









作者:StarRocks TSC Member、鏡舟科技 CTO——張友東
本文基於鏡舟科技 CTO、StarRocks TSC 成員張友東在 StarRocks Connect 2025 活動上的主題分享整理而成。圍繞大會的核心主題——“數據與世界的連接”,本文將從三個維度進行闡述:
- 過去:StarRocks 通過開源的力量,將全球的社區用户緊密聯繫在一起。
- 現在:StarRocks 正在推動數據與現代化數據分析應用的融合。
- 未來:StarRocks 將進一步探索數據分析與 AI Agent 的結合。
連接世界(過去)
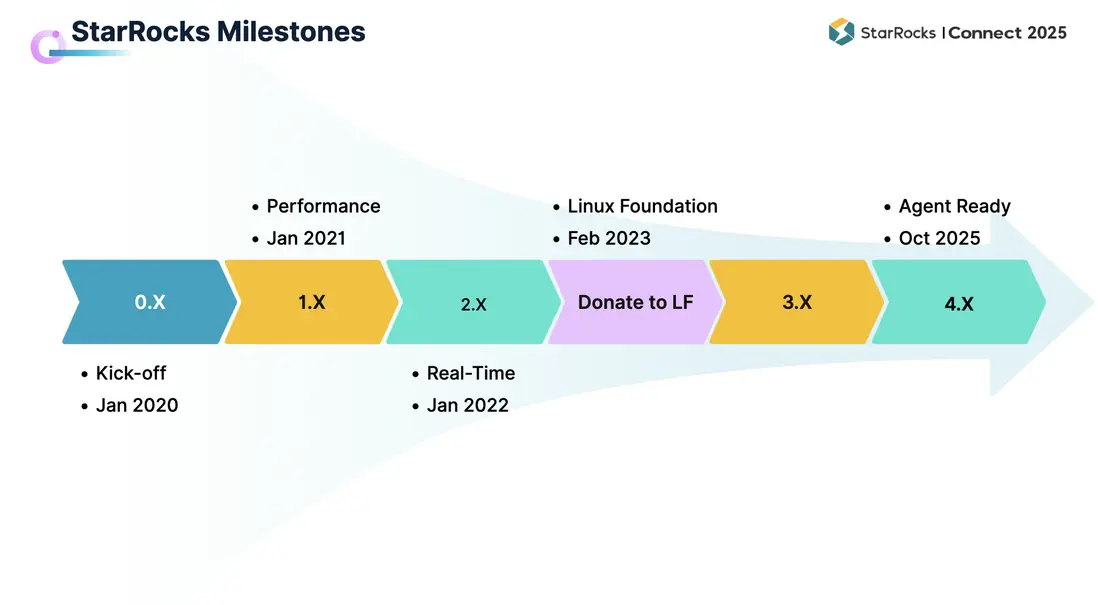
在過去五年中,StarRocks 始終保持着快速迭代。今年 10 月,StarRocks 即將發佈 4.0 版本,至此已經完成了從 1.0 到 4.0 的四次重要升級。
- 1.0 於 2021 年發佈。憑藉強大的性能,StarRocks 讓眾多社區用户認識並開始使用。
這 - 2.0 於 2022 年發佈, 以“新一代實時分析引擎”的定位逐漸被用户廣泛接受,在實時能力方面持續增強,幫助用户更好地支撐實時業務洞察。
- 3.0 於 2023 年 4 月發佈,標誌着 StarRocks 架構由存算一體向存算分離的升級,並顯著提升了湖倉分析能力。
- 全球化發展方面,2023 年 StarRocks 項目正式捐贈給 Linux 基金會。該基金會匯聚了包括 Linux、Kubernetes 在內的重量級開源項目,如今 StarRocks 也成為其中一員。
- 4.0 將於 2025 年 10 月推出,在 AI Agent 方向實現更多突破。

過去幾年,StarRocks 得到了全球眾多知名企業的廣泛採用。僅我們直接接觸到的,就有超過 500 家估值 10 億美元以上的公司在使用 StarRocks,而在更廣闊的開源社區中,實際用户數量遠超這一數字。
目前,StarRocks 的應用已經遍佈全球:
- 亞洲:在中國,各行各業的頭部企業幾乎都在嘗試使用 StarRocks 來加速業務,歷屆 Summit 上的“Logo 牆”便是最直觀的見證。在東南亞,新加坡、馬來西亞的代表性企業包括電商平台 Shopee、本地生活服務商 Grab,以及跨境電商巨頭 SHEIN,均已選擇 StarRocks。在日韓,韓國知名搜索引擎 NAVER、金融支付公司 Toss 也在生產環境中使用 StarRocks;此外,在印度、菲律賓等國家,StarRocks 也在快速拓展。
- 北美:StarRocks 在多個行業的領先企業中得到應用。金融與財税領域的 Intuit、電信巨頭 Verizon、Web3 領域的 Coinbase、興趣社交平台 Pinterest、科技巨頭 Microsoft、體育電商平台 Fanatics、旅遊巨頭 Expedia 等,都已在不同業務場景中使用 StarRocks。
