
零、Tricks集宜
0.1 知識搬運
- (1)PyTorch提速
- 預處理提速
- IO提速
- 訓練策略
- 代碼層面
- 模型設計
- 推理加速
- 時間分析
- 項目推薦
- 擴展閲讀
- (2)PyTorch節省顯存
- 儘量使用 inplace 操作
- 刪除loss
- 混合精度
- 對不需要反向傳播的操作進行管理
- 顯存清理
- 梯度累加
- 使用 checkpoint 技術
- torch.utils.checkpoint
- Training Deep Nets with Sublinear Memory Cost
- 相關工具
- 參考資料
- (3)其他技巧
- 重現
- 強制確定性操作
- 設置隨機數種子
0.2 Tricks輯要
0.2.1 訓練加速方法
(1)增大 batchsize 或者使用梯度累積
參考:I. Hugging Face 的 Thomas Wolf 的Medium文章《Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups》介紹瞭如何使用梯度累積;
II. Medium文章《What is Gradient Accumulation in Deep Learning?》
方法A. 把 batchsize 調到最大是一個頗有爭議的觀點。一般來説,如果在 GPU 內存允許的範圍內將 batchsize 調到最大,你的訓練速度會更快。但是,你也必須調整其他超參數,比如學習率。一個比較好用的經驗是,batchsize 大小加倍時,學習率也要加倍。
OpenAI 的論文《An Empirical Model of Large-Batch Training》很好地論證了不同的 batchsize 大小需要多少步才能收斂,在《How to get 4x speedup and better generalization using the right batch size》一文中,作者 Daniel Huynh 使用不同的 batchsize 大小進行了一些實驗,最終,他將 batchsize 大小由 64 增加到 512,實現了 4 倍的加速。然而,使用大 batchsize 的不足是,這可能導致解決方案的泛化能力比使用小 batchsize 的差。
方法B. 增加 batchsize 大小的另一種方法是在調用 optimizer.step() 之前在多個loss. backward() 傳遞中累積梯度,這個方法主要是為了規避 GPU 內存的限制而開發的。累積梯度的計算示意圖如下:
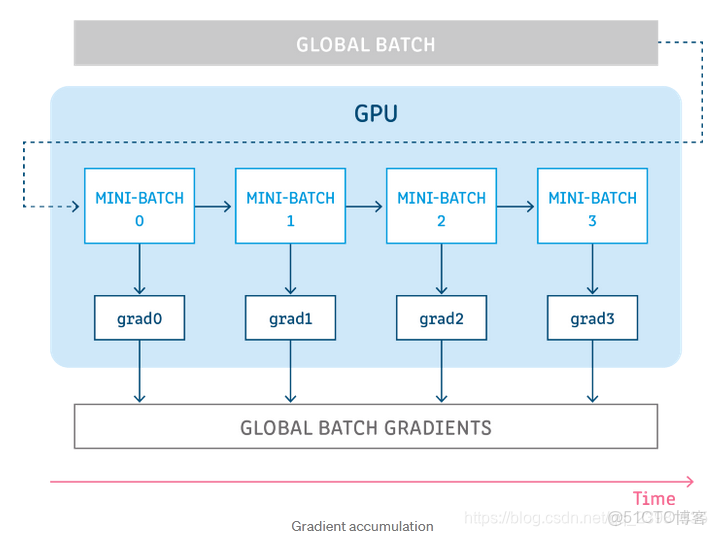
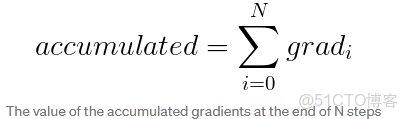
梯度累積可以通過如下方式實現:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged),即如果您使用的是在訓練樣本上平均的損失(大多數是這種情況),則必須除以梯度累積的step數量
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated(2)設置 torch.backends.cudnn.benchmark=True
參考——知乎《torch.backends.cudnn.benchmark ?!》,該文詳細該語句加置的地方及耗時測評;
cuDNN使用非確定性算法,並且可以使用torch.backends.cudnn.enabled = False來進行禁用,如果設置為torch.backends.cudnn.enabled =True,説明設置為使用使用非確定性算法,然後再設置:
torch.backends.cudnn.benchmark = true那麼cuDNN使用的非確定性算法就會自動尋找最適合當前配置的高效算法,來達到優化運行效率的問題。
一般來講,應該遵循以下準則:
- 如果網絡的輸入數據維度或類型上變化不大,設置torch.backends.cudnn.benchmark = true 可以增加運行效率;但是,如果您的模型發生了變化:例如,如果某些層僅在滿足某些條件時才被“激活”,或者您的循環中的層可以重複不同的次數,則設置torch.backends.cudnn.benchmark = true 可能會使您的執行停頓。〖注意:benchmark模式會提升計算速度,但是由於計算中有隨機性,每次網絡前饋結果略有差異。如果想要避免這種結果波動,設置:
torch.backends.cudnn.deterministic = True保證實驗的可重複性。〗 - 如果網絡的輸入數據在每次 iteration (1個iteration等於使用batchsize個樣本訓練一次)都變化的話,會導致 cnDNN 每次都會去尋找一遍最優配置,這樣反而會降低運行效率。即適用場景是網絡結構固定(不是動態變化的),網絡的輸入形狀(包括 batch size,圖片大小,輸入的通道)是不變的,其實也就是一般情況下都比較適用。反之,如果卷積層的設置一直變化,將會導致程序不停地做優化,反而會耗費更多的時間。
(3)使用. as_tensor() 而不是. tensor()
torch.tensor() 總是會複製數據。如果你要轉換一個 numpy 數組,使用 torch.as_tensor() 或 torch.from_numpy() 來避免複製數據。
0.2.2 設置種子seed保證實驗的可重複性
在神經網絡中,參數默認是進行隨機初始化的。如果不設置的話每次訓練時的初始化都是隨機的,導致結果不確定。如果設置初始化,則每次初始化都是固定的。
if args.seed is not None:
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed) #為當前GPU設置隨機種子;如果使用多個GPU,應該使用torch.cuda.manual_seed_all(args.seed)為所有的GPU設置種子
np.random.seed(args.seed)
random.seed(args.seed)
torch.backends.cudnn.benchmark = False #避免使用不確定性尋優算法
torch.backends.cudnn.deterministic = True #固定cuda的隨機數種子。torch.backends.cudnn.deterministic是啥?顧名思義,將這個 flag 置為True的話,每次返回的卷積算法將是確定的,即默認算法。如果配合上設置 Torch 的隨機種子為固定值的話,應該可以保證每次運行網絡的時候相同輸入的輸出是固定的一、 nn.Module VS nn.functional
(1)兩者區別
大部分nn中的層class都有nn.function對應,其區別是:
- nn.Module實現的layer是由class Layer(nn.Module)定義的特殊類,會自動提取可學習參數nn.Parameter;
- nn.functional中的函數更像是純函數,由def function(input)定義。
由於兩者性能差異不大,所以具體使用取決於個人喜好。對於激活函數和池化層,由於沒有可學習參數,一般使用nn.functional完成,其他的有學習參數的部分則使用類。但是Droupout由於在訓練和測試時操作不同,所以建議使用nn.Module實現,它能夠通過model.eval加以區分。
(2)搭配使用nn.Module和nn.functional
並不是什麼難事,之前有接觸過,nn.functional不需要放入__init__進行構造,所以不具有可學習參數的部分可以使用nn.functional進行代替。例如:
# Author : Hellcat
# Time : 2018/2/11
import torch as t
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x(3)nn.functional函數構造nn.Module類
由於nn.functional和nn.Module兩者主要的區別就是對於可學習參數nn.Parameter的識別能力,所以構造時添加了識別能力即可:
class Linear(nn.Module):
def __init__(self, in_features, out_features):
# nn.Module.__init__(self)
super(Linear, self).__init__()
self.w = nn.Parameter(t.randn(out_features, in_features)) # nn.Parameter是特殊Variable
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
# wx+b
return F.linear(x, self.w, self.b)
layer = Linear(4, 3)
input = V(t.randn(2, 4))
output = layer(input)
print(output)結果:
Variable containing:
1.7498 -0.8839 0.5314
-2.4863 -0.6442 1.1036
[torch.FloatTensor of size 2x3]二、nn.Parameter
PyTorch中的nn.Parameter類一個重要類,是Tensor的子類,定義為:class Parameter(torch.Tensor) 。令我驚訝的是,該類相關介紹在PyTorch教程中卻很少涉及。考慮以下全連接網絡模型的情況:
class net(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10,5)
def forward(self, x):
return self.linear(x)
myNet = net()
#prints the weights and bias of Linear Layer
print(list(myNet.parameters()))
#
'''
輸出
[Parameter containing:
tensor([[-0.1939, -0.2430, 0.0387, -0.2462, -0.0700, -0.0044, -0.0579, 0.0455,
-0.1914, 0.1268],
[-0.3100, -0.0877, 0.0519, 0.0234, 0.1073, 0.0912, 0.2233, 0.1715,
-0.1262, -0.0172],
[ 0.1459, -0.2765, 0.0401, -0.1624, 0.1423, -0.0781, 0.1027, -0.3040,
0.0215, 0.1991],
[-0.1773, -0.1894, -0.2755, -0.1385, 0.2424, -0.2276, 0.1285, -0.0502,
0.3129, -0.1826],
[ 0.1223, 0.1369, -0.1857, 0.1691, -0.1494, -0.1231, 0.0107, -0.1066,
-0.1654, 0.1744]], requires_grad=True), Parameter containing:
tensor([-0.1026, 0.3150, 0.1575, -0.0340, -0.2059], requires_grad=True)]
'''
for name,param in myNet.named_parameters():
print(f'{name}: {param}')
'''
輸出
linear.weight: Parameter containing:
tensor([[ 0.0788, -0.2255, 0.0154, 0.0445, -0.0953, 0.1999, -0.1963, 0.0500,
-0.0791, 0.0476],
[-0.1811, -0.0784, -0.1843, -0.1321, 0.1952, -0.2358, 0.1211, 0.2801,
-0.3048, -0.2656],
[-0.2316, -0.1713, 0.1449, 0.1743, -0.1630, -0.0036, -0.0988, -0.1806,
-0.2890, -0.1662],
[ 0.2089, -0.1322, -0.1279, -0.0939, 0.2218, -0.0417, -0.3014, -0.0466,
-0.1766, -0.3138],
[ 0.0940, -0.2141, -0.2048, 0.0433, 0.2419, -0.1913, 0.1929, 0.3044,
0.2844, -0.2509]], requires_grad=True)
linear.bias: Parameter containing:
tensor([ 0.3027, 0.0343, 0.0903, -0.2430, 0.1694], requires_grad=True)
'''可以看到返回了一個包含大小為(5,10)和 (5,)Tensor的列表,分別是全連接網絡模型的weights和bias。
其實每個nn.Module都有一個parameters()函數,該函數用於返回可訓練的參數( trainable parameters)。大多數時候,我們在構建神經網絡模型的時候就已經隱式地構建了它們,比如構建卷積層時使用的nn.Conv2d,PyTorch的作者已經在nn.Conv2d內部調用nn.Parameter將weights和biases定義成了該層parameters,所以無需我們自己來定義。
如果嘗試將Tensor分配給nn.Module的實例化對象net,除非將其定義為nn.Parameter對象,否則它不會顯示在net的parameters()中。這樣做是為了方便您可能需要緩存不可微Tensor的情況,例如RNNs需要緩存先前的輸出。
import torch
import dill
import torch.nn as nn
import torch.utils.data as Data
import torchvision # 數據庫
import torch.nn.functional as F
from matplotlib import pyplot as plt
import numpy as np
torch.manual_seed(1)
class net1(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10, 5)
self.tens = torch.ones(3, 4) # This won't show up in a parameter list
def forward(self, x):
return self.linear(x)
myNet = net1()
print(list(myNet.parameters()))
##########################################################
class net2(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10, 5)
self.tens = nn.Parameter(torch.ones(3, 4)) # This will show up in a parameter list
def forward(self, x):
return self.linear(x)
myNet = net2()
print(list(myNet.parameters()))
##########################################################
class net3(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10, 5)
self.net = net2() # Parameters of net2 will show up in list of parameters of net3
def forward(self, x):
return self.linear(x)
myNet = net3()
print(list(myNet.parameters()))可以看到結果中net1中定義的self.tens = torch.ones(3, 4) 並未出現在net1的parameters()中,而net2中定義的self.tens = nn.Parameter(torch.ones(3, 4))會出現在net2的parameters()中。由於net3使用了net2,所以net2的所有parameters也會出現在net3中。
三、nn.ModuleList() and nn.ParameterList()
我記得在PyTorch中實現YOLO v3時必須使用nn.ModuleList()。由於我是通過分析包含網絡結構的.txt文件來創建網絡,所以我將所有對應的nn.Module對象(如nn.Conv2d(),nn.Linear()等)存儲在一個list中,然後將該list直接賦給我構建網絡的成員,就像下面一樣:
import torch
import torch.nn as nn
torch.manual_seed(1)
layer_list = [nn.Conv2d(5, 5, 3), nn.BatchNorm2d(5), nn.Linear(5, 2)]
class myNet(nn.Module):
def __init__(self):
super().__init__()
self.layers = layer_list
def forward(self,x):
for layer in self.layers:
x = layer(x)
net = myNet()
print(list(net.parameters()))得到的結果是空的:
説明這種方法並沒有將Python列表中的模塊和參數註冊至網絡中,解決的方法就是使用nn.ModuleList,如下所示:
import torch
import torch.nn as nn
torch.manual_seed(1)
layer_list = [nn.Conv2d(5, 5, 3), nn.BatchNorm2d(5), nn.Linear(5, 2)]
class myNet(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.ModuleList(layer_list)
def forward(self,x):
for layer in self.layers:
x = layer(x)
net = myNet()
print(list(net.parameters())) # Parameters of modules in layer_list show up.可以看到結果已經顯示了所有的parameters,説明已經註冊成功。
類似地,tensor列表可以通過將其包裝在nn.ParameterList類中來註冊。
四、權重初始化
權重初始化可能會影響您的訓練結果。
1.單層網絡
(1)直接調用torch.nn.innit
在創建model後直接調用torch.nn.innit裏的初始化函數:
layer1 = torch.nn.Linear(10,20)
torch.nn.init.xavier_uniform_(layer1.weight)
torch.nn.init.constant_(layer1.bias, 0) (2)重寫reset_parameters()方法
也可以重寫reset_parameters()方法,並不推薦。參考RNNbase的源碼實現,使用方法如下:
def reset_parameters(self):
stdv = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
init.uniform_(weight, -stdv, stdv)2.多層網絡
此外,您可能需要針對不同種類的層使用不同的權重初始化方案,這種功能可以通過modules( )和apply( )函數來實現。
(1)modules逐子層初始化
net.modules()是nn.Module類的成員函數,該類返回一個迭代器,該迭代器會遍歷model中所有的子層,然後使用可在每個子層上調用的apply函數來進行初始化。實例如下:
import torch
import torch.nn as nn
torch.manual_seed(1)
import matplotlib.pyplot as plt
class myNet(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(10, 10, 3)
self.bn = nn.BatchNorm2d(10)
def weights_init(self):
for module in self.modules():
if isinstance(module, nn.Conv2d):
nn.init.normal_(module.weight, mean=0, std=1)
nn.init.constant_(module.bias, 0)
Net = myNet()
Net.weights_init()
for module in Net.modules():
if isinstance(module, nn.Conv2d):
weights = module.weight
weights = weights.reshape(-1).detach().cpu().numpy()
print(module.bias) # Bias to zero
plt.hist(weights)
plt.show()結果如下:
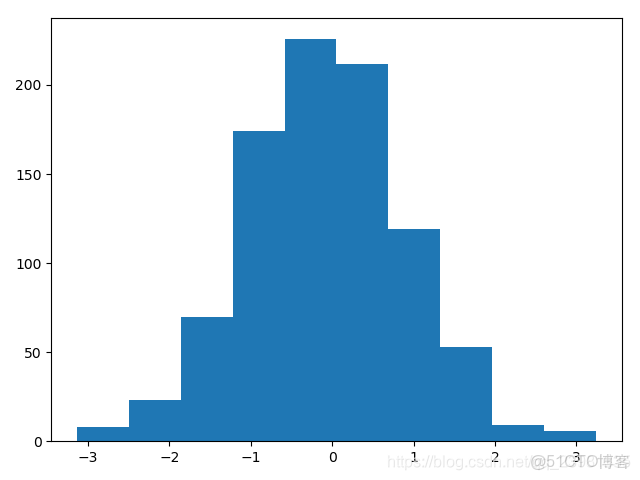
Histogram of weights initialised with Mean = 1 and Std = 1
(2)apply統一初始化
使用方式:model.apply(fn)
看一下apply作為類函數在nn.Module的實現:
def apply(self, fn):
r"""Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
as well as self. Typical use includes initializing the parameters of a model
(see also :ref:`torch-nn-init`).
