
生成對抗網絡(Generative Adversarial Networks, GAN)是一種深度學習模型,是近年來複雜分佈上無監督學習最具前景的學習方法之一。
GAN 主要包括了兩個部分,即生成器 generator 與判別器 discriminator。生成器主要用來學習真實圖像分佈從而讓自身生成的圖像更加真實,以騙過判別器。判別器則需要對接收的圖片進行真假判別。在整個過程中,生成器努力地讓生成的圖像更加真實,而判別器則努力地去識別出圖像的真假,這個過程相當於一個二人博弈,隨着時間的推移,生成器和判別器在不斷地進行對抗,最終兩個網絡達到了一個動態均衡:生成器生成的圖像接近於真實圖像分佈,而判別器識別不出真假圖像,對於給定圖像的預測為真的概率基本接近 0.5(相當於隨機猜測類別)。
這就是GAN的基本思想,其實並不難理解。但是,迴歸到神經網絡本身,怎麼去實現這種思想才是關鍵,我認為,進一步地,我認為如何定義損失函數才是關鍵。下圖為GAN原論文中的損失函數公式:
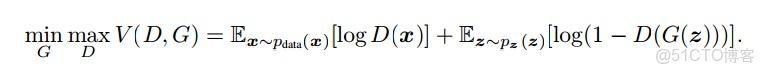
我們來説説這個公式:
- 整個式子由兩項構成。x表示真實圖片,z表示輸入G網絡的噪聲,而G(z)表示G網絡生成的圖片。
- D(x)表示D網絡判斷真實圖片是否真實的概率(因為x就是真實的,所以對於D來説,這個值越接近1越好)。而D(G(z))是D網絡判斷G生成的圖片的是否真實的概率。
- G的目的:上面提到過,D(G(z))是D網絡判斷G生成的圖片是否真實的概率,G應該希望自己生成的圖片“越接近真實越好”。也就是説,G希望D(G(z))儘可能得大,這時V(D, G)會變小。因此我們看到式子的最前面的記號是min_G。
- D的目的:D的能力越強,D(x)應該越大,D(G(x))應該越小。這時V(D,G)會變大。因此式子對於D來説是求最大(max_D)
接下來,我們通過代碼來實際感受生成式對抗網絡GAN。代碼使用Python3.8+tensorflow2.3.1實現,數據集為mnist手寫數字識別數據集。
In [1]:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import os
In [2]:
tf.__version__
Out[2]:
'2.3.1'
加載數據,我們只使用訓練集即可,忽略測試集:
In [3]:
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
In [4]:
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32') # 將數據轉換為圖像模式——單通道,然後轉換數據類型為float32。
當數據值在0周圍時,激活函數效果更加,所以,我們最好進行數據歸一化:
In [5]:
train_images = (train_images- 127.5) / 127.5 # 數據歸一化
In [6]:
batch_size = 256
buffer_size = 60000
In [7]:
datasets = tf.data.Dataset.from_tensor_slices(train_images) # tensorflow原生方法存儲數據
In [8]:
datasets = datasets.shuffle(buffer_size).batch(batch_size) # 打亂數據順序,分批成簇
In [10]:
train_images.shape
Out[10]:
(60000, 28, 28, 1)
現在,我們先定義一個生成器模型,模型網絡中,我們使用最原始的全連接網絡:
In [11]:
def generator_model():
model = keras.Sequential()
model.add(layers.Dense(256, input_shape=(100,), use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(512, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(28*28*1, use_bias=False, activation='tanh'))
model.add(layers.BatchNormalization())
model.add(layers.Reshape((28, 28, 1)))
return model
判別器模型好理解,就是一個簡單的全連接判別式網絡:
In [12]:
def discriminator_model():
model = keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(512, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(256, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(1))
return model
定義損失計算方式,在GAN網絡中使用的是交叉熵損失函數:
In [13]:
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
損失函數得分為兩個部分,一個是計算判別器的損失,一個是計算生成器的損失。其中,判別器損失也分為兩個部分,一個是計算對真實圖片的損失計算,在這一部分,我們期望模型能判別為真實圖片,也就是越靠近1越好,一個是計算對判別器的損失計算,在這一部分,我麼希望判別器能將圖像判別為假,也就是結果越靠近0越好:
In [14]:
# 生成器損失計算。
def discriminator_loss(real_out, fake_out):
real_loss = cross_entropy(tf.ones_like(real_out), real_out)
fake_loss = cross_entropy(tf.zeros_like(fake_out), fake_out)
return real_loss + fake_loss
In [15]:
# 判別器損失計算
def generator_loss(fake_out):
fake_loss = cross_entropy(tf.ones_like(fake_out), fake_out)
return fake_loss
定義優化器:
In [16]:
generator_opt = tf.keras.optimizers.Adam(1e-4)
discriminator_opt = tf.keras.optimizers.Adam(1e-4)
In [17]:
epochs = 160
noise_dim = 100 # 每個噪聲100維度
generate_image_num = 16 # 生成16個隨機噪聲
seed = tf.random.normal([generate_image_num, noise_dim]) # 16個隨機噪聲,用於可視化輸出訓練過程中的效果展示
In [18]:
generator = generator_model()
discriminator = discriminator_model()
訓練過程中的每一輪迭代,計算梯度,反向傳播:
In [19]:
def train_step(images):
noise = tf.random.normal([batch_size, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
real_out = discriminator(images, training=True)
gen_image = generator(noise, training=True)
fake_out = discriminator(gen_image, training=True)
gen_loss = generator_loss(fake_out)
disc_loss = discriminator_loss(real_out, fake_out)
gradient_gen = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradient_disc = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_opt.apply_gradients(zip(gradient_gen, generator.trainable_variables))
discriminator_opt.apply_gradients(zip(gradient_disc, discriminator.trainable_variables))
我們再定義可視化函數:
In [20]:
def genetate_plot_images(gen_model, test_noise):
pre_images = gen_model(test_noise, training=False)
fig = plt.figure(figsize=(32, 128))
for i in range(pre_images.shape[0]):
plt.subplot(1, 16, i+1)
plt.imshow((pre_images[i, :, :, 0] + 1)/2, cmap='gray')
plt.axis('off')
plt.show()
真實開始訓練:
In [21]:
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch in dataset:
train_step(image_batch)
if epoch % 20 == 0:
print('---------------------------------------------------------------------------epoch:%s-----------------------------------------------------------------------------'%(epoch+1))
genetate_plot_images(generator, seed)
print('---------------------------------------------------------------------------epoch:%s-----------------------------------------------------------------------------'%(epoch+1))
genetate_plot_images(generator, seed)
In [22]:

