
C語言自定義變量類型結構體理論:從初見到精通
延續上篇文章,本文將為大家帶來C語言結構體的更多更深入的內容
一,結構體的自引用
在瞭解自引用之前,我們先解釋一下線性數據結構之一的“鏈表”
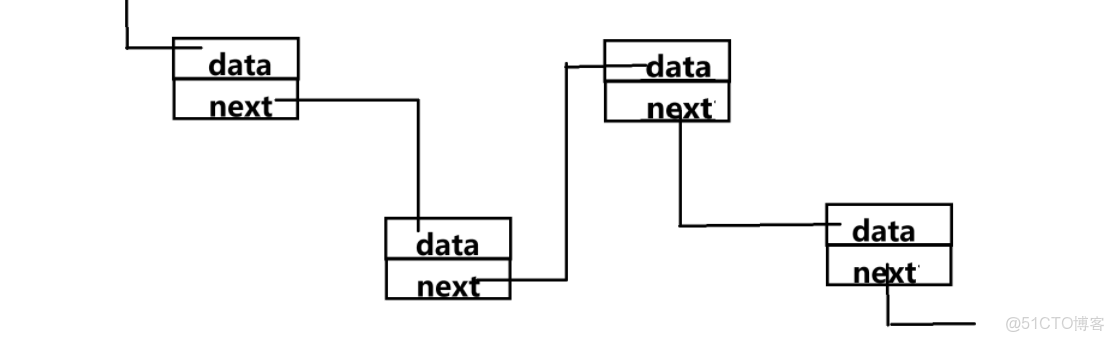
鏈表:顧名思義,每個數據之間通過一種鏈式鏈接形成的一種數據結構。在這樣的結構中,每一個數據塊(我們稱之為結點)需要具備兩種能力:存放數據和找到下一個結點。
因此,結構體剛好可以勝任這份工作:
我們可以寫一個結構體來介紹
struct Node
{
int data;//存放數據
struct Node*next;//指向下一個結點
};這個結構體有兩個成員變量:
存放數據的變量我們稱之為:數據域
存放下一個結點指針的變量我們稱之為:指針域
結構體可以找到下一個同類型結構體的這種操作,我們稱之為:“結構體的自引用”。
這樣,結構體就可以通過自引用找到鏈表中的所有元素了。
二,結構體的內存對齊
至此:我們已經掌握了結構體的所有基本操作了
接下來,讓我們思考一個問題:計算結構體的內存大小。
事實上當我們直接計算結構體的內存時會遇到這樣的問題:
struct S1
{
char c1;
int i;
char c2;
};
printf("%d\n", sizeof(struct S1));如果運行,那麼計算結果一定會出乎你的預料:是的,結果是8而不是6.
為什麼會出現這種情況呢:
事實上,結構體內部存在對齊現象。
在解釋這個問題之前,我們需要了解一點別的東西:
1,偏移量:

如圖,我們把這樣一張圖看作是內存的一個片段(用來存放結構體),
在內存中,我們定義開始存放數據的位置叫起始位置
以這個位置為基準,自上而下存儲數據,每個格子代表一字節。
每個字節相對於起始位置的距離我們稱之為:偏移量(如圖)
2,offsetof宏
offsetof宏用於計算結構體成員相對於結構體成員相對於結構體變量的偏移量
offsetof
offsetof (type,member)
Return member offset
This macro with functional form returns the offset value in bytes of member member in the data structure or union type type.
The value returned is an unsigned integral value of type size_t with the number of bytes between the specified member and the beginning of its structure.Return value
A value of type size_t with the offset value of member in type.