- 歐洲:流程挖掘領軍企業 Celonis、遊戲公司 InnoGames、本地生活 SaaS 企業 Fresha 等,也在其業務中部署了 StarRocks。
可以説,StarRocks 已經逐步實現了全球範圍的覆蓋。展望未來,我們相信,StarRocks 將會像 Oracle、MySQL、PostgreSQL 一樣,成為數據分析領域耳熟能詳的名字,併成為更多企業的首選。
連接現代數據分析(現在)
現代數據分析的挑戰
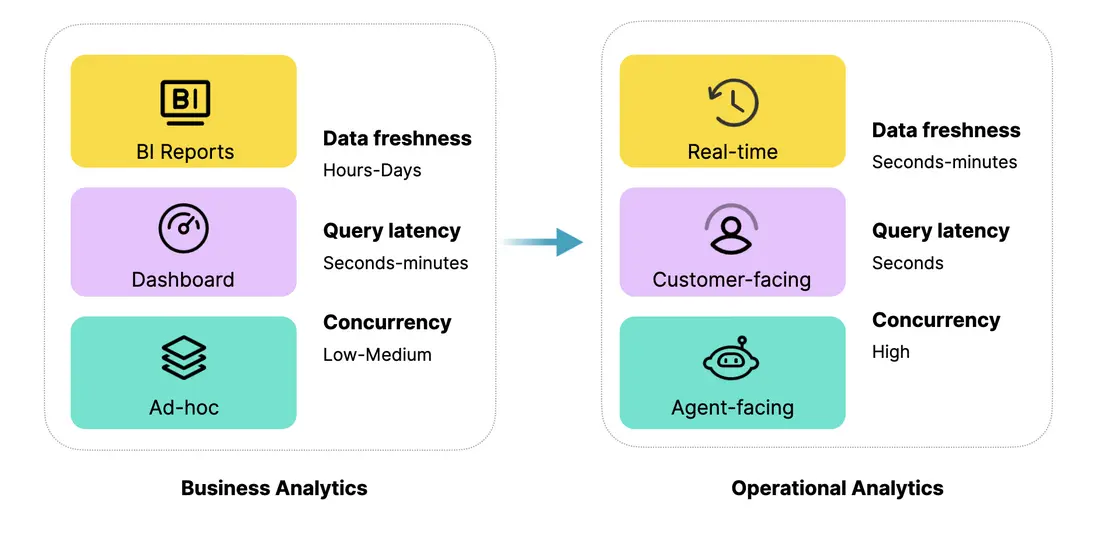
當前的數據分析應用正面臨新的挑戰。從場景演進的角度來看,現代化數據分析正在從 Business Analytics 向 Operational Analytics 拓展。
- Business Analytics:主要面向企業的戰略層面,強調公司級的大指標對齊和戰略分析。例如報表、Dashboard,以及分析師通過 Ad-hoc 查詢來判斷業務上漲或下降的原因。
- Operational Analytics:強調數據分析在戰略落地過程中的戰術支撐。其核心價值在於通過實時的分析洞察和針對客户的應用場景,為具體的運營動作提供指導。未來,隨着 AI Agent 的興起,這類場景還將進一步擴展。
在這兩類場景中,對數據分析的要求存在顯著差異。以常見的幾個核心維度為例:數據新鮮度、查詢延時、查詢併發。在 Operational Analytics 中,這些要求遠高於傳統的 Business Analytics。例如,數據新鮮度需要達到秒級或分鐘級的實時;面向客户的查詢延時必須控制在秒級以內;而在面向 Agent 的場景下,查詢併發量更是成倍提升。因此,新的運營分析場景對數據系統提出了前所未有的挑戰。
速度優先,治理缺失
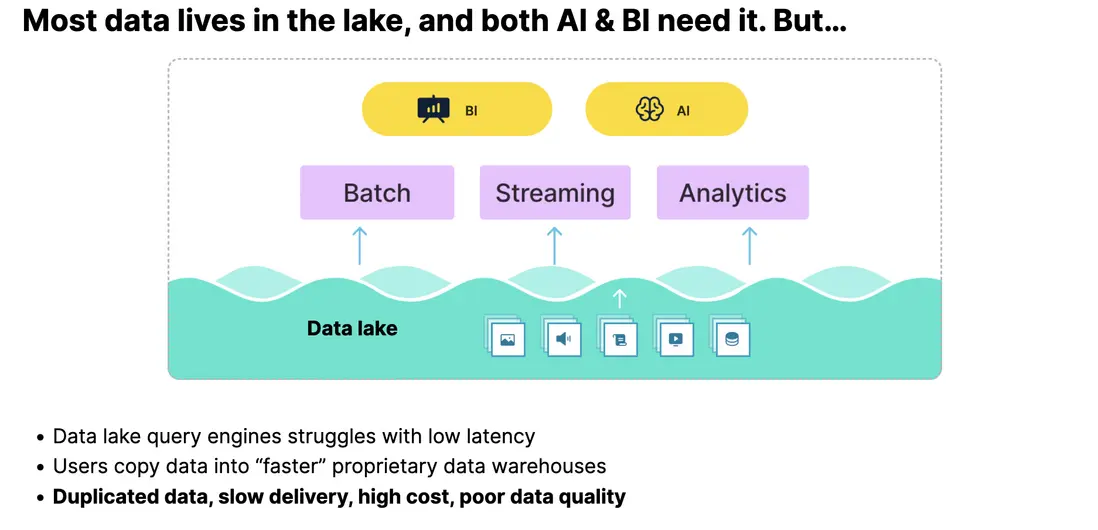
然而,理想與現實之間仍存在差距。當前,直接在 Data Lake 上進行分析,許多引擎都會面臨查詢性能不足的問題。為彌補性能與實時性,企業往往選擇將 Lake 上的數據再導入專用數據倉庫(如 ClickHouse 等)進行處理。這種方式導致架構呈現“煙囱式”特徵,即為每個業務場景單獨構建一套底層數據系統。
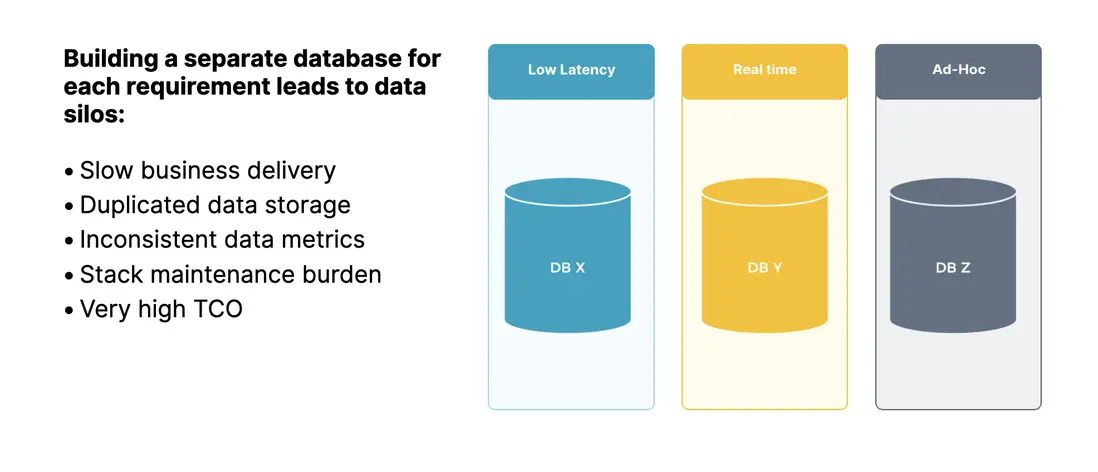
煙囱式架構的問題十分突出:
- 重複開發:不同場景需要獨立建設,業務交付效率低。
- 數據冗餘:同一份數據被多次存儲,佔用大量資源。
- 口徑不一致:數據分散在多個系統,導致指標口徑不一致。
- 運維複雜:多套系統並行運行,整體運維與運營成本高企。
正是為了解決這些痛點,StarRocks 應運而生。
面向現代分析的統一引擎
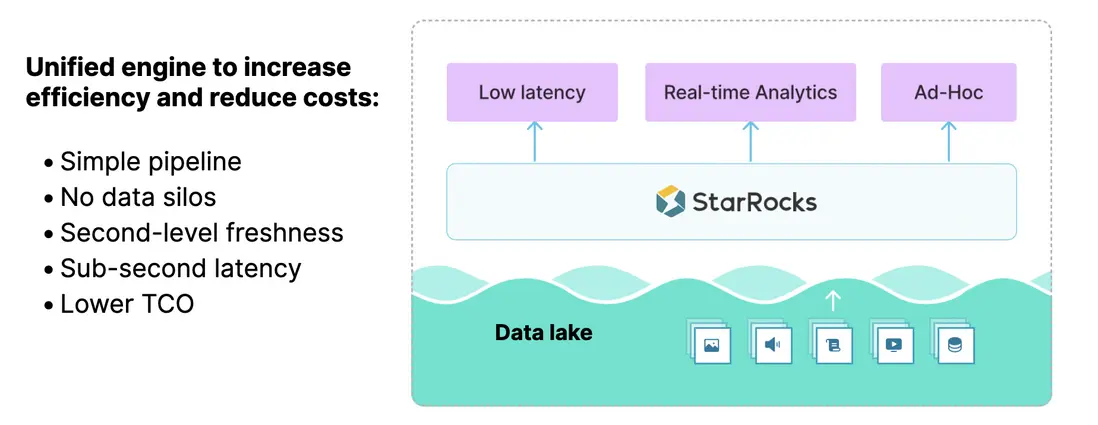
- 架構簡化:技術棧與數據管道得到顯著簡化,避免了“數據煙囱”的割裂問題。
- 性能提升:依託 StarRocks 強大的引擎能力,能夠為業務提供秒級的數據新鮮度和亞秒級的查詢性能。