Args:
fn (:class:`Module` -> None): function to be applied to each submodule
Returns:
Module: self
Example::
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.data.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
"""
for module in self.children():
module.apply(fn)
fn(self)
return self將函數fn遞歸的運用在每個子模塊上,這些子模塊由self.children()返回,常被用來初始化網絡層參數。注意fn需要一個參數。
具體使用方法:
- 定義weight_init函數,並在weight_init中通過判斷模塊的類型來進行不同的參數初始化定義類型。
- model=Net(…) 創建網絡結構
- model.apply(weight_init),將weight_init初始化方式應用到submodels上
實例1: 使用 isinstance(sub_module,class_name) 來判斷後進行初始化
# -*- coding: utf-8 -*-
import torch
from torch import nn
# hyper parameters
in_dim=1
n_hidden_1=1
n_hidden_2=1
out_dim=1
class Net(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.ReLU(True),
nn.Linear(n_hidden_1, n_hidden_2),
nn.ReLU(True),
nn.Linear(n_hidden_2, out_dim)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
# 1. 根據網絡層的不同定義不同的初始化方式
def weight_init(m):
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0)
# 也可以判斷是否為conv2d,使用相應的初始化方式
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# 是否為批歸一化層
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 2. 初始化網絡結構
model = Net(in_dim, n_hidden_1, n_hidden_2, out_dim)
# 3. 將weight_init應用在子模塊上
model.apply(weight_init)sub_module.__class__.__name__來確定name後,使用 str.find() 函數判斷後進行初始化
def weights_init(sub_module):
classname = sub_module.__class__.__name__
if classname.find("Conv") != -1:
nn.init.normal_(sub_module.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
nn.init.normal_(sub_module.weight.data, 1.0, 0.02)
nn.init.constant_(sub_module.bias.data, 0.0)五、modules() vs children()
(1)兩者區別
modules()會遍歷model中所有的子層,而children()僅會遍歷當前層。
先看代碼:
import torch
from torch import nn
# hyper parameters
in_dim=1
n_hidden_1=1
n_hidden_2=1
out_dim=1
class Net(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2),
nn.ReLU(True),
)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
# print(self.modules())
print("children")
for i, module in enumerate( self.children()):
print(i, module)
print("modules")
for i, module in enumerate( self.modules()):
print(i, module)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
model = Net(in_dim, n_hidden_1, n_hidden_2, out_dim)(2)網絡結構解讀
這是一個三層的網絡結構,將第一層的線性層和激活層放在一個nn.Sequential層中,將第二層的線性層和激活函數放在第二個nn.Sequential中,最後一個線性層作為單獨第三層。
整個網絡結構如下圖所示:
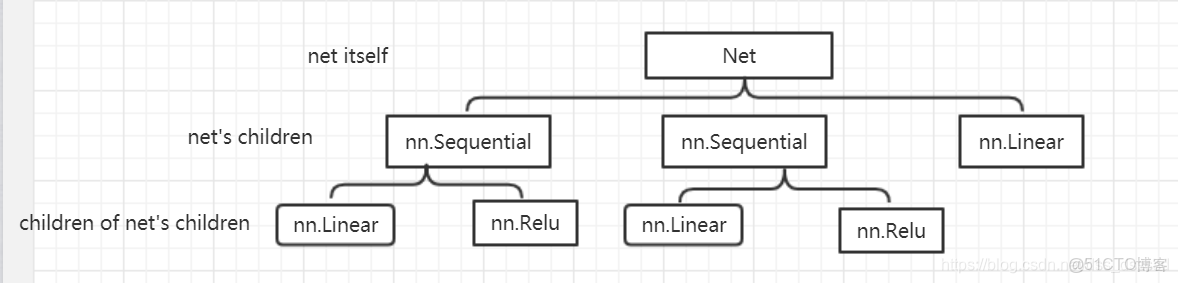
接下來看一下代碼__init__的print函數的打印信息:
self.children()
out:
children0 Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
1 Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
2 Linear(in_features=1, out_features=1, bias=True)
可以看出,self.children()存儲網絡結構的子層模塊,也就是net's children那一層。
self.modules()
out:
modules0 Net(
(layer): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
(layer2): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
(layer3): Linear(in_features=1, out_features=1, bias=True)
)
1 Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
2 Linear(in_features=1, out_features=1, bias=True)
3 ReLU(inplace)
4 Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
5 Linear(in_features=1, out_features=1, bias=True)
6 ReLU(inplace)
7 Linear(in_features=1, out_features=1, bias=True)可以看出,self.modules()採用深度優先遍歷的方式,存儲了net的所有模塊,包括net itself,net's children, children of net's children。
conclusion:
self.children()只包括網絡模塊的第一代兒子模塊,而self.modules()包含網絡模塊的自己本身和所有後代模塊。
(3)使用
for key in model.modules():
print(key)# model.modules()類似於 [[1, 2], 3],其遍歷結果為:
[[1, 2], 3], [1, 2], 1, 2, 3# model.children()類似於 [[1, 2], 3],其遍歷結果為:
[1, 2], 3也就是説,用model.children()進行初始化參數時,可能會漏掉部分,用model.modules()會遍歷所有層。
六、_modules和modules()
(1)區別
_modules是nn.Module類的成員變量(OrderedDict數據類型),為__init__中的self._modules;而modules()為nn.Module類的成員函數,函數modules()返回一個包含 當前模型 所有模塊的迭代器。
(2)成員變量self._modules
定義如下:
def __init__(self):
self._modules = OrderedDict()使用:如自定義Lambda層時使用self._modules.values(此例子見鄙人另一篇博客《pytorch構建ResNet/ResNeXt網絡(自定義Lambda層)》):
import torch
import torch.nn as nn
from torch.autograd import Variable
from functools import reduce
class LambdaBase(nn.Sequential):
def __init__(self, fn, *args):
super(LambdaBase, self).__init__(*args)
self.lambda_func = fn
def forward_prepare(self, input):
output = []
for module in self._modules.values():
output.append(module(input))
return output if output else input
class Lambda(LambdaBase):
def forward(self, input):
return self.lambda_func(self.forward_prepare(input))
class LambdaMap(LambdaBase):
def forward(self, input):
return list(map(self.lambda_func,self.forward_prepare(input)))
class LambdaReduce(LambdaBase):
def forward(self, input):
return reduce(self.lambda_func,self.forward_prepare(input))(3)成員函數modules()
定義如下:
def modules(self):
r"""Returns an iterator over all modules in the network.
