
在當今數據驅動的商業環境中,企業越來越依賴數據分析來驅動決策。無論是用户行為分析、業務報表還是運營監控,企業都需要具備快速、高效的數據處理能力。企業在數據分析能力上的演進,往往始於 TP(事務處理)系統,隨着業務發展不斷探索 TP 系統的擴展方案,最終走向構建獨立的 AP(分析處理)系統。
企業實時分析典型演進過程
第一階段:使用 TP 系統支撐事務處理和數據分析
在企業信息系統建設的早期,主要存儲在 OLTP(在線事務處理)系統中,比如 PostgreSQL、MySQL、SQL Server 等。因為數據“就在那兒”,最自然的方式就是直接從 TP 系統中執行 SQL 查詢來獲取所需分析數據:
- 查詢訂單、用户、庫存、交易等業務數據;
- 生成運營報表,支撐內部管理;
- 快速開發查詢接口,滿足臨時的 BI 需求。
在業務初期,數據規模有限,分析需求也相對簡單,系統架構輕量,能夠高效支撐當下業務,避免了多系統部署和複雜數據流帶來的額外成本與運維壓力。然而,隨着業務快速發展,數據量迅速增長,分析場景愈發複雜,查詢延遲上升,事務與分析負載相互影響,原有系統逐漸難以支撐持續擴展的業務需求。
第二階段:探索 TP 系統的擴展方案
為了在不破壞 TP 系統穩定性的前提下支撐持續擴展的業務需求,部分企業開始嘗試基於 TP 的擴展方案。以下是行業中常見的做法與代表系統:
1. 分片與分佈式擴展:Citus、TiDB、Vitesse
這些系統具備了基於關係數據庫的水平擴展能力,使 TP 系統可以存儲更大規模的數據並處理更高併發。
- Citus:是 PostgreSQL 的分佈式擴展插件,可將表自動切分到多個節點,實現並行處理和查詢加速。
- TiDB:兼容 MySQL 協議的分佈式 HTAP 數據庫,事務與分析融合,適用於在線業務+報表的場景。
- Vitesse:基於 MySQL 的分佈式中間件,解決數據庫擴展、容錯和自動化問題,常用於大規模 TP 系統。
2. 讀寫分離與多副本架構:Amazon Aurora
- Amazon Aurora 提供了高性能、彈性擴展的雲數據庫,並支持最多 15 個只讀副本,用於分擔查詢壓力。這類方案適用於中等複雜度的分析任務,但在海量數據和複雜查詢面前,Aurora 等 TP 架構依然面臨查詢瓶頸。
這些方案雖然在一定程度上緩解了單機性能瓶頸,但本質仍屬於 TP 系統架構,難以根本解決事務與分析並存所帶來的矛盾。面對大規模、多維度的聚合分析,這類系統能力有限,查詢操作常常干擾寫入,導致系統性能波動,影響整體穩定性。同時,架構複雜、運維門檻高,隨着寫入量和查詢壓力的持續上升,資源消耗不斷加劇,系統成本快速攀升,性能瓶頸也日益顯現。尤其在高吞吐數據導入和實時更新方面能力不足,限制了對業務變化的快速響應。而 TP 系統以行存為主的特性,使其在處理 TB 級以上數據的分析任務時,性能與專為分析設計的 AP 系統存在顯著差距,難以勝任更復雜、更大規模的分析需求。
第三階段:複雜分析使用 AP 系統
隨着數據量不斷增長、分析需求日益複雜,很多企業逐漸意識到,無法再依賴原有的 TP 系統同時滿足事務處理與分析需求。因此,企業通常會將一些複雜的分析查詢遷移到專門的 AP 系統中,例如 Redshift、Snowflake、BigQuery 等,用於支撐大規模的數據分析任務。而對於對實時性要求高、併發量大的查詢,仍會保留在 TP 系統中運行,以確保系統的快速響應和穩定性。在一些高併發場景中,數據甚至會在 AP 系統中完成加工處理後,迴流到 TP 系統中,進一步支撐實時查詢和業務服務。