- 成本優化:整體架構的構建成本與業務交付效率,均較以往基於煙囱式架構有顯著改善。
當然,實現這一理想並非易事。StarRocks 之所以能夠承擔統一引擎的角色,源於其在多個關鍵能力上的持續突破,包括實時分析、查詢性能以及湖倉分析。
實時洞察與成本效益並行
先來看實時分析。這裏需要特別強調的是——必須具備高性價比的實時分析能力。StarRocks 在 2.0 版本基於存算一體架構,已經具備了強大的實時分析性能,並在社區中積累了大量應用案例。然而,如果進一步要求在保證實時性的同時兼顧性價比,則需要在架構上做出更多優化。
因此,在 3.0 版本中,StarRocks 完成了從存算一體到存算分離的架構升級。當前,基於存算分離架構的用户規模正在快速增長。
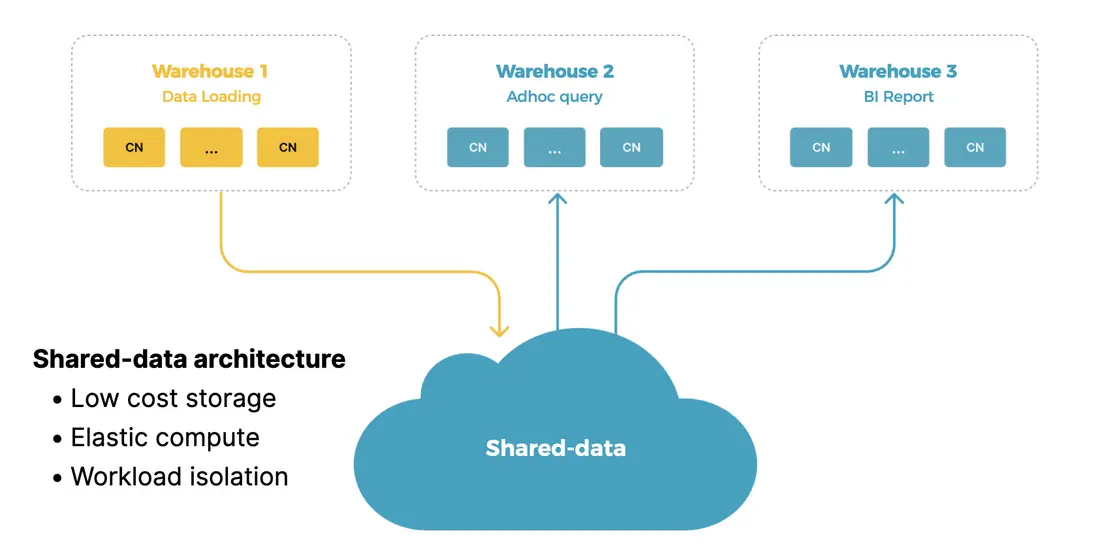
存算分離的優勢主要體現在三個方面(如下圖所示):
- 更低的存儲成本:通過對象存儲,顯著降低整體存儲開銷。
- 計算彈性:計算與存儲解耦,可根據業務需求實現彈性擴展。
- 多倉隔離:數據共享的同時,不同 workload 可通過 Multi-warehouse 能力實現獨立隔離。
在存算一體架構下,StarRocks 已經在實時分析方面積累了大量經驗。但在存算分離架構下,如何同時保證實時分析能力與低成本,這在業界也是一個很大的挑戰。
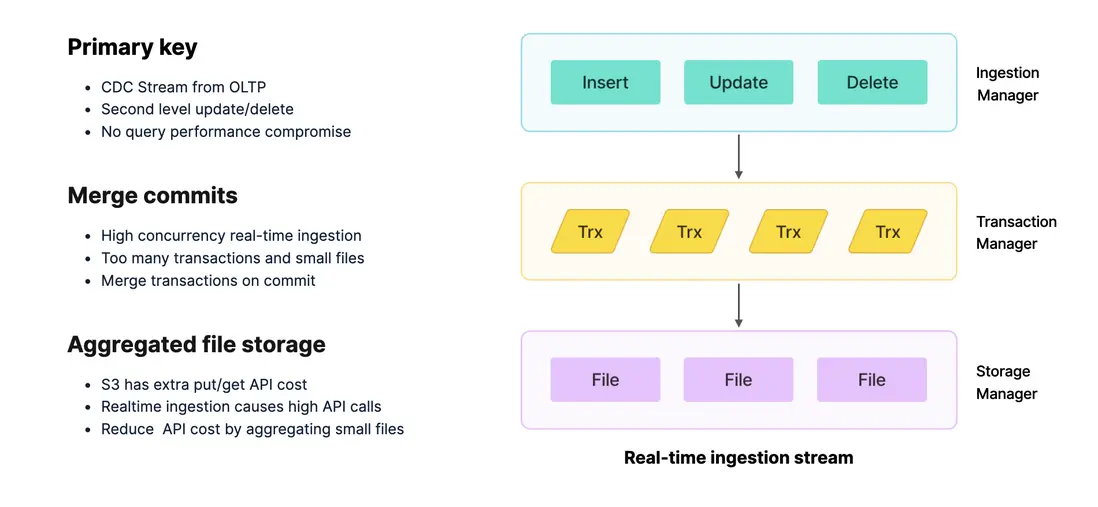
在存算分離架構下,StarRocks 針對實時分析的數據寫入鏈路進行了深入優化。從最上層的 Pipeline 集成(支持 Insert、Update、Delete),到請求接收、事務管理,再到底層存儲的全過程,每一環節都面臨實時場景的挑戰。
- 實時分析的主要數據流來自上游 OLTP 數據庫,涉及 Insert、Update、Delete 操作。StarRocks 在內核層面通過組件化模型,能夠直接支持 CDC 流式數據同步,將 OLTP 的變更無縫導入。
- 實時場景往往伴隨高併發寫入,這會給引擎帶來巨大壓力。為此,StarRocks 採用 Merge Commits 機制,在事務提交時對小事務進行合併,從而降低系統開銷並提升整體寫入性能。
- 在存算分離架構中,數據存儲依賴 S3 對象存儲。對象存儲在頻繁讀寫時會產生額外的 API 調用成本。StarRocks 的優化策略是將大量小的事務文件、日誌文件與數據文件合併後再提交,從而減少 API 調用次數,顯著降低存儲成本。
自 3.0 版本發佈以來,已有大量用户從存算一體升級至存算分離架構,並在成本上獲得了顯著優化。隨着上述機制的持續演進,實時分析的成本優勢將進一步擴大。
極速查詢,持續突破
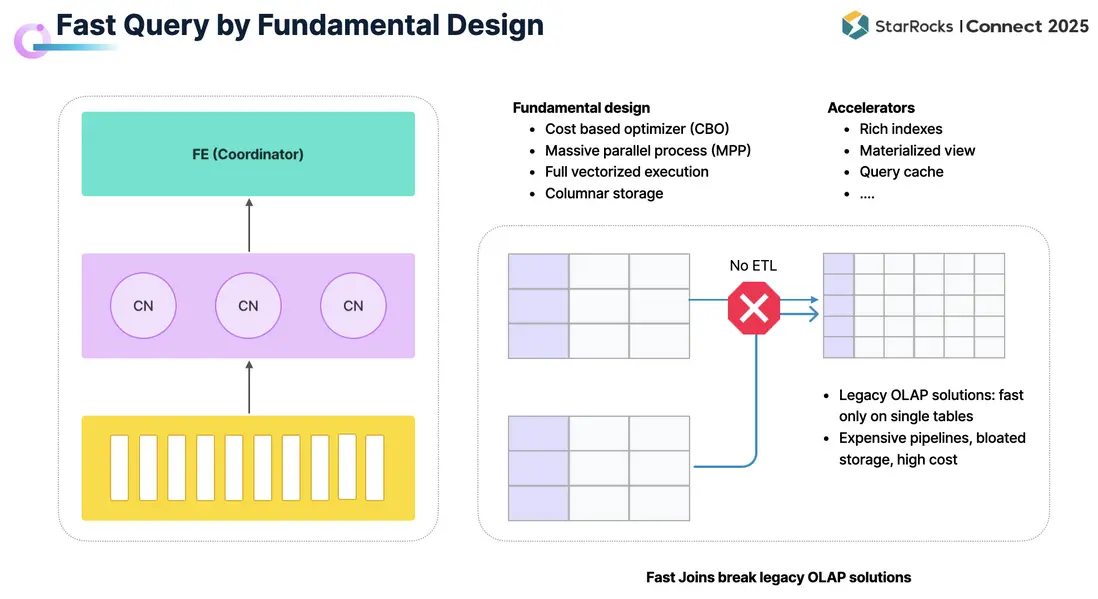
在眾多應用場景中,查詢延時往往是最核心的指標之一。StarRocks 之所以能夠在查詢性能上保持優勢,主要體現在以下三個方面:
- StarRocks 從設計之初便面向高速查詢進行優化。自底層到執行層,形成了完整的性能支撐鏈路:包括基於 CBO 的優化器、分佈式 MPP 架構、全面向量化的執行引擎,以及高效的列式存儲。
在此基礎上,StarRocks 提供了豐富的加速機制:從 Bloom Filter、Bitmap 等索引,到最新引入的文本索引與向量索引,以適配不同場景需求;透明物化視圖可在通用場景下顯著提升查詢效率;再加上 Query Cache 等技術手段,使得 StarRocks 能夠持續保障低延時的查詢性能。
值得一提的是,StarRocks 天生對多表 Join 進行了優化,能夠在複雜查詢中保持高效。這大幅降低了數據工程師的建模負擔,不再需要通過構建大寬表來規避 Join,避免了由此帶來的數據膨脹與存儲成本增加。
- 僅有堅實的設計基礎還不夠,StarRocks 在過去幾年中持續進行性能優化,確保查詢能力不斷提升。
- 在優化器層面:通過 Join Reorder、表達式下推,以及針對數據熱點和分佈不均情況的優化策略,顯著提升了查詢效率。
- 在執行層面:通過改進 Shuffle 策略、引入 Runtime Filter 等機制,使執行調度更加高效,從而進一步增強執行性能。
這些優化累計已達數百項,使得 StarRocks 在查詢性能上持續進步。以 TPC-DS 1TB 測試為例,從 2.0 到 3.0,再到即將發佈的 4.0,StarRocks 的性能指標一直保持穩定提升。
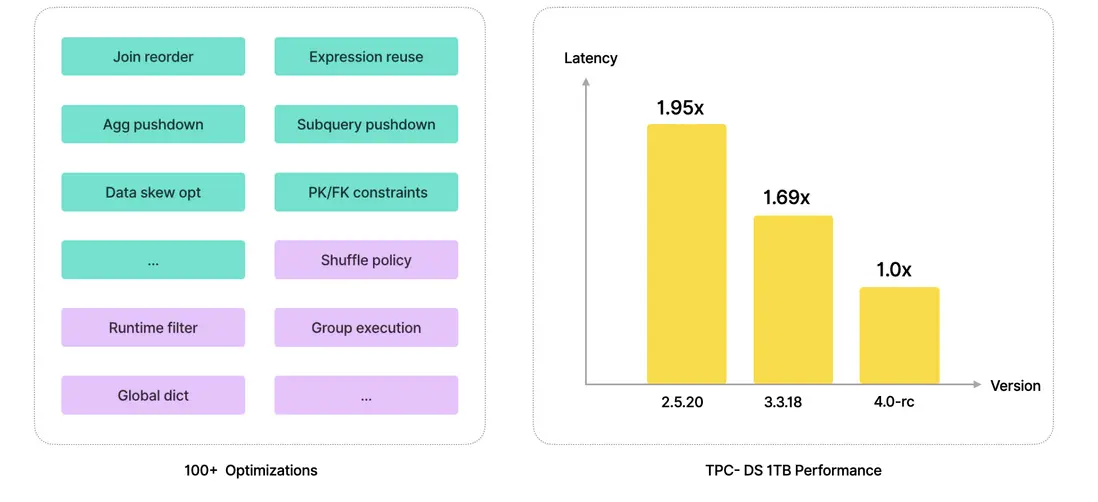
- 有了堅實的基礎與持續迭代,數據庫產品仍不能僅停留在 Benchmark 的成績上,更關鍵的是要在真實業務場景中同樣展現穩定而優異的表現。
在真實場景下,StarRocks 面臨的挑戰與 Benchmark 存在顯著差異:
- 數據類型:Benchmark 多為結構化數據,而在實際業務中,半結構化數據更加普遍。
- 數據狀態:Benchmark 通常基於靜態數據集,而真實場景中的數據則在持續變化。
- 系統環境:Benchmark 默認節點穩定,而在生產環境中,節點升降級、重啓、甚至 crash 都是常態。
正是面向這些差異化挑戰,StarRocks 才能在真實業務鏈路中(從數據集成到數據分析)持續保證穩定的查詢性能。
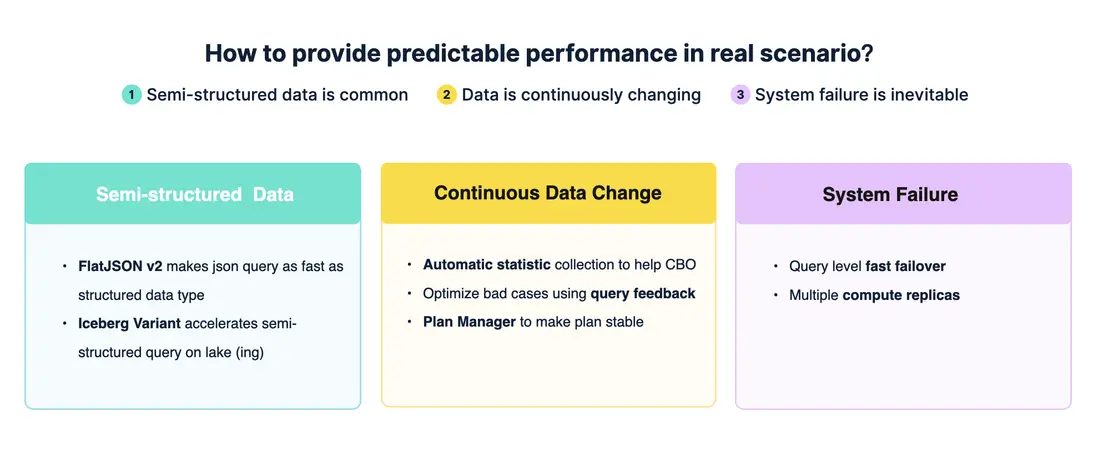
那麼,StarRocks 如何在真實場景下同樣保持高效與穩定的查詢性能呢?主要體現在以下幾個方面:
- 半結構化數據支持,StarRocks 原生引擎已支持 FlatJSON 功能,可以自動將 FlatJSON 數據“斬平”,在半結構化數據的分析性能上實現超過 10 倍的提升。該能力自 3.0 版本引入後,在 4.0 中已迭代至第二代(V2),性能進一步優化。對於存儲在數據湖中的數據,當前 Iceberg 社區已在 Parquet 上提出 Variant 標準來支持半結構化數據,StarRocks 也在持續增強對 Variant 查詢的能力。