Yields:
Module: a module in the network
Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
"""
for name, module in self.named_modules():
yield module例如:
l = nn.Linear(2, 2)
net = nn.Sequential(l, l)
for idx, m in enumerate(net.modules()): #類外訪問
print(idx, '->', m)結果:
0 -> Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)(4)對比
以第五章的例子進行改寫,
class Net(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2),
nn.ReLU(True),
)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
print('self._modules')
print(self._modules.values())
print("list(self.modules())")
print(list(self.modules()))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
model = Net(in_dim, n_hidden_1, n_hidden_2, out_dim)建立的網絡結構如下:
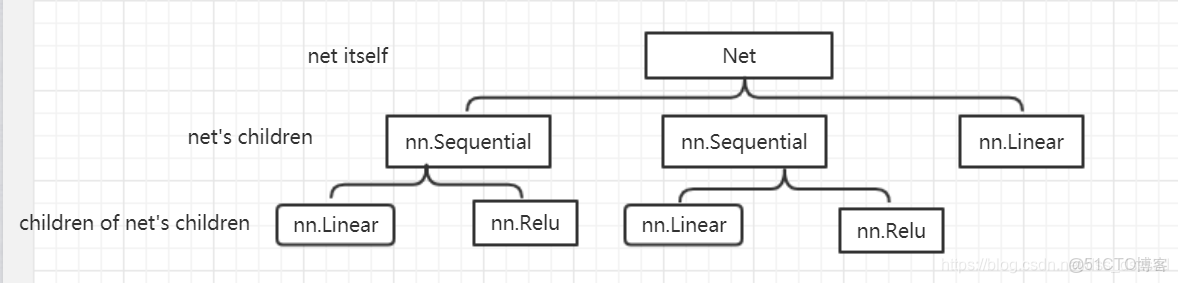
輸出結果:
- self._modules
out:
self._modulesOrderedDict([('layer', Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)), ('layer2', Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)), ('layer3', Linear(in_features=1, out_features=1, bias=True))])可以看出,self._modules類似於model.children(),存儲網絡結構的子層模塊,也就是net's children那一層。
- list(model.modules())
out:
list(self.modules())[Net(
(layer): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
(layer2): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
(layer3): Linear(in_features=1, out_features=1, bias=True)
), Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
), Linear(in_features=1, out_features=1, bias=True), ReLU(inplace), Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
), Linear(in_features=1, out_features=1, bias=True), ReLU(inplace), Linear(in_features=1, out_features=1, bias=True)]用model.modules()會遍歷所有層。
(5)總結
- self._modules類似於model.children(),存儲網絡結構的子層模塊,也就是
net's children那一層; - 用model.modules()會遍歷所有層。
七、model.named_parameters() 、model.parameters()、model.state_dict().items()
(1)model.named_parameters(): 迭代打印model.named_parameters()將會打印每一次迭代元素的名字和param。
for name, param in model.named_parameters():
print(name,param.requires_grad)
param.requires_grad=False假設您有以下神經網絡。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
#torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,
# dilation=1,groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# define the forward function
return x現在,讓我們打印與每個NN層關聯的權重參數的大小。
model = Net()
for name, param in model.named_parameters():
print(name, param.size())輸出:
conv1.weight torch.Size([6, 1, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([16, 6, 5, 5])
conv2.bias torch.Size([16])
fc1.weight torch.Size([120, 400])
fc1.bias torch.Size([120])
fc2.weight torch.Size([84, 120])
fc2.bias torch.Size([84])
fc3.weight torch.Size([10, 84])
fc3.bias torch.Size([10])(2)model.parameters():迭代打印model.parameters()將會打印每一次迭代元素的param而不會打印名字,這是他和named_parameters的區別,兩者都可以用來改變requires_grad的屬性。
for param in model.parameters():
print(param.requires_grad)
param.requires_grad=False(3)model.state_dict().items():對於恢復的模型,如果我們想查看某些層的參數,可以使用model.state_dict().items()。使用model.state_dict().items()每次迭代打印該選項的話,會打印所有的name和param,但是這裏的所有的param都是requires_grad=False,沒有辦法改變requires_grad的屬性,所以改變requires_grad的屬性只能通過上面的兩種方式。
for name, param in model.state_dict().items():
print(name,param.requires_grad=True)舉例1:
# 定義一個網絡
from collections import OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
# 打印網絡的結構
print(model)輸出:
Sequential (
(conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU ()
(conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU ()
)如果我們想獲取conv1的weight和bias:
params=model.state_dict()
for k,v in params.items():
print(k) #打印網絡中的變量名
print(params['conv1.weight']) #打印conv1的weight
print(params['conv1.bias']) #打印conv1的bias舉例2: 見《源碼詳解Pytorch的state_dict和load_state_dict》
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.my_tensor = torch.randn(1) # 參數直接作為模型類成員變量
self.register_buffer('my_buffer', torch.randn(1)) # 參數註冊為 buffer
self.my_param = nn.Parameter(torch.randn(1))
self.fc = nn.Linear(2,2,bias=False)
self.conv = nn.Conv2d(2,1,1)
self.fc2 = nn.Linear(2,2,bias=False)
self.f3 = self.fc
def forward(self, x):
return x
model = MyModel()
print(model.state_dict())
>>>OrderedDict([('my_param', tensor([-0.3052])), ('my_buffer', tensor([0.5583])), ('fc.weight', tensor([[ 0.6322, -0.0255],
[-0.4747, -0.0530]])), ('conv.weight', tensor([[[[ 0.3346]],
[[-0.2962]]]])), ('conv.bias', tensor([0.5205])), ('fc2.weight', tensor([[-0.4949, 0.2815],
[ 0.3006, 0.0768]])), ('f3.weight', tensor([[ 0.6322, -0.0255],
[-0.4747, -0.0530]]))])(4)
optimizer = optim.SGD(
filter(lambda p: p.requires_grad, model.parameters()), #只更新requires_grad=True的參數
lr=cfg.TRAIN.LR,
momentum=cfg.TRAIN.MOMENTUM,
weight_decay=cfg.TRAIN.WD,
nesterov=cfg.TRAIN.NESTEROV
)再進行隨機參數初始化:
def init_weights(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_uniform(m.weight.data)
model.apply(init_weights)八、Print網絡有關信息
(1)簡介
我們可能需要打印有關網絡的信息,無論是用於用户還是用於調試目的。 PyTorch使用它的named_ *函數提供了一種非常整潔的方式來打印有關網絡的信息,主要包括以下4種功能:
- named_parameters。返回一個迭代器,該迭代器給出一個包含參數名稱的元組(如果一個卷積層為self.conv1,則其參數將為conv1.weight和conv1.bias),以及nn.Parameter的__repr__函數返回的值;
- named_modules。與上面類似,但是迭代器返回的模塊類似於modules()函數;
- named_children。與上面類似,但是迭代器返回的模塊類似於children()函數;
- named_buffers。返回緩衝區tensors,如Batch Norm層的運行平均值。
(2)使用
在第六章的例子後加這麼一句:
for x in model.named_modules():
print(x[0], x[1], "\n-------------------------------")out:
Net( (layer): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
(layer2): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
(layer3): Linear(in_features=1, out_features=1, bias=True)
)
-------------------------------
layer Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
-------------------------------
layer.0 Linear(in_features=1, out_features=1, bias=True)
-------------------------------
layer.1 ReLU(inplace)
-------------------------------
layer2 Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
(1): ReLU(inplace)
)
-------------------------------
layer2.0 Linear(in_features=1, out_features=1, bias=True)
-------------------------------
layer2.1 ReLU(inplace)
-------------------------------
layer3 Linear(in_features=1, out_features=1, bias=True)
-------------------------------九、不同層設置不同的學習率+選擇性學習某些層參數
在本節中,我們將學習如何為不同的層設置不同的學習率及選擇性學習某些層的參數。
9.1 不同層設置不同的學習率
通常,我們將介紹如何針對不同的參數組設置不同的超參數,包括對不同的層設置不同的學習率,以及對偏差和權重設置不同的學習率。例如以下代碼中,我們對網絡所有參數都設置了相同的學習率:
class myNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10,5)
self.fc2 = nn.Linear(5,2)
def forward(self, x):
return self.fc2(self.fc1(x))
Net = myNet()
optimiser = torch.optim.SGD(Net.parameters(), lr = 0.5)但是,torch.optim類允許我們以字典的形式給不同參數集提供不同的學習率。
情形1:假如Net只有兩個層self.fc1以及self.fc2,兩個層設置不同的lr,則:
optimiser = torch.optim.SGD([{"params": Net.fc1.parameters(), 'lr' : 0.001, "momentum" : 0.99},
{"params": Net.fc2.parameters()}], lr = 0.01, momentum = 0.9)在上述情況下,參數 fc1使用0.01的學習率和0.99的動量。
情形2:假如Net有多個層:self.fc1、self.fc2、self.conv1、self.conv2等,如果只為self.fc1參數指定超參數,其他層使用該超參數的默認值,若一個個層單獨列出來未免太繁瑣,如果有的層不在optim中指出,在訓練的時候就不會更新該層的參數,因此可以通過以下方式進行設置:
lr = 0.001 #默認學習率
fc1_params = list(map(id, Net.fc1.parameters()))
base_params = filter(lambda p: id(p) not in fc1_params, Net.parameters())
#filter() 方法的語法:filter(function, iterable),函數用於過濾序列,過濾掉不符合條件的元素,
#返回一個迭代器對象,如果要轉換為列表,可以使用 #list() 來轉換。該接收兩個參數,第一個為函數,
#第二個為序列,序列的每個元素作為參數傳遞給函數進行判斷,最後將返回 True 的元素放到新列表中。
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': Net.fc1.parameters(), 'lr': lr * 100},
, lr=lr, momentum=0.9)如果為多層如self.fc1、self.fc2的參數指定超參數,其它層使用默認參數,則:
lr = 0.001 #默認學習率
fc1_params = list(map(id, Net.fc1.parameters()))
fc2_params = list(map(id, Net.fc2.parameters()))
base_params = filter(lambda p: id(p) not in fc1_params+fc2_parameter, Net.parameters())
#filter() 方法的語法:filter(function, iterable),函數用於過濾序列,過濾掉不符合條件的元素,
#返回一個迭代器對象,如果要轉換為列表,可以使用 #list() 來轉換。該接收兩個參數,第一個為函數,
#第二個為序列,序列的每個元素作為參數傳遞給函數進行判斷,最後將返回 True 的元素放到新列表中。
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': Net.fc1.parameters(), 'lr': lr * 100},
{'params': Net.fc2.parameters(), 'lr': lr * 900},
, lr=lr, momentum=0.9)9.2 在訓練中動態的調整學習率
在介紹如何動態調整學習率之前,先講解一下optimizer.param_groups。optimizer通過param_group來管理參數組,param_group到底有幾個呢?舉例説明,在9.1節中,param_group其實就是optimizer中的'params'個數,如下例有2個`param_group’即:len(optim.param_groups)==2,
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)而下例只有1個`param_group’:
optim.SGD(model.parameters(), lr=1e-2, momentum=.9)param_group中保存了參數組及其對應的學習率,動量等等,單個param_group如optimizer.param_groups[0]是個長度6的字典,其結構為:[{'params','lr', 'momentum', 'dampening', 'weight_decay', 'nesterov'},{……}],集合了優化器的各項參數。
可以查看的優化器參數:
print('查看optimizer.param_groups結構:')
i_list=[i for i in optimizer.param_groups[0].keys()]
print(i_list)
#['amsgrad', 'params', 'lr', 'betas', 'weight_decay', 'eps']所以我們可以通過更改param_group['lr']的值來更改對應參數組的學習率。
再介紹如何動態調整學習率。很多時候我們要對學習率(learning rate)進行衰減,下面的代碼示範瞭如何每30個epoch按10%的速率衰減:
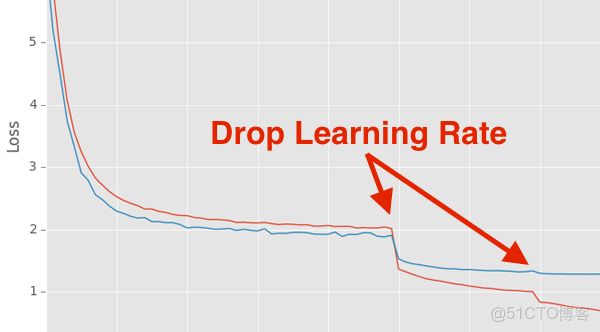
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr使用的嵌入方法:
{注意,學習率的更新要放在訓練和驗證集測試之後進行}
1、每隔一定的epoch調整學習率
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
for epoch in epochs:
train(...)
validate(...)
adjust_learning_rate(optimizer, epoch)
或者from torch.optim import lr_scheduler
adjust_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in epochs:
train(...)
validate(...)
adjust_lr_scheduler.step()
注意,學習率的更新要放在訓練和驗證集測試之後進行。
2、以一定的策略調整學習率
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer,
lambda epoch : (1.0-epoch/epochs) if epochs <= epochs else 0, last_epoch=-1)
for epoch in epochs:
train(...)
validate(...)
scheduler9.3 如何擇性學習某些參數,即固定某些層訓練
對於我們現有的模型model,通過調整參數的requires_grad 屬性控制該模型是否參與求導運算:
首先,介紹怎麼獲取參數的name: 您可以使用上面介紹的named_parameters()函數根據不同的層(或者參數是權重還是偏差)創建參數列表,如何得到網絡層所有參數的name呢(包括可學習參數及不可學習參數)?
for name, param in net.named_parameters():
if param.requires_grad:
print("requires_grad: True ", name)
else:
print("requires_grad: False ", name)它會遍歷得到所有下級模塊(兒子模塊,孫子模塊,等等)的參數。如果模型中包含多個子模塊,可用通過
sub_block = model.children()獲取該模塊,然後通過迭代索引的方式獲取參數:
for name, param in sub_block.named_parameters()接下來,介紹如何固定某些層訓練,思路就是利用tensor的requires_grad,每一個tensor都有自己的requires_grad成員,值只能為True和False。
- 我們對不需要參與訓練的參數的requires_grad設置為False。
- 在optim參數模型參數中過濾掉requires_grad為False的參數。
我們先搭建一個小網絡進行例子詳解:
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,32,3)
self.conv2 = nn.Conv2d(32,24,3)
self.prelu = nn.PReLU()
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
nn.init.constant_(m.bias.data,0)
if isinstance(m,nn.Linear):
m.weight.data.normal_(0.01,0,1)
m.bias.data.zero_()
def forward(self, input):
out = self.conv1(input)
out = self.conv2(out)
out = self.prelu(out)
return out假如我們需要固定第一個卷積層的參數,訓練其他層的所有參數,則做法就是:需要遍歷第一層的參數,然後為其設置requires_grad:
model = Net()
for name, p in model.named_parameters():
if name.startswith('conv1'):
p.requires_grad = False
import torch.optim as optim
optimizer = optim.Adam(filter(lambda x: x.requires_grad is not False ,model.parameters()),lr= 0.2)model中的參數的requires_grad和optim中的params_group():
for p in model.parameters():
print(p.requires_grad)
'''
輸出:
False #conv1的weights
False #conv1的bias
True
True
True
'''for p in optimizer.param_groups[0]['params']:
print(p.requires_grad)
print(type(p))
'''
True
<class 'torch.nn.parameter.Parameter'>
True
<class 'torch.nn.parameter.Parameter'>
True
<class 'torch.nn.parameter.Parameter'>
'''能看出優化器僅僅對requires_grad為True的參數進行迭代優化。
十、pytorch獲取模型某一層參數名及參數值
Motivation:
I wanna modify the value of some param;
I wanna check the value of some param.
The needed function:
- state_dict() #generator type
- model.modules() #generator type
- named_parameters() #OrderDict type
from torch import nn
import torch
#creat a simple model
model = nn.Sequential(
nn.Conv3d(1,16,kernel_size=1),
nn.Conv3d(16,2,kernel_size=1))#tend to print the W of this layer
input = torch.randn([1,1,16,256,256])
if torch.cuda.is_available():
print('cuda is avaliable')
model.cuda()
input = input.cuda()
#打印某一層的參數名
for name in model.state_dict():
print(name)
#Then I konw that the name of target layer is '1.weight'
#schemem1(recommended)
print(model.state_dict()['1.weight'])
#scheme2
params = list(model.named_parameters())#get the index by debuging
print(params[2][0])#name
print(params[2][1].data)#data
#scheme3
params = {}#change the tpye of 'generator' into dict
for name,param in model.named_parameters():
params[name] = param.detach().cpu().numpy()
print(params['0.weight'])
#scheme4
for layer in model.modules():
if(isinstance(layer,nn.Conv3d)):
print(layer.weight)
#打印每一層的參數名和參數值
#schemem1(recommended)
for name,param in model.named_parameters():
print(name,param)
#scheme2
for name in model.state_dict():
print(name)
print(model.state_dict()[name])十一、將網絡模型參數tensor的數據類型dtype設置成一樣
假如訓練時,需要將要訓練的模型參數tesor在有cuda時全部設置為torch.cuda.FloatTensor,而在只有cpu時設置成torch.FloatTensor。具體就是在訓練時將model.train()改為model.type(expect_dtype).train(),具體為:
def get_dtype():
expect_dtype=torch.cuda.FloatTensor if torch.cuda.is_available else torch.FloatTensor
return expect_dtype
....
