

作者:曹霖
本系列文章將圍繞東南亞頭部科技集團的真實遷移歷程展開,逐步拆解 BigQuery 遷移至 MaxCompute 過程中的關鍵挑戰與技術創新。本篇為第十二篇,基於 阿里雲MaxCompute 實現BigQuery 10萬條SQL智能轉寫遷移。
注:客户為東南亞頭部科技集團,文中用 GoTerra 表示。
一、項目背景
在全球化和數字化加速的浪潮下,越來越多的企業出於成本優化、合規要求和業務協同等原因,考慮將自建或三方大數據平台遷移至阿里雲MaxCompute。本案例基於是東南亞頭部科技集團 GoTerra,其業務生態覆蓋網約車、電商、外賣、物流及金融支付等多個垂直領域,多年運行在 Google Cloud BigQuery 的數倉平台,基於綜合優勢分析規劃全量遷移至阿里雲 MaxCompute。
相比數據搬遷本身,遷移過程中一個更為棘手的挑戰是:
- 10 萬條 SQL 腳本的高質量快速轉寫。這其中既包含簡短的分析 SQL,也包含上萬行、嵌套極深的複雜 ETL 邏輯。
- 腳本廣泛使用了 BigQuery 特有的語法、函數(如
UNNEST、SAFE_CAST、FORMAT_DATE)、複雜數據類型(ARRAY、STRUCT、BIGNUMERIC)和獨有優化模式。 - 在歷史業務沉澱下,不少 SQL 邏輯與業務規則、數據模型緊密綁定,稍有不慎便會影響數據產品準確性。
傳統人力轉寫方式顯然不現實。內部測算顯示:
- 假設工程師日均高質量轉寫 5 條 SQL,則需 2 萬人天;
- 即便 100 人並行,也要近 1 年才能完成,遠超半年上線目標。
- 質量一致性無法保障,知識傳遞和規則固化存在巨大難度,迴歸測試成本高昂。
在這樣背景下,團隊必須找到 自動化+協同化的工程化解法,提升 SQL 轉換率,實現大規模、可控的遷移。
二、解決方案
整體策略
我們基於阿里雲 Cloud Migration Hub(CMH)/ Lake Migration Hub(LMH) 自動化遷移能力,配合自研規則引擎、AST(抽象語法樹)轉換、大語言模型(LLM)輔助和人工修正,構建“一條龍”的 工具主導+人工兜底 方案,並在遷移過程中沉澱可複用的 遷移知識庫。
遷移整體分為兩大階段:
- 數據遷移:將 BigQuery 表數據平滑搬遷到 MaxCompute(包括全量及後續增量),使用在線遷移、MMS(MaxCompute Migration Serverless) 等。
- SQL 轉寫:藉助 CMH/LMH 自動化批量轉換 SQL,並通過規則迭代、LLM 增強、人工修正,實現高準確率交付。
數據遷移與SQL轉寫遷移方案的技術實現與優化