- 在實際場景中,數據往往處於不斷變化之中。為此,StarRocks 提供多層機制:
- 自動收集數據變化後的最新統計信息,以幫助 CBO 做出更優的執行決策。但考慮到實時收集的成本,仍可能存在部分性能不佳的查詢情況。
- Query Feedback:通過查詢反饋機制,在執行完成後分析計劃是否合理,如不合理則進行調整,逐步優化查詢效果。
- Plan Manager:通過計劃管理器將查詢與執行計劃綁定,即使在數據變化、節點升降級等情況下,也能保持查詢計劃穩定,從而保障性能的一致性。
- 系統故障:在真實生產環境中,版本升級、節點重啓、彈性擴容等情況時常發生。針對這些挑戰,StarRocks 藉助存算分離架構,配合快速 Failover 機制,一旦檢測到節點故障,即可迅速完成任務調度,由其他節點接管,最大限度地減少對業務的影響。
此外,StarRocks 還支持多計算副本機制。當某一計算副本出現故障時,其他副本能夠立即接管服務,從而進一步提升系統在故障場景下的穩定性與可靠性。
Lakehouse 架構下的極速價值交付
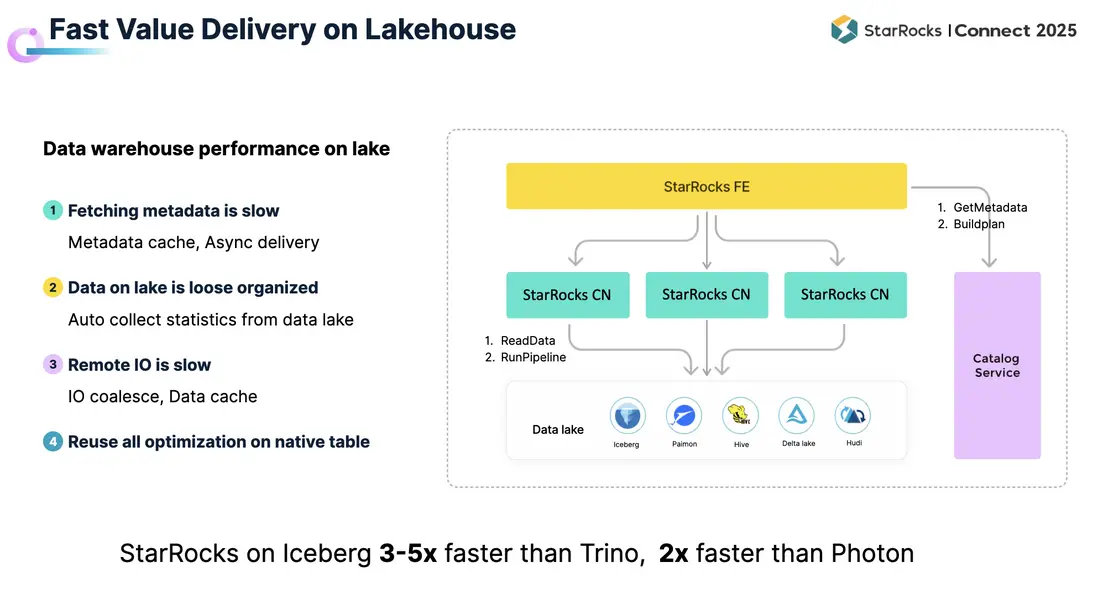
前文已從架構基礎、持續迭代以及真實場景等角度闡述了 StarRocks 在高性能查詢上的優化。結合 Lakehouse 的發展趨勢,越來越多的數據被統一存儲在數據湖中。此時,新的問題出現了:StarRocks 能否將其強大的分析引擎能力應用於湖上數據? 答案是肯定的。過去幾年中,StarRocks 持續優化湖上數據的分析性能,使用户能夠在數據湖中直接完成分析並快速交付價值。
然而,與本地表相比,數據湖場景也帶來了一些獨特挑戰:
- 元數據存儲在遠端,訪問延時較高。
- 數據組織鬆散:大量入湖數據缺乏良好組織,數據質量參差不齊,統計信息不足。
- I/O 鏈路較長:從湖中讀取數據的過程遠比本地複雜,性能壓力顯著。
針對這些問題,StarRocks 採取了多方面的優化措施:
- 在元數據訪問方面,引入緩存機制以加速獲取,同時在獲取元數據的過程中即可啓動調度,將任務下發至計算節點,從而減輕調度節點壓力並加快整體執行速度。
- 在數據組織與統計信息方面,StarRocks 支持在數據湖上自動收集統計信息,供 CBO 參考,從而生成更優的執行計劃。
- 在 I/O 層面,StarRocks 通過相鄰 I/O 合併機制以及 Data Cache,大幅減少 I/O 次數和延時。藉助這些優化,StarRocks 在數據湖上的分析性能已接近 Native Table 的水平。
與其他湖倉引擎相比,StarRocks 在 Iceberg 上的查詢性能約為 Trino 的 3–5 倍,是 Photon 的兩倍以上,能夠滿足絕大多數數據湖分析場景的需求。
