









AI Compass前沿速覽:Cursor 2.0、Firefly Image5、Agent HQ 、LongCat-Video、Kimi-k2 Thinking
AI-Compass 致力於構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本項目對您有所幫助,請為我們點亮一顆星!🌟
1.每週大新聞
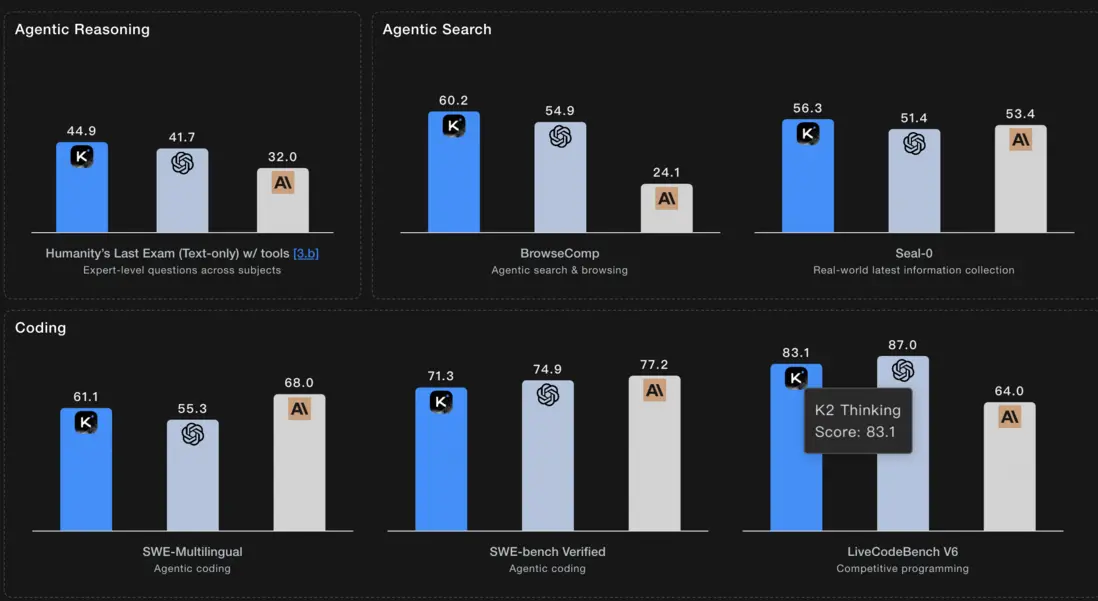
Kimi-k2 Thinking
Kimi K2 Thinking是月之暗面(Moonshot AI)推出的最先進的開放推理模型,是Kimi K2系列的延伸,專注於智能體(agentic)和長週期推理能力。該模型旨在通過其獨特的“思考”機制,在推理、編碼和智能體工具基準測試中超越現有模型,包括一些專有和開源的競爭對手,成為領先的開源AI系統。
核心功能
- 持久性分步思考與推理: 能夠進行持續的、逐步的思考,處理複雜的推理工作流程,跨越數百個步驟。
- 動態工具調用: 支持動態調用外部工具,以完成更廣泛的任務和獲取實時信息。
- 多步決策與行動: 具備規劃、搜索、執行和綜合證據的端到端自主能力,不僅僅是回答問題,更能主動執行任務。
- 長上下文處理: 支持256k token的超長上下文窗口,確保在多輪交互和複雜場景下維持穩定的工具使用。
技術原理
- 萬億參數MoE架構: 基於萬億參數的混合專家(Mixture-of-Experts, MoE)架構構建,每次前向傳播激活320億參數。
- 256k上下文窗口: 提供行業領先的256k token上下文支持,有效處理大規模文本信息。
- INT4量化: 採用原生INT4量化技術,優化模型效率。
- 開放透明: 作為開源模型,提供代碼和推理過程的可檢查性,便於學術研究和企業定製。
- 分層模型提供: 提供Kimi-K2-Base(基礎模型,用於微調和定製解決方案)和Kimi-K2-Instruct(經過後訓練的模型,適用於通用聊天和智能體體驗)兩種版本。
應用場景
- 複雜問題解決: 適用於需要多步推理、邏輯判斷和長期規劃的複雜任務。
- 智能體系統開發: 作為基礎模型,可用於構建能夠自主操作、執行復雜工作流的AI智能體。
- 領域特定定製: 學術研究者和企業開發者可以對其進行微調,以適應特定領域的需求和用例。
- 內容生成與分析: 例如,自動進行“每日新聞報告”工作流,包括調用工具搜索信息、分析內容並生成結構化輸出。
- 編程輔助與代碼生成: 在編碼和相關邏輯任務中表現出色,可用於提升開發效率。
- 高級對話與交互: 適用於需要深度理解和持久化對話狀態的智能聊天機器人和虛擬助手。
- https://moonshotai.github.io/Kimi-K2/thinking.html
零一萬物聯合開源中國推出OAK平台
零一萬物聯合開源中國推出了OAK(Open AgentKit)平台,旨在成為Agent世界的“生態適配器”,目標是打造OpenAI AgentKit的開源替代方案。該平台是一個專為開發者設計的一站式開源解決方案,通過結合開源生態力量,加速AI Agent的開發與落地,支持對接多種開源大模型。
核心功能
- Agent Builder 可視化編排與代碼生成: 提供可視化界面,支持Agent的編排設計,並能最終生成代碼。
- 評估與優化工具: 集成強大的工具,支持數據集管理、鏈路追蹤評分和自動化提示詞調優,以系統性提升Agent性能。
- 嵌入式組件: 提供類似ChatKit的嵌入式組件,極大簡化在應用中集成對話式Agent界面的開發成本。
- OAK Framework (LangCrew): 全棧多Agent開發框架,賦能高效架構設計。
- OAK Builder: Agent構建器,聯合開源中國與社區力量共建。
- OAK Runtime: 提供穩定可靠的Agent運行時環境。
- OAK Studio: 可視化工作台,支持Agent的部署、評測、追蹤與持續優化。
技術原理
OAK平台是零一萬物團隊博採眾長,融合業界主流框架優勢後構建的,專為專業級Agent生產設計。它不僅集成了多個框架的核心優勢,還具備更簡單易用、功能豐富的特點。該平台以“做OpenAI AgentKit的開源平替”為目標,支持對接多種開源大模型,並已作為零一萬物萬智平台中多個“超級員工”Agent的重要底層支撐。其核心在於將研發過程中搭建的Agent開發框架進行開源,通過開放協作模式促進技術普惠。