這是對C-library原文的引用,可知,
offsetof宏有兩個參數:結構體類型名和結構體成員變量名
返回值:偏移量(size_t類型)
應用舉例:
struct S1
{
char c1;
int i;
char c2;
};
size_t test=offsetof(struct S1,c1);
printf("%zu",test);瞭解了這麼多之後,讓我們正式探討結構體對齊的內涵。
3,結構體的對齊規則
1. 結構體的第⼀個成員對⻬到和結構體變量起始位置偏移量為0的地址處。
2, 其他成員變量要對⻬到某個數字(對⻬數)的整數倍的地址處。
對齊數=編譯器默認的⼀個對⻬數與該成員變量⼤⼩的較⼩值。
VS 中默認的值為 8。
Linux中gcc沒有默認對⻬數,對⻬數就是成員⾃⾝的⼤⼩。
3. 結構體總⼤⼩為最⼤對⻬數(結構體中每個成員變量都有⼀個對⻬數,所有對⻬數中最⼤的)的 整數倍。
4. 如果嵌套了結構體的情況,嵌套的結構體成員對⻬到⾃⼰的成員中最⼤對⻬數的整數倍處,結構 體的整體⼤⼩就是所有最⼤對⻬數(含嵌套結構體中成員的對⻬數)的整數倍。
我們用兩個例子來解釋這些規則
struct S2
{
char c1;
char c2;
int i;
};
printf("%d\n", sizeof(struct S2));
根據規則,因為char類型的大小是一個字節,其倍數可以是所有正整數,
char1放在偏移0的位置,char2放在偏移1的位置。
int的大小是4個字節,VS默認對齊數是8,8>4,對齊數是4,在偏移4開始向後4個字節。
最後整個內存的大小是8個字節是4的倍數,不需要補充空缺。
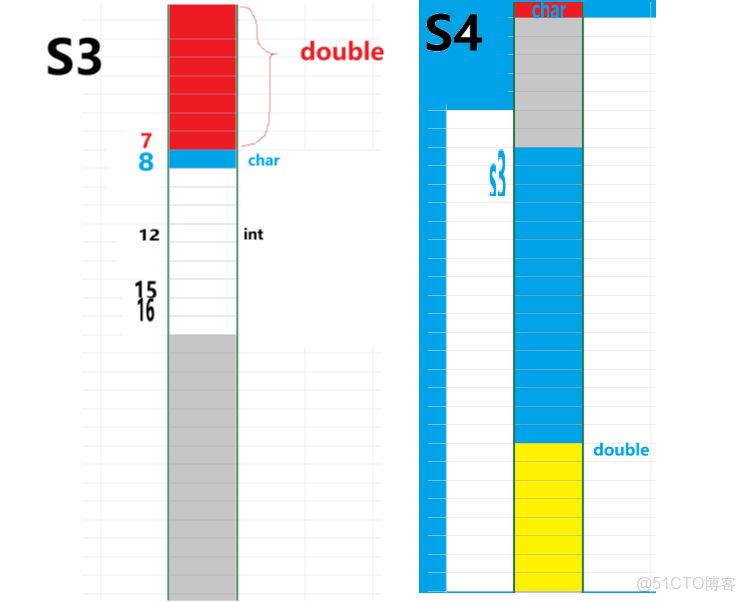
struct S3
{
double d;
char c;
int i;
};
struct S4
{
char c1;
struct S3 s3;
double d;
};
printf("%d\n", sizeof(struct S4));看代碼,
double類型的d佔8個字節。char類型的c佔1個字節。int類型的i佔4個字節。
由於字節對齊規則,double 類型要求8字節對齊,char 類型後會填充3字節,使得 int 類型從第 8 + 1 + 3 = 12 字節開始,最終 struct S3 的大小為 8 + 1 + 3 + 4 = 16 字節
char類型的c1佔1個字節。struct S3類型的s3佔16個字節。double類型的d佔8個字節。
char 類型後需要填充7字節以滿足 struct S3 的8字節對齊要求,struct S3 本身大小為16字節,之後 double 類型直接從第 1 + 7 + 16 = 24 字節開始,因此 struct S4 的大小為 1 + 7 + 16 + 8 = 32 字節 。
4, 為什麼存在內存對⻬?