基於阿里雲Cloud Migration Hub(CMH)/Lake Migration Hub(LMH)的自動化遷移能力,結合自主研發的規則引擎、抽象語法樹(AST)轉換技術、大語言模型(LLM)輔助及人工修正機制,我們構建了一套“工具主導+人工兜底”的端到端遷移解決方案。該方案不僅實現了從數據層到應用層的全棧遷移,還通過遷移知識庫的持續沉澱,顯著提升了遷移效率與準確性。遷移過程分為以下兩個核心階段:
第一階段:數據遷移——保障數據平滑過渡的全生命週期管理
數據遷移是整個遷移工程的基礎,其核心目標是將源端BigQuery的數據無縫遷移到阿里雲MaxCompute,並確保遷移過程的高可用性、一致性和可擴展性。
工具與架構:採用阿里雲在線遷移工具(Online Migration)和MMS(MaxCompute Migration Serverless)進行全量數據遷移。在線遷移工具通過分佈式架構實現高吞吐量傳輸,支持斷點續傳和錯誤重試機制,確保大規模數據(如PB級)的穩定遷移。MMS則通過Serverless服務化模式,按需分配計算資源,降低運維複雜度。
第二階段:SQL轉寫——自動化與人工協同的智能轉換
SQL轉寫是遷移過程中技術難度最高的環節,涉及語法、函數、UDF(用户定義函數)及性能優化的複雜轉換。我們通過“自動化為主,人工為輔”的分層策略,結合AST分析、規則引擎和LLM技術,實現高準確率的SQL轉換。
1. 自動化轉換引擎
- AST語法樹解析:基於ANTLR或自研解析器構建BigQuery SQL的抽象語法樹(AST),逐層分析語法結構。例如,將BigQuery的
SELECT APPROX_COUNT_DISTINCT(column)轉換為MaxCompute的SELECT COUNT(DISTINCT column),並通過AST節點替換實現。 - 規則引擎迭代優化:
- 內置規則庫:預置超過200條遷移規則,覆蓋數據類型映射(如BigQuery的
TIMESTAMP→MaxCompute的DATETIME)、函數替換(如SAFE函數的兼容性處理)、窗口函數調整等場景。 - 動態規則擴展:通過遷移知識庫的實時反饋,持續迭代規則庫。例如,若發現某類CASE-WHEN嵌套語句轉換失敗,可立即新增規則並重新運行轉換流程。
- LLM輔助轉換:針對複雜或模糊的SQL語句(如自定義UDF或依賴源端特定語法的查詢),利用大語言模型(如通義千問)進行語義解析和意圖理解。例如,將BigQuery的
STRUCT類型轉換為MaxCompute的LATERAL VIEW表達式,LLM可輔助生成等效邏輯的SQL代碼。
2. 人工修正與質量控制
- 自動化缺陷定位:通過靜態代碼分析工具和動態執行測試(在測試環境中運行轉換後的SQL),快速定位轉換失敗的語句。例如,若轉換後的SQL在MaxCompute執行時因類型不匹配報錯,系統將標記該SQL並提示可能的修復方向。
- 專家介入流程:
- 優先級分級:根據錯誤類型(如語法錯誤、性能隱患、業務邏輯偏差)和影響範圍,將問題分為P0-P3等級,優先處理高風險缺陷。