應用場景
- AI Agent開發: 賦能廣大開發者進行高效的AI Agent開發,降低開發門檻。
- 企業級AI解決方案: 作為零一萬物萬智平台“超級員工”Agent的底層支撐,為企業提供智能自動化解決方案。
- 敏感行業應用: 支持私有化部署,確保數據“不出域”,有助於金融、醫療、政務、前沿科研等領域突破AI落地合規瓶頸,實現AI應用在全域可控環境下的部署。
- 開源生態共建: 鼓勵社區開發者共同參與,為開源AI Agent生態貢獻力量。
MiniMax Music 2.0:讓音樂創作屬於每一個人
MiniMax Music 2.0 是由中國人工智能公司MiniMax推出的一款先進的AI音樂創作模型,旨在利用前沿人工智能技術革新音樂製作流程,為創作者提供強大的工具。該模型是中國AI原生行業快速發展中的一個重要成果。
核心功能
- 高精度人聲情感還原:能夠精準捕捉並再現人聲演唱中的細膩情緒表達。
- 器樂動態張力呈現:有效還原和生成器樂演奏的動態細節和表現力。
- 多樣化唱法與風格支持:支持流行、爵士、搖滾等多種音樂唱法和風格的切換與融合。
- 綜合音樂內容生成:提供從人聲到器樂的全面音樂創作與編排能力。
技術原理
Music 2.0 的核心技術基於先進的深度學習架構,可能包括:
- 生成式對抗網絡 (GANs) 或變分自編碼器 (VAEs):用於生成高質量、高真實感的音頻波形和音樂結構。
- Transformer 模型:利用其在序列建模方面的優勢,處理音樂的時序信息和長距離依賴,確保音樂的連貫性和邏輯性。
- 多模態特徵學習:通過分析大量音樂數據,學習並解耦音高、音色、節奏、情感等多種音樂元素特徵。
- 數字信號處理 (DSP):結合專業的音頻處理技術,對AI生成的原始音頻進行優化,提升音質和聽感。
應用場景
- 專業音樂創作與製作:輔助音樂人、作曲家進行靈感探索、小樣製作及編曲。
- 影視遊戲配樂:快速生成符合場景氛圍的背景音樂和音效。
- 數字內容創作:為短視頻、播客、直播等數字媒體提供定製化音樂內容。
- 廣告與營銷:創作與品牌形象和營銷活動主題相符的專屬音樂。
- 音樂教育與互動娛樂:作為工具輔助音樂學習,或在互動娛樂產品中生成個性化音樂體驗。
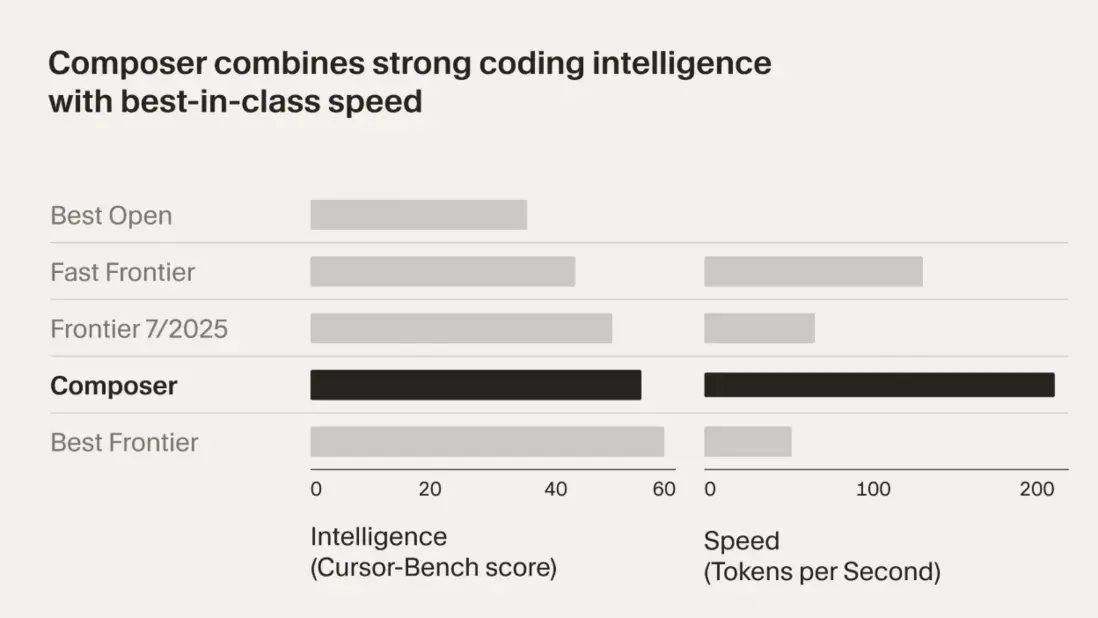
Cursor 2.0來了!多agent並行
Cursor 2.0 是一個集成了人工智能的軟件開發平台,其核心更新在於引入了多智能體並行處理能力,旨在革新AI輔助編程範式。通過允許多個AI代理協同工作,並行執行任務,Cursor 2.0 大幅提升了代碼開發效率和複雜問題的解決能力,將AI編碼帶入了一個更具“智能體化”和“自動化”的時代。
核心功能
- 多智能體並行執行: 能夠同時運行多達八個AI代理,顯著加速代碼生成、調試和項目開發流程。
- 交互式AI編碼界面: 提供直觀的用户界面,支持用户與並行運行的AI代理進行實時交互和協作。
- Composer代碼模型: 推出新的Composer模型,專門優化AI軟件開發,提高代碼質量和開發效率。
- Worktrees/本地並行代理: 支持通過內部分支實現並行代理執行,管理複雜的代碼開發任務。
- Agentic AI編碼: 轉變傳統的AI編碼方式,使AI代理能夠更自主地進行決策和行動,處理更復雜的編程邏輯。
技術原理
Cursor 2.0 的多智能體並行能力主要依賴於分佈式代理架構。其核心技術可能包括:
- 智能體編排與調度: 實現對多個AI代理的任務分配、協作和結果整合,確保並行任務的有效管理。
- 深度學習模型(如Composer): 基礎是先進的編碼專用大型語言模型(LLMs),這些模型經過優化,能理解代碼上下文、生成高質量代碼和執行重構等複雜任務。
- 並行計算框架: 利用多線程或多進程技術,甚至分佈式計算,來支持多個AI代理同時執行計算密集型任務。
- 代碼版本控制集成: 與Git等版本控制系統深度集成,通過“Worktrees”或內部版本分支來管理並行代理所產生的代碼變更,確保代碼的獨立開發和最終合併。
- 實時反饋與迭代循環: 智能體在執行任務過程中能夠獲取實時反饋,並據此調整策略,形成高效的迭代開發循環。
應用場景
- 大型項目開發: 協調多個智能體同時處理項目中的不同模塊或功能,加速整體開發進程。
- 複雜系統調試與測試: 讓智能體並行查找代碼中的錯誤、生成測試用例,並執行自動化測試。
- 代碼重構與優化: 多個智能體可以從不同角度分析現有代碼庫,提出並執行優化方案,提升代碼性能和可維護性。
- 跨語言/框架開發: 智能體可專門負責不同編程語言或技術棧的任務,實現無縫集成。
- 初創企業與敏捷開發團隊: 通過AI智能體輔助快速原型開發、迭代和功能實現,提高開發效率,縮短產品上市時間。
Emu3.5 – 智源研究院推出的多模態世界大模型
Emu3.5(悟界·Emu3.5)是北京智源人工智能研究院發佈的一款多模態世界大模型。該模型通過在超過10萬億多模態Token(主要來源於互聯網視頻,總時長約790年)上進行端到端預訓練,旨在學習和內化現實物理世界的動態規律,從而實現對世界動態的理解和預測,被譽為“世界大模型”的開創者。
核心功能
Emu3.5具備強大的跨模態泛化與具身操作能力,主要體現在:
- 統一多模態生成與編輯:能夠根據複雜文本描述生成高細節圖像,並支持語義級的智能圖像編輯,無需手動選區。
- 時空動態推理:可對視頻幀序列進行連貫編輯,例如實現對視頻中角色動作的精準控制。
- 世界建模與探索:能夠像智能體(Agent)一樣理解長時序、空間一致的序列,模擬在虛擬環境中的探索和操作,並生成連貫的視覺序列。
- 具身操作任務分解:將複雜的機器人任務(如倒水、摺疊衣物)分解為帶有語言指令和關鍵幀圖像的子任務。
- 視覺指導與長時程創作:能夠提供具有連貫性和指導意義的視覺內容,生成分步教學指南或從草圖到成品的全視覺流程。
技術原理
Emu3.5的核心突破在於其獨特的統一架構和創新技術:
- 統一的NSP(Next-State Prediction)框架:模型將文本、圖像、動作指令等多模態輸入視為連續的狀態序列,通過預測“下一個狀態”來實現端到端的智能推理,超越了傳統多模態模型僅做特徵對齊的方式,實現了真正的跨模態自由切換與協同推理。
- 原生多模態架構:不同於以LLM為基礎的多模塊模式,Emu3.5直接對多模態數據進行統一編碼和處理,從底層具備世界建模能力。
- 離散擴散適配(DiDA)技術:為解決自迴歸模型在圖像生成上的速度瓶頸,DiDA技術將逐個Token的生成方式轉變為並行的雙向預測,在幾乎不犧牲性能的前提下,將每張圖像的推理速度提升近20倍。
- 海量視頻數據預訓練:通過在龐大的視頻數據上進行大規模訓練,模型能夠內化現實世界的運行規律,從而進行更深層次的模擬和推理。
- 多模態Scaling範式:首次揭示了不同於語言預訓練和推理的“多模態Scaling範式”,奠定了其作為“世界大模型”基座的地位。
應用場景
Emu3.5的強大能力使其在多個領域具有廣闊的應用前景:
- 機器人控制與具身智能:為訓練更通用的具身智能體提供基礎,實現機器人在物理世界的感知-決策-執行閉環。
- 虛擬助手:提升虛擬助手的理解能力和互動體驗,使其能處理更復雜的現實世界任務。
- 智能設計與創意產業:提供高精度、可控的圖像編輯和圖文並茂的視覺故事生成,賦能設計師和創作者。
- 教育領域:用於智能課件生成等,提供更生動、直觀的學習內容。
- 醫療領域:應用於多模態病歷分析,輔助醫生進行診斷和治療。
- 娛樂領域:作為“AI導演”,輔助電影、遊戲等內容的創作與生成,實現更逼真的視頻和場景。
- 科學研究:智源研究院宣佈將開源Emu3.5的部分能力,以支持社區的進一步研究和開發,推動多模態生態發展。
豆包視頻生成模型1.0 pro fast
核心功能
-
Seedance 1.0 Pro:
- 文本到視頻生成 (Text-to-Video): 根據文字描述自動生成視頻內容。
- 圖像到視頻生成 (Image-to-Video): 將靜態圖片轉換為動態視頻,並支持高級電影級運鏡。
- 高清視頻輸出: 能夠生成高質量的1080P視頻,甚至支持4K(高級版)。
- 快速生成: 提供超快的“Seedance Lite”引擎,實現秒級生成多鏡頭短片。
- 多模態輸入: 支持文字和圖像作為輸入,進行視頻內容創作。
技術原理
-
Seedance 1.0 Pro:
- 生成對抗網絡/擴散模型 (GAN/Diffusion Models): 核心採用先進的深度學習模型,如擴散模型,通過學習海量視頻數據中的時空特徵,實現從文本或圖像到視頻的高質量生成。
- 多模態理解與融合: 整合自然語言處理(NLP)和計算機視覺(CV)技術,精準理解文本描述和圖像內容,並將其轉化為視頻元素的指令。
- 運動與運鏡控制: 內置高級算法,能精確控制視頻中的物體運動軌跡、鏡頭視角、景深變化等電影級運鏡效果。
- 高效計算架構: 結合字節跳動火山引擎的雲計算能力,優化模型推理速度,實現快速視頻渲染,如Seedance Lite引擎的部署。
