目錄
摘要
1.auto-encoder概念
2.auto-encoder優勢
3.de-nosing auto-encoder
1.auto-encoder概念
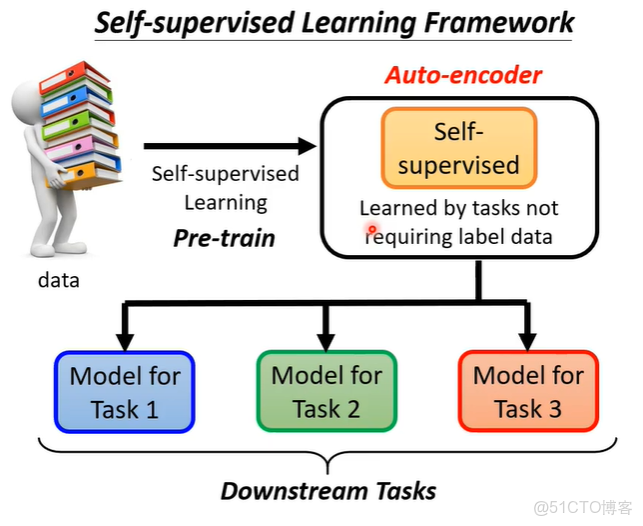
auto-encoder也算是self-supervised learning的一環,簡單複習一下self-supervised learning。我們有大量沒標註的資料,用這些資料可以訓練一個模型(BRET可以做填空題,GPT系列可以預測下一個token),之後可以把這個模型用在下游任務中。在BERT和GPT之前,有一個同樣不需要標註資料的任務,就是auto-encoder。
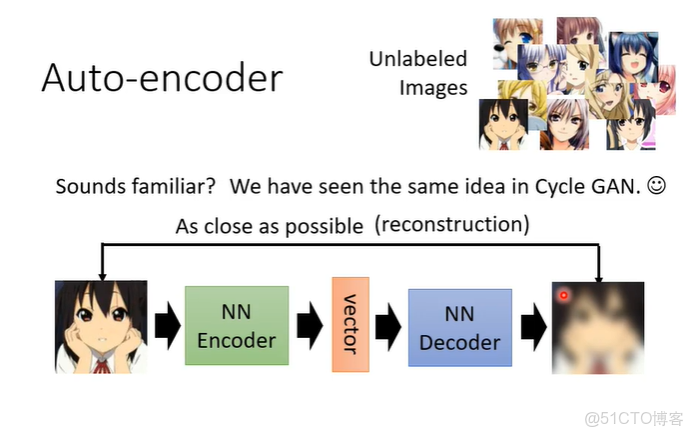
用影像舉例,假設有大量的圖片在auto-encoder中,在auto-encoder有兩個network,一個encoder,一個decoder。encoder將一張圖片讀進來輸出一個向量,即encoder將圖片變成一個向量,這個向量再作為decoder的輸入,decoder會產生一張圖片,訓練的目標是encoder的輸入與decoder的輸出越接近越好。這個概念與cycle GAN有些類似。
2.auto-encoder優勢
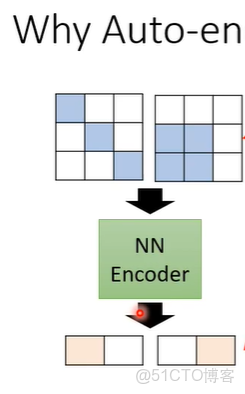
