Sort Key) 設計方案。
儘可能讓不同公司的數據分佈在不同的 Tablet 下,提高其數據局部性。即使在極端情況下,不同業務數據仍分佈到了同一 Tablet (哈希衝突),我們依然可以利用排序鍵對數據進行重新分佈,使其落入不同的 Segment。由於 Flat JSON 的優化效果最終作用於 Segment 級別,這一策略能夠顯著提升其整體性能。
根據測試結果,該優化方案相較於原始實現可 降低約 80% 的查詢時延。
Gin Index 的優化
在倒排索引的使用中,我們發現其行為往往像一個“黑盒”——用户難以直接瞭解分詞器在處理文本後的實際效果。
為此,我們新增了一個 tokenize 函數,用户可以通過該函數清楚地看到在指定分詞器下,輸入文本被解析成的最終 Token 形式,從而更好地理解索引效果。
此外,我們還針對算子(Operator) 進行了擴展與優化。為了更好地承接業務需求,我們將原有的 match 算子進行了抽象化處理,構建了一個可擴展的算子規則框架,使其能夠靈活擴展基於 match 的等多種模式。基於這一框架,我們開發了新的 MATCH\_ALL 以及 MATCH\_ANY 算子,可直接下推至存儲引擎執行,大幅提升查詢效率。
由於 match phrase 的支持需要依賴 Clucene 組件。並且社區在早期為降低存儲成本而移除了位置信息,我們在內部版本中恢復了該功能,使系統能夠重新支持短語級匹配,目前相關測試已完成,後續功能開發仍在持續推進中。
未來規劃

未來的優化工作主要聚焦在三個方向:
- Query Insight
我們計劃在現有社區提供的 Query Profile 基礎上,進一步完善查詢洞察體系,使系統能夠更清晰地展示 SQL 各算子的執行耗時。此外,還將引入智能優化建議機制,當某些算子執行時間過長時,系統能夠自動給出潛在的優化方案。
- 半結構化數據支持
當前的重點仍在 Flat JSON。儘管我們已在性能與易用性上進行了大量優化,但由於其暫不支持索引,查詢性能與 Pinot 仍存在一定差距。同時,我們也在繼續推進 Variant Shredding 的優化方案。
- 文本檢索優化
在文本檢索方面,我們仍有多項改進計劃:
目前主鍵表與存算分離架構均不支持倒排索引,算子類型與配置選項也相對有限。我們正與社區合作,持續擴展支持範圍,完善配置能力。
同時,我們也在探索新的搜索引擎方向。例如,社區正在構建新的存儲引擎以替代 Clucene,我們內部也在探索是否可將 Clucene 升級至 Tantivy 等其他新一代的文本搜索引擎或者搭建 StarRocks 內置的文本搜索引擎。