應用場景
-
Seedance 1.0 Pro:
- 數字內容創作: 為短視頻、音樂視頻、廣告片、電影預告片等提供快速、高效的AI輔助生成工具。
- 社交媒體營銷: 創作者和品牌能夠快速製作高質量的宣傳視頻,提高社交媒體內容的吸引力。
- 個性化視頻定製: 根據用户輸入的個性化需求,生成定製化的視頻內容。
- 遊戲與動漫製作: 輔助生成場景、角色動作或特效視頻片段,提高製作效率。
Firefly Image 5 – Adobe推出的最新圖像生成模型
Firefly Image 5 是Adobe最新發布的圖像生成模型,屬於Adobe Firefly系列創意生成式AI模型。它以原生400萬像素的輸出能力為核心亮點,能夠直接生成高分辨率圖像,並大幅提升圖像細節表現力,尤其在人物渲染方面進行了優化,旨在為用户提供更精細、更專業的圖像創作體驗。
核心功能
- 高分辨率圖像生成: 支持原生400萬像素輸出,直接生成細節豐富的高清圖像。
- 文本到圖像創作: 用户可通過文本提示(Text-to-Image)按需生成定製化圖像。
- 內容憑證附加: 自動為AI生成的圖像附加內容憑證,表明其AI創作來源。
- 人物渲染優化: 針對人物圖像生成進行了專門的算法優化,提升了真實感和細節。
技術原理
Firefly Image 5 基於生成式AI模型架構,利用深度學習技術,通過海量數據集進行訓練。其獨特之處在於強調原生400萬像素的輸出能力,這可能涉及到優化了模型內部的超分辨率或高分辨率生成機制。模型訓練數據源僅限於獲得許可或不受版權保護的內容,確保了內容使用的合規性。內容憑證的自動附加可能採用了區塊鏈或數字水印技術,以實現對AI生成內容的透明化溯源。
應用場景
- 創意設計與藝術創作: 設計師和藝術家可利用其生成高分辨率概念圖、插畫或數字藝術作品。
- 營銷與廣告內容製作: 快速生成高質量的宣傳圖片、廣告素材,滿足營銷需求。
- 產品原型與視覺化: 為產品開發提供快速的視覺原型或場景渲染。
- 社交媒體內容生產: 創作引人注目的高分辨率社交媒體圖片。
- Adobe生態系統整合: 未來將深度集成至Adobe Creative Cloud和Adobe Express等產品中,賦能Adobe GenStudio等營銷解決方案。
2.每週項目推薦
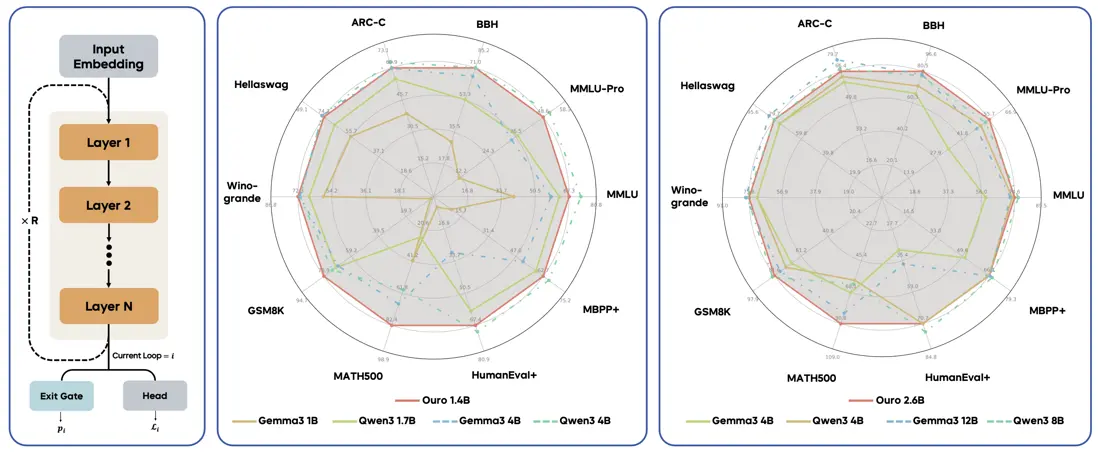
Ouro – 字節Seed推出的循環語言模型
Ouro 是字節跳動(ByteDance Seed)推出的一系列預訓練循環語言模型 (LoopLM)。該模型家族旨在通過獨特的循環架構和訓練策略,在保持緊湊模型規模(如1.4B和2.6B參數)的同時,實現卓越的參數效率和強大的推理能力,其性能可媲美甚至超越參數量大得多的模型。Ouro 模型已開源,具備良好的可擴展性。
核心功能
- 高效推理: Ouro模型通過其循環架構,在較低參數量下實現與大型模型相當或更優的推理性能,尤其在數學和科學推理任務中表現突出。
- 參數效率: 顯著提升模型參數效率,降低了計算資源需求和運營成本。
- 開源模型: 提供1.4B和2.6B等不同參數規模的開源版本,便於研究和二次開發。
- 可擴展性: 具備良好的擴展潛力,支持進一步的研究和應用拓展。
技術原理
Ouro 的核心技術原理在於其循環語言模型 (Looped Language Model, LoopLM) 架構,旨在實現潛在推理的擴展 (Scaling Latent Reasoning)。這與傳統的單向或Transformer架構有所不同。通過引入循環機制,模型能夠:
- 迭代共享信息: 在推理過程中,模型可以迭代地共享和更新中間表示,從而在有限的參數空間內進行更深層次的複雜推理。
- 增強推理能力: 特別是通過迭代處理,提升模型在需要多步驟思考、邏輯推理和問題解決(如數學和科學領域)任務上的表現。
- 參數共享與效率: 循環結構允許在不同推理步驟中複用模型參數,從而在保持高性能的同時,顯著減少整體模型參數量,達到卓越的參數效率。
應用場景
- 高效大模型部署: 適用於對計算資源和部署成本敏感的場景,如邊緣設備或資源受限的服務器。
-
複雜推理任務: 可用於需要強大邏輯推理能力的領域,例如:
- 數學問題求解
- 科學研究與分析
- 代碼理解與生成
- 模型研究與開發: 作為開源基礎模型,可供研究人員和開發者在此基礎上進行創新,探索新的模型結構和應用方向。
- 教育與智能輔導: 在需要逐步推理和解釋的學習系統中,提供高效、準確的輔助。#### 簡介