....
expect_dtype = get_dtype()
#原語句:model.train()
model.type(expect_dtype).train() #Sets the module in training mode.
...
...十二、GPU訓練的模型在保存時也保存成cpu可載入的類型
增加函數:
def save_model(model, filename): #保存為CPU中可以打開的模型
state = model.state_dict()
x=state.copy()
for key in x:
x[key] = x[key].clone().cpu()
torch.save(x, filename)調用方式如下:
torch.save(model.state_dict(), r'./Modelmodel_cuda_%d.pkl' % i) # #保存為僅GPU中可以打開的模型
save_model(model, r'./Model/modle_cpu_%d.pkl'%i) #保存為CPU中可以打開的模型十三、pytorch之保存與加載模型
torch.save(): 保存一個序列化的對象到磁盤,使用的是Python的pickle庫來實現的。torch.load(): 解序列化一個pickled對象並加載到內存當中。torch.nn.Module.load_state_dict(): 加載一個解序列化的state_dict對象
1. state_dict
在PyTorch中所有可學習的參數保存在model.parameters()中。state_dict是一個Python字典。保存了各層與其參數張量之間的映射。torch.optim對象也有一個state_dict,它包含了optimizer的state,以及一些超參數。
2. 保存&加載模型來inference(recommended)
(1)save
torch.save(model.state_dict(), PATH)(2)load
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval() # 當用於inference時不要忘記添加- 保存的文件名後綴可以是
.pt或.pth - 當用於inference時不要忘記添加
model.eval()
3. 保存&加載整個模型(not recommended)
(1)save
torch.save(model, PATH)(2)load
# Model class must be defined somewhere
model = torch.load(PATH)
model.eval()4. 保存&加載帶checkpoint的模型用於inference或resuming training
注: resume: (中斷後) 繼續
(1)save
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)(2)load
model = TheModelClass(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
# or
model.train()5. 保存多個模型到一個文件中
(1)save
torch.save({
'modelA_state_dict': modelA.state_dict(),
'modelB_state_dict': modelB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
...
}, PATH)(2)load
modelA = TheModelAClass(*args, **kwargs)
modelB = TheModelAClass(*args, **kwargs)
optimizerA = TheOptimizerAClass(*args, **kwargs)
optimizerB = TheOptimizerBClass(*args, **kwargs)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict']
modelB.load_state_dict(checkpoint['modelB_state_dict']
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict']
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict']
modelA.eval()
modelB.eval()
# or
modelA.train()
modelB.train()- 此情況可能在
GAN,Sequence-to-sequence,或ensemble models中使用 - 保存
checkpoint常用.tar文件擴展名
6. Warmstarting Model Using Parameters From A Different Model
(1)save
torch.save(modelA.state_dict(), PATH)(2)load
modelB = TheModelBClass(*args, **kwargs)
modelB.load_state_dict(torch.load(PATH), strict=False)- 在遷移訓練時,可能希望只加載部分模型參數,此時可置
strict參數為False來忽略那些沒有匹配到的keys
7. 保存&加載模型跨設備
在使用pytorch的過程,經常會需要加載模型參數,不管是別人提供給我們的模型參數,還是我們自己訓練的模型參數,那麼加載模型參數就會碰到一些情況,即GPU模型和CPU模型,這兩種模型是不能混為一談的,下面分情況進行操作説明。
情況一:模型是GPU模型,預加載的訓練參數也是GPU;模型是CPU模型,預加載的訓練參數也是CPU,這種情況下我們都只用直接用下面的語句即可:
torch.load('model_dict.pkl')情況二:GPU->CPU,即定義好的模型是CPU,預加載的訓練參數卻是GPU,那麼需要這樣:
torch.load('model_dict.pkl', map_location=lambda storage, loc: storage)情況三:CPU->GPU,即定義好的模型是GPU,預加載的訓練參數卻是CPU:
torch.load('model_dic.pkl', map_location=lambda storage, loc: storage.cuda)
#子情況,CPU->GPU1 模型是GPU1,預加載的訓練參數卻是CPU:
torch.load('model_dic.pkl', map_location=lambda storage, loc: storage.cuda(1))情況四:GPU0->GPU1,即定義好的模型是GPU1,預加載的訓練參數卻是GPU0:
torch.load('modelparameters.pth', map_location={'cuda:1':'cuda:0'})8. 保存torch.nn.DataParallel模型
(1)save
torch.save(model.module.state_dict(), PATH)(2)load
# Load to whatever device you want公司配備多卡的GPU服務器,當我們在上面跑程序的時候,當迭代次數或者epoch足夠大的時候,我們通常會使用nn.DataParallel函數來用多個GPU來加速訓練。一般我們會在代碼中加入以下這句:
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)似乎只要加上這一行代碼,你在ternimal下執行watch -n 1 nvidia-smi後會發現確實會使用多個GPU來並行訓練。但是細心點會發現其實第一塊卡的顯存會佔用的更多一些,那麼這是什麼原因導致的?查閲pytorch官網的nn.DataParrallel相關資料,首先我們來看下其定義如下:
CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)module即表示你定義的模型,device_ids表示你訓練的device,output_device這個參數表示輸出結果的device,而這最後一個參數output_device一般情況下是省略不寫的,那麼默認就是在device_ids[0],也就是第一塊卡上,也就解釋了為什麼第一塊卡的顯存會佔用的比其他卡要更多一些。進一步説也就是當你調用nn.DataParallel的時候,只是在你的input數據是並行的,但是你的output loss卻不是這樣的,每次都會在第一塊GPU相加計算,這就造成了第一塊GPU的負載遠遠大於剩餘其他的顯卡。
下面來具體講講nn.DataParallel中是怎麼做的。
首先在前向過程中,你的輸入數據會被劃分成多個子部分(以下稱為副本)送到不同的device中進行計算,而你的模型module是在每個device上進行復制一份,也就是説,輸入的batch是會被平均分到每個device中去,但是你的模型module是要拷貝到每個devide中去的,每個模型module只需要處理每個副本即可,當然你要保證你的batch size大於你的gpu個數。然後在反向傳播過程中,每個副本的梯度被累加到原始模塊中。概括來説就是:DataParallel 會自動幫我們將數據切分 load 到相應 GPU,將模型複製到相應 GPU,進行正向傳播計算梯度並彙總。
注意還有一句話,官網中是這樣描述的:
The parallelized module must have its parameters and buffers on device_ids[0] before running this DataParallel module.
意思就是:在運行此DataParallel模塊之前,並行化模塊必須在device_ids [0]上具有其參數和緩衝區。在執行DataParallel之前,會首先把其模型的參數放在device_ids[0]上,一看好像也沒有什麼毛病,其實有個小坑。我舉個例子,服務器是八卡的服務器,剛好前面序號是0的卡被別人佔用着,於是你只能用其他的卡來,比如你用2和3號卡,如果你直接指定device_ids=[2, 3]的話會出現模型初始化錯誤,類似於module沒有複製到在device_ids[0]上去。那麼你需要在運行train之前需要添加如下兩句話指定程序可見的devices,如下:
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3"當你添加這兩行代碼後,那麼device_ids[0]默認的就是第2號卡,你的模型也會初始化在第2號卡上了,而不會佔用第0號卡了。這裏簡單説一下設置上面兩行代碼後,那麼對這個程序而言可見的只有2和3號卡,和其他的卡沒有關係,這是物理上的號卡,邏輯上來説其實是對應0和1號卡,即device_ids[0]對應的就是第2號卡,device_ids[1]對應的就是第3號卡。(當然你要保證上面這兩行代碼需要定義在
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)這兩行代碼之前,一般放在train.py中import一些package之後。)
那麼在訓練過程中,你的優化器同樣可以使用nn.DataParallel,如下兩行代碼:
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
optimizer = nn.DataParallel(optimizer, device_ids=device_ids)那麼使用nn.DataParallel後,事實上DataParallel也是一個Pytorch的nn.Module,那麼你的模型和優化器都需要使用.module來得到實際的模型和優化器,如下:
保存模型:
torch.save(net.module.state_dict(), path)
加載模型:
net=nn.DataParallel(Resnet18())
net.load_state_dict(torch.load(path))
net=net.module
優化器使用:
optimizer.step() --> optimizer.module.step()還有一個問題就是,如果直接使用nn.DataParallel的時候,訓練採用多卡訓練,會出現一個warning:
UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars;
will instead unsqueeze and return a vector.首先説明一下:每張卡上的loss都是要彙總到第0張卡上求梯度,更新好以後把權重分發到其餘卡。但是為什麼會出現這個warning,這其實和nn.DataParallel中最後一個參數dim有關,其表示tensors被分散的維度,默認是0,nn.DataParallel將在dim0(批處理維度)中對數據進行分塊,並將每個分塊發送到相應的設備。單卡的沒有這個warning,多卡的時候採用nn.DataParallel訓練會出現這個warning,由於計算loss的時候是分別在多卡計算的,那麼返回的也就是多個loss,你使用了多少個gpu,就會返回多少個loss。(有人建議DataParallel類應該有reduce和size_average參數,比如用於聚合輸出的不同loss函數,最終返回一個向量,有多少個gpu,返回的向量就有幾維。)
關於這個問題在pytorch官網的issues上有過討論,下面簡單摘出一些。
DataParallel does not work with tensors of dimension 0 · Issue #9811 · pytorch/pytorchgithub.com
前期探討中,有人提出求loss平均的方式會在不同數量的gpu上訓練會以微妙的方式影響結果。模塊返回該batch中所有損失的平均值,如果在4個gpu上運行,將返回4個平均值的向量。然後取這個向量的平均值。但是,如果在3個GPU或單個GPU上運行,這將不是同一個數字,因為每個GPU處理的batch size不同!舉個簡單的例子(就直接摘原文出來):
A batch of 3 would be calculated on a single GPU and results would be [0.3, 0.2, 0.8] and model that returns the loss would return 0.43.
If cast to DataParallel, and calculated on 2 GPUs, [GPU1 - batch 0,1], [GPU2 - batch 2] - return values would be [0.25, 0.8] (0.25 is average between 0.2 and 0.3)- taking the average loss of [0.25, 0.8] is now 0.525!
Calculating on 3 GPUs, one gets [0.3, 0.2, 0.8] as results and average is back to 0.43!
