









作者:任志民,2023 年加入去哪兒旅行數據平台團隊,主要負責數據平台 OLAP 引擎基礎建設和相關數據產品研發工作。
導讀:
在去哪兒網新一代數據平台架構中,StarRocks 作為統一 OLAP 引擎,替代了原有的 Trino、Presto、Druid、Impala、Kudu、Iceberg、ClickHouse 等多個引擎。如今,去哪兒網 StarRocks 集羣覆蓋全司業務線,支撐 7 大數據產品,集羣規模達數十台,日 PV 突破百萬,外表 P95 秒級、內表 P95 毫秒級,性能表現穩定高效。
本文將帶你走進這一實踐過程,解讀架構升級背後的思路與成效。
業務背景
去哪兒網的數據平台為了滿足各業務線的看數、取數、用數需求,沉澱出多種數據產品,包括 QBI 看板、質檢系統、即席 /SQL 分析、趣分析、離線圈人、實時營銷等。這些數據產品依賴於多種計算引擎和數據存儲來滿足不同的業務場景需求。例如:
- Trino、Presto:基於 Hive 數據分析,應用於看板、即席分析場景
- Impala、kudu:業務系統埋點數據實時寫入,Hive 離線、kudu 實時數據聯邦分析
- Druid:kafka 數據實時寫入,應用於看板
- ClickHouse:Hive 數據離線導入,應用於用户分析、離線圈人場景
然而,多引擎架構帶來了諸多挑戰,如引擎之間的兼容性問題、性能瓶頸、運維成本高等。因此,去哪兒網決定對現有的計算架構進行升級,引入一種更為高效、統一的數據處理方案。

選型與評估
在選型過程中,對 StarRocks、ClickHouse、Trino、Kylin 等多個引擎進行了深入調研和評估。從場景覆蓋度、查詢性能、運維難度等多個角度綜合考慮,StarRocks 表現優異,最終成為去哪兒網數據平台升級的首選方案。
場景覆蓋度
寫入能力對比
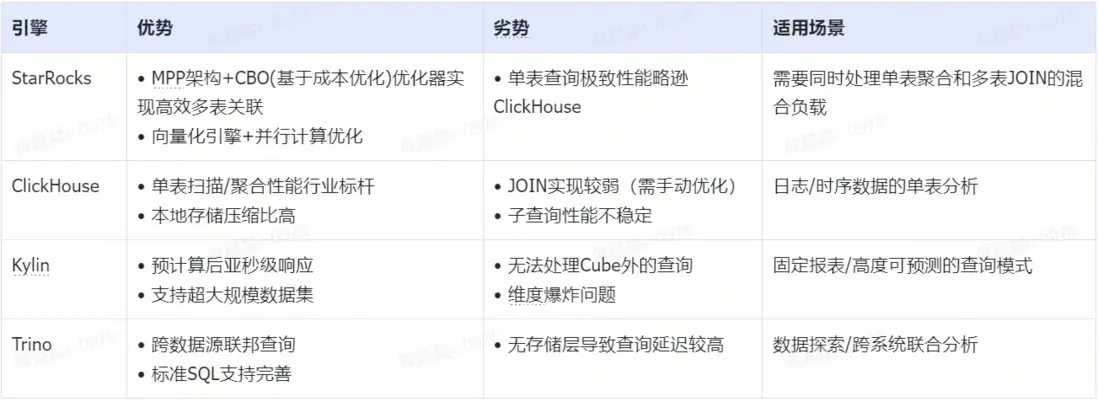
(1)StarRocks
- 支持 Flink/Kafka 實時攝入+ 批量導入( broker load )
- 獨創的 Primary Key 模型支持 UPSERT(類似 Kudu)
(2)ClickHouse
- 更適合批量導入(如 INSERT INTO SELECT)
