
摘要: 本文詳細闡述了從零開始構建一個萬卡規模AI GPU集羣的分階段實施方案。文章從百卡驗證集羣、千卡生產集羣到萬卡超算集羣三個階段,深入探討了每個階段的架構設計、硬件選型、網絡拓撲、存儲方案、軟件棧以及Slurm的核心配置要點,旨在為AIOps工程師和系統架構師提供一份可落地、可演進的實踐指南。
關鍵詞: Slurm, GPU集羣, AIOps, Lustre, InfiniBand, 高可用, Slurm Federation
1. 前言
隨着大語言模型(LLM)的飛速發展,對大規模GPU算力的需求呈爆炸式增長。Slurm作為HPC領域應用最廣泛的開源作業調度系統,是構建大規模AI集羣的核心組件。本文將基於實踐經驗,分享一套從0到10,000+ GPU的Slurm集羣部署架構演進方案。
2. 第一階段:百卡驗證集羣 (1-128 GPUs)
此階段的核心目標是快速驗證技術棧、跑通端到端的訓練流程。
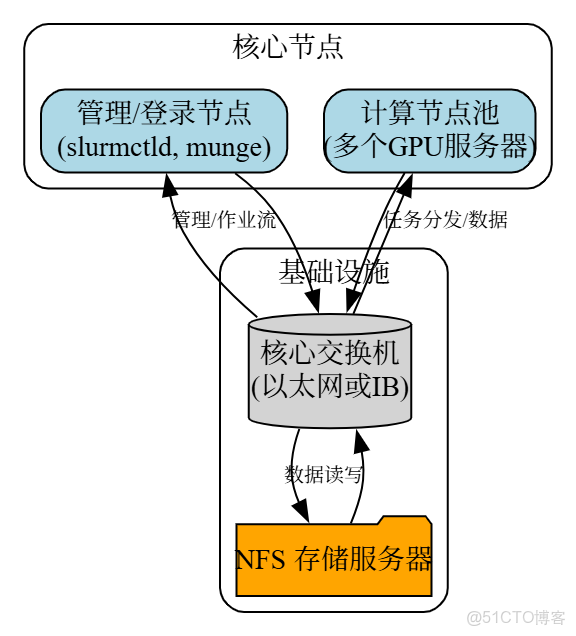
2.1 架構設計
採用單體式架構,包含管理/登錄、計算、存儲三大基本單元。
2.2 部署要點
- 硬件:管理節點(高頻CPU, 大內存),計算節點(8*A800/H800),存儲(NAS),網絡(100G RoCEv2或入門級IB)。
- 存儲:採用NFS協議,提供/home, /data, /apps等統一掛載點。
- 軟件棧:
- OS: Rocky Linux 9 / Ubuntu 24.04 LTS
- 自動化: Ansible進行標準化部署(NVIDIA Driver, CUDA, Docker/Apptainer, Slurm, Munge)。
- 監控: Prometheus + Grafana + DCGM-Exporter。
- Slurm核心配置 (slurm.conf): codeIni
# 核心配置示例
SlurmctldHost=mgmt01
ProctrackType=proctrack/cgroup
GresTypes=gpu
NodeName=gpu[01-08] CPUs=128 RealMemory=1024000 Gres=gpu:a800:8
PartitionName=main Nodes=gpu[01-08] Default=YES MaxTime=INFINITE State=UP3. 第二階段:千卡生產集羣 (128-2,048 GPUs)
此階段的核心是解決性能瓶頸和單點故障,確保業務連續性。
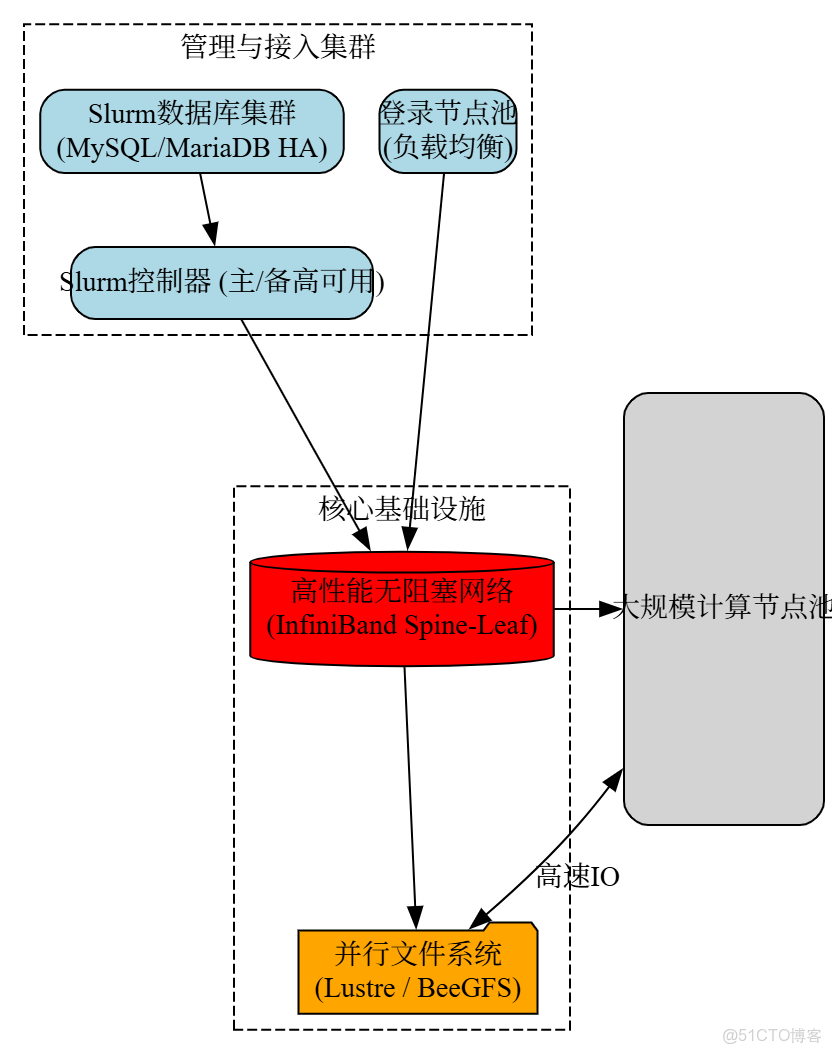
3.1 架構設計
向服務化、高可用架構演進,物理分離管理、登錄、計算、存儲等功能集羣。
3.2 部署要點
- 高可用:
- Slurm: slurmctld採用主備模式,由Pacemaker+Corosync實現自動故障轉移。
- 數據庫: 為slurmdbd配置獨立的MariaDB Galera Cluster。
