









引言
隨着年輕人的社交需求不斷增長,各種社交軟件應運而生,這些社交軟件通常都會有好友推薦功能,根據六度分離理論,理想情況下,每個人通過6個人就可以跟所有人產生關聯,因此K-hop算法(K跳算法)被用於實現好友推薦,現在讓我們來嘗試使用GeaFlow在5分鐘內實現K-hop算法吧!
K-hop(K跳)算法介紹
K-hop算法是一種基於圖論的算法,用於尋找一個起點通過K次以內跳躍能夠到達的節點,也就是從起點出發,找出K層內與之關聯的節點。K-hop算法廣泛應用於好友推薦、影響力預測和關係發現等場景。
K-hop算法本質上是一種廣度優先搜索(BFS)算法,通過從起點開始不斷向外擴散的方式來計算每一個節點到起點的跳躍數。算法流程如下:

GeaFlow實現K-hop算法
首先需要通過實現AlgorithmUserFunction接口來編寫K-hop算法的UDGA,K-hop算法的參考實現如下:
package com.antfin.rayag.myUDF;
import com.antgroup.geaflow.common.type.primitive.IntegerType;
import com.antgroup.geaflow.common.type.primitive.StringType;
import com.antgroup.geaflow.dsl.common.algo.AlgorithmRuntimeContext;
import com.antgroup.geaflow.dsl.common.algo.AlgorithmUserFunction;
import com.antgroup.geaflow.dsl.common.data.RowEdge;
import com.antgroup.geaflow.dsl.common.data.RowVertex;
import com.antgroup.geaflow.dsl.common.data.impl.ObjectRow;
import com.antgroup.geaflow.dsl.common.data.impl.types.IntVertex;
import com.antgroup.geaflow.dsl.common.function.Description;
import com.antgroup.geaflow.dsl.common.types.StructType;
import com.antgroup.geaflow.dsl.common.types.TableField;
import com.antgroup.geaflow.model.graph.edge.EdgeDirection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
@Description(name = "khop", description = "built-in udga for KHop")
public class KHop implements AlgorithmUserFunction<Object, Integer> {
private AlgorithmRuntimeContext<Object, Integer> context;
private int srcId = 1;
private int k = 1;
@Override
public void init(AlgorithmRuntimeContext<Object, Integer> context, Object[] parameters) {
this.context = context;
if (parameters.length > 2) {
throw new IllegalArgumentException(
"Only support zero or more arguments, false arguments "
+ "usage: func([alpha, [convergence, [max_iteration]]])");
}
if (parameters.length > 0) {
srcId = Integer.parseInt(String.valueOf(parameters[0]));
}
if (parameters.length > 1) {
k = Integer.parseInt(String.valueOf(parameters[1]));
}
}
@Override
public void process(RowVertex vertex, Iterator<Integer> messages) {
List<RowEdge> outEdges = new ArrayList<>(context.loadEdges(EdgeDirection.OUT));
//第一輪迭代將所有頂點初始化,目標點的K值初始化為0,並向鄰點發送消息,其他點的K值初始化為Integer.MAX_VALUE
if (context.getCurrentIterationId() == 1L) {
if(srcId == (int) vertex.getId()) {
sendMessageToNeighbors(outEdges, 1);
context.updateVertexValue(ObjectRow.create(0));
context.take(ObjectRow.create(vertex.getId(), 0));
}else{
context.updateVertexValue(ObjectRow.create(Integer.MAX_VALUE));
}
} else if (context.getCurrentIterationId() <= k+1) {
int currentK = (int) vertex.getValue().getField(0, IntegerType.INSTANCE);
