
系統編程和網絡編程初步
學習 Linux 是為了在 Linux 下進行系統級別和網絡級別的編程。Linux 只是操作系統的代表,其他的 Windows、MacOS等也可以進行類似的編程模式,Linux 因為開源,內核源碼公開,所以從 Linux 入手能更好地理解這一塊。其他的閉源操作系統只能學習相關接口的調用。
系統級代碼的特點:這些代碼的背後很多都是操作系統或網絡的知識。之前的代碼都是圍繞某個問題進行編程,而系統級代碼都是圍繞如何更好地利用 OS 的特性展開。
馮諾依曼體系結構
計算機領域有2位祖師爺,一位是馮 $\cdot$ 諾依曼,另一位是艾倫 · 圖靈。
在計算機領域還有很多可以稱祖師爺的,比如雷納斯 · 託瓦茲是開源的祖師爺。
當代的計算機架構就是由馮諾依曼祖師爺定義的。這個計算機架構被現在的計算機採用,於是舊採用馮諾依曼的名字命名。
什麼是體系結構?在《計算機組成原理》的書籍和相關課程中會提到。計算機組成即計算機由哪些硬件組成,部分場景會將體系結構説成是芯片架構,因為芯片是最核心的組件、硬件。
芯片架構目前主要用的硬件是 x86或x86/x64,這些都是因特爾構建的計算機體系,其他的比如手機用的是 ARM。
無論是常見的計算機,如筆記本;還是不常見的計算機,如服務器,甚至電子設備如遙控器,大部分都遵守馮諾依曼體系。

截至目前,我們所認識的計算機,都是由一堆硬件、組件組成:
- 輸入單元:
包括鍵盤,鼠標,話筒,攝像頭,掃描儀,寫字板,USB,磁盤、SSD、聲卡、網卡、顯卡等。
關於磁盤:磁盤即硬盤,是外部設備的一種,且是永久存儲介質。現代的筆記本電腦不再是磁盤,而是SSD(Solid State Disk或Solid State Drive,固態硬盤)。
SSD和磁盤在物理結構上不同,簡單來説磁盤的原理是機械運動來刻錄數據,而SSD是通過半導體芯片和電流結合存儲信息。因為機械結構在運行速度上始終比不上電流(可以無限接近光速),所以SSD大面積替代了磁盤作為筆記本電腦的永久存儲介質。
- 中央處理器(CPU):
含有運算器和控制器,以及各種寄存器和各種級別的緩存。關於CPU的學習重點在寄存器上。 - 輸出單元:
用於展示計算機的處理信息,例如顯示器,喇叭,打印機,磁盤,網卡,顯卡等。 - 存儲器:
指的是內存,可以理解為帶電臨時存儲介質(非專業術語,不可用於學術論文),一旦電源斷開內存存儲的數據就會消失。
這些單元通過一系列的總線例如數據總線、地址總線和控制總線進行連接。且幾乎所有的輸入、輸出設備都可以以某種方式插入主板中。
若對電腦進行拆機,可以查看主板的結構,可以看到風扇、內存條等構件,還可以看到主板提供的外置內存條的插口。
外置內存條最直接的應用是插卡遊戲機,但遊戲卡只能讀。
為什麼歷史選擇了馮氏結構
計算機的本質其實就是把數據給計算機,它在自身的內部做計算,計算完之後把結果再顯示出來,馮諾依曼體系結構就是按這樣的設計來進行復合的。
同一時期的體系結構比如哈佛結構(程序和數據分開存儲)、神經網絡模型(如M-P模型,人工智能的模型)等,卻只有馮氏結構在競爭中勝出。原因很多,這裏選其中一個方面進行描述。
