事後觀察經驗回放。OpenAI的論文。
1707.01495
摘要:
處理稀疏獎勵。提出了Hindsight Experience Replay新技術,使得可以從稀疏二元的獎勵中進行有效的學習。可以與任意off-policy的強化學習算法結合。可以看作一種implicit curriculum。
在用機械臂操作物件的任務進行了演示。在3個不同的任務上進行了實驗:pushing, sliding, and pick-and-place。在每一個任務中只使用了表示任務是否完成的二元獎勵。消解實驗表明Hindsight Experience Replay對在這些具有挑戰性的環境裏進行有效訓練是至關重要的組分。在物理仿真的訓練可以部署到物理機器人上並完成任務。實驗視頻地址https://goo.gl/SMrQnI
關鍵觀察:
不同於當前的model-free RL算法,人有一種能力,可以從不符合期待的結果裏學習,如同從符合期待的結果裏學習。想象你在學習曲棍球,試圖把一個球餅打進一個網裏。你打了一下球餅,球餅沒入網,從網的右邊過去了。在這種情況下,標準的強化學習算法會把這個過程的一系列動作看作一次不成功的打擊,而幾乎不會從中學習到什麼。但是我們可以從中得出另外一個結論,就是説,這一系列動作可能是成功的,如果球網在再過去右邊一點。
Hindsight Experience Replay (HER) 適用於多目標的情況,如:到達每一個系統的狀態可以當作一個獨立的目標。HER基於訓練universal policies (Schaul et al., 2015a) 。universal policies不僅把當前狀態作為輸入,而且目標狀態作為輸入。HER背後的核心點是用一個其它的目標去替換智能體試圖達成的目標。
(UVFA)
Universal Value Function Approximators (UVFA) (Schaul et al., 2015a) is an extension of DQN to the setup where there is more than one goal we may try to achieve. 每一個episode不僅與(s, a)相關,而且與g也相關。在一個episode裏, g選定以後就保持不變。策略和Q函數不僅與(s, a)相關,而且與g也相關。
A motivating example

標準RL失效,improving exploration,count-based exploration,bootstrapped DQN都失效。reward shaping有效,需要提供領域知識。
HER方法背後的核心點是用另外一個目標重新評估行動軌跡——這個行動軌跡雖然不同幫助我們學習怎麼到達目標狀態g,但是它確定可以告訴我們怎麼樣到達狀態sT。這種信息可以通過使用off-policy RL算法來獲取,在其時我們把經驗回放裏的目標狀態從g修改到sT。另外,我們可以在回放裏保留原來目標g。通過這種修改,至少有一半的行動軌跡有不同於-1的獎勵。這樣的話,學習就變得更容易了。
DQN without HER can only solve the task for n ≤ 13 while DQN with HER easily solves the task for n up to 50.
HER Algorithm
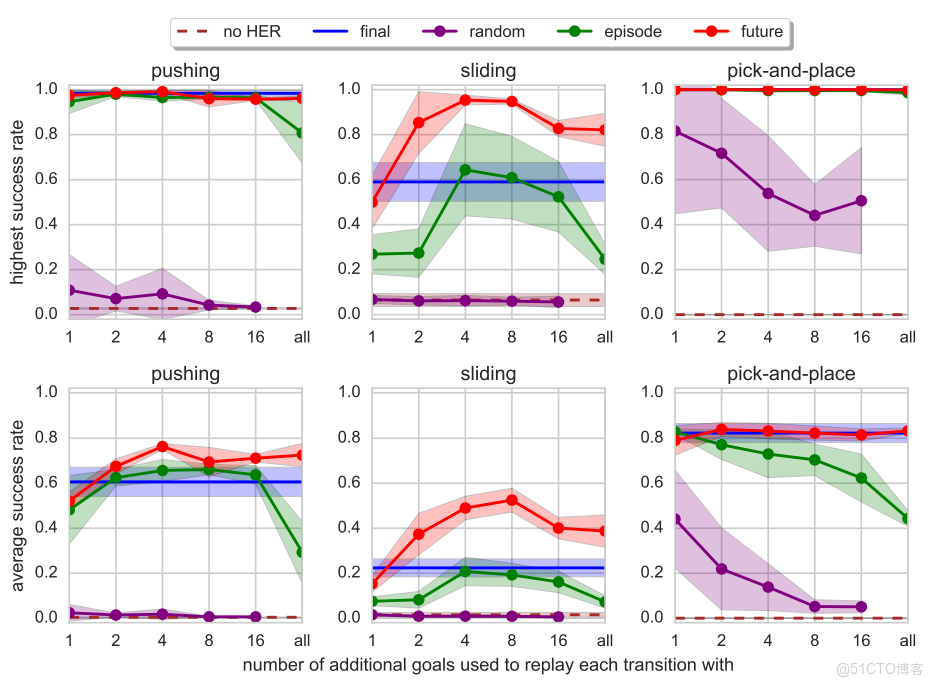
為了使用HER,一個必須要做的事情是選擇一個額外目標集合。最簡單的一個版本是給每一個行動軌跡一個目標m(sT),即軌跡最終狀態所獲取的目標。

How many goals should we replay each trajectory with and how to choose them?