然而,數據湖不僅涉及查詢,更是未來的整體趨勢。當前,許多大型企業已在積極推進數據湖建設,但對於中型和小型企業而言,構建數據湖仍存在顯著挑戰:需要搭建完整的 Pipeline,還要承擔數據寫入與治理的複雜工作,其門檻遠高於使用 StarRocks Native Table。
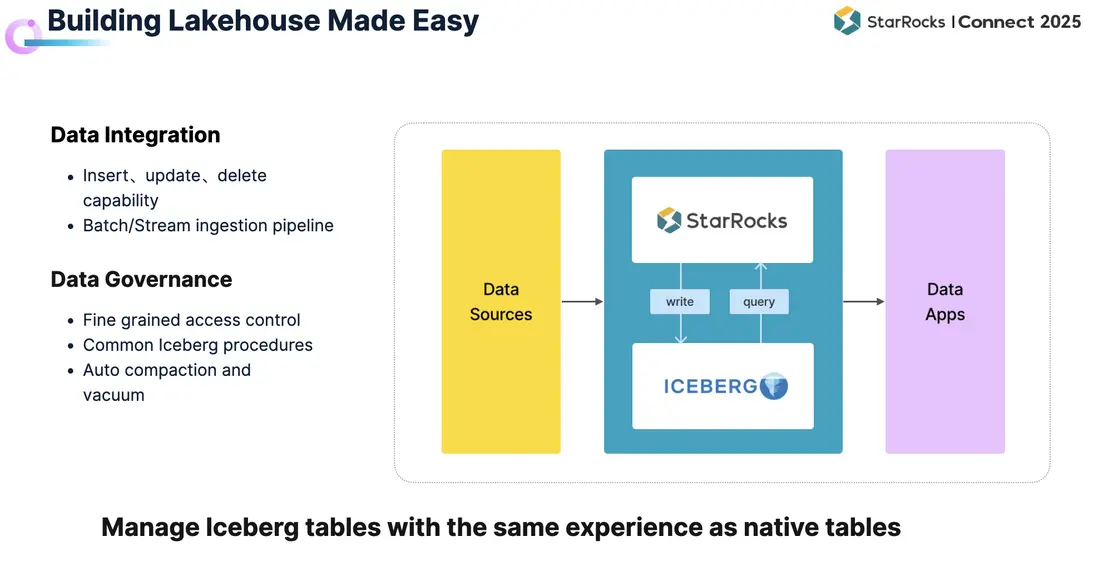
為此,StarRocks 正在持續提升數據湖構建能力,主要體現在以下兩個方面:
- 數據集成
- 支持在數據湖上直接對 Iceberg Format 執行 Insert、Update、Delete 操作。
- 打通批流一體的寫入鏈路,支持從對象存儲和 Kafka 流直接導入數據至 Iceberg,大幅簡化數據接入流程。
- 數據治理
- 提供統一的訪問控制,規範誰可以訪問數據湖中的數據及其方式。
- 針對 Iceberg 數據提供一系列治理能力,以提升數據質量和查詢效率。
- 在治理的基礎上進一步實現自動化,讓用户無需手動維護,便可像使用 StarRocks Native Table 一樣,將數據直接導入並服務於線上業務。
Pinterest: 基於 StarRocks 存算分離的實時洞察
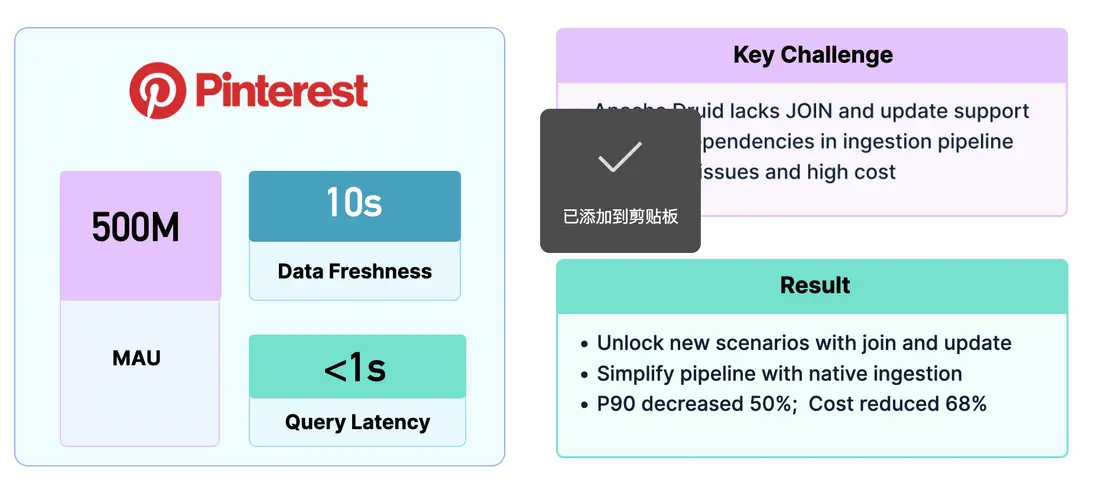
北美興趣社交的領軍企業 Pinterest,其廣告平台面臨極高的實時分析挑戰:月活躍用户超過 5 億,對數據新鮮度要求需在 10 秒以內,查詢延時則需小於 1 秒。此前,Pinterest 使用 Druid,但由於在多表 Join 與 Update 支持上的限制,不得不依賴複雜的 Pipeline 構建大寬表,既增加了開發複雜度,也帶來了穩定性和高成本的問題。
升級至 StarRocks 後,Pinterest 的廣告平台效率顯著提升:藉助實時更新與多表 Join 能力,數據可直接導入並分析,無需複雜的 Pipeline。實際效果顯示,P90 延時下降 50%,計算與存儲成本降低 68%,整體運行成本僅為原來的三分之一。
Fanatics: Iceberg x StarRocks
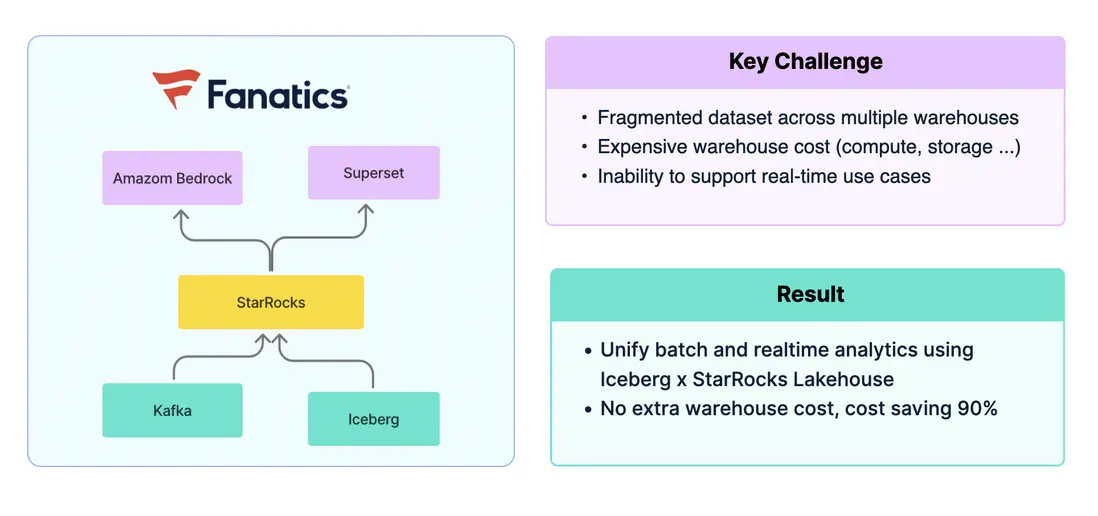
北美知名體育電商平台 Fanatics,其數據全部統一存儲在 Iceberg 中。但在分析時,需要將數據導入 Redshift、Flink、Druid 等不同系統以支撐各類場景。這種方式不僅造成數據孤島,難以關聯,還帶來了高昂的計算與存儲成本,且難以滿足實時分析需求。
引入 StarRocks 後,Fanatics 構建了統一的湖倉架構:Iceberg 數據在離線場景中可由 StarRocks 直接查詢,實時數據則通過 Kafka 導入 StarRocks 即刻分析,並能在同一引擎中實現跨場景關聯,支持 BI 與 AI 應用。最終,Fanatics 成功統一了公司數據平台的技術棧,整體成本下降 90%。
淘寶閃購: Paimon x StarRocks
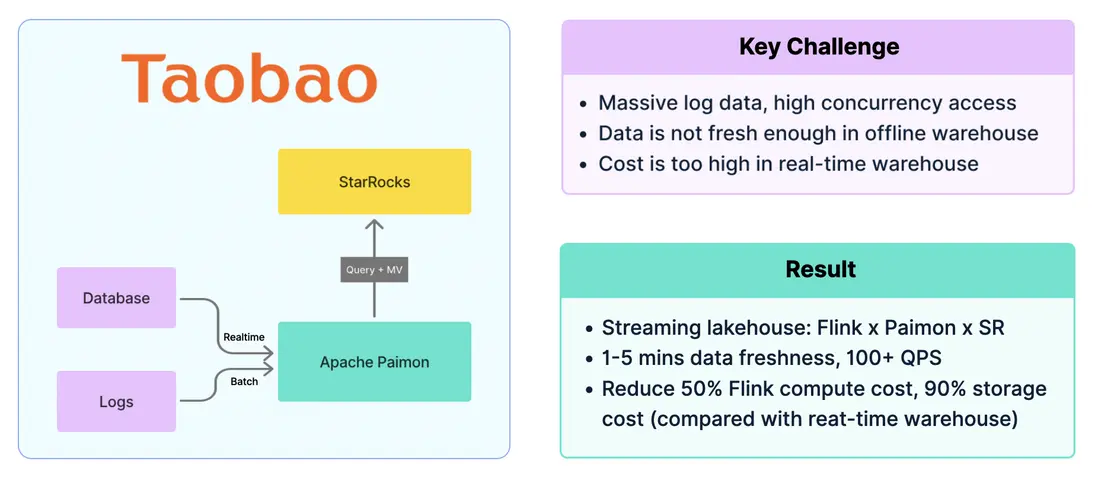
