









摘要:歸檔冷數據至 S3,藉助 StarRocks 實現一致性驗證與存儲降本
作者:Riley ,Airtable 數據基礎設施團隊
導讀:
開源無國界,在本期“StarRocks 全球用户精選案例”專欄中,我們將介紹總部位於舊金山的雲端協作服務公司 Airtable。作為一家致力於讓用户像操作表格一樣輕鬆構建數據應用的企業,Airtable 在 2025 年完成了向 AI 原生應用平台 的轉型,平台同時支持企業級安全與治理能力,並與外部系統集成,實現複雜業務流程的自動化。
隨着業務增長,Airtable 需要長期保存的歷史記錄數據(如撤銷、版本歷史)迅速膨脹,佔據了近一半存儲空間。為降低成本,Airtable 推出了 Live Shard Data Archive(LSDA)項目,將訪問頻率極低的數據遷移至 S3,並利用 StarRocks 驗證歸檔數據與源數據的一致性。
本文聚焦數據驗證階段,重點介紹:
- 為何選擇 StarRocks 解決數據驗證問題
- 數據導入與導出優化方案
- 歸檔數據導入實踐
概覽
在 Airtable,應用級(或“基於 Base 的”)數據存儲在 Amazon RDS 的多個分片 MySQL 實例上,每個 Base 對應一個獨立分片。隨着 Base 不斷更新變化,我們會記錄與其歷史相關的追加寫入數據(append-only data),用於支持撤銷(Undo)、歷史版本(Revision History)等功能,讓企業用户可以查看長達三年前的記錄變更。
隨着業務規模擴張,這類追加寫入表的體量迅速增長,如今已接近佔到整個 Airtable 存儲總量的一半。而這些數據的訪問頻率卻極低,卻與日常使用的 Base 數據存放在同一存儲層,帶來了不必要的存儲成本壓力。
項目背景
Live Shard Data Archive(LSDA)項目旨在將訪問頻率極低的追加寫入數據遷移到成本更低的 Amazon S3,以縮減 RDS 實例的磁盤容量。遷移完成後,我們可以安全刪除舊數據並重建 RDS 實例,從而釋放空間。
整個遷移過程分為三步:
- 數據歸檔與轉換:從 RDS 提取並轉換數據,存入 S3,並確保應用代碼能高效、穩定地訪問歸檔數據;
- 數據驗證:比對歸檔數據與 RDS 源數據,確保遷移過程中未引入不一致問題;
- 更新應用邏輯,使其可以直接從 S3 讀取數據。
完成這些步驟後,我們能夠安全截斷已遷移至 S3 的數據,大幅降低 RDS 存儲佔用和成本。
本文將重點介紹第二步的首個階段——數據驗證。
歸檔與轉換
將 RDS 數據歸檔並轉換為存儲在 S3 上的最終形態,需要分三步完成:
- 利用 RDS 自帶功能,將數據庫快照直接導出到 S3,文件格式為 Parquet。
- 為優化歸檔數據的查詢延遲,需要基於客户維度重新分區。這個環節挑戰很大,因為需要處理的數據規模超過 1PB,文件數量超過 1000 萬個。我們採用 Apache Flink 進行增量式讀取和處理,將數據重新分區到每個客户的獨立分區中。
- 通過高併發的 Kubernetes 重寫任務(rewriter job)對每個客户的歸檔數據進行排序,併為重寫後的 Parquet 文件添加索引和 Bloom Filter,從而加速常見查詢模式。
驗證概覽與方案考慮
為了驗證數據一致性,我們需要對歸檔數據與源數據逐行比對,確保每一行記錄完全匹配。最直接的做法是:從歸檔中讀取一行,在 RDS 中查找對應記錄並進行比對。
但這一思路在實踐中並不可行——數據量接近 1PB、記錄數約 2 萬億條,而 RDS 還要承載線上業務流量,如此規模的額外查詢會給生產環境帶來巨大壓力。
為避免影響線上,我們改為使用原始且未改動的 RDS 導出文件作為比對源數據。這些文件同樣存儲在 S3 中,消除了直接查詢生產實例的風險。然而,逐行比對仍然過慢,難以滿足驗證效率要求。
最終,我們確定了一種可行方案:將兩份數據加載到關係型數據庫中,通過表 Join 快速找出差異,從而高效完成驗證。
藉助 StarRocks 進行數據驗證
在本次數據驗證項目中,數據基礎設施團隊協同存儲團隊,共同評估並選定了最適合的技術方案,以高效完成整體驗證工作。
為何選擇 StarRocks 來解決數據驗證問題?