第四階段:擁抱 AP 系統,實現分析計算與事務的解耦
隨着數據規模持續擴大,事務處理系統(TP)的數據導入速度難以跟上行為數據生成的節奏,導致數據延遲持續增加。與此同時,部分複雜查詢被轉移到分析處理系統(AP)執行,其他分析任務仍在 TP 系統中完成,這使得系統運維難度和資源成本不斷攀升,遠超專門的 AP 系統。
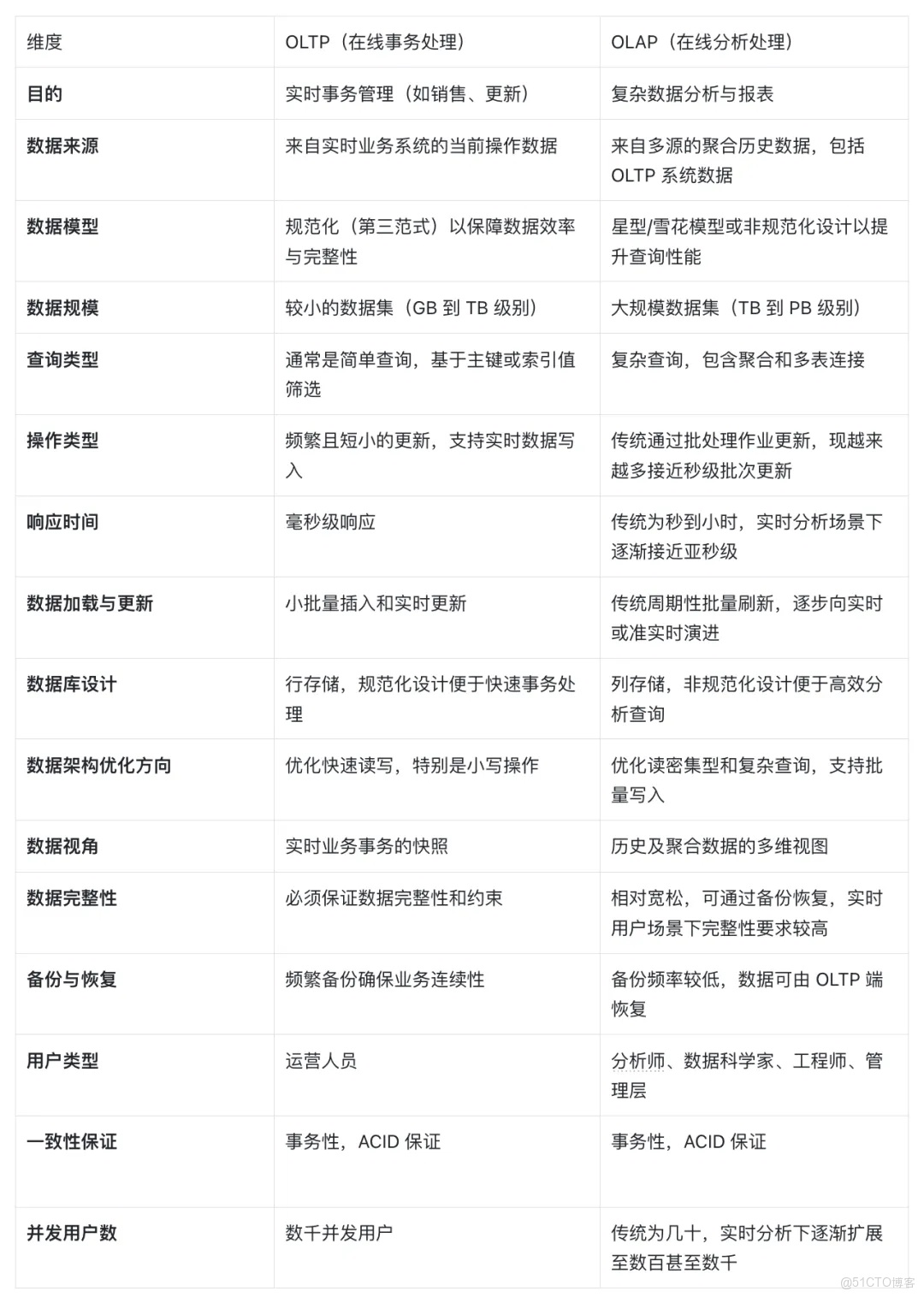
下表總結了 OLTP 與 OLAP 在關鍵維度上的主要區別,便於理解兩者在架構定位上的差異。
OLTP vs OLAP 對比
面對這種挑戰,越來越多企業開始認識到:對於實時分析場景,採用具備高併發與高性能的一體化 AP 系統來統一承載,能夠大幅提升效率;而批量處理和離線分析等需求,則可以選擇更適合的 AP 系統來完成。這樣不僅優化了整體架構,也有效控制了成本,同時提升了數據分析能力,助力企業實現更加高效的數據驅動運營。
實時數據需求直接導入實時 OLAP 系統,常見做法是將事務處理系統(TP)與分析處理系統(AP)解耦,通過變更數據捕獲(CDC)技術,實現 TP 系統數據的實時同步,同時行為數據也直接寫入實時 OLAP。實時 OLAP 系統需具備快速更新能力和高效查詢性能。該架構不僅避免了對核心業務系統的影響,還使企業能夠第一時間獲取並分析最新數據,廣泛應用於用户行為分析、實時報表、風險監控等關鍵場景,顯著提升了數據決策的及時性和價值。
OLAP 系統的選擇:為什麼是 Apache Doris?
Apache Doris 適合大數據量下需要高併發查詢、AdHoc 和實時數據更新的場景:
低延遲高吞吐寫入
支持多種數據導入方式,通過 Stream Load 可實現數據秒級可見、單節點寫入吞吐可達百萬行/秒,輕鬆滿足海量數據的實時入庫需求。
用户案例:網易雲音樂
網易雲音樂作為知名音樂流媒體平台,每天產生大量用户行為數據、業務數據及日誌數據,這些數據在異常行為跟蹤、客訴問題定位、運行狀態監控、性能優化等方面扮演守護者的角色。面對每日萬億級別數據的增量,網易雲音樂選擇使用 Apache Doris 替換 ClickHouse 構建新的日誌平台,目前已穩定運行 3 個季度,規模達到 50 台服務器,2PB 數據,每天新增日誌量超過萬億條,峯值寫入吞吐達 6GB/s。
在低延遲高吞吐寫入場景中,網易雲音樂採用 Flink + Doris Connector 實現流式數據無縫對接,通過多項關鍵優化措施顯著提升了寫入性能:
- 寫入流程優化:在 append 數據操作時,直接寫入壓縮流,無需經過 ArrayList 中轉,大幅降低內存使用,TM 內存佔用從 8G 降至 4G,有效避免了因 batch size 設置過高導致的 OOM 問題。
- 單 tablet 導入功能:開啓單 tablet 導入功能(要求表使用 random bucket 策略),極大提升寫入性能,解決了寫入 tablet 過多時元數據產生過多影響寫入性能的問題。