- 實時寫入依賴 Kafka 引擎表+物化視圖,鏈路複雜
(3)Trino
- 本質是查詢層,寫入依賴底層存儲(如 HDFS/S3)
- 無法自主優化數據佈局
(4)Kylin
- 必須通過 Cube 構建作業(通常小時/天級延遲)
- 無法處理實時更新
運維成本的關鍵考量
另外當前看板平台引擎以 Trino 為主,StarRocks 支持了 Trino 方言,兼容率達到了 90%,經過二次開發後兼容率達到了 99%,這樣可以極大的提高遷移效率,降低了遷移成本。
StarRocks 簡介
StarRocks 是新一代極速全場景 MPP (Massively Parallel Processing) 分佈式數據庫。可以滿足企業級用户的多種分析需求,包括 OLAP (Online Analytical Processing) 多維分析、定製報表、實時數據分析和 Ad-hoc 數據分析等。
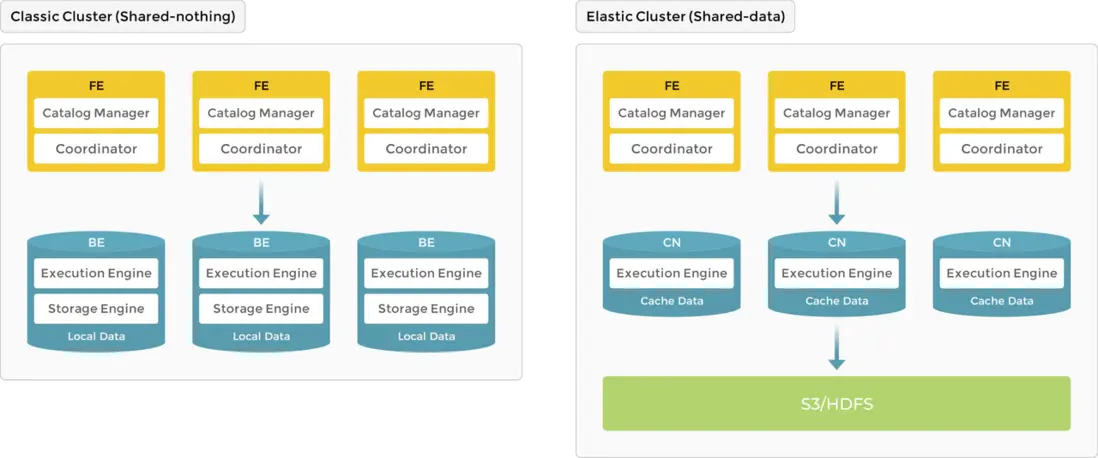
StarRocks的架構簡單,分為前端和後端。前端節點稱為 FE。後端節點有兩種類型,BE 和 CN (計算節點)。當使用本地存儲數據時,需要部署 BE;當數據存儲在對象存儲或 HDFS 時,需要部署 CN。StarRocks 不依賴任何外部組件,簡化了部署和維護。節點可以水平擴展而不影響服務正常運行。此外,StarRocks 具有元數據和服務數據副本機制,提高了數據可靠性,有效防止單點故障 (SPOF)。
StarRocks 特性-MPP 架構
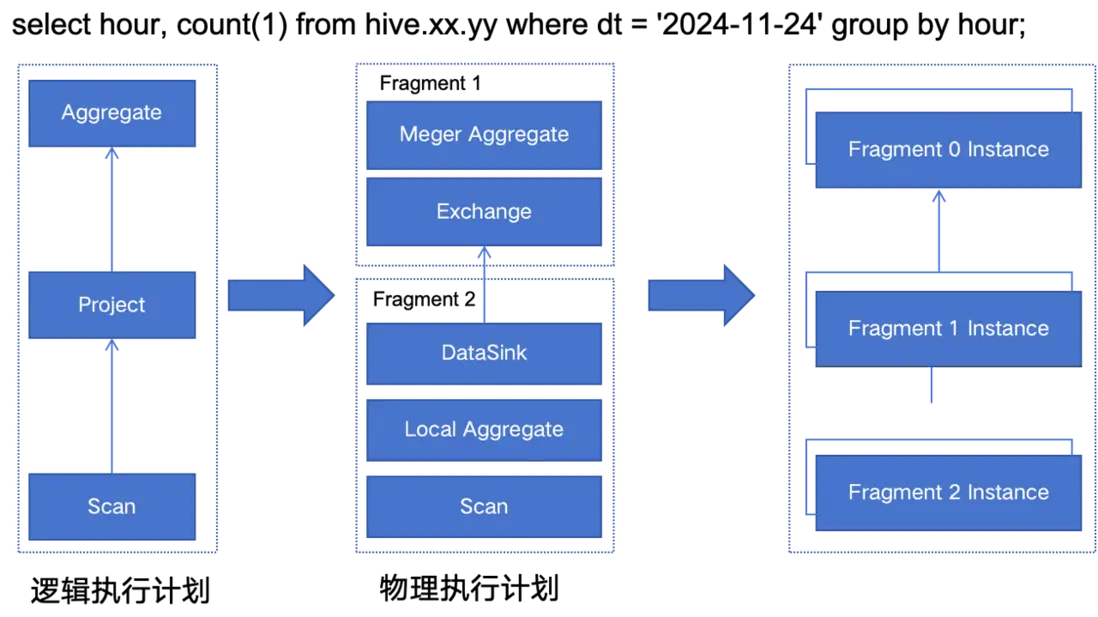
StarRocks 採用的是 MPP 分佈式執行框架,一條查詢請求會被拆分成多個物理計算單元,在多機並行執行。每個執行節點擁有獨享的資源(CPU、內存),能夠使得單個查詢請求可以充分利用所有執行節點的資源。
以下圖為例,查詢 SQL 在經過詞法、語法解析、生成邏輯計劃、邏輯計劃重寫、CBO 優化器後,最終生成了物理執行計劃。每個物理計劃是由一系列的操作算子組成,例如 Frgment2 包含了 Scan、Local Aggregate、DataSink。每個物理執行計劃又會按照實際處理的數據量大小,生成多個實例執行,每個實例是最小的執行單元,會調度在 BE 節點執行。不同邏輯執行單元可以由不同數目的物理執行單元來具體執行,以提高資源使用率,提升查詢速度。