數據驗證的核心挑戰是要對兩份規模巨大的數據集執行大量 Join 操作,而這兩個數據集各自接近萬億行。如何在可控的計算成本下高效完成如此高強度的計算,是項目的關鍵難點。
經過調研,我們最終選擇 StarRocks,因為它在 Join 性能方面表現突出,能夠在同等負載下避免其他查詢引擎常見的性能瓶頸。
在實際落地中,我們將 S3 中的原始 Parquet 文件加載到 StarRocks 本地表,並利用其 Colocation Join 機制來高效完成數據驗證所需的 Join 操作。
StarRocks 架構
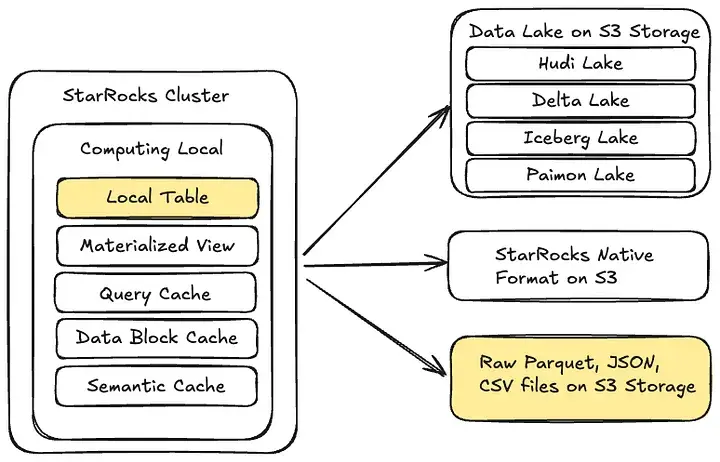
StarRocks 的整體架構支持訪問多種類型的數據源:
- S3 數據湖:包括 Hudi 、Delta Lake、Iceberg 和 Paimon ;
- S3 原生存儲格式:支持直接在 S3 上以 StarRocks 原生格式創建並持久化表;
- S3 原始文件:可直接對存儲在 S3 中的 Parquet、JSON 或 CSV 文件進行查詢。
在本項目中,我們將 S3 中的原始 Parquet 文件加載至 StarRocks 本地表,用於執行數據驗證(前文已介紹)。
數據導入優化:提升 StarRocks 的數據加載性能
我們需要將接近 1 萬億行的數據從原始 Parquet 文件加載到 StarRocks 本地表中。這些數據由數億個小文件組成,如果缺乏合理的優化和並行處理策略,整個導入過程可能需要耗時數月。
為提升數據導入吞吐量,我們採取了以下優化措施:
- 降低副本數量(3 → 1)
由於這是一次性的數據驗證任務,並不涉及生產環境的高可用性要求,因此我們將副本數量從 3 個減少到 1 個,大幅降低了需要導入的數據總量。 - 提升內部導入並行度
導入完成後才會進行基於 Join 的驗證,因此導入性能不會影響線上服務。我們通過調整以下參數提升並行度:
pipeline_dop
pipeline_sink_dop - 增加每個分區的桶(Bucket)數量
為避免單個桶過大,我們將每個桶的數據量限制在 5GB 以內,並通過增加桶數量顯著提升導入吞吐量。雖然這可能導致數據壓縮 Compaction 任務延後,但在本場景中完全可接受。
通過以上優化,我們成功實現了大規模數據的高效導入
數據導入與導出
在完成 StarRocks 部署後,我們需要加載兩部分數據:
- 來自 RDS 導出的源數據;
- 經過轉換、計劃作為查詢來源的歸檔數據。
考慮到時間與成本,直接在 StarRocks 中存儲全部約 1PB 的數據並不可行,因此我們選擇僅對錶中的非主鍵列進行哈希處理。
在本次加載過程中,我們共導入了兩張表,以下示例主要聚焦 _actionLog 表。
初始方案:哈希非主鍵列的簡化表結構
我們為每張表設計了類似的表結構,初始設計如下:
CREATE TABLE `_rdsExportActionLog` (
`id` bigint(20) NOT NULL COMMENT "",
`application` varchar(65533) NOT NULL COMMENT "",
`hash_value` varchar(65533) NULL COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`, `application`)
DISTRIBUTED BY HASH(`id`, `application`)
ORDER BY(`application`)