似乎一看,這麼求平均loss確實有不合理的地方。那麼有什麼好的解決辦法呢,可以使用size_average=False,reduce=True作為參數。每個GPU上的損失將相加,但不除以GPU上的批大小。然後將所有平行損耗相加,除以整批的大小,那麼不管幾塊GPU最終得到的平均loss都是一樣的。
那pytorch貢獻者也實現了這個loss求平均的功能,即通過gather的方式來求loss平均:
Support modules that output scalar in Gather (and data parallel) by SsnL · Pull Request #7973 · pytorch/pytorchgithub.com
如果它們在一個有2個GPU的系統上運行,DP將採用多GPU路徑,調用gather並返回一個向量。如果運行時有1個GPU可見,DP將採用順序路徑,完全忽略gather,因為這是不必要的,並返回一個標量。
9 GPU環境設置及單機並行訓練
9.1 CUDA 基本使用
(1)查看 GPU 信息
更多接口,參考 torch.cuda。
torch.cuda.is_available() # 判斷 GPU 是否可用
torch.cuda.device_count() # 判斷有多少 GPU
torch.cuda.get_device_name(0) # 返回 gpu 名字,設備索引默認從 0 開始
torch.cuda.current_device() # 返回當前設備索引torch.device
torch.device 表示 torch.Tensor 分配到的設備的對象。其包含一個設備類型(cpu 或 cuda),以及可選的設備序號。如果設備序號不存在,則為當前設備,即 torch.cuda.current_device() 的返回結果。
可以通過如下方式創建 torch.device 對象:
# 通過字符串
device = torch.device('cpu')
device = torch.device('cuda:1') # 指定類型及編號。注意,代碼不會檢查編號是否合法
device = torch.device('cuda') # 默認為當前設備還可以通過設備類型加上編號,來創建 device 對象:
device = torch.device('cuda', 0)
device = torch.device('cpu', 0)9.2 配置 CUDA 訪問限制
可以通過如下方式,設置當前 Python 腳本可見的 GPU。
(1)在終端設置
CUDA_VISIBLE_DEVICES=1 python my_script.py實例
Environment Variable Syntax Results
CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen
CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible
CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional
CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked
CUDA_VISIBLE_DEVICES="" No GPU will be visible(2)在 Python 代碼中設置
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 2"(3)使用函數 set_device
import torch
torch.cuda.set_device(id)注:官方建議使用
CUDA_VISIBLE_DEVICES,但編程過程中發現利用 os.environ["CUDA_VISIBLE_DEVICES"]指定cuda代號後, 利用torch.cuda.current_device()仍輸出的是“0”,所以建議使用set_device函數。
9.3 單機單卡訓練
(1)用 GPU 訓練
默認情況下,使用 CPU 訓練模型。可以通過如下方式,通過 GPU 進行訓練。使用 GPU 時,模型和輸入必須位於同一張 GPU 上。
.to(device) 和 .cuda() 的區別如下:
.to()- 對於
module而言,.to()是inplace的,而.cuda()不是;而對於tensor而言,兩者一致。
注:實測,兩者時間消耗持平。
方式 1 :
device = torch.device("cuda:1") # 指定模型訓練所在 GPU
# 將 GPU 轉移至 GPU
if torch.cuda.is_available() and use_gpu:
net = net.cuda(device) # 默認在第一塊 GPU 上訓練
# 同時將數據轉移至 GPU
if torch.cuda.is_available() and use_gpu:
inputs = inputs.cuda(device)
labels = labels.cuda(device)方法 2 :
device = torch.device("cuda:1") # 指定模型訓練所在 GPU
# 將 GPU 轉移至 GPU
if torch.cuda.is_available() and use_gpu:
net = net.to(device) # 默認在第一塊 GPU 上訓練
# 同時將數據轉移至 GPU
if torch.cuda.is_available() and use_gpu:
inputs = inputs.to(device)
labels = labels.to(device)(2)存在的問題
a. batch size 太大
當想要用大批量進行訓練,但是 GPU 資源有限,此時可以通過梯度累加(accumulating gradients)的方式進行。
梯度累加的基本思想在於,在優化器更新參數前,也就是執行 optimizer.step() 前,進行多次反向傳播,是的梯度累計值自動保存在 parameter.grad 中,最後使用累加的梯度進行參數更新。
這個在 PyTorch 中特別容易實現,因為 PyTorch 中,梯度值本身會保留,除非我們調用 model.zero_grad() 或 optimizer.zero_grad()。
修改後的代碼如下所示:
model.zero_grad() # 重置保存梯度值的張量
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # 前向計算
loss = loss_function(predictions, labels) # 計算損失函數
loss.backward() # 計算梯度
if (i + 1) % accumulation_steps == 0: # 重複多次前面的過程
optimizer.step() # 更新梯度
model.zero_grad() # 重置梯度b. model 太大
當模型本身太大,以至於不能放置於一個 GPU 中時,可以通過梯度檢查點 (gradient-checkpoingting) 的方式進行處理。梯度檢查點的基本思想是以計算換內存。具體來説就是,在反向傳播的過程中,把梯度切分成幾部分,分別對網絡上的部分參數進行更新。如下圖所示:
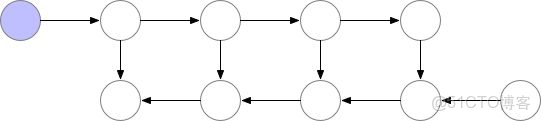
梯度檢查點圖示
這種方法速度很慢,但在某些例子上很有用,比如訓練長序列的 RNN 模型等。具體可參考:From zero to research — An introduction to Meta-learning
9.4 單機多卡訓練 —— 並行訓練
單機多卡訓練,即並行訓練。並行訓練又分為數據並行 (Data Parallelism) 和模型並行兩種。數據並行指的是,多張 GPU 使用相同的模型副本,但是使用不同的數據批進行訓練。而模型並行指的是,多張GPU 分別訓練模型的不同部分,使用同一批數據。兩者對比如下圖所示:
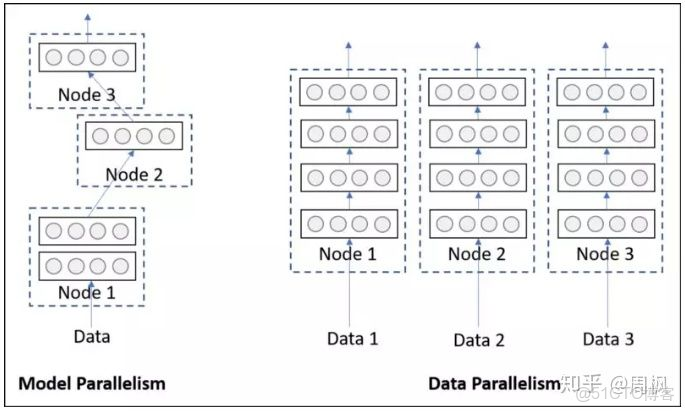
模型並行 VS 數據並行
(1)數據並行
Pytorch API【Class 原型】
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)【參數】
- module :要進行並行的
module。這裏隱含了一點 ,即網絡中的某一層也是可以進行數據並行的,但是一般不會這麼使用。 - device_ids :
CUDA列表,可以為torch.device類型,也可以是編號組成的int列表。默認使用全部 GPU - output_device : 某一
GPU編號或torch.device。指定輸出的GPU,默認為第一個,即device_ids[0]
【返回值】
要進行並行的模型。
【基本使用方式】
>>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
>>> output = net(input_var) # input_var can be on any device, including CP數據並行的原理
數據並行的具體原理流程為:
- 將模型加載至主設備上,作為
controller,一般設置為cuda:0 - 在每次迭代時,執行如下操作:
- 將
controller模型複製(broadcast)到每一個指定的GPU上 - 將總輸入的數據
batch,進行均分,分別作為各對應副本的輸入 (scatter) - 每個副本獨立進行前向傳播,並進行反向傳播,但只是求取梯度
- 將各副本的梯度彙總(
gather)到controller設備,並進行求和 (reduced add)
During the backwards pass, gradients from each replica are summed into the original module. - 更具總體度,更新
controller設備上的參數
注意事項
【警告 1】
- 設置的
batch size為總的批量尺寸,其必須大於GPU數量。 - 在
parallelized module運行之前,必須保證其在controller設備上,存在參數和buffers。 - 並行的
GPU列表中,必須包含主GPU - 當
forward()中,module返回一個標量,那麼並行的結果將返回一個vector,其長度等於device的數量,對應於各個設備的結果。
【警告 2】
在每次前向傳播過程中,module 都先會被複制到每一個 device 上。因此,在前向傳播中,任何對該運行的 module 的副本的更新,在此後都將會丟失。
比方説,如果 module 有一個 counter 屬性,每次前向傳播都會進行累加,則它將會保持為初始值。因為更新是發生在模型的副本(在其他 device 上的副本)上的,並且這些更新在前向傳播結束之後將會被銷燬。
然而,DataParallel 保證 controller 設備上的副本的參數和 buffers 與其他並行的 modules 之間共享存儲。因此,如若對 controller device 的 參數和 buffers 的更改,將會被記錄。例如,BatchNorm2d 和 spectral_norm() 依賴於這種行為來更新 buffers。
【警告 3】
定義於 module 及其子 module 上的前向傳播和反向傳播 hooks,將會被調用 len(device_ids) 次,每個設備對應一次。
具體來説,hooks 只能保證按照正確的順序執行對應設備上的操作,即在對應設備上的 forward() 調用之前執行,但是不能保證,在所有 forward)() 執行之前,通過 register_forward_pre_hook() 執行完成所有的 hooks。
【警告 4】
任何位置和關鍵字 (positional and keyword) 輸入都可以傳遞給 DataParallel,處理一些需要特殊處理的類型。
tensors 將會在指定維度(默認為 0)上被 scattered。 tuple, list 和 dict 類型則會被淺拷貝。其他類型則會在不同的線程之間進行共享,且在模型前向傳播過程中,如果進行寫入,則可被打斷。
【警告 5】
當對 pack sequence -> recurrent network -> unpack sequence 模式的 module 使用 DataParallel 或 data_parallel 時,有一些小的問題。
每個設備上的 forward 的對應輸入,將僅僅是整個輸入的一部分。因為默認的 unpack 操作 torch.nn.utils.rnn.pad_packed_sequence() 只會將該設備上的輸入 padding 成該設備上的最長的輸入長度,因此,將所有設備的結構進行彙總時,可能會發生長度的不匹配的情況。
因此,可以利用 pad_packed_sequence() 的 total_length 參數來保證 forward() 調用返回的序列長度一致。代碼如下所示:
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class MyModule(nn.Module):
# ... __init__, other methods, etc.
# padded_input is of shape [B x T x *] (batch_first mode) and contains
# the sequences sorted by lengths
# B is the batch size
# T is max sequence length
def forward(self, padded_input, input_lengths):
total_length = padded_input.size(1) # get the max sequence length
packed_input = pack_padded_sequence(padded_input, input_lengths,
batch_first=True)
packed_output, _ = self.my_lstm(packed_input)
output, _ = pad_packed_sequence(packed_output, batch_first=True,
total_length=total_length)
return output
m = MyModule().cuda() # 設置 controller 模型
dp_m = nn.DataParallel(m) # 進行副本拷貝示例程序
下面是使用 DataParrel 的核心代碼,其餘部分與一般的訓練流程一致。
# 設置當前腳本可見的 GPU 列表
# 這裏設置 0 號和 1 號 GPU 對當前腳本可見。
# 此時,若 DataParallel 中指定使用其他 GPU 資源,額外的編號將會被忽略
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
# 使用數據並行
# 1. 將 model 轉移到某 GPU 上 -- net.cuda()
# 2. 指定並行訓練要用到的 GPU -- device_ids=[0, 1]
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
net = nn.DataParallel(net.cuda(), device_ids=[0, 1])
# 將數據轉移到 controller 所在 GPU
if torch.cuda.is_available() and use_gpu:
inputs = inputs.cuda(device)
labels = labels.cuda(device)(2)模型的加載
def _Single2Parallel(self, origin_state):
"""
將串行的權值參數轉換為並行的權值參數
:param origin_state : 原始串行權值參數
:return : 並行的權值參數
"""
converted = OrderedDict()
for k, v in origin_state.items():
name = "module." + k
converted[name] = v
return converted
def _Parallel2Single(self, origin_state):
"""
將並行的權值參數轉換為串行的權值參數
:param origin_state : 原始串行權值參數
:return : 並行的權值參數
"""
converted = OrderedDict()
for k, v in origin_state.items():
name = k[7:]
converted[name] = v
return converted(3)模型並行
如果模型本身較大,一張 GPU 放置不下時,要通過模型並行來處理。模型並行指的是,將模型的不同部分,分別放置於不同的 GPU 上,並將中間結果在 GPU 之間進行傳遞。
儘管從執行時間上來看,將模型的不同部分部署在不同設備上確實有好處,但是它通常是出於避免內存限制才使用。具有特別多參數的模型會受益於這種並行策略,因為這類模型需要很高的內存佔用,很難適應到單個系統。
基本使用
下面,我們以一個 toy 模型為例,講解模型並行。模型並行的實現方式如下所示:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.features_1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True), # 30
......
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # 12
).to('cuda:0')
self.features_2 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=2),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True), # 5
......).to('cuda:1') # 1
self.classifier = nn.Sequential(
nn.Dropout(),
......