從存儲的角度看體系結構
CPU其實是有數據的臨時存儲能力的,包括少量的寄存器,還有對應的各種各樣的cache緩存。
內存可以叫做掉電易失性存儲單元,也就是説它一旦掉電了,那麼最終我們的數據也就沒了。
其他外設(外部設備),比如説磁盤, SSD、顯卡、網卡和其他外設,也有數據的存儲能力。只不過它們的存儲能力是比較小的啊。而且其他的設備本身自帶了一些類似於CPU、寄存器的核心部件,一般稱作叫端口。
寄存器,緩存,內存,磁盤,固態硬盤,這些都有數據的存儲能力。
所以計算機裏幾乎所有的設備都有存儲數據的能力:
- CPU也有寄存器和各種級別的緩存。
- 內存可以叫做掉電易失性存儲單元,即它一旦掉電了,則內存存儲的數據也就沒了。
- 其他的設備,它們本身也是具有數據的存儲能力的。設備本身自帶了一些類似於CPU寄存器的東西,一般把它叫端口。
為什麼我們要談存儲呢?因為所有的設備之間交互的時候,本質就是把數據從一個設備拷貝到另一個設備,所以存儲的效率就直接決定了拷貝的效率,也就直接決定了設備和設備之間通信的效率。
拷貝效率本身就是設備和設備之間通信的效率,如果它的效率很高的話,我們的整機的計算機的效率就會比較高啊。
存儲分級
計算機的存儲體系存在存儲分級的概念。即距離CPU越近(或和CPU交互越多)的存儲單元呢,它的存儲效率是越高的,那麼距離CPU越遠的,它的存儲效率是越低的。
這裏參考c語言的常用關鍵字-CSDN博客中的 register 的描述。可以看到,計算機中的存儲結構存在很明顯的存儲分級以及金字塔的結構。這裏我們的主角是 CPU 和內存。
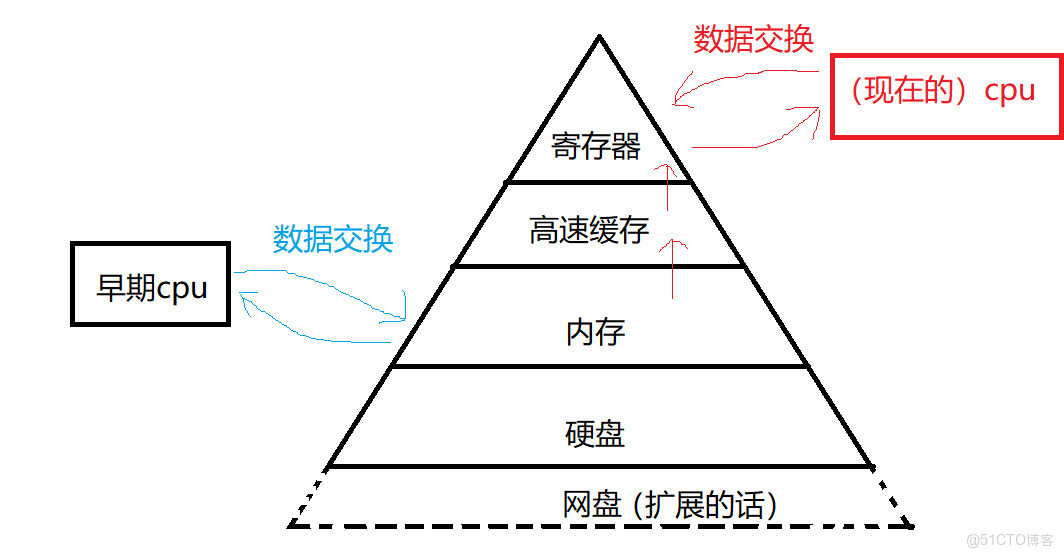
一般存儲效率高的存儲單元(點名CPU、寄存器),往往成本比較高,即需要花更多的錢、更多的技術才能製造這個零件;而存儲的效率比較低的存儲單元(點名硬盤、各種外部設備),造價會比較便宜啊。內存呢是相對適中的。
CPU在進行通信的時候,更多的是從寄存器直接讀取數據。所有的數據在被計算機拿到後,先得拿到到寄存器裏,CPU從寄存器拿出這個過程對於人的感覺來説是很快的。但CPU再拿其他數據的話,有可能從內存裏呢啊,然後再考慮從外設去拿。
CPU的速度非常快,若直接去外設裏拿數據的話,那麼它的效率會比從寄存器中拿低一些。
為什麼要用存儲分級
現代CPU的數據處理速度基本上是納秒級別的,那麼計算、存儲、讀取的時候都是這個級別的處理速度,而內存可以簡單地理解成微秒或者是納米級別。
輸入、輸出單元這些外設可以理解成它是毫秒級別,甚至秒級別。
從極端的角度考慮,例如全用效率高的和全用效率低的:
若全部用存取數據的效率快的零件組裝計算機,就像《名偵探柯南》裏烏丸蓮耶的黃昏別館,牆壁、地基等全部由純金打造:
由上面的這些結論,如果我們訂做一款計算機,都設計成大比例的寄存器或告訴緩存,不要內存,不要什麼磁盤,那麼此時所有的計算機零部件全部採用高價的。這種高效率的計算機設計方式,在技術上它是肯定可以的,無非就是請更多的工程師花更多錢去做這台計算機。