- 協同開發環境:提供基於IDE的聯機調試工具,允許開發者直接修改轉換後的SQL,並通過版本控制系統(如Git)管理修改記錄,確保可追溯性。
- 遷移知識庫的閉環反饋:每次人工修正後,系統自動提取修正前後的SQL差異,並將其歸類為新規則或案例存入知識庫。例如,若某次修正解決了BigQuery的
ARRAY_AGG到MaxCompute的COLLECT_SET轉換問題,該規則將被優先級提升,並在後續遷移中自動應用。
3. 轉換後驗證與優化
- 功能驗證:在測試集羣中執行轉換後的SQL,對比源端和目標端的查詢結果,確保業務邏輯一致性。
- 性能調優:利用MaxCompute的執行計劃分析工具,識別轉換後SQL的性能瓶頸(如全表掃描、Join順序不當),並通過索引優化、分區裁剪或謂詞下推等手段提升效率。
- 遷移知識庫的持續優化:將驗證過程中發現的性能優化策略(如特定函數轉換方式)補充至知識庫,形成“遷移-修正-優化”的閉環。
遷移知識庫的核心價值與應用場景
遷移知識庫是整個方案的關鍵支撐,其價值體現在以下方面:
- 規則複用與加速迭代:通過積累遷移規則、缺陷案例和最佳實踐,新項目可直接調用知識庫中的已有規則,減少重複性開發。例如,某金融客户在遷移過程中發現BigQuery的
DATE_TRUNC函數在MaxCompute中需配合DATE_FORMAT使用,該規則可直接複用至其他項目。 - 風險預判與質量提升:知識庫中的歷史案例可輔助遷移前的風險評估,例如提前識別BigQuery的
ML_*機器學習函數在MaxCompute中的替代方案,避免遷移後期的返工。 - 跨團隊協作與知識傳承:知識庫採用統一的Markdown格式和分類標籤(如按場景、工具、複雜度分類),支持多團隊並行查閲與貢獻,降低隱性知識流失風險。
技術優勢與遷移成效
通過上述技術方案,我們實現了以下顯著優勢:
- 遷移效率提升:相比純人工遷移,自動化工具將SQL轉寫效率提升80%以上,單項目遷移週期從數年縮短至數月。
- 準確性保障:結合規則引擎與LLM的雙通道驗證,部分場景SQL轉換準確率超過90%,人工修正僅需處理約10%的複雜場景。
- 成本優化:通過MMS的Serverless模式和按需計費機制,降低數據遷移成本,同時減少因停機遷移導致的業務損失。
三、核心技術
1. SQL 轉換主流技術:AST 驅動
相比複雜且易出錯的正則/模板替換,AST 驅動的 SQL 轉換具備可擴展、高可維護等優勢:
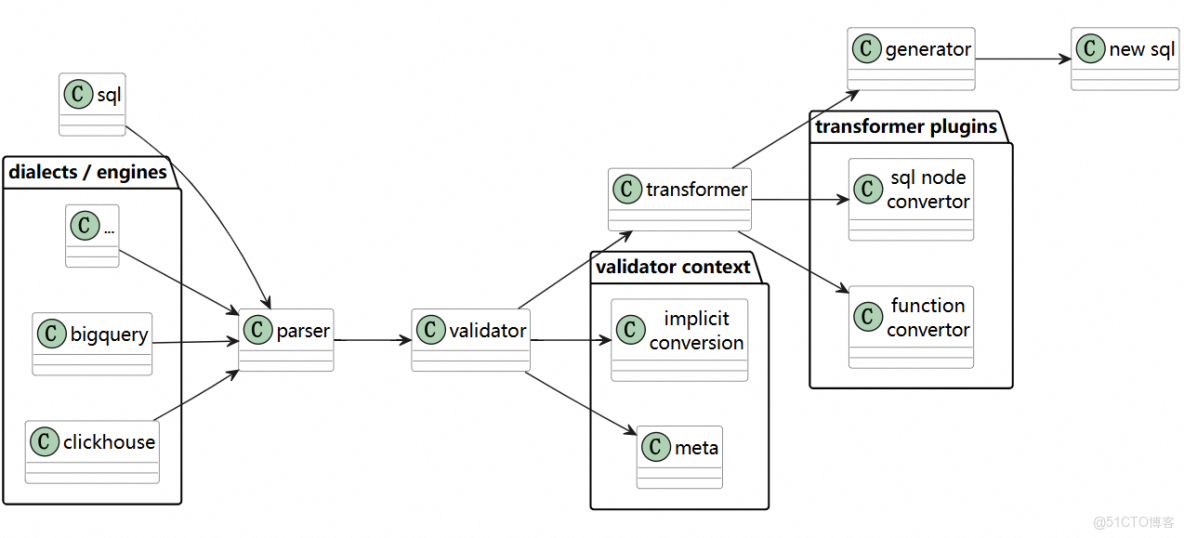
流程:
- Parse:將 BigQuery SQL 解析為抽象語法樹(AST),保留結構和節點類型(SELECT、FROM、FUNCTION_CALL 等)。
- Transform:按規則庫替換/重構 AST 節點,例如:
FORMAT_DATE('%Y-%m-%d', col)→TO_CHAR(col, 'yyyy-MM-dd')UNNEST(array_col)→LATERAL VIEW EXPLODE(array_col)- 隱式類型轉換規則修正
- Generate:輸出目標 MaxCompute SQL。
優勢:
- 對複雜嵌套、長 SQL 穩定性高
- 易於增量維護規則
- 可結合類型系統和元數據增強(RAG 思路)
2. SQL 轉換示例
BigQuery SQL:
SELECT FORMAT_DATE('%Y-%m-%d', order_time) AS order_date,
COUNT(DISTINCT user_id) AS uv
FROM `project.dataset.orders`
WHERE order_time >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY order_date;MaxCompute SQL:
SELECT TO_CHAR(order_time, 'yyyy-MM-dd') AS order_date,
COUNT(DISTINCT user_id) AS uv
FROM orders
WHERE order_time >= DATEADD(CURRENT_DATE, -30)
GROUP BY order_date;映射規則:
FORMAT_DATE→TO_CHAR(參數位置調整)DATE_SUB→DATEADD(順序/符號兼容)- 去除 BigQuery 數據集前綴
- 類型映射:DATE 保持一致,BIGINT 替換 INT64
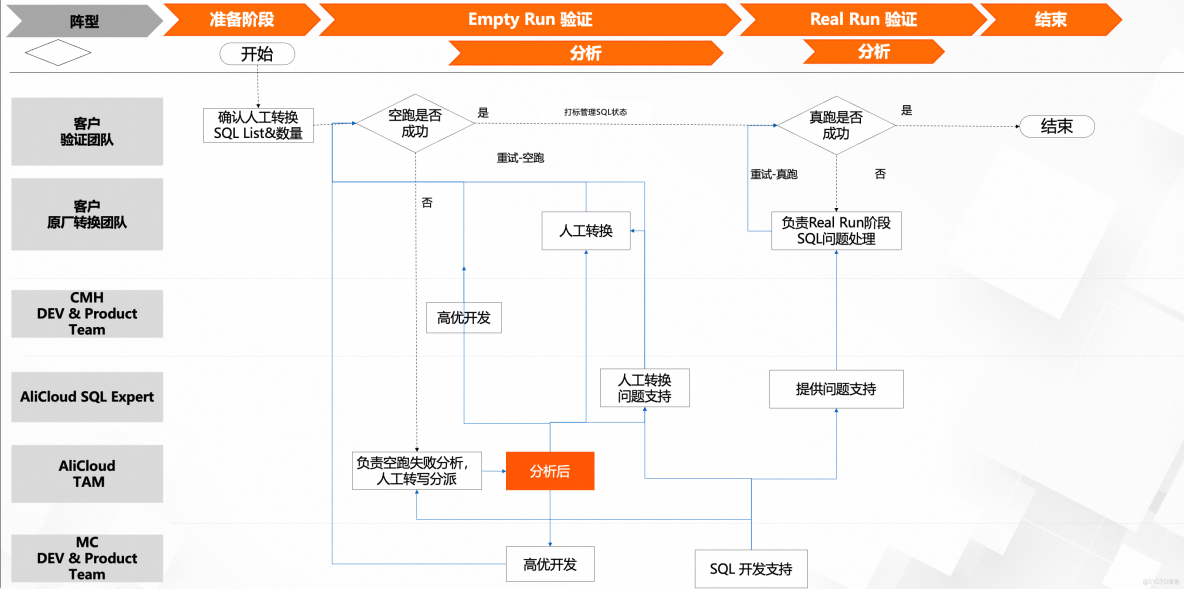
3. SQL轉寫流程
4. 行業實踐與趨勢
在多家企業的跨雲 SQL 遷移中,總結出幾條趨勢:
- AST+規則庫 是工程實踐中相對高效可控的技術路徑
- LLM 加持的混合模式 在處理尾部長尾複雜 SQL 時展現價值
- 知識庫驅動持續優化 可複用性強,提升 ROI
- 平台自適配增強 比單純靠轉換器更能保障業務一致性
四、小結與未來展望
本項目成果:
- 在 4 個月內完成 SQL 轉寫任務,比計劃提前 1 個月上線
- 工具轉換率從 5%→80%,人工成本下降 70%+
- 沉澱上千條規則和案例,形成可複用的 SQL 遷移知識庫
- 平台能力增強,提升未來兼容性
展望:
- 推動 CMH/LMH 全自動化遷移平台,支持更多方言(Snowflake、Databricks 等)
- 引入在線實時 SQL 轉換 API,支持多雲混合分析
- 結合執行計劃與成本模型的自動化 SQL 優化器
- 依託知識庫與 RAG 提高 LLM 轉換一致性與可解釋性
參考研究:
- 《Mallet: SQL Dialect Translation with LLM Rule Generation》