nn.Linear(1024, class_num)).to('cuda:1')
def forward(self, x):
out = self.features_1(x.to('cuda:0'))
out = self.features_2(out.to('cuda:1'))
out = out.view(-1, 384)
out = self.classifier(out)
out = F.softmax(out, dim=1)
return out上面的 toy 模型看起來和在單個 GPU 上運行的模型沒什麼區別,只不過用 to(device) 來將模型內的不同層分散到不同的 GPU 上進行運行,並且將中間結果轉移到對應的 GPU 上即可。
backward() 和 torch.optim 將會自動考慮梯度,與在一個 GPU 上沒有區別。
注意:在調用
loss函數時,labels與output必須在同一個GPU上。
# 此時,不在此需要使用 model = model.cuda()
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
for data in trainloader:
images, labels = data
# 要處理的部分
images = images.to('cuda:0')
labels = labels.to('cuda:1') # 必須與輸出所在 GPU 一致
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()模型並行的性能分析
以上的實現解決了單個模型太大,不能存放於一個 GPU 的情況。然而,需要注意的是,相較於在單個 GPU 上運行,其速度更慢。因為任何時候,只有一個 GPU 在工作,而另一個則閒置。而當中間結果在 GPU 之間進行轉移時,速度會進一步下降。
下面同時實例分析。以 resnet50 為例,用隨機生成的數據輸入,比較兩個版本的運行時間。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
import torchvision.models as models
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for _ in range(num_batches):
# generate random inputs and labels
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
# run forward pass
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
# run backward pass
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
import numpy as np
import timeit
num_repeat = 10
stmt = "train(model)"
setup = "model = ModelParallelResNet50()"
# globals arg is only available in Python 3. In Python 2, use the following
# import __builtin__
# __builtin__.__dict__.update(locals())
mp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
mp_mean, mp_std = np.mean(mp_run_times), np.std(mp_run_times)
setup = "import torchvision.models as models;" + \
"model = models.resnet50(num_classes=num_classes).to('cuda:0')"
rn_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
rn_mean, rn_std = np.mean(rn_run_times), np.std(rn_run_times)
def plot(means, stds, labels, fig_name):
fig, ax = plt.subplots()
ax.bar(np.arange(len(means)), means, yerr=stds,
align='center', alpha=0.5, ecolor='red', capsize=10, width=0.6)
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xticks(np.arange(len(means)))
ax.set_xticklabels(labels)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig(fig_name)
plt.close(fig)
plot([mp_mean, rn_mean],
[mp_std, rn_std],
['Model Parallel', 'Single GPU'],
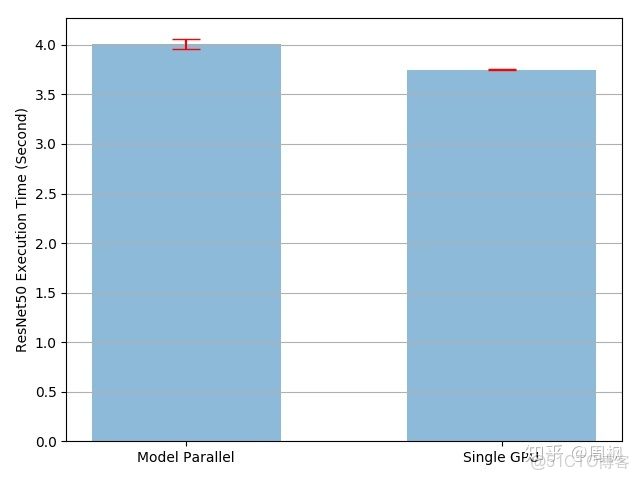
'mp_vs_rn.png')結果如下所示。模型並行相較於單 GPU 訓練的模型,訓練時間開銷多出 4.02/3.75-1=7% 左右。當然,這存在優化空間,因為多 GPU 中,每一時刻只有一個 GPU 進行訓練,其他閒置。而在中間數據轉移過程中,又消耗一定的時間。
模型並行 VS 單 GPU
解決方法:輸入流水線
解決上面的問題的最直接的方式就是使用流水線技術,即 GPU-0 輸出到 GPU-1 之後,在 GPU-1 訓練的同時,GPU-0 接收下一批數據,這樣就可以多 GPU 同時執行了。
下面,我們將 120 個樣本的 batch 再次細分,分為 20 張樣本每份的小 batch。由於 Pytorch 同步啓動 CUDA 操作,因此,該操作不需要使用額外的多線程來處理。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev runs on cuda:1
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next runs on cuda:0, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')需要注意的是,device-to-device 的 tensor copy 操作是同步的。如果創建多個數據流,則需要保證 copy 操作以合適的同步方式進行。
在完成 tensor 拷貝之前,對 source tensor 進行寫入,或者對 target tensor 進行讀寫,都可能會導致不可預期的行為。上面的實現中,在源和目標設備中,均只使用了默認的 stream,因此無需額外的強化同步操作。
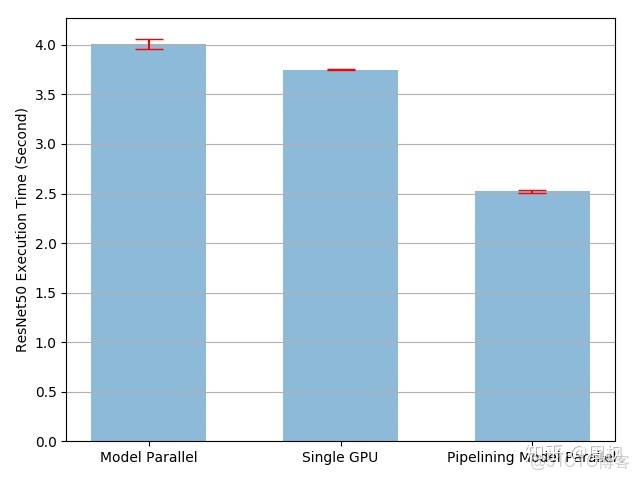
模型並行 VS 單 GPU VS 流水線模型並行
如上圖所示,流水線輸入確實加速了訓練進程,大約 3.75/2.51-1=49%,但距離 100% 的加速相去甚遠。由於我們在流水線並行實現中,引入了一個新的參數 split_sizes,但是並不知曉其對訓練時間的影響。
直覺上來説,使用一個小的 split_sizes 將會導致許多微小的 CUDA 內核的啓動,而使用較大的 split_sizes,則會導致較長的空閒時間。下面是一個搜索最佳 split_sizes 的實驗。
means = []
stds = []
split_sizes = [1, 3, 5, 8, 10, 12, 20, 40, 60]
for split_size in split_sizes:
setup = "model = PipelineParallelResNet50(split_size=%d)" % split_size
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
means.append(np.mean(pp_run_times))
stds.append(np.std(pp_run_times))
fig, ax = plt.subplots()
ax.plot(split_sizes, means)
ax.errorbar(split_sizes, means, yerr=stds, ecolor='red', fmt='ro')
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xlabel('Pipeline Split Size')
ax.set_xticks(split_sizes)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig("split_size_tradeoff.png")
plt.close(fig)實驗結果如下所示:
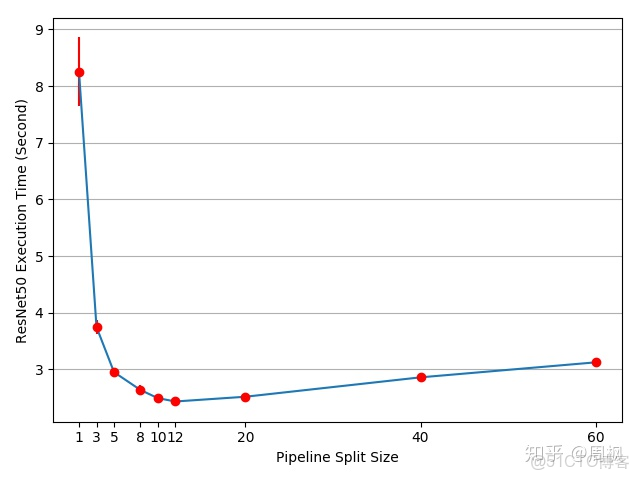
流水線輸入分割份數
如上圖所示,最佳的參數為 12,其將導致 3.75/2.43-1=54% 的加速。但這仍存在加速的可能。例如,所有在 cuda:0 上的操作放在默認的 stream 上。這意味着,在下一個 split 上的計算,不能與上一個 split 的 copy 操作進行重疊。然而,由於 next_split 和 prev_plit 是不同的 tensor,因此這不存在問題。
該實現需要在每個 GPU 上使用多個 stream,並且模型中不同的子網絡需要使用不同的 stream 管理策略。
10 pytorch中 tensor.detach() 和 tensor.data 的區別
10.1 區別
區別可以歸納為一句話:.detach()is to detach a tensor from the network graph, making the tensor no gradient, while ‘.data’ is only to obtain tensor-data from Variable
PyTorch中tensor.data 仍保留,但建議使用 tensor.detach(),區別在於x .data 返回和 x 的相同數據 tensor, 但不會加入到x的計算曆史裏,且require s_grad = False,這樣有些時候是不安全的,因為 x.data 不能被 autograd 追蹤求微分 。x .detach() 返回相同數據的 tensor,且 requires_grad=False,但能通過 in-place 操作在進行反向傳播的時候報告給 autograd 。
舉例:
tensor.data
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> out
tensor([0.7311, 0.8808, 0.9526], grad_fn=<SigmoidBackward>)
>>> c = out.data
>>> c
tensor([0.7311, 0.8808, 0.9526])
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的數值被c.zero_()修改
tensor([0., 0., 0.], grad_fn=<SigmoidBackward>)
>>> out.sum().backward() # 反向傳播
>>> a.grad # 這個結果很嚴重的錯誤,因為out已經改變了
tensor([ 0., 0., 0.])tensor.detach()
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.detach()
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的值被c.zero_()修改 !!
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 需要原來out的值,但是已經被c.zero_()覆蓋了,所以結果報錯
RuntimeError: one of the variables needed for gradient
computation has been modified by an這兩個例子説的很清楚,但事實上還有一個微小差別,請看下面的實驗。首先,筆者的配置是pytorch 1.1.0和python 3。那detach和data兩個區別到底是什麼呢?首先都是無梯度的純tensor,如下,
t = torch.tensor([0., 1.], requires_grad=True)
t2 = t.detach()
t3 = t.data
print(t2.requires_grad, t3.requires_grad)
# ouptut: False, False事實上,這兩個新的tensor t2和 t3 和原始 tensor t 都共享一塊數據內存。
其次,detach之後,在in-place的操作,並不會一定報錯,而且,有些情況下,梯度反傳計算是完全正確的!這是為什麼呢?其實是基於一個很簡單的道理,在計算梯度的時候,分兩種計算方式,第一種,
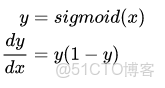
以及第二種,

你們一定看出來區別了,就是bp的時候自變量不一樣,第一種是y,第二種是x。做個實驗看看,
x = torch.tensor(0., requires_grad=True)
y = x.sigmoid()
y.detach().zero_()
print(y)
y.backward()不出所料,報錯如下,
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor []], which is output 0 of SigmoidBackward, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True)原因:這裏修改了y的data,而BP的計算依賴這個data,因此報錯。那換成另外一個操作呢,
x = torch.tensor(1., requires_grad=True)
y = x ** 2
y.detach().zero_()
print(y)
y.backward()
print(x.grad)這裏成功輸出如下,
tensor(0., grad_fn=<PowBackward0>)
tensor(2.)總之,用detach還是很保險的,有些情況下是能夠報錯的,但並不全都是。事實上,直接修改圖中的節點很少用到,一般都是用來計算一些其他的輔助變量,用以debug,這是比較多。
10.2 用法實例
(1).detach()
場合一:當反向傳播時,如果僅更新部分網絡。例如,在訓練GAN時,僅更新netD而不更新netG時,您應該這樣編寫:
fake = netG(noise)
out_ = netD(fake.detach())
loss = …場合二: requires_grad=True的tensor取值轉換成numpy
'''requires_grad=True的tensor'''
>>> tensor1 = torch.tensor([1.0,2.0],requires_grad=True)
>>> type(tensor1)
<class 'torch.Tensor'>
#錯誤用法
>>> tensor2=tensor1.numpy()
Traceback (most recent call last):
File "<pyshell#42>", line 1, in <module>
tensor1=tensor1.numpy()
RuntimeError: Can't call numpy() on Variable that requires grad. Use var.detach().numpy() instead.
#正確用法
>>> tensor2=tensor1.detach().numpy()
>>> tensor2
array([1., 2.], dtype=float32)
'''requires_grad=False的tensor'''
>>> tensor1 = torch.tensor([1.0,2.0])
>>> tensor2=tensor1.numpy()
>>> tensor2
array([1., 2.], dtype=float32)(2).data
As for .data, from data-type Variable, get data through '.data '.
11 requires_grad_(), detach(), torch.no_grad()的區別
11.1 基本概念
Tensor是一個多維矩陣,其中包含所有的元素為同一數據類型。默認數據類型為torch.float32。tensor的grad參數見鏈接《tensor的grad參數》。
- 示例一
>>> a = torch.tensor([1.0])
>>> a.data
tensor([1.])
>>> a.grad
>>> a.requires_grad
False
>>> a.dtype
torch.float32
>>> a.item()
1.0
>>> type(a.item())
<class 'float'>Tensor中只有一個數字時,使用torch.Tensor.item()可以得到一個Python數字。requires_grad為True時,表示需要計算Tensor的梯度。requires_grad=False可以用來凍結部分網絡,只更新另一部分網絡的參數。
- 示例二
>>> a = torch.tensor([1.0, 2.0])
>>> b = a.data
>>> id(b)
139808984381768
>>> id(a)
139811772112328
>>> b.grad
>>> a.grad
>>> b[0] = 5.0
>>> b
tensor([5., 2.])
>>> a
tensor([5., 2.])a.data返回的是一個新的Tensor對象b,a、b的 id 不同,説明二者不是同一個Tensor,但b與a共享數據的存儲空間,即二者的數據部分指向同一塊內存,因此修改b的元素時,a的元素也對應修改。
11.2 requires_grad_()與detach()
>>> a = torch.tensor([1.0, 2.0])
>>> a.data
tensor([1., 2.])
>>> a.grad
>>> a.requires_grad
False
>>> a.requires_grad_()
tensor([1., 2.], requires_grad=True)
>>> c = a.pow(2).sum()
>>> c.backward()
>>> a.grad
tensor([2., 4.])
>>> b = a.detach()
>>> b.grad
>>> b.requires_grad
False
>>> b
tensor([1., 2.])
>>> b[0] = 6
>>> b
tensor([6., 2.])
>>> a
tensor([6., 2.], requires_grad=True)requires_grad_()
requires_grad_()函數會改變Tensor的requires_grad屬性並返回Tensor,修改requires_grad的操作是原位操作(in place)。其默認參數為requires_grad=True。requires_grad=True時,自動求導會記錄對Tensor的操作,requires_grad_()的主要用途是告訴自動求導開始記錄對Tensor的操作。
detach()
detach()函數會返回一個新的Tensor對象b,並且新Tensor是與當前的計算圖分離的,其requires_grad屬性為False,反向傳播時不會計算其梯度。b與a共享數據的存儲空間,二者指向同一塊內存。
注:共享內存空間只是共享的數據部分,
a.grad與b.grad是不同的。
11.3 torch.no_grad()
torch.no_grad()是一個上下文管理器,用來禁止梯度的計算,通常用來網絡推斷中,它可以減少計算內存的使用量。
>>> a = torch.tensor([1.0, 2.0], requires_grad=True)
>>> with torch.no_grad():
... b = n.pow(2).sum()
...
>>> b
tensor(5.)