- 負載均衡優化:每個 batch flush 完成後隨機選擇 BE 節點寫入數據,解決 BE 寫入不均衡問題,相較之前導入性能提升 70%。
- 容錯能力增強:調整 failover 策略,優化重試邏輯並增加重試時間間隔,當 FE/BE 發生單點故障時能自動感知和重試恢復,保證服務高可用。
在元數據性能優化方面,針對 HDD 硬盤環境下 Stream Load 耗時突增問題,通過調整 3 台 Follower FE 為異步刷盤模式,實現了 4 倍性能提升,有效解決了同步元數據階段的嚴重耗時問題。
整體收益顯著:查詢響應整體 P99 延遲降低 30%,併發查詢能力從 ClickHouse 的 200 提升至 500+,寫入穩定性大幅改善,運維成本顯著降低,在壞盤和宕機場景下實現自恢復能力。
完整閲讀:網易雲音樂基於 Apache Doris 的萬億級日誌平台建設實踐
實時更新能力強
配合主流數據同步工具(如 Kafka、Canal、DataX、SeaTunnel 等)可實現從 TP 系統到 Doris 的準實時數據同步。其“Merge-on-Write”的更新機制兼顧寫入性能與更新效率,適配主流 CDC 場景。
用户案例 :中通快遞
隨着中通快遞業務的持續增長,昔日雙 11 的業務高峯現已成為每日常態,原有數據架構在數據時效性、查詢效率、與維護成本方面,均面臨着較大的挑戰。為此,中通快遞引入 SelectDB,藉助其高效的數據更新、低延時的實時寫入與優異的查詢性能,在快遞業務實時分析場景、BI 報表與離線分析場景、高併發分析場景中均進行了應用實踐。
在實時分析場景中,基於 SelectDB 靈活豐富的 SQL 函數公式、高吞吐量的計算能力,實現了結果表的查詢加速,能夠達到每秒上 2K+ 數量級的 QPS 併發查詢,數據報表更新及時度大大提高。
SelectDB 的引入滿足了複雜與簡單的實時分析需求。目前,SelectDB 日處理數據超過 6 億條,數據總量超過 45 億條,字段總量超過 200 列,並實現服務器資源節省 2/3、查詢時長從 10 分鐘降至秒級的數十倍提升。
案例回顧:中通快遞基於 SelectDB 實時數倉的應用實踐
極致的查詢性能
Doris 天生為分析優化,具備列式存儲、向量化執行引擎、位圖索引、多級緩存、物化視圖等優化手段,能夠支撐亞秒級的分析響應時間,並支持複雜的多維分析、聚合與 JOIN 查詢。
用户案例 :拉卡拉
拉卡拉是國內首家數字支付領域上市企業,從支付、貨源、物流、金融、品牌和營銷等各維度,助力商户、企業及金融機構數字化經營。隨着實時交易數據規模日益增長,拉卡拉早期基於 Lambda 架構構建的數據平台面臨存儲成本高、實時寫入性能差、複雜查詢耗時久、組件維護複雜等問題。拉卡拉選擇使用 Apache Doris 替換 Elasticsearch、Hive、HBase、TiDB、Oracle/MySQL 等組件,完成 OLAP 引擎的統一,實現了查詢性能提升 15 倍、資源減少 52% 的顯著成效。
在極致查詢性能場景中,拉卡拉充分發揮了 Apache Doris 天生為分析優化的多項能力,在金融核心業務中實現了顯著的性能提升:
- 風控場景查詢優化:替換 Elasticsearch 後,查詢響應時間從 15 秒縮短至 1 秒以內,查詢性能提升 15 倍。