在淘寶閃購的海量交易場景中,每日上億訂單產生龐大的日誌數據,對數據系統提出了極高挑戰。離線數倉雖然成本低,但只能提供天級或小時級的新鮮度,無法滿足業務需求;實時數倉則因高昂的存儲與計算成本難以大規模推廣。
淘寶閃購最終採用 Flink + Paimon + StarRocks 的實時湖倉架構。數據由 Flink 實時處理後寫入 Apache Paimon,再通過 StarRocks 提供實時分析。該方案實現了 1–5 分鐘 的數據新鮮度,支撐上百級別的高併發複雜查詢。與此同時,Flink 計算成本降低 50%,存儲由本地切換至對象存儲後,整體成本下降 90%,系統性能與性價比得到顯著提升。
淘寶閃購實時分析黑科技:StarRocks + Paimon撐起秋天第一波奶茶自由
連接 AI Agent(未來)
面向未來,StarRocks 正在積極探索如何更好地服務 AI Agent,將數據分析能力與 Agent 場景高效銜接。隨着各行各業不斷加速 AI 賦能,StarRocks 立足於數據系統的核心優勢,持續拓展並構建面向 AI 的新能力,以滿足用户在智能化轉型中的迫切需求。
在此背景下,我們做了一個面向數據建模優化的 Demo(因整體視頻時長限制,此處不單獨展示,完整演示可在下方視頻回放中查看)。社區用户在建模時經常面臨分區、分桶與排序等關鍵抉擇;一旦建模合理,後續分析效率將顯著提升,但這通常需要對 StarRocks 架構有較深入的理解。Demo 的使用方式是:將若干建表語句與查詢語句輸入,一鍵觸發優化;短時間後輸出由 AI 推薦的建表語句。這些推薦在多個真實業務場景中已驗證具有實用價值。
需要説明的是,大模型的原始能力雖強,但直接 one-shot 輸入(如直接給出 DDL、查詢與 Profile)往往會得到準確率不高、甚至夾雜錯誤的信息。因此,在面向真實業務時,不能僅停留在 Benchmark 或“看上去有道理”的答案層面,而必須直面上述不確定性,確保最終結果可用、可控。
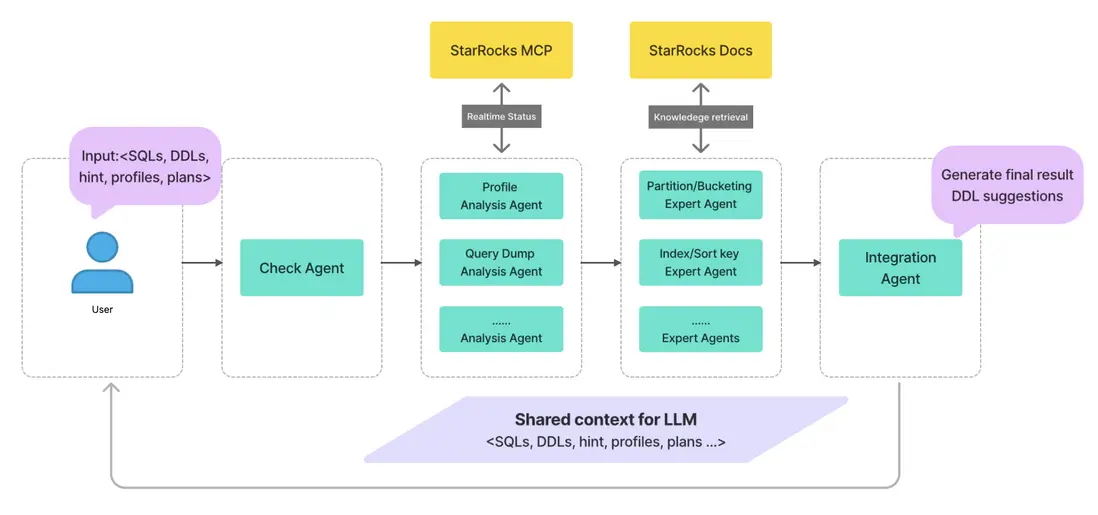
為解決上述問題,把建表優化與 Profile 分析拆解為可控的細粒度任務,並通過 Multi-Agent 協作完成整體鏈路,實現建表優化。
具體流程如下:
- 用户可直接從 StarRocks 系統拉取,或手動輸入所需上下文信息,包括建表語句、查詢語句以及(可選的)Profile。
- 首先對上下文進行有效性與一致性校驗;若輸入本身存在錯誤或矛盾,及時攔截並返回問題點,避免“錯題入場”。
- 在分析階段,按模塊將任務拆分給多個 Agent(對應不同分析視角),逐一完成各自分析並輸出階段性結論,這些結論會沉澱為後續步驟的共享上下文。
- 基於前述分析結論,由負責分區、分桶、排序 Key 等方向的專家型 Agent 給出針對性的建模優化建議。
- 匯聚各專家 Agent 的建議,形成可執行的建表示例與配置要點;在此基礎上,按建議完成建表即可。