如果所有的計算機都這樣搞了,計算機會變得非常貴啊,普通老百姓就買不起了,就不會有這麼多的人有電腦。不會有這麼多人有電腦,就不會有這麼多人上網,不會有這麼多人上網,就不會存在用户量有上億的,上十億的大型互聯網公司存在,也就不會有現在欣欣向榮的各種互聯網經濟。
所以互聯網的蓬勃發展本質的原因,其中有一個重要的因素就是這個計算機一效率要不差,並且它還不能貴啊。那麼這樣的話才能夠讓我們的互聯網那麼到來,然後然後給我們提供各種便利的服務。
雖然外設的數據存取很慢,但若全部把計算機的部件搞成便宜貨(即使用造價便宜的CPU)來匹配現在的外設,效率很慢,並沒有滿足用户需求。
在數據層面上,當代CPU一般是不和外設進行交互。儘管確實存在有將外設的數據讀到CPU中,經過處理後再讀到內存,但現在不是,現在已經有了獨立的各種各樣的設備,CPU只要發一個信號,那些設備自動幫我們去搬運數據。
從木桶原理考慮:
木桶原理:由木片構成的桶,能裝的水取決於最短的那塊木板。若今天允許CPU直接和外設交互的話,那麼整機的效率是最慢的,整機的效率最後肯定和各種外設的效率是保持一致的。
CPU一般不和外設交互呢,主要原因是受木桶原理的影響,導致整機效率降低。
所以CPU一般它在拿數據時不考慮寄存器,不考慮什麼緩存,它至少要能從內存裏拿數據。
不管學任何編程語言,不管學的是 C++ 還是 Java,包括彙編,會發現所有的編程定義變量、對象全部都是在內存當中進行申請的。申請完之後,這個變量、對象,要經過CPU去執行訪問。
所以所有的變量都是在內存裏,原因就在這裏,因為硬件層面上, CPU只能和內存直接交互。
若要讓CPU去進行對一個,或一批,或一段,或一大堆數據進行對應的計算操作的話,我們一定要想辦法先把數據從對應的輸入單元,”搬運“ 到內存中,那麼在輸入單元往內存裏 ”搬運“ 數據的同時,CPU可以同時在進行着其他的計算,當它計算完之後,內存中的數據也”搬運“ 好了,此時 CPU 和內存之間的工作時間就交叉起來了,時間就互相重疊了,效率自然而然就高了。
內存可是有 4 GB、8 GB 的存儲空間,而CPU可能最多隻能計算100 MB 的數據。然後操作系統識別到在這個用計算機裏,未來可能還會要用第 200 到第 300 MB 的數據,所以操作系統直接把幾千 MB 的數據 “搬運” 過來。
也就是在拷貝數據從輸入設備到內存的同時,CPU也在跟內存打交道,
所以他的這個時間上呢,就可能出現重疊,從而提高效率。
最終CPU是整個系統最快的核心部件,又因為CPU不再和外設打交道了,它直接和內存打交道,內存雖然不是整個體結構裏最快的,但是它也不慢。
也就是説在不違反木桶原理這個客觀規律的基礎上,直接仿問硬件造成的短板比直接訪問內存的短板短,即使效率依舊趕不上純CPU這樣的效率,但相比較於純外設,它的效率就提高了。
所以 CPU 一般優先和內存進行數據交流。
內存既跟外設打交道,又跟CPU打交道,正是因為它的存在呢,在純硬件層面就把內存當個超大的緩存,至於這個緩存誰來維護,什麼時候把數據放到內存裏,什麼時候把數據顯示到輸出設備,這些軟件邏輯方面的工作由操作系統來做。