其他特性
另外 StarRocks 具備其他特性,例如全新的 CBO 優化器,在複雜的多表關聯場景下,優秀的優化器可以選擇一個更優的執行計劃,這樣才可以保障極致的查詢性能。智能物化視圖,可以用於數倉分倉、查詢加速,StarRocks 的物化視圖支持基表更新、物化視圖同步更新的策略。
應用實踐
集羣現狀
目前去哪兒網的 StarRocks 集羣已經覆蓋了全司業務線,包括 7 個數據產品。集羣規模達到數百級,最大單集羣規模達到幾十台。日 PV 近百萬+,外表 P95 耗時秒級,內表 P95 耗時毫秒級。這些性能指標充分證明了 StarRocks 在去哪兒網數據平台中的高效性和穩定性。

新數據平台架構
在新數據平台架構中,StarRocks 作為統一的 OLAP 計算引擎,替代了原有的Trino、Presto、Druid、Impala、kudu、Iceberg、ClickHouse 等多個引擎。這一變革極大地簡化了數據平台的運維工作,降低了運維成本。同時 StarRocks 的高性能也提升了數據平台的整體查詢性能。
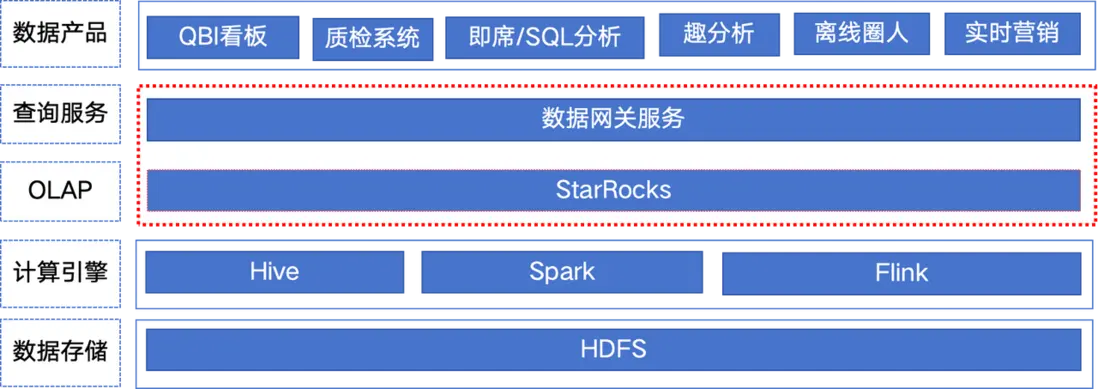
新的數據平台演進主要分為基礎建設、業務產品落地兩個階段。
基礎建設
為了保障 StarRocks 集羣的穩定性和高效性,去哪兒網在基礎建設方面做了大量工作。包括建設可觀測、高可用的 StarRocks 集羣,並基於 StarRocks 建設統一的查詢服務。通過採集服務、監控告警、節點自愈等技術手段,實現了對 StarRocks 集羣的全面監控和管理。此外,還通過分區裁剪、物化緩存等技術手段對查詢性能進行了優化。
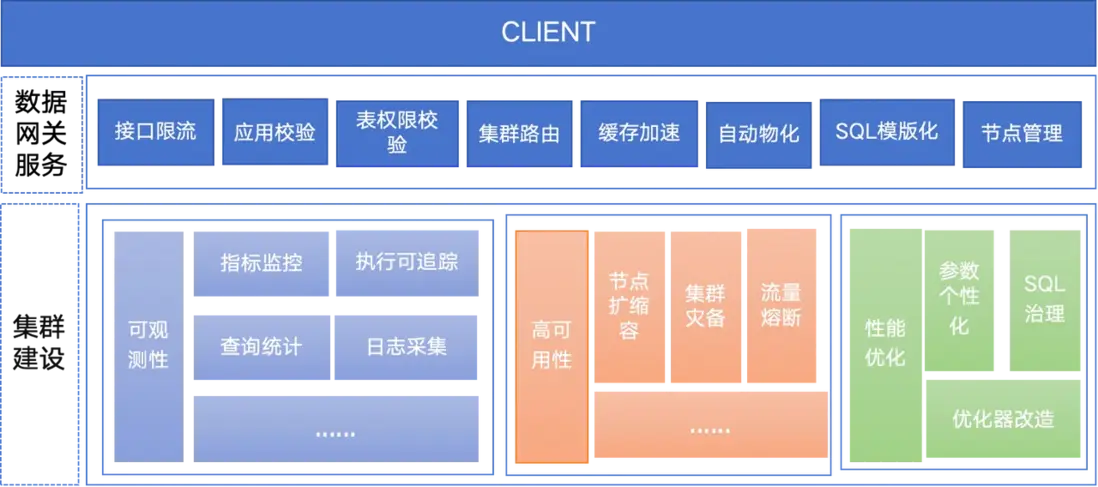
可觀測性-指標監控
為了全面掌控 StarRocks 集羣的運行狀態,我們決定將 StarRocks 的指標信息與公司內部的監控系統實現無縫對接,以此為基礎構建一套完善的監控與管理體系。具體而言,我們將主要開展以下工作:
(1)優化 StarRocks 的指標信息體系:我們對 StarRocks 進行改造,以豐富和完善其現有的指標信息。在此過程中,我們將特別關注那些對集羣性能有重要影響的關鍵指標,如訪問 HDFS 和 MetaStore 的相關耗時等,並考慮將它們作為自定義指標納入監控體系。這將有助於我們更準確地瞭解集羣的實時運行狀況,及時發現潛在的問題。
(2)採集 StarRocks 的 metrics 數據並集成到監控系統中:部署專門的採集服務,用於實時抓取 StarRocks 的 metrics 數據。這些數據將被實時傳輸到 watcher (監控系統的核心組件)中,由後者進行進一步的處理和分析。通過 watcher,我們可以實現對 StarRocks 集羣的實時監控,包括性能指標、健康狀態等關鍵信息的展示和告警。
(3)部署常駐服務以實現自動化處理:為了提升集羣的運維效率,在集羣節點上部署常駐服務。這些服務將負責接收 watcher 發出的回調信息,並根據預設的策略進行自動化處理。例如,對於某些可以通過重啓恢復正常的節點故障,常駐服務可以實現節點的自動重啓,從而大大縮短故障恢復的時間。
通過上述措施的實施,我們將能夠建立起一套高效、可靠的 StarRocks 集羣監控與管理體系,為集羣的穩定運行提供有力保障。
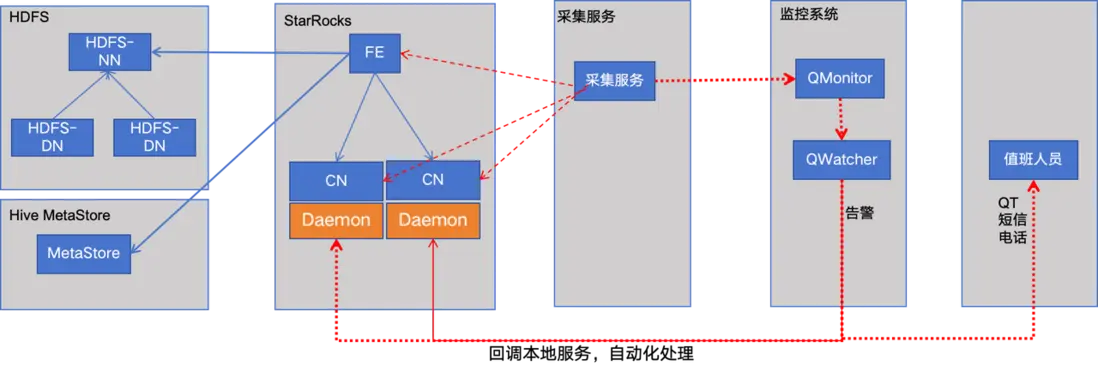
高可用-集羣災備
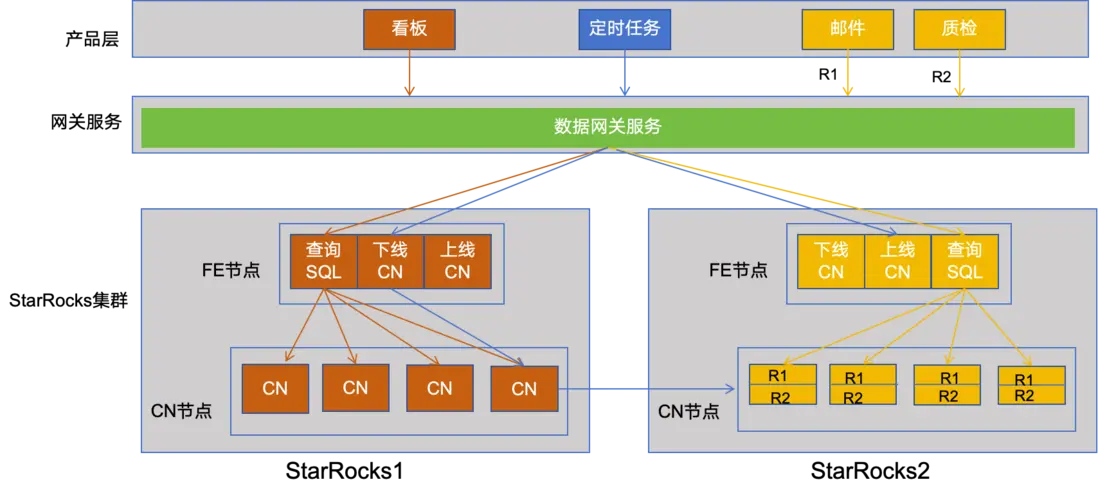
為了確保對外提供穩定且高效的服務,集羣災備方案的實施是不可或缺的。在集羣的設計過程中,我們深入考慮了業務的獨特性質,包括使用高峯時段、嚴格的響應時間要求以及容錯性需求。例如,看板服務的訪問主要集中在每天的 10 點至 20 點,且對響應時間有着極高的要求;而郵件服務則主要在 0 點至 24 點進行訪問,對響應時間的要求相對較低,但對容錯性有着較高的標準。為了應對這些不同的業務需求,我們做了以下工作。
(1)搭建了兩個獨立的集羣( StarRocks1 和 StarRocks2)。看板、郵件服務均接入統一的查詢服務,該服務根據業務類型智能地路由到不同的集羣(看板服務路由到 StarRocks1,郵件服務路由到 StarRocks2),從而實現了物理層面的隔離。