- 登錄節點: 採用LVS/HAProxy做負載均衡。
- 網絡:必須升級至InfiniBand (IB) NDR 400G網絡,構建兩層Spine-Leaf無阻塞胖樹拓撲。
- 存儲:廢棄NFS,部署Lustre或BeeGFS等並行文件系統。MDS(元數據服務器)需高可用,OSS(對象存儲服務器)需多台以提供聚合帶寬。
- Slurm核心配置 (slurm.conf): codeIni
# 高可用與數據庫記賬配置
ControlMachine=slurm-master
BackupController=slurm-backup
AccountingStorageType=accounting_storage/slurmdbd
AccountingStorageHost=db-vip4. 第三階段:萬卡超算集羣 (2,048-10,000+ GPUs)
此階段的核心挑戰在於應對極致的擴展性和系統管理的複雜性。
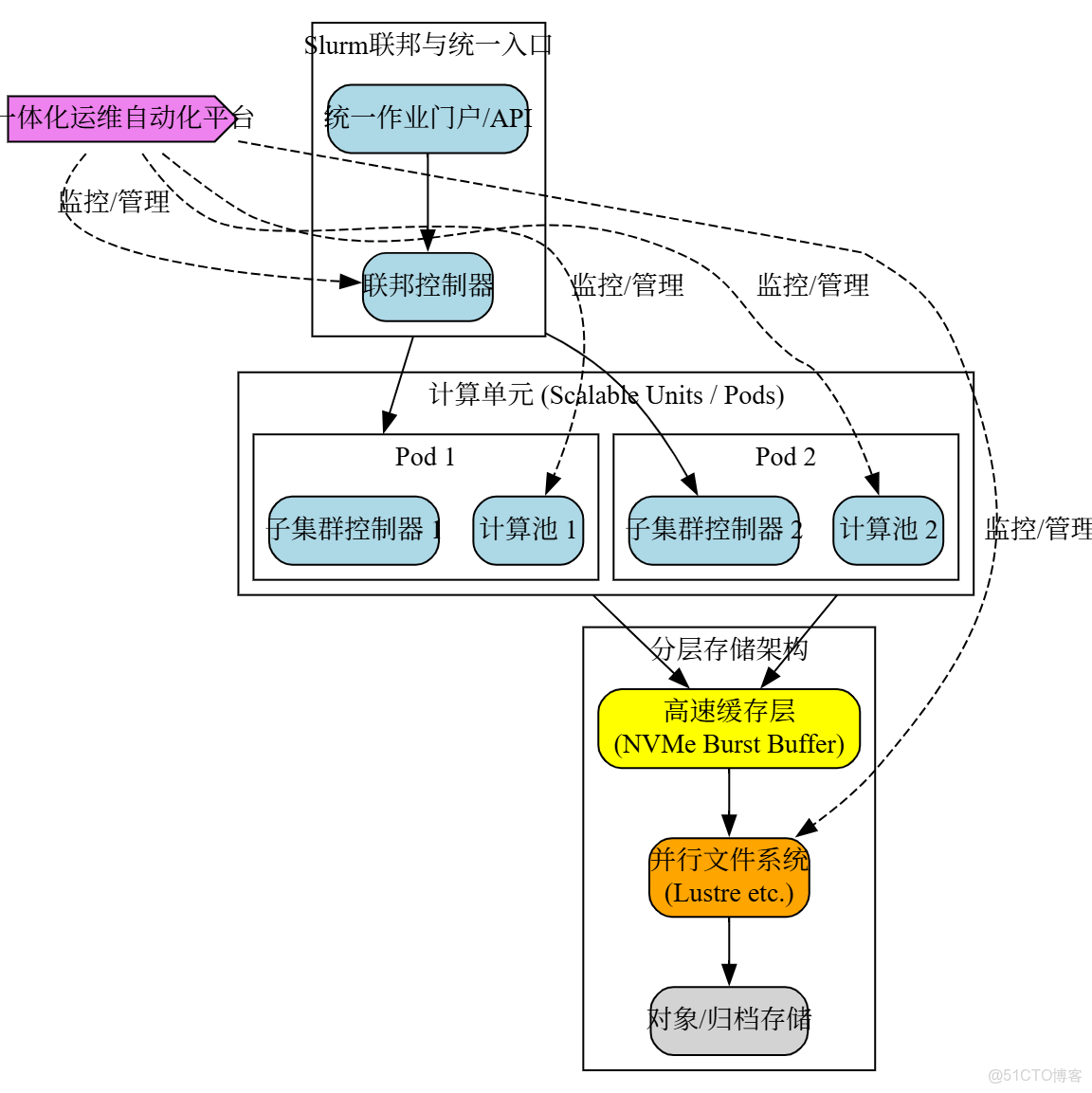
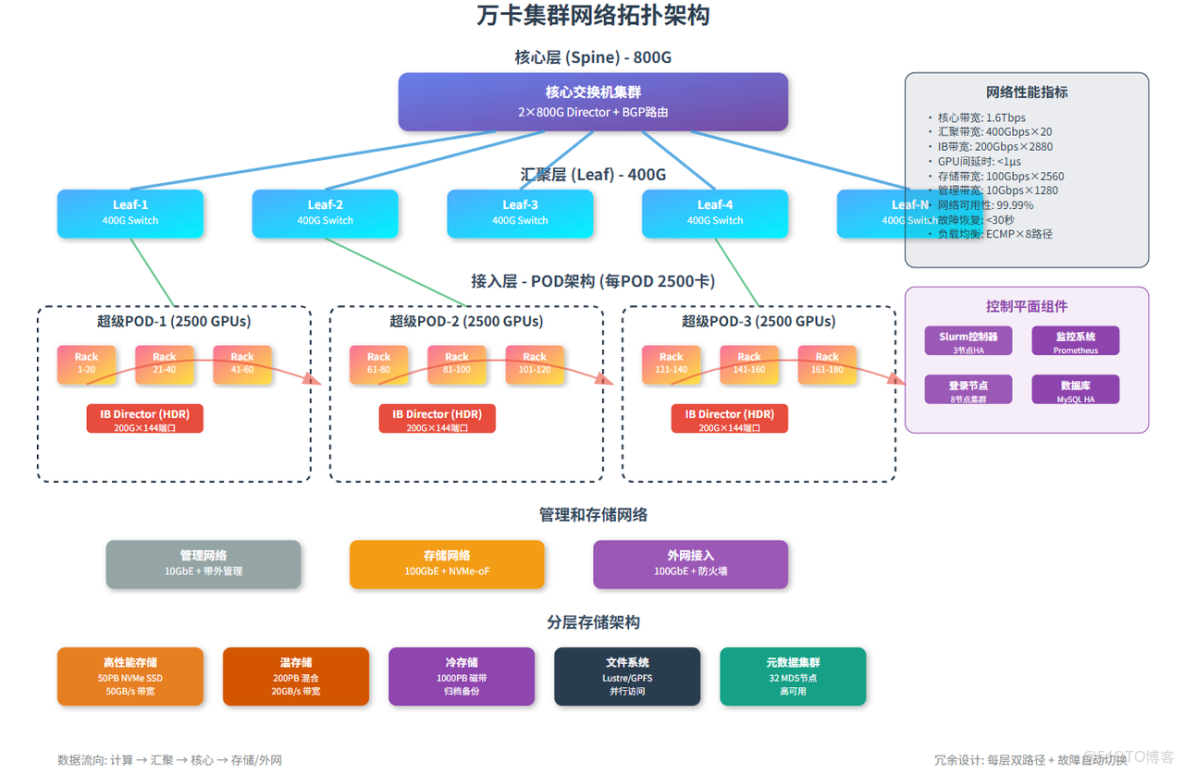
4.1 架構設計
採用Slurm Federation聯邦架構,將大集羣拆分為多個由子slurmctld管理的子集羣(Pod),上層由聯邦協調器統一調度。
4.2 部署要點
- 網絡:升級至3-Tier Fat-Tree或Dragonfly+拓撲,實現全局低延遲互聯。在計算節點上引入DPU卸載網絡和存儲負載。