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "action_log_group",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"compression" = "ZSTD"
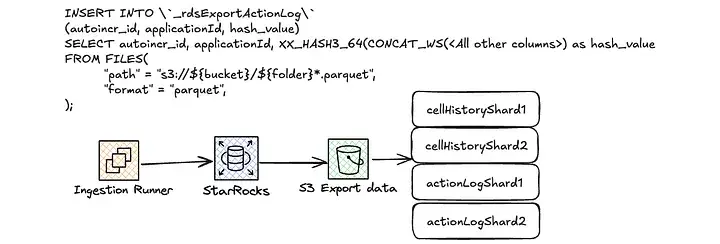
);隨後,我們使用類似如下的 INSERT 語句進行數據加載:
INSERT INTO \`exportActionLog\`
WITH LABEL ${label}
(id, application, hash_value)
SELECT id, application, XX_HASH3_64(CONCAT_WS(',',
<columns>)) as hash_value
FROM FILES(
"path" = "s3://${bucket}/${folder}*.parquet",
"format" = "parquet",
);數據分佈與加載瓶頸
這種加載方式耗時極長——僅導入兩個分片就需要近一天時間。隨着數據量增加、表規模擴大,導入速率進一步下降。
更意外的是,提高本地並行度(即同時加載多個分片)幾乎沒有帶來性能提升;而當並行度超過 5 時,系統還會頻繁出現如下情況:
JobId: 14094
Label: insert_16604b11–7f2d-11ef-888c-46341e0f370e
State: LOADING
Progress: ETL:100%; LOAD:99%
Type: INSERT我們發現,加載進度常常迅速到達 99%,卻長時間停滯在此狀態,無法快速完成。
根據 StarRocks 官方文檔:
“當所有數據加載完成後,LOAD 參數會返回 99%,隨後數據才開始生效;數據完全生效後,LOAD 才會返回 100%。”
顯然,我們的初始方案在數據生效這一環節遇到了性能瓶頸。
優化一:增加 Bucket 數量
最初的數據分佈僅基於 id 和 application,且未指定 Bucket 數量(具體機制可參考 StarRocks 官方文檔)。
我們的假設是:隨着數據量增大,單個 Bucket 過於龐大,導致處理效率下降。
在諮詢 StarRocks 團隊後,建議將較小表的 Bucket 數量調整至 7200 個。
因此,表結構被修改為如下形式:
CREATE TABLE `exportActionLog` (
`id` bigint(20) NOT NULL COMMENT "",
`application` varchar(65533) NOT NULL COMMENT "",
`hash_value` varchar(65533) NULL COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`, `application`)
DISTRIBUTED BY HASH(`id`, `application`) BUCKETS 7200
ORDER BY (`application`)
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "action_log_group",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"compression" = "ZSTD"
);然而,這種方式雖然顯著提升了加載速度,但也引發了內存問題:
message: 'primary key memory usage exceeds the limit.
tablet_id: 10367, consumption: 126428346066, limit: 125241246351.