(2)針對看板服務在特定時間段內資源利用率較低的問題,我們充分利用了 StarRocks 的 CN 節點快速上下線的特性。在非高峯時段,即非 10 點至 20 點的時間段內,我們將 StarRocks1 集羣中的部分 CN 節點下線,並將這些資源靈活地擴容到 StarRocks2 集羣中,以應對質檢和郵件服務在夜間高峯時段的資源需求。
(3)此外,為了避免郵件服務和質檢服務在 StarRocks2 集羣中可能產生的資源競爭問題,我們運用了 StarRocks 的資源組功能,實現了業務之間的隔離。這不僅確保了每個業務都能獲得所需的資源,還提高了整個系統的穩定性和可靠性。
通過這一系列精心設計的策略,我們成功地構建了一個既高效又靈活的集羣系統,能夠充分滿足各種業務的複雜需求。
查詢性能-性能優化
StarRocks 作為一個功能強大的開源產品,雖然在多數情況下能夠提供出色的性能和功能,但在某些特定的應用場景中,仍然存在一定的優化空間。為了更好地滿足我們業務的需求,我們結合實際使用場景,對 StarRocks 進行了一系列有針對性的優化。
如下圖,兩個 SQL 語義相同,查詢 Hive 表的昨天分區的一條數據,但是執行情況卻相差很大,包括掃描的分區數、讀取的數據量、以及最終的查詢耗時。
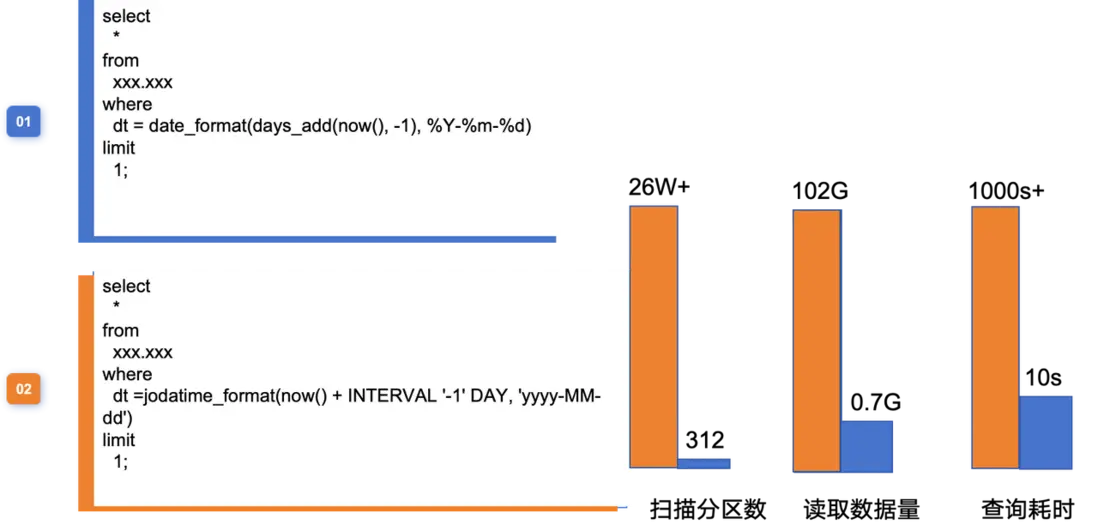
於是我們通過分析進行了特定優化。
(1)對 SQL 的解析流程進行了詳盡的分析,從 SQL 文本輸入到最終生成物理執行計劃,整個流程涵蓋了詞法分析、語法分析、邏輯計劃生成、邏輯計劃重寫、基於代價的優化(CBO)以及物理計劃的最終確定。在深入剖析這一流程後,我們發現生成邏輯計劃和邏輯計劃改寫這兩個環節對 SQL 執行計劃的影響尤為顯著。

(2)在生成邏輯計劃的過程中,系統遵循一系列預定義的規則來進一步簡化關係表達式。

(3)其中 FoldConstantsRule 規則扮演着至關重要的角色,它專注於常量摺疊,通過不斷迭代操作符,對函數類型的操作(如 callOperator )利用預置的函數進行反射調用,從而提前計算出常量值,實現表達式的簡化。

(4)以 date_format(days_add(now(), -1), %Y-%m-%d) 為例,具體的遞歸結果如下。

(5)隨後在邏輯計劃改寫環節,系統進一步應用分區裁剪等優化規則,以減少不必要的數據掃描和處理,提高查詢效率。