⼤ 部分的參考資料都是這樣説的:
1. 平台原因(移植原因): 不是所有的硬件平台都能訪問任意地址上的任意數據的;某些硬件平台只能在某些地址處取某些特定 類型的數據,否則拋出硬件異常。
2. 性能原因: 數據結構(尤其是棧)應該儘可能地在⾃然邊界上對⻬。原因在於,為了訪問未對⻬的內存,處理器需要 作兩次內存訪問;⽽對⻬的內存訪問僅需要⼀次訪問。假設⼀個處理器總是從內存中取8個字節,則地 址必須是8的倍數。如果我們能保證將所有的double類型的數據的地址都對⻬成8的倍數,那麼就可以 ⽤⼀個內存操作來讀或者寫值了。否則,我們可能需要執⾏兩次內存訪問,因為對象可能被分放在兩 個8字節內存塊中。
總體來説:結構體的內存對⻬是拿空間來換取時間的做法。
那在設計結構體的時候,我們既要滿⾜對⻬,⼜要節省空間,如何做到:
讓 佔⽤空間⼩的成員儘量集中在⼀起
5,修改默認對⻬數
#pragma 這個預處理指令,可以改變編譯器的默認對⻬數。
#include
#pragma pack(1)//設置默認對⻬數為1
struct S
{
char c1;
int i;
char c2;
};
#pragma pack()//取消設置的對⻬數,還原為默認
int main()
{
printf("%d\n", sizeof(struct S));
return 0;
}如代碼:通過#pragma(1)指令將默認對齊數改成1,通過#pragma()恢復指令。
三,補充一下結構體傳參的內容
函數傳參的時候,參數是需要壓棧,會有時間和空間上的系統開銷。
如果傳遞⼀個結構體對象的時候,結構體過⼤,參數壓棧的的系統開銷⽐較⼤,所以會導致性能的下降。
結論: 結構體傳參的時候,要傳結構體的地址而不是結構體。
四,結構體與位段
1,什麼是位段
位段的聲明和結構是類似的,有兩個不同:
1. 位段的成員必須是 int 、 unsigned int 或 signed int ,
(在C99中位段成員的類型也可以 選擇其他類型。)
2. 位段的成員名後邊有⼀個冒號和⼀個數字。
舉例
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};A就是⼀個位段類型。
2,位段的內存分配