Memory stats of top five tablets: 53331(73M)53763(73M)53715(73M)53667(73M)53619(73M): 優化二:按 Shard ID 對錶進行分區
將表按 Shard ID 分區並以此方式加載數據,可以為每個分區單獨指定 Bucket 數量,使數據存儲更高效。
通過簡單計算,我們得出了以下結論:
actionLog => 10TB (Hashed) => 10 * 1024 / 148 shards = 69GB per shard =>
34 buckets to host it => add some buffer, 64 buckets per partition
In total: 64 buckets per partition * 148 shards = 9472 buckets此外,這種分佈策略還支持按 Shard 逐一驗證數據,避免因一次性加載過多數據而造成內存壓力。
最終,我們基於該方案創建了新的表結構,並調整了加載語句,使其可直接從 S3 文件路徑中提取 Shard ID。
CREATE TABLE `exportActionLog` (
`id` bigint(20) NOT NULL COMMENT "",
`application` varchar(65533) NOT NULL COMMENT "",
`shard` int(11) NOT NULL COMMENT "",
`hash_value` varchar(65533) NULL COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`, `application`, `shard`)
PARTITION BY (`shard`)
DISTRIBUTED BY HASH(`id`, `application`) BUCKETS 64
ORDER BY(`application`)
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "action_log_group_partition_by_shard",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"compression" = "ZSTD"
);
這一改進顯著提升了數據導入速度:LSDA 數據在不到 10 小時內便從 S3 成功加載至 StarRocks,平均吞吐量約每分鐘 20 億行。
歸檔數據導入
在將完整的 RDS 導出(作為驗證的真實來源數據)成功導入 StarRocks 之後,我們還需要導入歸檔數據,並在這兩份數據之間執行驗證。由於歸檔數據的存儲格式與導出數據不一致,這帶來了額外挑戰。
借鑑導出數據的導入經驗,我們採用相同的表結構來存儲歸檔數據——包括相同的 Bucket 數量和基於 Shard ID 的分區策略。
這種方式使導出數據和歸檔數據能夠位於同一 Colocation Group,從而充分利用 StarRocks 的 Colocation Join 功能。
CREATE TABLE `_rdsArchiveActionLog` (
`autoincr_id` bigint(20) NOT NULL COMMENT "",
`applicationId` varchar(65533) NOT NULL COMMENT "",
`shardId` int(11) NOT NULL COMMENT "",
`hash_value` varchar(65533) NULL COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`autoincr_id`, `applicationId`, `shardId`)
PARTITION BY (`shardId`)
DISTRIBUTED BY HASH(`autoincr_id`, `applicationId`) BUCKETS 64
ORDER BY(`applicationId`)