(6)經過深入的分析和討論,確定 jodatime_format 函數沒有摺疊是因為缺少相應的解析函數,因此在生成邏輯計劃的階段新增 jodatime_format 方法。這個方法將利用 Joda-Time 庫(或類似的日期時間處理庫)來更高效地處理日期和時間的格式化操作,從而進一步提升 SQL 解析和執行的效率。通過這一優化措施,能夠為用户提供更加快速和準確的查詢服務。

應用落地
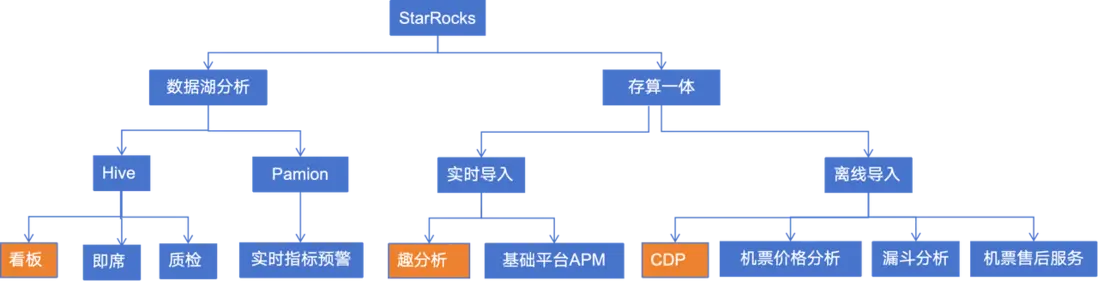
StarRocks 憑藉其強大的查詢分析能力,完美支持了對 Hive、Pamion 等數據湖存儲平台的深度整合與高效查詢。這一特性使得 StarRocks 能夠輕鬆駕馭看板展示、即席查詢、質量檢測等多種複雜分析場景,為用户提供了前所未有的數據洞察能力。在存算分析方面,StarRocks 更是展現出了其獨特的優勢。它支持實時導入和離線導入兩種靈活的導入方式,為用户提供了極大的便利,已經成功應用於趣分析、基礎平台、CDP 等多個產品,同時在機票價格分析、漏斗分析、機票售後服務等場景中,也展現出了其強大的分析能力和應用價值。
最佳實踐-QBI 看板
QBI 看板簡介
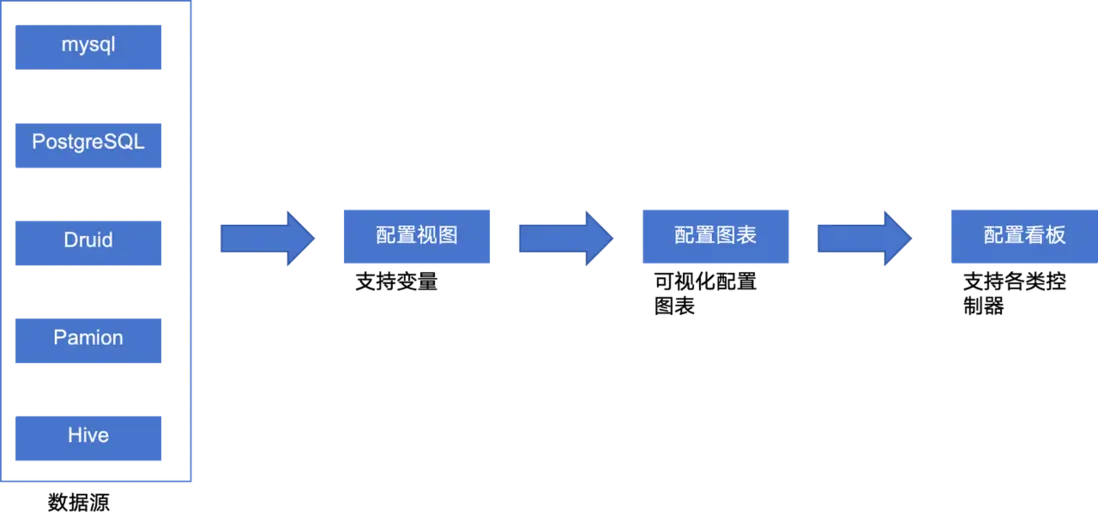
QBI 看板是去哪兒網數據平台中的重要應用之一。QBI 看板實現了自助化看板配置,承載了全司的報表業務,月 PV 是百萬級別、月 UV 是千級別。通過視圖、圖表、看板分層,實現了數據與可視化的解耦以及數據複用。這些特性極大地提升了 QBI 看板的使用效率和用户體驗。
QBI 看板應用效果
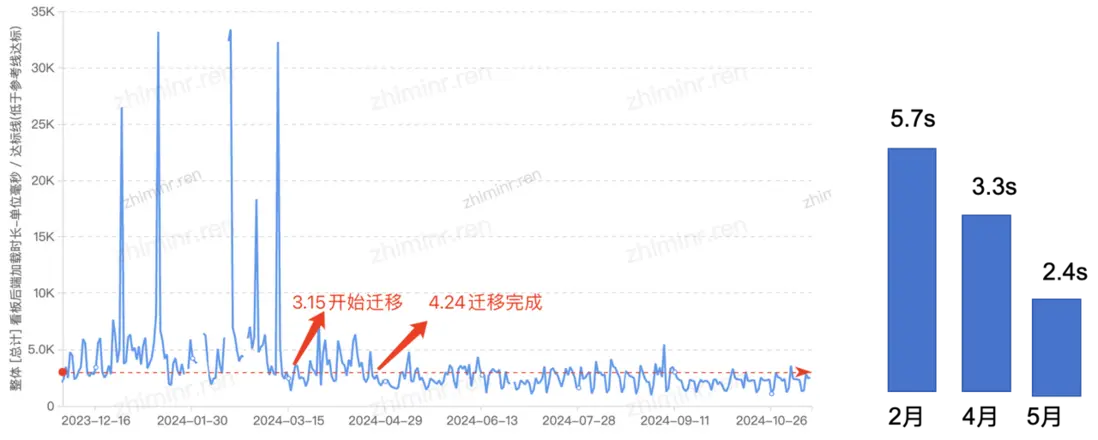
自 3 月份起,QBI 看板項目踏上了逐步遷移的征程,並在 4 月份圓滿完成了整個遷移過程,隨着遷移工作的持續推進,QBI 看板的查詢性能越來越好。具體來看,2 月份時,查詢 P95 還徘徊在 5.7 秒的較高水平;而到了 4 月份,隨着遷移工作的逐步完成,查詢 P95 已經顯著下降至 3.3 秒;5 月份,這一指標進一步優化至 2.4 秒,實現了近乎翻倍的性能提升。
挑戰與方案