內存的角色定位
內存就是一個硬件級別的緩存。所有的外設,包括輸出、輸入設備,把數據 ”搬運“ 到內存的同時,內存也在將數據送進 CPU 進行計算,不同設備工作的時間就重疊了。
當 CPU 計算出結果,CPU可以將數據寫到內存裏,然後定期把數據輸出到外設並刷新數據,刷新的時候呢,再進行IO訪問的同時,CPU可以也進行正常的數據計算,這就是我們所對應的數據緩存。
寫進度條的時候,會發現數據是你如果不把它強制刷新或者輸出
\n或\r,它數據就是出不來。原因就是因為CPU把數據先寫到內存了,而不是 “ 數據直接從CPU送到外設” ,然後再由內存做刷新。在類似的場景刷新的時機就很重要,比如説這個計算機不忙了,就順便做一做。
絕大部分的現代計算機基於馮諾依曼體系結構,本質是用比較少的錢,做出來效率不錯的計算機。比較少的錢就體現在輸入輸出單元,它可以很慢了。然後呢,那麼內存那麼價格也不能接受。
至於CPU,用少量的寄存器即可完成日常所需的運算速度,也能很好地控制整個電腦的價格,但同時整機的一個效率達不到CPU,但也不至於差到外設的這種級別,而是以內存的速度為主。使用這樣的存儲分級結構,就能用少量的錢做出效率不錯的計算機。這就叫做性價比比較高。正因為它的性價比比較高,所以才為我們當代計算機提供了效率不差並且還不貴的計算機。
所以內存充當 CPU 和各種外設溝通的 ”中間角色“ 。更細節的地方後續有機會再介紹。
存儲分級的現實意義
程序在運行之前得先加載到內存,因為程序裏面呢無非就是代碼或者是數據。就是程序員寫的類,寫的函數啊,寫的循環,寫的判斷,這叫做程序員寫的代碼;而數據就是你在棧上開闢的空間。定的全局變量,靜態成員,這些都叫做數據,只要是代碼加數據,最終都要由CPU來進行執行或處理。
可以理解為程序運行起來,就是CPU在運行程序的代碼。但其實 CPU 只認識二進制。
CPU 能夠處理的前提條件是 CPU 先讀取到這些代碼和數據,而 CPU 只和內存有數據層面(二進制代碼或狀態)的交互。
所以代碼形成了可執行程序(拓展名一般為 .exe),可執行程序本質就是一個文件,而這個文件在磁盤也就是外設中保存。而CPU最終是要來執行處理代碼數據的,但是CPU只和內存打交道,所以就註定了必須在硬件層面上把程序從磁盤調動並將數據等加入內存,這個時候程序才能跑起來,
所以本質是因為叫做體系結構決定的。數據放到磁盤上則是通過文件操作進行。
所以編譯代碼(比如 c 語言到可執行程序)的本質就是:編譯器把代碼文本文件打開,然後把文件裏面的代碼全部讀到編輯程序內部,編譯器編譯程序內部的代碼,將代碼翻譯成二進制,然後再寫回到磁盤的二進制文件。等需要時再執行這個二進制文件。
總結
馮諾依曼體系結構是在通用性、簡單性和成本效益之間取得的最佳平衡點。它不是最快的,也不是最並行的,但它是最普適、最容易實現和普及的。
體系結構代入現象進行理解
QQ聊天
假設甲、乙兩人,假設甲在西安,乙在北京,他們都登上QQ這個軟件,打開聯繫對方的對話框。然後甲把和乙對話的對話框打開之後,然後緊接着甲給乙發了一條消息説 “在嗎” 。