- 項目官網:https://ouro-llm.github.io/
- HuggingFace模型庫:https://huggingface.co/collections/ByteDance/ouro
- arXiv技術論文:https://arxiv.org/pdf/2510.25741
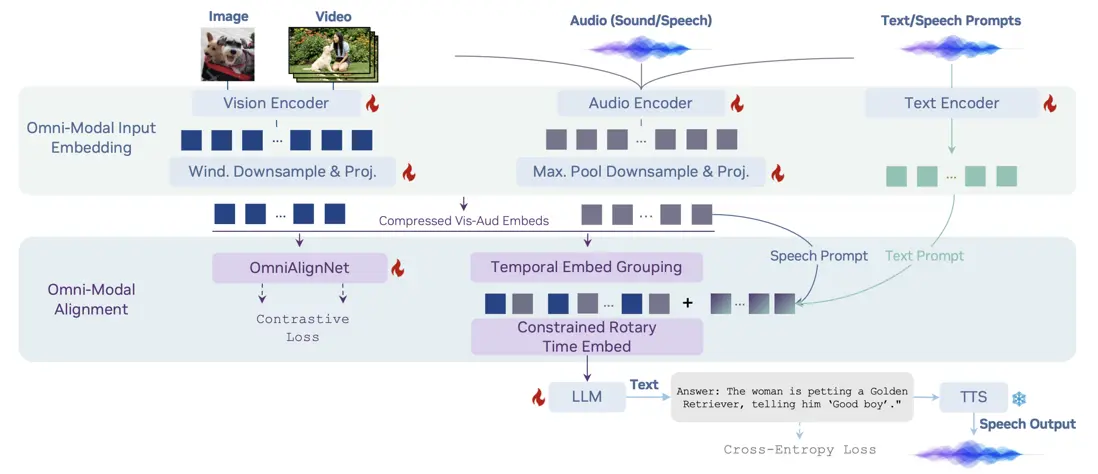
OmniVinci – NVIDIA推出的全模態大語言模型
OmniVinci是NVIDIA推出的一項開放式全模態大型語言模型(LLM)計劃,旨在通過整合視覺、音頻和文本等多種模態信息,實現機器智能對世界的全面感知和理解,以期媲美人類的感知能力。該模型於2025年10月發佈,其核心在於對模型架構和數據策展的精心設計,從而在多模態理解方面達到了先進水平,並展現出高效的訓練性能。

核心功能
- 全模態融合理解: 能夠同時處理和理解圖像、視頻、音頻及文本輸入,並生成基於這些多模態輸入的文本響應,支持可選的語音輸出。
- 跨模態推理與交互: 實現視覺、聽覺與語言信息之間的深度對齊和協同推理,支持複雜的全模態對話。
- 高效學習與性能優勢: 相較於同類模型,OmniVinci在顯著減少訓練數據量(例如,僅0.2萬億tokens對比Qwen2.5-Omni的1.2萬億tokens)的情況下,仍能實現卓越的性能表現。
- 開源研究平台: 作為開放源代碼項目,提供模型、代碼和研究框架,促進多模態AI領域的研究與發展。
技術原理
OmniVinci的技術核心在於其三項創新架構設計:
- OmniAlignNet: 專注於強化視覺與音頻嵌入在共享全模態潛在空間中的對齊。該組件通過跨注意力機制將不同模態的特徵投射至一個統一的語義空間,提升模態間的融合度。
- Temporal Embedding Grouping (TEG): 用於捕獲視覺與音頻信號之間的相對時間對齊信息。它通過分組處理時序嵌入,確保模型能理解多模態事件的時間關聯性。
- Constrained Rotary Time Embedding (CRTE): 負責編碼全模態嵌入中的絕對時間信息。這使得模型能夠精確識別事件的發生時間點和持續時長。
這些架構創新結合了一個包含2400萬條單模態和全模態對話的精心策劃數據集,並通過對比學習和交叉熵訓練範式,確保模型在多模態感知和推理中生成連貫且基於事實的響應。
應用場景
- 機器人技術: 為機器人提供更強大的環境感知和理解能力,使其能通過視聽輸入進行更智能的決策和交互。
- 智能助理與人機交互: 開發能夠理解用户多模態指令(如語音、圖像、視頻)並提供綜合反饋的下一代智能助理。
- 多媒體內容分析: 自動分析和理解視頻、音頻內容,進行事件檢測、場景描述、情緒識別等。
- 醫療健康: 輔助醫生進行醫學影像分析、聽診數據解讀以及患者病歷和對話的綜合理解。
- 工業自動化與質檢: 在智能製造和工業質檢中,結合視覺檢測與設備運行聲音分析,實現更精準的異常檢測和故障預測。
- 項目官網:https://nvlabs.github.io/OmniVinci/
- Github倉庫:https://github.com/NVlabs/OmniVinci
- arXiv技術論文:https://arxiv.org/pdf/2510.15870
Gambo – AI遊戲開發Agent
Gambo AI是一個創新的AI遊戲生成平台,旨在通過簡單的文本或創意輸入,快速自動化地創建完整的、可玩的電子遊戲。該平台集成了美術、音樂和代碼的生成能力,顯著降低了遊戲開發的門檻,並支持遊戲發佈後的即時貨幣化。
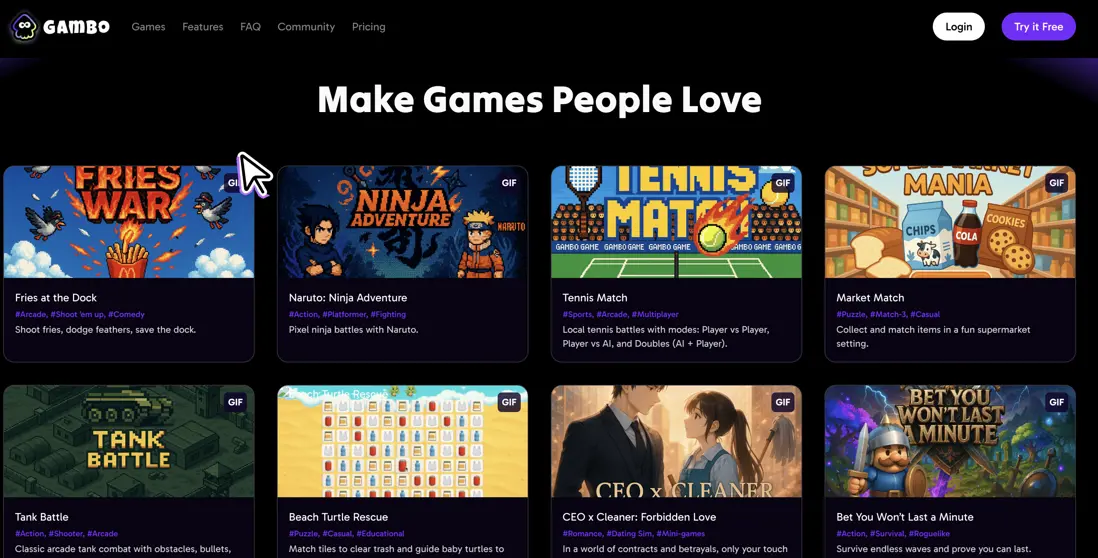
核心功能
- AI驅動的遊戲生成: 用户只需輸入遊戲創意或文本提示,AI即可自動生成包含藝術資產、音樂和核心代碼邏輯的完整遊戲。
- 多媒體內容自動化: 平台能夠生成遊戲所需的視覺(圖像、模型)、聽覺(音效、背景音樂)和文本內容。
- 無代碼/低代碼開發: 提供直觀的界面和自動化流程,使非專業開發者也能輕鬆創建和發佈遊戲。
- 即時貨幣化機制: 內置盈利功能,允許創作者從遊戲發佈之初就開始通過其作品獲得收益。
- 快速原型與迭代: 大幅縮短遊戲開發週期,支持在數分鐘內生成遊戲原型,便於快速測試和修改。
技術原理
Gambo AI的核心技術融合了先進的生成式人工智能模型:
- 大型語言模型 (LLMs): 用於解析用户的自然語言指令,將其轉化為結構化的遊戲設計元素和邏輯需求。