//如果當前頂點收到消息,並且K值為Integer.MAX_VALUE(沒有被遍歷到),則本輪應該修改K值,並向鄰邊發消息
if(messages.hasNext() && currentK == Integer.MAX_VALUE){
Integer currK = messages.next();
//將當前頂點寫出
context.take(ObjectRow.create(vertex.getId(), currK));
//更新當前頂點的K值
context.updateVertexValue(ObjectRow.create(currK));
//向鄰點發消息
sendMessageToNeighbors(outEdges, currK+1);
}
}
}
//設置輸出類型
@Override
public StructType getOutputType() {
return new StructType(
new TableField("id", IntegerType.INSTANCE, false),
new TableField("k", IntegerType.INSTANCE, false)
);
}
private void sendMessageToNeighbors(List<RowEdge> outEdges, Integer message) {
for (RowEdge rowEdge : outEdges) {
context.sendMessage(rowEdge.getTargetId(), message);
}
}
}
Geaflow運行K-hop算法實戰
將KHop類打包成UDGA
新建一個maven工程,將KHop類放/src/main/java目錄下,pom文件中需要添加如下依賴:
<dependency>
<groupId>com.antgroup.tugraph</groupId>
<artifactId>geaflow-dsl-common</artifactId>
<version>0.1</version>
</dependency>參考https://github.com/TuGraph-family/tugraph-analytics/blob/master/docs/docs-cn/application-development/dsl/overview.md
將UDGA上傳至geaflow-console平台
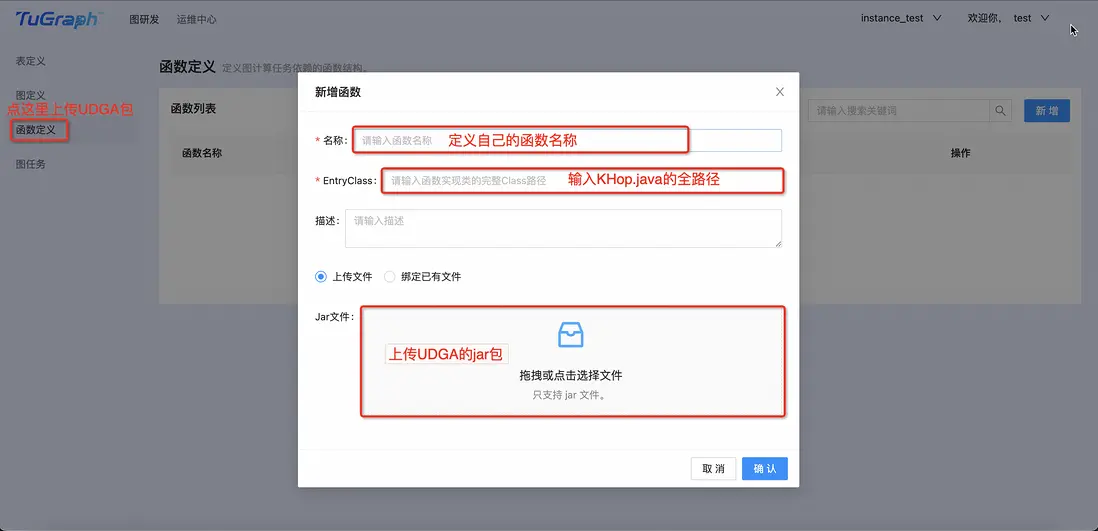
註冊khop函數,並在DSL中使用
set geaflow.dsl.window.size = -1;
set geaflow.dsl.ignore.exception = true;
CREATE GRAPH IF NOT EXISTS g (
Vertex v (
vid int ID,
vvalue int
),
Edge e (
srcId int SOURCE ID,
targetId int DESTINATION ID
)
) WITH (
storeType='rocksdb',
shardCount = 1
);
CREATE TABLE IF NOT EXISTS v_source (
v_id int,
v_value int
) WITH (
type='file',
//vertex文件中保存了點的信息,文件放在與KHop類目錄下的resources目錄下,此處可以換成其他數據源
geaflow.dsl.file.path = 'resource:///input/vertex'
);
CREATE TABLE IF NOT EXISTS e_source (
src_id int,
dst_id int
) WITH (
type='file',
//edge文件中保存了邊的信息,文件放在與KHop類目錄下的resources目錄下,此處可以換成其他數據源
geaflow.dsl.file.path = 'resource:///input/edge'
);
//定義結果表
CREATE TABLE IF NOT EXISTS tbl_result (
v_id int,
k_value int
) WITH (
type='file',
geaflow.dsl.file.path = '/tmp/result'
);
USE GRAPH g;
INSERT INTO g.v(vid, vvalue)
SELECT
v_id, v_value
FROM v_source;
INSERT INTO g.e(srcId, targetId)
SELECT
src_id, dst_id
FROM e_source;
//註冊khop函數
CREATE Function khop AS 'com.antfin.rayag.myUDF.KHop';
INSERT INTO tbl_result(v_id, k_value)
//調用khop函數,並返回結果
CALL khop(1,2) YIELD (vid, kValue)
RETURN vid, kValue
;運行結果
輸入數據如下
//vertex文件內容:
1,1
2,1
3,1
4,1
5,1
6,1
//edge文件內容:
1,3
1,5
1,6
2,3
3,4
4,1
4,6
5,4
5,6在container的/tmp/result文件中可以得到結果如下
1,0
3,1
5,1
6,1
4,2至此,我們就成功使用Geaflow實現並運行了K-hop算法了!是不是超簡單!快來試一試吧!
GeaFlow(品牌名TuGraph-Analytics) 已正式開源,歡迎大家關注!!!
歡迎給我們 Star 哦! GitHub👉 https://github.com/TuGraph-family/tugraph-analytics
更多精彩內容,關注我們的博客 https://geaflow.github.io/