1. 位段的成員可以是 int unsigned int
2. 位段的空間上是按照需要以4個字節( signed int 或者是 char 等類型 int )或者1個字節( char )的⽅式來開闢的。
3. 位段涉及很多不確定因素,位段是不跨平台的,注重可移植的程序應該避免使⽤位段。
舉例
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;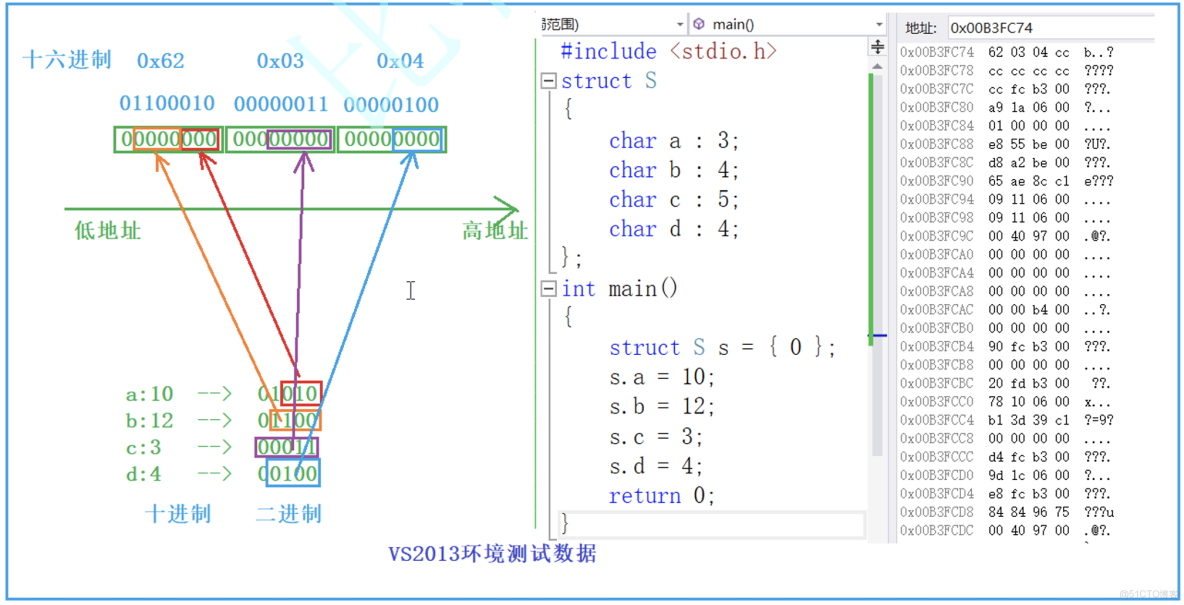
3,位段的跨平台問題
1. int 位段被當成有符號數還是⽆符號數是不確定的。
2. 位段中最⼤位的數⽬不能確定。(16位機器最⼤16,32位機器最⼤32,寫成27,在16位機器會 出問題。
3. 位段中的成員在內存中從左向右分配,還是從右向左分配,標準尚未定義。
4. 當⼀個結構包含兩個位段,第⼆個位段成員⽐較⼤,⽆法容納於第⼀個位段剩餘的位時,是捨棄 剩餘的位還是利⽤,這是不確定的。
總結: 跟結構相⽐,位段可以達到同樣的效果,並且可以很好的節省空間,但是有跨平台的問題存在。
4,位段的應⽤
下圖是⽹絡協議中,IP數據報的格式,我們可以看到其中很多的屬性只需要⼏個bit位就能描述,這⾥ 使⽤位段,能夠實現想要的效果,也節省了空間,這樣⽹絡傳輸的數據報⼤⼩也會較⼩⼀些,對⽹絡 的暢通是有幫助的
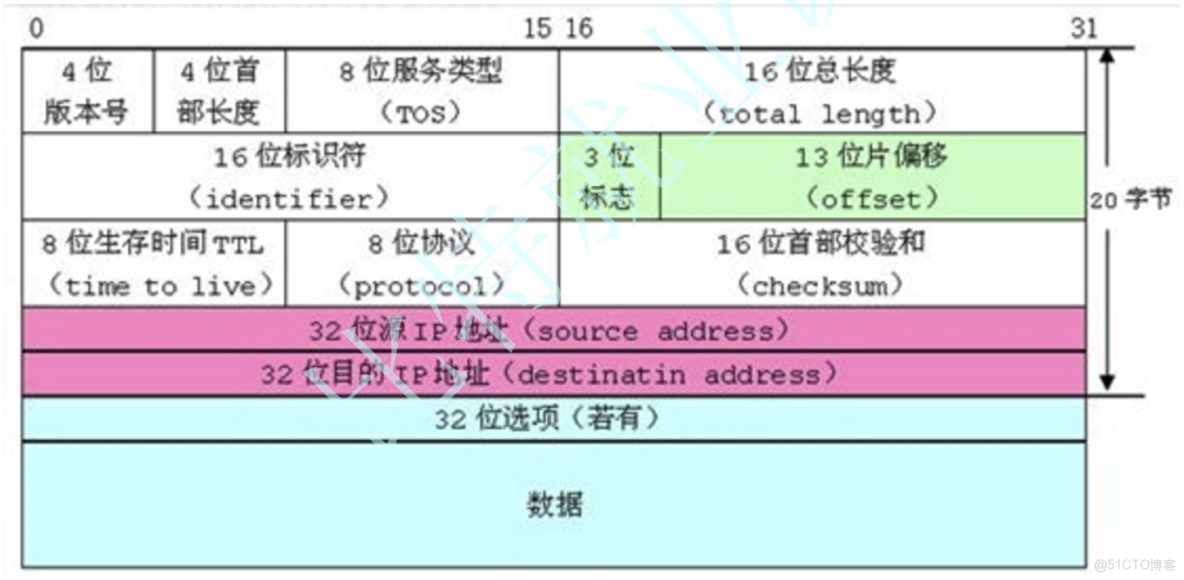
5,位段使⽤的注意事項
位段的⼏個成員共有同⼀個字節,這樣有些成員的起始位置並不是某個字節的起始位置,那麼這些位 置處是沒有地址的。
內存中每個字節分配⼀個地址,⼀個字節內部的bit位是沒有地址的。
所以不能對位段的成員使⽤&操作符,這樣就不能使⽤scanf直接給位段的成員輸⼊值,只能是先輸⼊ 放在⼀個變量中,然後賦值給位段的成員。
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
struct A sa = {0};
scanf("%d", &sa._b);//這是錯誤的
//正確的⽰範
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}