>>> b.requires_grad
False
>>> c = a.pow(2).sum()
>>> c.requires_grad
True上面的例子中,當 a 的requires_grad=True時,不使用torch.no_grad(),c.requires_grad為True,而使用torch.no_grad()時,b.requires_grad為False。當不需要進行反向傳播時(推斷)或不需要計算梯度(網絡輸入)時,requires_grad=True會佔用更多的計算資源及存儲資源。
11.4 總結
requires_grad_()會修改Tensor的requires_grad屬性;
detach()會返回一個與計算圖分離的新Tensor,新Tensor不會在反向傳播中計算梯度,會在特定場合使用;
torch.no_grad()更節省計算資源和存儲資源,其作用域範圍內的操作不會構建計算圖,常用在網絡推斷中。
12 torch.utils.data中的Dataset和DataLoader
12.1 Dataset
torch.utils.data.Dataset類是torch一個基礎的抽象類,Dataset可以是任何東西,但它始終包含一個__len__函數(通過Python中的標準函數len調用)和一個用來索引到內容中的__getitem__函數。其定義如下:
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):(1)較常見的是TensorDataset,它是一個封裝了張量的Dataset。通過定義長度和索引的方式,是我們可以對張量的第一維進行迭代,索引和切片。這將使我們在訓練中,獲取同一行中的自變量和因變量更加容易。
例如:假設我們有訓練數據集的輸入數據為x_train(shape為N×3),其標籤數據為y_train(shape為N×1),最原始的數據獲取方法是分別對x和y的值進行迭代循環:
xb = x_train[i*batchsize:(i+1)*batchsize]
yb = y_train[i*batchsize:(i+1)*batchsize]有了TensorDataset後, 可以直接一步獲取:
train_ds = TensorDataset(x_train, y_train)
xb,yb = train_ds[i*batchsize:(i+1)*batchsize](2)自定義Datasets的關鍵就是重載 "__len__"和"__getitem__"兩個函數!而 "__add__"函數的作用是使得類定義對象擁有"object1 + object2"的功能,一般情況不需要重載該函數。
- __len__函數:使得類對象擁有 "len(object)"功能,返回dataset的size。
- __getitem__函數:使得類對象擁有"object[index]"功能,可以用索引i去獲得第i+1個樣本。
12.2 DataLoader
PyTorch的torch.utils.data中的DataLoader負責批量數據管理,是在數據集上提供單進程或多進程的迭代器。你可以使用任意的Dataset創建一個DataLoader。DataLoader使得對批量數據的迭代更容易。
(1)參數
DataLoader完整的參數表如下:
class torch.utils.data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=<function default_collate>,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None)幾個關鍵的參數意思:
- shuffle:設置為True的時候,每個世代都會打亂數據集;
batch_size:batch的尺寸。- collate_fn:如何取樣本的,我們可以定義自己的函數來準確地實現想要的功能;
- drop_last:告訴如何處理數據集長度除於batch_size餘下的數據。True就拋棄,否則保留;
(2)簡單使用
DataLoader自動為我們提供每一小批量的數據來代替切片的方式:train_data[i*batchsize : (i+1)*batchsize],該接口主要用來將自定義的數據讀取接口的輸出或者PyTorch已有的數據讀取接口的輸入按照batch size封裝成Tensor。(方便產生一個可迭代對象(iterator),每次輸出指定batch_size大小的Tensor),可以認為DataLoader(train_ds,batch_size)輸出的為:train_dl = [(x_train_batch1,y_train_batch1),(x_train_batch2,y_train_batch2),....., (x_train_batchn,y_train_batchn)]。假設我們有訓練數據集的輸入數據為x_train(shape為N×3),其標籤數據為y_train(shape為N×1),將數據轉換成TensorData後,訓練時就可以直接使用以下DataLoader命令得到單個batch的數據進行使用:
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs)
for epoch in range(epochs):
for xb, yb in train_dl:
pred = model(xb)
loss = loss_func(pred, yb)(3)深入collate_fn
collate_fn應當是一個可調用對象,常見的可以是外部定義的函數或者lambda函數。DataLoader不設置collate_fn參數時每個batch_size輸出的樣本序列,所以可以理解為一個後處理的函數。collate_fn默認為default_collate(batch),其中batch為collate_fn的輸入,究其類型,其實batch為類型為list的數據,即batch=[ (x_train[0], y_train[0] ), (x_train[1] ,y_train[1] ), ...... , (x_train[batch_size], y_train[batch_size] )],list中每個元素都是一個列表,每個列表包含batch_size個元組,每個元組包含TensorDataset的單獨數據。default_collate的作用就是將batch中的x_train和y_train分別提取後stack後輸出,類似default_collate作用的函數可寫作如下:
def collate_func(batch):
# print(batch) #輸出為<class 'list'>
x=[]
y=[]
for (xi,yi) in batch:
x.append(xi)
y.append(yi)
return torch.stack(x),torch.stack(y)具體應用效果如下:
import torch
import torch.utils.data as Data
import numpy as np
def collate_func(batch):
print(f"i-th batch list data:{batch}")
x=[]
y=[]
for (xi,yi) in batch:
x.append(xi)
y.append(yi)
return torch.stack(x),torch.stack(y)
test = np.array([0,1,2,3,4,5,6,7,8,9,10,11])
inputing = torch.tensor(np.array([test[i:i + 3] for i in range(10)]))
target = torch.tensor(np.array([test[i:i + 1] for i in range(10)]))
print(inputing)
print(target)
'''
輸出為:
tensor([[ 0, 1, 2],
[ 1, 2, 3],
[ 2, 3, 4],
[ 3, 4, 5],
[ 4, 5, 6],
[ 5, 6, 7],
[ 6, 7, 8],
[ 7, 8, 9],
[ 8, 9, 10],
[ 9, 10, 11]])
tensor([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9]])
'''
torch_dataset = Data.TensorDataset(inputing,target)
batch_size = 3
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=batch_size,
collate_fn=collate_func
)
#
for (i,j) in loader:
print(f"i-th batch x_train output:{i}")
print(f"i-th batch y_train output:{j}")
print("**********************************************************************")
'''
輸出為:
i-th batch list data:[(tensor([0, 1, 2]), tensor([0])), (tensor([1, 2, 3]), tensor([1])), (tensor([2, 3, 4]), tensor([2]))]
i-th batch x_train output:tensor([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
i-th batch y_train output:tensor([[0],
[1],
[2]])
**********************************************************************
i-th batch list data:[(tensor([3, 4, 5]), tensor([3])), (tensor([4, 5, 6]), tensor([4])), (tensor([5, 6, 7]), tensor([5]))]
i-th batch x_train output:tensor([[3, 4, 5],
[4, 5, 6],
[5, 6, 7]])
i-th batch y_train output:tensor([[3],
[4],
[5]])
**********************************************************************
i-th batch list data:[(tensor([6, 7, 8]), tensor([6])), (tensor([7, 8, 9]), tensor([7])), (tensor([ 8, 9, 10]), tensor([8]))]
i-th batch x_train output:tensor([[ 6, 7, 8],
[ 7, 8, 9],
[ 8, 9, 10]])
i-th batch y_train output:tensor([[6],
[7],
[8]])
**********************************************************************
i-th batch list data:[(tensor([ 9, 10, 11]), tensor([9]))]
i-th batch x_train output:tensor([[ 9, 10, 11]])
i-th batch y_train output:tensor([[9]])
**********************************************************************
'''如果自定義collate_fn為以下函數:
collate_fn=lambda x:(
torch.cat([x[i][j].unsqueeze(0) for i in range(len(x))], 0
).unsqueeze(0) for j in range(len(x[0]))
)顯然,這裏x為[ (x_train[0], y_train[0] ), (x_train[1] ,y_train[1] ), ...... , (x_train[batch_size], y_train[batch_size] )],其中 i 取的是batch_size,j 取元組(x_train[i], y_train[i] )的長度,這裏即2。運行時, j=0時,對每個x[i][0](即x_train[i]),首先通過unsqueeze(0)方法在前面加一維,即將shape為(3,)變成(1,3),torch.cat([x_train[0],x_train[batch_size]],0)將其打包起來shape為(batch_size,3)的tensor,最後再通過unsqueeze(0)方法在前面加一維,變成shape為(1,batch_size,3))的tensor輸出;j=1時,對每個x[i][1](即y_train[i]),經過相同操作輸出變成shape為(1,3, 1))的tensor輸出。具體輸出結果為:
tensor([[[ 0, 1, 2],
[ 1, 2, 3],
[ 2, 3, 4]]], dtype=torch.int32)
tensor([[[ 0],
[ 1],
[ 2]]], dtype=torch.int32)
tensor([[[ 3, 4, 5],
[ 4, 5, 6],
[ 5, 6, 7]]], dtype=torch.int32)
tensor([[[ 3],
[ 4],
[ 5]]], dtype=torch.int32)
tensor([[[ 6, 7, 8],
[ 7, 8, 9],
[ 8, 9, 10]]], dtype=torch.int32)
tensor([[[ 6],
[ 7],
[ 8]]], dtype=torch.int32)
tensor([[[ 9, 10, 11]]], dtype=torch.int32)
tensor([[[ 9]]], dtype=torch.int32)十四 nn.Parameters & nn.Module.register_parameter& buffer & nn.Module.register_buffer()
14.0 parameter和buffer
模型中需要保存下來的參數包括兩種:
- 一種是反向傳播需要被optimizer更新的,稱之為parameter
- 一種是反向傳播不需要被optimizer更新的,稱之為buffer
第一種參數我們可以通過model.parameter()返回;第二種參數我們可以通過model.buffers()返回。因為我們模型保存的是state_dict返回的OrderedDict,所以這兩種參數不僅要滿足是/否需要更新的要求,還需要被保存到OrderedDict。
(1)parameter參數有兩種創建方式
1、我們可以直接將模型的成員變量(self.xxx)通過nn.Parameter()創建,會自動註冊到parameters中,可以通過model.parameters()返回,並且這樣創建的參數會自動保存到OrderedDict中去。
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.my_param = nn.Parameter(torch.randn(3, 3)) # 模型的成員變量
def forward(self, x):
# 可以通過 self.my_param 和 self.my_buffer 訪問
pass
model = MyModel()
for param in model.parameters():
print(param)
print("----------------")
print(model.state_dict())
輸出:
Parameter containing:
tensor([[-0.5421, 2.9562, 0.3447],
[ 0.0869, -0.3464, 1.1299],
[ 0.8644, -0.1384, -0.6338]])
----------------
OrderedDict([('param', tensor([[-0.5421, 2.9562, 0.3447],
[ 0.0869, -0.3464, 1.1299],
[ 0.8644, -0.1384, -0.6338]]))])2、通過nn.Parameter()創建普通的Parameter對象,不作為模型的成員變量,然後將Parameter對象通過register_parameter()進行註冊,可以通過model.parameters()返回,註冊後的參數也是會自動保存到OrderedDict中去。
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
param = nn.Parameter(torch.randn(3, 3)) # 普通 Parameter 對象
self.register_parameter("my_param", param)
def forward(self, x):
# 可以通過 self.my_param 和 self.my_buffer 訪問
pass
model = MyModel()
for param in model.parameters():
print(param)
print("----------------")
print(model.state_dict())輸出:
Parameter containing:
tensor([[-0.2313, -0.1490, -1.3148],
[-1.2862, -2.2740, 1.0558],
[-0.6559, 0.4552, 0.5993]])
----------------
OrderedDict([('my_param', tensor([[-0.2313, -0.1490, -1.3148],
[-1.2862, -2.2740, 1.0558],
[-0.6559, 0.4552, 0.5993]]))])(2)buffer參數的創建方式
這種參數的創建需要先創建tensor,然後將tensor通過register_buffer()進行註冊,可以通過model._all_buffers()返回,註冊完成後參數也會自動保存到OrderedDict中去。
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
buffer = torch.randn(2, 3) # tensor
self.register_buffer('my_buffer', buffer)
def forward(self, x):
# 可以通過 self.param 和 self.my_buffer 訪問
pass
model = MyModel()
for buffer in model._all_buffers():
print(buffer)
print("----------------")
print(model.state_dict())
輸出:
tensor([[-0.2191, 0.1378, -1.5544],
[-0.4343, 0.1329, -0.3834]])
----------------
OrderedDict([('my_buffer', tensor([[-0.2191, 0.1378, -1.5544],
[-0.4343, 0.1329, -0.3834]]))])總結:
I、模型中需要進行更新的參數註冊為Parameter,不需要進行更新的參數註冊為buffer
II、模型保存的參數是Model.state_dict()返回的OrderedDict
III、模型進行設備移動時(CPU--->GPU),模型中註冊的參數(Parameter和buffer)會同時進行移動。
14.1 nn.Module.register_parameter & nn.Parameters
nn.Parameters 與 register_parameter 都會向 _parameters寫入參數,但是後者可以支持字符串命名。 從源碼中可以看到,nn.Parameters為Module添加屬性的方式也是通過register_parameter向 _parameters寫入參數。
def __setattr__(self, name, value):
def remove_from(*dicts):
for d in dicts:
if name in d:
del d[name]
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
else:
buffers = self.__dict__.get('_buffers')
if buffers is not None and name in buffers:
if value is not None and not isinstance(value, torch.Tensor):
raise TypeError("cannot assign '{}' as buffer '{}' "
"(torch.Tensor or None expected)"
.format(torch.typename(value), name))
buffers[name] = value
else:
object.__setattr__(self, name, value)import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
print('before register:\n', self._parameters, end='\n\n')
self.register_parameter('my_param1', nn.Parameter(torch.randn(3, 3)))
print('after register and before nn.Parameter:\n', self._parameters, end='\n\n')
self.my_param2 = nn.Parameter(torch.randn(2, 2))
print('after register and nn.Parameter:\n', self._parameters, end='\n\n')
def forward(self, x):
return x
mymodel = MyModel()
for k, v in mymodel.named_parameters():
print(k, v)程序返回為:
before register:
OrderedDict()
after register and before nn.Parameter:
OrderedDict([('my_param1', Parameter containing:
tensor([[-1.3542, -0.4591, -2.0968],
[-0.4345, -0.9904, -0.9329],
[ 1.4990, -1.7540, -0.4479]], requires_grad=True))])
after register and nn.Parameter:
OrderedDict([('my_param1', Parameter containing:
tensor([[-1.3542, -0.4591, -2.0968],
[-0.4345, -0.9904, -0.9329],
[ 1.4990, -1.7540, -0.4479]], requires_grad=True)), ('my_param2', Parameter containing:
tensor([[ 1.0205, -1.3145],
[-1.1108, 0.4288]], requires_grad=True))])
my_param1 Parameter containing:
tensor([[-1.3542, -0.4591, -2.0968],
[-0.4345, -0.9904, -0.9329],
[ 1.4990, -1.7540, -0.4479]], requires_grad=True)
my_param2 Parameter containing:
tensor([[ 1.0205, -1.3145],
[-1.1108, 0.4288]], requires_grad=True)14.2 nn.Module.register_parameter & nn.Module.register_buffer()
torch.nn.register_parameter()用於註冊Parameter實例到當前Module中(一般可以用torch.nn.Parameter()代替);torch.nn.register_buffer()用於註冊Buffer實例到當前Module中。此外,Module中的parameters()函數會返回當前Module中所註冊的所有Parameter的迭代器;而_all_buffers()函數會返回當前Module中所註冊的所有Buffer的迭代器,(所以優化器不會計算Buffer的梯度,自然不會對其更新)。此外,Module中的state_dict()會返回包含當前Module中所註冊的所有Parameter和Buffer(所以模型中未註冊成Parameter或Buffer的參數無法被保存)。
PyTorch中定義模型時,有時候會遇到self.register_buffer('name', Tensor)的操作,該方法的作用是定義一組參數,該組參數的特別之處在於:模型訓練時不會更新(即調用 optimizer.step() 後該組參數不會變化,只可人為地改變它們的值),但是保存模型時,該組參數又作為模型參數不可或缺的一部分被保存。
為了更好地理解這句話,按照慣例,我們通過一個例子實驗來解釋:
首先,定義一個模型並實例化:
import torch
import torch.nn as nn
from collections import OrderedDict
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# (1)常見定義模型時的操作
self.param_nn = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(1, 1, 3, bias=False)),
('fc', nn.Linear(1, 2, bias=False))
]))
# (2)使用register_buffer()定義一組參數
self.register_buffer('param_buf', torch.randn(1, 2))
# (3)使用形式類似的register_parameter()定義一組參數
self.register_parameter('param_reg', nn.Parameter(torch.randn(1, 2)))
# (4)按照類的屬性形式定義一組變量
self.param_attr = torch.randn(1, 2)
def forward(self, x):
return x
net = Model()上例中,我們通過繼承nn.Module類定義了一個模型,在模型參數的定義中,我們分別以(1)常見的nn.Module類形式、(2)self.register_buffer()形式、(3)self.register_parameter()形式,以及(4)python類的屬性形式定義了4組參數。
(a)哪些參數可以在模型訓練時被更新?