- 生成對抗網絡 (GANs) 或擴散模型 (Diffusion Models): 負責根據設計需求生成高質量的遊戲美術資產(如角色、場景、道具)和紋理。
- AI代碼生成 (AI Code Generation): 通過機器學習模型將遊戲邏輯和行為規範轉化為可執行的遊戲代碼,可能涉及腳本語言或特定遊戲引擎API的調用。
- 程序化內容生成 (Procedural Content Generation, PCG): 利用算法動態生成遊戲關卡、地圖佈局、謎題和任務等,增加遊戲內容的多樣性和重複可玩性。
- 多模態AI整合: 有效結合文本、圖像和音頻生成技術,確保所有生成內容在風格和功能上的一致性與協調性。
應用場景
- 獨立遊戲開發者: 快速驗證遊戲創意、製作原型或開發完整的休閒遊戲,降低開發成本和時間。
- 創意內容創作者: 將文字或藝術構思轉化為互動娛樂產品,無需專業的編程或美術技能。
- 教育與培訓: 作為學習遊戲設計、AI應用或編程的實踐工具。
- 市場調研與用户測試: 快速生成不同風格或機制的遊戲Demo,用於獲取市場反饋和用户偏好數據。
- 休閒娛樂市場: 滿足用户對個性化、多樣化和快速更新的休閒遊戲需求。
- 官網地址:https://www.gambo.ai/
Ouro – 字節Seed推出的循環語言模型
Ouro是由字節跳動Seed團隊聯合多家機構發佈的一系列循環語言模型(Looped Language Models, LoopLM)。該系列模型以象徵循環與自我吞噬的“銜尾蛇”(Ouroboros)命名,旨在通過創新的架構和訓練範式,提升語言模型的參數效率和推理能力,在較小模型規模下實現與大型模型相當甚至超越的性能。
核心功能
Ouro模型的核心功能在於通過循環推理機制,顯著增強了語言模型在複雜推理任務上的表現,特別是對數學和科學推理等需要多步思考的任務進行了優化。具體體現在以下幾個方面:
- 高效參數利用:在較小的模型規模下(例如1.4B和2.6B參數),實現與更大規模(如4B甚至12B)SOTA大模型相媲美的性能。
- 強化潛在推理:通過迭代共享參數細化(iterative shared-parameter refinement)等機制,提升模型處理複雜邏輯和多步驟推理的能力。
- 多模態理解增強:OURO模型在視覺理解和問答方面也展現出增強的能力。
技術原理
Ouro的核心技術原理是循環語言模型(Looped Language Models, LoopLM)。這種模型結構允許語言模型通過迭代共享參數細化(iterative shared-parameter refinement)機制,在推理過程中進行多次自我修正和完善。具體來説:
- 循環結構:模型不是一次性生成結果,而是在內部進行多輪循環,每一輪都基於前一輪的輸出進行進一步的加工和推敲。
- 參數共享:在循環過程中,模型重用相同的參數集,這不僅大幅降低了模型所需的總參數量,也使得模型能夠通過迭代學習和優化內部表示。
- 潛在推理能力:通過這種循環和自我優化的過程,模型能夠更深入地探索問題空間,捕捉和增強潛在的推理鏈條,從而有效提升在複雜任務上的表現。這類似於人類在思考問題時反覆推敲的過程。
應用場景
Ouro模型憑藉其高效的推理能力和優異的性能表現,可以在以下場景中發揮重要作用:
- 數學與科學問題求解:優化後的模型在數學和科學推理任務上表現突出,適用於需要精確計算和邏輯推導的領域。
- 資源受限環境下的部署:由於其高參數效率,Ouro模型非常適合在計算資源有限的設備或場景中部署,如邊緣設備、移動應用等。
- 通用語言理解與生成:作為一種通用語言模型,可應用於文本摘要、問答系統、代碼生成、對話系統等廣泛的NLP任務。
- 多模態AI系統:其在視覺理解和問答方面的增強能力,也使其在結合圖像、視頻等信息的多模態應用中具有潛力,例如智能客服、內容創作輔助。
- 項目官網:https://ouro-llm.github.io/
- HuggingFace模型庫:https://huggingface.co/collections/ByteDance/ouro
- arXiv技術論文:https://arxiv.org/pdf/2510.25741
Agent HQ – GitHub
Agent HQ是一個統一的平台或“任務控制中心”,旨在幫助開發者在一個環境中高效管理、協調和部署來自不同供應商的AI編碼工具或AI代理。它解決了AI工具生態日益碎片化的問題,通過提供集中式的管理界面,簡化了多AI模型協同工作的複雜性,旨在提高軟件開發效率和質量。