- 對賬單系統高併發處理:藉助 Doris 優秀的併發處理和極速查詢能力,支持每日億級數據規模和百萬級查詢請求,查詢 99 分位數響應時長控制在 2 秒以內,數據延遲可控制在 5 秒。
- 倒排索引加速大表關聯:通過添加倒排索引、調整分桶策略以及表結構優化,大表關聯查詢耗時從 200 秒縮短至 10 秒,查詢效率提升超過 20 倍。
- Light Schema Change 靈活變更:相比 Elasticsearch 需要通過 Reindex 進行 Schema 變更,Doris 的 Light Schema Change 機制更加高效靈活,支持字段和索引的快速增刪修改,極大提升了數據管理的便捷性和業務適應性。
整體收益顯著:服務器數量下降 52%,開發運維效率大幅提升,通過統一的 OLAP 引擎簡化了技術架構,降低了學習成本和運維複雜性。
完整閲讀:拉卡拉 x Apache Doris:統一金融場景 OLAP 引擎,查詢提速 15 倍,資源直降 52%
高併發處理能力
得益於 MPP 架構,Doris 可輕鬆擴展計算資源,支持海量用户併發訪問分析報表,是支撐數據門户、運營後台、用户行為分析等實時應用場景的理想方案。
用户案例:快手
快手作為知名短視頻平台,OLAP 系統為內外多個場景提供數據服務,每天承載近 10 億的查詢請求。原有湖倉分離架構面臨存儲冗餘、資源搶佔、治理複雜等問題。快手通過引入 Apache Doris 湖倉一體能力替換 ClickHouse,升級為湖倉一體架構,涉及數十萬張表、數百 PB 的數據增量處理。
在高併發處理場景中,Apache Doris 憑藉強大的 MPP 架構和分佈式查詢引擎,為快手提供了卓越的併發查詢支撐能力:
- 海量併發查詢支撐:系統每天承載近 10 億查詢請求,覆蓋 ToB 系統(商業化報表引擎、DMP、磁力金牛、電商選品)和內部系統(KwaiBI、春節/活動大屏、APP 分析、用户理解中心等)的高併發訪問需求。
- 智能查詢路由:通過查詢路由服務分析和預估查詢的數據掃描量,將超大查詢自動路由到 Spark 引擎,避免大查詢佔用過多 Doris 資源,確保高併發場景下的系統穩定性。
- 物化視圖透明改寫:結合 Doris 的物化視圖改寫能力和自動物化服務,實現查詢性能提升至少 6 倍,百億級別以下數據可實現毫秒級響應,有效支撐高併發查詢場景。
- 緩存優化加速:通過元數據緩存和數據緩存雙重優化,元數據訪問平均耗時從 800 毫秒降至 50 毫秒,顯著提升高併發場景下的查詢響應效率。
整體收益:實現了統一存儲和鏈路簡化,無需數據導入即可直接訪問湖倉數據,在支撐海量併發查詢的同時大幅降低了運維複雜度和存儲成本。
完整閲讀:快手:從 Clickhouse 到 Apache Doris,實現湖倉分離向湖倉一體架構升級
統一數據體驗 Doris 提供類 SQL 的接口,兼容 MySQL 協議,易於 BI 工具對接(如 Tableau、Power BI、Superset 等),同時可通過視圖、物化視圖等能力,提供類似數據倉庫的建模支持。
可以滿足的典型場景包括:
- 面向用户的實時分析(Customer-Facing Analytics) 將訂單、交易、行為等業務數據從數據庫中捕獲並同步至實時數倉(如 Apache Doris),支持用户在前端系統中秒級查看訂單狀態、活動參與情況、積分變化等。提升用户體驗的同時,也為推薦、搜索等系統提供最新的數據支持。