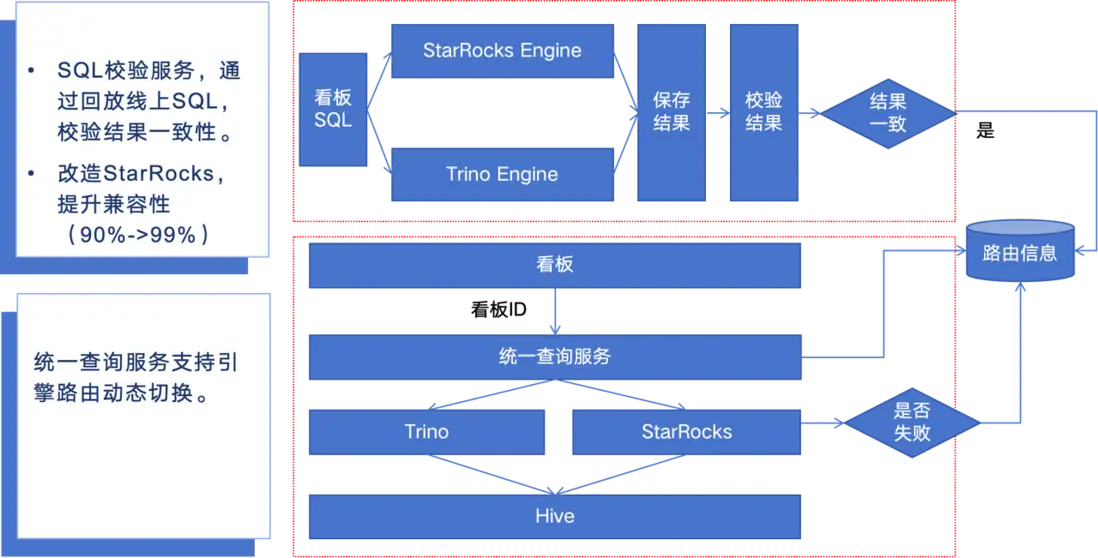
(1)結果一致性保障
引擎切換需要保障結果一致性以及遷移過程對用户透明。因此我們建立了完善的校驗體系、保障了平滑的遷移。主要工作包括:
a. 自主研發智能化比對工具鏈
- 實現全量 SQL 採集與自動化回放驗證
- 支持多維度結果比對(數值精度容錯、NULL 值等價判斷、排序規則標準化)
- 智能歸因分析引擎,自動分類不一致場景
b. 動態路由保障體系
- 基於一致性校驗結果的智能路由決策
- 雙引擎無縫切換機制
- 故障自動降級策略,確保業務連續性
- 全流程用户無感知遷移方案
(2)語法兼容性挑戰
針對 StarRocks 與 Trino 語法體系的兼容性挑戰(基準兼容率 90% ),如果需要手動兼容,工作量巨大且容易出錯。因此我們改造 StarRocks 來實現最後 10% 的兼容,主要涉及複雜函數語義、特殊語法結構和執行邏輯等核心難點,主要工作包括:
a. DDL語法增強
- 支持 CTAS(CREATE TABLE AS SELECT)語法
- 支持 INSERT INTO 語法兼容
b. 函數庫深度對齊
- 實現 dow/week 等日期函數語義統一
- 開發 date_parse/parse_datetime 等時間解析函數
- 支持 from_iso8601_timestamp 等 ISO 格式處理
c. 特殊值處理
- 統一 NULL 值語義處理標準
(3)遷移流程圖
最佳實踐-趣分析遷移
趣分析是去哪兒網提供的一款靈活自助的多維分析工具,實現了對後端埋點數據和離線數倉表的接入分析。同時通過 SQL 拆分、碎片緩存、結果拼接等技術手段,提升了查詢性能和分析效率。
趣分析架構
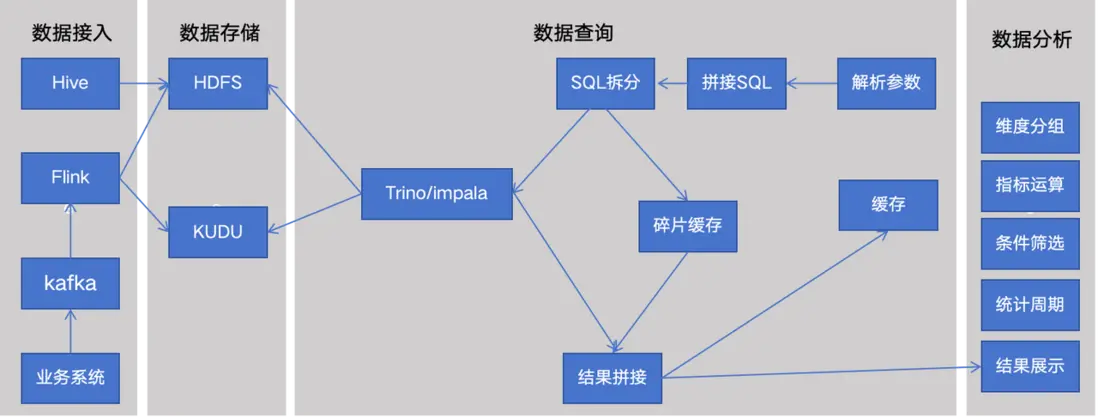
- 離線數據無需寫入,數據存在 HDFS 上,Trino 連 Hive 可直接讀表查詢。
- 實時數據來源包括實時數倉、規範化埋點實時數據等,通過 Kafka 由 Flink 實時寫入 Kudu 表作為熱數據,同時寫一份到 HDFS 做為冷數據和備份
- 在 Hive 表和 Kudu 表基礎上建 Impala 視圖,將離線和實時數據表 Union 在一起,以供查詢。
遷移過程