除整條 Multi-Agent 鏈路外,依託 StarRocks 的 MCP Server,可與 Agent 進行實時的上下文交互。同時,Agent 需要獲取 StarRocks 最新文檔作為參考,以輔助其決策與分析。
基於上述實踐,可歸納出對底層數據分析系統的共性要求:
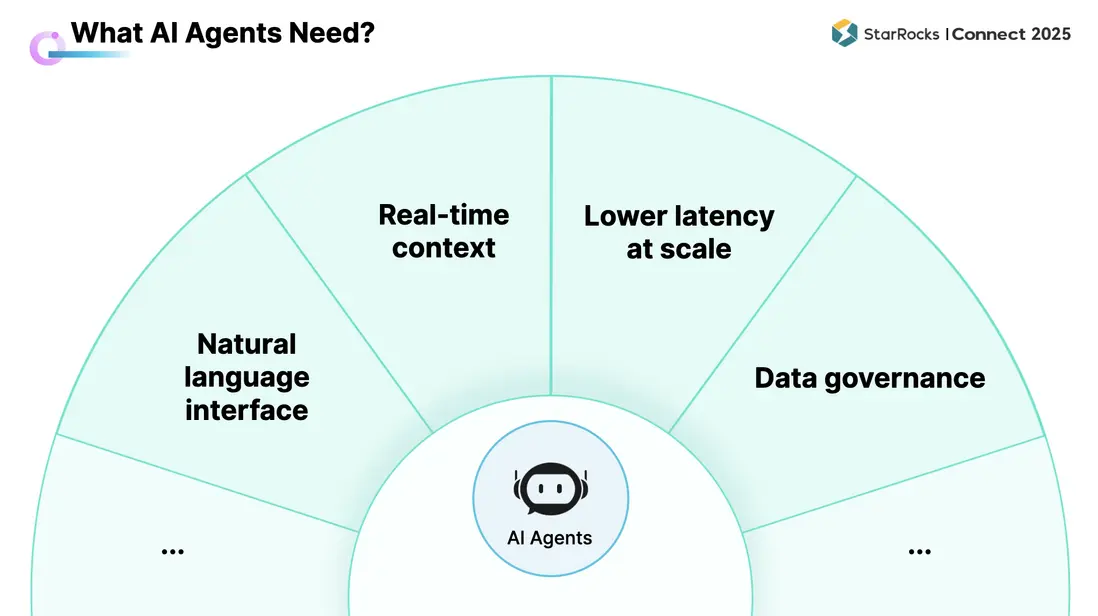
- 自然語言接口支持,需要提供可用的自然語言入口:可通過 MCP Server 暴露接口,或自建語義層(如 Text-to-SQL)以支持文本查詢。
- Agent 的結論高度依賴實時信息,系統需可用以獲取實時運行狀態、實時文檔等上下文,並將其納入推理與決策流程。
-
多個 Agent 往往以多輪、密集方式與系統交互,該模式不同於人工分析:
需要足夠低的查詢延時以支撐多輪對話與快速迭代;
需要足夠高的併發能力以容納多 Agent 同時訪問與協同。
- 數據質量與治理能力,若底層數據質量不足,Agent 的最終表現將受限。因此,數據治理是對數據系統的核心要求之一。
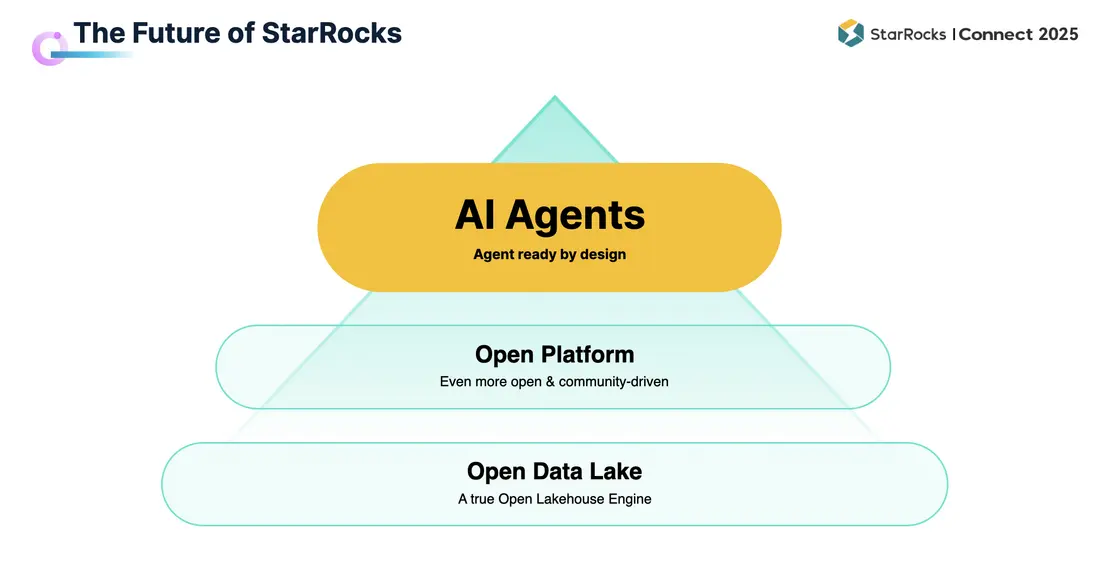
綜合前文所述,StarRocks 在許多方面已具備明顯優勢,並在其他環節持續補充與完善。未來,我們希望將 StarRocks 打造成真正 “AI Agent Ready” 的系統。
從發展思路來看(如上圖所示),最底層是 StarRocks 已經具備的 Lakehouse 基礎能力,能夠提供實時、高併發的數據分析;最頂層則是 AI Agent,代表未來 “AI is everything” 的世界,一切業務場景都將與 Agent 交互。如何將兩者結合,是留給我們的重大挑戰。
解決路徑在於中間的 Open Platform 層。核心思路是保持足夠的開放性:開放社區、開源系統,並與更廣泛的開放生態對接,覆蓋包括 BI、AI 在內的多樣化數據分析場景。通過這一平台化的開放連接,StarRocks 將與生態夥伴一道,為 AI Agent 構建更完善的數據分析環境。
One More Thing
自 2023 年起,StarRocks 存算分離架構已在社區廣泛應用,數百位用户積極投入實踐。基於開源 StarRocks,許多廠商也構建了企業級功能。例如, StarRocks 企業級 Multi-warehouse 能力,不少社區用户反饋,這一功能將顯著簡化和加速不同場景的構建。
因此,我們正式宣佈:StarOS Multi-warehouse 企業級能力將於 2025 年底前全面開源。我們希望通過開源技術,幫助更多企業釋放數據價值,創造更大的業務成果。
https://www.bilibili.com/video/BV1hhnFz9Ey7/?aid=115246756792...
PPT 獲取鏈接:https://forum.mirrorship.cn/t/topic/20074