- 運營監控與分析 運維、客服、市場等部門可以實時查看關鍵指標(如系統交易量、失敗率、退貨率),並快速響應業務波動。CDC 保證了數據與業務系統的實時一致性,使監控結果具有可信度。
- 模型訓練與特徵回填 將用户行為日誌和業務數據同步到分析庫後,ML 工程師可以基於最新數據生成訓練樣本、回填特徵值,顯著加快模型迭代速度,提升預測準確率。
- 多維分析與自助 BI 將結構化業務數據實時匯聚到 OLAP 系統,結合維度模型,支持業務人員進行靈活多維分析,滿足從明細到聚合的多層級洞察需求,減少對開發人員的依賴。
ClickHouse 實時更新原理
在 ClickHouse 中,雖然底層存儲以追加為主,但通過 ReplacingMergeTree 引擎,用户可以實現類似“實時更新”的效果。其核心思想是:在寫入時保留所有版本的數據,在後台合併時自動保留最新版本,從而實現數據的“更新”。
詳情參考文檔
具體工作原理如下:
- 寫入階段 使用
ReplacingMergeTree創建表時,通常會指定一個唯一標識列(如主鍵)和一個版本列(如update_time)。每次對同一主鍵的數據更新時,系統不會直接覆蓋舊數據,而是插入一行新版本的記錄。 - 合併階段(Merge) ClickHouse 的後台合併線程會在空閒時自動執行數據文件的合併操作。對於
ReplacingMergeTree表,合併過程中會根據主鍵值和版本列,自動保留每組主鍵下版本最新的記錄,刪除舊版本,實現最終的“更新”語義。 - 查詢階段 查詢過程中可能會讀到尚未合併的多個版本記錄,因此建議設置
FINAL查詢語法,如:
SELECT * FROM my_table FINAL;
Apache Doris 實時更新原理
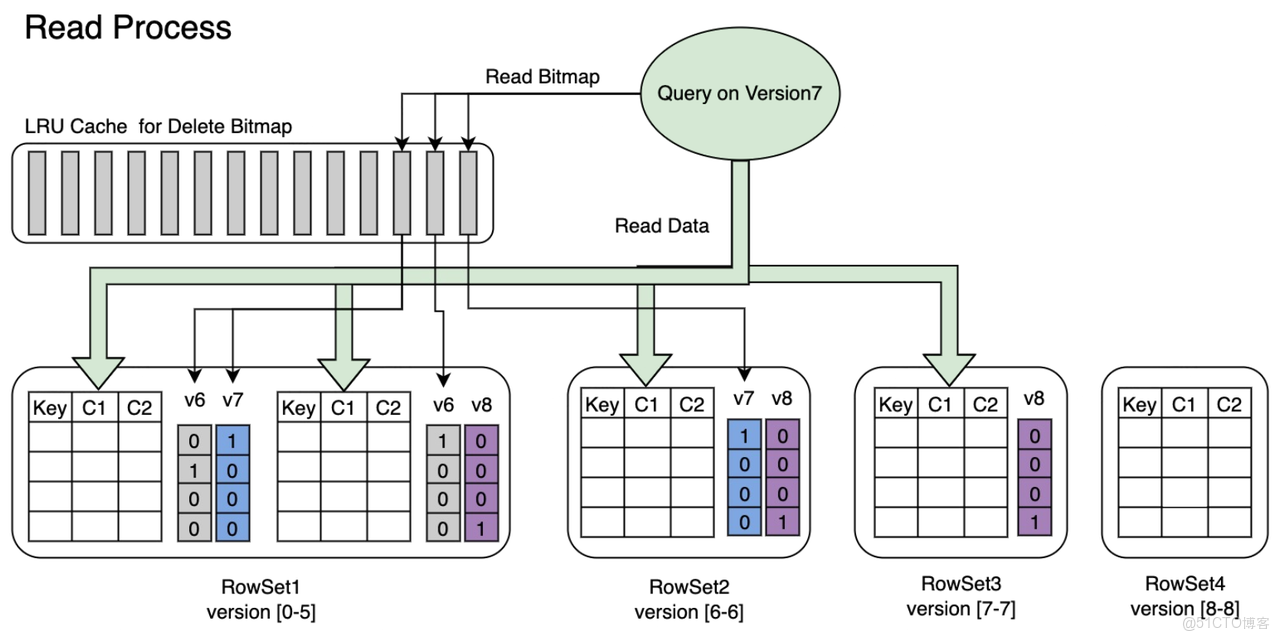
在需要頻繁更新數據的場景中,可以使用 Doris 提供的 Unique Key 模型來建表,實現對同一主鍵的數據進行高效覆蓋更新。Doris 通過一種名為標記刪除(Delete Bitmap)的機制,有效提升查詢性能。與 ClickHouse 查詢時進行更新清理的方式不同,Doris 的標記刪除機制無需在查詢時實時計算刪除邏輯,因此可以顯著減少查詢延遲,確保查詢響應時間穩定在百毫秒以內,並支持高併發訪問。
具體來説,Doris 的處理分為兩個階段:
- 寫入階段 在使用 Unique Key 創建表時,您通常會指定一個唯一標識(如主鍵 ID)和一個版本列(如更新時間
update_time)。每當新數據寫入時,如果主鍵相同且版本更新,Doris 會自動為舊數據打上“刪除標記”,這些信息隨着數據一同寫入底層存儲。 - 查詢階段 在查詢過程中,Doris 會自動識別並跳過那些已被標記刪除的舊數據行,無需實時對比或掃描多個版本,從而實現低延遲、高效率的數據讀取。
藉助這套機制,Doris 能夠同時滿足 實時更新 和 高速查詢 的雙重需求,非常適合用於用户畫像、訂單中心、指標快照等典型更新型分析場景。
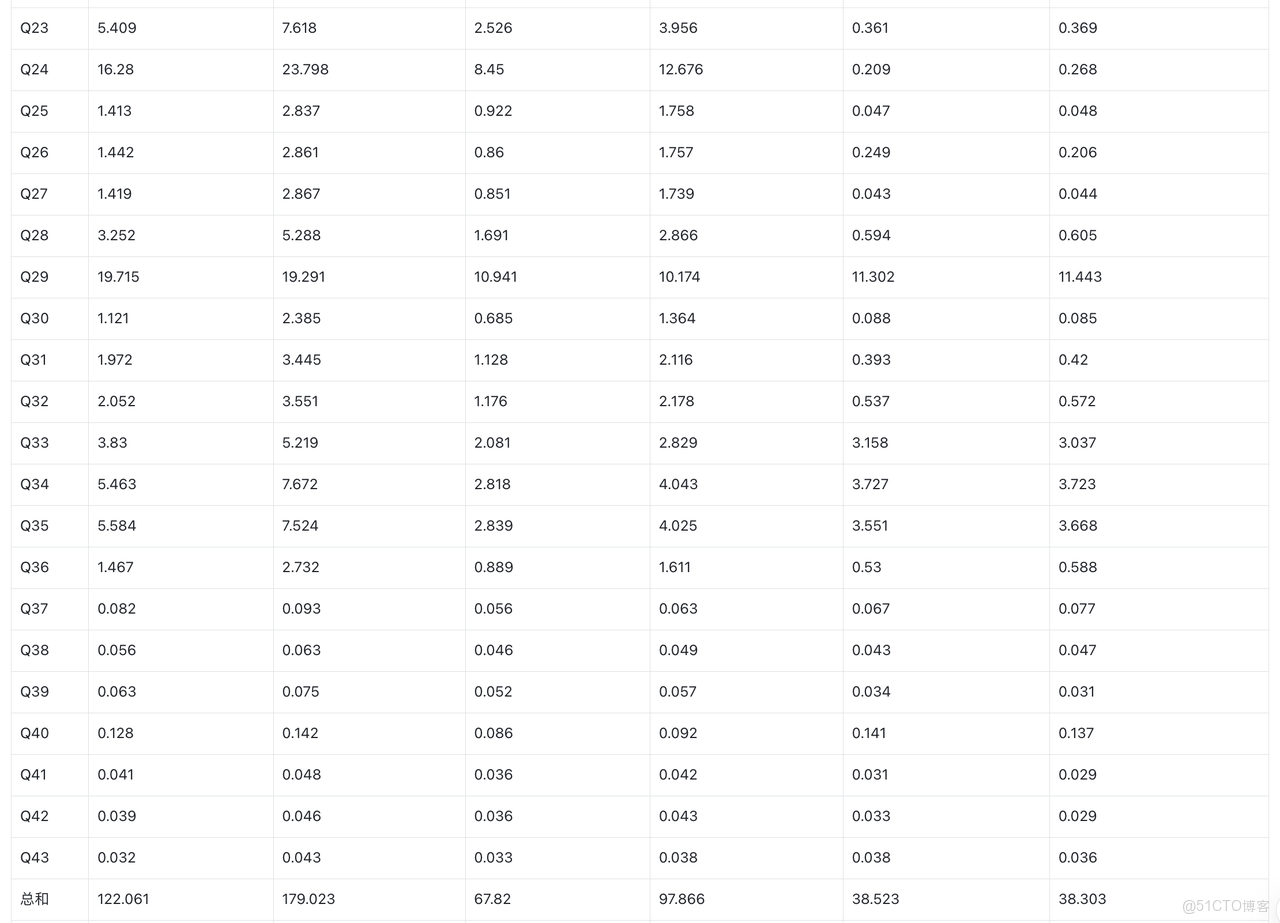
性能對比