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "action_log_group_partition_by_shard",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"compression" = "ZSTD"
);RDS 導出與歸檔目錄結構的差異
不過,RDS 導出數據與歸檔數據在 S3 中的存儲方式差異很大。
RDS 導出數據採用大目錄結構,每個目錄對應 StarRocks 中的一個 Shard 和 Partition。這種結構使得導入非常簡單——可以用通配符批量導入目錄下的所有 Parquet 文件,並從目錄路徑直接提取 Shard ID 用於分區字段。
而歸檔數據則完全不同。為了方便應用直接從 S3 讀取,數據是按 Application 維度存儲的,導致:
- 數據分散在超過 600 萬個小目錄中,每個目錄對應一個應用;
- 應用與分片並不一一對應,有些應用的數據甚至分佈在多個分片;
- S3 中也沒有保存源分片信息,無法像導出數據那樣直接從路徑提取 Shard ID。
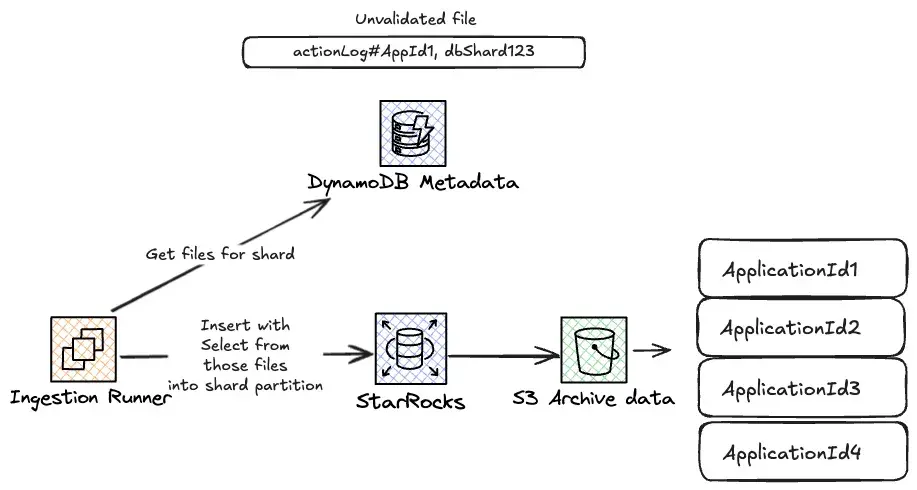
為解決這一問題,我們使用 DynamoDB 中的文件元數據,並創建了以 Shard ID 為排序鍵的全局二級索引(Global Secondary Index),然後按 Shard ID 查詢對應文件並執行導入。
通過 Union 在 StarRocks 中批量插入
StarRocks 的 INSERT 語句每次只能指定單一路徑,這意味着每個文件都需要單獨執行一條 INSERT。
相比之下,RDS 導出數據僅有約 160 個目錄及對應的 INSERT 語句,而歸檔數據卻需要執行超過 600 萬條
為此,我們嘗試對流程進行高並行化處理:
- 同時加載多個 Shard ;
- 每個 Shard 內同時運行多個進程。
由於程序基於 Node.js 和 TypeScript,並非真正多線程,但可以通過多進程緩解 I/O 阻塞。
我們嘗試用 10 個線程併發加載單個分片,結果遇到了新的問題:
message: 'Failed to load data into tablet 14775287,
because of too many versions, current/limit: 1006/1000.
You can reduce the loading job concurrency, or increase loading data batch size.
If you are loading data with Routine Load, you can increase
FE configs routine_load_task_consume_second and max_routine_load_batch_size由於多個進程同時執行插入,StarRocks 產生了過多的表版本,而其基於壓縮頻率的合併處理速度無法跟上。同時,StarRocks 的版本上限為 1000,無法通過簡單調參解決。
因此,我們嘗試減少插入語句數量,將更多工作交由 StarRocks 完成。當時 CPU 和內存使用率都很低,但加載過程依然緩慢甚至失敗。
由於每個 SELECT 語句只能指定一個路徑,我們採用折中方案:通過循環生成 SQL,將多個文件路徑拼接到同一條 INSERT 語句中,例如:
INSERT INTO <table>
SELECT * FROM FILE_1
UNION ALL
SELECT * FROM FILE_2
……藉助這一策略,我們得以同時處理 100 個應用的數據,顯著加快了整體加載速度。最終,僅用約 3 天時間,就完成了來自 600 萬個應用、約 1 萬億行數據的歸檔側加載。
致謝
感謝 Daniel Kozlowski、Kun Zhou、Matthew Jin 和 Xiaobing Xia 在該項目中的重要貢獻。
本文翻譯自 The Airtable Engineering Blog:https://medium.com/airtable-eng/live-shard-data-archive-expor...