核心功能
- 多源AI代理集成: 能夠無縫集成和管理來自OpenAI、Google、Anthropic、xAI、Cognition等多個領先供應商的AI編碼代理。
- 統一任務分配與監控: 允許開發者向不同AI代理分配編程任務,並提供“任務控制中心”以實時跟蹤代理的工作進度和狀態。
- 協作工作流協調: 將AI代理作為“第一類協作夥伴”引入到GitHub等開發平台,使其深度參與代碼審查、拉取請求和CI/CD等開發流程。
- 權限與治理管理: 提供集中化的權限管理功能,確保AI代理的部署和操作符合企業政策和安全標準。
- 跨平台一致體驗: 在Web界面、IDE(如VS Code)、移動應用和命令行工具中提供一致的用户交互和管理體驗。
- 互操作性與擴展性: 構建可擴展的基礎設施,促進不同AI代理、數據源和AI模型之間的互操作性。
技術原理
- 統一控制平面架構 (Unified Control Plane Architecture): Agent HQ作為抽象層,在底層AI代理和上層開發者之間提供一個標準化的接口和管理機制,實現多代理的統一調度和編排。
- 任務編排與代理生命週期管理 (Task Orchestration and Agent Lifecycle Management): 平台支持對AI代理的任務進行分解、分配、執行監控和結果聚合,並管理代理的部署、更新和銷燬。
- API與SDK層 (API & SDK Layer): 提供開放的API和SDK,允許第三方AI代理便捷地接入平台,實現功能擴展和定製。
- 基於大語言模型 (LLM) 的智能體 (LLM-based Agents): 核心AI代理通常基於大型語言模型構建,使其具備理解、生成和執行代碼的能力,並能進行推理、規劃和採取行動。
- 並行計算與數據處理 (Parallel Computing & Data Processing): (部分平台提及)可能採用高效的並行計算引擎,以處理大量數據和支持AI代理的實時分析能力。
- AI可觀測性 (AI Observability): 包含監控工具,用於跟蹤AI代理的性能、行為和潛在偏差,確保其可靠運行。
應用場景
-
軟件開發與工程:
- 自動化代碼輔助: 自動生成代碼片段、測試用例、文檔和API規範。
- Bug修復與代碼優化: 自動識別並修復代碼中的錯誤,提供性能優化建議。
- 項目管理與任務自動化: 將複雜的編程任務分解並分配給AI代理,自動處理簡單的重複性開發工作。
- 代碼審查與質量保證: 輔助代碼審查過程,標記潛在問題或提供改進意見。
-
企業級AI解決方案:
- 跨行業自動化: 在金融、醫療、零售、製藥等行業中,利用專業AI代理實現特定業務流程的自動化。
- 企業內容生成與管理: 自動生成報告、營銷文案或內部知識文檔。
- 數據分析與洞察: 自動化數據收集、分析和可視化,輔助決策制定。
-
AI代理生態系統構建:
- 為AI代理開發者提供一個標準化的開發、測試和部署環境。
- 促進不同AI代理和AI模型之間的集成與協作,加速AI應用創新。
官網地址:https://github.blog/news-insights/company-news/welcome-home-a...
GigaBrain-0 – 開源VLA具身模型
GigaBrain-0 是一種新型的視覺-語言-行動(VLA)基礎模型。它通過利用世界模型(World Model)生成大規模多樣化數據,顯著減少了對真實機器人數據的依賴,旨在提升跨任務(cross-task)泛化能力。該項目是開源的,並由Open GigaAI維護。
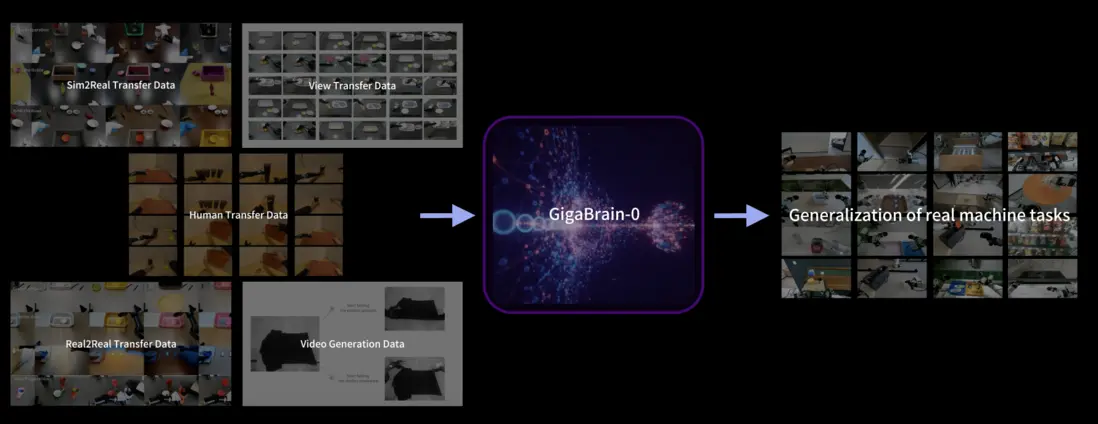
核心功能
GigaBrain-0 的核心功能在於實現具身智能體(Embodied Agent)的視覺感知、語言理解與物理行動之間的協同。它能夠通過合成數據進行高效學習,從而在多種機器人任務中展現出強大的通用性和適應性,有效克服了傳統具身學習中真實數據採集成本高、多樣性不足的挑戰。
技術原理
GigaBrain-0 的技術核心是基於世界模型驅動的數據生成範式。具體來説,它利用先進的生成模型(Generative Models)模擬物理世界,生成豐富的、多樣化的視覺、語言和行動序列數據。這些合成數據被用於訓練 VLA 模型,使其能夠學習複雜的感知-決策-行動策略。該方法通過仿真環境中的大規模數據預訓練,將具身智能的訓練效率和泛化能力提升至新的水平,減少了對昂貴且耗時的真實世界交互數據的需求。