當分析負載從 TP 或者 HTAP 演進到 AP 時,一個常見場景是將 TP 系統中的變更數據(通過 CDC)同步到 AP 系統,用於後續的報表分析和業務監控。這類場景通常涉及大量的數據更新,而不僅僅是新增數據,因此對分析系統的更新處理能力和查詢性能提出了更高要求。
為了評估 Doris 和 ClickHouse 在這一類實時更新分析場景下的表現,我們基於典型的行業測試模型 ClickBench 和 SSB(Star Schema Benchmark) 進行了測試,分別對數據集中的 25% 和 100% 的記錄進行了更新操作。
更新 SQL 詳情參考
為確保性能對比的合理性,結合 ClickHouse Cloud 與 SelectDB Cloud 套餐配置的差異,制定瞭如下測試方案:ClickHouse Cloud 採用雙副本,單副本分別配置為 8 核 32GB 和 16 核 64GB;SelectDB Cloud 則採用單副本 16 核 128GB 配置。通過該設計,可在整體資源層面分別實現核數對等(16 核)與內存對等(128GB)的橫向對比,從而更全面地評估兩者在不同資源維度下的性能表現。
原始數據:ssb
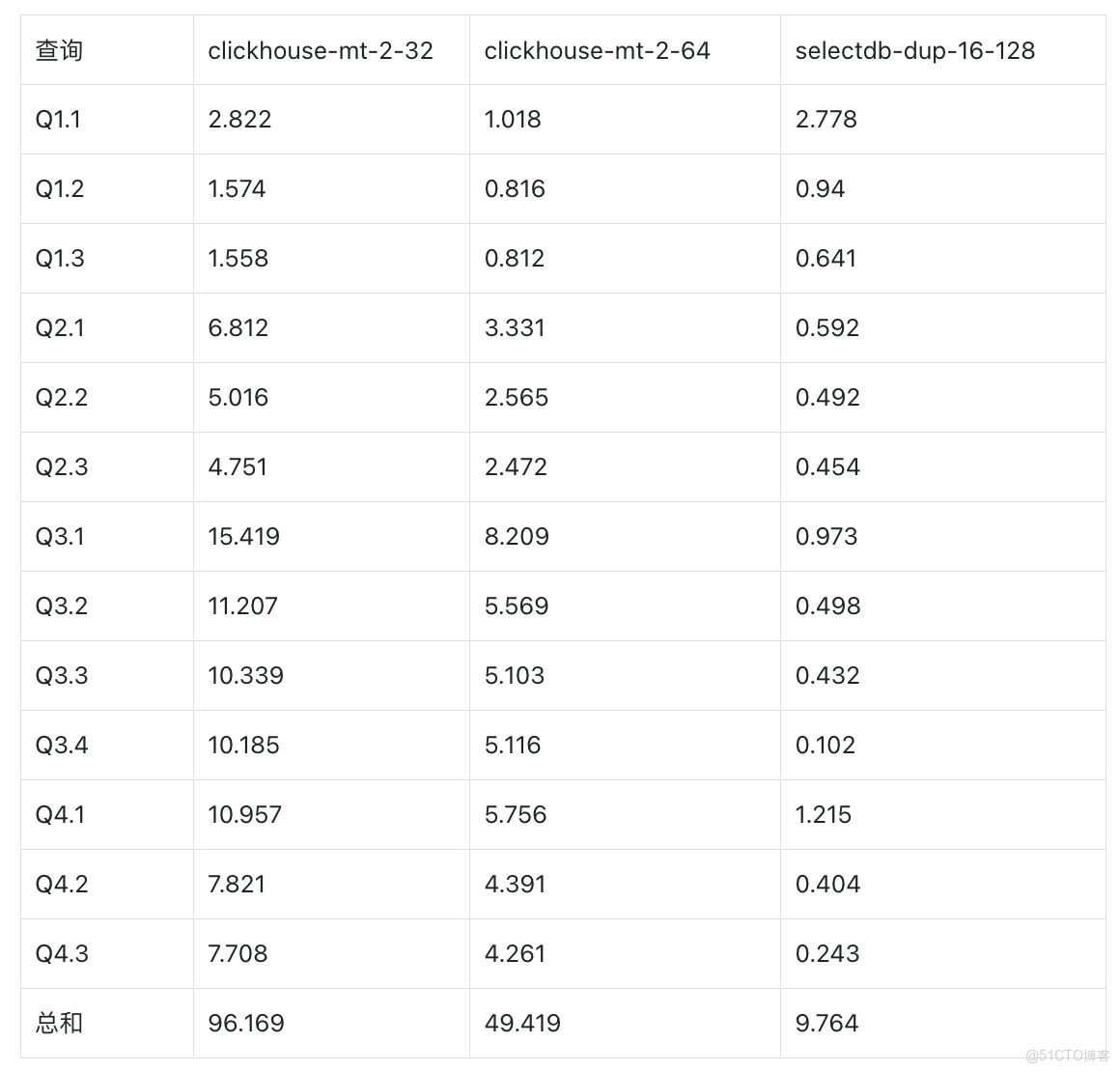
SSB-sf100
ClickHouse MergeTree vs SelectDB Duplicate Key
- SelectDB (16c 128GB)的性能是 ClickHouse 32c 128GB(2 replica 每個 replica 16c 64GB)的 5 倍。
- SelectDB (16c 128GB)的性能是 ClickHouse 16c 64GB(2 replica 每個 replica 16c 64GB)的 9.8 倍。
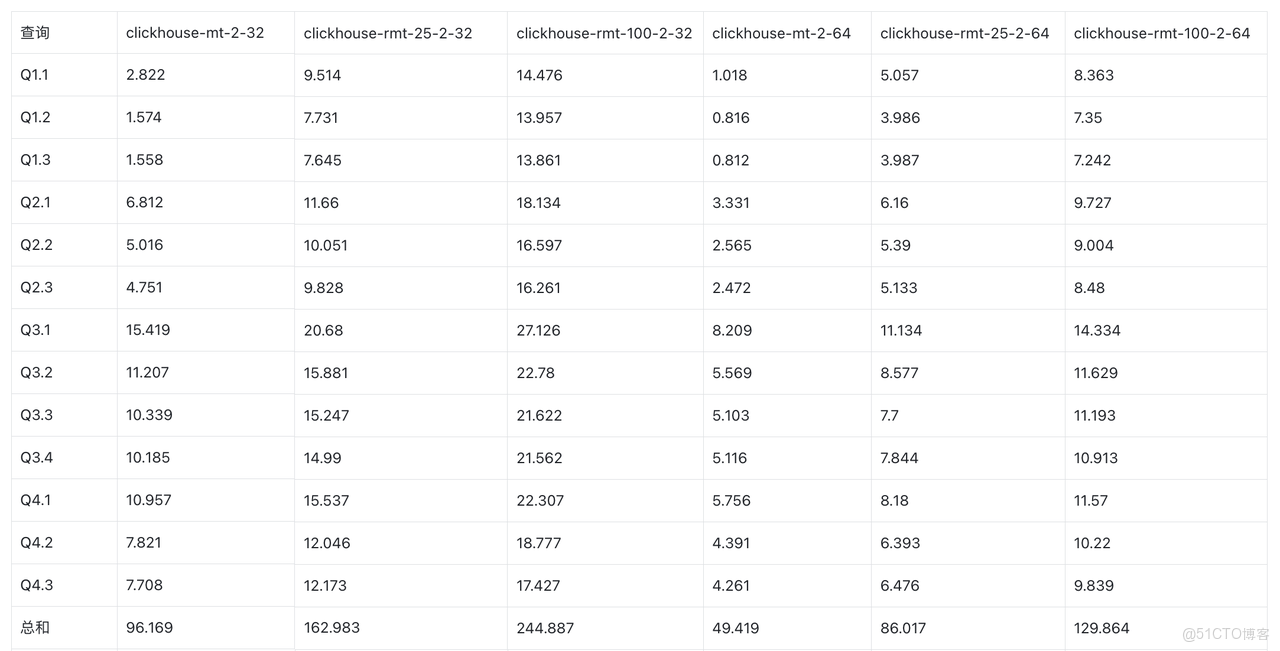
ClickHouse MergeTree vs ReplacingMergeTree
- 25% 更新比例下,ClickHouse ReplacingMergeTree 相比 MergeTree 性能下降 1.6 倍。
- 100% 更新比例下,ClickHouse ReplacingMergeTree 相比 MergeTree 性能下降 2.5 倍。
ClickHouse ReplacingMergeTree vs SelectDB UniqueKey
- SelectDB (16c 128GB)相比 ClickHouse 32c 128GB(2 replica 每個 replica 16c 64GB)
- 25% 更新比例條件下,SelectDB 的性能是 ClickHouse 的 14 倍。
- 100% 更新比例條件下,SelectDB 的性能是 ClickHouse 的 18 倍。
- SelectDB (16c 128GB)相比 ClickHouse 16c 64GB(2 replica 每個 replica 8c 32GB)
- 25% 更新比例條件下,SelectDB 的性能是 ClickHouse 的 25 倍。
- 100% 更新比例條件下,SelectDB 的性能是 ClickHouse 的 34 倍。
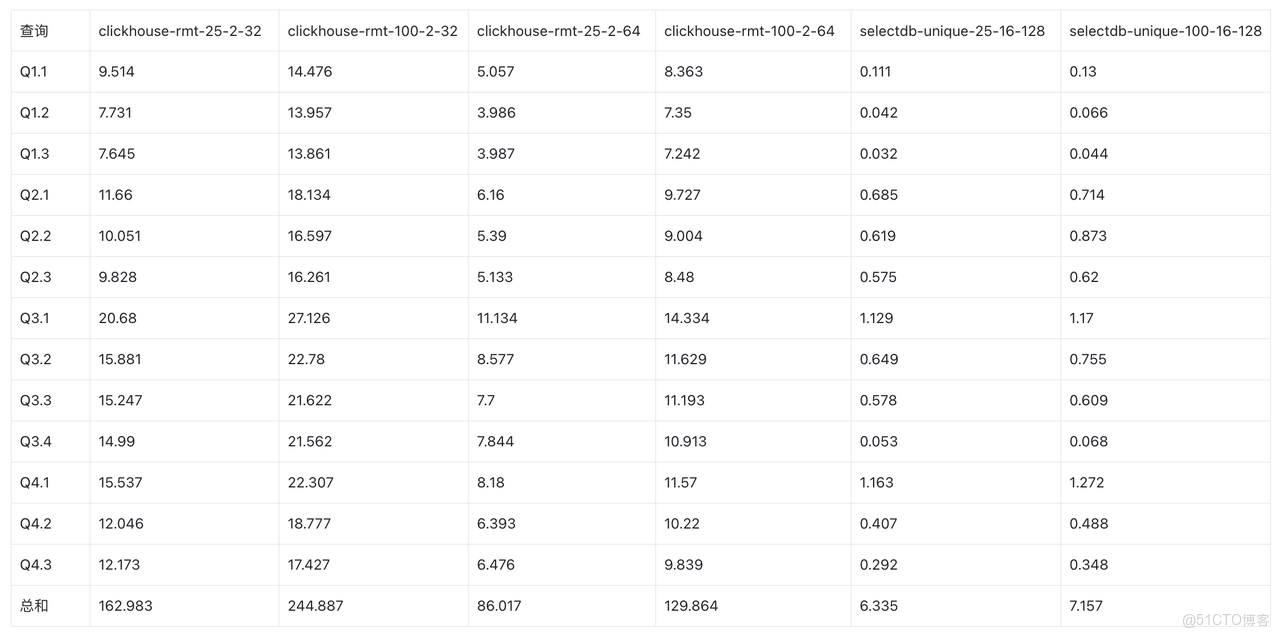