- 分層存儲 (HSM):
- L1緩存: 基於NVMe-oF的Burst Buffer,用於熱數據讀寫。
- L2性能層: Lustre/BeeGFS並行文件系統。
- L3容量層: Ceph等對象存儲,用於數據歸檔。
- 運維體系:
- IaC/OaC: 全面使用Terraform, Ansible, GitOps管理集羣。
- AIOps: 建立智能運維平台,實現異常檢測、根因分析和故障自愈。
- Slurm核心配置:
- 在頂層和所有子集羣中配置Federation參數。
- 啓用TopologyPlugin,實現基於網絡拓撲的作業調度,優化通信密集型任務。
5. 總結對比
|
特性/階段
|
百卡驗證集羣 |
千卡生產集羣 |
萬卡超算集羣 |
|
Slurm架構 |
單控制器
|
主備高可用
|
Slurm聯邦 (Federation)
|
|
網絡技術 |
以太網 / 入門IB
|
高性能IB (NDR)
|
3-Tier IB / DPU
|
|
存儲方案 |
NFS
|
並行文件系統
|
分層存儲 (HSM)
|
|
運維管理 |
半自動化腳本
|
體系化運維
|
AIOps / OaC
|
6. 結語
從0到1萬卡GPU集羣的演進,是技術架構和運維理念不斷升級的過程。通過分階段、模塊化的建設思路,可以有效控制風險,平滑擴展,最終構建出能夠支撐未來AI發展的強大算力底座。