應用場景
- 機器人操作與控制: 適用於各種機器人任務,如物體抓取、放置、組裝以及複雜環境導航等。
- 具身AI研究: 為開發和測試新型具身智能體提供了一個高效且可擴展的平台。
- 虛擬現實/增強現實: 可用於創建更智能、交互性更強的虛擬角色和環境。
- 自動化工業: 在工業機器人、倉儲物流等領域實現更靈活、適應性更強的自動化解決方案。
- 項目官網:https://gigabrain0.github.io/
- Github倉庫:https://github.com/open-gigaai/giga-brain-0
LongCat-Video – 美團開源的AI視頻生成模型
LongCat-Video是美團LongCat團隊開源的136億參數視頻生成基礎模型。它是一個強大的AI模型,能夠將文本和圖像轉化為高質量的視頻,旨在在文本到視頻(Text-to-Video)、圖像到視頻(Image-to-Video)等多種任務上提供出色的性能,並在內部和公共基準測試中與領先的開源模型及商業解決方案相媲美。
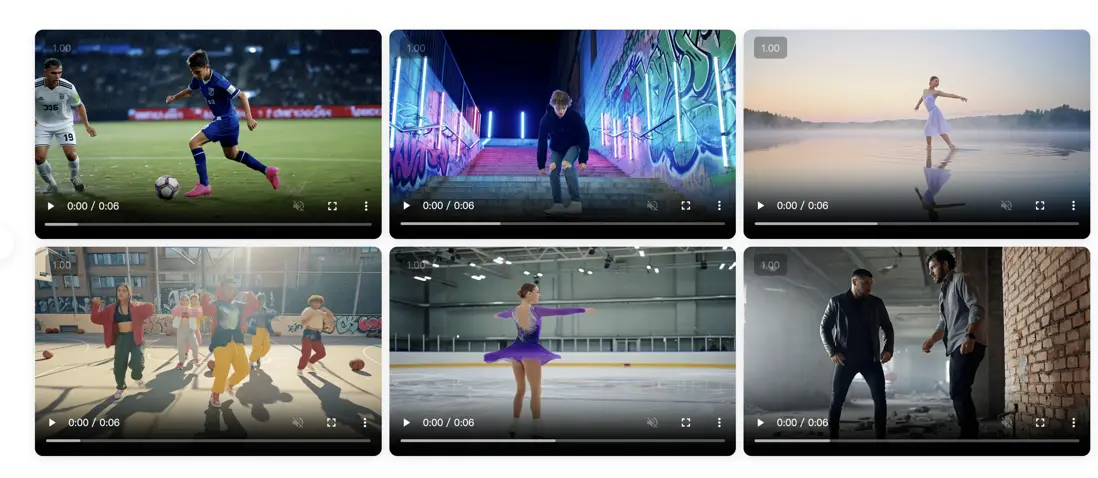
核心功能
LongCat-Video的核心功能包括:
- 文本到視頻生成 (Text-to-Video Generation):根據輸入的文字描述生成相應的視頻內容。
- 圖像到視頻生成 (Image-to-Video Generation):將靜態圖像轉化為動態視頻。
- 視頻編輯與優化 (Video Editing and Optimization):通過AI技術提升視頻的視覺質量、運動質量和文本對齊度。
技術原理
LongCat-Video採用136億參數的Transformer架構作為其基礎模型。其關鍵技術原理是利用多獎勵強化學習優化 (Multi-reward Reinforcement Learning Optimization),特別是Group Relative Policy Optimization (GRPO) 方法。通過這種優化訓練,模型在文本對齊、視覺質量和運動質量等多個維度上實現了性能提升,確保生成視頻的整體質量和逼真度。
應用場景
LongCat-Video的應用場景廣泛,包括:
- 內容創作:電影製作、廣告、短視頻平台等領域,用於快速生成原型、特效或完整視頻。
- 個性化營銷:根據用户輸入或偏好,生成定製化的產品介紹視頻或宣傳片。
- 教育與培訓:將文本教材或圖像資料轉換為動態演示視頻,提升教學互動性。
- 虛擬現實/增強現實 (VR/AR):生成高質量的虛擬場景和動畫內容。
- 遊戲開發:輔助生成遊戲過場動畫或環境動態效果。
- 項目官網:https://meituan-longcat.github.io/LongCat-Video/
- Github倉庫:https://github.com/meituan-longcat/LongCat-Video
3. AI-Compass
AI-Compass 致力於構建最全面、最實用、最前沿的AI技術學習和實踐生態,通過六大核心模塊的系統化組織,為不同層次的學習者和開發者提供從完整學習路徑。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本項目對您有所幫助,請為我們點亮一顆星!🌟
📋 核心模塊架構:
- 🧠 基礎知識模塊:涵蓋AI導航工具、Prompt工程、LLM測評、語言模型、多模態模型等核心理論基礎
- ⚙️ 技術框架模塊:包含Embedding模型、訓練框架、推理部署、評估框架、RLHF等技術棧
- 🚀 應用實踐模塊:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿應用架構
- 🛠️ 產品與工具模塊:整合AI應用、AI產品、競賽資源等實戰內容
- 🏢 企業開源模塊:彙集華為、騰訊、阿里、百度飛槳、Datawhale等企業級開源資源
- 🌐 社區與平台模塊:提供學習平台、技術文章、社區論壇等生態資源
📚 適用人羣:
- AI初學者:提供系統化的學習路徑和基礎知識體系,快速建立AI技術認知框架
- 技術開發者:深度技術資源和工程實踐指南,提升AI項目開發和部署能力
- 產品經理:AI產品設計方法論和市場案例分析,掌握AI產品化策略
- 研究人員:前沿技術趨勢和學術資源,拓展AI應用研究邊界
- 企業團隊:完整的AI技術選型和落地方案,加速企業AI轉型進程
- 求職者:全面的面試準備資源和項目實戰經驗,提升AI領域競爭力