ClickBench
原始數據:clickbench
ClickHouse MergeTree vs ReplacingMergeTree
- ClickBench 下 25% 更新比例 ClickHouse ReplacingMergeTree 相比 MergeTree 性能下降超過 170%。
- ClickBench 下 100% 更新比例 ClickHouse ReplacingMergeTree 相比 MergeTree 性能下降超過 290%。
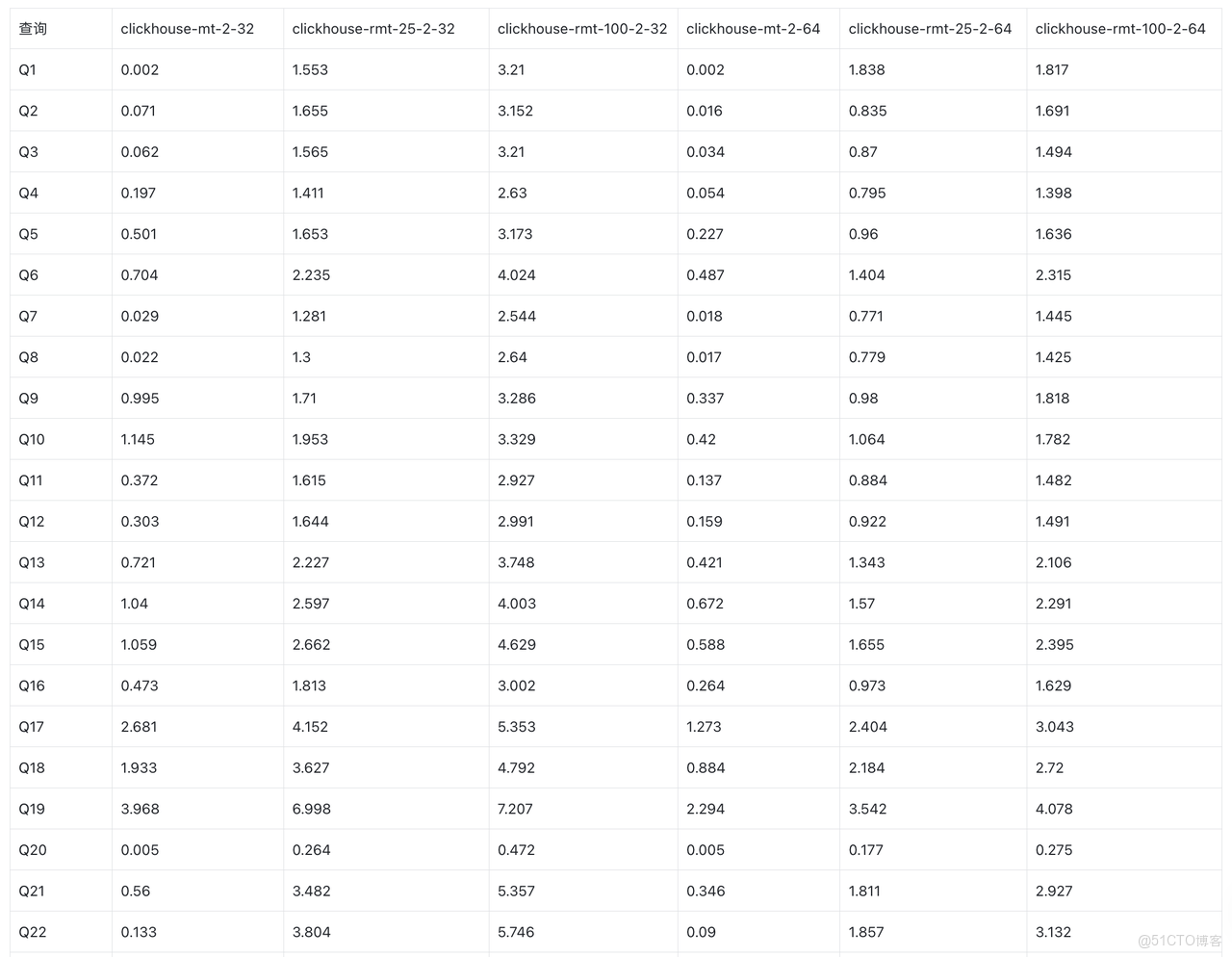
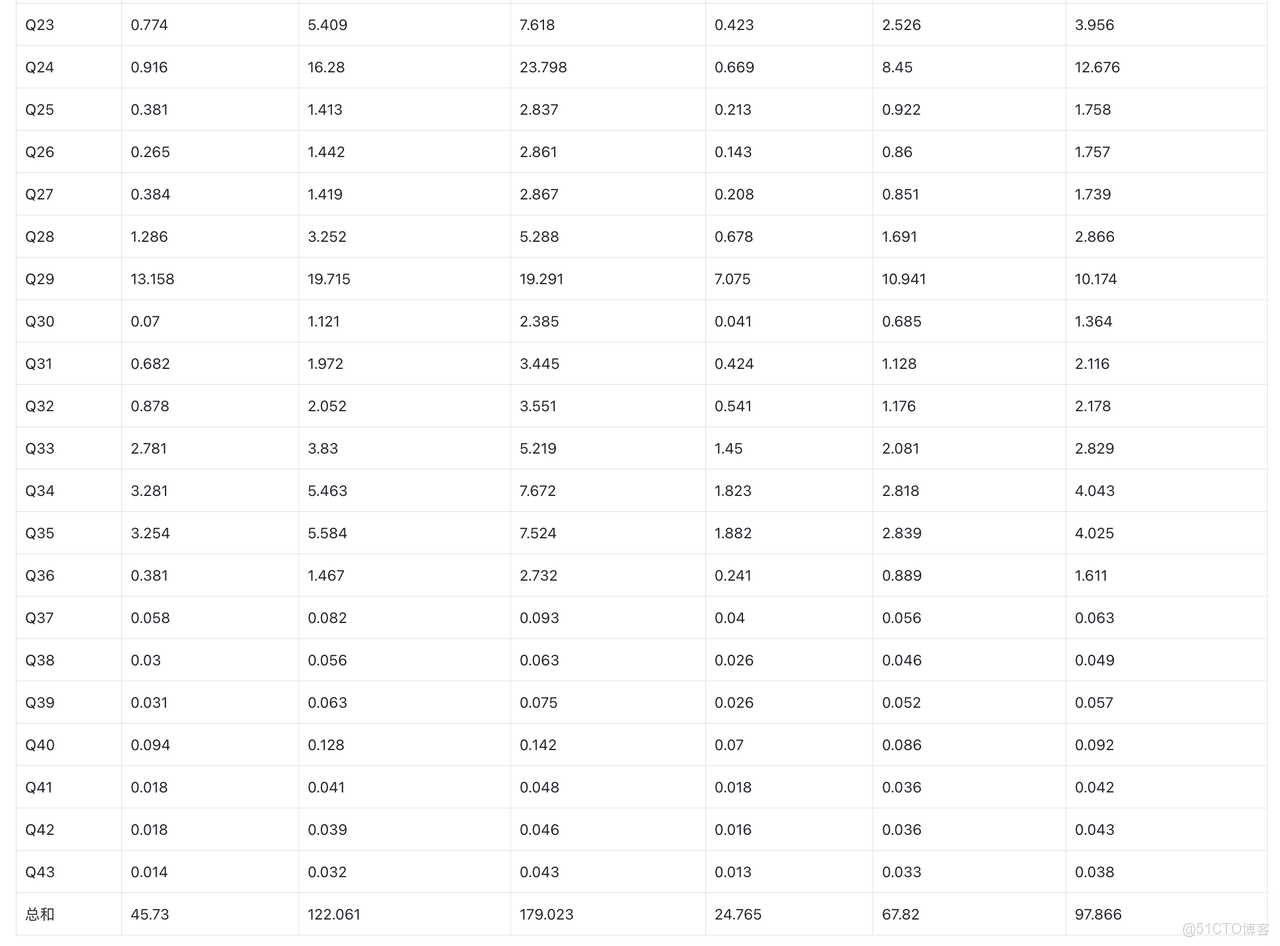
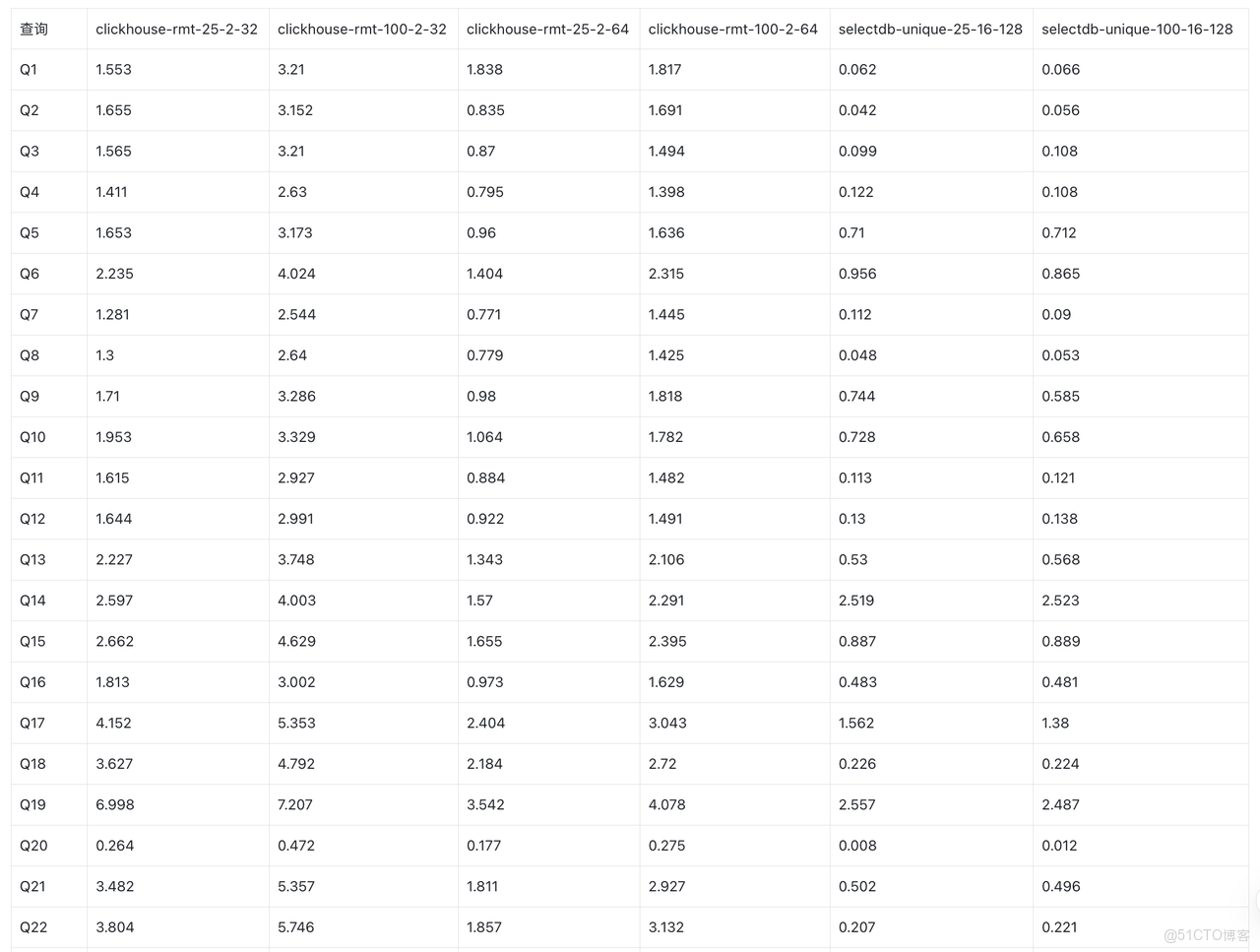
ClickHouse ReplacingMergeTree vs SelectDB UniqueKey
- SelectDB (16c 128GB)相比 ClickHouse 32c 128GB(2 replica 每個 replica 16c 64GB)
- 25% 更新比例條件下,查詢耗時低 43%
- 100% 更新比例條件下,查詢耗時低 60%
- SelectDB (16c 128GB)相比 ClickHouse 16c 64GB(2 replica 每個 replica 8c 32GB)
- 25% 更新比例條件下,查詢耗時低 68%。
- 100% 更新比例條件下,查詢耗時低 78%。
用户案例
案例一:森馬服飾(MySQL)
森馬服飾作為中國休閒服飾和童裝領域的領先企業,覆蓋線上線下全渠道零售,門店總數達到 8000+ 家。為支撐全域貨通中台項目,森馬引入阿里雲 SelectDB 替換原 Elasticsearch + 分佈式 MySQL 混合架構,統一分析 16+ 核心業務,實現複雜查詢 QPS 提升 400%,響應時間縮短至秒級。
在高併發處理場景中,阿里雲 SelectDB 憑藉 MPP 架構為森馬提供了強大的併發查詢支撐:
- 多場景併發支撐:同時支撐 2B 業務、2C 業務、直營店、加盟商等多場景下的高併發數據分析需求,複雜查詢 QPS 達到 200+ 水平。
- 資源隔離能力:基於存算分離架構,在線訂單查詢服務和離線聚合分析 BI 場景分別使用獨立計算組,避免相互干擾,確保高併發場景下系統穩定性。
- 彈性擴縮容:在直播大促等高壓力時段,可快速在線擴容應對流量激增,無需停服和數據搬遷,顯著提升應對突發高併發的靈活性。
- 統一架構簡化:替換雙系統架構,統一支持簡單過濾查詢、海量數據聚合分析、複雜多表關聯查詢,無需維護複雜業務邏輯來處理高併發多表關聯分析。
顯著收益:億級庫存流水聚合查詢縮短至 8 秒內,運維成本大幅降低,業務高峯期系統運行平穩,為全渠道運營提供可靠的高併發數據分析支撐。
完整閲讀:森馬服飾從 Elasticsearch 到阿里雲 SelectDB 的架構演進之路
案例二:天眼查(PostgreSQL)
天眼查是一家數據服務公司,為用户提供超過 3 億家企業的商業、財務和法務信息查詢服務,涵蓋 300+ 維度數據。隨着業務增長,其盡調平台需要支持內部營銷和運營團隊的即席查詢及用户分羣等新需求。該平台使用 Apache Doris 替換了原有的 Apache Hive、MySQL、Elasticsearch 和 PostgreSQL 混合架構,實現數據寫入效率提升 75%,用户分羣延遲降低 70%。