在硬件層面上,解釋一下 “在嗎” 在設備層面上的數據流動,即從開始甲從鍵盤裏輸這個消息,最後這個消息打在了乙的顯示器上,整個的過程的梳理:
這裏假設沒人學過網絡,所以忽略掉網絡啊,把網絡的就當成一個簡單的自動處理信息的黑盒,知道它有傳送信息的功能就可以。
首先甲乙都登上 QQ 這個軟件的前提條件是甲乙各自都得有一台電腦(不考慮無法安裝 QQ 的計算機),現在就假設甲乙各自有一台電腦,本質就是雙方各自有一個馮諾依曼結構的計算機(其他結構也可以)。
信息 “在嗎” 在數據流動的時候,肯定要在甲的電腦上就流動,然後到網絡,再到乙的電腦(假設沒學過網絡,所以忽視網絡的傳輸細節)。
首先甲在輸入 “在嗎” 的時候肯定是通過輸入設備(至於是鍵盤還是語音識別即聲卡不重要,都是輸入設備),這個信息最終輸入到甲的計算機的內存中。
甲首先得啓動QQ這個軟件, 本質是QQ這個軟件在甲的電腦上再運行起來了。當它先運行起來之後,QQ便加載到內存裏。
所以輸入信息給QQ,其實就是輸入信息給內存。
再然後,“在嗎” 的數據就從鍵盤輸入到了存儲器。但到存儲器的信息不止 “你好”,還包括暱稱,頭像,發送時間等等諸多信息。所以需要把多個信息組合起來,形成一個完整的信息對象(結構體或類),然後再發送給乙。這個組合的過程至少得有類似於字符串拷貝拼接的功能。
所以這裏就註定了信息要由CPU參與計算,形成一個可以發送的 “在嗎” 的消息及其他信息的組合對象。根據馮諾依曼體系結構,一定是從存儲器讀進入CPU進行處理,處理完再寫回內存,之後再把 “在嗎” 的消息對象輸出到對應的一個叫做輸出設備上,這個輸出設備就只能是網卡(和網絡有關才能發送信息出去)。
數據經過網絡的過程到網絡時再做相關介紹。然後乙從網絡裏收到了 “在嗎” 這條消息,這個消息也是通過乙的電腦的輸入設備得到,而且和網絡有關的很可能也是網卡。之後網卡將 “在嗎” 這個信息對象輸入存儲器中,而且還是內存中。再之後就是經過 CPU 對這個 “你好” 對象的解包裝,之後再把它寫回存儲器,再把有關的信息輸出到乙的電腦的輸出設備上,這個輸出設備就是顯示器(因為最終目的是讓乙看到信息)。

而且 “在嗎“ 不止通過網卡和網絡發送出去,還會打印在屏幕上,所以輸出設備不一定只有一個,包裝好的數據是一式多份進行輸出的。根據這個原理,我們甚至可以做一個簡單的聊天軟件(以後有機會再嘗試)。
舉這個案例是為了能意識到其他設備也會充當輸入設備,只要是輸入設備,數據一定是優先先給內存的,而不是直接到CPU上的。
活學活用QQ的案例
這裏就不舉更多的案例了。
往後在思考或者是解釋一些計算機現象的時候,覺得自己描述不清楚,只要能夠想到硬件層面上的一些現象,並藉助這些現象進行解釋,就可以將問題化繁為簡。在計算機體系結構(大部分情況是馮諾依曼,不排除少部分特殊體系結構)的計算機下的所有的軟件(這裏只舉例多台設備的通信軟件)都在這個硬件的邏輯當中去思考。
類似防洪治沙,最後水怎麼走,完全全取決於河道它怎麼修,修好了,不管河怎麼走,水怎麼流啊,都繞不開這個河道。