為了確保趣分析平台上近 200 個項目能夠順利且平穩地完成遷移,我們主要採取以下策略:
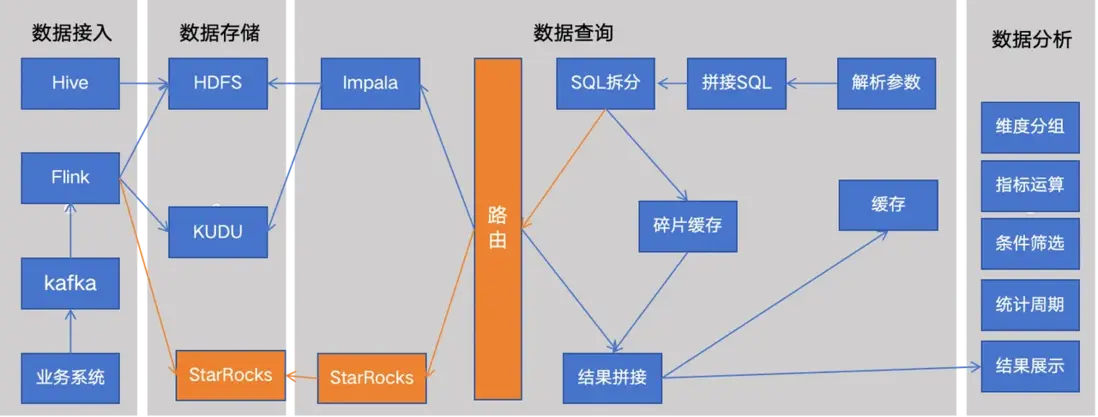
- 在數據寫入層採用雙寫,同步寫 StarRocks、Kudu,同時會做數據一致性校驗,保證數據的完整性、準確性。
- 在數據查詢層,增加路由信息,以根據實際需求自動或手動調整查詢引擎。
- 在切換查詢引擎前,進行了詳盡的性能測試,以確保 StarRocks 能夠滿足業務需求,同時做了語法校驗,保證查詢結果的一致性。
挑戰與方案:如何保障數據低延遲?
為了保證實施數據的低延遲,對 Flink 任務進行了分析,主要分為 3 個環節,kafka-source 負責讀取數據,data-transform 負責做數據轉換,sr-sink 負責把數據寫入到 StarRocks。
其中 sr-sink 是採用的 StarRocks 提供的 connector,基本原理是在內存中積攢小批數據,再通過 Stream Load 一次性導入 StarRocks。
為了保障數據低延遲同時又不增加導入 StarRocks 頻率的有效方法是把相同項目的數據,發送到同一組的 sr-sink 算子, 使內部儘快達到行數或者字節數的條件。同時為了保證數據延遲的可觀測性,採集了算子的相關指標,進行監控。
StarRocks 改造以及社區貢獻
在 StarRocks 的落地過程中,我們對 StarRocks 做了改造,包括提高 Trino 語法兼容率( 90% -> 99% );改造優化器支持語法裁剪;增加自定義參數、自定義指標,提高集羣的自我保護機制,並向社區提交多個 PR。
具體功能改造,舉例如下:

未來規劃
(1)在當前數據驅動決策的時代背景下,企業對於數據倉庫的擴展能力、靈活性、可靠性及穩定性提出了更為嚴苛的要求。為此,我們未來會把 StarRocks 部署於公司自建的 Kubernetes 集羣之上,旨在藉助 Kubernetes 的強大基礎設施管理能力,為 StarRocks 提供一個更加健壯、靈活且易於擴展的運行環境。
(2)在實時數倉場景中,利用物化視圖的多層構建和同步更新機制,可以顯著提升查詢性能,為了實踐該特性,為企業提供了更為實時、準確的數據支持,助力業務決策的高效進行。