假設一個3x3的圖片變為2維的向量,再還原。那麼怎麼樣從9個數值變為2個數值,再還原為9個數值呢?因為對於影像來説不是所有3x3的矩陣都是圖片,圖片的變化是有限的,雖然圖片是3x3但是實際上他的變化可能只有2種類型。
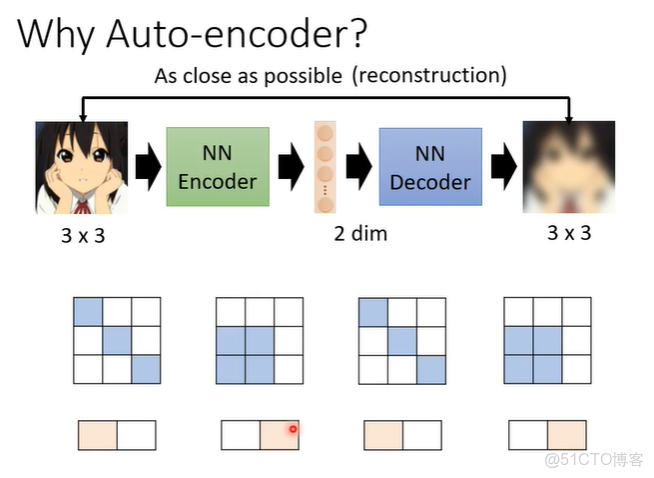
當我們把一個高維度的圖片變成低維度的向量時,只要找出它有限的變化,就可以把本來複雜的東西用比較簡單的方法來表示。如果可以把複雜的圖片用簡單的方法表示,那在下游任務中就只需要較少的訓練資料,就可以讓機器學到本來要它學的事情。
3.de-nosing auto-encoder
de-nosing auto-encoder是auto-encoder的一個變形,它把原來輸入的圖片加上一些雜訊,之後一樣通過encoder變為向量,再通過decoder把他還原回來,但是要還原的不是encoder的輸入而是加入雜訊前的圖片。這樣就多了一個任務,除了還原圖片之外,還需要自己學會如何去除雜訊。
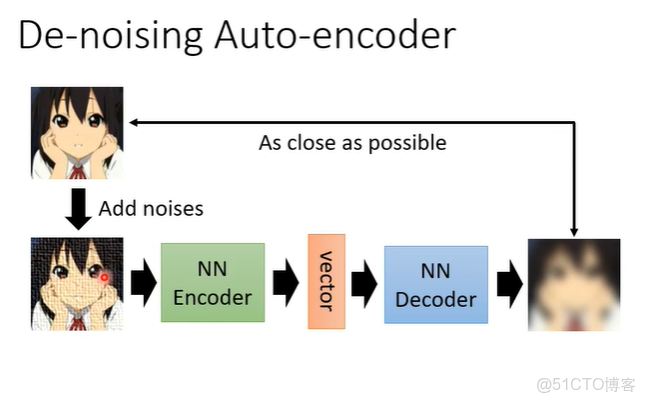
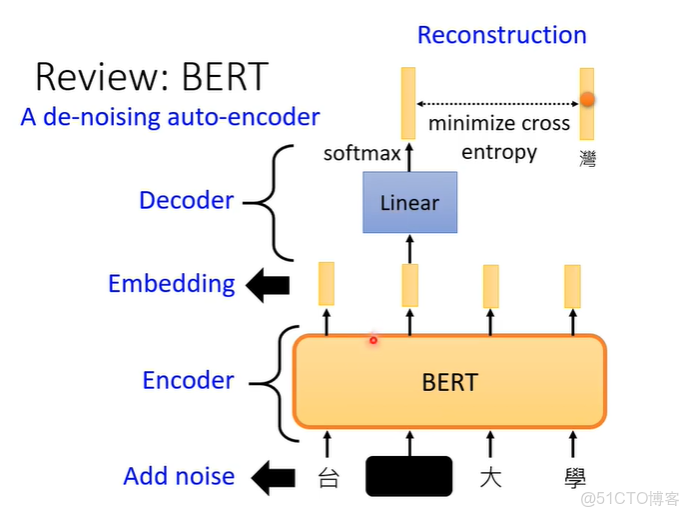
其實今天的BERT也可以看作是de-nosing auto-encoder。輸入我們會加mask,那些mask就是noise,BERT的模型就是encoder,輸出就是embedding,接下來linear 的模型就是decoder,它要做的就是還原原來的句子,也就是把原來被蓋住的部分還原。