在高併發處理場景中,Apache Doris 的 MPP 架構為平台提供了強大的併發查詢支撐能力:
- 即席查詢能力:原架構每次新需求都需要在 Hive 中開發測試數據模型,寫入 MySQL 調度任務。現在 Apache Doris 擁有全量明細數據,面對新請求只需配置查詢條件即可執行即席查詢,僅需低代碼配置即可響應新需求。
- 高效用户分羣:在結果集小於 500 萬的用户分羣場景中,Apache Doris 能夠實現毫秒級響應。通過連續密集的用户 ID 映射優化,用户分羣延遲降低 70%,顯著提升高併發分羣任務處理效率。
- 統一架構簡化:消除了多組件間的複雜讀寫操作,無需預定義用户標籤,標籤可基於任務條件自動生成,大幅簡化用户分羣流程,提高 A/B 測試的靈活性。
- 穩定數據寫入:支持每天近 10 億條新數據流入,使用不同數據模型適配不同場景(MySQL 數據採用 Unique 模型,日誌數據採用 Duplicate 模型,DWS 層數據採用 Aggregate 模型)。
顯著收益:數據倉庫架構更加簡單,對開發者和運維人員更加友好,2 個 Apache Doris 集羣承載數十 TB 數據,為客户提供實時、準確的企業信息查詢服務。
完整閲讀:秒級數據寫入,毫秒查詢響應,天眼查基於 Apache Doris 構建統一實時數倉
案例三:寶舵 BOCDOP(TiDB)
寶舵是寶尊集團旗下商業化獨立品牌,擁有 1000 餘名技術工程師,為集團 8000+ 員工和全球 450+ 品牌提供電商全渠道數據分析服務。寶舵早期基於 TiDB 構建實時數倉,隨着數據量增長面臨處理效率、OLAP 擴展、成本等挑戰。通過引入 SelectDB 替換 TiDB,實現寫入速度提升 10 倍,成本直降 30% 的顯著成效。
在實時更新場景中,SelectDB 為寶舵提供了強大的實時數據處理能力,特別體現在多源數據同步方面:
- 多源異構數據實時接入:支持 100+ 業務模塊的多渠道數據實時接入,通過 Canal、Mongo-Connector、OGG 等工具獲取 MySQL、MongoDB、Oracle 等不同類型業務數據庫的 binlog,實現秒級延遲數據同步。
- 高吞吐實時寫入:利用分區分桶策略與單副本寫入機制,在雙 11 峯值時段實現每秒百萬級數據寫入,最高寫入速度從 20 萬/分提升至 230 萬/分,較傳統方案提升 10 倍。
- 流式數據處理:通過 Kafka + Flink + SelectDB 流式寫入能力,將分散在訂單、支付、物流等業務模塊的數據實時匯聚,數據同步提速 30%。
- 資源隔離保障:為"作戰室看板"單獨分配計算資源組,避免高併發查詢與實時寫入的資源爭用,確保關鍵業務查詢響應時間穩定在 500ms 內。
顯著收益:在雙 11 等大促期間數據量達平日 30-60 倍的情況下,實現數據供應 0 事故、報表服務可用性 99.9%,查詢性能提升 66%,為多渠道電商運營提供穩定的實時數據支撐。
完整閲讀:SelectDB 實時分析性能突出,寶舵成本鋭減與性能顯著提升的雙贏之旅