這可以通過net.parameters()查看,因為定義優化器時是這樣的:optimizer = SGD(net.parameters(), lr=0.1)。為了方便查看,我們使用 net.named_parameters():
In [8]: list(net.named_parameters())
Out[8]:
[('param_reg',
Parameter containing:
tensor([[-0.0617, -0.8984]], requires_grad=True)),
('param_nn.conv.weight',
Parameter containing:
tensor([[[[-0.3183, -0.0426, -0.2984],
[-0.1451, 0.2686, 0.0556],
[-0.3155, 0.0451, 0.0702]]]], requires_grad=True)),
('param_nn.fc.weight',
Parameter containing:
tensor([[-0.4647],
[ 0.7753]], requires_grad=True))]可以看到,我們定義的4組參數中,只有(1)和(3)定義的參數可以被更新,而self.register_buffer()和以python類的屬性形式定義的參數都不能被更新。也就是説,modules和parameters可以被更新,而buffers和普通類屬性不行。
那既然這兩種形式定義的參數都不能被更新,二者可以互相替代嗎?答案是不可以,原因看下一節:
(b)這其中哪些才算是模型的參數呢?
模型的所有參數都裝在 state_dict 中,因為保存模型參數時直接保存 net.state_dict()。我們看一下其中究竟是哪些參數:
In [9]: net.state_dict()
Out[9]:
OrderedDict([('param_reg', tensor([[-0.0617, -0.8984]])),
('param_buf', tensor([[-1.0517, 0.7663]])),
('param_nn.conv.weight',
tensor([[[[-0.3183, -0.0426, -0.2984],
[-0.1451, 0.2686, 0.0556],
[-0.3155, 0.0451, 0.0702]]]])),
('param_nn.fc.weight',
tensor([[-0.4647],
[ 0.7753]]))])可以看到,通過 nn.Module 類、self.register_buffer() 以及 self.register_parameter() 定義的參數都在 state-dict 中,只有用python類的屬性形式定義的參數不包含其中。也就是説,保存模型時,buffers,modules和parameters都可以被保存,但普通屬性不行。
(3)self.register_buffer() 的使用方法
在用self.register_buffer('name', tensor) 定義模型參數時,其有兩個形參需要傳入。第一個是字符串,表示這組參數的名字;第二個就是tensor 形式的參數。
在模型定義中調用這個參數時(比如改變這組參數的值),可以使用self.name 獲取。本文例中,就可用self.param_buf 引用。這和類屬性的引用方法是一樣的。
在實例化模型後,獲取這組參數的值時,可以用 net.buffers() 方法獲取,該方法返回一個生成器(可迭代變量):
In [10]: net.buffers()
Out[10]: <generator object Module.buffers at 0x00000289CA0032E0>
In [11]: list(net.buffers())
Out[11]: [tensor([[-1.0517, 0.7663]])]
# 也可以用named_buffers() 方法同時獲取名字
In [12]: list(net.named_buffers())
Out[12]: [('param_buf', tensor([[-1.0517, 0.7663]]))](4)modules, parameters 和 buffers
實際上,PyTorch 定義的模型用OrderedDict() 的方式記錄這三種類型,分別保存在self._modules, self._parameters 和 self._buffers 三個私有屬性中。調試模式時就可以看到每個模型都有這幾個私有屬性:
調試模式 變量窗口
由於是私有屬性,我們無法在實例化的變量上調用這些屬性,可以在模型定義中調用它們:
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 常見定義模型時的操作
self.param_nn = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(1, 1, 3, bias=False)),
('fc', nn.Linear(1, 2, bias=False))
]))
# 使用register_buffer()定義一組參數
self.register_buffer('param_buf', torch.randn(1, 2))
# 使用形式類似的register_parameter()定義一組參數
self.register_parameter('param_reg', nn.Parameter(torch.randn(1, 2)))
# 按照類的屬性形式定義一組變量
self.param_attr = torch.randn(1, 2)
print('self._modules: ', self._modules)
print('self._parameters: ', self._modules)
print('self._buffers: ', self._modules)
def forward(self, x):
return x模型實例化時,調用了 init() 方法,我們就可以看到調用輸出結果:
In [21]: net = Model()
self._modules: OrderedDict([('param_nn', Sequential(
(conv): Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), bias=False)
(fc): Linear(in_features=1, out_features=2, bias=False)
))])
self._parameters: OrderedDict([('param_reg', Parameter containing:
tensor([[-0.5666, -0.2624]], requires_grad=True))])
self._buffers: OrderedDict([('param_buf', tensor([[-0.4005, -0.8199]]))])在模型的實例化變量上調用時,三者有着相似的方法:
net.modules()
net.named_modules()
net.parameters()
net.named_parameters()
net.buffers()
net.named_buffers()細心的讀着可能會發現,self._parameters 和 net.parameters() 的返回值並不相同。這裏self._parameters 只記錄了使用 self.register_parameter() 定義的參數,而net.parameters() 返回所有可學習參數,包括self._modules 中的參數和self._parameters 參數的並集。
實際上,由nn.Module類定義的參數和self.register_parameter() 定義的參數性質是一樣的,都是nn.Parameter 類型。
十五、梯度累積
15.0 梯度累積原理
梯度累積是一種用於優化神經網絡訓練的技巧,主要是解決顯存不足的問題。在傳統的梯度下降算法中,每次迭代更新網絡參數時,需要將所有訓練樣本的梯度都累加起來,並求平均值,再利用平均梯度來更新參數。但是,當訓練樣本較多或者網絡較深時,梯度的計算和更新會消耗大量顯存,導致內存溢出或者訓練速度變慢。
梯度累積是一種訓練神經網絡的數據Sample樣本按Batch拆分為幾個小Batch的方式,然後按順序計算。在進一步討論梯度累積之前,我們來看看神經網絡的計算過程。
深度學習模型由許多相互連接的神經網絡單元所組成,在所有神經網絡層中,樣本數據會不斷向前傳播。在通過所有層後,網絡模型會輸出樣本的預測值,通過損失函數然後計算每個樣本的損失值(誤差)。神經網絡通過反向傳播,去計算損失值相對於模型參數的梯度。最後這些梯度信息用於對網絡模型中的參數進行更新。
優化器用於對網絡模型模型權重參數更新的數學公式。以一個簡單隨機梯度下降(SGD)算法為例。
假設Loss Function函數公式為:
=\frac{1}{2}\left(h\left(x^k\right)-y^k\right)^2")
在構建模型時,優化器用於計算最小化損失的算法。這裏SGD算法利用Loss函數來更新權重參數公式為:

其中

是網絡模型中的可訓練參數(權重或偏差),

是學習率,

是相對於網絡模型參數的損失。
梯度累積則是隻計算神經網絡模型,但是並不及時更新網絡模型的參數,同時在計算的時候累積計算時候得到的梯度信息,最後統一使用累積的梯度來對參數進行更新。

在不更新模型變量的時候,實際上是把原來的數據Batch分成幾個小的Mini-Batch,每個step中使用的樣本實際上是更小的數據集。
在N個step內不更新變量,使所有Mini-Batch使用相同的模型變量來計算梯度,以確保計算出來得到相同的梯度和權重信息,算法上等價於使用原來沒有切分的Batch size大小一樣。即:

最終在上面步驟中累積梯度會產生與使用全局Batch size大小相同的梯度總和。
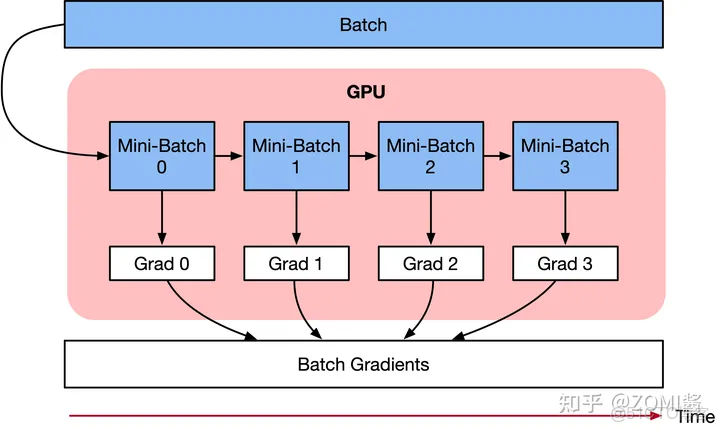
當然在實際工程當中,關於調參和算法上有兩點需要注意的:
學習率 learning rate:一定條件下,Batch size越大訓練效果越好,梯度累積則模擬了batch size增大的效果,如果 accumulation steps為4,則Batch size增大了4倍,根據經驗,使用梯度累積的時候需要把學習率適當 放大。
歸一化 Batch Norm:accumulation steps為4時進行Batch size模擬放大效果,和真實Batch size相比,數據的分佈其實並不完全相同,4倍Batch size的BN計算出來的均值和方差與實際數據均值和方差不太相同,因此有些實現中會使用Group Norm來代替Batch Norm。
15.1 梯度累積實現
正常訓練一個batch的偽代碼:
for i, (images, labels) in enumerate(train_data):
# 1. forwared 前向計算
outputs = model(images) # 正向傳播
loss = criterion(outputs, labels) # 計算損失
# 2. backward 反向傳播計算梯度
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向傳播,計算梯度
optimizer.step() # 更新參數model(images)輸入圖像和標籤,前向計算。criterion(outputs, labels)通過前向計算得到預測值,計算損失函數。ptimizer.zero_grad()清空歷史的梯度信息。loss.backward()進行反向傳播,計算當前batch的梯度。optimizer.step()根據反向傳播得到的梯度,更新網絡參數。
即在網絡中輸入一個batch的數據,就計算一次梯度,更新一次網絡。
使用梯度累加後:
# 梯度累加參數
accumulation_steps = 4
for i, (images, labels) in enumerate(train_data):
# 1. forwared 前向計算
outputs = model(imgaes) # 正向傳播
loss = criterion(outputs, labels) # 計算損失函數
# 2.1 loss regularization loss正則化
loss += loss / accumulation_steps # 損失標準化
# 2.2 backward propagation 反向傳播計算梯度
loss.backward() # 反向傳播,計算梯度
# 3. update parameters of net
if ((i+1) % accumulation)==0:
# optimizer the net
optimizer.step() # 更新參數
optimizer.zero_grad() # 梯度清零model(images)輸入圖像和標籤,前向計算。criterion(outputs, labels)通過前向計算得到預測值,計算損失函數。loss / accumulation_stepsloss每次更新,因此每次除以steps累積到原梯度上。loss.backward()進行反向傳播,計算當前batch的梯度。- 多次循環偽代碼步驟1-2,不清空梯度,使梯度累加在歷史梯度上。
optimizer.step()梯度累加一定次數後,根據所累積的梯度更新網絡參數。optimizer.zero_grad()清空歷史梯度,為下一次梯度累加做準備。
梯度累積就是,每次獲取1個batch的數據,計算1次梯度,此時梯度不清空,不斷累積,累積一定次數後,根據累積的梯度更新網絡參數,然後清空所有梯度信息,進行下一次循環。

